RAG拓展、变体、增强版(三)
概述
不管是工程届还是学术届,对RAG的研究过于火热,之前整理过几篇:
- RAG概述
- RAG拓展、变体、增强版(一)
- RAG拓展、变体、增强版(二)
本文继续汇总。
Router
Router:模型路由,应用程序可使用不同模型,来响应不同类型Query,好处:
- 对于特定的问题,使用更专业的模型,提高响应质量:比如一个模型专门用于排除技术故障,另一个专门用于处理用户问答。专业化的模型可能比通用模型表现得更好;
- 节省成本:将简单查询,路由到更便宜的小模型如
qwen2.5-14b-instruct-1m,将复杂问题路由到更贵的大模型如qwen3-max。
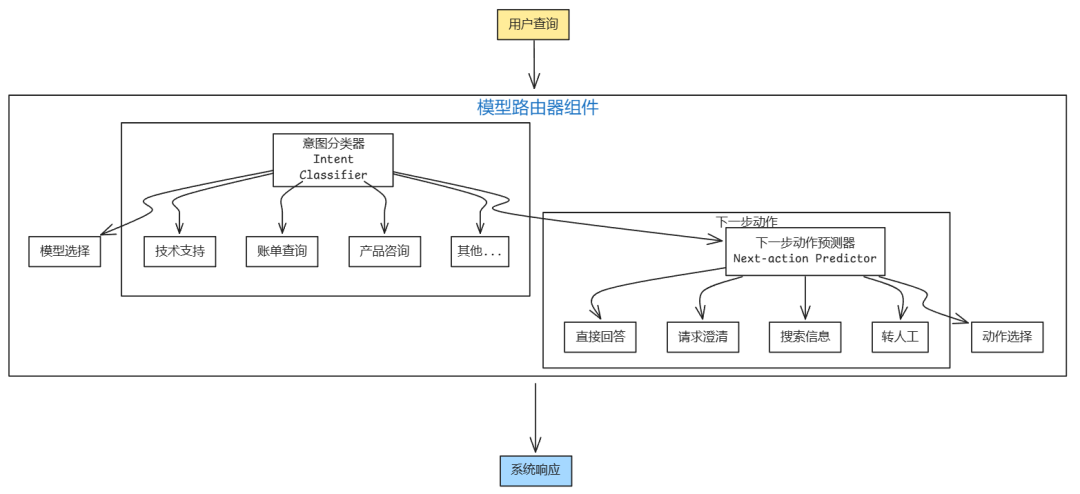
Router通常包含一个意图分类器(intent classifier),用于预测用户意图;根据预测的意图,query会被路由到适当的解决方案。
意图分类器还可防止超出范围的对话,可使用意图分类器来判断查询是否超出范围。若查询被认为不适当,聊天机器人可使用预设的回复礼貌拒绝,而不会浪费大模型的API调用。
如果系统可以访问多个操作,Router可以通过内置下一步操作预测器(next-action predictor)来帮助系统决定下一步要采取什么行动。尤其是当查询模糊时,可以请求澄清。
Intent Classifier和Next-action Predictor可以是通用模型或专用分类模型。专用分类模型一般比通用模型小得多而且更快,这样系统就可以使用多个这样的小模型,而不会产生较大的额外延迟和成本。
将查询路由到具有不同上下文限制的模型时,可能需要相应地调整查询的上下文。考虑1000 个 token 的查询,给到了一个只具有 4000 token 上下文限制的模型,而系统检索后带来了 8000 个 token 的上下文。这时你需要选择截断查询的上下文以适应原定的模型,或是将查询路由到具有更大上下文的模型。
gateway
模型网关(model gateway)是一个中间层,用于确保组织以统一且安全的方式与不同的模型进行交互。其最基本的功能是使开发人员能够以标准方式访问不同模型——无论是私有化部署的模型还是通过云厂商通过API提供的模型。
模型网关的核心功能是访问控制和成本管理。只需要给用户提供模型网关的访问权限,而不是将组织的大模型API token(很容易泄露)分发给每个需要访问的人,从而创建一个集中、可控的访问点。
模型网关还可以实现细粒度的访问控制,指定哪些用户或应用程序可以访问哪些模型。此外,网关能监控和限制API调用的使用,防止滥用并有效管理成本。
模型网关也可以用来实现故障转移策略,以克服速率限制或API故障(常见问题)。当主要API不可用时,网关可以将请求路由到替代模型,在短暂等待后重试,或以其他方式处理故障。这确保了应用程序可以平稳运行,不会中断。
由于请求和响应已经通过网关流动,这是实现其他功能(如负载均衡、日志记录和分析)的好地方。一些网关服务甚至提供缓存和防护机制。
随着模型路由和网关的增加,RAG系统变得更加完善,生成、评分以及路由的功能都可以集成在模型网关中实现。与用于评分的模型一样,用于路由的模型一般要比用于生成的模型小。
UltraRAG
论文,OpenBMB组织开源(GitHub,1.7K Star,147 Fork)RAG系统,官网文档,项目主页。对OpenBMB感兴趣,可延伸阅读OpenBMB开源组织介绍。
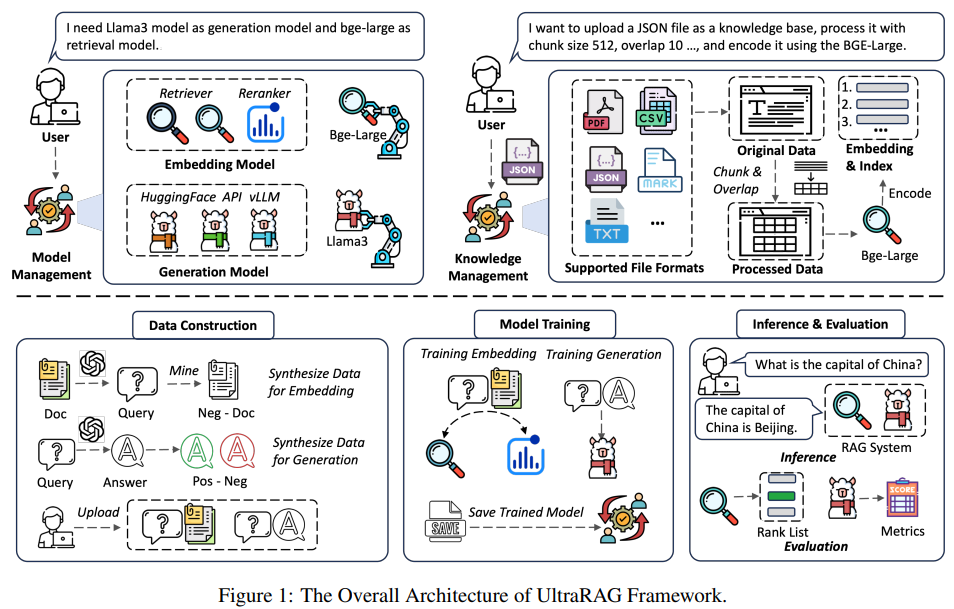
清华大学THUNLP实验室、东北大学NEUIR实验室、OpenBMB与AI9stars联合推出的UltraRAG 2.0,基于MCP的开源框架,让开发者只需编写YAML文件,就能实现串行、循环、条件分支等复杂逻辑,用几十行代码搭建出媲美DeepResearch、Search-o1的高性能RAG系统。
核心解决方案是组件化封装+灵活编排:
- 将检索、生成等核心功能封装为标准化MCP Server
- 通过函数级Tool接口实现模块"热插拔"
- 用YAML文件声明式定义复杂推理流程
三大核心亮点
低代码构建复杂Pipeline
无需深入编程细节,只需编写YAML配置文件,就能实现:
- 多轮迭代检索(如Search-o1的思维链+检索模式)
- 基于条件判断的动态流程切换
- 复杂推理链路的串行/并行调度
# 示例:简单的迭代检索生成流程
pipeline:- step: retriever.retrieve # 调用检索服务params:query: "{{input.query}}"top_k: 5output: context- loop: 3 # 迭代3轮steps:- step: generator.reflect # 生成反思params: context "{{context}}"output: reflection- step: retriever.retrieve # 基于反思二次检索params: query "{{reflection}}"output: new_context
开箱即用的生态支持
框架内置17个主流科研Benchmark,包括:
- 问答任务:NaturalQuestions、HotpotQA等
- 知识密集型任务:FEVER、TriviaQA等
- 长文本理解:Qasper、NarrativeQA等
同时提供大规模语料库支持:
- wiki-2018(2100万文档)
- wiki-2024
| 任务类型 | 数据集名称 | 原始数据数量 | 评测采样数量 |
|---|---|---|---|
| QA | NQ | 3,610 | 1,000 |
| QA | TriviaQA | 11,313 | 1,000 |
| QA | PopQA | 14,267 | 1,000 |
| QA | AmbigQA | 2,002 | 1,000 |
| QA | MarcoQA | 55,636 | 1,000 |
| QA | WebQuestions | 2,032 | 1,000 |
| Multi-hop QA | HotpotQA | 7,405 | 1,000 |
| Multi-hop QA | 2WikiMultiHopQA | 12,576 | 1,000 |
| Multi-hop QA | Musique | 2,417 | 1,000 |
| Multi-hop QA | Bamboogle | 125 | 125 |
| Multi-hop QA | StrategyQA | 2,290 | 1,000 |
| Multiple-choice | ARC | 3,548 | 1,000 |
| Multiple-choice | MMLU | 14,042 | 1,000 |
| Long-formQA | ASQA | 948 | 948 |
| Fact-verification | FEVER | 13,332 | 1,000 |
| Dialogue | WoW | 3,054 | 1,000 |
| Slot-filling | T-REx | 5,000 | 1000 |
无缝扩展与部署
通过模块化设计实现:
- 支持vLLM部署的大模型服务
- 兼容FAISS、LanceDB等向量数据库
- 自定义Server只需实现标准接口
部署LLM服务仅需一行命令:
# 启动vLLM服务
bash script/vllm_serve.sh --model lmsys/vicuna-7b-v1.5
部署
conda create -n ultrarag python=3.12
conda activate ultrarag
git clone https://github.com/OpenBMB/UltraRAG.git --depth 1
cd UltraRAG
pip install uv
uv pip install -e ".[all]"
ultrarag run examples/sayhello.yaml
Elysia
Weaviate开源,1.7K Star,231 Fork,文档,基于决策树架构调用工具来构建RAG的工具。
核心是决策智能体,可根据用户指令和上下文,基于决策树动态调用各种工具来完成任务。可根据数据内容和上下文动态选择最佳的数据展示方式,比如表格、卡片、对话、文档、图表等;自动化分析数据结构、生成摘要和元数据,更好的理解数据,以进行更有效的查询按需分块,查询时才对文档进行分块。与Weaviate深度集成,内置查询和操作Weaviate的工具,支持自定义工具。
Late Chunking
延迟分块,用于改进文本嵌入的质量。利用长上下文嵌入模型,在变换器模型之后和均值池化之前进行分块,从而捕获完整的上下文信息。与传统的朴素分块方法相比,延迟分块在各种检索任务中表现更优,且无需额外训练。
论文,Jina AI开源(GitHub)实现。
延迟分块是一种利用最近嵌入模型的长上下文输入窗口与大多数应用程序的最佳文本块相对较小的大小之间的差异的策略。这些模型支持更长的输入文本,例如jina-embeddings-v2-small支持8192个标记——大约十页标准文本——而最佳块大小通常要小得多,例如段落的大小。
输入
- 文本TTT:待处理的文本。
- 分块策略SSS:用于确定分块边界的策略(如固定大小边界、句子边界或语义句子边界)。
输出:块嵌入EEE,由每个块的嵌入向量组成的序列(e1,e2,...,en)(e_1,e_2,...,e_n)(e1,e2,...,en)。
具体步骤如下:
- 分块:使用分块策略SSS将文本TTT分块,得到分块序列(c1,...,cn)(c_1,...,c_n)(c1,...,cn);
- 标记化:将文本TTT标记化为一系列标记(tokens),得到标记ID序列(τ1,τ2,...,τm)(τ_1,τ_2,...,τ_m)(τ1,τ2,...,τm)和每个标记的字符长度序列(o1,o2,...,om)(o_1,o_2,...,o_m)(o1,o2,...,om)。
- 嵌入生成:使用嵌入模型对标记ID序列(τ1,τ2,...,τm)(τ_1,τ_2,...,τ_m)(τ1,τ2,...,τm)进行编码,生成每个标记的嵌入向量序列(ϑ1,…,ϑm)(\vartheta_1,\ldots,\vartheta_m)(ϑ1,…,ϑm)。
- 确定分块边界:
- 计算分块cic_ici的起始和结束字符位置
start_char和end_char; - 初始化
start_token和end_token为0; - 遍历标记序列(τ1,τ2,...,τm)(τ_1,τ_2,...,τ_m)(τ1,τ2,...,τm);
- 将
(start_token,end_token)添加到chunk_boundaries列表中; - 如果当前标记的字符长度ojo_joj加上之前的字符长度总和等于
start_char,则设置start_token为jjj; - 如果当前标记的字符长度ojo_joj加上之前的字符长度总和等于
end_char,则设置end_token为jjj; - 初始化一个空列表
chunk_boundaries用于存储分块边界; - 对于每个分块cic_ici:
- 计算分块cic_ici的起始和结束字符位置
- 均值池化:
- 对标记嵌入序列(ϑstart_token,…,ϑend_token)(\vartheta_{start\_token},\ldots,\vartheta_{end\_token})(ϑstart_token,…,ϑend_token)进行均值池化,生成该块的嵌入向量eie_iei;
- 将eie_iei添加到
embeddings列表中; - 初始化一个空列表
embeddings用于存储块嵌入; - 对于每个分块边界
(start_token,end_token);
- 返回块嵌入:返回块嵌入序列E=(e1,e2,...,en)E=(e_1,e_2,...,e_n)E=(e1,e2,...,en)。
长延迟分块(Long Late Chunking)
对于超过模型上下文长度的长文档,提出长延迟分块方法。
输入:
- 文本TTT:待处理的文本。
- 分块策略SSS:用于确定分块边界的策略(如固定大小边界、句子边界或语义句子边界)。
- 最大标记长度lmaxl_{max}lmax:每个宏块的最大标记数量。
- 重叠长度www:宏块之间的重叠标记数量。
输出:块嵌入EEE,由每个块的嵌入向量组成的序列(e1,e2,...,en)(e_1,e_2,...,e_n)(e1,e2,...,en)。
具体详细步骤:
- 分块:使用分块策略SSS将文本TTT分块,得到分块序列(c1,...,cn)(c_1,...,c_n)(c1,...,cn);
- 标记化:将文本TTT标记化为一系列标记(tokens),得到标记ID序列(τ1,τ2,...,τm)(τ_1,τ_2,...,τ_m)(τ1,τ2,...,τm)和每个标记的字符长度序列(o1,o2,...,om)(o_1,o_2,...,o_m)(o1,o2,...,om)。
- 检查标记数量:如果标记数量mmm小于等于最大标记长度lmaxl_{max}lmax,则直接使用延迟分块方法处理。
- 初始化变量:初始化变量iendi_{end}iend为lmaxl_{max}lmax,istarti_{start}istart为1,以及一个空列表
embeddings用于存储块嵌入。 - 处理宏块:
- 使用嵌入模型对标记ID序列(τistart,...,τiend)(τ_{i_{start}},...,τ_{i_{end}})(τistart,...,τiend)进行编码,生成每个标记的嵌入向量序列(ϑistart,...,ϑiend)(\vartheta_{i_{start}},...,\vartheta_{i_{end}})(ϑistart,...,ϑiend);
- 如果istarti_{start}istart为1,则将所有标记嵌入(ϑistart,...,ϑiend)(\vartheta_{i_{start}},...,\vartheta_{i_{end}})(ϑistart,...,ϑiend)添加到
embeddings列表中; - 否则,将重叠部分的标记嵌入(ϑistart+w,...,ϑiend)(\vartheta_{i_{start}+w},...,\vartheta_{i_{end}})(ϑistart+w,...,ϑiend)添加到
embeddings列表中; - 更新标记位置:istarti_{start}istart更新为iend+1i_{end}+1iend+1,iendi_{end}iend更新为min(iend+lmax−w,m)min(i_{end}+l_{max}-w,m)min(iend+lmax−w,m);
- 当iendi_{end}iend小于标记总数mmm时,执行以下步骤:
- 返回块嵌入序列E=(e1,e2,...,en)E=(e_1,e_2,...,e_n)E=(e1,e2,...,en)。
训练方法(Training Method)
旨在进一步提高延迟分块的检索准确性,基于跨度池化(Span Pooling)技术,通过训练模型将标注文本跨度中的相关信息编码到其标记嵌入中。
训练数据准备
训练数据由查询、相关文档和文档中相关跨度的标注组成。具体步骤如下:
- 数据收集:从数据集中收集查询、相关文档和文档中相关跨度的标注。
- 数据格式化:将数据格式化为元组(q,d,(start,end))(q,d,(start,end))(q,d,(start,end)),其中qqq是查询,ddd是相关文档,(start,end)(start,end)(start,end)是文档中相关跨度的标注。
使用两个数据集进行训练:
- FEVER:包含从维基百科中提取的文档,并标注文档中支持或反驳查询声明的相关句子。
- TriviaQA:包含从维基百科和网页中提取的文档,并标注文档中包含答案的相关短语。
训练过程包括以下几个关键步骤:
- 标记化:对文档进行标记化,生成标记序列;
- 输入:文档ddd
- 输出:标记ID序列(τ1,τ2,...,τm)(τ_1,τ_2,...,τ_m)(τ1,τ2,...,τm)和每个标记的字符长度序列(o1,o2,...,om)(o_1,o_2,...,o_m)(o1,o2,...,om)
- 嵌入生成:使用长上下文嵌入模型对文档的所有标记进行编码,生成每个标记的嵌入向量;
- 输入:标记ID序列(τ1,τ2,...,τm)(τ_1,τ_2,...,τ_m)(τ1,τ2,...,τm)
- 输出:标记嵌入向量序列(ϑ1,…,ϑm)(\vartheta_1,\ldots,\vartheta_m)(ϑ1,…,ϑm)
- 跨度池化:对标注跨度内的标记嵌入进行均值池化,生成文档嵌入;
- 输入:标记嵌入向量序列(ϑ1,…,ϑm)(\vartheta_1,\ldots,\vartheta_m)(ϑ1,…,ϑm)和标注跨度(start,end)(start,end)(start,end)
- 输出:文档嵌入yyy
- InfoNCE损失:使用InfoNCE损失进行训练,确保查询嵌入与相关文档嵌入的相似度高于与其他文档嵌入的相似度
- 输入:查询嵌入xxx和文档嵌入yyy
- 输出:InfoNCE损失LNCE\mathcal{L}_{\mathrm{NCE}}LNCE
训练超参数
- 模型:jina-embeddings-v3和jina-embeddings-v2-small-en
- 训练数据:FEVER和TriviaQA
- 批量大小:512
- 训练步数:500步
- 损失函数:InfoNCE损失
微调过程本身遵循Gunther et al.(2023)中描述的成对训练阶段,其中模型在文本对上使用InfoNCE损失进行训练,该损失定义在一批B=((x1,y1),...,(xk,yk))B=((x_1,y_1),...,(x_k,y_k))B=((x1,y1),...,(xk,yk))的kkk对上,并使用余弦相似度函数sss:LNCE(B):=−∑(xi,yi)∈Blnes(xi,yi)/τ∑i′=1kes(xi,yi′)/τ\mathcal{L}_{\mathrm{NCE}}(B) := - \sum_{(x_i, y_i) \in B} \ln \frac{e^{s(x_i, y_i)/\tau}}{\sum_{i'=1}^{k} e^{s(x_i, y_{i'})/\tau}}LNCE(B):=−(xi,yi)∈B∑ln∑i′=1kes(xi,yi′)/τes(xi,yi)/τ
在这里,查询向量xix_ixi通过通常的方式将嵌入模型应用于查询文本qiq_iqi获得。对于文档嵌入yiy_iyi,通过将模型应用于文档did_idi获得标记嵌入集ϑi,1,…,ϑi,n\vartheta_{i,1},\ldots,\vartheta_{i,n}ϑi,1,…,ϑi,n,并对跨度(start,end)(start,end)(start,end)内的标记嵌入执行均值池化操作,因此称为跨度池化。
文中使用双向版本的损失Lpairs\mathcal{L}_{pairs}Lpairs,其中B†=((y1,x1),...,(yk,xk))B^\dagger=((y_1,x_1),...,(y_k,x_k))B†=((y1,x1),...,(yk,xk))通过交换对的顺序从BBB获得:Lpairs(B):=LNCE(B)+LNCE(B†)\mathcal{L}_{\mathrm{pairs}}(B):=\mathcal{L}_{\mathrm{NCE}}(B)+\mathcal{L}_{\mathrm{NCE}}(B^\dagger)Lpairs(B):=LNCE(B)+LNCE(B†)
CoRAG
论文,微软推出Chain-of-RAG,

利用动态检索过程,使得模型能够:
- 逐步检索信息并进行调整;
- 根据需要重新制定查询;
- 自主决定需要多少次检索步骤。
三个组件:
- 生成检索链
- 在这些增强数据集上训练模型
- 调整测试时使用的计算资源:
- 调整最大检索步骤数
- 更改最佳 N 选取样本的检索链数量
- 修改树搜索的搜索深度和展开次数
使用拒绝采样方法来自动生成检索链
- 不是一次性检索所有信息,而是将搜索拆分为更小的步骤。
- 它生成子问题及其对应的子答案。
- 模型为每个子问题检索文档并提供答案,然后才进入下一步。
- 这一过程持续进行,直到答案正确或步骤耗尽。
- 最终,选择最有可能产生正确答案的最佳检索链。
训练:一旦 CoRAG 创建了自己的中间检索步骤,它会在这些增强数据集上微调 LLM,帮助模型同时学习执行三个任务:
- 预测下一个子问题(学习如何拆解复杂查询)
- 预测子答案(在每一步找到有用的信息)
- 预测最终答案(将所有信息整合起来)
ComoRAG
论文,GitHub,
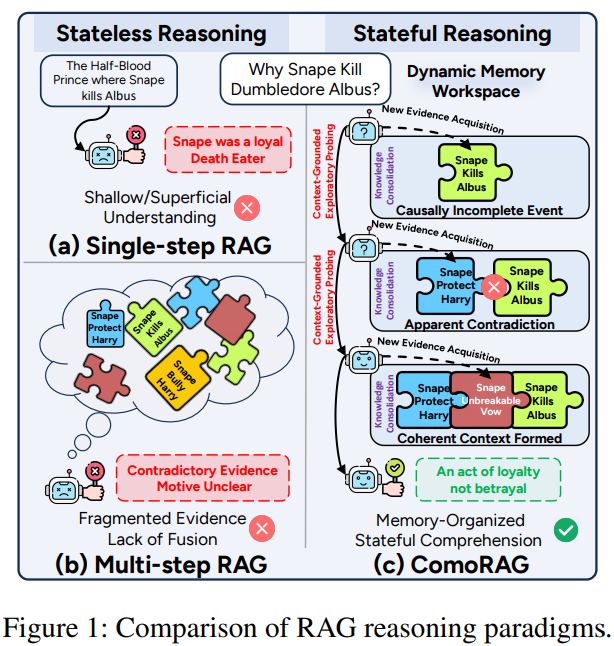
单步RAG和多步RAG均属于无状态推理(Stateless Reasoning)范畴,其推理过程不依赖于或无法有效利用先前的探索状态。ComoRAG则实现有状态推理(Stateful Reasoning),其推理状态是持续演化的。这种根本区别构成ComoRAG解决叙事理解挑战的理论基础。
叙事理解与多跳问答(Multi-hop Question Answering,QA)有着本质区别。多跳QA寻求在固定事实间建立静态路径,而叙事理解则需要持续构建和修订对情节、角色及其演变动机的全局心智模型。
ComoRAG的核心创新在于其认知启发的架构设计,该设计直接模仿前额叶皮层的功能机制,由三个概念支柱构成:层次化知识源、动态记忆工作区和元认知控制循环。
层次化知识源:三维度认知框架
ComoRAG首先构建一个层次化知识索引,从三个互补的认知维度建模原始文本,类似于PFC如何从大脑不同区域整合不同类型的记忆:
真实层(Veridical Layer):作为事实证据基础,真实层由直接的原始文本块组成,类似于人类记忆中对事实细节的精确回忆。为确保推理可追溯至源证据,系统指示LLM为每个文本块生成知识三元组(subject-predicate-object)。这些三元组参与每次检索,强化查询与对应文本块的匹配,已被证明能有效提升检索准确性(类似HippoRAG方法)。真实层为叙事理解提供了坚实的事实基础,是解决复杂问题的关键起点。
语义层(Semantic Layer):为捕捉超越长距离上下文依赖的主题和概念联系,语义层采用GMM驱动的聚类算法,递归总结语义相似的文本块,形成层次摘要树。这一设计借鉴了RAPTOR的工作,使框架能够检索超越表面层次的概念信息。语义层使系统能够理解抽象概念,而非仅停留在具体事件层面。
情节层(Episodic Layer):前两层提供了事实细节和高级概念的视角,但缺乏对叙事中至关重要的时序发展或情节进展的捕捉。情节层通过滑动窗口摘要机制重构情节线和故事弧线,捕获按时间线连续或因果相关事件的序列叙事发展。窗口大小根据文档长度动态调整:
- 对于短至中等长度的叙事(N≤200块):使用逐步增大的窗口尺寸(3、5、8和10),分别适用于最多20、50、100和200块的文档,目的是为较短上下文保留细节
- 对于长叙事(N>200):应用对数缩放函数,窗口大小计算为:W=min(20,max(10,⌊log2(N)×2⌋))W=\min\left(20,\max\left(10,\lfloor \log_2(N) \times 2 \rfloor \right)\right)W=min(20,max(10,⌊log2(N)×2⌋))
随后,将每个窗口中的文本块连接,由LLM生成简洁摘要,该摘要需保持时间顺序并识别关键事件和因果关系。
动态记忆工作区:状态式推理的核心
动态记忆工作区是ComoRAG实现状态式推理的核心,包含记忆单元,作为元认知调节进行连贯多步探索和推理的桥梁。
- 记忆单元的结构与功能:每个记忆单元mmm功能性地总结一次检索操作,表示为三元组:m=(p,Eptype,Cptype)m=(p,E_p^{type},C_p^{type})m=(p,Eptype,Cptype),其中ppp是触发此检索的探测查询;EptypeE_p^{type}Eptype是从单一知识层检索到的同质证据集(type∈{ver,sem,epi});CptypeC_p^{type}Cptype是由Comprehension Agent生成的合成线索,反映这些检索到的证据如何补充对原始查询qinitq_{init}qinit的理解。
- 记忆池的动态演化机制:记忆池通过嵌入编码整合历史记忆,为后续检索提供上下文感知的查询生成基础。当系统遇到推理阻塞时,记忆池允许系统回顾先前的探索,识别知识缺口,并生成新的探测查询。这种动态演化机制实现了叙事理解中所需的"动态记忆"特性,使系统能够像人类一样,随着新发现不断更新其对叙事的理解。
- 记忆单元的生成效率:在元认知过程中,生成的记忆单元数量遵循公式∣Mencode(t)∣=3×∣P(t)∣|M_{\mathrm{encode}}^{(t)}| = 3 \times |P^{(t)}|∣Mencode(t)∣=3×∣P(t)∣,即每个探测查询在三个知识层上生成三个记忆单元。这一设计保证系统在探索新证据的同时保持计算效率,避免过度冗余。
元认知控制循环:认知启发的推理引擎
元认知控制循环是ComoRAG的心脏,完全实现元认知调节的概念。由监管过程(Regulatory Process)和元认知过程(Metacognitive Process)组成,形成一个闭环的演化推理状态系统。
Regulatory Process:目标导向的规划:在推理循环开始时,如果前一步骤以失败告终,监管过程会被调用。核心操作Self-Probe由Regulation Agent(πprobeπ_{probe}πprobe)协调,其决策基于对先前失败的反思,探索更多必要背景或相关信息。Self-Probe输入包括:终极目标qinitq_{init}qinit、到上一步结束的完整探索探查历史Phistt−1P_{hist}^{t-1}Phistt−1,以及导致失败的即时知识缺口{C}t−1\{C\}^{t-1}{C}t−1。其输出PtP^tPt是当前循环的新战略检索探针集:P(t)=πprobe(qinit,Phist(t−1),{C}(t−1))P^{(t)} = \pi_{\mathrm{probe}}(q_{\mathrm{init}}, P_{\mathrm{hist}}^{(t-1)}, \{C\}^{(t-1)})P(t)=πprobe(qinit,Phist(t−1),{C}(t−1))
探测查询的明确定义:探测查询是系统为突破推理阻塞而生成的探索性查询,以便获取补充信息。与传统RAG中静态的查询不同,探测查询是动态生成的,具有语义差异化与互补覆盖特性,针对角色、事件、对象和地点等不同信息维度生成。
Metacognitive Process:记忆驱动的推理:元认知过程接收当前循环的新探针PtP^tPt,执行推理以解决原始查询,同时跟踪进展与记忆空间。它包含五个关键操作,形成一个闭环系统:
- Tri-Retrieve:对每个探针p∈P(t)p \in P^{(t)}p∈P(t),在三种知识层上执行检索,获取每个层中与嵌入相似度高的证据。这一操作实现了跨层次证据获取,确保系统能够从不同认知维度探索叙事;
- Mem-Encode:对每个ppp和type,立即处理检索到的证据,生成新的记忆单元,跟踪此特定探针对最终答案的补充方式。此步骤生成的记忆单元数量为∣Mencode(t)∣=3×∣P(t)∣|M_{\mathrm{encode}}^{(t)}| = 3 \times |P^{(t)}|∣Mencode(t)∣=3×∣P(t)∣;
- Mem-Fuse:识别与qinitq_{init}qinit高嵌入相似度的相关历史线索,由Integration Agent(πfuseπ_{fuse}πfuse)合成高阶背景摘要:Cfuse(t)=πfuse(qinit,Mpool(t−1)∘qinit)C_{\mathrm{fuse}}^{(t)} = \pi_{\mathrm{fuse}}(q_{\mathrm{init}},M_{\mathrm{pool}}^{(t-1)} \circ q_{\mathrm{init}})Cfuse(t)=πfuse(qinit,Mpool(t−1)∘qinit),实现新旧证据的融合,是形成连贯叙事理解的关键;
- Try-Answer:应用QA Agent(πQAπ_{QA}πQA)处理这些最新证据和历史背景,生成循环的最终输出:O(t)=πQA(qinit,Mencode(t),Cfuse(t))O^{(t)} = \pi_{QA}(q_{\mathrm{init}}, M_{\mathrm{encode}}^{(t)}, C_{\mathrm{fuse}}^{(t)})O(t)=πQA(qinit,Mencode(t),Cfuse(t))。如果无法确定答案,则触发新的推理循环;
- Mem-Update:将新生成的记忆单元简单纳入全局池,为其嵌入编码,用于未来检索和推理:Mpool(t)←Mpool(t−1)∪Mencode(t)M_{\mathrm{pool}}^{(t)} \leftarrow M_{\mathrm{pool}}^{(t-1)} \cup M_{\mathrm{encode}}^{(t)}Mpool(t)←Mpool(t−1)∪Mencode(t)。
五个操作——从Self-Probe生成新探针,到Tri-Retrieve获取证据,Mem-Encode形成记忆,Mem-Fuse整合新旧知识,Try-Answer尝试解答,再到Mem-Update更新记忆池——共同构成一个完整的、自我迭代的认知循环。当Try-Answer失败时,系统会利用更新后的记忆池再次启动Self-Probe,从而形成一个不断演化的推理状态闭环:
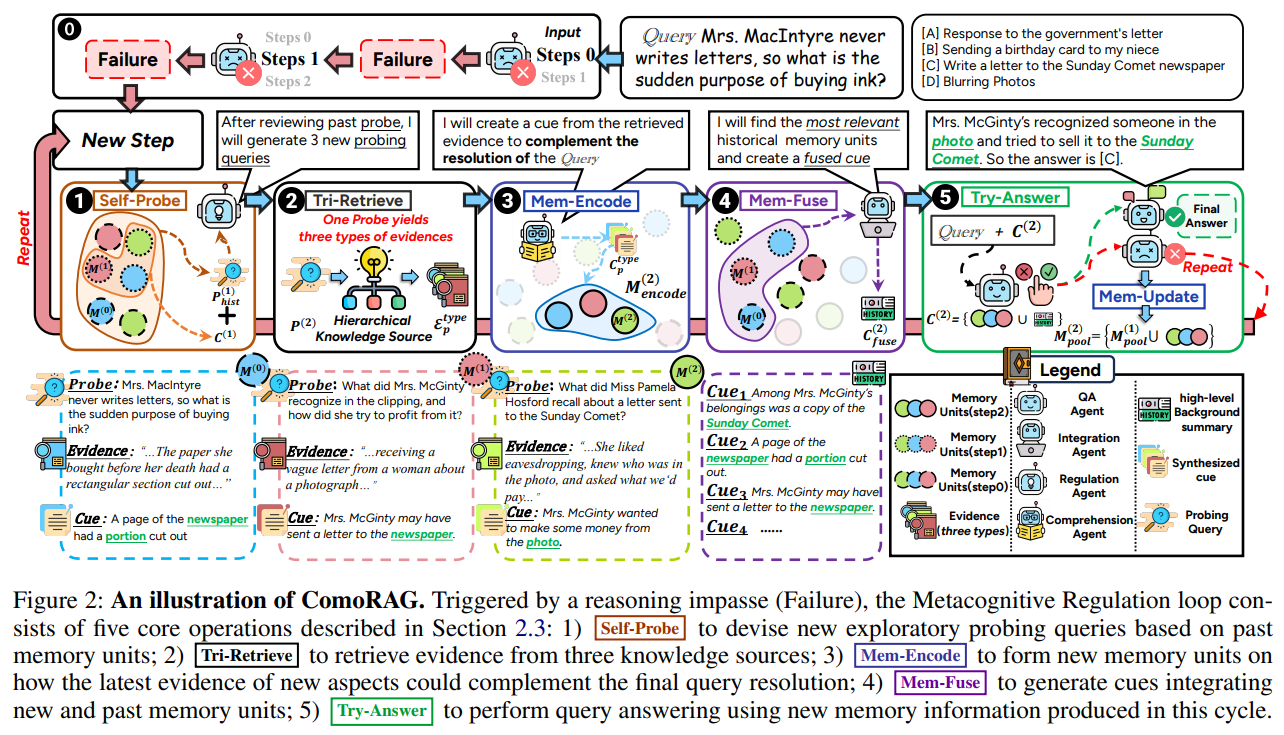
上图展示ComoRAG的工作流程。与传统RAG不同,ComoRAG形成一个闭环系统:当遇到推理阻塞(Failure)时,系统不是简单地放弃或重复检索,而是通过Self-Probe生成新的探索性探针,Tri-Retrieve获取新证据,Mem-Encode形成记忆单元,Mem-Fuse整合新旧记忆,最终通过Try-Answer尝试解答。这一闭环使系统能够像人类一样,通过迭代探索逐步构建完整理解。