先知社区文章批量爬虫工具
先知社区文章批量爬虫工具
一个ai味浓厚的先知文章批量爬取工具,由于打算利用pandawiki来搭建个人知识库,所以拷问ai写了这么个爬取先知文章的工具,后续作为知识库喂给ai
地址:https://github.com/Huu1j/crawl_xz
功能特点
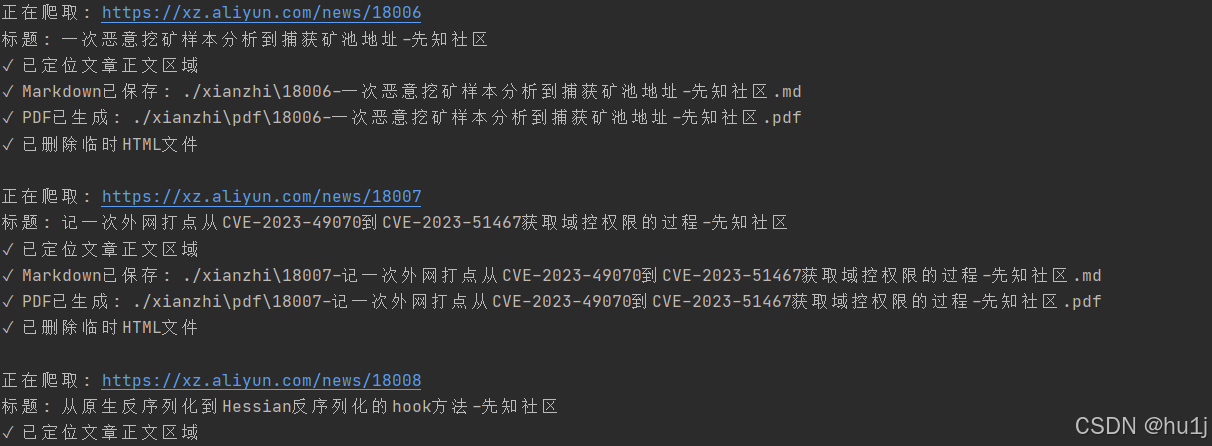
✅ 批量爬取先知社区(xz.aliyun.com)文章
✅ 支持 /t/ 和 /news/ 两种URL格式
✅ 精确提取标题和正文(去除评论、点赞等无关内容)
✅ 支持三种输出格式(Markdown/PDF/HTML)
✅ 无头模式运行,相对静默
安装依赖
1. 安装Python依赖包
pip install -r requirements.txt
2. Chrome浏览器
确保系统中已安装 Chrome 浏览器。程序会自动下载匹配版本的 ChromeDriver,无需手动配置!
若显示版本不匹配,删除当前目录的ChromeDriver,重新运行
使用方法
命令行参数
查看帮助:
python crawl_xz_aliyun.py --help
所有参数:
--type 文章类型 (news/t, 默认: news)
--start 起始文章ID (默认: 9450)
--end 结束文章ID (默认: 9455)
--format 输出格式 (md/md+pdf/all, 默认: all)
--sleep 请求间隔(秒)(默认: 5)
--dir 保存目录 (默认: ./xianzhi)
使用示例
示例 1:仅生成 Markdown
python crawl_xz_aliyun.py --format md --start 9450 --end 9455
示例 2:生成 MD + PDF
python crawl_xz_aliyun.py --format md+pdf --start 9450 --end 9455
示例 3:生成所有格式
python crawl_xz_aliyun.py --format all --start 9450 --end 9455
输出结果
爬取完成后,会在指定目录生成以下内容:
xianzhi/
├── images/ # 所有文章的图片
├── pdf/ # PDF和HTML文件
│ ├── 9450-文章标题.pdf
│ └── 9450-文章标题.html
└── 9450-文章标题.md # Markdown文件
注意事项
⚠️ 合法使用: 该项目仅用于个人学习研究
致谢
感谢先知社区提供优质的安全技术文章!
License
本项目仅供学习交流使用。
支持
如有问题或建议,欢迎反馈!