Pytorch 预训练网络加载与迁移学习基本介绍
工具准备:
首先,有个用于观察python网络的结构的库非常好用:torchinfo
安装下载也非常简单 : pip install torchinfo
pytorch中调用预训练网络
官方文件:官方介绍连接
在pytorch中调用预训练网络是一件非常简单的事情,这里我以torchvision举例:
import torchvision
weights = torchvision.models.EfficientNet_B0_Weights.DEFAULT
model = torchvision.models.efficientnet_b0(weights=weights).to(device)这里只用了两行代码便实现了模型的部署与导入,我这里的版本用的是0.14的这一版需要将我们想要的权重(weights)输入到我们利用torchvision构建的模型实例(model)当中去,这一点需要注意。
肯定有宝宝要问了,那models该怎么选择,我咋知道有什么models可以给我们用?
这里建议参考官方文档。就是最上面的介绍链接。
在官网中会将网络模型按任务为我们分好类别,会分成分类,语义分割,目标检测等任务,下面以分类任务为例子,

上面是分类任务模型,只能说多到怀疑人生,它所包含参数更是多到一页都展示不完的地步。
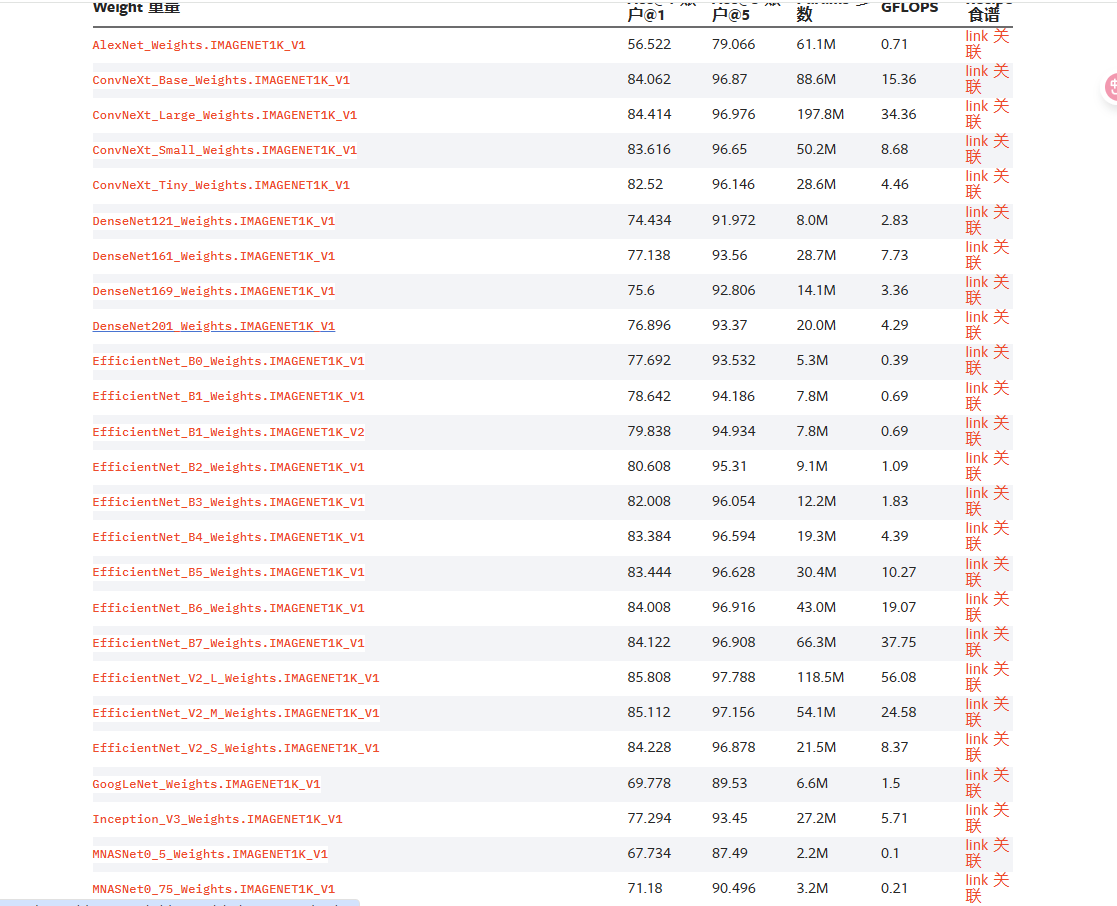
那我们到底该怎么去用预训练网络,以及我们该怎么去实现迁移学习呢?
在最开始的代码中,我们加载了一个EfficientnetB0的模型,我们首先先来看看模型的网络结构
import torchvision# .DEFAULT 这里采用模型默认最优权重weights = torchvision.models.EfficientNet_B0_Weights.DEFAULTmodel = torchvision.models.efficientnet_b0(weights = weights).to(device)summary(model, input_size = (16,3,224,224),col_names=["input_size", "output_size", "num_params", "trainable"], col_width=20,row_settings = ["var_names"])执行上面的代码后,我们可以看到下面这样的信息,注意看小括号里面的内容,row_settings = ["var_names"],这一行代码是将模型中的变量名字都展示出来。
我们可以发现整个EfficientNet 其实就是3个部分features,avgpool,classifier。这三个部分的功能分别是特征的提取,通道的对齐,全连接层调整特征到分类的数量维度。为了达到我们利用网络特征提取的能力而又能去执行我们自己的任务,我们一般来说会对特征处的网络进行反向传播能力的禁止,也就是说要去对特征提取层进行一个所谓冻结的操作。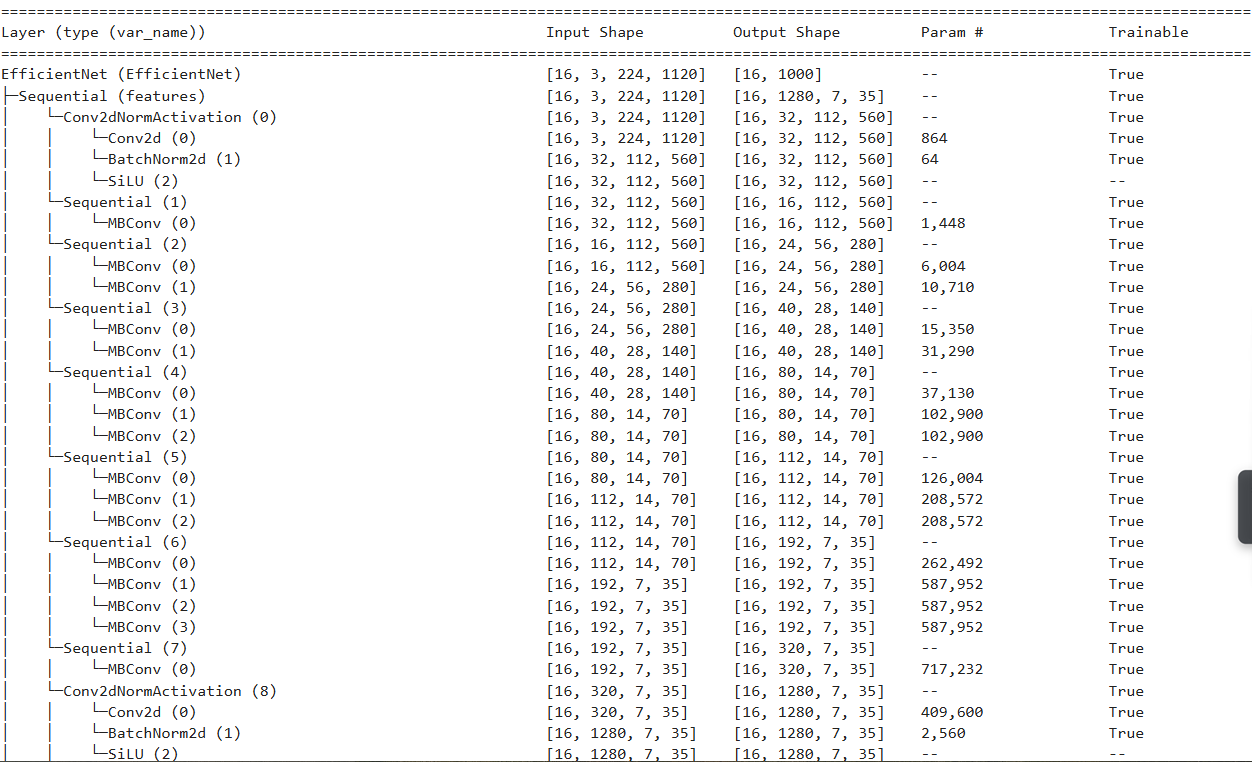
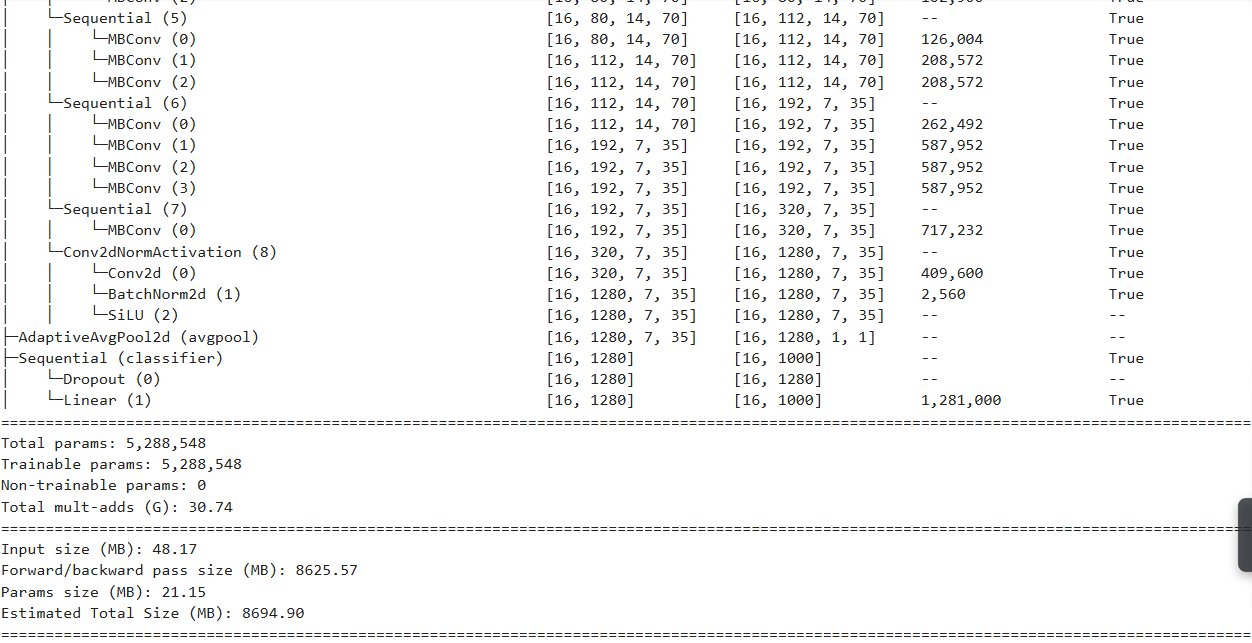
冻结首先要能get到features层的参数:
# 这行代码可以让我们获得一个关于features层完整参数的一个迭代器
model.features.parameters()我们利用上面的对features层所有参数的迭代器进行梯度的禁止传递:
for param in model.features.parameters():param.requires_grad = FalseOK,我们已经完成了对迁移学习的第一步:锁住模型网络中的特征提取网络。
第二步就是将分类头给替换成我们喜欢的样子:这里的分类头(classifier)是长下面这个样子的,有一个用于正则化的Dropout层跟一个用于特征重投影映射的线性层。假设我们现在只需要3个类我们应该怎么做呢?
经过苦思冥想之后,我们发现,原来可以重写这个classifier。先看看原来的classifier.
model.classifier
我们可以发现他是1000个类,
现在我们开始重写:
model.classifier = torch.nn.Sequential(torch.nn.Dropout(0.1,inplace = True),torch.nn.Linear(in_features = 1280,out_features = 10,bias =True) ).to(device)上面这样就重写了模型的分类器,这样一个强大的预训练网络就被调整成俺们想要的样子了。可以塞入我们已经有的一系列的网络训练py文件中进行训练了。
总结一下:最简单的迁移学习模型的建立就干了两件事,1.锁鲜,把最有价值的features层锁住
2.换头,把分类头换成自己需要的头。and模型完成,训练的事就是下文了哈哈哈。
这篇文章写给我那笨笨的女朋友(wink❥(^_-)