不只是语法糖:解构作为 Rust 安全与清晰度的基石
不只是语法糖:解构作为 Rust 安全与清晰度的基石
在许多语言中,数据解构(Destructuring)被视为一种便捷的“语法糖”——一种从数据结构中提取值的快捷方式。然而,在 Rust 中,解构的地位远超于此。它不是一个孤立的特性,而是模式匹配(Pattern Matching) 系统的核心表现,是所有权模型的直接执行者,也是 Rust 类型安全与代码清晰度的基石。
理解解构,就是理解 Rust 如何“看待”数据。本文将深入剖析元组、结构体和枚举的解构模式,探讨其在 Rust 设计哲学中的核心地位,以及它如何赋予我们编写既安全又极富表现力的代码的能力。
解构的核心:所有权的转移与借用
Rust 中每一次 let 绑定、match 分支或函数参数传递,本质上都是一次模式匹配。而解构,就是这个模式匹配过程中的“拆包”行为。它的首要职责,是明确数据在“拆包”过程中的所有权归属。
默认情况下,解构是一次移动(动(Move) 操作。
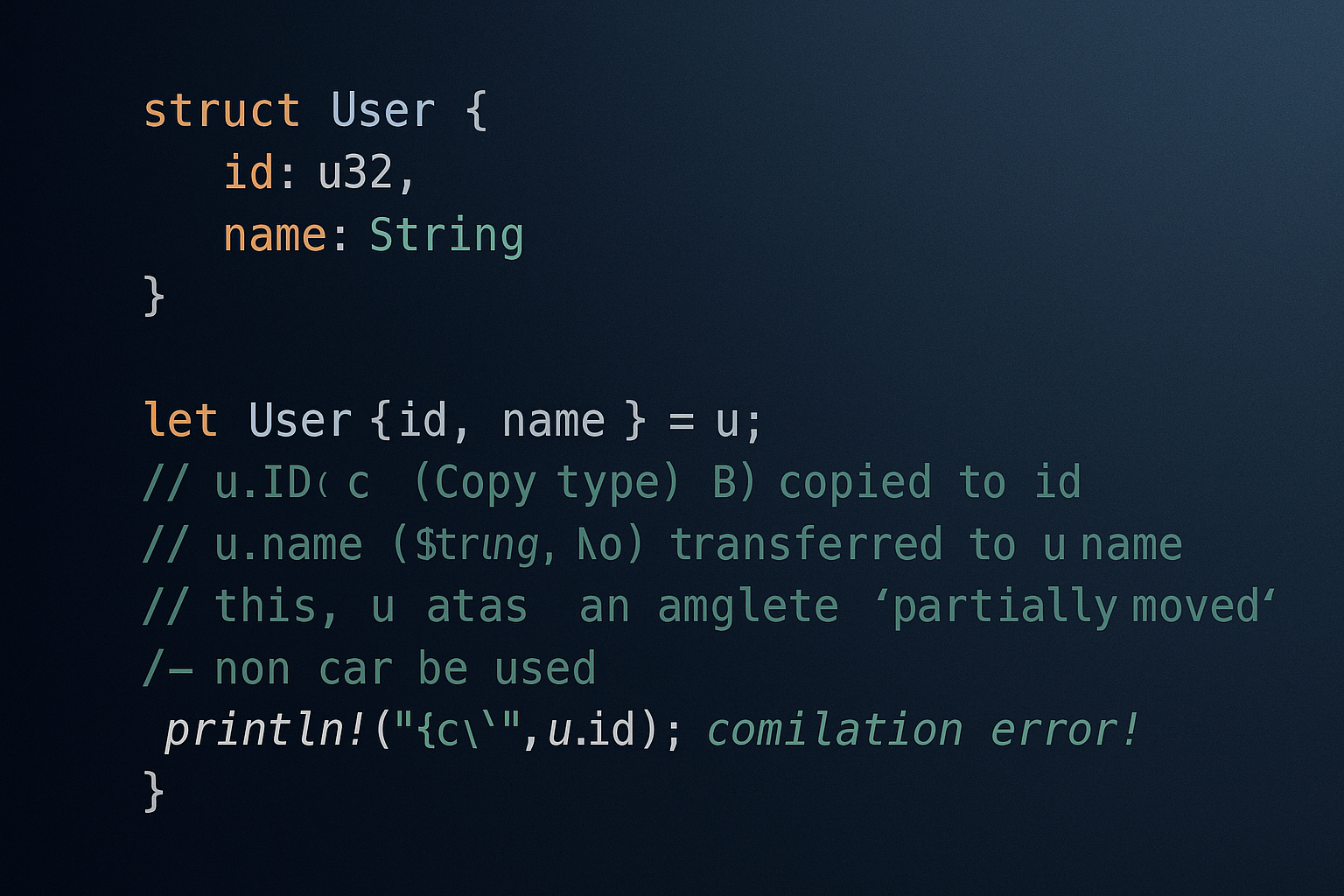
struct User { id: u32, name: String }
let u = User { id: 1, name: String::from("Alice") };// 解构 `u`
let User { id, name } = u;// `u.id` (Copy 类型) 被复制到了 `id`
// `u.name` (String, Move 类型) 的所有权被转移到了 `name`
// 此时,`u` 作为一个整体已经被 "部分移动",不能再被使用
// println!("{}", u.id); // 编译错误!
这个行为至关重要。解构不是简单地“创建别名”,它严格执行了所有权规则。String 类型没有实现 Copy Trait,因此它的所有权必须转移。编译器通过解构模式,清晰地追踪到了 name 字段的所有权流向,并立即阻止了对已失效的 u 的访问,从而在编译时杜绝了“use-after-move”错误。
精确控制:ref 与 ref mut 的外科手术
如果我们不希望(或不能)转移所有权呢?解构模式提供了 ref 和 ref mut 关键字,允许我们在模式内部进行精确到字段的借用。
这不仅仅是 `let name = &u.name;的替代品。在 match 语句中,它的威力才真正显现,它允许我们在一个复杂的结构中,同时对不同部分进行不同类型的借用,而不会违反借用检查器。
struct AppConfig { db_pool: DbPool, settings: Settings }
let mut config = AppConfig { ... };// 假设我们想在一个 match 中同时可变借用 settings,不可变借用 db_pool
match &mut config {// 这里是关键!AppConfig { ref db_pool, ref mut settings } => {// 我们获得了 &DbPooldb_pool.execute_query(...);// 我们获得了 &mut Settingssettings.update_theme("dark");}
}
请注意,我们匹配的是 &mut config。ref db_pool 捕获了一个 `&DbPool从 &mut AppConfig 降级为 &DbPool),而 ref mut settings 则捕获了一个 `&mut SettingsRust 的借用检查器能够理解这种“字段级别的分裂借用”(Field-level disjoint borrows),这是 Rust 安全并发与可变性控制的精妙体现。
实践的艺术:模式匹配中的高级解构
解构的真正力量在于它与 match 语句的结合,它能让我们以一种声明式的方式,清晰地处理复杂的、嵌套的数据结构。
实践案例:解构复杂的 API 响应
想象一下,我们正在处理一个返回 Result<Option<(User, AuthToken)>, ApiError> 的函数。这是一个常见的嵌套结构,使用传统 if let 会变得非常臃肿,而 match 和解构则能优雅地将其“压平”。
enum ApiError { Timeout, RateLimited, ServerError(u16) }
struct User { id: u32 }
struct AuthToken { token: String }fn handle_response(response: Result<Option<(User, AuthToken)>, ApiError>) {match response {// 1. 解构 Result::Ok 和 Option::Some// 2. 解构内部的元组 (User, AuthToken)// 3. 再次解构 User 和 AuthToken 结构体// 4. 使用 `..` 忽略 AuthToken 的字段// 5. 使用 `@` 绑定来同时获取整体和部分// 6. 使用匹配守卫 (match guard) `if`Ok(Some((User { id }, token_data @ AuthToken { .. }))) if id > 1000 => {println!("Handling VIP user {}. Token found.", id);// `token_data` 绑定了整个 AuthToken 结构体process_vip_token(token_data); }// 捕获 id <= 1000 的情况Ok(Some((User { id }, _))) => {println!("Handling regular user {}. Token ignored.", id);}Ok(None) => {println!("Success, but no data returned.");}// 7. 解构枚举变体及其内部数据Err(ApiError::ServerError(500)) => {println!("Critical: Internal Server Error (500)!");}Err(ApiError::RateLimited) => {println!("Please slow down: Rate limited.");}// 8. 使用 `_` 捕获所有其他错误Err(_) => {println!("An unknown API error occurred.");}}
}
在这个案例中,我们同时使用了多种解构技术:
- 嵌套解构 (
Ok(Some((User { ... })))) 让我们能一层层“透视”数据。 @绑定模式 (token_data @ AuthToken { .. }) 允许我们在解构的同时,也保留一个对被解构值(AuthToken)的绑定。..忽略模式 (AuthToken { .. }) 和_占位符,使我们的匹配既详尽(Exhaustive)又简洁。我们只关心我们需要的,而..确保了即使AuthToken结构体未来增加了新字段,这段代码也无需修改,极大地提升了代码的健壮性。- 字面量与守卫 (
ServerError(500)和if id > 1000) 让我们能在模式中直接表达复杂的业务逻辑。
专业洞见:解构的设计哲学
Rust 的解构设计,深刻地体现了其**“显式优于隐式”(Explicitness over Implicitness)和“编译时保证”**(Compile-time Guarantees)的哲学。
- 解构即所有权契约:
let { a, b } = s不仅仅是赋值,它是一个所有权声明。a和b的类型(是T、&T还是&mut T)在let绑定这一刻就由解构模式(是否使用ref/ref mut)和被解构的值(是 `s、&s还是&mut s)共同确定。这种显式性,是 Rust 内存安全的核心。 - 详即正确性:
match强制的详尽性检查(Exhaustiveness)是解构的“安全网”。编译器强迫我们处理enum的所有变体,或者struct的所有(我们关心的)字段。这消除了其他语言中普遍存在的 `null(None)检查遗漏和switch语句的default陷阱。 - 模式是“反向”:思考解构的最佳方式,是将其视为数据构造的反向操作。你如何使用 `User { id: 1, name “A” }
来构造它,就如何使用User { id, name }` 来解构它。这种对称性极大地降低了心智负担,使代码的意图一目了然。
结语
在 Rust 中,解构远非一个便利工具。它是一种思维方式。它迫使我们在与数据交互的那一刻就思考:这份数据的所有权归谁?我需要它的全部还是部分?我需要读取它还是修改它?
通过将这些问题前置到模式匹配中,Rust 将潜在的运行时错误(如空指针、悬垂引用、数据竞争)扼杀在了编译阶段。精通解构,不仅能让你写出更简洁、更富表现力的 Rust 代码,更是你真正开始用“Rust 的方式”思考的标志。