深度学习之实验三 手写数字识别
一、实验目的
1.熟练掌握 MNIST 手写数字数据集的特性与处理流程(加载、预处理、划分),理解数据预处理对模型适配的关键作用,能根据不同网络输入要求完成数据格式调整。
2.学会基于 PyTorch 框架,将 LeNet、AlexNet、VGG、ResNet、MobileNet 及 “VGG+注意力机制” 等网络应用于手写数字识别任务,明确各网络针对 10 分类任务(0-9 数字)的结构适配逻辑。
3.深入理解各经典网络的设计原理与性能特点,对比不同网络在手写数字识别任务中的准确率、推理效率差异,掌握 “基础网络+注意力机制” 的性能优化思路。
4.培养基于实际任务需求选择与调整网络模型的工程能力,为后续复杂图像识别任务中的模型设计与优化奠定基础。
二、实验内容
1.采用LeNet网络实现手写数字识别
(1)网络结构适配
基于 LeNet 原始架构(专为手写数字识别设计),无需大幅调整,核心适配点:
输入层:保持单通道设计,适配 MNIST 28×28 图像,确保输入维度与网络首层卷积核参数匹配。
卷积与池化层:保留 2 个卷积层(5×5 卷积核,逐步提升通道数)、2 个最大池化层(2×2 池化核,步长 2),通过卷积提取图像局部特征,池化减少特征维度并保留关键信息。
全连接层:调整最终输出层维度为 10(对应 0-9 数字分类),前序全连接层维度根据卷积 + 池化后特征图的展平维度适配,确保数据流向逻辑连贯。
(2)网络测试与性能分析
模型推理:将预处理后的测试集输入适配后的 LeNet 网络,获取模型预测结果,计算测试准确率,评估网络对简单手写数字特征的提取能力。
性能总结:分析 LeNet 作为早期网络的优势(结构简单、计算量小、推理速度快)与局限(深层特征提取能力弱,复杂手写数字变形场景精度有限),总结其在手写数字识别任务中的适用场景。
进入之前的py39虚拟环境,检查 PyTorch 是否可用

欧克,检擦完成,接下来开始创建工程实现。
1、工程创建
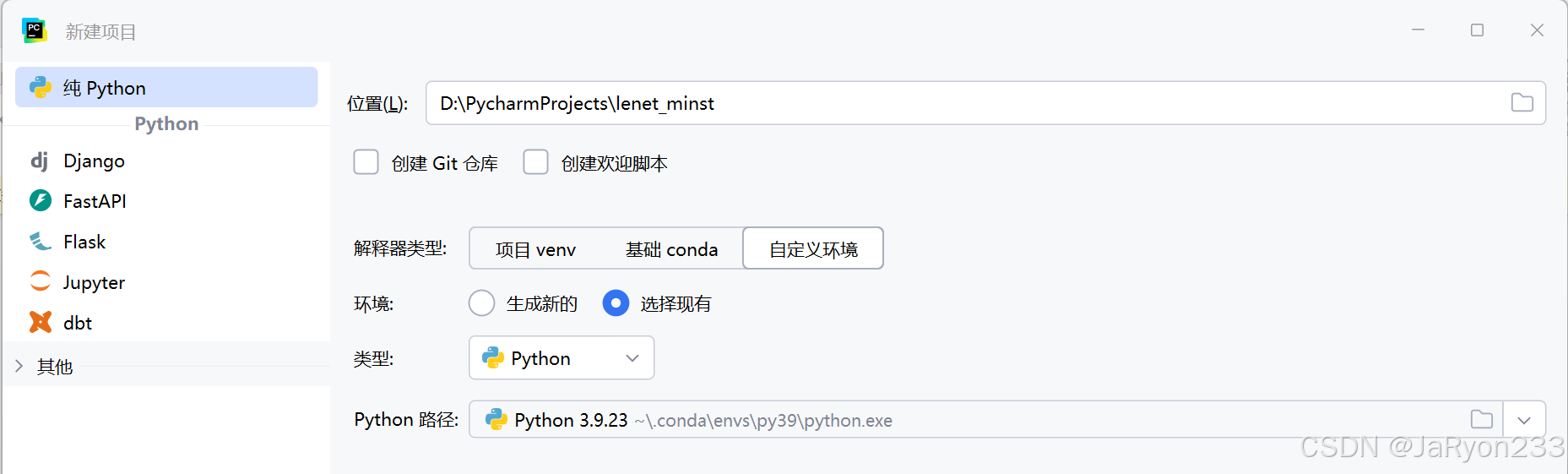
2、工程结构创建
如何,新建文件和主程序文件,结果如下图所示。

3、编写网络结构文件
在 lenet_mnist\models 文件夹下创建 lenet.py 文件
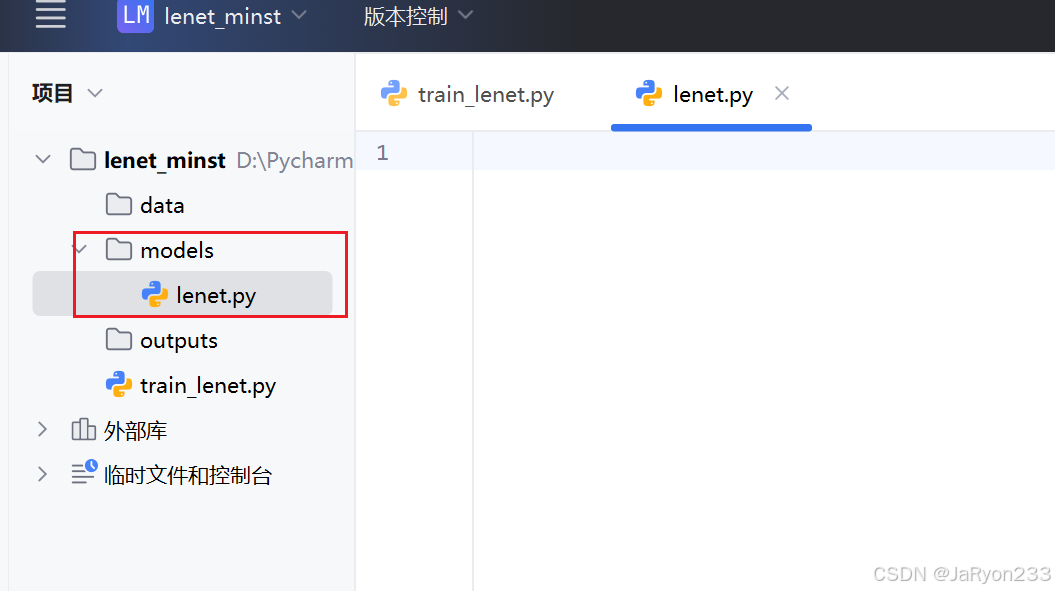
并编写代码如下所示
import torch
import torch.nn as nn
import torch.nn.functional as Fclass AlexNetMNIST(nn.Module):def __init__(self, num_classes=10):super(AlexNetMNIST, self).__init__()self.features = nn.Sequential(nn.Conv2d(1, 64, kernel_size=11, stride=4, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(64, 192, kernel_size=5, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(192, 384, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.AdaptiveAvgPool2d((1, 1)) )self.classifier = nn.Sequential(nn.Dropout(0.5),nn.Linear(256*1*1, 4096),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes))def forward(self, x):x = self.features(x)x = torch.flatten(x, 1)x = self.classifier(x)return x
4、编写训练脚本
在项目根目录(D:\lenet_mnist\)下文件 train_lenet.py中编写训练脚本,参考代码如下
# train_lenet.py
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from models.lenet import LeNet
from tqdm import tqdm
import matplotlib.pyplot as plt
import os# ==================== 参数定义 ====================
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
BATCH_SIZE = 64
LR = 0.01
EPOCHS = 10
SAVE_PATH = "./outputs/lenet_mnist.pth"# ==================== 数据加载 ====================
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])train_dataset = datasets.MNIST(root="./data", train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root="./data", train=False, download=True, transform=transform)train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)# ==================== 模型定义 ====================
model = LeNet().to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=LR, momentum=0.9)# ==================== 训练与测试函数 ====================
def train_one_epoch(epoch):model.train()running_loss, correct, total = 0.0, 0, 0for images, labels in tqdm(train_loader, desc=f"Epoch {epoch} Training"):images, labels = images.to(DEVICE), labels.to(DEVICE)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item() * images.size(0)_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()return running_loss / total, correct / totaldef test_model():model.eval()total_loss, correct, total = 0, 0, 0with torch.no_grad():for images, labels in tqdm(test_loader, desc="Testing"):images, labels = images.to(DEVICE), labels.to(DEVICE)outputs = model(images)loss = criterion(outputs, labels)total_loss += loss.item() * images.size(0)_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()return total_loss / total, correct / total# ==================== 主训练循环 ====================
train_losses, test_losses, train_accs, test_accs = [], [], [], []for epoch in range(1, EPOCHS + 1):train_loss, train_acc = train_one_epoch(epoch)test_loss, test_acc = test_model()train_losses.append(train_loss); test_losses.append(test_loss)train_accs.append(train_acc); test_accs.append(test_acc)print(f"\nEpoch {epoch}/{EPOCHS} | Train Loss: {train_loss:.4f} Acc: {train_acc*100:.2f}% | Test Loss: {test_loss:.4f} Acc: {test_acc*100:.2f}%")# ==================== 保存模型 ====================
os.makedirs("./outputs", exist_ok=True)
torch.save(model.state_dict(), SAVE_PATH)
print(f"\nModel saved to {SAVE_PATH}")# ==================== 绘制曲线 ====================
plt.figure(figsize=(8,4))
plt.subplot(1,2,1)
plt.plot(train_losses, label='Train Loss')
plt.plot(test_losses, label='Test Loss')
plt.legend(); plt.title('Loss Curve')plt.subplot(1,2,2)
plt.plot(train_accs, label='Train Acc')
plt.plot(test_accs, label='Test Acc')
plt.legend(); plt.title('Accuracy Curve')plt.tight_layout()
plt.show()
当然,可能需要额外安装库tqdm。
tqdm 是一个 Python 的进度条库,常用于训练循环中显示训练进度。如果你在运行时看到 红色波浪线,可以进入虚拟环境确认当前环境是否包含 tqdm:
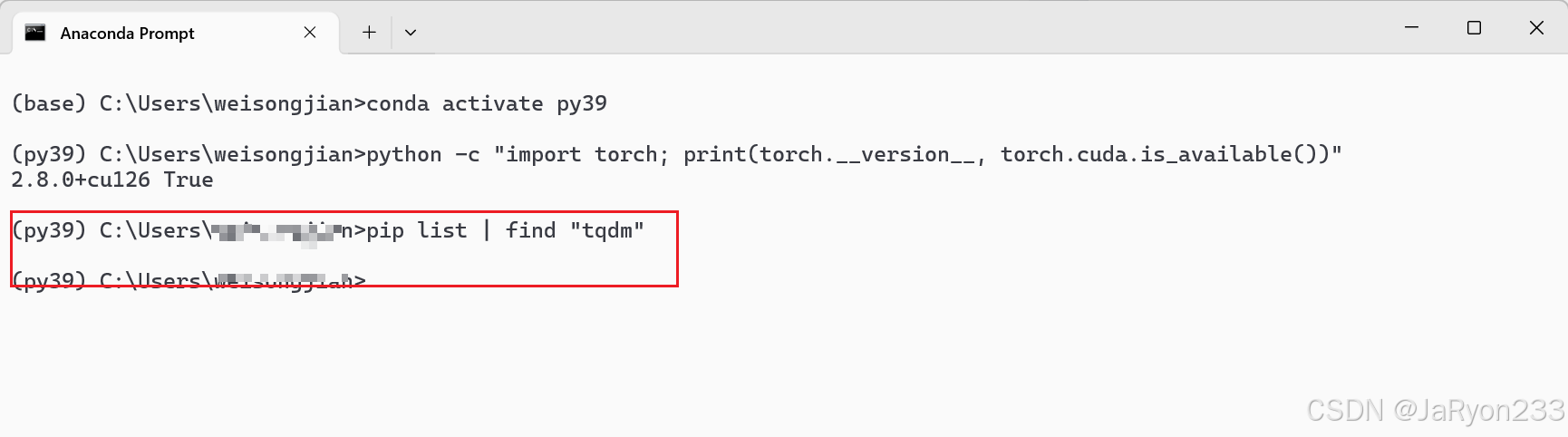
没有输出,就说明没装。
那就安装一下 tqdm,终端输入pip install tqdm回车。安装成功后如下图所示
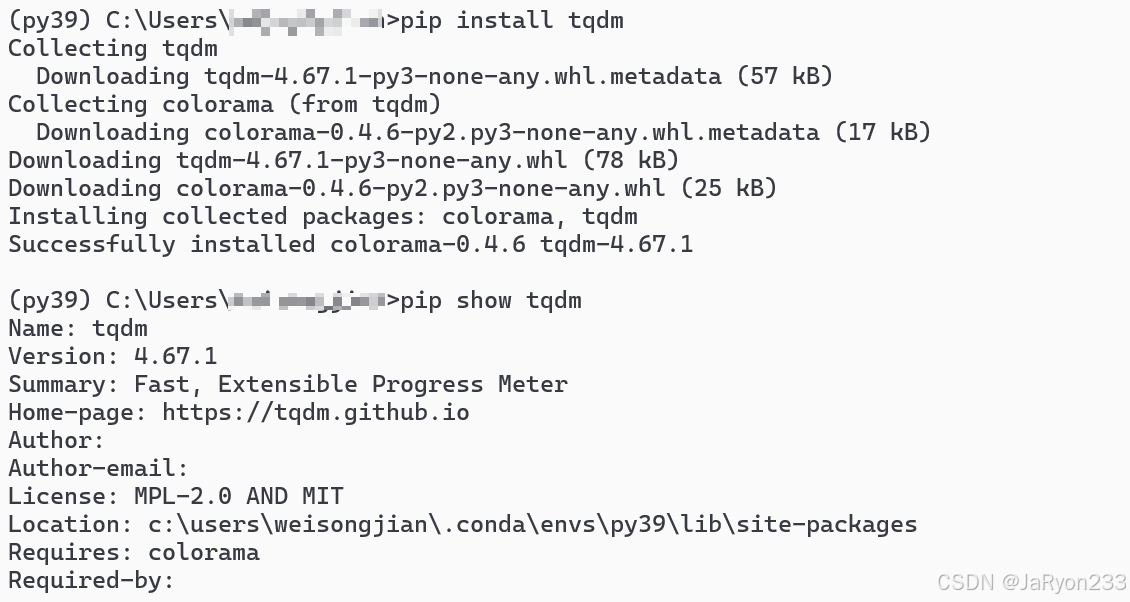
此时代码不在爆红,如下图所示
5、运行程序
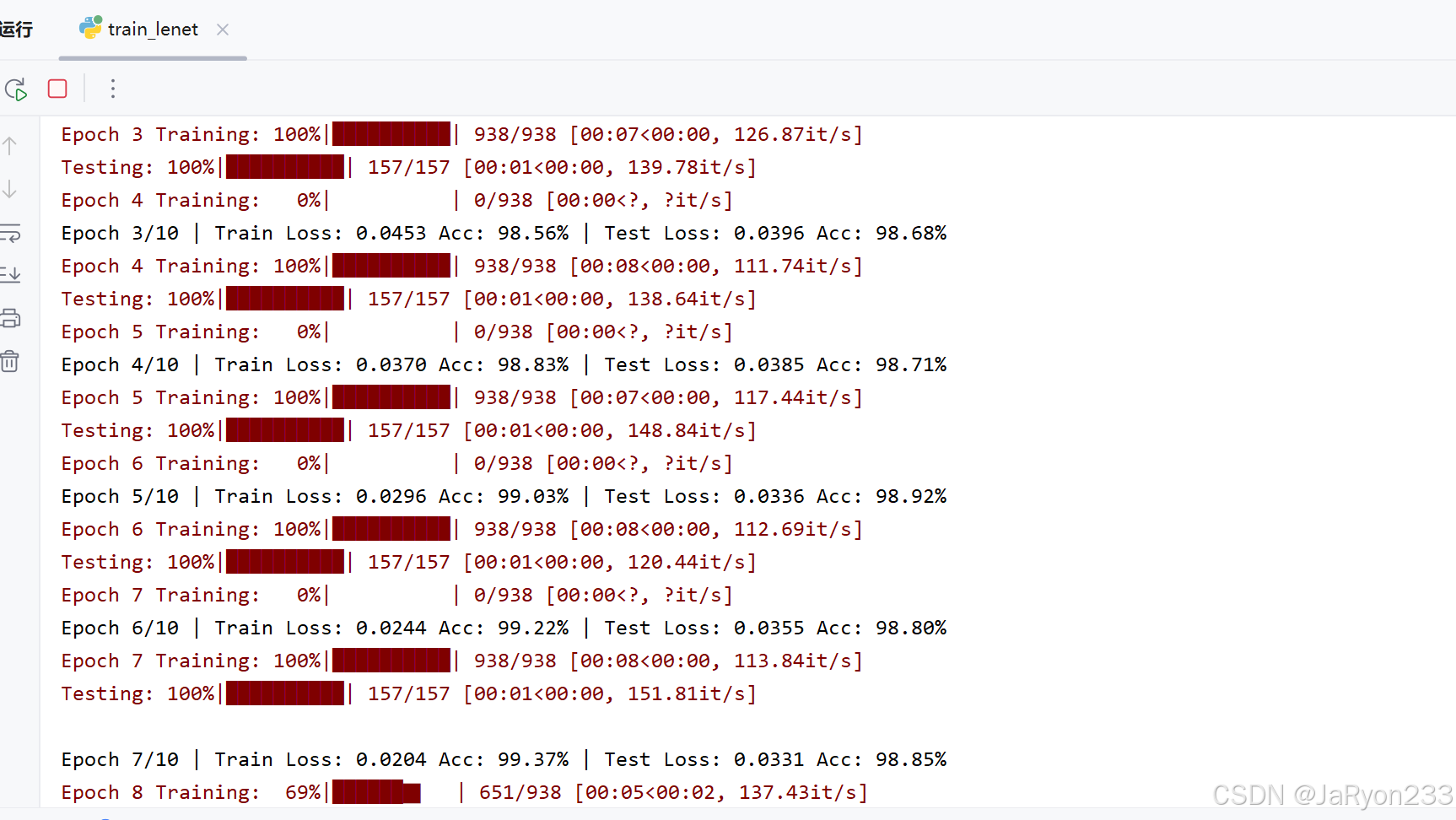
接着运行训练脚本。第一次运行时会自动从 torchvision 下载 MNIST 数据集,大约几十 MB。下载后自动缓存到 data/ 文件夹。
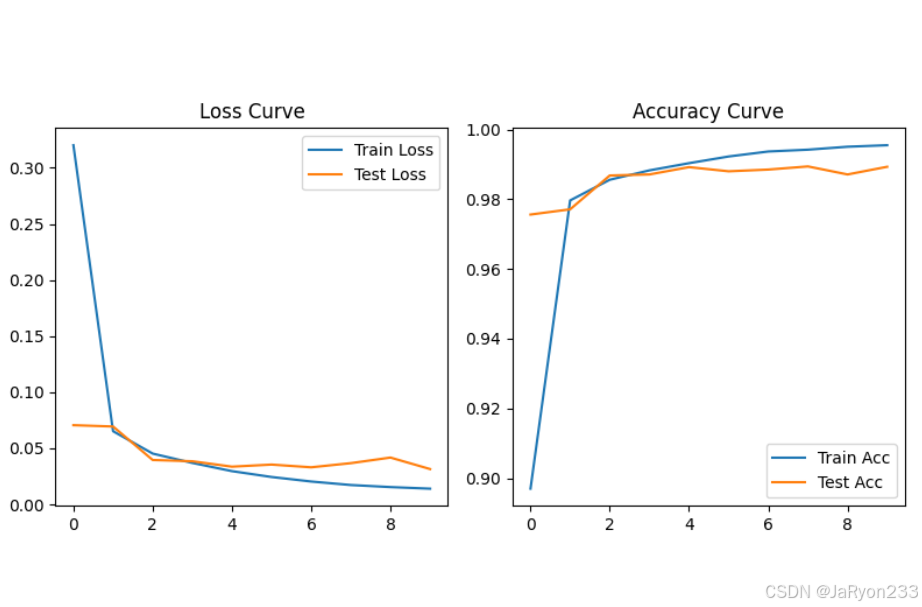
最后弹出两张图(损失曲线 + 准确率曲线),如下图所示。
6、结果测试
新建test.py文件,编写如下所示代码,进行手写数字识别测试。
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from models.lenet import LeNet
import random# -------------------------------
# 1. 数据准备
# -------------------------------
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)# -------------------------------
# 2. 加载模型
# -------------------------------
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = LeNet().to(device)
model.load_state_dict(torch.load("outputs/lenet_mnist.pth", map_location=device))
model.eval()# -------------------------------
# 3. 计算测试准确率
# -------------------------------
correct = 0
total = 0
with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)outputs = model(data)_, predicted = torch.max(outputs, 1)total += target.size(0)correct += (predicted == target).sum().item()print(f"测试集准确率: {100 * correct / total:.2f}%")# -------------------------------
# 4. 随机展示模型识别结果
# -------------------------------
fig, axes = plt.subplots(2, 5, figsize=(10, 4))
for i, ax in enumerate(axes.flat):idx = random.randint(0, len(test_dataset) - 1)img, label = test_dataset[idx]with torch.no_grad():pred = model(img.unsqueeze(0).to(device))pred_label = pred.argmax(dim=1).item()ax.imshow(img.squeeze(), cmap='gray')ax.set_title(f"GT:{label}, Pred:{pred_label}")ax.axis('off')plt.tight_layout()
plt.show()
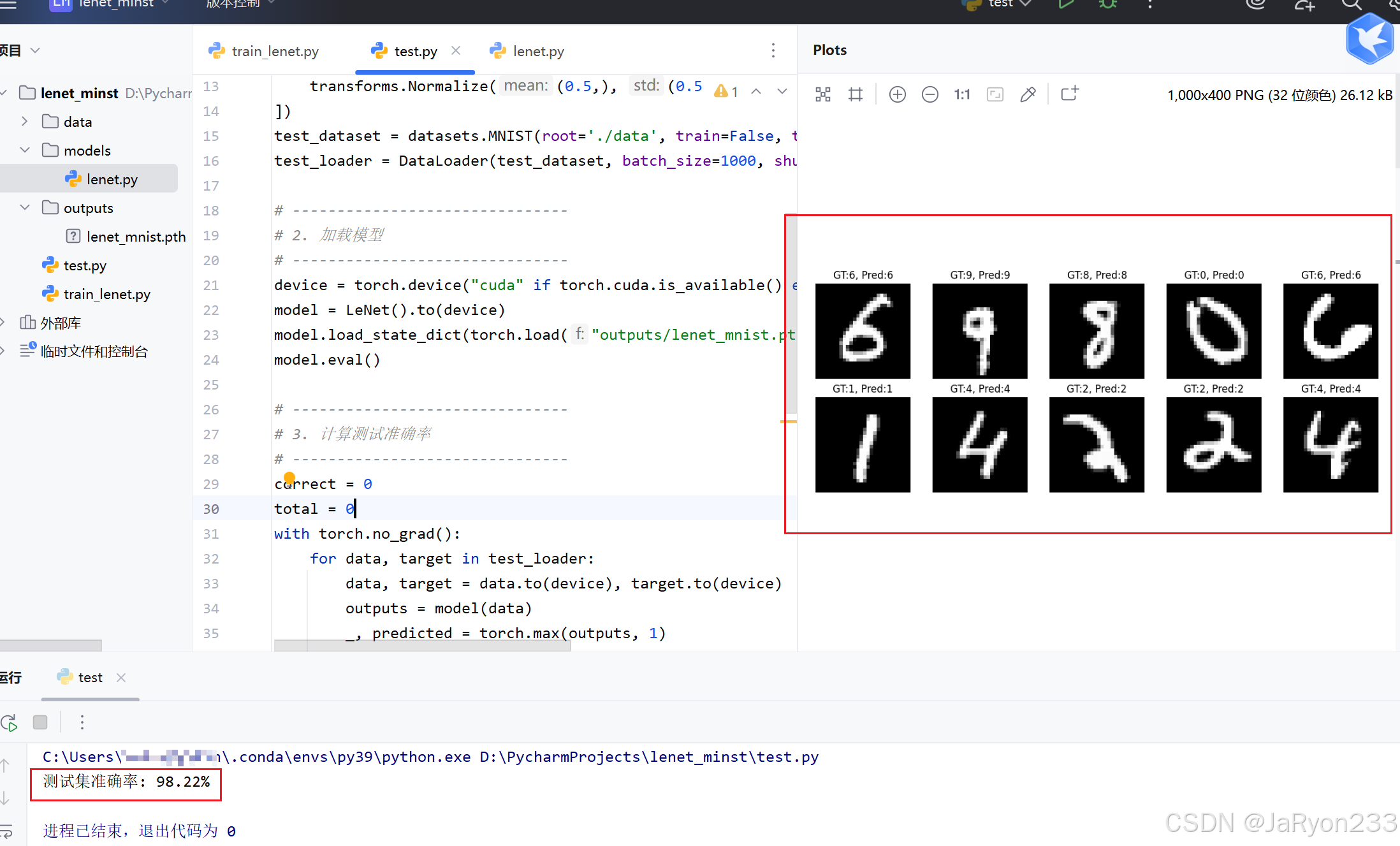
运行程序可得下属结果
2.采用AlexNet网络实现手写数字识别
(1)网络结构适配
基于 AlexNet“5 卷积 + 3 全连接” 架构,针对 MNIST 任务调整:
输入层适配:通过通道复制将 MNIST 单通道图像转为三通道,或修改首层卷积层输入通道数为 1;若网络要求固定输入尺寸(如 224×224),通过插值将 28×28 图像放大,确保输入维度与卷积层参数匹配。
卷积与池化层:保留 5 个卷积层(首层 11×11 卷积核、步长 4,后续层 3×3 或 5×5 卷积核)、3 个最大池化层(3×3 池化核、步长 2),通过多卷积层逐步提取更复杂的图像特征,重叠池化提升特征提取精度。
分类层调整:将原始 1000 类输出的全连接层改为 10 类,保留 dropout 层(失活概率 0.5)以减少过拟合,确保网络适配 10 分类任务。
(2)网络测试与性能分析
模型推理:使用预处理后的测试集评估网络性能,计算测试准确率,对比 LeNet 分析 AlexNet 因 “多卷积层 + 复杂特征提取” 带来的精度提升。
性能总结:分析 AlexNet 相比 LeNet 的优势(深层特征提取能力强、精度更高)与不足(参数量与计算量更大、推理速度较慢),总结其在手写数字识别中对复杂特征场景的适配性。
🆗,同理首先创建新的工程
1、工程创建
2、工程目录构建
如何搭建号工程目录结构的框架,为编写代码做准备。
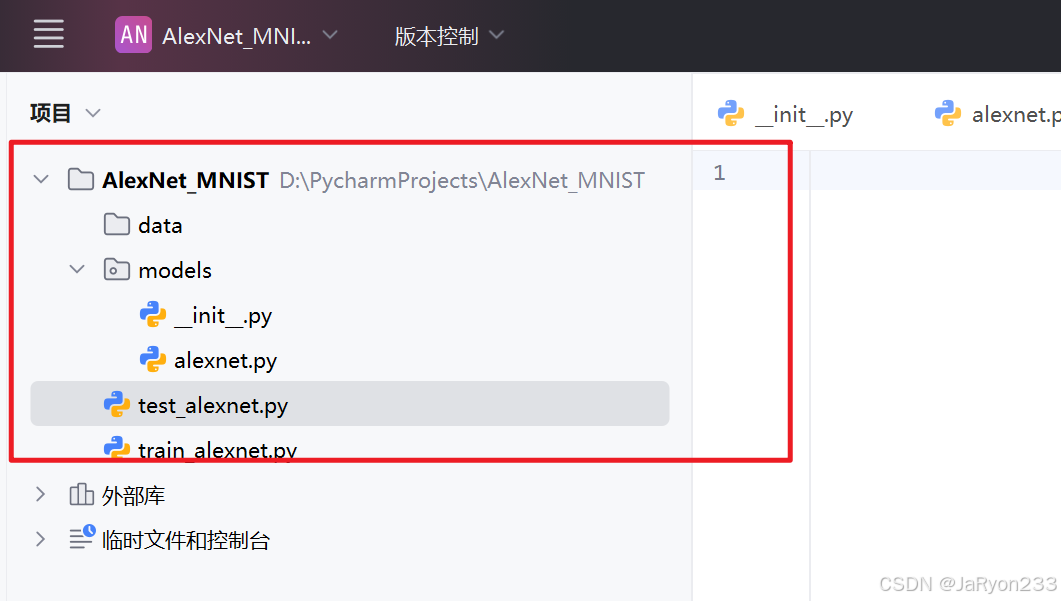
3、网络构建
接下来在alexnet.py文件编写网络结构文件,参考代码如下
import torch
import torch.nn as nn
import torch.nn.functional as Fclass AlexNetMNIST(nn.Module):def __init__(self, num_classes=10):super(AlexNetMNIST, self).__init__()self.features = nn.Sequential(nn.Conv2d(1, 64, kernel_size=11, stride=4, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(64, 192, kernel_size=5, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(192, 384, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.AdaptiveAvgPool2d((1, 1)) # 自适应池化)self.classifier = nn.Sequential(nn.Dropout(0.5),nn.Linear(256*1*1, 1024), # 将4096改小以匹配MNIST任务nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(1024, 512),nn.ReLU(inplace=True),nn.Linear(512, num_classes))def forward(self, x):x = self.features(x)x = torch.flatten(x, 1)x = self.classifier(x)return x
注:256*1*1 的数字需要根据输入图像尺寸和卷积池化输出特征图大小调整
4、编写训练脚本(模型训练)
在新建的alexnet_train.py中编写模型训练代码,参考代码如下
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from models.alexnet import AlexNetMNISTdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 数据预处理
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])# 数据加载
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=128, shuffle=False)# 模型、损失、优化器
model = AlexNetMNIST().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)epochs = 10
for epoch in range(epochs):model.train()total_loss = 0for data, target in train_loader:data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()total_loss += loss.item()# 每个 epoch 输出训练 Lossavg_loss = total_loss / len(train_loader)# 测试集准确率model.eval()correct = 0total = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)_, predicted = torch.max(output, 1)total += target.size(0)correct += (predicted == target).sum().item()accuracy = 100 * correct / totalprint(f"Epoch {epoch+1}, Loss: {avg_loss:.4f}, Test Accuracy: {accuracy:.2f}%")model.train()# 保存模型
torch.save(model.state_dict(), "alexnet_mnist.pth")
5、运行训练脚本
运行上面模型训练代码,进行模型训练,整个过程可能有点慢,耐心你等待。

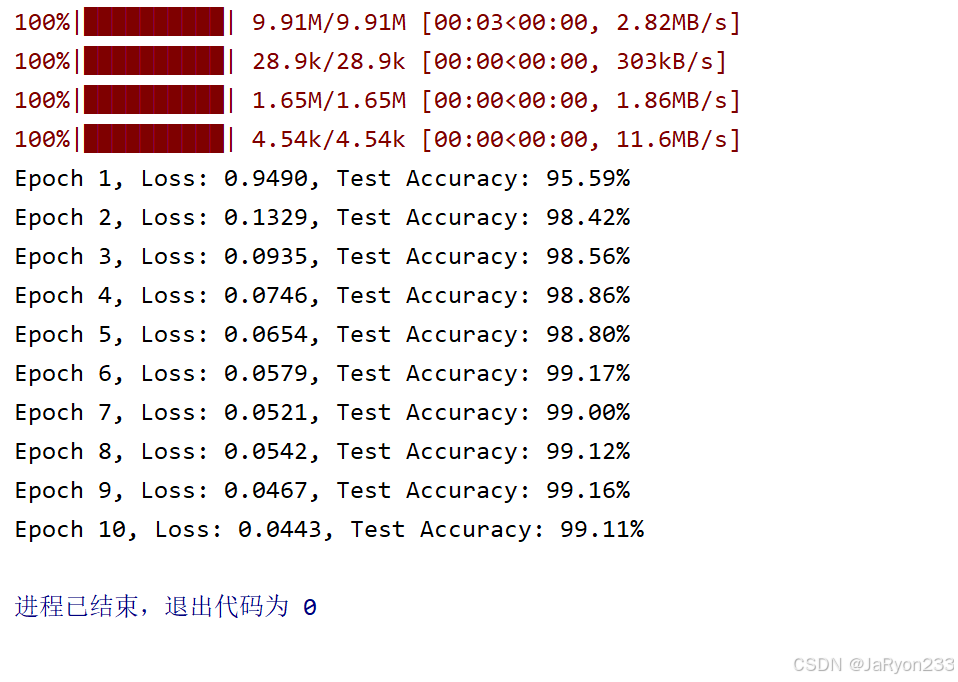
6、结果测试
最后编写test.py文件,测试一下。参考代码如下
import torch
import torch.nn as nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from models.alexnet import AlexNetMNIST
import matplotlib.pyplot as plt
import random# ===================================
# 1️ 设备选择
# ===================================
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")# ===================================
# 2️ 数据预处理(需与训练一致)
# ===================================
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])# ===================================
# 3️ 加载测试集
# ===================================
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)# ===================================
# 4️ 加载模型
# ===================================
model = AlexNetMNIST().to(device)
model.load_state_dict(torch.load("alexnet_mnist.pth", map_location=device))
model.eval()
print("模型加载完成,开始测试...")# ===================================
# 5️ 评估模型准确率
# ===================================
correct = 0
total = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)outputs = model(data)_, predicted = torch.max(outputs, 1)total += target.size(0)correct += (predicted == target).sum().item()accuracy = 100 * correct / total
print(f"测试集准确率: {accuracy:.2f}%")# ===================================
# 6️ 随机展示几个预测结果
# ===================================
print("\n随机展示预测结果:")
indices = random.sample(range(len(test_dataset)), 5)
for idx in indices:# 取样数据image, label = test_dataset[idx]image_input = image.unsqueeze(0).to(device)# 模型推理output = model(image_input)_, pred = torch.max(output, 1)# 反归一化并显示img_show = image.squeeze() * 0.5 + 0.5 # 反归一化plt.imshow(img_show, cmap='gray')plt.title(f"True: {label}, Pred: {pred.item()}")plt.axis('off')plt.show()
运行代码可得结果如下
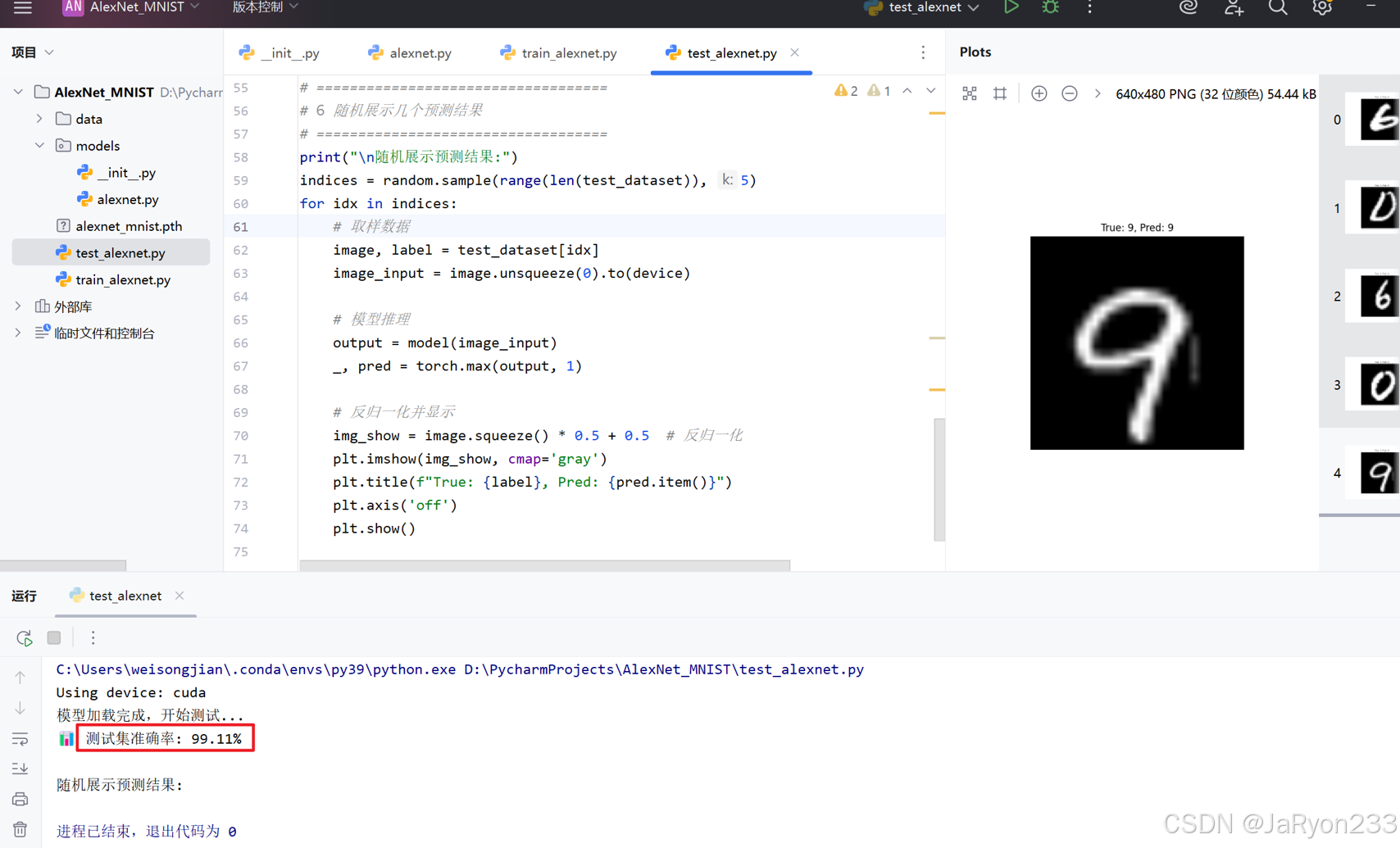
显然,随机测试结果最终测试数据集正确率达99%左右
3、采用VGG网络实现手写数字识别
(1)网络结构适配
基于 VGG 经典架构(以 VGG16 为例,“13 卷积 + 3 全连接”,分 5 个卷积块),适配 MNIST 任务:
输入层适配:同 AlexNet,通过通道复制或输入层参数调整适配三通道要求,插值调整图像尺寸至网络所需规格(如 224×224)。
卷积与池化层:保留 5 个卷积块(2+2+3+3+3 个卷积层),每个卷积层使用 3×3 小卷积核、padding=1(确保卷积后特征图尺寸不变),每个卷积块后接 2×2 步长 2 的最大池化层;通过 “小卷积核 + 多层数” 组合,增强局部特征提取能力,提升特征表达精度。
分类层调整:将全连接层输出维度从 1000 改为 10,保留 dropout 层(失活概率 0.5),根据卷积块最终输出特征图的展平维度(如 512×7×7)适配前序全连接层输入维度。
(2)网络测试与性能分析
模型推理:测试网络在 MNIST 测试集上的准确率,对比 AlexNet 分析 “小卷积核 + 深层数” 结构对特征提取精度的提升效果。
性能总结:分析 VGG 优势(特征提取更精细、精度更高)与局限(参数量大、计算成本高、推理速度慢),总结其在对精度要求较高的手写数字识别场景中的适用性。
1、工程创建
同理创建工程VGG_MNIST。
2、工程目录构建
如何搭建号工程目录结构的框架,为编写代码做准备。

3、网络构建
接下来在alexnet.py文件编写网络结构文件,参考代码如下
# models/vgg.py
import torch
import torch.nn as nnclass VGG16_MNIST(nn.Module):"""VGG16-style network adapted to MNIST:- input channel = 1- uses 5 conv blocks (2,2,3,3,3 conv layers)- uses MaxPool 2x2 after each block- classifier outputs 10 classes with Dropout(0.5)- expects input resized to 224x224 (we do Resize in transforms)"""def __init__(self, num_classes=10):super().__init__()# conv blocks (in_channels, out_channels)self.features = nn.Sequential(# Block1: 1 -> 64nn.Conv2d(1, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2), # 112x112# Block2: 64 -> 128nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2), # 56x56# Block3: 128 -> 256nn.Conv2d(128, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2), # 28x28# Block4: 256 -> 512nn.Conv2d(256, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2), # 14x14# Block5: 512 -> 512nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2), # 7x7)# classifier - note: for input 224x224 final feature map is 512x7x7 -> 25088self.classifier = nn.Sequential(nn.Dropout(0.5),nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes))def forward(self, x):x = self.features(x)x = torch.flatten(x, 1) # batch x (512*7*7)x = self.classifier(x)return x
注:256*1*1 的数字需要根据输入图像尺寸和卷积池化输出特征图大小调整
4、编写训练脚本(模型训练)
在新建的alexnet_train.py中编写模型训练代码,参考代码如下
# train_vgg.py
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from models.vgg import VGG16_MNISTdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Device:", device)# transforms: Resize to 224x224, keep single channel
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])# datasets and loaders
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=2, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=256, shuffle=False, num_workers=2, pin_memory=True)# model, loss, optimizer
model = VGG16_MNIST().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5) # decayepochs = 12
for epoch in range(1, epochs+1):model.train()running_loss = 0.0for images, labels in train_loader:images, labels = images.to(device), labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item() * images.size(0)avg_loss = running_loss / len(train_loader.dataset)# validationmodel.eval()correct = 0total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)outputs = model(images)_, preds = torch.max(outputs, 1)total += labels.size(0)correct += (preds == labels).sum().item()acc = 100.0 * correct / totalprint(f"Epoch {epoch}/{epochs} Loss: {avg_loss:.4f} Test Acc: {acc:.2f}%")scheduler.step()# save model
torch.save(model.state_dict(), "vgg16_mnist.pth")
print("Saved vgg16_mnist.pth")
5、运行训练脚本
运行上面模型训练代码,进行模型训练,整个过程可能有点慢,耐心你等待。
6、结果测试
最后编写test.py文件,测试一下。参考代码如下
# test_vgg.py
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from models.vgg import VGG16_MNIST
import matplotlib.pyplot as plt
import randomdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = DataLoader(test_dataset, batch_size=128, shuffle=False)model = VGG16_MNIST().to(device)
model.load_state_dict(torch.load("vgg16_mnist.pth", map_location=device))
model.eval()# accuracy
correct = 0
total = 0
with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)outputs = model(images)_, preds = torch.max(outputs, 1)total += labels.size(0)correct += (preds == labels).sum().item()
acc = 100.0 * correct / total
print(f"Test Accuracy: {acc:.2f}%")# show random samples
indices = random.sample(range(len(test_dataset)), 6)
for idx in indices:img, lbl = test_dataset[idx]out = model(img.unsqueeze(0).to(device))_, pred = torch.max(out, 1)img_show = img.squeeze() * 0.5 + 0.5plt.imshow(img_show, cmap='gray')plt.title(f"GT:{lbl} Pred:{pred.item()}")plt.axis('off')plt.show()
运行代码可得结果如下
显然,随机测试结果最终测试数据集正确率达99%左右
后面的哎不想写了,,,无后续