MySQL:with窗口函数说明及使用案例
窗口函数(Window Function)是MySQL 8.0引入的重要功能,允许在查询结果的特定"窗口"(数据子集)上执行计算,而不改变结果集的行数。与聚合函数不同,窗口函数不会将多行合并为一行。MySQL的WITH窗口函数(也称为公共表表达式CTE + 窗口函数)
1. 基本语法结构
WITH cte_name AS (SELECT column1,column2,window_function() OVER (PARTITION BY ... ORDER BY ...) as window_columnFROM table
)
SELECT * FROM cte_name;
- cte_name:结果集的名称,类似表名,可以当做是一张表,不过这个结果集不存在索引
- OVER:定义窗口的范围
- window_function():窗口函数,ROW_NUMBER(),RANK()等
- partition by:将数据分成多个独立的分区,类似group by子句,但是在窗口函数中,数据不会合并为一行
- order by:order by和普通查询语句中的order by没什么不同
2. 常用窗口函数分类
2.1 排名函数
| 函数 | 说明 | 示例 |
|---|---|---|
ROW_NUMBER() | 连续编号(无重复) | 1,2,3,4,5 |
RANK() | 排名(允许并列) | 1,2,2,4,5 |
DENSE_RANK() | 密集排名 | 1,2,2,3,4 |
2.2 聚合函数
| 函数 | 说明 |
|---|---|
SUM() OVER() | 窗口内求和 |
AVG() OVER() | 窗口内平均值 |
COUNT() OVER() | 窗口内计数 |
MAX() OVER() | 窗口内最大值 |
MIN() OVER() | 窗口内最小值 |
2.3 分布函数
| 函数 | 说明 |
|---|---|
NTILE(n) | 分成n组 |
PERCENT_RANK() | 百分比排名 |
CUME_DIST() | 累积分布 |
3. 实际应用示例
示例数据准备
-- 医疗影像检查记录表
CREATE TABLE medical_exams (exam_id INT PRIMARY KEY,patient_id INT COMMENT '患者ID',exam_date DATE COMMENT '检查日期',exam_type VARCHAR(50) COMMENT '检查类型',cost DECIMAL(10,2) COMMENT '费用',hospital_id INT COMMENT '医院ID'
);INSERT INTO medical_exams VALUES
(1, 101, '2024-01-10', 'CT', 500.00, 1),
(2, 101, '2024-01-15', 'MRI', 800.00, 1),
(3, 102, '2024-01-12', 'X-Ray', 200.00, 1),
(4, 103, '2024-01-18', 'CT', 500.00, 2),
(5, 101, '2024-01-20', 'Ultrasound', 300.00, 1),
(6, 104, '2024-01-22', 'MRI', 800.00, 2);
4. 详细用法示例
4.1 基础排名查询
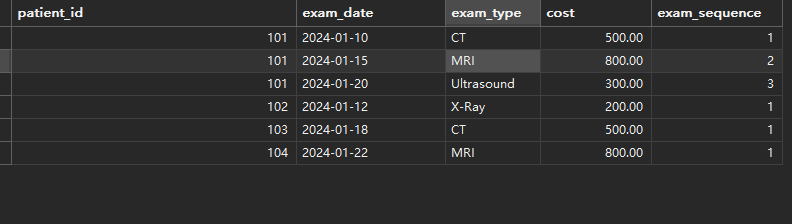
-- 每个患者的检查记录按时间排序,ROW_NUMBER()生成连续的行号
WITH patient_exams AS (SELECT patient_id,exam_date,exam_type,cost,ROW_NUMBER() OVER (PARTITION BY patient_id ORDER BY exam_date) as exam_sequenceFROM medical_exams
)
SELECT * FROM patient_exams;运行结果
4.2 累计统计
-- 计算每个患者的当前累计检查费用,平均费用
WITH patient_costs AS (SELECT patient_id,exam_date,exam_type,cost,SUM(cost) OVER (PARTITION BY patient_id ORDER BY exam_date) as cumulative_cost,AVG(cost) OVER (PARTITION BY patient_id) as avg_cost_per_examFROM medical_exams
)
SELECT * FROM patient_costs;
运行结果
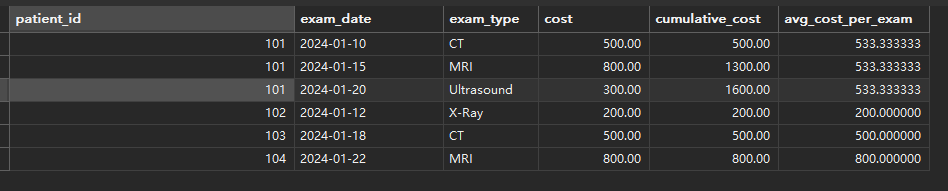
说明:id为101的第一次500,第二次累计500+800=1300,第三次500+800+300=1600
-- 获取每个患者的最近一次检查
WITH patient_exams AS (SELECT *,ROW_NUMBER() OVER (PARTITION BY patient_id ORDER BY exam_date DESC) as rnFROM medical_exams
)
SELECT * FROM patient_exams WHERE rn = 1;
-- 等同于以前用的group by语句
SELECT *
FROM medical_exams
WHERE (patient_id, exam_date) IN (SELECT patient_id, MAX(exam_date)FROM medical_examsGROUP BY patient_id
)
ORDER BY patient_id;
运行结果
4.3 获取前三的排名
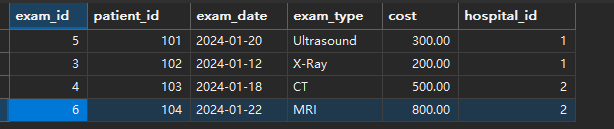
-- 每个医院内检查费用排名
WITH hospital_ranking AS (SELECT exam_id,patient_id,hospital_id,exam_type,cost,RANK() OVER (PARTITION BY hospital_id ORDER BY cost DESC) as cost_rank,-- 排名ROW_NUMBER() OVER (PARTITION BY hospital_id ORDER BY cost DESC) as row_num -- 连续编号FROM medical_exams
)
SELECT * FROM hospital_ranking
WHERE cost_rank <= 3; -- 每个医院费用前三的检查
运行结果

使用窗口函数 RANK() OVER (PARTITION BY hospital_id ORDER BY cost DESC) 按医院分组,按检查费用降序排名
5. 高级窗口函数用法
5.1 使用窗口框架
-- 计算移动平均(最近3次检查)
WITH moving_avg AS (SELECT patient_id,exam_date,cost,AVG(cost) OVER (PARTITION BY patient_id -- 按患者分组ORDER BY exam_date -- 按检查日期排序ROWS BETWEEN 2 PRECEDING AND CURRENT ROW -- 窗口范围:当前行+前2行
) as avg_last_3_examsFROM medical_exams
)
SELECT * FROM moving_avg;
- ROWS:按物理行数计算(不是按值)
- 2 PRECEDING:当前行之前的2行
- CURRENT ROW:当前行
- 合计:当前行 + 前2行 = 3行
这里的窗口可以加额外的条件,比如只计算最近一年的数据
...FROM medical_examsWHERE exam_date >= DATE_SUB(CURDATE(), INTERVAL 1 YEAR)
计算过程
-- 第1行:只有当前行
窗口范围:第1行
计算:(500) / 1 = 500.00-- 第2行:前1行 + 当前行
窗口范围:第1-2行
计算:(500 + 800) / 2 = 650.00-- 第3行:前2行 + 当前行
窗口范围:第1-3行
计算:(500 + 800 + 300) / 3 = 533.33-- 第4行:前2行 + 当前行(第2-4行)
窗口范围:第2-4行
计算:(800 + 300 + 600) / 3 = 566.67-- 第5行:前2行 + 当前行(第3-5行)
窗口范围:第3-5行
计算:(300 + 600 + 400) / 3 = 433.33
运行结果
patient_id | exam_date | cost | avg_last_3_exams
101 | 2024-01-10 | 500.00 | 500.00
101 | 2024-01-15 | 800.00 | 650.00
101 | 2024-01-20 | 300.00 | 533.33
101 | 2024-01-25 | 600.00 | 566.67
101 | 2024-01-30 | 400.00 | 433.33
窗口框架的其他写法
-- 写法1:明确指定
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW-- 写法2:简写(MySQL 8.0+)
ROWS 2 PRECEDING-- 写法3:向后扩展
ROWS BETWEEN CURRENT ROW AND 2 FOLLOWING -- 当前行+后2行-- 写法4:前后扩展
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING -- 前1行+当前行+后1行-- 写法5:无界窗口
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW -- 从开始到当前行
ROWS vs RANGE 的区别
| 特性 | ROWS(物理行) | RANGE(逻辑值) |
|---|---|---|
| 计算方式 | 按行数计算 | 按值范围计算 |
| 适用场景 | 固定行数移动平均 | 按时间范围统计 |
| 示例 | 最近3行 | 最近30天 |
RANGE示例:
-- 计算最近30天内的平均费用
AVG(cost) OVER (PARTITION BY patient_idORDER BY exam_dateRANGE BETWEEN INTERVAL 30 DAY PRECEDING AND CURRENT ROW
) as avg_last_30_days
5.2 前后值比较
-- 与上一次检查比较
WITH exam_comparison AS (SELECT patient_id,exam_date,exam_type,cost,LAG(cost) OVER (PARTITION BY patient_id ORDER BY exam_date) as prev_exam_cost,cost - LAG(cost) OVER (PARTITION BY patient_id ORDER BY exam_date) as cost_change,LEAD(exam_date) OVER (PARTITION BY patient_id ORDER BY exam_date) as next_exam_dateFROM medical_exams
)
SELECT * FROM exam_comparison;
函数功能说明
| 函数 | 作用 | 示例 |
|---|---|---|
LAG() | 获取前一行的值 | 上次检查的费用 |
LEAD() | 获取后一行的值 | 下次检查的日期 |
cost - LAG(cost) | 计算变化量 | 费用增减金额 |
计算过程
-- 患者101的记录处理:
第1行:LAG(cost) = NULL(没有前一行)cost_change = 500 - NULL = NULLLEAD(exam_date) = '2024-01-15'(下一行日期)第2行:LAG(cost) = 500.00(前一行费用)cost_change = 800 - 500 = 300.00(增加300)LEAD(exam_date) = '2024-01-20'第3行:LAG(cost) = 800.00cost_change = 300 - 800 = -500.00(减少500)LEAD(exam_date) = NULL(没有下一行)-- 患者102的记录处理(重新开始):
第4行:LAG(cost) = NULL(新患者,没有前一行)cost_change = NULLLEAD(exam_date) = NULL
运行结果

LAG()和LEAD()的完整语法
LAG(column, offset, default_value) OVER (...)
LEAD(column, offset, default_value) OVER (...)
| 参数 | 说明 | 示例 |
|---|---|---|
column | 要获取的列 | cost, exam_date |
offset | 偏移量(默认1) | LAG(cost, 2)获取前2行的值 |
default_value | 默认值(替代NULL) | LAG(cost, 1, 0)无前一行时返回0 |
高级用法示例:
-- 获取前2次检查的费用
LAG(cost, 2, 0) OVER (PARTITION BY patient_id ORDER BY exam_date) as cost_2_exams_ago,-- 获取后一次检查的类型
LEAD(exam_type, 1, '未知') OVER (PARTITION BY patient_id ORDER BY exam_date) as next_exam_type,-- 计算与上上次检查的变化
cost - LAG(cost, 2, cost) OVER (...) as change_from_2_exams_ago
5.3 百分比计算
-- 计算每项检查费用在总费用中的占比
WITH cost_analysis AS (SELECT exam_id,patient_id,exam_type,cost,SUM(cost) OVER (PARTITION BY patient_id) as total_patient_cost,cost / SUM(cost) OVER (PARTITION BY patient_id) * 100 as cost_percentage,PERCENT_RANK() OVER (PARTITION BY patient_id ORDER BY cost) as cost_percent_rankFROM medical_exams
)
SELECT * FROM cost_analysis;
PERCENT_RANK()的计算公式:(当前行的排名 - 1) / (总行数 - 1)
6. 多级窗口函数
6.1 复杂分析查询
-- 多层分析:患者+医院级别统计
WITH multi_level_analysis AS (SELECT exam_id,patient_id,hospital_id,exam_type,cost,-- 患者级别统计SUM(cost) OVER (PARTITION BY patient_id) as patient_total,RANK() OVER (PARTITION BY patient_id ORDER BY exam_date) as patient_exam_seq,-- 医院级别统计AVG(cost) OVER (PARTITION BY hospital_id) as hospital_avg_cost,COUNT(*) OVER (PARTITION BY hospital_id) as exams_per_hospital,-- 全局统计SUM(cost) OVER () as grand_total,RANK() OVER (ORDER BY cost DESC) as global_cost_rankFROM medical_exams
)
SELECT exam_id,patient_id,hospital_id,exam_type,cost,ROUND(cost / patient_total * 100, 2) as patient_cost_percentage,ROUND(cost / hospital_avg_cost, 2) as cost_vs_hospital_avg
FROM multi_level_analysis;
也可以单独拆开多个cte
WITH
cte1 AS (SELECT ...),
cte2 AS (SELECT ...),
cte3 AS (SELECT ...)
SELECT ... FROM cte1 JOIN cte2 ...;
多CTE链式查询
WITH
department_stats AS (SELECT department_id, COUNT(*) as emp_count, AVG(salary) as avg_salaryFROM employees GROUP BY department_id
),
salary_analysis AS (SELECT department_id,emp_count,avg_salary,RANK() OVER (ORDER BY avg_salary DESC) as salary_rankFROM department_stats
)
SELECT * FROM salary_analysis WHERE salary_rank <= 3;
7. 实际应用场景
7.1 患者检查频率分析
-- 分析患者检查频率模式
WITH exam_patterns AS (SELECT patient_id,exam_date,exam_type,-- 计算与上一次检查的时间间隔DATEDIFF(exam_date, LAG(exam_date) OVER (PARTITION BY patient_id ORDER BY exam_date)) as days_since_last_exam,-- 检查频率排名NTILE(4) OVER (PARTITION BY patient_id ORDER BY exam_date) as frequency_quartileFROM medical_exams
)
SELECT patient_id,AVG(days_since_last_exam) as avg_days_between_exams,COUNT(*) as total_exams
FROM exam_patterns
GROUP BY patient_id
HAVING COUNT(*) > 1;
7.2 医院业务量分析
-- 医院月度业务分析
WITH monthly_stats AS (SELECT hospital_id,DATE_FORMAT(exam_date, '%Y-%m') as exam_month,COUNT(*) as exam_count,SUM(cost) as monthly_revenue,-- 月度排名RANK() OVER (PARTITION BY hospital_id ORDER BY SUM(cost) DESC) as revenue_rank,-- 月度增长LAG(SUM(cost)) OVER (PARTITION BY hospital_id ORDER BY DATE_FORMAT(exam_date, '%Y-%m')) as prev_month_revenueFROM medical_examsGROUP BY hospital_id, DATE_FORMAT(exam_date, '%Y-%m')
)
SELECT hospital_id,exam_month,exam_count,monthly_revenue,ROUND(monthly_revenue / NULLIF(prev_month_revenue, 0) * 100, 2) as growth_rate
FROM monthly_stats;
8. 性能优化技巧
8.1 使用适当的索引
-- 为窗口函数创建索引
CREATE INDEX idx_patient_date ON medical_exams(patient_id, exam_date);
CREATE INDEX idx_hospital_cost ON medical_exams(hospital_id, cost DESC);
8.2 分区数据限制
-- 限制分区数据量
WITH recent_exams AS (SELECT * FROM medical_exams WHERE exam_date >= DATE_SUB(CURDATE(), INTERVAL 30 DAY)
),
ranked_data AS (SELECT patient_id,exam_date,exam_type,ROW_NUMBER() OVER (PARTITION BY patient_id ORDER BY exam_date DESC) as rnFROM recent_exams
)
SELECT * FROM ranked_data WHERE rn = 1; -- 最近一次检查
9. 常见错误与解决方案
9.1 避免的陷阱
-- ❌ 错误:在WHERE中使用窗口函数结果
SELECT exam_id, ROW_NUMBER() OVER () as rn
FROM medical_exams
WHERE rn = 1; -- 错误!rn在WHERE时不可用-- ✅ 正确:使用子查询或CTE
WITH numbered_exams AS (SELECT exam_id, ROW_NUMBER() OVER () as rnFROM medical_exams
)
SELECT exam_id FROM numbered_exams WHERE rn = 1;
10. MySQL 8.0+ 新特性
10.1 命名窗口
-- 定义可重用的窗口
SELECT patient_id,exam_date,cost,SUM(cost) OVER w as running_total,AVG(cost) OVER w as moving_avg
FROM medical_exams
WINDOW w AS (PARTITION BY patient_id ORDER BY exam_date ROWS UNBOUNDED PRECEDING);
10.2 JSON数据处理
1.1 JSON_TABLE函数
SELECT *
FROM JSON_TABLE('[{"name": "John", "age": 30}, {"name": "Jane", "age": 25}]','$[*]' COLUMNS (name VARCHAR(50) PATH '$.name',age INT PATH '$.age')
) AS jt;
功能:将JSON数组转换为关系型表格
- 输入:JSON数组字符串
- 路径:
$[*]表示遍历数组所有元素 - 列映射:
name VARCHAR(50) PATH '$.name':提取name字段age INT PATH '$.age':提取age字段
输出结果:
name | age
John | 30
Jane | 25
1.2 JSON_EXTRACT和JSON_CONTAINS_PATH
SELECT exam_id,JSON_EXTRACT(patient_info, '$.name') as patient_name,JSON_EXTRACT(patient_info, '$.age') as patient_age,JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.insurance')) as insurance_type
FROM medical_records
WHERE JSON_CONTAINS_PATH(patient_info, 'one', '$.chronic_diseases');
函数说明:
JSON_EXTRACT(json_doc, path):提取JSON字段值(返回JSON格式)JSON_UNQUOTE():去除JSON字符串的引号JSON_CONTAINS_PATH(json_doc, 'one', path):检查是否存在指定路径
2.1 创建医疗记录表
CREATE TABLE medical_records (record_id INT PRIMARY KEY AUTO_INCREMENT,exam_id VARCHAR(20) NOT NULL,patient_info JSON NOT NULL,exam_data JSON NOT NULL,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
2.2 插入测试数据
INSERT INTO medical_records (exam_id, patient_info, exam_data) VALUES
('EXAM001', '{"name": "张三","age": 45,"gender": "男","insurance": "城镇职工医保","chronic_diseases": ["高血压", "糖尿病"],"contact": {"phone": "13800138000","emergency_contact": "李四"},"medical_history": {"allergies": ["青霉素"],"surgeries": ["阑尾切除术-2015"]}
}', '{"exam_type": "CT","body_part": "胸部","results": {"diagnosis": "肺部结节","size": "5mm","location": "右上肺","urgency": "常规随访"},"radiologist": "王医生","cost": 680.00
}'),('EXAM002', '{"name": "李四","age": 32,"gender": "女", "insurance": "新农合","chronic_diseases": [],"contact": {"phone": "13900139000","emergency_contact": "王五"},"medical_history": {"allergies": [],"surgeries": []}
}', '{"exam_type": "MRI","body_part": "头部","results": {"diagnosis": "正常","findings": "未见明显异常","urgency": "常规"},"radiologist": "赵医生","cost": 1200.00
}'),('EXAM003', '{"name": "王五","age": 68,"gender": "男","insurance": "离退休干部医保","chronic_diseases": ["冠心病", "高血压", "糖尿病"],"contact": {"phone": "13700137000", "emergency_contact": "赵六"},"medical_history": {"allergies": ["阿司匹林"],"surgeries": ["冠状动脉搭桥术-2020", "胆囊切除术-2018"]}
}', '{"exam_type": "超声","body_part": "腹部","results": {"diagnosis": "胆囊息肉","size": "8mm","recommendation": "定期复查"},"radiologist": "孙医生","cost": 350.00
}');
3.1 基础信息提取
-- 提取患者基本信息
SELECT exam_id,JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.name')) as patient_name,JSON_EXTRACT(patient_info, '$.age') as patient_age,JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.gender')) as gender,JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.insurance')) as insurance_type,JSON_UNQUOTE(JSON_EXTRACT(exam_data, '$.exam_type')) as exam_type,JSON_EXTRACT(exam_data, '$.cost') as cost
FROM medical_records;
结果:
exam_id | patient_name | patient_age | gender | insurance_type | exam_type | cost
EXAM001 | 张三 | 45 | 男 | 城镇职工医保 | CT | 680.00
EXAM002 | 李四 | 32 | 女 | 新农合 | MRI | 1200.00
EXAM003 | 王五 | 68 | 男 | 离退休干部医保 | 超声 | 350.00
3.2 慢性病患者筛选
-- 查找有慢性病的患者
SELECT exam_id,JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.name')) as patient_name,JSON_EXTRACT(patient_info, '$.age') as age,JSON_EXTRACT(patient_info, '$.chronic_diseases') as chronic_diseases
FROM medical_records
WHERE JSON_CONTAINS_PATH(patient_info, 'one', '$.chronic_diseases')AND JSON_LENGTH(JSON_EXTRACT(patient_info, '$.chronic_diseases')) > 0;
结果:
exam_id | patient_name | age | chronic_diseases
EXAM001 | 张三 | 45 | ["高血压", "糖尿病"]
EXAM003 | 王五 | 68 | ["冠心病", "高血压", "糖尿病"]
3.3 复杂条件查询
-- 查找有特定过敏史的高龄患者
SELECT exam_id,JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.name')) as name,JSON_EXTRACT(patient_info, '$.age') as age,JSON_EXTRACT(patient_info, '$.medical_history.allergies') as allergies
FROM medical_records
WHERE JSON_EXTRACT(patient_info, '$.age') >= 60AND JSON_CONTAINS(JSON_EXTRACT(patient_info, '$.medical_history.allergies'), '"阿司匹林"');
3.4 使用JSON_TABLE展开数组数据
-- 展开慢性病数组为多行
SELECT mr.exam_id,JSON_UNQUOTE(JSON_EXTRACT(mr.patient_info, '$.name')) as patient_name,diseases.disease_name
FROM medical_records mr,
JSON_TABLE(JSON_EXTRACT(mr.patient_info, '$.chronic_diseases'),'$[*]' COLUMNS (disease_name VARCHAR(50) PATH '$')
) AS diseases
WHERE JSON_LENGTH(JSON_EXTRACT(mr.patient_info, '$.chronic_diseases')) > 0;
结果:
exam_id | patient_name | disease_name
EXAM001 | 张三 | 高血压
EXAM001 | 张三 | 糖尿病
EXAM003 | 王五 | 冠心病
EXAM003 | 王五 | 高血压
EXAM003 | 王五 | 糖尿病
4.1 医疗费用分析
-- 按保险类型统计费用
SELECT JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.insurance')) as insurance_type,COUNT(*) as exam_count,ROUND(AVG(JSON_EXTRACT(exam_data, '$.cost')), 2) as avg_cost,ROUND(SUM(JSON_EXTRACT(exam_data, '$.cost')), 2) as total_cost
FROM medical_records
GROUP BY JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.insurance'))
ORDER BY total_cost DESC;
4.2 检查结果严重程度分析
-- 分析检查结果的紧急程度
SELECT exam_id,JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.name')) as patient_name,JSON_UNQUOTE(JSON_EXTRACT(exam_data, '$.exam_type')) as exam_type,JSON_UNQUOTE(JSON_EXTRACT(exam_data, '$.results.diagnosis')) as diagnosis,JSON_UNQUOTE(JSON_EXTRACT(exam_data, '$.results.urgency')) as urgency_level,CASE WHEN JSON_UNQUOTE(JSON_EXTRACT(exam_data, '$.results.urgency')) = '紧急' THEN '高危'WHEN JSON_UNQUOTE(JSON_EXTRACT(exam_data, '$.results.urgency')) = '常规随访' THEN '中危'ELSE '低危'END as risk_level
FROM medical_records
ORDER BY CASE WHEN urgency_level = '紧急' THEN 1WHEN urgency_level = '常规随访' THEN 2ELSE 3END;
5.1 患者完整档案查询
SELECT exam_id,-- 基本信息JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.name')) as name,JSON_EXTRACT(patient_info, '$.age') as age,JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.gender')) as gender,-- 联系信息JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.contact.phone')) as phone,JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.contact.emergency_contact')) as emergency_contact,-- 医疗信息JSON_EXTRACT(patient_info, '$.chronic_diseases') as chronic_diseases,JSON_EXTRACT(patient_info, '$.medical_history.allergies') as allergies,JSON_EXTRACT(patient_info, '$.medical_history.surgeries') as surgeries,-- 检查信息JSON_UNQUOTE(JSON_EXTRACT(exam_data, '$.exam_type')) as exam_type,JSON_UNQUOTE(JSON_EXTRACT(exam_data, '$.body_part')) as body_part,JSON_UNQUOTE(JSON_EXTRACT(exam_data, '$.results.diagnosis')) as diagnosis,JSON_EXTRACT(exam_data, '$.cost') as cost,-- 计算字段CASE WHEN JSON_EXTRACT(patient_info, '$.age') >= 65 THEN '老年患者'WHEN JSON_EXTRACT(patient_info, '$.age') >= 45 THEN '中年患者'ELSE '青年患者'END as age_group,CASE WHEN JSON_LENGTH(JSON_EXTRACT(patient_info, '$.chronic_diseases')) >= 2 THEN '多病共存'WHEN JSON_LENGTH(JSON_EXTRACT(patient_info, '$.chronic_diseases')) = 1 THEN '单一慢性病'ELSE '无慢性病'END as chronic_statusFROM medical_records;
6.1 创建函数索引
-- 为常用查询字段创建索引
ALTER TABLE medical_records ADD INDEX idx_patient_name ((JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.name'))));ALTER TABLE medical_recordsADD INDEX idx_patient_age ((JSON_EXTRACT(patient_info, '$.age')));ALTER TABLE medical_recordsADD INDEX idx_exam_type ((JSON_UNQUOTE(JSON_EXTRACT(exam_data, '$.exam_type'))));
6.2 物化视图模式
-- 创建简化视图提高查询性能
CREATE VIEW patient_summary AS
SELECT record_id,exam_id,JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.name')) as patient_name,JSON_EXTRACT(patient_info, '$.age') as age,JSON_UNQUOTE(JSON_EXTRACT(patient_info, '$.insurance')) as insurance,JSON_UNQUOTE(JSON_EXTRACT(exam_data, '$.exam_type')) as exam_type,JSON_EXTRACT(exam_data, '$.cost') as cost,created_at
FROM medical_records;