李宏毅机器学习笔记37
目录
摘要
1.Critic
Monte-Carlo(MC) based apporach
Temporal-difference(TD) apporach
Critic应用在actor
Advantage Actor-Critic
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是RL中的Critic,包括critic的基本概念,两种训练方法和差异,如何应用在actor上以及应用在actor后计算方式。
1.Critic
critic给作用是评估一个actor的好坏,定义一个函数V(s),输入是游戏状况s,输出是上一节提到的G'(discounted cumulated reward),但此时游戏并未结束,V(s)是预测actor得到什么样的reward。下图中表示不同轮次的actor。

critic有两种训练方法
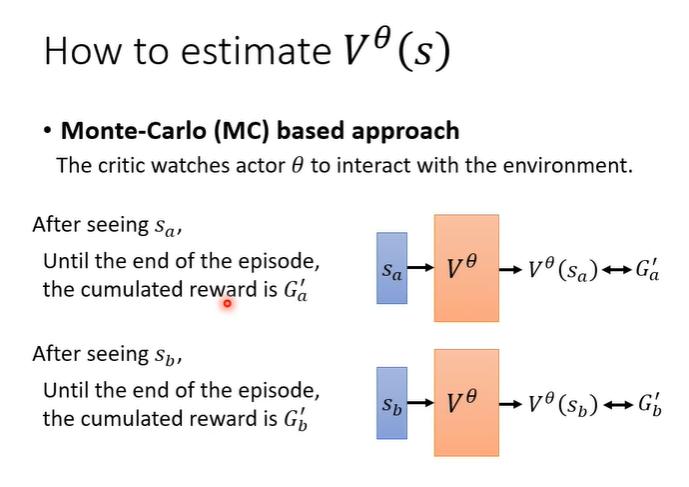
Monte-Carlo(MC) based apporach
MC方法是将actor与环境互动很多轮,得到很多训练资料,当看见s_a时输出应该与G'_a越近越好,这是一种很直观的做法。
Temporal-difference(TD) apporach
TD方法是希望不用玩完整场游戏才能得到训练资料,而是看见s_t,a_t,r_t,s_t+1就可以拿来更新V(s)的参数。这样的好处是当游戏时间较长甚至不会结束时,同样可以训练V(s)。观察V(s_t)与V(s_t+1),不难看出他们的关系,训练方法就是计算V(s_t)与V(s_t+1),虽然不知道他们应该是多少,但是知道他们应该符合他们的关系式。所以可以通过{s_t,a_t,r_t,s_t+1}这样一笔资料进行训练。

MC与TD存在一些差异,下图所示的8个episodes用于计算V(s),用MC会自然而然的得到1,而用TD会得到3/4,原因在于假设不同,MC假设是s_a与s_b是有关联的,而TD是假设s_a与s_b是无关联的,只是关于s_a的资料太少只看见了s_a使得r=0的情况.

Critic应用在actor
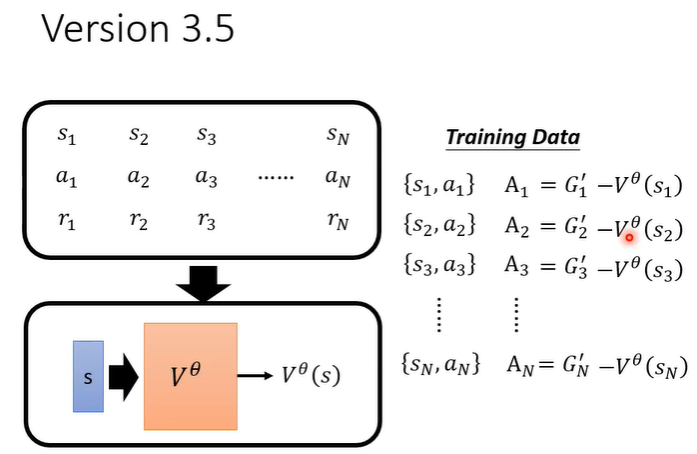
A做标准化时,需要让所有的G'减去一个baseline b为了让A有正有负。

这个b的值应该设为V(s)的值。
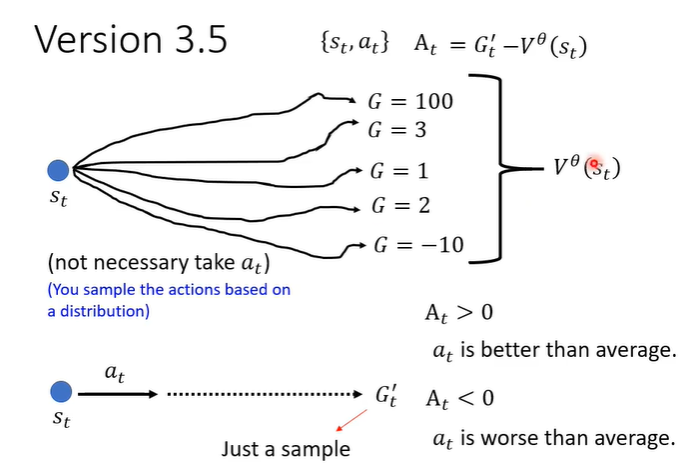
为什么它是合理的呢?V(s)的值实际上是看见画面s得到的reward的期望值,actor具有随机性做出的行为会有很多的可能,把这些可能的行为得到的分数平均起来就是V(s)的值。G'的含义是在画面s下执行行为a得到的评价分数,如果A大于0就代表G'大于V(s),说明行为a得到的分数高于平均,认为这个行为a是好的,所以我们鼓励actor执行a。如果A小于0就代表G'小于V(s),说明行为a得到的分数低于平均,认为这个行为a是不好的,所以我们不鼓励actor执行a。
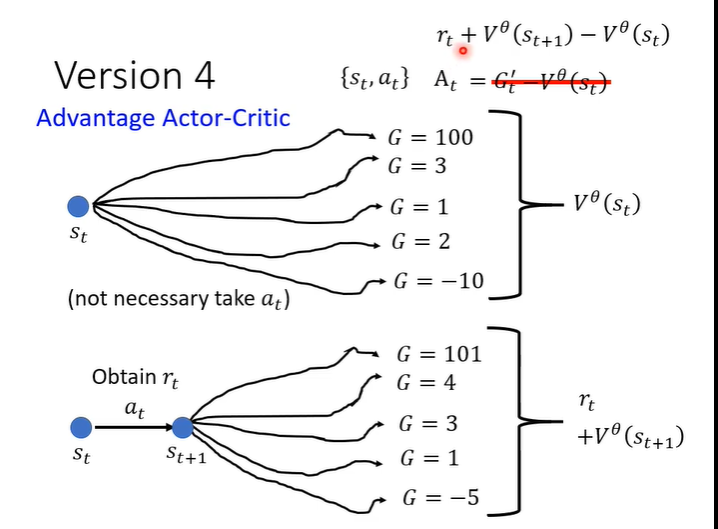
Advantage Actor-Critic
但是G'是一个sample的结果,即执行a后一直到游戏结束的一个结果,把一个sample减去平均并不合理。所以需要“平均减平均”,执行完a_t后得到r_t,在s_t的后一个画面s_t+1一直玩下去就得到很多可能,平均起来就是V(s_t+1),再加上r_t,代表原来的G'。