C++ 分治 归并排序解决问题 力扣 LCR 170. 交易逆序对的总数 题解 每日一题
文章目录
- 题目描述
- 为什么这道题值得你花几分钟时间看懂?
- 算法原理
- 为什么可以用归并来解决这个问题
- 细节分析:排序不会影响计数准确性吗?
- 如何用归并来解决
- 代码实现
- 代码优化思路:全局复用临时数组
- 时间复杂度与空间复杂度分析
- 总结
- 下题预告


题目描述
题目链接:力扣 LCR 170. 交易逆序对的总数
题目描述:
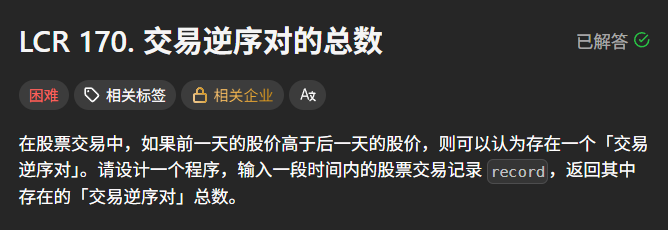
示例 1:
输入:record = [9, 7, 5, 4, 6]
输出:8
解释:交易中的逆序对为 (9, 7), (9, 5), (9, 4), (9, 6), (7, 5), (7, 4), (7, 6), (5, 4)。
提示:
0 <= record.length <= 50000
为什么这道题值得你花几分钟时间看懂?
这道题是归并排序的“进阶实战题”,更是帮你打通“分治思想”从“排序”到“实际统计问题”的关键桥梁,花几分钟吃透它,收获远不止解对一道题:
-
深化分治思想的灵活应用:普通归并排序只需要“拆分-合并”完成排序,这道题则要求在合并过程中“顺带”统计逆序对,能帮你理解分治思想的核心——不仅能解决排序这类“处理型问题”,还能解决逆序对统计这类“计数型问题”,拓宽算法应用思路。
-
掌握“排序+统计”的高效结合技巧:暴力解法O(n²)超时是必然,这道题的核心价值在于教会你“如何利用排序的有序性优化统计效率”——把原本O(n²)的计数操作,通过归并排序的有序特性降为O(nlogn),这种“借排序优化统计”的思路,能迁移到很多类似的“成对计数”问题中。
-
攻克归并排序的核心疑问:很多人刚学归并解决逆序对时,都会困惑“排序会不会打乱原始顺序,导致计数出错”。吃透这道题,能彻底搞懂“归并排序中子数组排序不影响跨数组逆序对计数”的本质,帮你真正掌握归并排序的底层逻辑,而不是死记硬背代码。
这道题不是简单的“排序变种”,而是检验你是否真正理解分治思想的“试金石”,学会它,你对归并排序的理解会直接上一个台阶~
特别忠告:一定要先把归并排序的基础逻辑(拆分规则、合并步骤、递归终止条件)完全弄明白,再看这篇博客。归并排序是理解逆序对统计的前提,基础不牢固会导致后续算法原理的讲解出现理解断层,反而浪费更多时间,对归并排序有遗忘的朋友可以看我的上一篇博客C++ 分治 归并排序 力扣 912. 排序数组 其中详细讲解了归并排序的原理及实现步骤。
算法原理
为什么可以用归并来解决这个问题
在最开始的时候,我只想到了暴力解法但是很显然一个困难题目如果能用两个for暴力解出来就太不正常了,事实证明这道题的数据范围是 0 <= record.length <= 50000 暴力时间复杂度是O(n2)大概率超时,所以一定有别的方法来解决这道题。
而归并排序的“拆分-合并”逻辑,恰好能高效统计逆序对,核心在于“利用有序性优化计数”,我们一步步拆解其中的逻辑,至于原因我们一点一点说(最开始属实我也没想到)。
1.逆序对的统计逻辑:拆分后分三类计数
我们计算逆序对数无非就是两个元素对比计数,那么一个数组可以计算逆序数,那么我们也可以计算两个数组的逆序数,如下图👇:

此时,我们就可以和归并排序的思路进行了简单重合,别急最终答案一定不是reta + retb,对我们还差一步统计数组a和b两个数组中所有的逆序对数等于retc,那么我们就可以得到最终逆序对数为reta + retb + retc(左边的逆序对 + 右边的逆序对 + (左子数组元素 > 右子数组元素的跨数组逆序对))但是这样本质还是暴力枚举时间并没有一点改进,关键在于下一步的优化。
2.优化计数:有序子数组让跨数组计数变高效
我们目前的困境就是解决效率问题,基于上面我们的摸索其实可以在 一左一右的逆序对 的时候进行优化,暴力中我们是左面找一个元素右面找一个元素比较计数,时间复杂度是O(n2),但是如果数组是有序的那么计数可以通过规律变成O(n),往往相较于数组无序的一个一个比较O(n2)计数的效率高,如下图👇:

那么我们这样改进呢?左边的逆序对 ➡ 对左边进行排序 ➡ 右边的逆序对 ➡ 对右边进行排序 ➡ 一左一右的逆序对,那就能够将时间复杂度降低到O(nlogn),我知道你现在一定有疑问我们下面来解答。
细节分析:排序不会影响计数准确性吗?
那么现在你现在一定右上面的疑问,我最开始也有这个疑问,我们明明求得是固定顺序的数组中的逆序数,你给排序了岂不是打乱了顺序吗,计数还对吗?
答案是:完全不影响计数的准确度
这个问题的核心在于理解:归并排序中对「子数组的排序」只改变了子数组内部的元素顺序,但完全不影响「原始数组中逆序对的总数统计」。这看似反直觉,其实我们从「逆序对的定义」和「排序的作用范围」两个角度看就能理解:
逆序对的定义是「基于原始数组的位置关系」,而非元素值本身
逆序对的本质是「原始数组中,位置在前的元素 > 位置在后的元素」。例如 [9,7,5,4,6] 中,(9,7) 是逆序对,因为在原始数组中 9 位于 7 之前且更大。
归并排序的递归分割始终基于「原始数组的位置」:
- 无论子数组如何排序,左子数组的所有元素在原始数组中都位于右子数组元素的左侧(例如左子数组
[9,7]的元素在原始数组中都在右子数组[5,4,6]之前)。 - 因此,「左子数组元素 > 右子数组元素」的逆序对,其「前后位置关系」是原始数组决定的,与子数组是否排序无关。
子数组排序仅影响「内部顺序」,但内部逆序对已提前统计
归并排序的步骤是 左边的逆序对 ➡ 对左边进行排序 ➡ 右边的逆序对 ➡ 对右边进行排序 ➡ 一左一右的逆序对,所以并不影响内部因为我们是统计完才排序:
- 第一步:递归处理左、右子数组,统计它们内部的逆序对(例如
[9,7]内部的(9,7)在排序前就已被统计)。 - 第二步:对左、右子数组排序(例如
[9,7]排为[7,9],[5,4,6]排为[4,5,6])。此时子数组内部的顺序改变了,但内部逆序对已经统计完毕,后续不会再处理。 - 第三步:合并两个排序后的子数组,统计「左元素 > 右元素」的跨数组逆序对。由于子数组已排序,此时可以高效计算(例如左
[7,9]和右[4,5,6]中,7>4时,左数组中7及其右侧的9都大于4,对应原始数组中(7,4)和(9,4)两个逆序对)。
排序的作用:让「跨数组逆序对的统计」变高效,而非改变逆序对本身
子数组排序后,元素的相对顺序改变了,但:
- 左子数组中任意元素在原始数组中的位置,仍然都在右子数组元素之前(位置关系不变)。
- 因此,「左元素 > 右元素」的数量,与原始数组中左子数组元素 > 右子数组元素的数量完全一致(只是通过排序让统计更方便)。
例如,原始左子数组 [9,7] 和右子数组 [5,4,6] 中,跨数组逆序对是 (9,5), (9,4), (9,6), (7,5), (7,4), (7,6) 共 6 个。
排序后左 [7,9]、右 [4,5,6] 合并时,统计的仍是这 6 个(只是计算方式从逐个比较变成了利用有序性批量计算)。
所以按照我们的思路,子数组的排序只影响内部元素的顺序,但不改变原始数组中「左子数组元素在右子数组元素之前」的位置关系。而逆序对的统计基于:
- 子数组内部的逆序对(排序前已统计)。
- 跨数组的逆序对(位置关系不变,排序后高效统计)。
因此,排序操作既不会遗漏也不会重复计算逆序对,最终结果与原始数组的逆序对总数完全一致,可以拿示例一来对比的画下👇:

如何用归并来解决
我们上面已经说明了,这个方法是正确,在解法和思路上与归并高度重合,这就是为什么这道题可以用归并来做,不同点就是我们要进行计数,如下图👇我们会有两种可能:

- 拆分(Divide):找到数组中间位置mid,将数组拆分为左子数组(left ~ mid)和右子数组(mid+1 ~ right),递归处理左右子数组,统计各自内部的逆序对。
- 合并(Merge):
- 准备两个指针cur1(左子数组起始)、cur2(右子数组起始),以及临时数组tmp存储合并结果。
- 对比record[cur1]和record[cur2]:
- 若record[cur1] <= record[cur2]:直接将record[cur1]加入临时数组,cur1后移(无逆序对)。
- 若record[cur1] > record[cur2]:将record[cur2]加入临时数组,cur2后移,同时统计逆序对——左子数组中cur1及右侧所有元素都大于record[cur2],逆序对数量增加“mid - cur1 + 1”。
- 将剩余元素加入临时数组,再把临时数组的结果复制回原数组,完成合并。
- 返回总计数:递归过程中累计左、右、跨数组的逆序对数量,最终返回总数。
代码实现
```cpp
class Solution {
public:vector<int> tmp; // 全局临时数组,避免递归中频繁创建,优化空间开销int reversePairs(vector<int>& record) {tmp.resize(record.size()); // 初始化临时数组,仅分配一次内存return Msort(record, 0, record.size() - 1);}// 递归函数:处理[left, right]区间,返回该区间的逆序对总数int Msort(vector<int>& record, int left, int right) {if (left >= right) return 0; // 递归终止:子数组长度为1或0,无逆序对// 1. 拆分:递归处理左右子数组,统计内部逆序对int mid = left + (right - left) / 2; // 避免(left+right)溢出int ret = 0;ret += Msort(record, left, mid); // 左子数组内部逆序对ret += Msort(record, mid + 1, right); // 右子数组内部逆序对// 2. 合并:统计跨数组逆序对,并合并为有序数组int cur1 = left, cur2 = mid + 1; // cur1:左子数组指针,cur2:右子数组指针int i = 0; // 临时数组的索引while (cur1 <= mid && cur2 <= right) {if (record[cur1] > record[cur2]) {// 左元素>右元素,统计逆序对:左子数组cur1及右侧元素都大于当前右元素ret += mid - cur1 + 1;tmp[i++] = record[cur2++];} else {// 无逆序对,直接加入左元素tmp[i++] = record[cur1++];}}// 处理左子数组剩余元素while (cur1 <= mid) {tmp[i++] = record[cur1++];}// 处理右子数组剩余元素while (cur2 <= right) {tmp[i++] = record[cur2++];}// 将合并后的有序结果复制回原数组for (int k = left; k <= right; k++) {record[k] = tmp[k - left]; // 临时数组从0开始,对应原数组left位置}return ret;}
};
代码优化思路:全局复用临时数组
归并排序的空间开销主要来自临时数组,这里采用“全局复用”的优化策略,相比“递归内创建临时数组”更高效:
- 优化点:在reversePairs函数中初始化一次临时数组,递归过程中反复复用,避免每次合并都创建新数组,减少内存分配和释放的开销。
- 优势:对于题目中“50000”的数组规模,这种优化能明显提升执行效率,同时保证空间复杂度仍为O(n)(临时数组长度固定为原数组长度)。
时间复杂度与空间复杂度分析
- 时间复杂度:O(nlogn)。数组拆分的深度为logn(如长度n的数组需拆log2n层),每一层的合并与计数操作都需要遍历当前层的所有元素(O(n)),因此总时间复杂度为O(nlogn)。
- 空间复杂度:O(n)。核心开销是全局临时数组(O(n)),递归栈的开销为O(logn)(远小于临时数组),因此总空间复杂度由临时数组决定,为O(n)。
总结
- 核心思路:利用归并排序的“拆分-合并”逻辑,将逆序对统计拆分为“左内部、右内部、跨数组”三类,借助有序子数组的特性,把跨数组计数从O(n²)优化为O(n),最终实现O(nlogn)的高效解法。
- 关键理解:子数组排序不影响逆序对计数的准确性,因为排序在“内部逆序对统计之后”,且不改变“左子数组元素在右子数组元素之前”的原始位置关系。
- 优化技巧:全局复用临时数组,避免递归中频繁创建销毁数组,降低内存操作开销,提升执行效率。
- 迁移价值:这种“排序+统计”的结合思路,可迁移到其他需要统计“成对元素关系”的问题中,比如统计数组中“右边元素比左边小k”的对数等,是分治思想的典型应用。
下题预告
下一篇我们将聚焦 力扣 315. 计算右侧小于当前元素的个数——这道题堪称分治思想的“深度应用场”!刚掌握归并排序解决逆序对的核心逻辑,正好用它来进阶实战:它不仅能帮你进一步强化“排序中统计”的解题思维,还能让你学会如何将“右侧小于当前元素”的问题,转化为更熟悉的逆序对相关场景,打通算法灵活转化的关键链路。
Doro 又又又带着小花🌸来啦!🌸奖励🌸看到这里的你!如果这篇内容帮你理清了归并排序的实战细节,或是让你对“排序+统计”的思路更清晰,别忘了点赞支持呀!把它收藏起来,以后复习这类问题时翻出来,就能快速回忆起核心逻辑~关注我,我会持续更新算法系列内容,有什么解题思路或疑问我们随时讨论,对算法感兴趣的朋友也可以去我的算法专辑看看,里面还有更多经典算法题等着你解锁!