从无状态到有状态,LLM的“记忆”进化之路
"状态"指的是应用在其特定时间点的状况。一个应用属于有状态还是无状态,取决于它是否记录与用户、系统或其他组件交互的上下文。有状态应用会将这些状态信息保存在持久化存储中,确保即使在重启后也能维持其状态。因此,有状态与无状态应用的核心区别在于:前者会保存过去与现在的交互信息,而后者则不会。
从无状态的HTTP协议讲起
在现代互联网应用中,HTTP协议是信息交换的基础。然而,HTTP的设计原则之一就是它无状态。每次HTTP请求都是独立的,它并不保存关于前一次请求的任何信息。
换句话说,当客户端向服务器发送一个请求时,服务器并不会记住客户端以前的请求,也不会自动携带任何历史数据到后续的请求中。这种特性让HTTP协议简单、灵活,但也带来了一些挑战,特别是在需要连续跟踪用户状态或请求历史的场景下。

为什么HTTP是无状态的?
HTTP之所以是无状态的,主要是为了保持其简单性和效率。每个请求都是独立的,服务器在处理每个请求时不需要关心之前发生的事情,这就意味着:
资源节约:服务器不需要保存任何状态信息,减少了内存和存储的开销。
高并发支持:每个请求可以独立处理,服务器可以更轻松地扩展,以处理大量并发的客户端请求。
怎样让HTTP变得有状态?
然而,HTTP这种无状态的设计也有其局限性。例如,在用户登录后,服务器不能记住用户的身份,为了使HTTP从无状态变为有状态,通常需要引入一些机制来保存和传递状态信息。由于HTTP本身设计为无状态,每个请求都是独立的,无法记住历史信息或用户上下文。为了在HTTP中引入“状态”,通常有几种常见的做法:
Cookies
当客户端第一次与服务器交互时,服务器会将一个或多个小的文本文件(cookies)发送到客户端,这些文件通常包含标识信息(如会话ID、用户身份等)。之后,每次客户端向服务器发送请求时,都会将这些cookies随请求一同发送,服务器根据这些信息来恢复会话状态。
Session(会话)
Session机制通常是在服务器端维护一个用户的会话信息,而客户端仅通过一个会话标识符(通常是session ID)来跟踪会话。
当用户首次与服务器交互时,服务器会为该用户创建一个会话(Session)并生成一个唯一的Session ID,然后通过HTTP响应将这个Session ID作为cookie发送给客户端。客户端随后在每次请求时,都会携带该Session ID。服务器根据Session ID查找该用户的会话信息,从而保持状态。
JWT(JSON Web Tokens)
JWT是一种轻量级的机制,用于在客户端和服务器之间传递信息,且信息可以被签名以验证其真实性。通过加密的方式生成一个令牌(token)。这个令牌可以存储在客户端(通常是localStorage或sessionStorage),并随着每次请求发送给服务器。服务器通过验证JWT来确认请求的合法性和恢复用户的状态。
LocalStorage / SessionStorage
LocalStorage 和 SessionStorage 是浏览器提供的两种Web存储机制,它们允许在客户端浏览器中存储数据。
-
LocalStorage:用于长期存储数据,浏览器关闭后数据仍然保留。
-
SessionStorage:用于存储会话数据,浏览器关闭后数据被清除。
URL参数 / Query Strings
通过URL参数来传递状态信息是一种直接的方法,常用于短期的状态管理。服务器通过URL中的查询参数(例如?session_id=12345)传递一些状态信息,这些信息将随请求一起发送给服务器,用于恢复用户的会话或某些任务状态。
通过上述方法,我们可以将原本无状态的HTTP协议“变得有状态”,使得Web应用能够记住用户的状态、持续会话并提供个性化的体验。
再举一个例子
让我用简单的例子再来解释什么是有状态和无状态。
无状态
想象你在一家餐厅里点餐。服务员给你一张菜单,你告诉他你要点的菜。他把订单传给厨房,厨房做菜、准备好后交给服务员,最后把食物端给你。
关键点:每次你和服务员的交流都是独立的。你不需要跟服务员重复说“我是谁”,因为每次点餐时,服务员都会完全按照你当前说的话来处理。
这就是“无状态”——每次互动都是独立的,系统不记得之前的交互,每次都只处理当前的信息。
有状态
有状态就是系统能够“记住”过去的事情,在未来的交互中参考这些过去的信息。

继续用餐厅的例子,这次你还是去那家餐厅点餐,但是服务员记得你上次来过,知道你喜欢辣的食物。于是,当你点菜时,服务员会建议你“上次您喜欢的那个辣味炒菜,我们这次有新鲜的食材,您要不要试试?”他不仅记住了你点的菜,还记住了你偏好的口味。
关键点:系统在每次与用户互动时,可以使用“历史”来做决策。服务员记得你上次吃过什么,甚至了解你个人的偏好,让你在每次访问时都能享受到个性化的服务。
这就是“有状态”——系统在不同的交互中保持历史上下文,并根据这些信息来提供更合适的响应。
总的来说
无状态指的是每次交互是独立的,系统不记得之前的内容。例如:HTTP协议、普通的问答系统。
它的好处就是简单、高效,处理每个请求都不需要存储历史信息。缺点就在于无法提供个性化的体验,不能追踪上下文。
有状态是系统记得并利用历史信息,能在后续交互中做出更智能的响应。例如:个性化推荐、聊天机器人、虚拟助手。
有状态的好处是能够提供个性化的服务和更连贯的体验。缺点则主要是系统需要更多的资源来保存和管理这些历史信息。
LLM的无状态与有状态
接下来我们讲一讲LLM的有无状态情况。
大多数默认的LLM(如GPT-3、GPT-4等)是无状态的,因为它们处理每个输入时都不存储任何历史上下文。每个请求的生成是独立的,模型不会记住之前的对话或请求。
但是我们经常使用的网页应用对话产品DeepSeek、ChatGPT则是有状态的,诸如DeepSeek-R1、GPT-3、GPT-4这些模型所处的角色是DeepSeek、ChatGPT等产品背后的基础模型,前者是无状态的,后者则是有状态的。
更专业一点的来讲,底层模型(DeepSeek-R1、GPT-3、GPT-4)本身是无状态的,而上层应用/产品(DeepSeek、ChatGPT)通过某些方式模拟了“有状态”的体验。
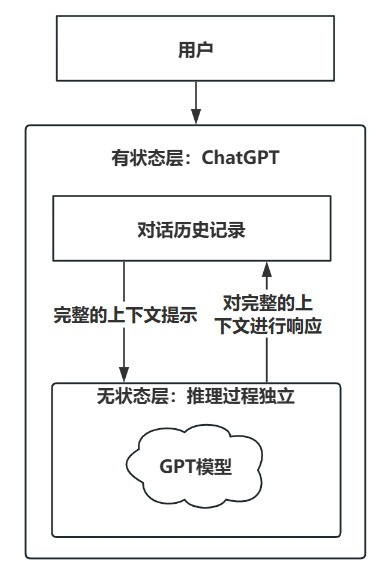
有状态的LLM和无状态的LLM各自有其独特的优势和适用场景。选择使用哪种类型的模型,通常取决于应用需求、用户交互的复杂度、以及对话或任务的连贯性要求。
无状态的LLM(Stateless LLM)
无状态的LLM,通常作为API对外提供,其优点在于简单性与高效性,每次输入是独立处理的,不需要额外的上下文存储和管理,模型和系统更简单,响应速度更快。以及低资源消耗,无状态的系统不需要在多个对话轮次间保存和更新状态,因此减少了对内存和存储的需求。
它的适用场景主要有:
简单、独立的任务:无状态的LLM适用于那些每次用户输入都是独立的、不依赖于历史的场景。例如:
-
单轮问题回答:如果用户提问的问题没有历史上下文关系(如“地球有多大?”),无状态模型可以快速生成准确的答案。
-
查询系统:如FAQ系统,用户提问一个问题,模型根据现有的知识库返回答案,不需要上下文记忆。
-
信息生成:比如文章摘要、文本生成、编程帮助等,输入和输出之间没有强关联的场景。
高频、并发请求:无状态的LLM可以轻松处理大量并发请求,因为它不需要维持每个用户的对话状态,每次处理的请求是独立的。这使得它在需要高吞吐量的应用中具有较高的效率。
信息搜索或检索:用于在知识库或文档中搜索相关信息的场景。例如,查询数据库、资料库等,可以通过一次性检索完成任务。
有状态的LLM(Stateful LLM)
有状态LLM能够维护对话的连贯性,并理解和利用上下文信息,避免了用户需要重复说明自己的背景或需求。它能提供更加个性化的、情境化的回答,改善用户体验。
此外,它还能在多轮对话中保持任务的上下文信息,帮助用户完成复杂任务,并减少遗漏或错误。通过维护历史上下文,有状态的LLM可以更好地模拟人类的对话方式,记住前面的讨论,使得对话更加流畅和自然。
它的适用场景主要有:
多轮对话系统:对于需要保持上下文连贯性的对话系统,如聊天机器人、虚拟助手(例如:Siri、Alexa、Google Assistant),有状态LLM能记住用户的历史互动,提供更自然、个性化的回答。例如:
-
连续对话:当用户连续提问有关某个话题的问题时,模型需要记住前面的对话内容以保持连贯性(例如:“我喜欢看科幻电影,推荐一些。” → “那你会喜欢《星际穿越》。”)。
-
上下文感知任务:如果用户在前一轮对话中设置了任务(如:“明天帮我提醒去买菜”),有状态的模型能记住并及时提醒。
个性化推荐系统:通过对用户历史偏好、行为或兴趣的记忆,有状态的LLM可以为用户提供更加个性化的建议或服务。例如,基于用户的购物历史、浏览记录等来推荐产品、电影或其他内容。
长时间交互和复杂任务:对于那些跨时间、涉及多个步骤的任务,如项目管理助手、语音助手,有状态的LLM可以在多次交互中跟踪任务进度,避免重复询问或忘记之前的任务。
情感分析和心理健康支持:有状态的LLM可以根据用户的情感变化或对话历史,提供更加贴近用户需求的情感支持。例如,心理健康聊天机器人能记住用户之前的情绪状态,及时给出鼓励和安慰。
怎样实现有状态的LLM?
随着LLM技术的发展,单纯的无状态模型逐渐不够满足复杂应用的需求,尤其是在涉及长期交互、个性化和多轮对话时。所以就需要我们提供有状态的LLM。
要让默认的无状态的大语言模型(LLM,如GPT-3、GPT-4等)变得有状态,需要对模型的输入处理和记忆管理做一些特定的设计和改造。这通常涉及到将对话历史、用户上下文或任务状态作为上下文信息传递给模型,以便让模型能够保持对话的连续性并根据过去的信息进行合理的推理。业界也已经提出了几种成熟的方案和方法来实现这一目标。
上下文窗口管理(Context Window)
LLM如GPT系列本身是无状态的,但可以通过在每次请求中将上下文(历史对话或用户信息)作为输入传递来“模拟”有状态的行为。
这种方法的关键是管理一个“上下文窗口”。每次新的输入会包含一定长度的历史上下文,这些上下文信息会随着对话的进行逐步更新。
如何实现:
1)当用户发起一个新请求时,除了当前的输入内容外,还将先前的对话(历史对话)作为上下文传递给模型。
2)模型根据这些上下文生成响应。
3)为了避免模型的上下文窗口过大,通常会根据需求对上下文进行裁剪。比如,只保留最近的几轮对话内容,或者对历史对话进行摘要处理。

上下文窗口有大小限制(例如GPT-3的最大上下文窗口为2048个token)。因此,随着对话历史的增加,模型只能处理有限的上下文,需要对历史内容进行选择性保留或压缩。
外部存储和检索(Memory Augmented)
使用一些方法通过将长期记忆或状态存储在外部数据库或知识库中,允许LLM在每次对话中动态地检索并更新这些外部存储的信息,从而实现有状态的功能。
例如,结合检索增强生成(RAG)技术,模型可以从外部存储中拉取相关的背景信息,并将其作为输入的一部分一起传递给模型。
如何实现:
1)将用户的历史交互、偏好、设置等信息存储在外部数据库中(例如,NoSQL数据库、Redis、向量数据库等)。
2)每次模型生成新的响应时,从数据库中检索相关的上下文并将其作为输入传递给模型,以便根据历史信息生成更具连贯性的回答。
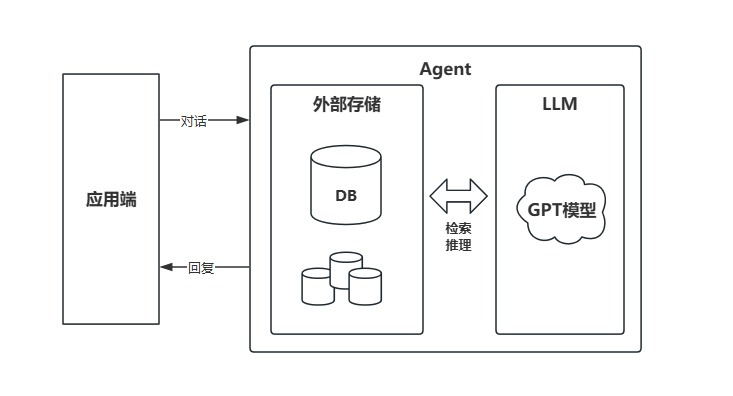
存在的挑战:
-
外部存储的管理复杂度较高,需要保证数据的一致性和更新及时性。
-
检索和存储机制需要优化,否则可能会影响系统的响应速度和准确性。
通过会话标识符(Session ID)跟踪状态
另一种常见的方案是通过会话标识符(Session ID)来跟踪每个用户的对话状态。会话标识符允许将用户的历史对话信息与特定会话绑定,每次对话时都携带该标识符,使得模型能够从存储中检索到与该标识符相关的历史上下文。
如何实现:
1)为每个用户生成一个会话ID,在用户发起对话时,系统将该ID与用户的历史对话记录绑定。
2)在每个请求中,LLM会通过会话ID从数据库或缓存中获取相应的历史上下文,并将其作为输入的一部分传递给模型。
存在的挑战:
-
需要有效的会话管理和存储机制,以确保会话信息的持久性和更新。
-
处理长时间未活动的会话,避免会话丢失或过期。
基于事件的记忆机制(Event-based Memory)
在某些场景下,可以通过事件驱动的记忆机制来实现有状态。即每当某个特定事件(如用户提供的新信息或新的任务要求)发生时,模型会更新其记忆状态,并根据新的状态生成响应。
如何实现:
1)将系统中的关键事件(如用户的选择、对话的关键点)作为记忆单元存储,并在每次生成新响应时,根据事件的历史对话和最新事件来更新模型的行为。
2)这种方法往往结合强化学习(RL)或其他智能体学习技术来让模型能够根据不断变化的环境自我调整记忆。
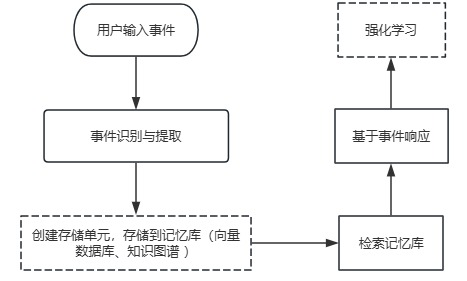
存在的挑战:
-
事件驱动的记忆机制通常需要更多的上下文知识和推理能力。
-
确保事件存储的及时更新和相关性判断,避免过时或无关的信息影响模型决策。
到这里大家可能会有疑问,基于事件的记忆机制和基于外部存储与检索有什么本质上的不同?
总的来说,基于外部存储与检索 描述的是 “在哪里”和 “怎么取”,它是实现记忆的技术架构和载体。而基于事件的记忆机制 描述的是“记什么”和“何时记”,它是管理记忆的策略、逻辑和内容类型。
可以说,“基于事件的记忆机制”是构建在“基于外部存储与检索”这个基础架构之上的一个高级应用和策略。
主流方案对比表
| 方案类型 | 代表产品 | 记忆方式 | 适用场景 | 成熟度 |
|---|---|---|---|---|
| 向量数据库 + RAG | ChatGPT Memory, Notion AI, Pinecone+LangChain | 向量检索历史片段 | 个性化问答、知识助手 | ⭐⭐⭐⭐⭐ |
| 会话状态机 | Dialogflow CX, Rasa | 显式状态变量 | 客服、任务型流程 | ⭐⭐⭐⭐ |
| 长上下文模型 | Claude 3, GPT-4 Turbo | 模型内上下文窗口 | 长文档分析、单会话记忆 | ⭐⭐⭐⭐ |
| 个人AI助手 | Replika, Pi, Character.AI | 用户级记忆存储 | 情感陪伴、个人助理 | ⭐⭐⭐⭐ |
| 企业集成平台 | Salesforce Einstein, ServiceNow | 对接CRM/ERP | 客户服务、内部助手 | ⭐⭐⭐⭐⭐ |
未来趋势
混合架构成为主流:RAG + 状态机 + 长上下文 + 模型微调(如LoRA)组合使用。
记忆可编辑与遗忘机制:如Meta的“LLM Memory Editing”研究,允许用户删除/修改记忆。
联邦记忆与隐私保护:本地化记忆存储(如Apple的Private Cloud Compute)。
AI代理(Agent)的自主记忆:AutoGPT、BabyAGI等自主代理正在探索“自我记录与规划”的长期记忆系统。
小总结
要让无状态的LLM变得有状态,核心的策略是通过上下文管理、外部存储、会话跟踪以及动态记忆更新来实现对话的连续性和上下文的保持。业界已经提出了多种方案,如RAG(检索增强生成)、会话ID管理、记忆增强模型等,这些方法能够让LLM更好地跟踪用户需求、理解历史上下文,并提供更加个性化和连贯的对话体验。