大型语言模型(LLM)架构大比拼
从 DeepSeek-V3 到 MiniMax-M2:现代 LLM 架构设计一览
自原始 GPT 架构问世至今已过去七年。乍看之下,从 GPT-2(2019 年)到DeepSeek-V3 与 Llama 4(2024–2025 年),人们或许会惊讶于这些模型在结构上竟仍如此相似。
诚然,位置编码已从绝对位置编码演进为旋转位置编码(RoPE),多头注意力(Multi-Head Attention, MHA)也大多被分组查询注意力(Grouped-Query Attention, GQA)所取代,而更高效的 SwiGLU 激活函数也已替代了 GELU 等旧式激活函数。然而,在这些细微的改进之下,我们是否真的见证了突破性的变革,还是仅仅在打磨同一套架构基础?
要通过比较 LLM 来确定哪些关键要素导致其表现优异(或不尽如人意)的性能,向来极为困难:数据集、训练方法和超参数差异巨大,且往往缺乏详细的文档记录。
尽管如此,我认为审视这些架构本身的结构性变化仍然极具价值,有助于我们了解 2025 年 LLM 开发者们正在探索的方向。
作者:Sebastian Raschka, PhD
原文链接:https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
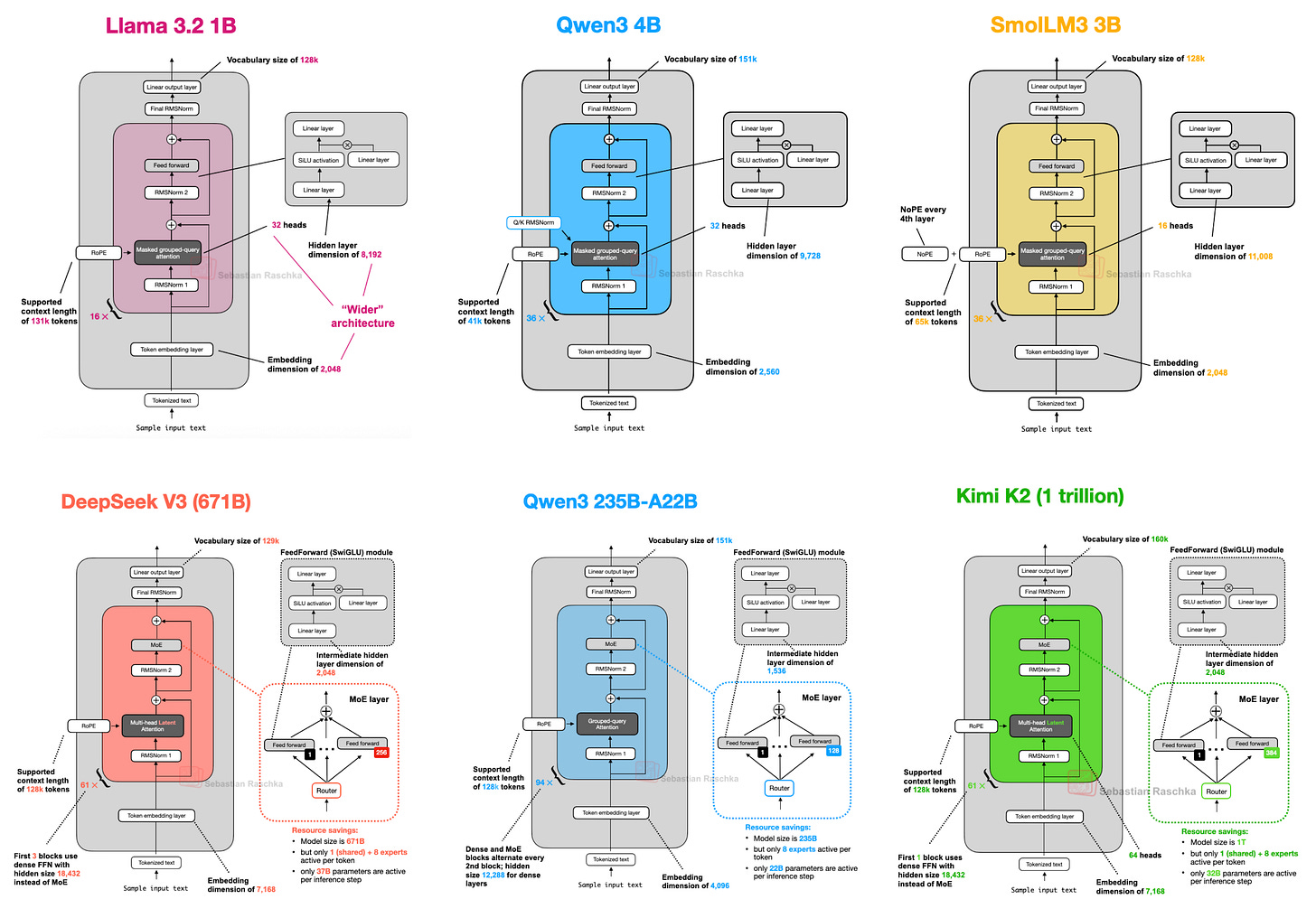
因此,本文将不聚焦于基准性能或训练算法,而是专注于定义当今旗舰开源模型的架构发展。
1. DeepSeek V3/R1
你可能已不止一次听说,DeepSeek R1 在 2025 年 1 月发布时引起了巨大反响。DeepSeek R1 是一个推理模型,构建于 2024 年 12 月推出的 DeepSeek V3 架构之上。
尽管本文聚焦于 2025 年发布的架构,但鉴于 DeepSeek V3 是在 2025 年随 DeepSeek R1 的推出才获得广泛关注与采用,将其纳入讨论是合理的。
本节将聚焦 DeepSeek V3 引入的两项关键架构技术,它们显著提升了计算效率,并使其区别于众多其他 LLM:
- 多头潜在注意力(Multi-Head Latent Attention, MLA)
- 专家混合(Mixture-of-Experts, MoE)
1.1 多头潜在注意力(MLA)
在讨论 MLA 之前,我们先简要回顾其背景,以理解其设计动机。为此,我们从近年来已成为新标准的分组查询注意力(GQA)谈起。GQA 是一种比多头注意力(MHA)更节省计算与参数的替代方案。
简要总结 GQA:与 MHA 中每个头都拥有独立的键(Key)和值(Value)投影不同,GQA 通过让多个查询头共享同一组键值投影来减少内存占用。
例如,如下图所示,如果有 2 个键值组和 4 个注意力头,则头 1 和 2 可能共享一组键值,而头 3 和 4 共享另一组。这减少了键值计算的总量,从而降低内存使用并提升效率(根据消融研究表明,对建模性能并无明显影响)。
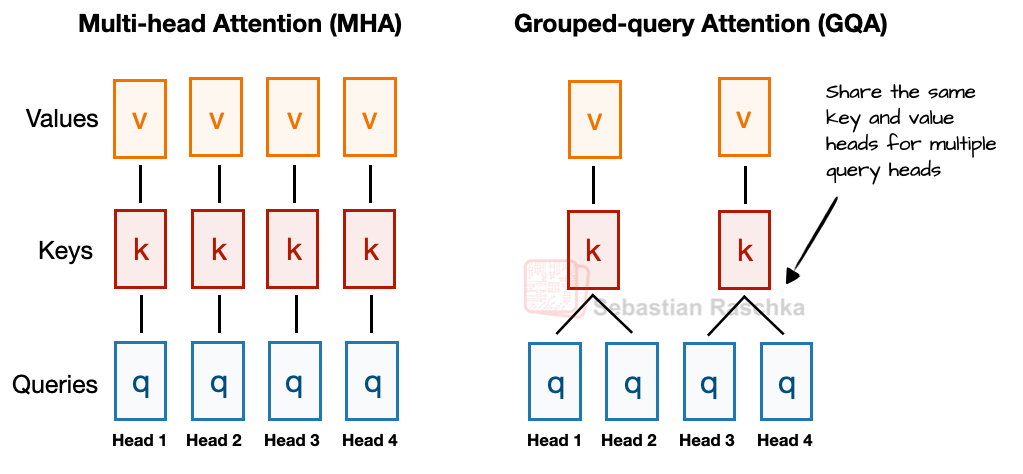
GQA 的核心思想是通过在多个查询头之间共享键值头,来减少键值头的数量。
- 降低了模型参数量
- 在推理时减少了键值张量的内存带宽消耗,因为 KV 缓存中需要存储和检索的键值更少。
尽管 GQA 主要是 MHA 的一种计算效率优化方案,但消融研究(例如原始 GQA 论文和 Llama 2 论文中的研究)表明,其建模性能与标准 MHA 相当。
而多头潜在注意力(MLA)则提供了另一种不同的内存节省策略,尤其适合与 KV 缓存配合使用。与 GQA 共享键值头不同,MLA 在将键值张量存入 KV 缓存前,先将其压缩到一个更低维的空间中。
在推理时,这些压缩后的张量会被重新投影回原始维度后再使用,如下图所示。这增加了一次矩阵乘法,但显著减少了内存占用。(查询(query)会在训练时被压缩,但推理时不压缩。)
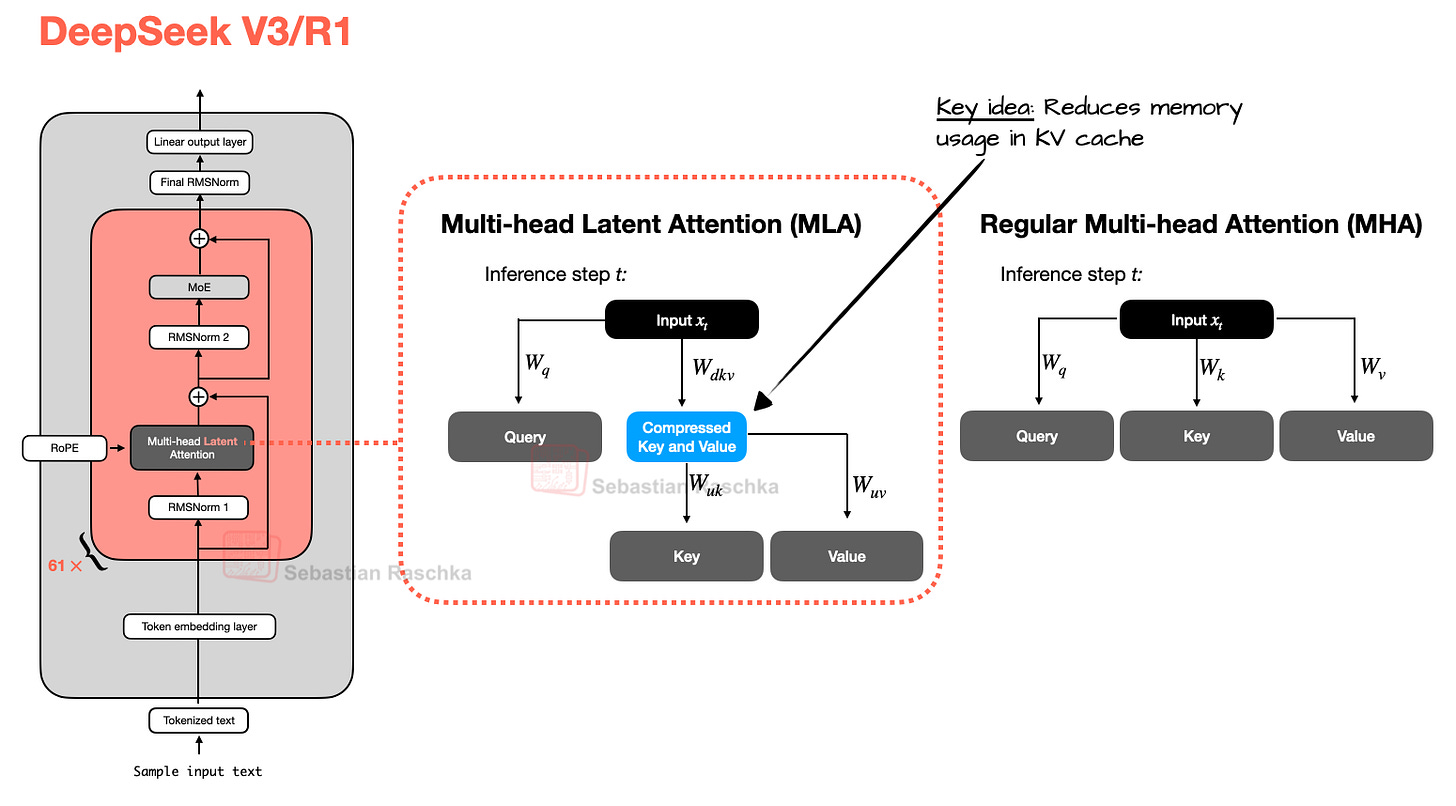
值得一提的是,MLA 并非 DeepSeek V3 首创,其前代 DeepSeek-V2 已引入并使用了该技术。此外,V2 论文中包含几项有趣的消融研究,或许能解释 DeepSeek 团队为何选择 MLA 而非 GQA(见下图)。
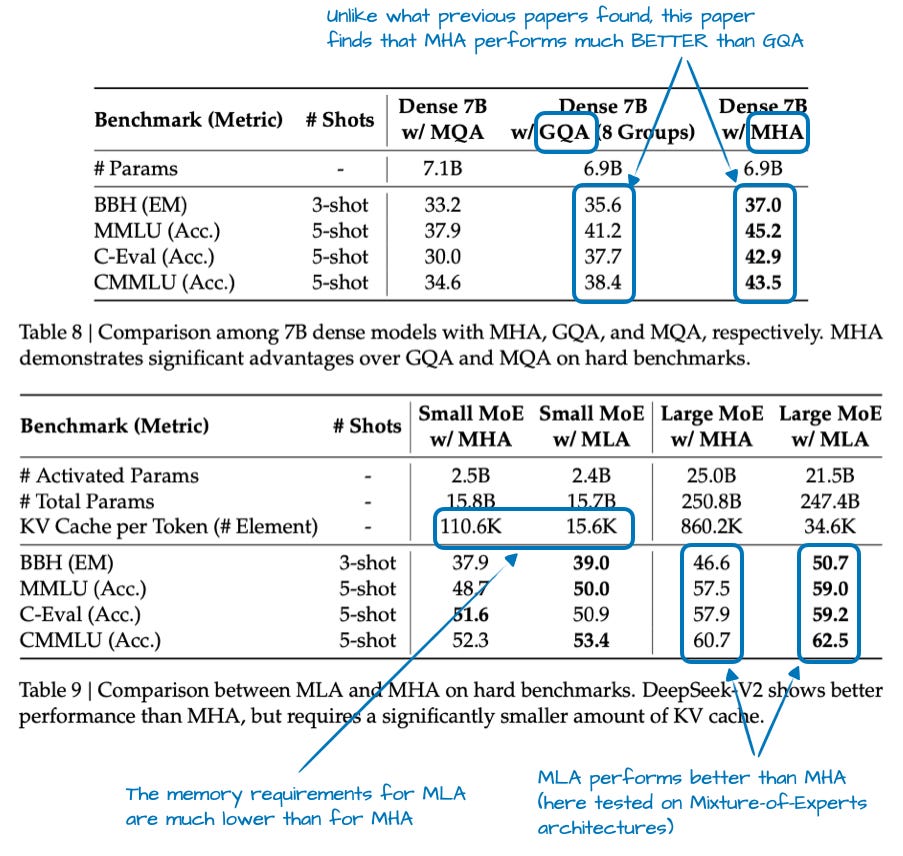
如图 4 所示,GQA 表现似乎不如 MHA,而 MLA 的建模性能甚至优于 MHA,这很可能是 DeepSeek 团队选择 MLA 的原因。(若能同时比较 MLA 与 GQA 之间”每个词元(Token)的 KV 缓存“上的节省效果就更理想了!)
总结本节:MLA 是一种巧妙的技巧,在减少 KV 缓存内存使用的同时,甚至比MHA 略微提升了建模性能。
1.2 混合专家模型(MoE)
DeepSeek 架构中另一项值得强调的重大组件是其专家混合(MoE)层。虽然 MoE 并非 DeepSeek 首创,但今年它强势回归,后文将讨论的许多架构也采用了该技术。
MoE 的核心思想是将 Transformer 块中的每个前馈网络(FeedForward)模块替换为多个“专家”层,每个专家本身也是一个前馈模块。这意味着我们将单个前馈块替换为多个前馈块,如下图所示。
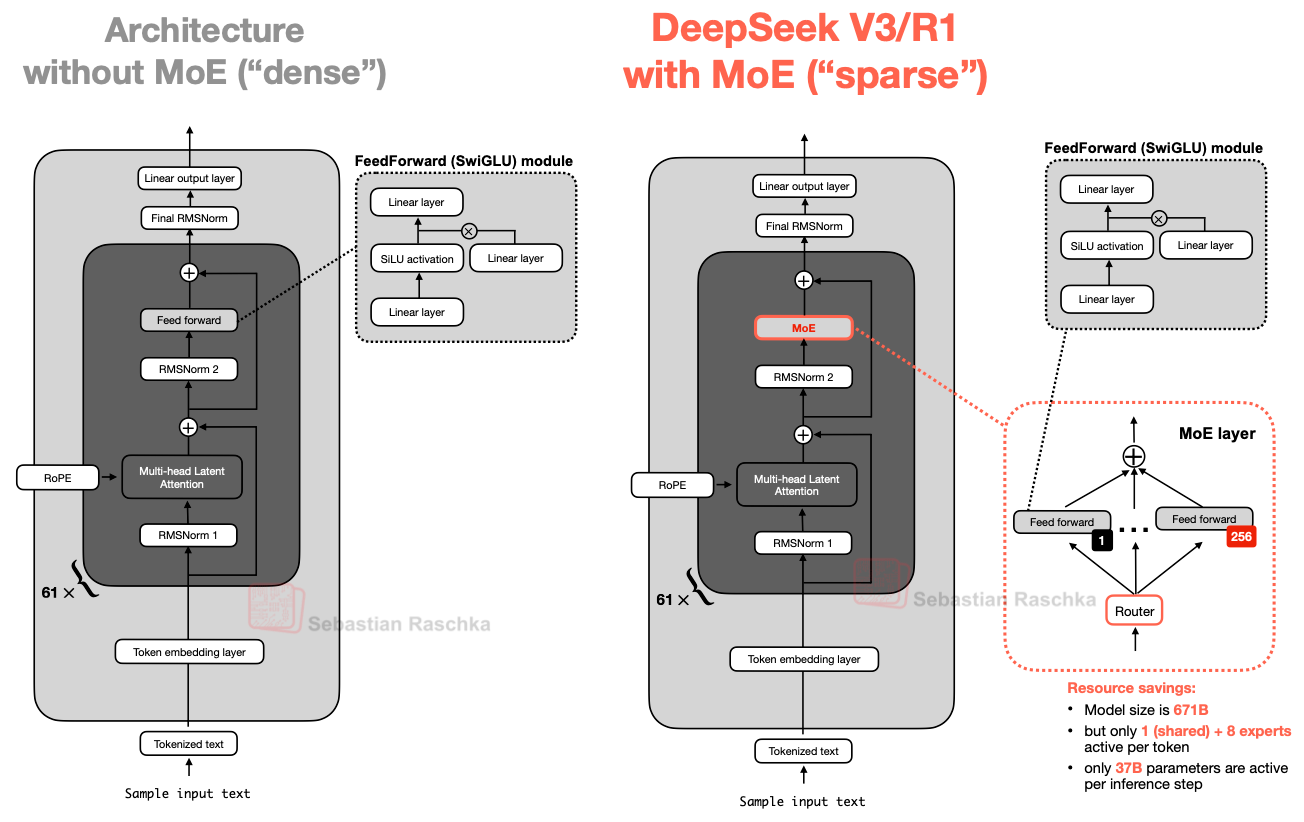
Transformer 模块内部的前馈网络块(上图中深灰色块)通常占据了模型总参数的很大一部分。(请注意,Transformer 块及其前馈模块在 LLM 中会重复多次;DeepSeek-V3 中重复了 61 次。)
因此,将单个前馈块替换为多个前馈块(MoE 设置)会大幅增加模型总参数量。但关键技巧在于:并非每个 token 都激活所有专家。相反,一个路由器(router)只为每个 token 选择一小部分专家。
由于每次仅激活少量专家,MoE 模块常被称为稀疏(sparse)模块,与始终使用全部参数的稠密(dense)模块形成对比。然而,MoE 通过大量总参数提升了 LLM 的容量,使其在训练中能吸收更多知识;而稀疏性则保证了推理效率,因为我们不会同时使用所有参数。
例如,DeepSeek-V3 每个 MoE 模块包含 256 个专家,总参数达 6710 亿。但在推理时,每次仅激活 9 个专家(1 个共享专家 + 路由器选择的 8 个),这意味着每次推理步骤仅使用约 370 亿参数,而非全部 6710 亿。
DeepSeek-V3 MoE 设计的一个显著特点是使用了共享专家(shared expert)——一个对每个 token 始终激活的专家。这一想法并非全新,早在 DeepSeek 2024 MoE 和 2022 DeepSpeedMoE 论文论文中就已提出。
DeepSpeedMoE 论文 首次指出,共享专家能提升整体建模性能。这很可能是因为常见或重复模式无需由多个独立专家分别学习,从而为专家腾出更多空间去学习更专业的模式。
1.3 DeepSeek 总结
总而言之,DeepSeek-V3 是一个拥有 6710 亿参数的巨型模型,发布时性能超越了包括 4050 亿参数 Llama 3 在内的其他开源模型。尽管规模更大,但得益于其 MoE 架构(每次推理仅激活约 370 亿参数),它在推理时反而更加高效。
另一个关键的区别特征是 DeepSeek-V3 使用了多头潜在注意力(MLA)而非分组查询注意力(GQA)。MLA 和 GQA 都是标准多头注意力(MHA)在推理效率上的替代方案,尤其是在使用 KV 缓存时。尽管 MLA 实现更复杂,但 DeepSeek-V2 论文中的研究表明,其建模性能优于 GQA。
2. OLMo 2
由非营利组织艾伦人工智能研究所(Allen Institute for AI)推出的 OLMo 系列模型,因其在训练数据和代码方面的透明度,以及相对详细的技术报告而备受瞩目。
虽然你可能不会在任何基准测试排行榜的顶端找到 OLMo 模型,但它们结构清晰,更重要的是,由于其透明性,为 LLM 开发提供了极佳的蓝图。
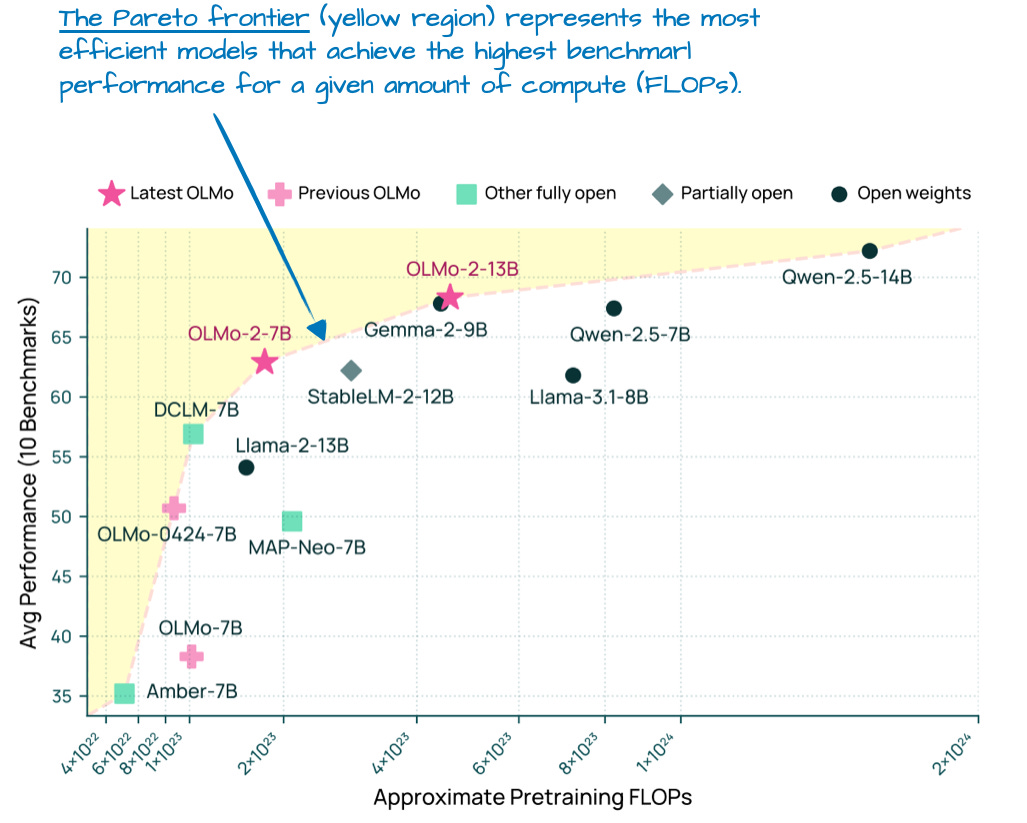
尽管 OLMo 模型因其透明度而受欢迎,但它们的性能也并不差。事实上,在 1 月份发布时(在 Llama 4、Gemma 3 和 Qwen 3 之前),OLMo 2 模型正处于计算与性能的帕累托前沿,如下图所示。
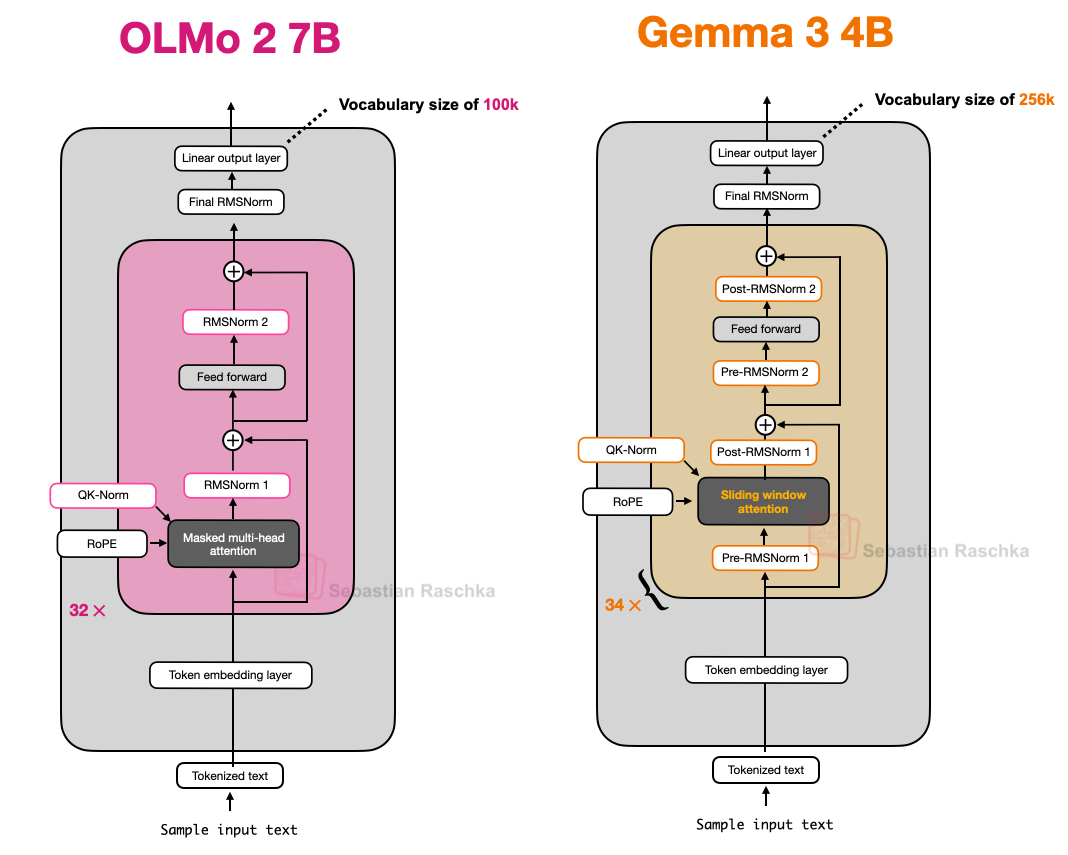
本文仅聚焦 LLM 架构细节(而非训练或数据)。那么 OLMo2 有哪些有趣的架构设计?主要体现在归一化(normalization)方面:RMSNorm 层的位置,以及新增的 QK-norm,下文将逐一讨论。
另一值得一提的是,OLMo 2 仍使用传统的多头注意力(MHA),而非 MLA 或 GQA。
2.1 归一化层的位置
总体而言,OLMo 2 大体遵循原始 GPT 模型的架构,与其他当代 LLM 相似。但存在一些值得注意的偏差,我们先从归一化层谈起。
与 Llama、Gemma 及大多数其他 LLM 类似,OLMo 2 将 LayerNorm 替换为 RMSNorm。
但 RMSNorm 并非新概念(它本质上是 LayerNorm 的简化版,可训练参数更少),此处不再赘述。
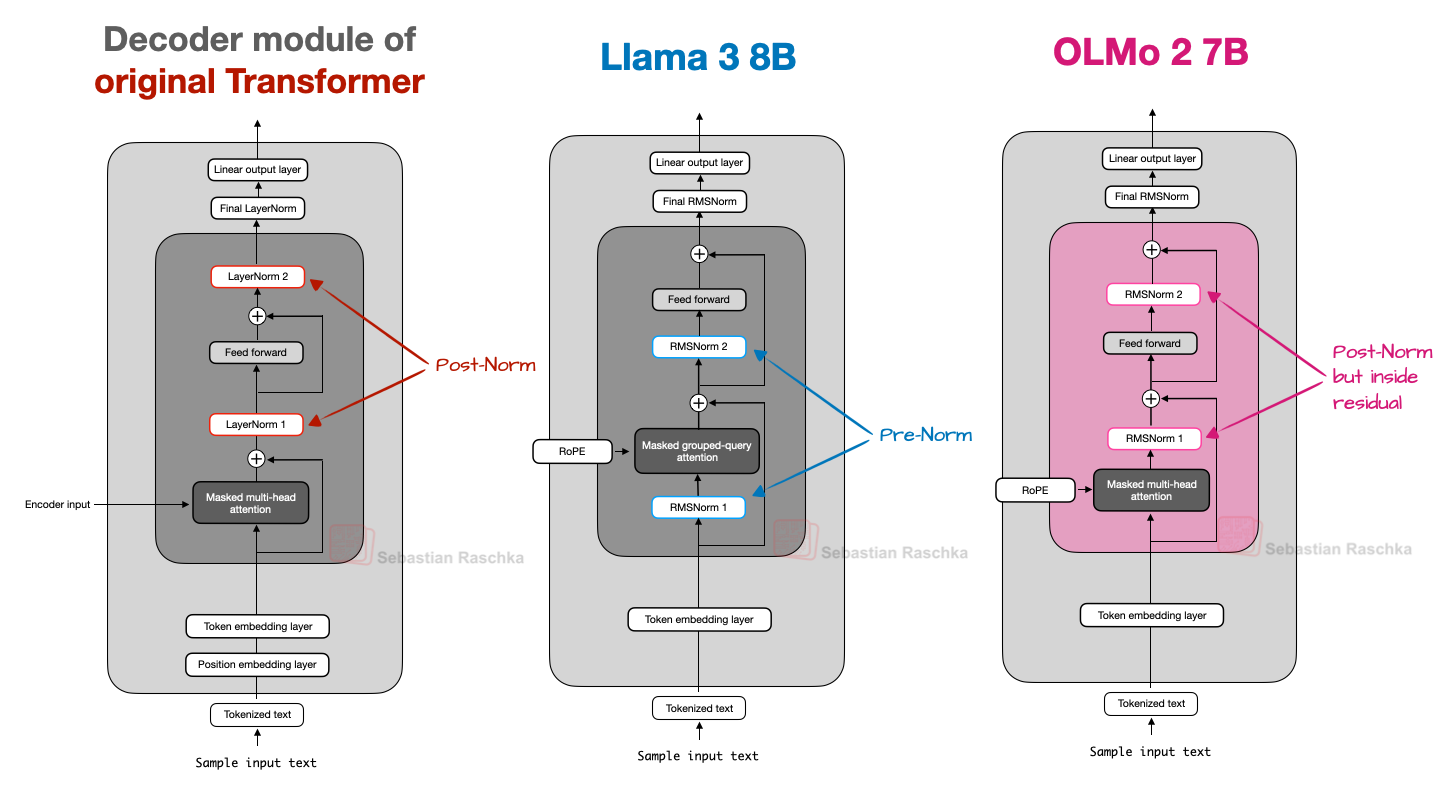
然而,RMSNorm 层的位置值得讨论。原始 Transformer(出自《Attention is all you need》)在注意力模块和前馈模块之后分别放置两个归一化层,这被称为 Post-LN 或 Post-Norm。
而 GPT 及其后的大多数 LLM 则将归一化层置于注意力和前馈模块之前,即 Pre-LN 或 Pre-Norm。
Post-Norm 与 Pre-Norm 的对比如下图所示。
2020 年,Xiong 等人指出,Pre-LN 在初始化时能产生更稳定的梯度。此外,研究者提到 Pre-LN 甚至无需精心设计的学习率预热(warm-up),而这对于 Post-LN 至关重要。
提及这一点是因为 OLMo 2 采用了一种 Post-LN 形式(但使用 RMSNorm 而非 LayerNorm,故称为 Post-Norm)。
在 OLMo 2 中,归一化层被置于注意力和前馈层之后,如上图所示。但请注意,与原始 Transformer 架构不同,这些归一化层仍位于残差连接(skip connections)内部。
那么,他们为何调整归一化层位置?原因在于它提升了训练稳定性,如下图所示。
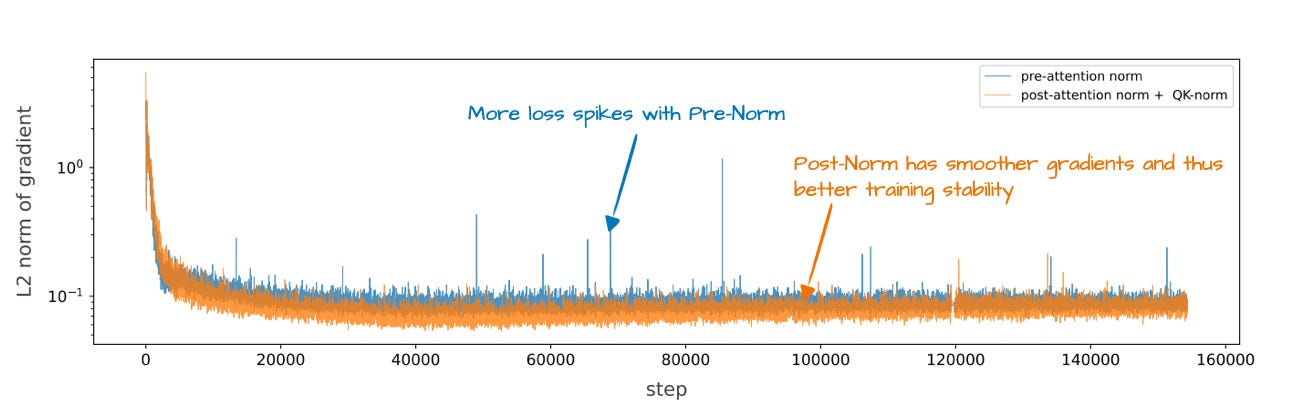
遗憾的是,该图同时展示了层重排与 QK-Norm 的效果,后者是另一个独立概念。因此,很难单独评估归一化层重排本身的贡献。
2.2 QK-Norm
既然前文已提及 QK-norm,且后文将讨论的 Gemma 2、Gemma 3 等模型也使用了该技术,我们简要说明其含义。
QK-Norm 本质上是另一个 RMSNorm 层。它被置于多头注意力(MHA)模块内部,在应用 RoPE 之前对查询(q)和键(k)进行归一化。以下是我为 Qwen3 从零实现 编写的分组查询注意力(GQA)层代码片段(GQA 中的 QK-norm 应用与 OLMo 的 MHA 类似):
class GroupedQueryAttention(nn.Module):def __init__(self, d_in, num_heads, num_kv_groups,head_dim=None, qk_norm=False, dtype=None):# ...if qk_norm:self.q_norm = RMSNorm(head_dim, eps=1e-6)self.k_norm = RMSNorm(head_dim, eps=1e-6)else:self.q_norm = self.k_norm = Nonedef forward(self, x, mask, cos, sin):b, num_tokens, _ = x.shape# 应用投影queries = self.W_query(x) keys = self.W_key(x)values = self.W_value(x) # ...# 可选归一化if self.q_norm:queries = self.q_norm(queries)if self.k_norm:keys = self.k_norm(keys)# 应用 RoPEqueries = apply_rope(queries, cos, sin)keys = apply_rope(keys, cos, sin)# 扩展 K 和 V 以匹配头的数量keys = keys.repeat_interleave(self.group_size, dim=1)values = values.repeat_interleave(self.group_size, dim=1)# 注意力attn_scores = queries @ keys.transpose(2, 3)# ...
如前所述,与 Post-Norm 一起,QK-Norm 稳定了训练过程。请注意,QK-Norm 并非由 OLMo 2 发明,而是可以追溯到 2023 年的 Scaling Vision Transformers 论文。
2.3 OLMo 2 总结
简言之,OLMo 2 架构设计的亮点主要在于 RMSNorm 的位置:在注意力和前馈模块之后(一种 Post-Norm 变体),以及在注意力机制内部对查询和键额外应用 RMSNorm(QK-Norm)。这两者共同提升了训练损失的稳定性。
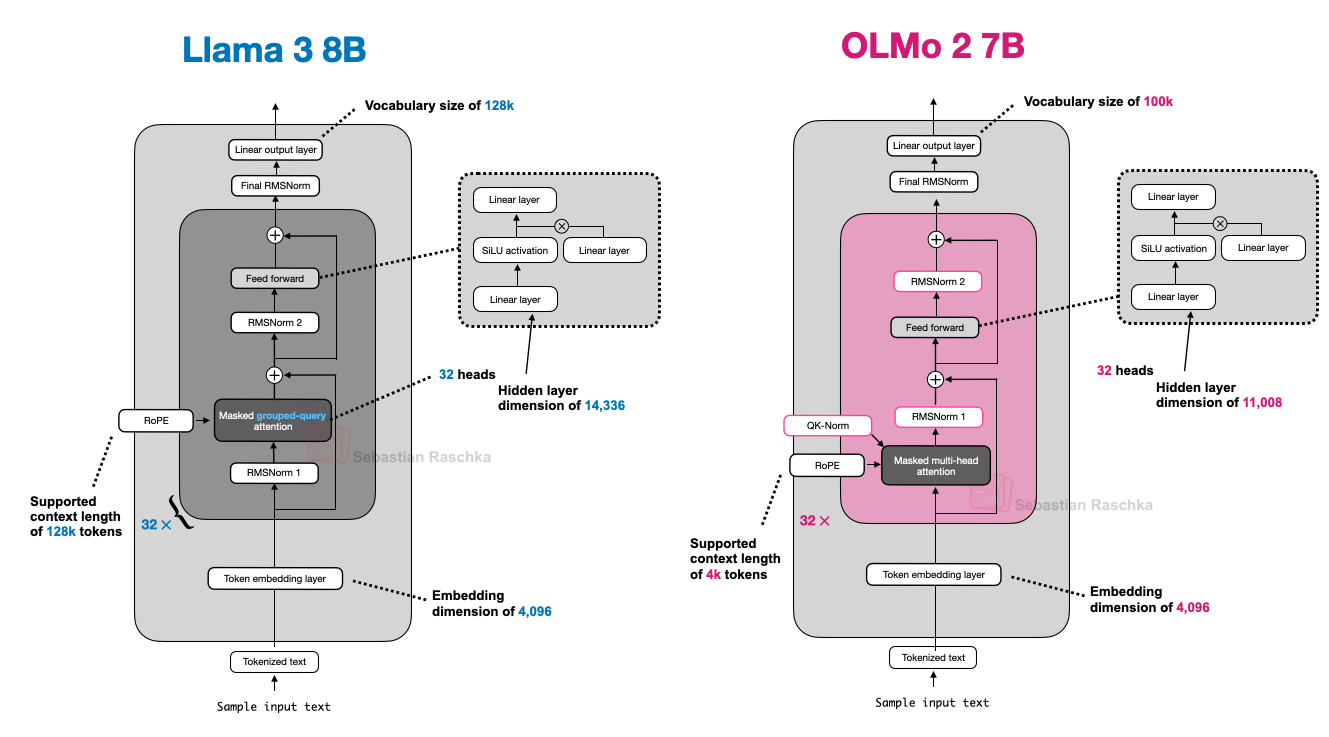
下图进一步将 OLMo 2 与 Llama 3 进行对比;可见,除 OLMo 2 仍使用传统 MHA(而非 GQA)外,两者架构相对相似。(不过,OLMo 2 团队三个月后发布了使用 GQA 的 32B 变体。)
3. Gemma 3
Google 的 Gemma 模型一直表现出色,我认为其受关注程度相比 Llama 系列等热门模型略显不足。
Gemma 的显著特点之一是较大的词表大小(以更好支持多语言),以及对 27B 规模的更强聚焦(而非 8B 或 70B)。但需注意,Gemma 2 也提供更小规模:1B、4B 和 12B。
27B 规模恰到好处:能力远超 8B 模型,但资源消耗又远低于 70B 模型,甚至可在 Mac Mini 上流畅本地运行。
那么,Gemma 3 还有哪些亮点?如前所述,DeepSeek-V3/R1 等模型使用专家混合(MoE)架构,在固定模型规模下降低推理内存需求。(MoE 方法也被后文将讨论的多个模型采用。)
而 Gemma 3 则采用另一种“技巧”来降低计算成本:滑动窗口注意力(Sliding Window Attention)。
3.1 滑动窗口注意力
通过滑动窗口注意力(最初在 2020 年的 LongFormer 论文中引入,并已被 Gemma 2 使用),Gemma 3 团队能够大幅减少 KV 缓存中的内存需求,如下图所示。
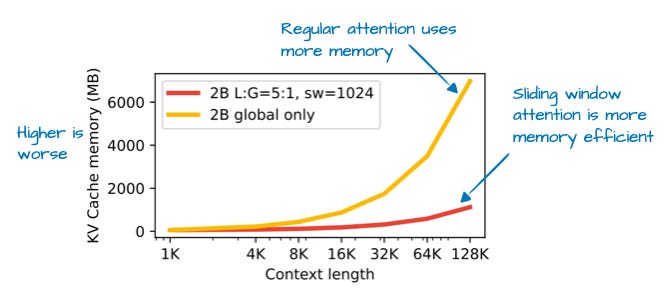
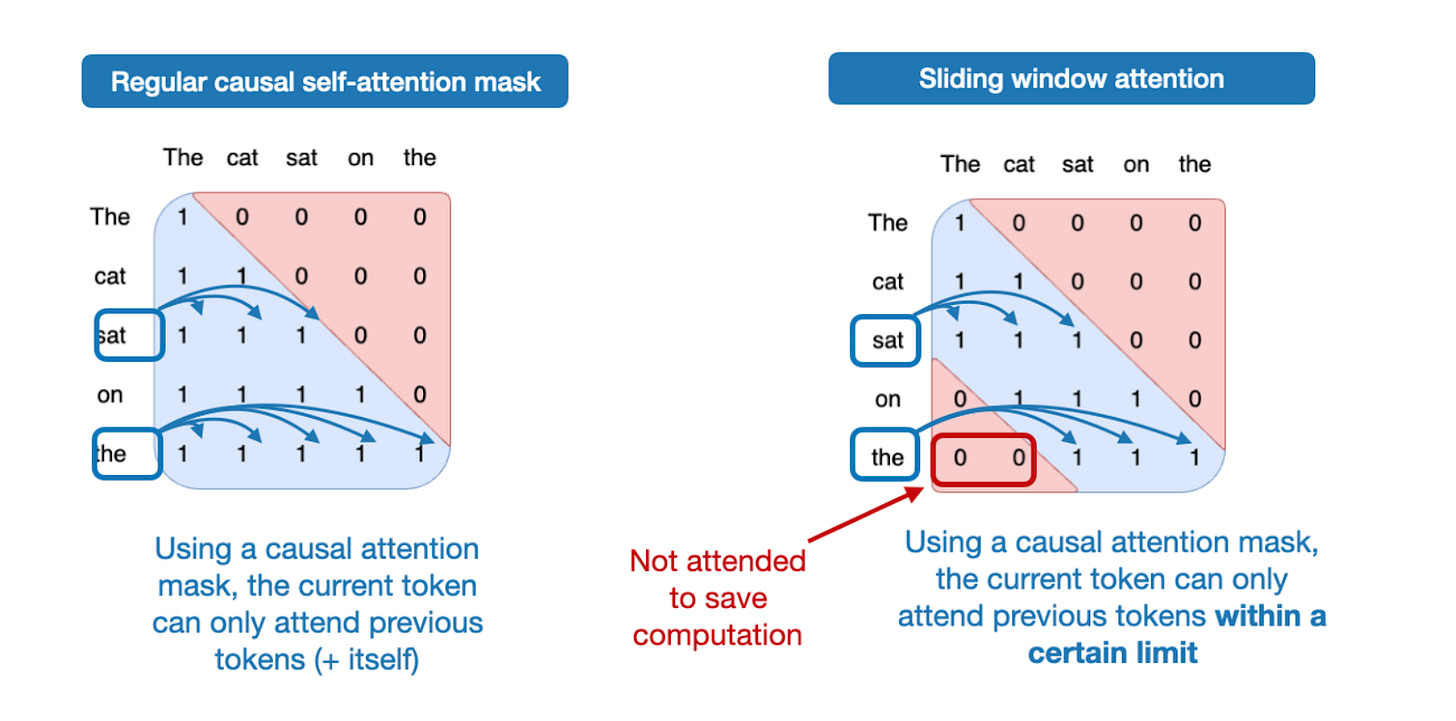
那么,什么是滑动窗口注意力?若将常规自注意力视为**全局(global)注意力机制(每个序列元素可访问所有其他元素),则滑动窗口注意力可视为局部(local)**注意力,因为它限制了当前查询位置周围的上下文范围。如下图所示。
需注意,滑动窗口注意力可与多头注意力(MHA)或分组查询注意力(GQA)结合使用;Gemma 3 使用的是分组查询注意力。
如前所述,滑动窗口注意力也被称为局部注意力,因为局部窗口随当前查询位置移动。相比之下,常规注意力是全局的,每个 token 可访问所有其他 token。
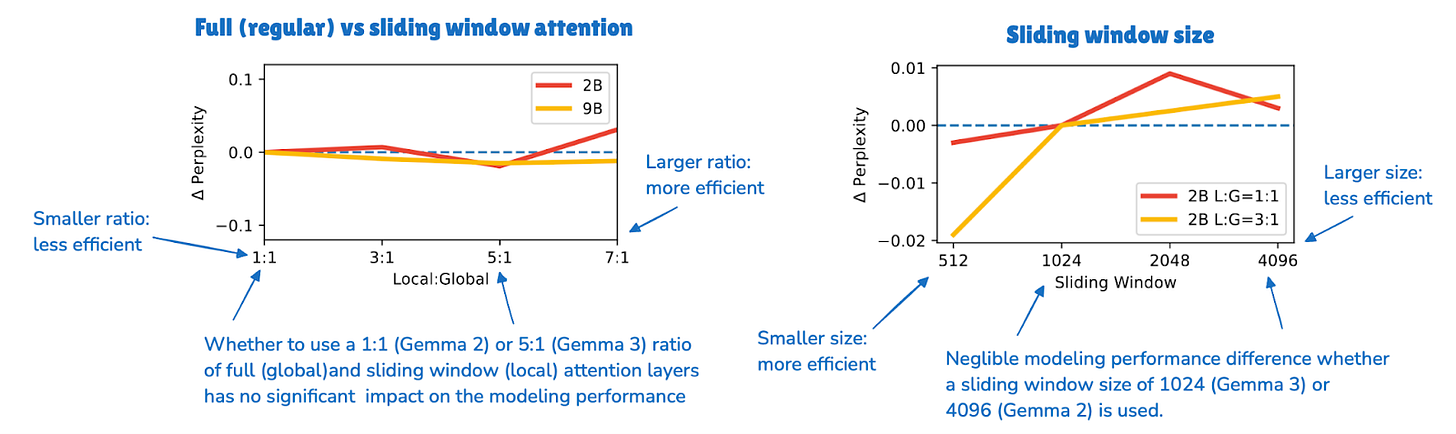
Gemma 2 前代架构已使用滑动窗口注意力。Gemma 3 的不同之处在于调整了全局(常规)与局部(滑动)注意力的比例。
例如,Gemma 2 使用混合注意力机制,滑动窗口(局部)与全局注意力比例为 1:1,每个 token 可关注附近 4k token 的上下文。
Gemma 2 在每隔一层使用滑动窗口注意力,而 Gemma 3 将比例调整为 5:1,即每 5 个滑动窗口(局部)注意力层才配 1 个完整注意力层;此外,滑动窗口大小从 Gemma 2 的 4096 缩减至仅 1024。这使模型更侧重高效、局部的计算。
根据其消融研究,滑动窗口注意力对建模性能影响极小,如下图所示。
尽管滑动窗口注意力是 Gemma 3 最显著的架构特点,我还想简要补充归一化层位置,作为对前文 OLMo 2 部分的延续。
3.2 Gemma 3 中的归一化层放置
一个细微但有趣的细节是,Gemma 3 在其分组查询注意力模块周围同时采用了 Pre-Norm 和 Post-Norm 设置的 RMSNorm。
这与 Gemma 2 类似,但仍值得强调,因为它不同于:(1)原始 Transformer 的 Post-Norm(《Attention is All You Need》),(2)GPT-2 推广并被众多后续架构采用的 Pre-Norm,以及(3)前文所述 OLMo 2 的 Post-Norm 变体。
我认为这种归一化层放置方式是一种相对直观的方法,兼顾了 Pre-Norm 与 Post-Norm 的优点。在我看来,多一点归一化无伤大雅。最坏情况下,若额外归一化冗余,仅会带来轻微效率损失。实际上,由于 RMSNorm 相对廉价,这几乎不会产生可察觉的影响。
3.3 Gemma 3 总结
Gemma 3 是一款性能出色的开源 LLM,在我看来,其在开源社区中略显被低估。最有趣的是其使用滑动窗口注意力提升效率(未来若能与 MoE 结合将更值得期待)。
此外,Gemma 3 的归一化层位置独特,在注意力和前馈模块前后均放置了 RMSNorm 层。
3.4 额外内容:Gemma 3n
在 Gemma 3 发布几个月后,谷歌推出了 Gemma 3n,这是一个为小型设备效率而优化的 Gemma 3 模型,目标是在手机上运行。
Gemma 3n 为提升效率所做的一项改变是所谓的逐层嵌入(Per-Layer Embedding, PLE)参数层。其核心思想是仅将模型参数的子集保留在 GPU 内存中。针对文本、音频、视觉等模态的 token 层特定嵌入,则按需从 CPU 或 SSD 流式加载。
下图展示了 PLE 的内存节省效果,列出标准 Gemma 3 模型的参数为 54.4 亿。这很可能指 Gemma 3 的 40 亿变体。
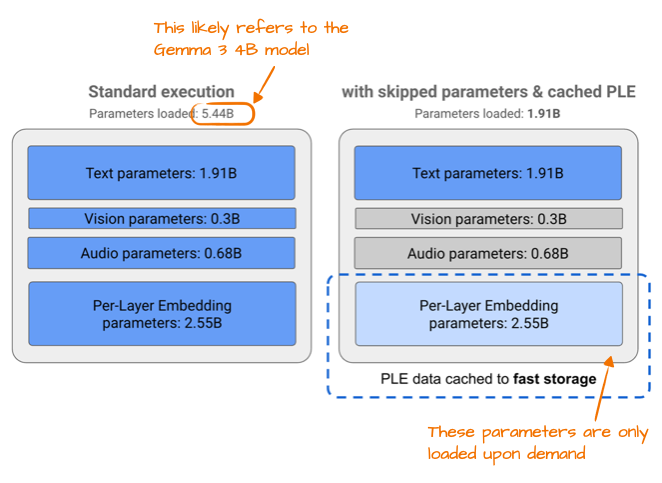
54.4 亿与 40 亿的差异源于 Google 报告 LLM 参数量的有趣方式:他们常排除嵌入参数以使模型显得更小,但在某些情况下(如此处)又包含嵌入参数以使模型显得更大。这并非 Google 独有,已成为领域内普遍做法。
另一有趣技巧是 MatFormer(Matryoshka Transformer 的缩写)。例如,Gemma 3n 使用单一共享 LLM(Transformer)架构,可切分为更小的、可独立使用的模型。每个切片均经过独立训练,因此推理时可仅运行所需部分(而非完整大模型)。
4. Mistral Small 3.1
Mistral Small 3.1 24B 于 Gemma 3 发布后不久(2025 年 3 月)推出,其在多个基准上超越 Gemma 3 27B(数学除外),且速度更快。
Mistral Small 3.1 相比 Gemma 3 推理延迟更低的原因,可能在于其自定义分词器,以及缩减 KV 缓存和层数。除此之外,其架构相当标准,如下图所示。
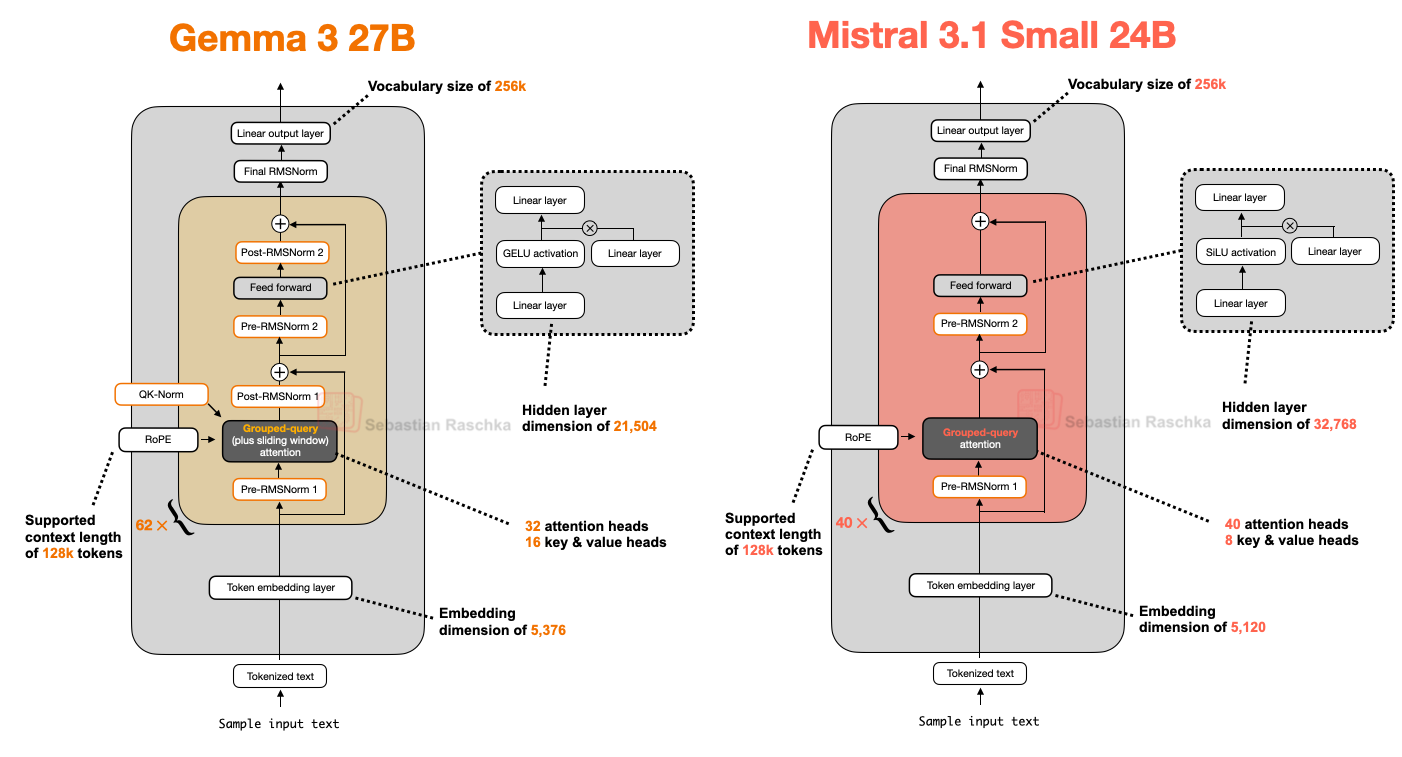
有趣的是,早期 Mistral 模型曾使用滑动窗口注意力,但在 Mistral Small 3.1 中似乎已弃用(官方 Model Hub 配置文件中默认设置为 “sliding_window”: null,且模型卡未提及该技术)。
因此,由于 Mistral 使用常规分组查询注意力(而非 Gemma 3 的滑动窗口 GQA),或许能通过更优化的代码(如 FlashAttention)进一步节省推理计算。我推测,滑动窗口注意力虽减少内存使用,但未必降低推理延迟,而 Mistral Small 3.1 正专注于此。
5. Llama 4
本文早前对专家混合(MoE)的详尽讨论在此再次派上用场。Llama 4 也采用了 MoE 方法,其余架构相当标准,与 DeepSeek-V3 高度相似,如下图所示。(Llama 4 原生支持多模态,类似 Gemma 和 Mistral。但本文聚焦语言建模,故仅讨论文本模型。)
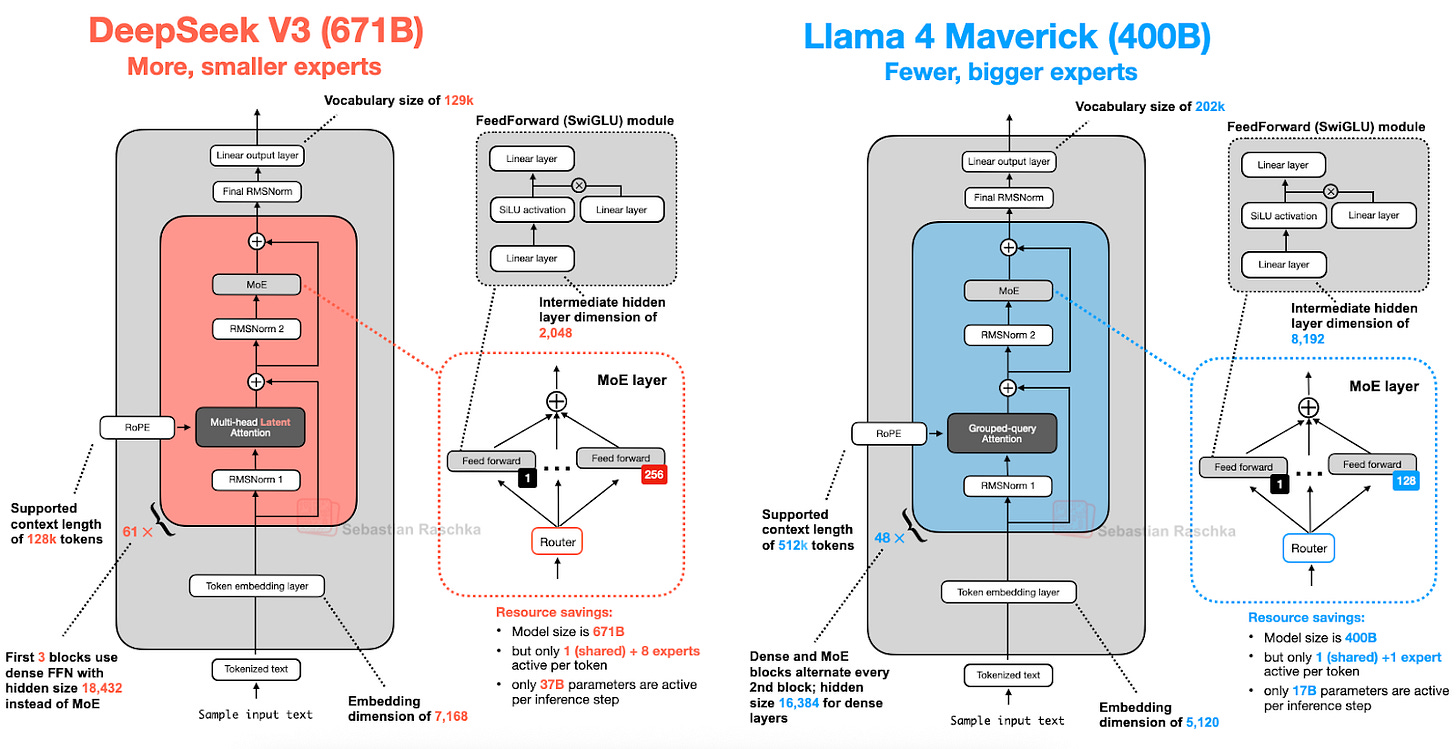
尽管 Llama 4 Maverick 架构整体与 DeepSeek-V3 高度相似,但仍有一些值得强调的差异。
首先,Llama 4 使用与其前代类似的分组查询注意力,而 DeepSeek-V3 使用前文讨论的多头潜在注意力(MLA)。DeepSeek-V3 与 Llama 4 Maverick 均为超大架构,DeepSeek-V3 总参数量约大 68%。但 DeepSeek-V3 的活跃参数(370 亿)是 Llama 4 Maverick(170 亿)的两倍以上。
Llama 4 Maverick 采用更经典的 MoE 设置:专家数量更少但规模更大(2 个活跃专家,每专家隐藏层大小 8192),而 DeepSeek-V3 有 9 个活跃专家(每专家隐藏层大小 2048)。此外,DeepSeek 在每个 Transformer 块(除前 3 个外)均使用 MoE 层,而 Llama 4 则在每两个 Transformer 块中交替使用 MoE 与稠密模块。
鉴于架构间存在诸多细微差异,难以精确评估其对最终模型性能的影响。但主要结论是:MoE 架构在 2025 年显著流行。
6. Qwen3
Qwen 团队始终提供高质量的开源 LLM。2023 年 NeurIPS LLM 效率挑战赛中,优胜方案均基于 Qwen2。
如今,Qwen3 系列模型再次登顶各规模榜单。该系列包含 7 个稠密模型:0.6B、1.7B、4B、8B、14B 和 32B;以及 2 个 MoE 模型:30B-A3B 和 235B-A22B。
6.1 Qwen3 (稠密)
我们先讨论稠密模型架构。截至本文撰写时,0.6B 模型可能是当前世代最小的开源模型。根据我的个人经验,其在小规模下表现极佳:本地运行时吞吐量高、内存占用低,且易于本地训练(用于教学目的)。
因此,Qwen3 0.6B 已取代 Llama 3 1B 成为我的首选。两者架构对比如下。
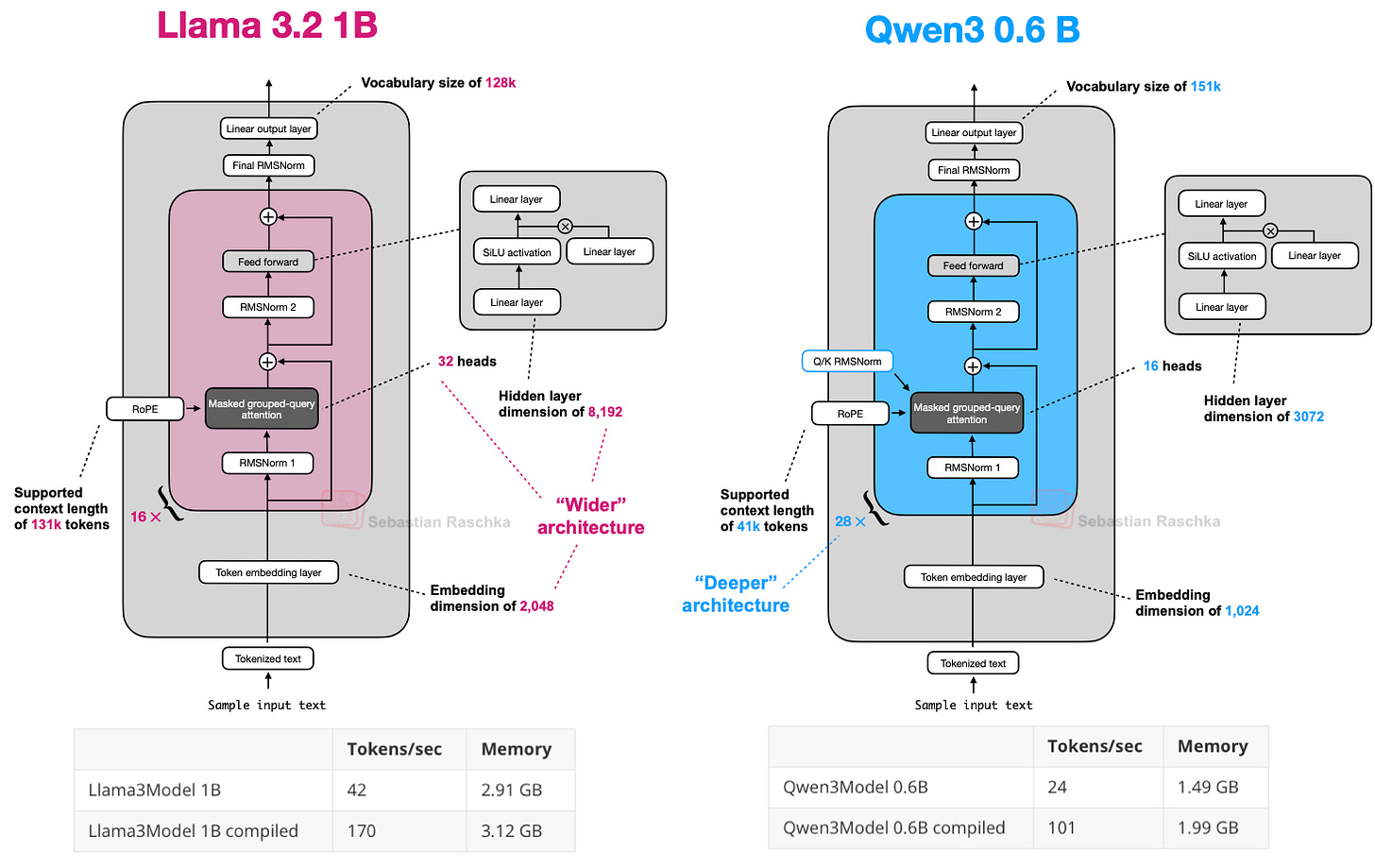
若你对不依赖第三方 LLM 库的纯 PyTorch Qwen3 实现感兴趣,我最近已从零实现 Qwen3。
上图中的计算性能数据基于我在 A100 GPU 上运行的从零 PyTorch 实现。可见,Qwen3 内存占用更小(整体架构更小,隐藏层和注意力头也更少),但 Transformer 块更多,导致运行速度较慢(每秒生成 token 数更低)。
6.2 Qwen3 (MoE)
如前所述,Qwen3 还提供两种 MoE 变体:30B-A3B 和 235B-A22B。为何某些架构(如 Qwen3)同时提供常规(稠密)和 MoE(稀疏)版本?
如本文开头所述,MoE 变体有助于在固定基础模型规模下降低推理成本。同时提供两种版本,可让用户根据目标和约束灵活选择。
稠密模型通常更易于微调、部署和跨硬件优化。
而 MoE 模型则针对推理扩展进行了优化。例如,在固定推理预算下,它们能实现更高的整体模型容量(即因规模更大而在训练中吸收更多知识),而不会同比例增加推理成本。
通过发布两种类型,Qwen3 系列可支持更广泛的用例:稠密模型适用于稳健性、简洁性和微调;MoE 模型适用于大规模高效服务。
最后,我们将 Qwen3 235B-A22B(A22B 表示“220 亿活跃参数”)与 DeepSeek-V3(活跃参数近两倍,达 370 亿)进行对比。
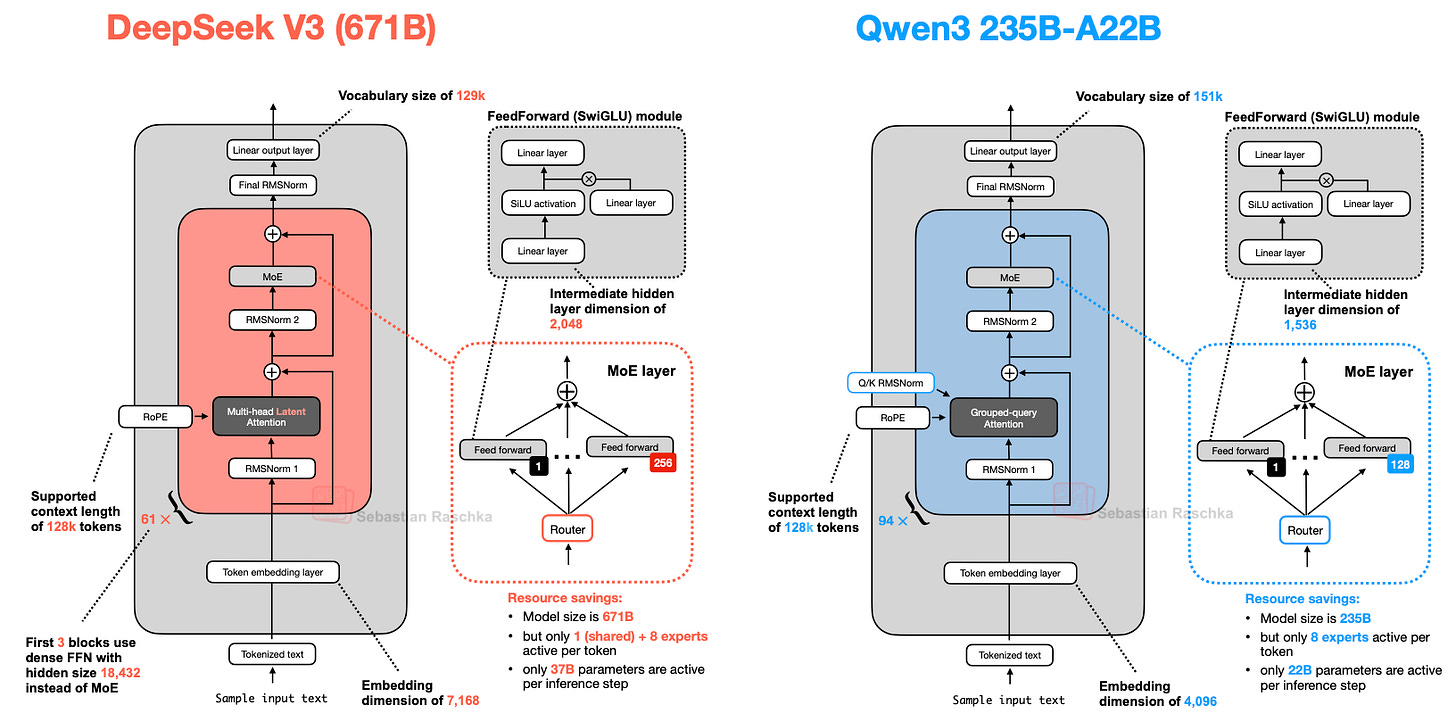
如上图所示,DeepSeek-V3 与 Qwen3 235B-A22B 架构极为相似。但值得注意的是,Qwen3 模型放弃了共享专家(早期 Qwen 模型如 Qwen2.5-MoE 曾使用共享专家)。
遗憾的是,Qwen3 团队未披露放弃共享专家的原因。我猜测,或许在其设置中(专家数从 Qwen2.5-MoE 的 2 个增至 Qwen3 的 8 个),共享专家对训练稳定性已非必要,且通过仅使用 8 个(而非 8+1 个)专家可节省额外计算/内存成本。(但这无法解释为何 DeepSeek-V3 仍保留共享专家。)
更新:Qwen3 开发者之一 Junyang Lin 回应如下:
“当时我们并未发现共享专家带来足够显著的改进,且担心其对推理优化造成影响。老实说,对此问题并无明确答案。”
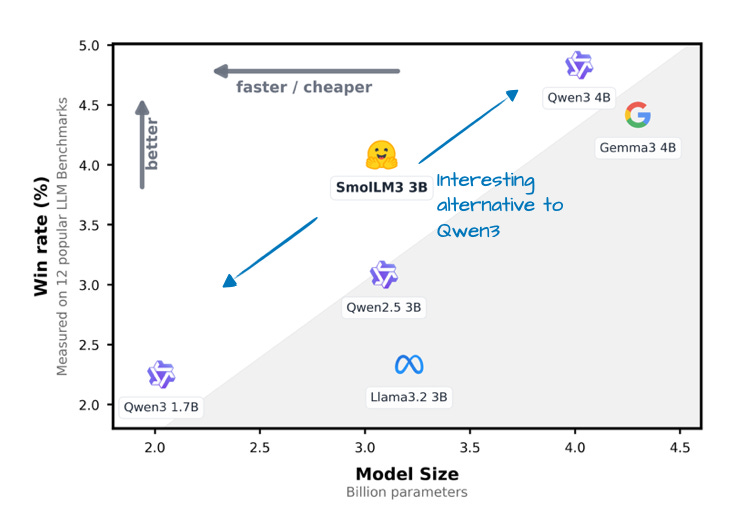
7. SmolLM3
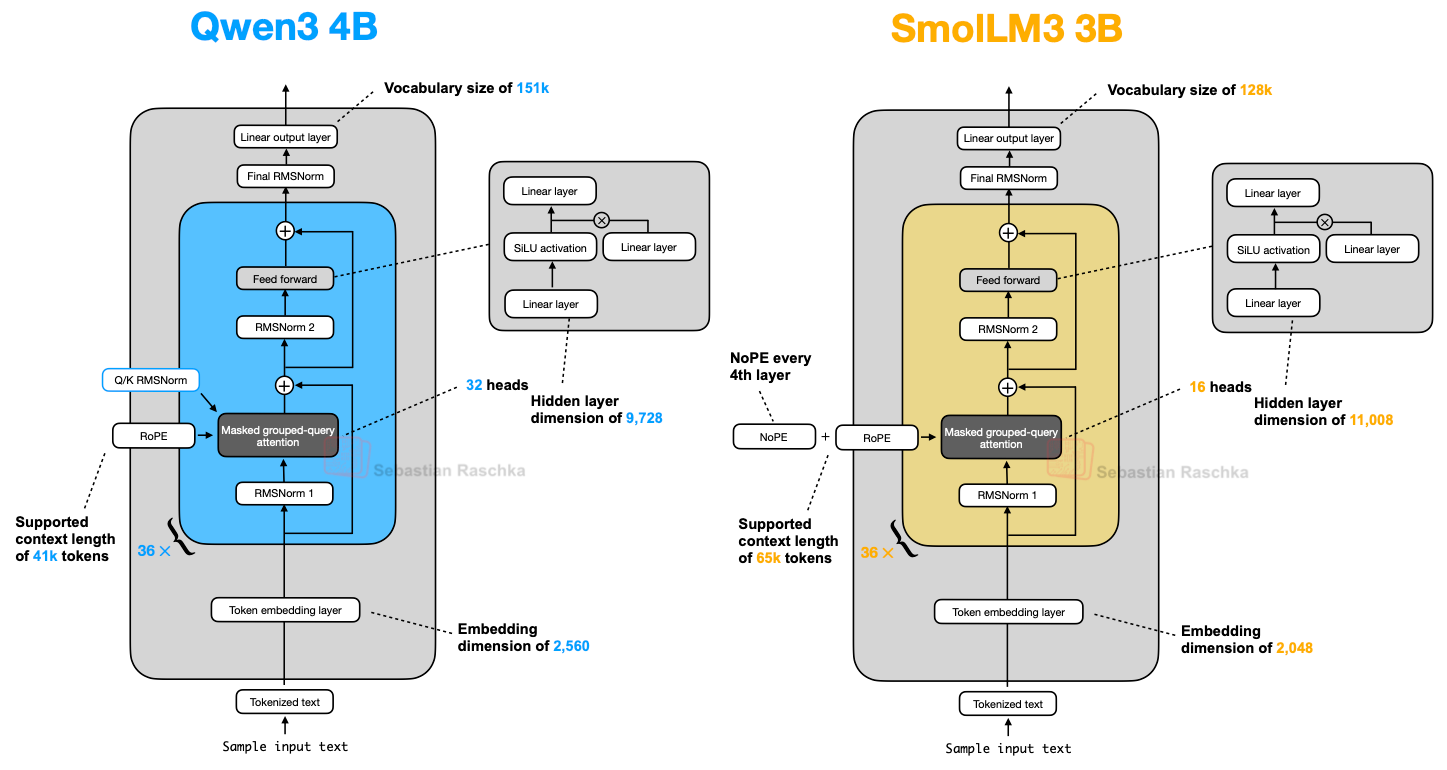
SmolLM3 或许不如本文讨论的其他 LLM 流行,但我认为它仍值得纳入,因其在相对小巧便捷的 30 亿参数规模下提供了出色的建模性能,介于 Qwen3 1.7B 与 4B 之间,如下图所示。
此外,它还像 OLMo 一样公开了大量训练细节,这在当前实属罕见且值得赞赏!
如架构对比图所示,SmolLM3 架构相当标准。但最有趣的特点或许是其使用了 NoPE(No Positional Embeddings,无位置编码)。
7.1 无位置编码 (NoPE)
在 LLM 的背景下,NoPE 是一个可以追溯到 2023 年一篇论文(《位置编码对 Transformer 长度泛化能力的影响》)的较早概念,旨在移除显式的位置信息注入(如早期 GPT 架构中的绝对位置嵌入层,或如今的 RoPE))。
在基于 Transformer 的 LLM 中,位置编码通常是必要的,因为自注意力机制对 token 顺序无感。绝对位置嵌入通过额外嵌入层向 token 嵌入添加位置信息来解决此问题。
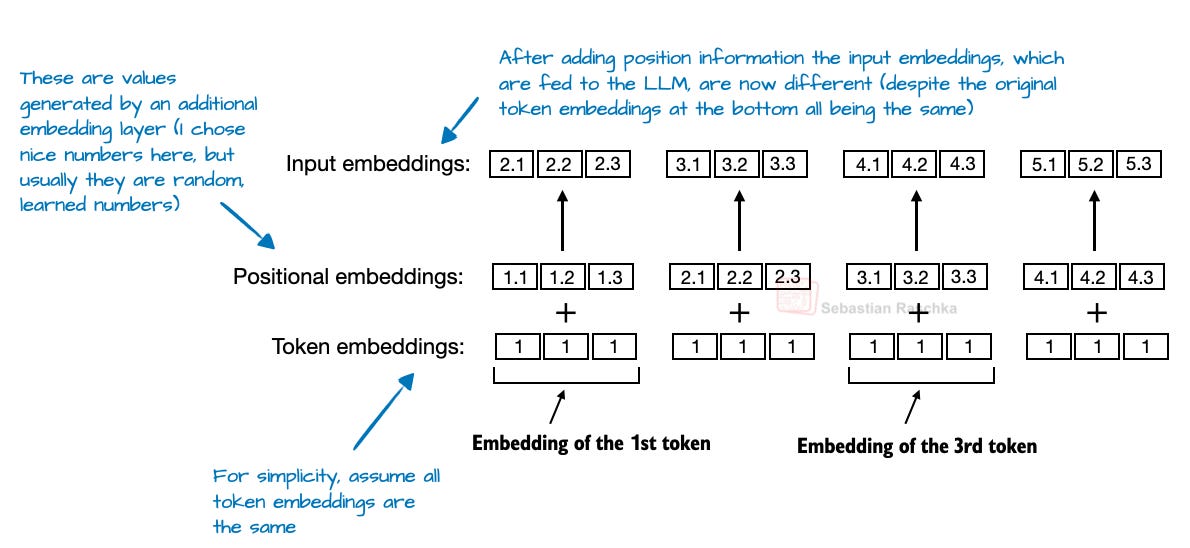
而 RoPE 则通过根据 token 位置旋转查询和键向量来解决此问题。
但在 NoPE 层中,完全不添加任何位置信号:无固定、无学习、无相对。什么都没有。
尽管没有位置嵌入,模型仍通过因果注意力掩码((causal attention mask))知晓 token 顺序。该掩码阻止每个 token 关注未来 token。因此,位置 t 的 token 仅能关注位置 ≤ t 的 token,从而保留自回归顺序。
因此,尽管未显式添加位置信息,模型结构中仍隐含方向感,LLM 在常规梯度下降训练中可学会利用此特性(若对优化目标有益)。(详见 NoPE 论文中的定理。)
综上,NoPE 论文不仅发现无需显式位置信息注入,还发现 NoPE 具有更好的长度泛化能力,即 LLM 回答性能随序列长度增加而下降的幅度更小,如下图所示。
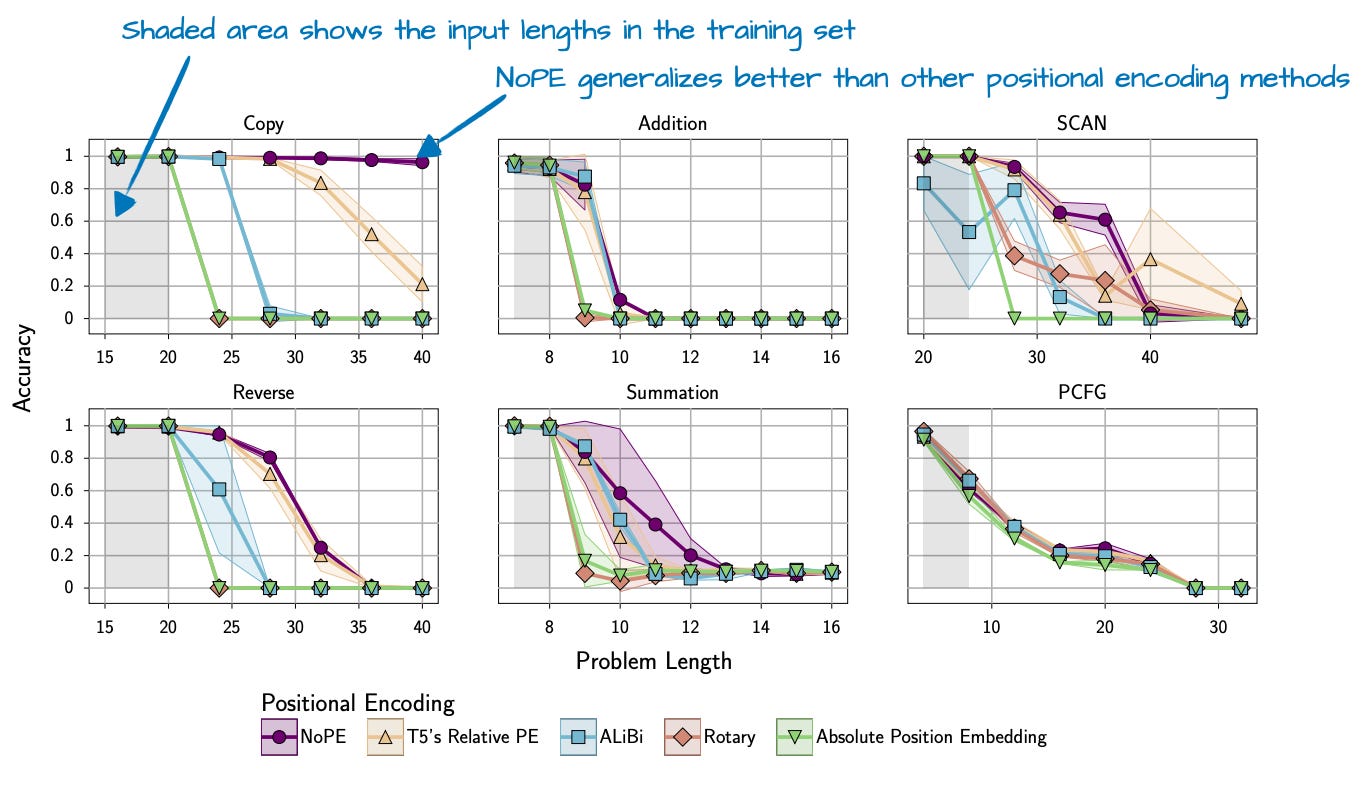
需注意,上述实验基于约 1 亿参数的较小 GPT 式模型和较小上下文长度。这些发现能否推广至更大、更现代的 LLM 尚不明确。
因此,SmolLM3 团队很可能仅在每第 4 层应用 NoPE(或更准确地说,省略 RoPE)。
8. Kimi K2
Kimi K2 最近在 AI 社区引起巨大轰动,因其作为开源模型却展现出惊人性能。根据基准测试,其性能媲美 Google Gemini、Anthropic Claude 和 OpenAI ChatGPT 等顶级闭源模型。
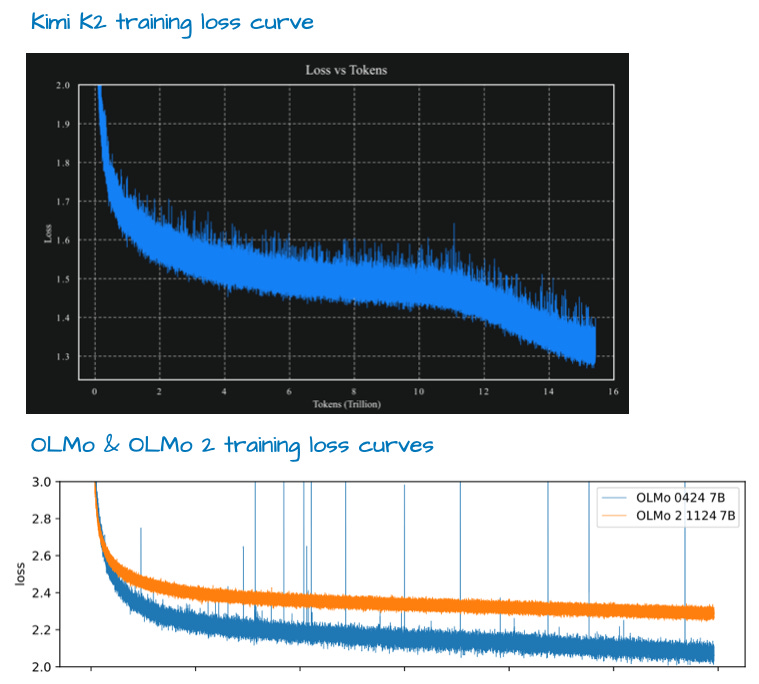
一个显著特点是其使用了相对较新的 **Muon 优化器 **(而非 AdamW)的变体。据我所知,这是首次在如此规模的生产模型中使用 Muon(此前仅证明可扩展至 16B)。这带来了极佳的训练损失曲线,很可能助其登顶榜首。
尽管有人评论其损失曲线异常平滑(无尖峰),但我认为并非异常平滑(例如,参见下图 OLMo 2 的损失曲线;且梯度 L2 范数可能是衡量训练稳定性的更好指标)。但其损失曲线的衰减速度确实令人印象深刻。
然而,如本文引言所述,训练方法属于另一话题。
该模型本身拥有 1 万亿参数,这确实令人印象深刻。
在撰写本文时,它可能是这一代最大的 LLM(考虑到 Llama 4 Behemoth 尚未发布,专有 LLM 不计算在内,以及谷歌的 1.6 万亿 Switch Transformer 是来自不同代的编码器-解码器架构)。
这也是一种“回归本源”:Kimi K2 基本采用本文开头讨论的 DeepSeek-V3 架构,但规模更大,如下图所示。
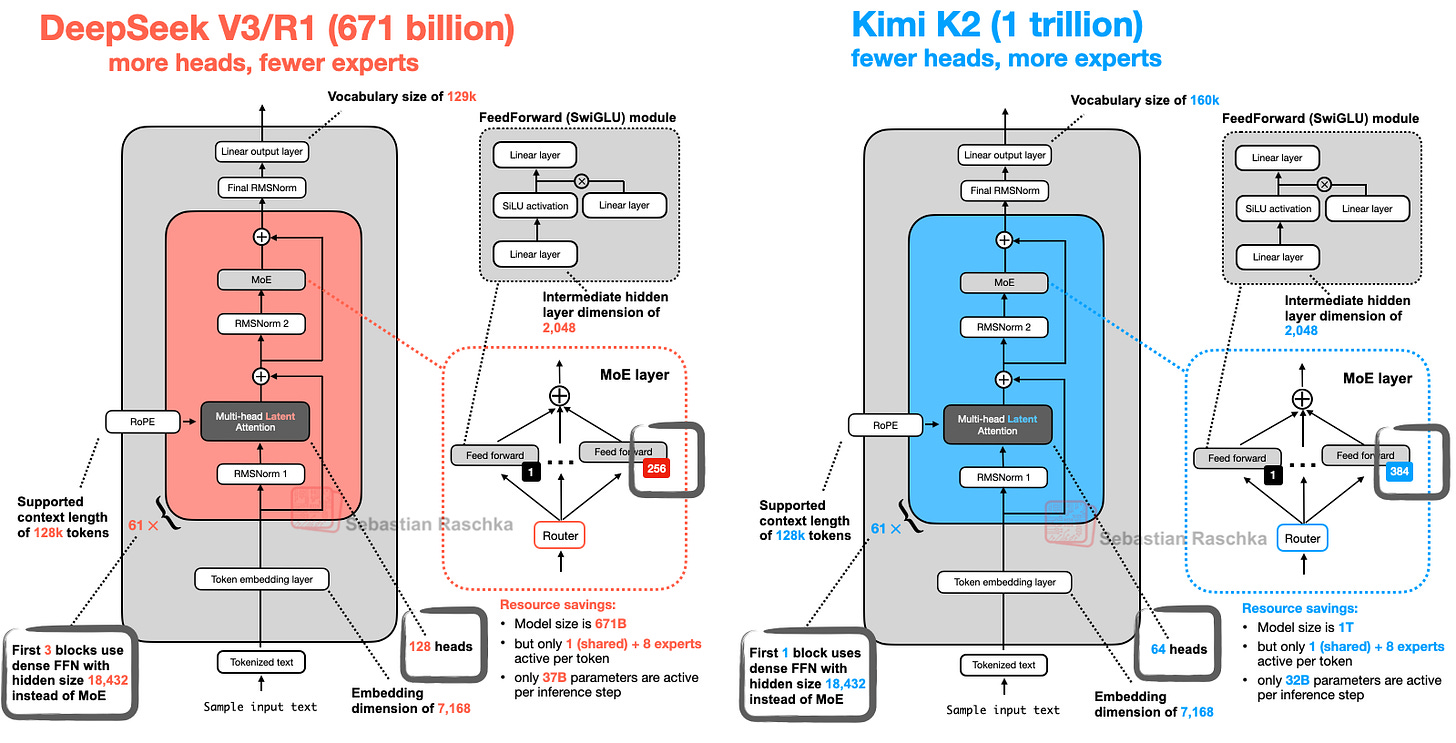
如上图所示,Kimi K2 与 DeepSeek V3 基本相同,仅在 MoE 模块中使用了更多专家,且在多头潜在注意力(MLA)模块中减少了头数。
Kimi K2 并非横空出世。早期的 Kimi 1.5 模型(见《Kimi k1.5: Scaling Reinforcement Learning with LLMs》论文)同样令人印象深刻。但其不幸与 DeepSeek R1 论文同日(1 月 22 日)发布。此外,据我所知,Kimi 1.5 权重从未公开。
因此,Kimi K2 团队很可能吸取了教训,在 DeepSeek R2 发布前便将 Kimi K2 作为开源模型共享。
9. GPT-OSS
OpenAI 发布了 gpt-oss-120b 和 gpt-oss-20b,这是其自 2019 年 GPT-2 以来的首批开源模型。鉴于 OpenAI 开源模型备受期待,我更新了本文以纳入它们。
在总结亮点前,先概述两个模型 gpt-oss-20b 和 gpt-oss-120b,如图 26 所示。
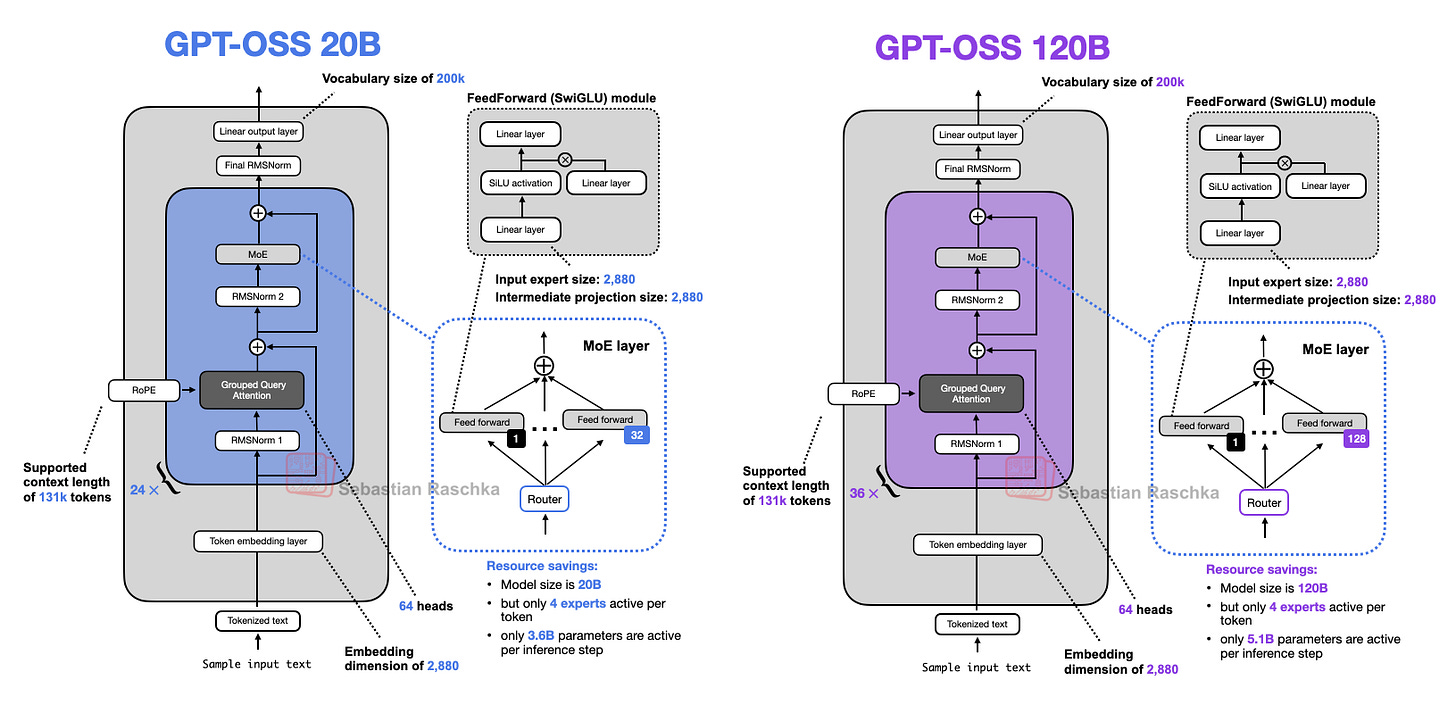
如上图所示,该架构包含我们此前讨论的其他架构中的所有熟悉组件。例如,下图将较小的 gpt-oss 架构与 Qwen3 30B-A3B(同样是 MoE 模型,活跃参数量相近:gpt-oss 为 36 亿,Qwen3 30B-A3B 为 33 亿)并列对比。
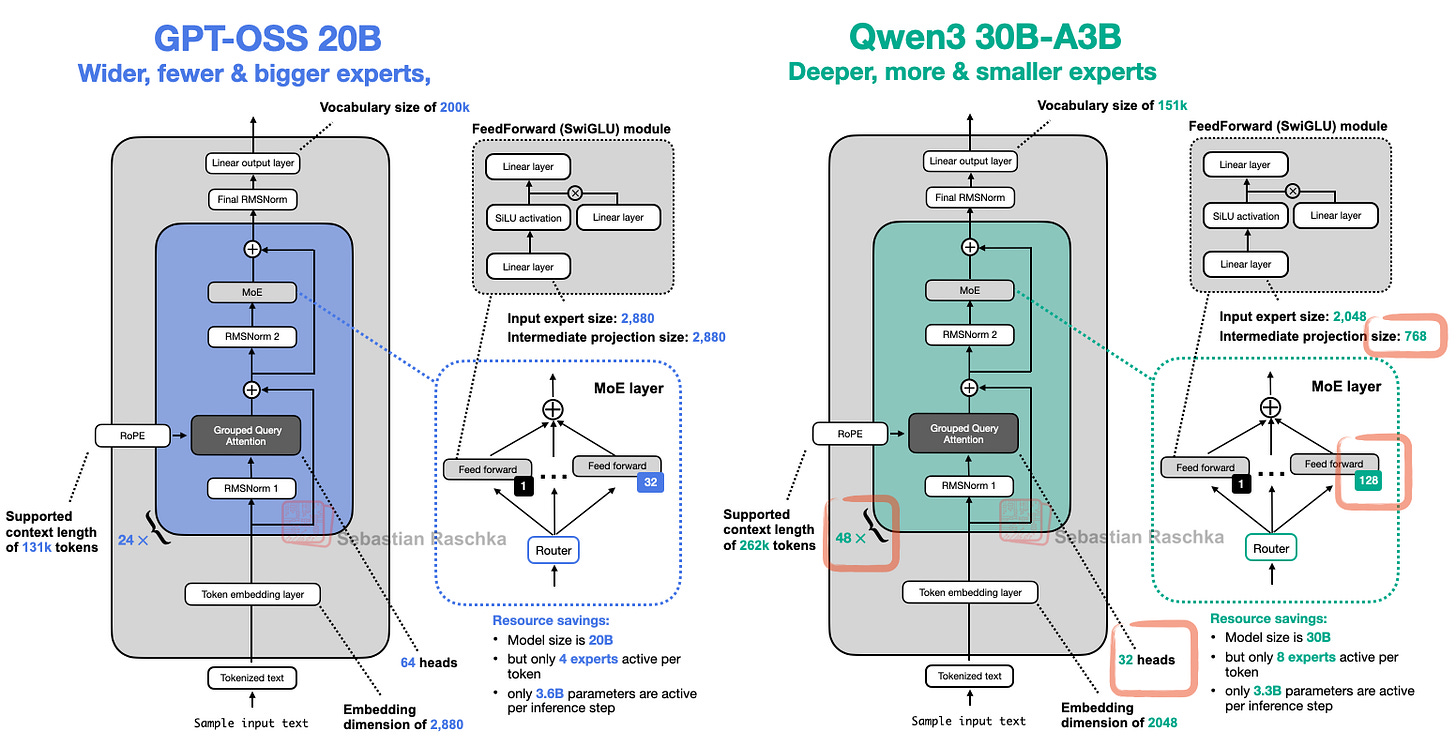
上图未展示的一个细节是,gpt-oss 使用滑动窗口注意力(类似 Gemma 3,但每两层使用一次,而非 5:1 比例)。
9.1 宽度与深度
上图显示 gpt-oss 与 Qwen3 使用相似组件。但仔细观察会发现,Qwen3 是更深的架构(48 个 Transformer 块 vs 24 个)。
而 gpt-oss 则是更宽的架构:
- 嵌入维度为 2880(而非 2048)
- 中间专家(前馈)投影维度也为 2880(而非 768)
还需注意,gpt-oss 的注意力头数是 Qwen3 的两倍,但这不直接增加模型宽度(宽度由嵌入维度决定)。
在固定参数量下,哪种方法更具优势?一般而言,更深模型更具灵活性,但因梯度爆炸/消失问题更难训练(RMSNorm 和残差连接旨在缓解此问题)。
更宽架构的优势在于推理更快(每秒 token 吞吐量更高),因并行化更好,但内存成本更高。
关于建模性能,据我所知,尚无良好的同参数量、同数据集的对比研究(Gemma 2 论文中的消融研究除外(表 9))。该研究发现,对于 90 亿参数架构,更宽设置略优于更深设置:在 4 个基准上,更宽模型平均得分为 52.0,更深模型为 50.8。
9.2 少而大的专家 vs 多而小的专家
值得注意的是 gpt-oss 的专家数量 surprisingly 少(32 个而非 128 个),且每 token 仅激活 4 个(而非 8 个)。但每个专家规模远大于 Qwen3 的专家。
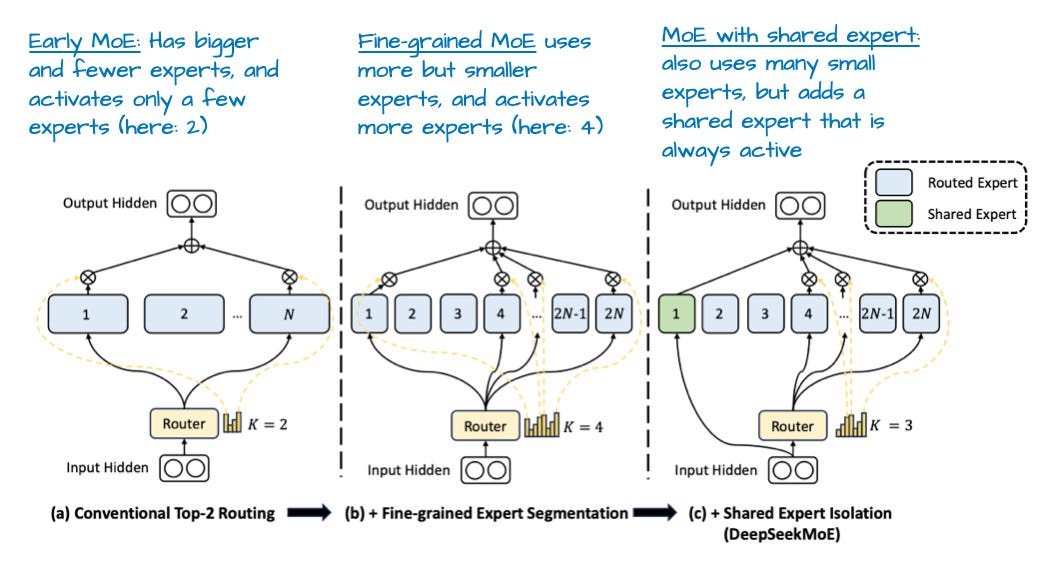
这很有趣,因为近期趋势(如 DeepSeekMoE 论文所示)指向更多、更小的专家更有利。在总参数量固定下,这一变化如 DeepSeekMoE 论文图 28 所示。
这很有趣,因为最近的趋势和发展都指向更多、更小的模型是有益的。在总参数量不变的情况下,这种变化在 DeepSeekMoE 论文的下图 28 中得到了很好的说明。
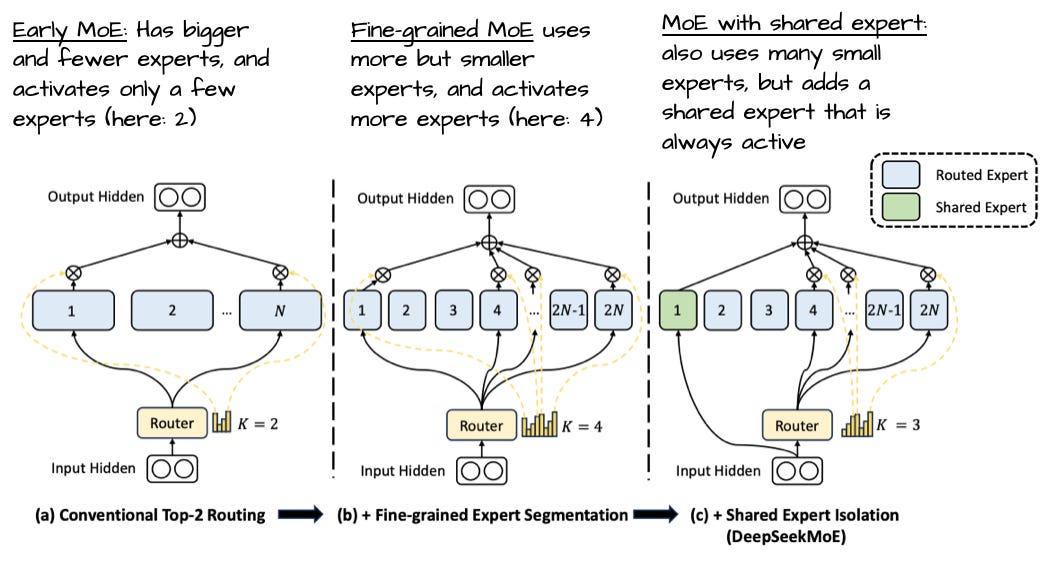
值得注意的是,与 DeepSeek 模型不同,gpt-oss 和 Qwen3 均未使用共享专家。
9.3 注意力偏置(Bias)和注意力汇点(Attention Sinks)
gpt-oss 和 Qwen3 均使用分组查询注意力。主要区别在于 gpt-oss 在每第二层通过滑动窗口注意力限制上下文长度(如前所述)。
但有一个细节引起了我的注意:gpt-oss 似乎为注意力权重使用了偏置单元(bias units),如下图所示。
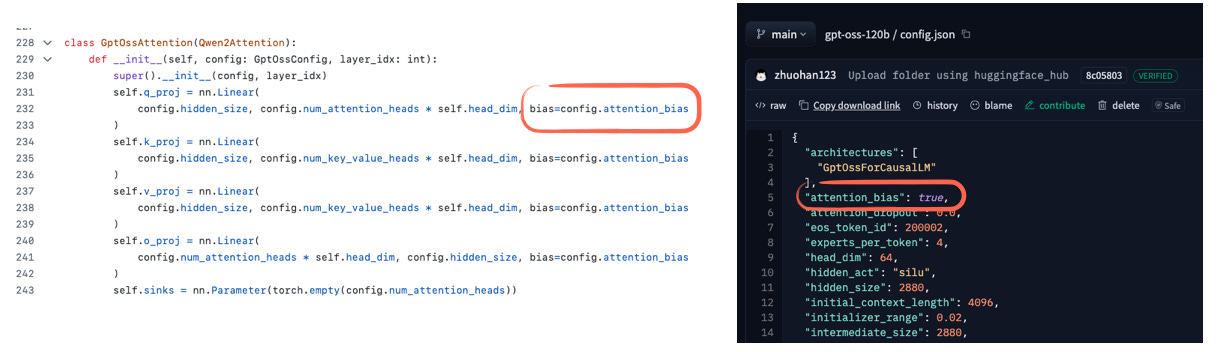
图gpt-oss 模型在注意力层中使用偏置单元。代码示例见此处。
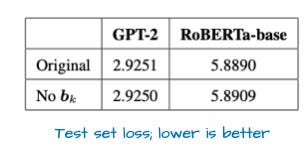
自 GPT-2 时代以来,我再未见过这些偏置单元,它们通常被视为冗余。事实上,近期一篇论文从数学上证明了这一点(至少对键变换 k_proj 成立)。实证结果也显示,有无偏置单元差异甚微(见下图)。
你可能还注意到上图代码截图中 sinks 的定义。一般而言,注意力汇聚点是置于序列开头的特殊“始终被关注”token,用于稳定注意力(尤其在长上下文场景中)。即当上下文很长时,开头的这个特殊 token 仍会被关注,并可学习存储关于整个序列的通用信息。(我认为最初由《Efficient Streaming Language Models with Attention Sinks》论文提出。)
在 gpt-oss 实现中,注意力汇聚点并非输入序列中的实际 token。而是作为每头学习的偏置 logits 附加到注意力分数上(下图)。目标与前述注意力汇聚点相同,但无需修改分词后的输入。
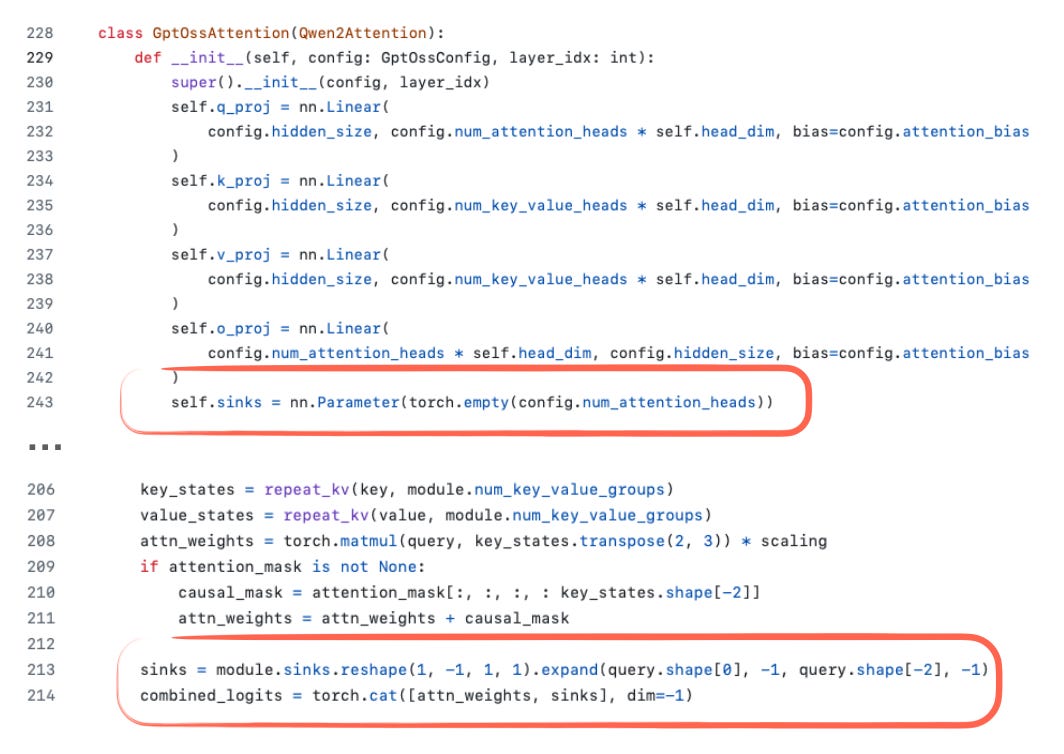
基于 Hugging Face 的代码此处。
10. Grok 2.5
Grok 2.5 是 xAI 去年的旗舰生产模型。此前讨论的所有模型均为从一开始就发布的开源模型。例如,gpt-oss 很可能并非 GPT-4 的开源克隆,而是专为开源社区训练的定制模型。
通过 Grok 2.5,我们得以罕见地一窥真实生产系统(尽管是去年的)。
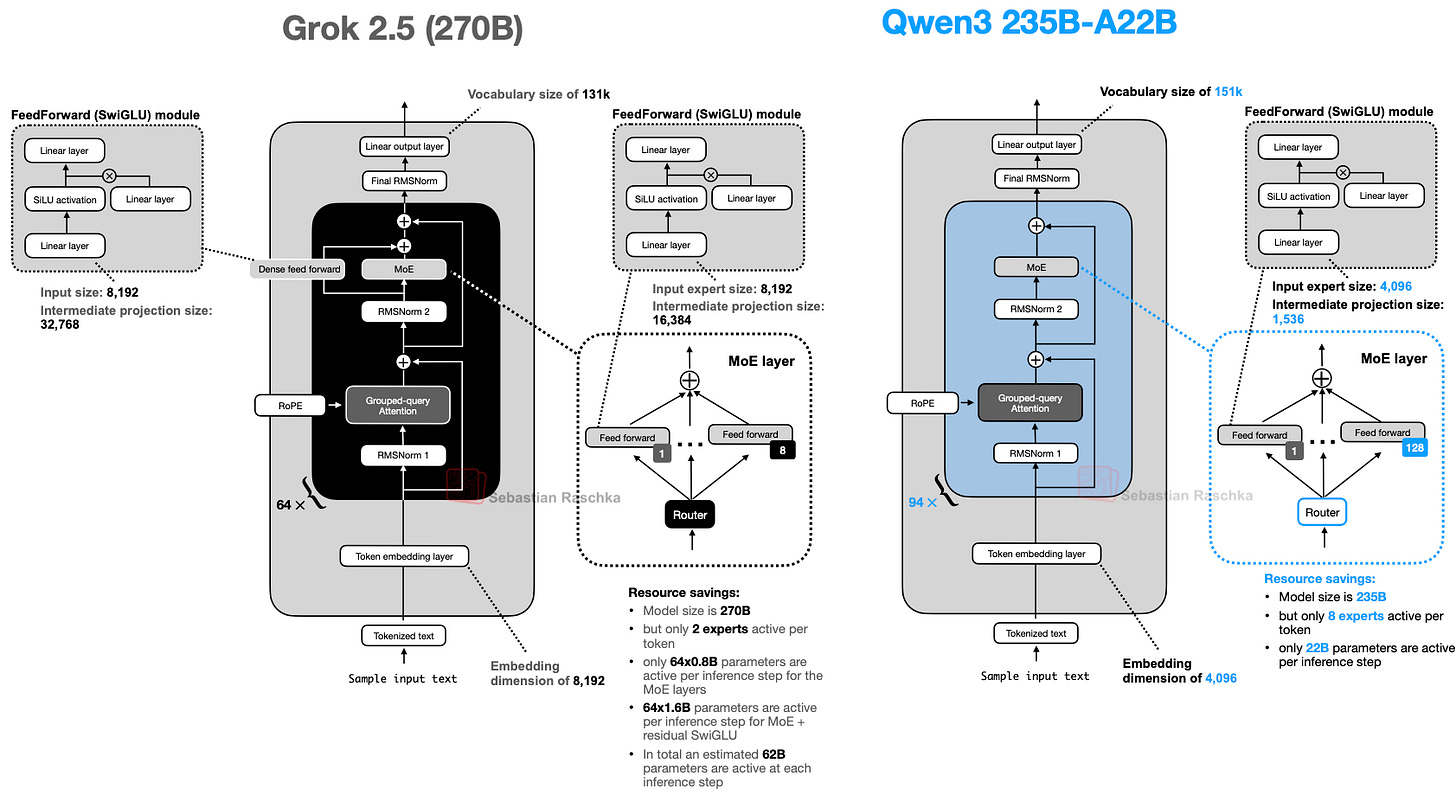
架构上,Grok 2.5 整体相当标准(下图 ),但有几个值得注意的细节。
例如,Grok 2.5 使用少量大型专家(8 个),这反映了较旧的趋势。如前所述,近期设计(如 DeepSeekMoE 论文)更倾向大量小型专家(Qwen3 也如此)。
另一有趣选择是使用了相当于共享专家的组件。如图左侧所示的额外 SwiGLU 模块充当始终开启的共享专家。它与经典共享专家设计不完全相同(其中间维度翻倍),但理念一致。( Qwen3 省略共享专家很有趣,且期待 Qwen4 及后续模型是否会改变。)
11. GLM-4.5
GLM-4.5 是今年的另一个重要发布。它是一款指令/推理混合模型,类似 Qwen3,但针对函数调用和智能体(agent)场景进行了更优优化。
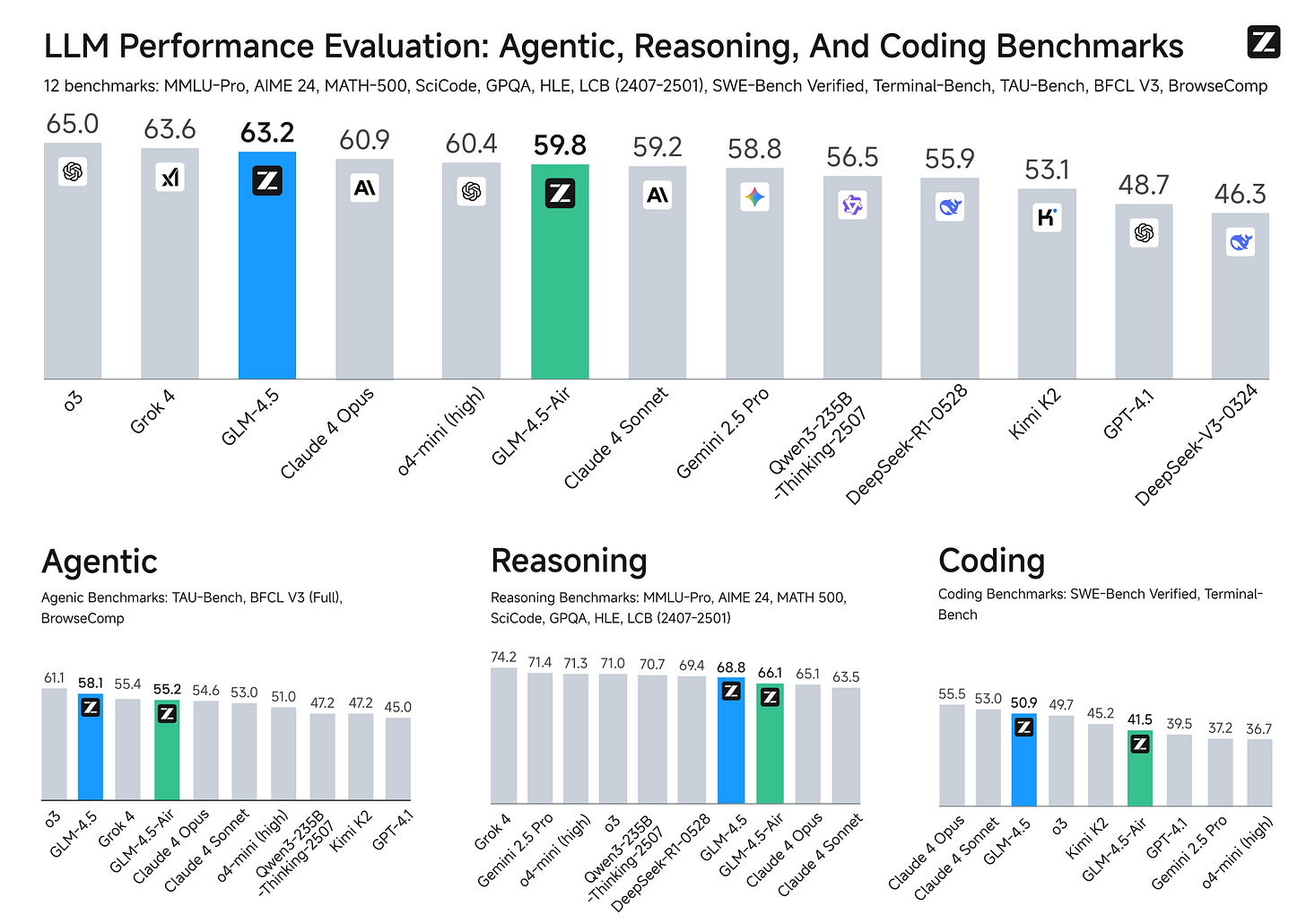
图来自官方 GitHub 仓库 https://github.com/zai-org/GLM-4.5 的 GLM-4.5 基准测试。
GLM-4.5 提供两个变体。旗舰 3550 亿参数模型在 12 个基准上平均超越 Claude 4 Opus,仅略逊于 OpenAI o3 和 xAI Grok 4。还有更紧凑的 1060 亿参数版本 GLM-4.5-Air,性能仅略低于 3550 亿模型。
下图将 3550 亿参数的架构与 Qwen3 进行了比较。
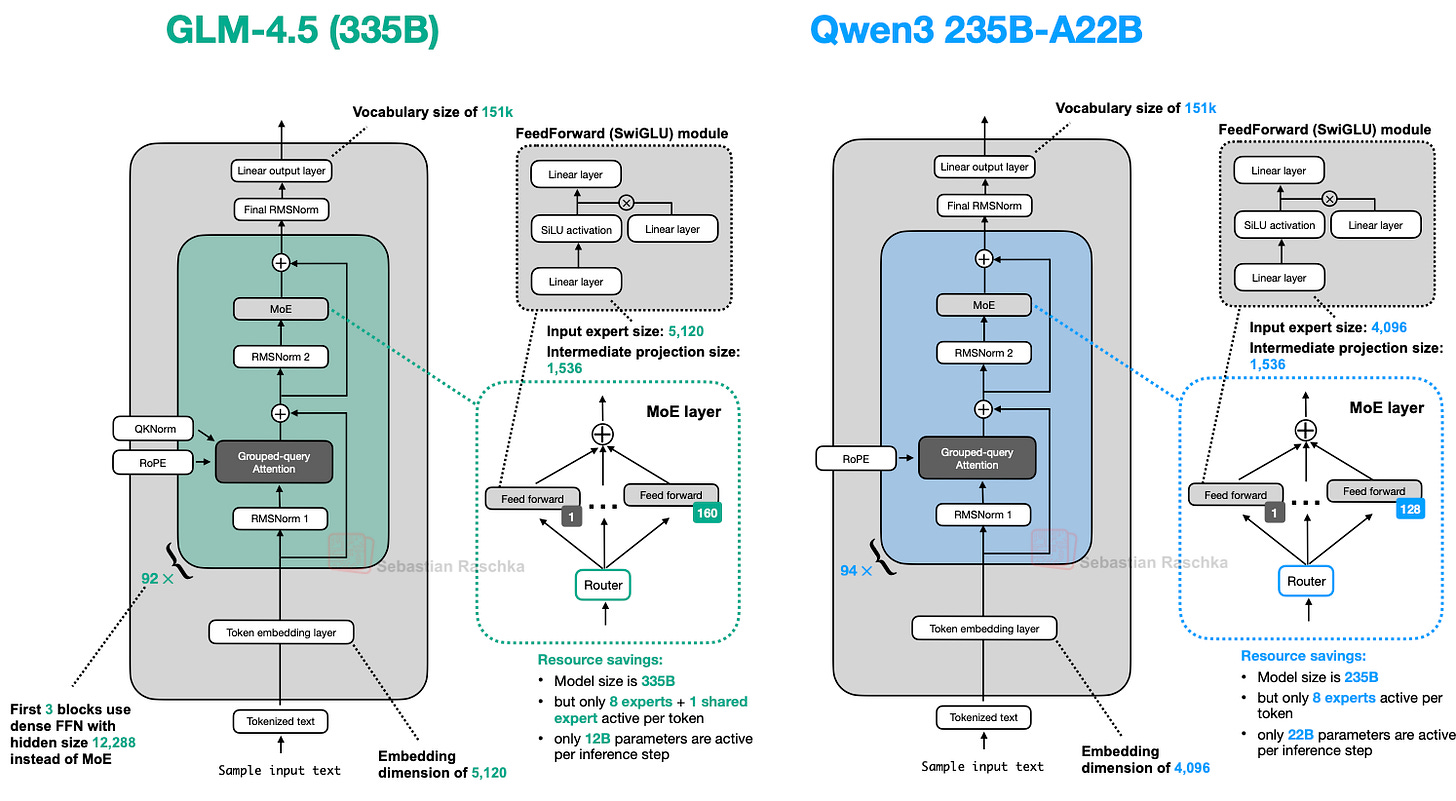
两者设计大体相似,但 GLM-4.5 采纳了 DeepSeek V3 首创的结构选择:3 个稠密层位于 MoE 块之前。为何如此?在大型 MoE 系统中,以若干稠密层开头可提升收敛稳定性与整体性能。若立即引入 MoE 路由,稀疏专家选择的不稳定性可能干扰早期句法和语义特征提取。因此,保持初始层稠密可确保模型在路由决策开始塑造高层处理前,形成稳定的低层表示。
此外,GLM-4.5 使用了类似 DeepSeek-V3 的共享专家(与 Qwen3 不同)。
(有趣的是,GLM-4.5 也保留了 GPT-2 和 gpt-oss 使用的注意力偏置机制。)
12. Qwen3-Next
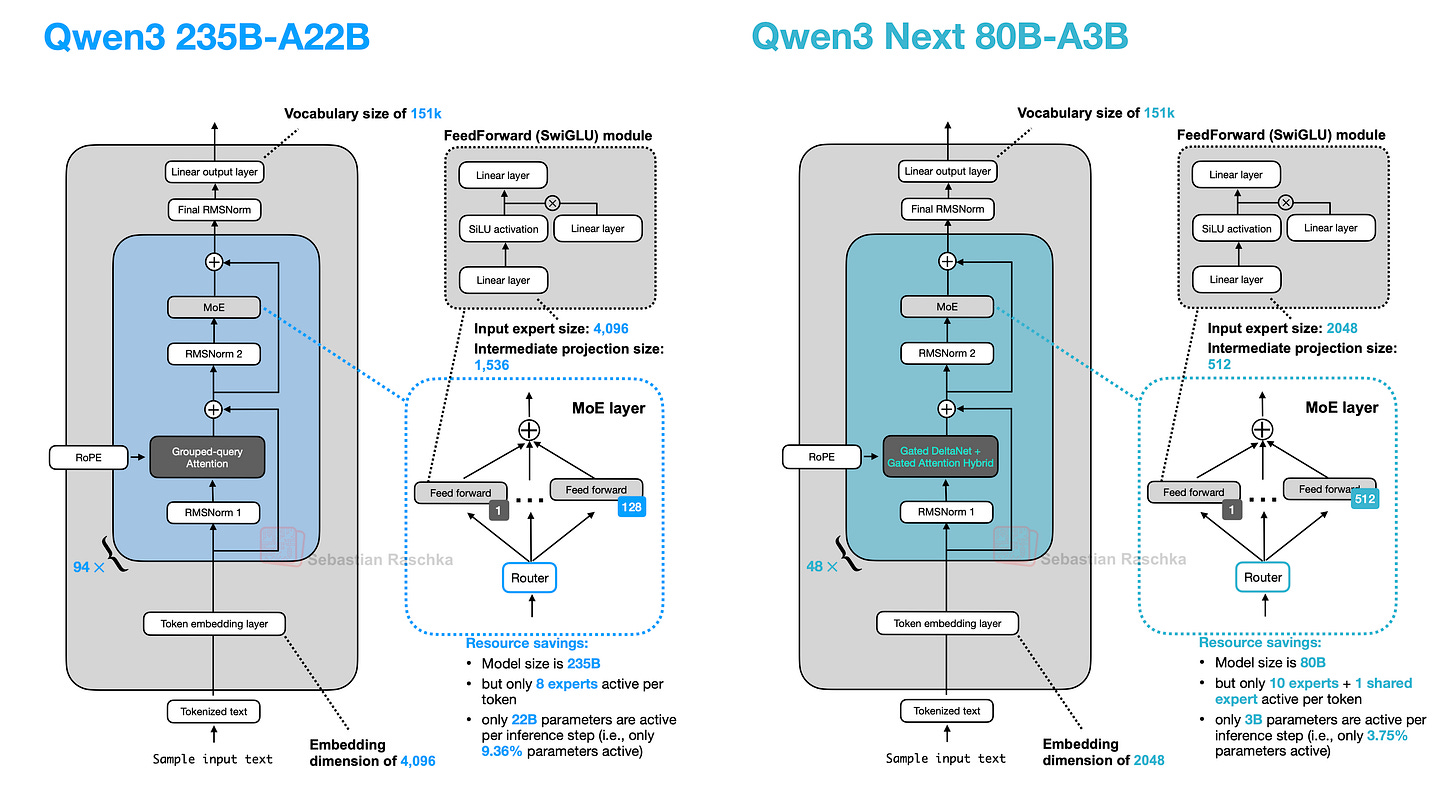
2025 年 9 月 11 日,Qwen3 团队发布了 Qwen3 Next 80B-A3B(下图),提供 Instruct 和 Thinking 两种变体。尽管其设计基于前文讨论的 Qwen3 架构,将其作为独立条目列出,以保持图编号一致并突出其设计变更。
12.1 专家规模和数量
新 Qwen3 Next 架构的突出之处在于:尽管比前代 235B-A22B 模型小 3 倍(下图 ),却引入了四倍数量的专家,甚至增加了共享专家。这两项设计选择(高专家数量和包含共享专家)正是所强调的未来方向。
12.2 门控 DeltaNet + 门控注意力混合机制
另一亮点是其用 门控 DeltaNet + 门控注意力混合机制 替代了常规注意力机制,这有助于在内存使用方面支持原生 262k token 上下文长度(前代 235B-A22B 模型原生支持 32k,通过 YaRN 缩放支持 131k)。
那么,这种新混合注意力如何工作?与分组查询注意力(GQA)(仍为标准缩放点积注意力,通过在查询头组间共享 K/V 以减少 KV 缓存大小和内存带宽,但其解码成本和缓存仍随序列长度增长)不同,其混合机制以 3:1 的比例混合 门控 DeltaNet 块与 门控注意力 块,如下图所示。
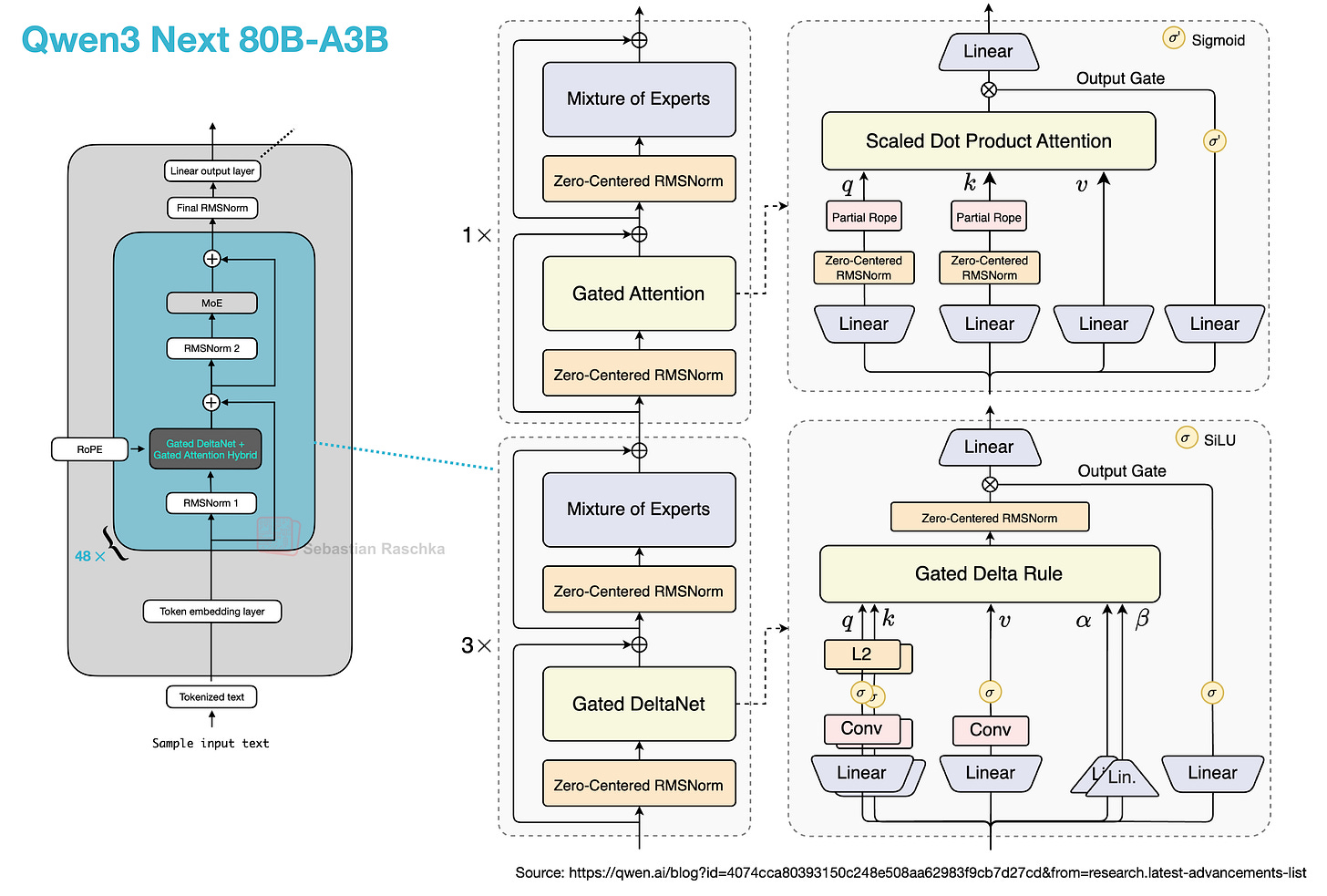
门控 DeltaNet + 门控注意力混合机制。请注意,它们以 3:1 的比例排列,意味着 3 个带门控 DeltaNet 的 Transformer 模块后跟着 1 个带门控注意力的 Transformer 模块。右侧子图来自 Qwen3 官方博客:https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list
我们可以将门控注意力块视为可与 GQA 一起使用的标准缩放点积注意力,但增加了若干调整。门控注意力 与普通 GQA 块的主要区别在于:
- 输出门控(通常为逐通道的 sigmoid 控制),在将注意力结果加回残差前对其进行缩放;
- QKNorm 使用零中心 RMSNorm,而非标准 RMSNorm;
- 部分 RoPE(仅在部分维度上应用)。
这些本质上只是对 GQA 的稳定性调整。
而门控 DeltaNet 则是更显著的改变。在 DeltaNet 块中,q、k、v 和两个门控(α, β)由线性和轻量卷积层生成,并通过归一化,该层用快速权重 delta 规则 更新替代了注意力。
但其权衡在于,DeltaNet 的内容检索精度低于完整注意力,因此保留了一个门控注意力层。
鉴于注意力计算复杂度随序列长度平方增长,引入 DeltaNet 组件旨在提升内存效率。在“线性时间、无缓存”家族中,DeltaNet 块本质上是 Mamba 的替代方案。Mamba 通过学习的状态空间滤波器(本质上是随时间变化的动态卷积)维护状态。DeltaNet 则维护一个由 α 和 β 更新的微型快速权重内存,并用 q 读取它,小卷积仅用于辅助生成 q、k、v、α、β。
12.3 多词元预测 (MTP)
上述两小节描述了两项面向效率的设计决策。好事成三,Qwen3 还增加了另一项技术:多 token 预测(Multi-Token Prediction, MTP)。【多token和多词元表达意思一致】
多 token 预测训练 LLM 在每一步预测多个未来 token,而非单个。此处,在每个位置 t,小型额外头(线性层)输出 t+1...t+k 的 logits,并对这些偏移量的交叉熵损失求和(MTP 论文 推荐 k=4)。这一额外信号加速了训练,推理时仍可逐 token 进行。但额外头可用于推测性多 token 解码,Qwen3-Next 似乎是这么做的,尽管细节仍较模糊:
Qwen3-Next 引入了原生的多词元预测(MTP)机制,这不仅产生了一个对推测解码具有高接受率的 MTP 模块,而且还增强了整体性能。此外,Qwen3-Next 特别优化了 MTP 的多步推理性能,通过保持训练和推理一致性的多步训练,进一步提高了推测解码在真实场景中的接受率。
来源:Qwen3-Next 博客文章
13. MiniMax-M2
最近,开源权重 LLM 的开发者分享了他们为效率优化的核心架构的变体。一个例子是 Qwen3-Next(见上一节),它用一个快速的门控 DeltaNet 模块替换了一些全注意力模块。另一个例子是 DeepSeek V3.2,它使用稀疏注意力,这是一种线性注意力的变体,用一些建模性能换取了计算性能的提升。
现在,MiniMax-M1 属于与上述模型类似,因为它使用了一种线性注意力的变体(闪电注意力),比常规(全)注意力提供了更高的效率。新的 MiniMax-M2 版本目前被认为是最好的开源权重模型(根据基准性能)。
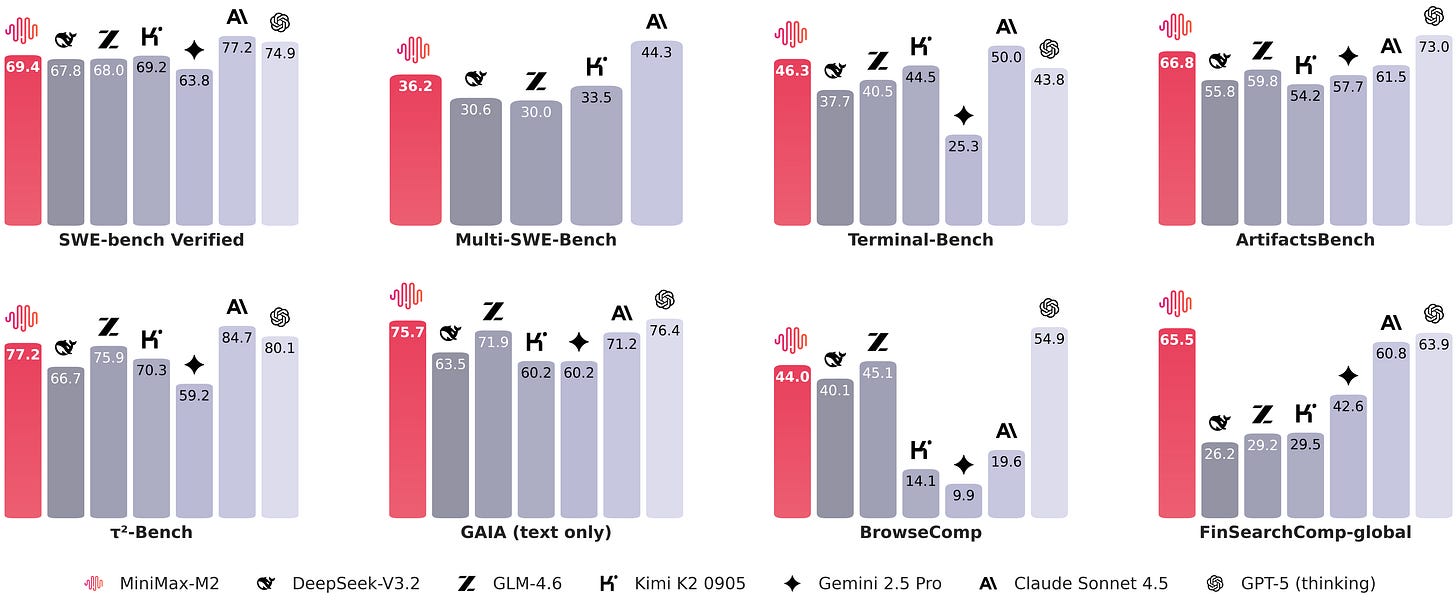
图片来自官方模型中心发布 readme 文件。
如下面的概览图所示,MiniMax-M2 与其他解码器风格的 Transformer LLM 分组在一起,因为它没有使用 MiniMax-M1 中提出的高效闪电注意力变体。相反,开发者们回归使用了全注意力,很可能是为了提高建模(和基准)性能。
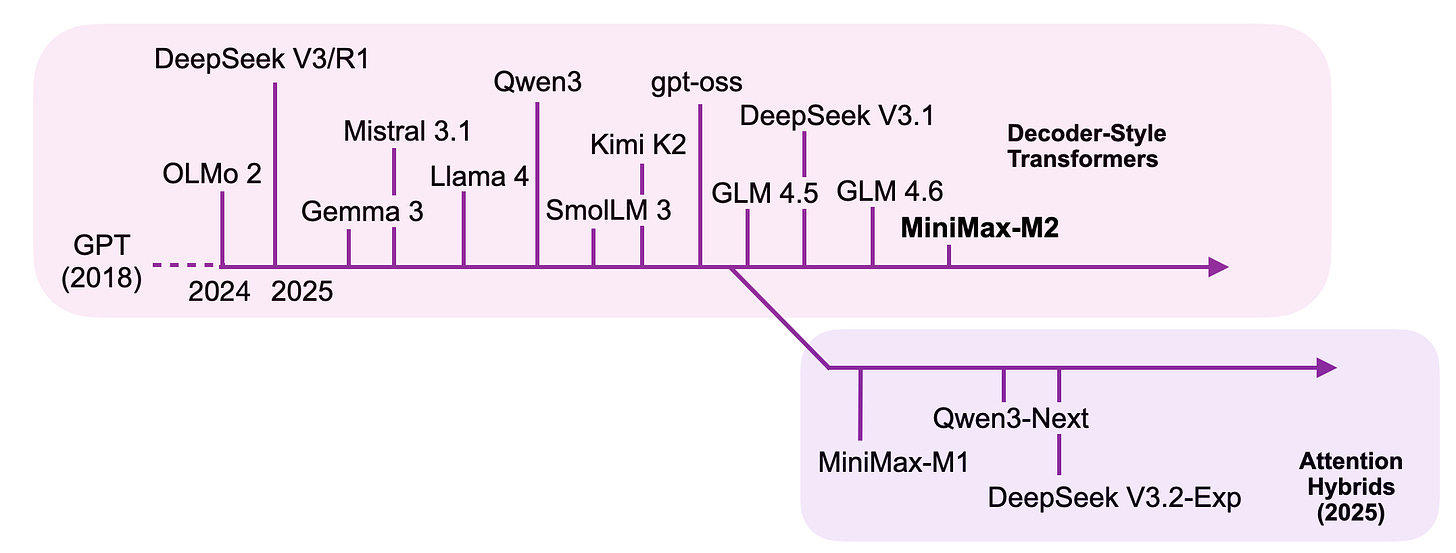
本文涵盖的主要 LLM 的时间线,旁边是一些注意力混合模型,它们构成了更高效的替代方案,用一些建模性能换取了效率的提升。
总体而言,MiniMax-M2 与 Qwen3 惊人地相似。除了改变层数、大小等之外,它总体上使用了相同的组件。
13.1 逐层 QK-Norm
这里也许一个值得注意的亮点是,MiniMax-M2 使用了一种所谓的“逐层”(per_layer)QK-Norm,而不是常规的 QK-Norm。仔细查看代码会发现,它在注意力机制内部是这样实现的:
self.q_norm = MiniMaxText01RMSNormTP(self.head_dim * self.total_num_heads, eps=...)self.k_norm = MiniMaxText01RMSNormTP(self.head_dim * self.total_num_kv_heads, eps=...)
在这里,hidden_size 等于连接后的头(num_heads * head_dim),所以 RMSNorm 的缩放向量对每个头(以及每个头维度)都有不同的参数。
所以,“per_layer”意味着 RMSNorm(用于 QK-Norm,如前所述)在每个 Transformer 模块中定义(与常规 QK-Norm 一样),但此外,它不是在注意力头之间重用,而是每个注意力头都有一个独特的 QK-Norm。
模型配置文件还包括一个滑动窗口注意力设置(类似于上文中的 Gemma 3),但是,就像在 Mistral 3.1 中一样,它默认是禁用的。
除此之外,除了逐层 QK-Norm,该架构与 Qwen3 非常相似,如下图所示。
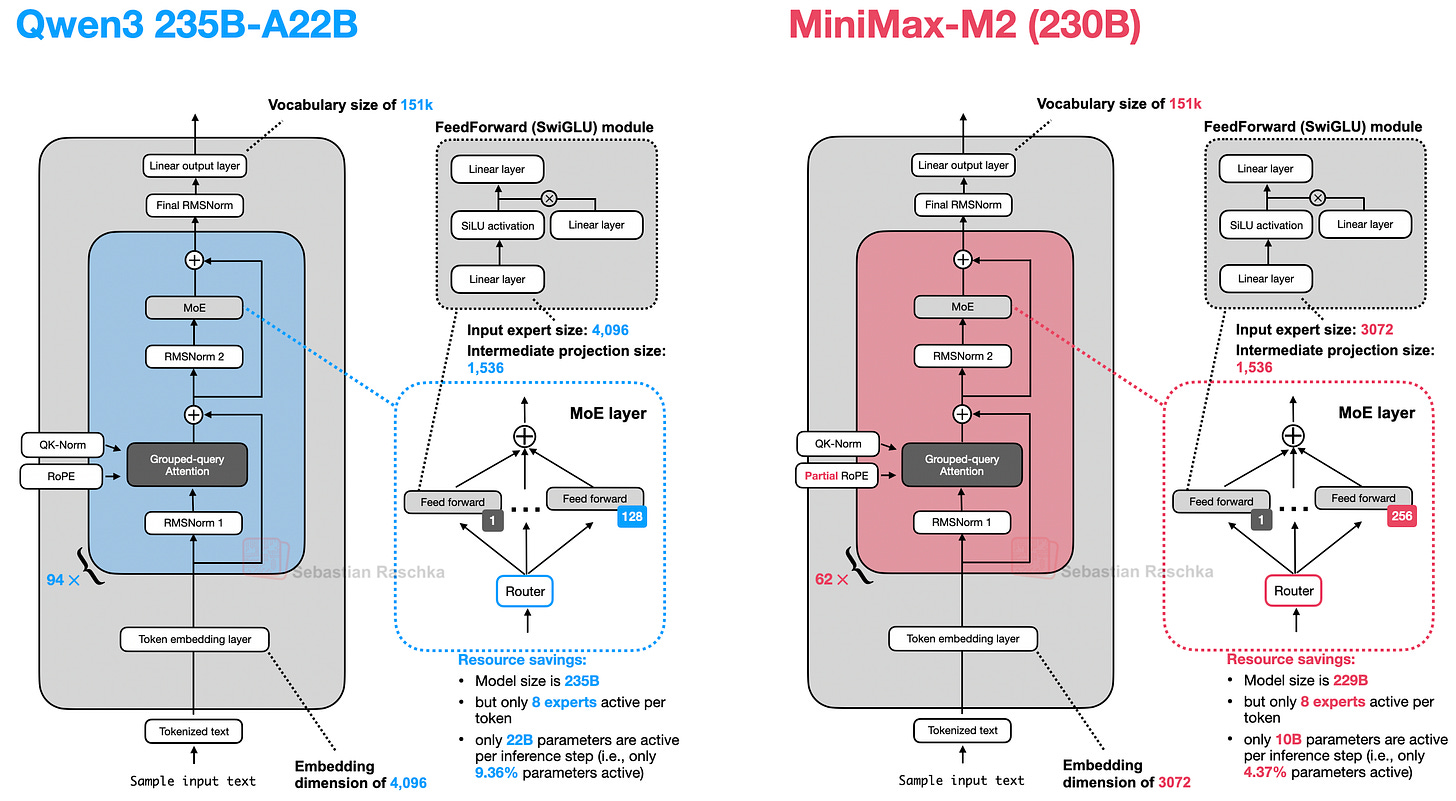
13.2 MoE 稀疏度
其他有趣的细节,如下图所示,包括他们不使用共享专家(类似于 Qwen3,但与 Qwen3-Next 不同)。如前所述,共享专家是有用的,因为它们减少了其他专家之间的冗余。
此外,从上图可以明显看出,MiniMax-M2 的“稀疏度”是 Qwen3 的两倍。也就是说,在与 Qwen3 235B-A22B 大致相同的规模下,MiniMax-M2 每个词元只有 100 亿而不是 220 亿的激活专家(也就是说,在 MiniMax-M2 的每个推理步骤中使用了 4.37% 的参数,而 Qwen3 使用了 9.36% 的激活词元)。
13.3 部分 RoPE
最后,与 MiniMax-M1 类似,MiniMax-M2 在注意力模块内部使用“部分”RoPE 而不是常规 RoPE 来编码位置信息。与常规 RoPE 类似,旋转是在应用 QK-Norm 之后应用于查询和键的。
这里的部分 RoPE(Partial RoPE) 意味着只有每个头的前 rotary_dim 个通道获得旋转位置编码,而剩下的 head_dim - rotary_dim 个通道保持不变。
在官方 M1 的 README 文件中,开发者提到:
旋转位置编码(RoPE)应用于一半的注意力头维度,基频为 10,000,000
我们可以将其想象如下:
Full RoPE: [r r r r r r r r]
Partial RoPE: [r r r r — — — —]
在上面的概念性插图中,“r”表示被旋转(位置编码)的维度,而破折号是未触及的维度。
这有什么意义呢?在 M1 论文中,开发者表示:
…在 softmax 注意力维度的一半上实现 RoPE,可以在不降低性能的情况下实现长度外推。
活词元)。
13.3 部分 RoPE
最后,与 MiniMax-M1 类似,MiniMax-M2 在注意力模块内部使用“部分”RoPE 而不是常规 RoPE 来编码位置信息。与常规 RoPE 类似,旋转是在应用 QK-Norm 之后应用于查询和键的。
这里的部分 RoPE(Partial RoPE) 意味着只有每个头的前 rotary_dim 个通道获得旋转位置编码,而剩下的 head_dim - rotary_dim 个通道保持不变。
在官方 M1 的 README 文件中,开发者提到:
旋转位置编码(RoPE)应用于一半的注意力头维度,基频为 10,000,000
我们可以将其想象如下:
Full RoPE: [r r r r r r r r]
Partial RoPE: [r r r r — — — —]
在上面的概念性插图中,“r”表示被旋转(位置编码)的维度,而破折号是未触及的维度。
这有什么意义呢?在 M1 论文中,开发者表示:
…在 softmax 注意力维度的一半上实现 RoPE,可以在不降低性能的情况下实现长度外推。
我的推测是,这可以防止对长序列,特别是那些比训练数据集中最长文档还要长的序列,进行“过度”旋转。也就是说,这里的理由可能是,没有旋转比一个模型在训练中从未见过的“坏”或“过于极端”的旋转要好。