技术分享 | torch.profiler:利用探针收集模型执行信息的性能分析工具
大模型训练与推理涉及庞大的参数规模和数据量,若无法在模型设计和执行之前预估时间成本,可能带来巨大损失。分享 PyTorch 深度学习框架中的性能分析器 Profiler,探讨其在模型性能分析中的作用和价值。
猴先生说:大模型训练和推理是运行时的程序,因而对程序的分析方法同样适用于模型,不同之处在于程序行为。
1 背景介绍
大模型(Large Language Model,LLM)是人工智能领域里的一个特殊的分支,从机器学习、深度学习,到生成式预训练模型。“大”是对这类模型的一个非常准确的定位,参与模型训练的数据量大,构成深度神经网络的参数规模大。因此,不论是构建大模型,还是运行大模型,经济成本都是不容忽视的,尤其是时间成本。
一个非常有必要的需求,就是能够分析和预估模型训练的时间,在调试模型的过程中了解性能表现,帮助开发人员以更高效的速度来构建模型。PyTorch 是广泛使用的开源深度学习框架,它不仅支持高效的模型训练,还提供了性能分析器 Profiler 工具。本技术分享以 PyTorch 为例,通过实例介绍 Profiler 工具的典型使用方法。
2 Profiler 模块概述
PyTorch 开源项目torch/csrc/profiler目录下的 README.md 文档介绍了性能分析器 Profiler 模块的实现细节,其利用内置的钩子函数(类似于 Java Spring 框架的 AOP 机制)收集模型的执行信息,主要功能如下:
- 对框架内算子级别的操作进行插桩
- 与 Kineto 接口交互收集性能信息
- 收集 Python 程序的堆栈上下文
- 导出收集的信息,包括执行轨迹,时间线跟踪
PyTorch 设计了插桩函数调用的通用方法,对外接口命名为RecordFunctionCallback,定义在头文件 record_function.h 中第 129 行。用户或 PyTorch 自身可注册回调函数,性能分析器通过该机制记录每个操作调用的起止时间。

在 PyTorch 的具体实现中,执行轨迹(Execution trace,简称为 et)和时间线跟踪(简称为 trace)分别注册了上述回调函数,可以导出相应的 json 格式的信息。其中,执行轨迹以算子为基本单位,记录程序的执行流程和控制依赖,导出的信息记录文件可用于回放模型训练的执行过程。相应的代码定义在源文件 execution_trace_observer.cpp 中第 969 行。
时间线跟踪同样注册回调函数,同时与 Kineto 接口交互计算函数级别的性能(CPU 以及 GPU 消耗的开销),导出的信息记录文件可用 Chrome 浏览器观察各个算子的起始时间和耗时情况。相应的代码定义在源文件 profiler_kineto.cpp 中第 565 行。

3 一个神经网络实例
用一个简单的神经网络来体验这两种信息记录对模型训练发挥的作用,我的工作环境是 windows 11 操作系统中的 WSL2,创建了 Ubuntu 22.04 发行版,使用 Python 3.10.12。PyTorch 库的安装就不在赘述了,直接给出实例代码。
import torch
import torch.nn as nn# ---------- 模型准备 ------------# 定义输入层大小、隐藏层大小、输出层大小和批量大小
in_dim, hidden_dim, out_dim = 10, 5, 1
batch_size = 16# 定义网络结构
model = nn.Sequential(nn.Linear(in_dim, hidden_dim), # 输入层到隐藏层的线性变换nn.ReLU(), # 隐藏层到输出层的激活函数nn.Linear(hidden_dim, out_dim), # 隐藏层到输出层的线性变换nn.Sigmoid(), # 输出层到输出的激活函数
)# 定义损失函数和优化器
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# ---------- 模型训练 ------------# 创建模拟数据
x = torch.randn(batch_size, in_dim)
y = torch.randn(batch_size, out_dim)# 创建 observer 并指定输出文件
et_obs = torch.profiler.ExecutionTraceObserver()
et_obs.register_callback("nn_demo_et.json")# 创建 profile
prof = torch.profiler.profile(activities=[torch.profiler.ProfilerActivity.CPU], # 只用 CPUrecord_shapes=True, # 记录 tensor shapeexecution_trace_observer=et_obs,# with_stack=True, # 记录调用栈,就能看到 trace
)
prof.start()# 执行梯度下降迭代
epochs = 3 # 迭代次数
for epoch in range(epochs):with torch.profiler.record_function(f"epoch_{epoch}"):y_pred = model(x) # 前向传播,计算预测值loss = criterion(y_pred, y) # 计算损失optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播,计算梯度optimizer.step() # 更新模型参数print(f"Epoch {epoch + 1}/{epochs}, Loss: {loss.item():.4f}")prof.stop()
prof.export_chrome_trace("nn_demo_trace.json")# ---------- 模型推理 ------------model.eval()
x_test = torch.randn(1, in_dim)
with torch.no_grad():y_test = model(x_test)
print("输入:", x_test.flatten())
print("输出:", y_test.flatten())
上述代码设计了一个简单的线性分类器,包括输入层到隐藏层的线性变化,通过 Relu 激活函数后,再从隐藏层到输出层的线性变化,最终通过 Sigmod 激活函数得到一维的结果,可用于做二分类。
代码中的torch.profiler.ExecutionTraceObserver语句注册了执行轨迹的回调函数,torch.profiler.profile语句注册了时间线跟踪的回调函数。执行该代码会生成nn_demo_et.json和nn_demo_trace.json两个文件,打开 Chrome 浏览器内置的 chrome://tracing 工具,载入后者 trace 文件,可看到如下图所示的时间线跟踪。

4 分布式训练实例
大模型通常采用分布式训练,通过将多个计算单元(如 CPU、GPU、NPU 等)组成集群来共同训练和装载模型。分布式训练可以有效提升计算能力,缩短训练时间,并解决单一设备内存不足的问题。根据不同的并行方式,分布式训练通常可以划分为以下三种类型:
- 数据并行(Data Parallel):将训练数据划分为多个子集,并将每个子集分配给不同的计算单元进行处理,每个计算单元保有一个完整的模型副本。
- 张量并行(Tensor Parallel):将模型的不同部分分配到不同的计算单元上,每个单元只计算模型的一部分。
- 流水线并行(Pipeline Parallel):将模型的不同层或模块划分到不同的设备上,每个设备处理不同的计算阶段,数据在设备之间像流水线一样传递。

本分享以数据并行为例,依然使用前一节的神经网络,通过创建多个进程将数据划分到 4 个 CPU 核心上执行训练。程序使用 gloo 库,在多个 CPU 核心上完成参数同步,模拟分布式训练的过程。代码如下:
import os
import torch
import torch.nn as nn
import torch.distributed as dist
from torch.utils.data import TensorDataset, DataLoader, DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP# ---------- 模型准备 ------------# 定义输入层大小、隐藏层大小、输出层大小和批量大小
in_dim, hidden_dim, out_dim = 10, 5, 1
batch_size = 16# 定义网络结构
model = nn.Sequential(nn.Linear(in_dim, hidden_dim), # 输入层到隐藏层的线性变换nn.ReLU(), # 隐藏层到输出层的激活函数nn.Linear(hidden_dim, out_dim), # 隐藏层到输出层的线性变换nn.Sigmoid(), # 输出层到输出的激活函数
)# 定义损失函数和优化器
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# ---------------- 进程初始化 ----------------
def init_process(rank, world_size, fn, backend="gloo"):"""每个进程入口"""os.environ["MASTER_ADDR"] = "127.0.0.1"os.environ["MASTER_PORT"] = "29500"dist.init_process_group(backend, rank=rank, world_size=world_size)fn(rank, world_size)dist.destroy_process_group()# ---------------- 训练函数 ----------------
def run_train(rank, world_size):torch.manual_seed(0)# 构造模拟数据,每个进程看一部分X = torch.randn(4 * batch_size, in_dim)Y = torch.randn(4 * batch_size, out_dim)dataset = TensorDataset(X, Y)sampler = DistributedSampler(dataset, world_size, rank, shuffle=True)loader = DataLoader(dataset, batch_size, sampler=sampler)ddp_model = DDP(model.to("cpu"))# 创建 observer 并指定输出文件et_obs = torch.profiler.ExecutionTraceObserver()et_obs.register_callback(f"nn_ddp_demo_et_r{rank}.json")# 创建 profileprof = torch.profiler.profile(activities=[torch.profiler.ProfilerActivity.CPU], # 只用 CPUrecord_shapes=True, # 记录 tensor shapeexecution_trace_observer=et_obs,# with_stack=True, # 记录调用栈,就能看到 trace)prof.start()# 执行梯度下降迭代epochs = 3 # 迭代次数for epoch in range(epochs):with torch.profiler.record_function(f"epoch_{epoch}"):# 必须!让 sampler 重新打乱sampler.set_epoch(epoch)for x, y in loader:y_pred = ddp_model(x) # 前向传播,计算预测值loss = criterion(y_pred, y) # 计算损失optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播,计算梯度optimizer.step() # 更新模型参数if rank == 0:print(f"Rank {rank}, Epoch {epoch + 1}/{epochs}, Loss: {loss.item():.4f}")prof.stop()prof.export_chrome_trace(f"nn_ddp_demo_trace_r{rank}.json")if __name__ == "__main__":world_size = 4torch.multiprocessing.spawn(init_process, args=(world_size, run_train, "gloo"), nprocs=world_size)
和前一节的例子一样,创建ExecutionTraceObserver记录执行轨迹,创建profile记录时间线跟踪。不过记录信息是按照单个进程收集的,因此按rank区分文件名。执行该程序会生成nn_ddp_demo_et_r{0-3}.json和nn_ddp_demo_trace_r{0-3}.json总共 8 个文件个文件。
为方便对齐和查看多个 CPU 核心的时间线跟踪,可以将 trace 文件进行合并。在大模型的帮助下,我写了一个脚本来执行该操作,代码如下:
import json, pathlibmerged = {"traceEvents": []}for fn in sorted(pathlib.Path(".").glob("nn_ddp_demo_trace*.json")):rank = pathlib.Path(fn).stem.replace("nn_ddp_demo_trace_", "") # 0 1 2 3print(fn, rank)with open(fn, encoding="utf-8") as f:part = json.load(f)for ev in part["traceEvents"]:# 跳过元数据if ev.get("ph") in ("M", "metadata"):continue# 加前缀 => 左侧泳道名自动带 r0_ / r1_ / ...if "pid" in ev:ev["pid"] = f"{rank}_pid{ev['pid']}"if "tid" in ev:ev["tid"] = f"{rank}_tid{ev['tid']}"merged["traceEvents"].append(ev)with open("merge_trace.json", "w") as f:json.dump(merged, f, indent=2)
执行该脚本会生成合并后的 trace 文件,命名为merge_trace.json,导入到 Chrome 浏览器工具中,可以看到如下图所示的时间线跟踪。其中的gloo:all_reduce部分展示了,各个 CPU 核心在每个 epoch 内同步梯度的通信时间。

5 Chakra 执行轨迹表示
trace 文件记录了算子的时间消耗,而 et 文件则记录了算子的程序依赖。通过将这两个文件进行对齐和关联,可以形成完整的执行记录。在此过程中,et 文件中的属性rf_id可以用来关联 trace 文件中的Record function id,从而精确追踪每个算子的执行过程。
PyTorch 官方文档提及了可以将 et 文件转换为标准的 Chakra 表示,这是一种开放且互操作的图示表示方法,专门用于 AI/ML 的工作负载格式,可用于模拟器和重放工具复现机器学习过程。项目的开源地址为 https://github.com/mlcommons/chakra.git,简单安装使用一下:
git clone https://github.com/mlcommons/chakra.git
cd chakra
python3 -m venv .venv
source .venv/bin/activate
pip install . # 源码安装 Chakra 库
pip install --upgrade protobuf # 也许会需要更新一下 protobuf 库
sudo apt install graphviz # 安装可视化图形库,执行轨迹可视化会用到
安装成功后,先用如下命令,将 PyTorch 生成的执行执行轨迹转换成 Chakra 格式,后缀命名为.et。转换后的.et文件是 protobuf 序列化存储的,无法直接用 json 格式进行查看。
chakra_converter PyTorch --input nn_demo_et.json --output nn_demo.et
接着,使用可视化命令将执行轨迹导出成图,可以是graphml,dot,pdf格式,更改后缀就可以生成对应的文件格式。
chakra_visualizer --input_filename nn_demo.et --output_filename nn_demo.pdf
截取部分展示执行轨迹内容的图示效果如下:
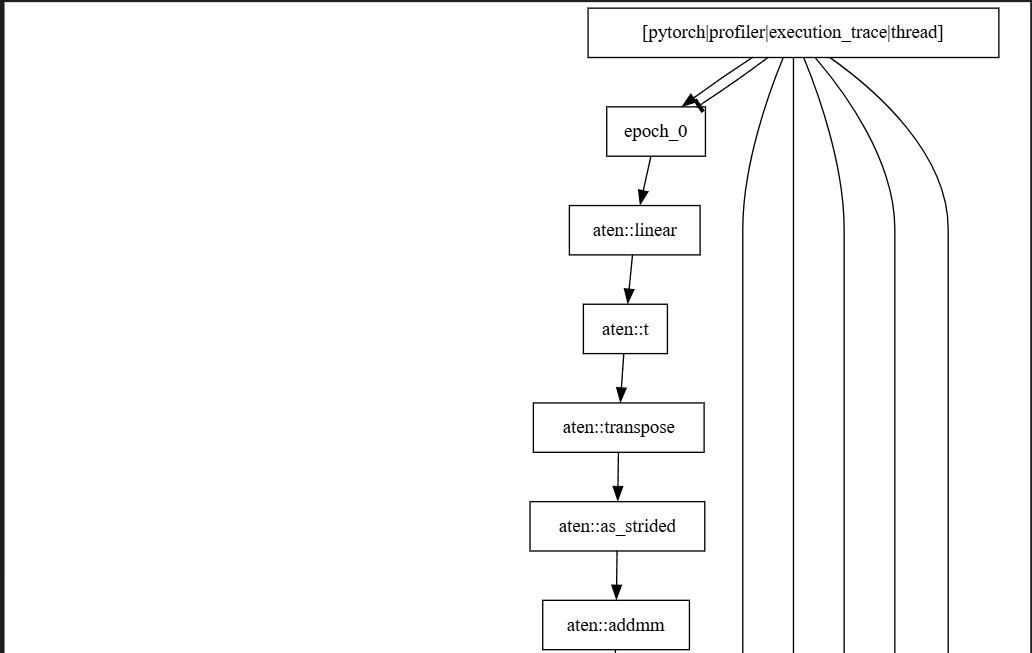
执行轨迹与时间消耗是程序分析中极具价值的工具。在仿真过程中,这些记录文件可作为输入,用于回放程序的执行过程,从而预估程序执行所需的时间成本。