让数据导入导出更智能:通用框架+验证+翻译的一站式解决方案

一、背景与挑战
在企业级应用开发中,数据导入导出是一项基础而重要的功能需求。随着业务规模的不断扩大和数据量的急剧增长,传统的数据处理方式面临着诸多挑战:
- 性能瓶颈:百万级数据量导出时容易出现内存溢出和服务器压力过大问题
- 通用性差:为不同业务场景重复开发导入导出功能,代码冗余度高
- 扩展性不足:难以灵活支持新的数据格式、验证规则和转换需求
- 用户体验:大量数据处理耗时过长,阻塞用户操作,影响系统响应性
- 数据质量:缺乏统一有效的数据验证机制,容易导致脏数据进入系统
- 维护成本高:功能分散,后期修改和维护难度大
二、基础知识与技术选型
2.1 核心技术对比
| 技术方案 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| Apache POI | 功能全面,支持复杂格式 | 内存消耗大,大数据处理能力弱 | 小数据量、复杂格式需求 |
| EasyExcel | 基于SAX流处理,内存占用低 | 某些复杂格式支持有限 | 大数据量导出,性能要求高 |
| EasyPoi | 注解驱动,配置简单 | 大数据处理性能不如EasyExcel | 中小数据量,配置化需求 |
| CSV格式 | 轻量级,处理速度快 | 不支持复杂格式和样式 | 超大数据量,只关注数据内容 |
| FastExcel | SAX字节流操作,性能提升20倍 | 社区相对较小 | 对性能有极致要求的场景 |
2.2 关键技术点
- 流式处理:通过SAX模式逐行读取和写入数据,避免一次性加载全部数据到内存
- 异步处理:将耗时的导入导出任务异步化,提升用户体验
- 多线程优化:利用并行计算提高大数据处理效率
- 模板引擎:支持基于模板的数据填充和生成
- 注解驱动:通过注解配置简化开发,提高代码可读性和维护性
- 事件监听器:基于事件的处理机制,实现数据的实时处理和转换
三、架构设计与核心原理
3.1 整体架构分层设计
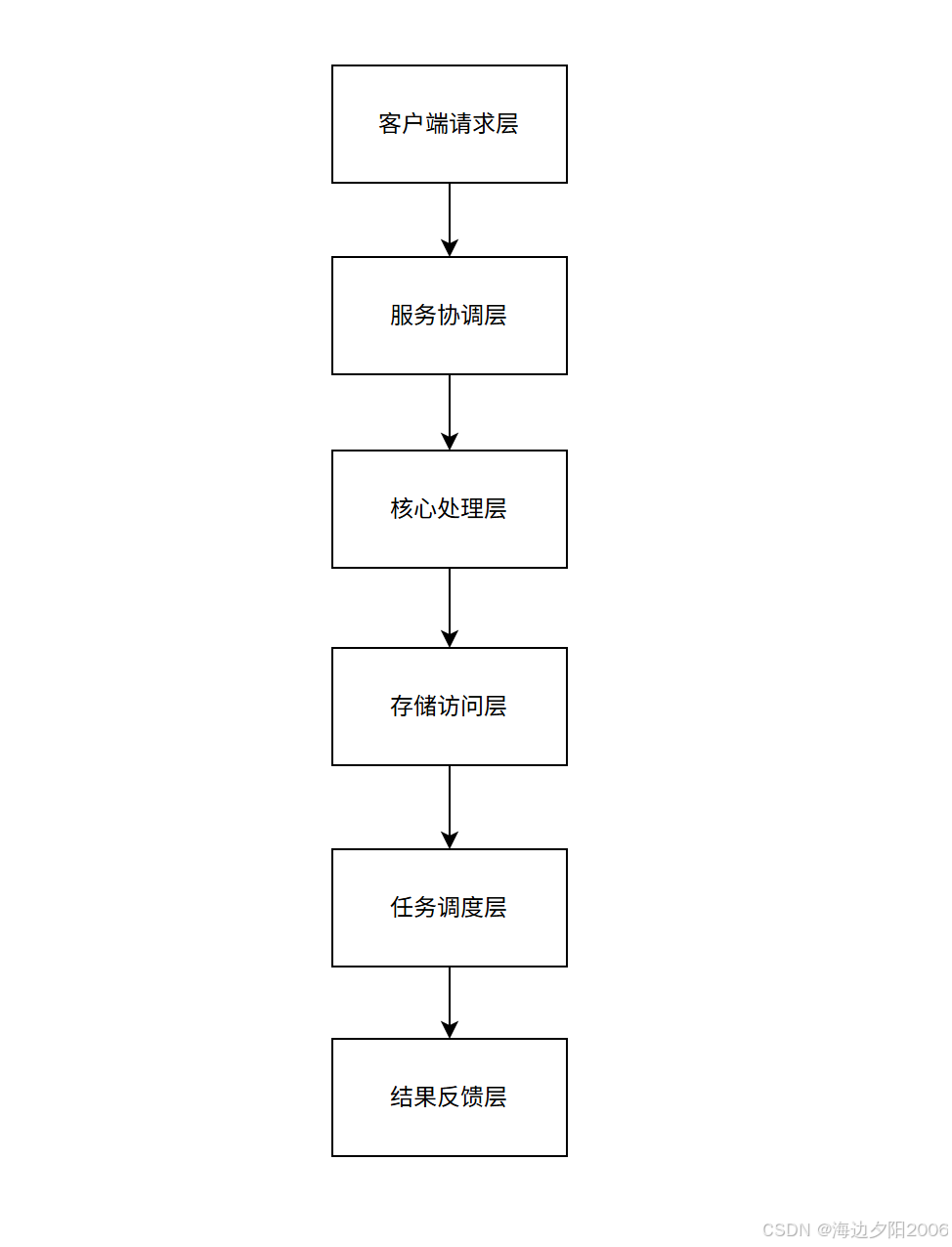
3.2 核心设计原则
- 单一职责原则:每个组件只负责特定功能,职责明确
- 开闭原则:通过接口和抽象类设计,支持功能扩展而不修改现有代码
- 依赖倒置:高层模块依赖抽象,不依赖具体实现
- 接口隔离:使用多个专门的接口,而不是单一的总接口
- 组合优于继承:通过组合方式构建功能,提高灵活性
3.3 可扩展性设计
- SPI机制:使用Java SPI机制实现组件的动态加载和扩展
- 策略模式:针对不同的数据格式、验证规则提供不同的策略实现
- 装饰器模式:在不改变原有对象的情况下,动态地给对象添加额外的功能
- 工厂模式:通过工厂方法创建具体的处理器实例
- 责任链模式:实现数据验证和转换的链式处理
四、核心组件与实现
4.1 通用注解设计
/*** Excel字段注解,用于配置字段的导入导出属性*/
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface ExcelField {/*** 列名*/String name() default "";/*** 列宽*/int width() default 15;/*** 是否为主键*/boolean primaryKey() default false;/*** 日期格式化*/String dateFormat() default "yyyy-MM-dd HH:mm:ss";/*** 字典类型*/String dictType() default "";/*** 是否可导入*/boolean importable() default true;/*** 是否可导出*/boolean exportable() default true;/*** 验证规则*/String[] validators() default {};
}/*** 字典注解,用于字段值的字典翻译*/
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Dict {/*** 字典类型编码*/String value();/*** 是否使用缓存*/boolean useCache() default true;
}4.2 核心接口定义
/*** 数据处理器接口*/
public interface DataProcessor<T> {/*** 处理单条数据*/T process(T data, int rowIndex); /*** 批量处理数据*/List<T> batchProcess(List<T> dataList);
}/*** 数据验证器接口*/
public interface DataValidator<T> {/*** 验证数据* @return 验证结果,null表示验证通过*/ValidationResult validate(T data, int rowIndex);
}/*** 字典转换器接口*/
public interface DictConverter {/*** 编码转名称*/String codeToName(String dictType, String code); /*** 名称转编码*/String nameToCode(String dictType, String name);
}/*** 导入导出模板接口*/
public interface ImportExportTemplate<T> {/*** 获取导出数据*/List<T> getExportData(Map<String, Object> params); /*** 处理导入数据*/ImportResult processImportData(List<T> dataList, Map<String, Object> params);
}4.3 通用导入导出管理器
/*** 通用导入导出管理器*/
public class ImportExportManager {private final DictConverter dictConverter;private final ValidatorFactory validatorFactory;private final TaskScheduler taskScheduler; /*** 导出数据*/public <T> void exportData(HttpServletResponse response,Class<T> clazz,List<T> dataList,String fileName) {// 使用EasyExcel进行导出,支持大数据量流式处理EasyExcel.write(response.getOutputStream(), clazz).registerWriteHandler(new DictDataWriteHandler(dictConverter)).sheet("数据").doWrite(dataList);} /*** 异步导出大数据量*/public <T> String asyncExportData(Class<T> clazz,Map<String, Object> params,ImportExportTemplate<T> template) {String taskId = generateTaskId();taskScheduler.schedule(() -> {try {List<T> dataList = template.getExportData(params);// 生成文件并存储String filePath = generateExportFilePath(fileName, lazz.getSimpleName());// 流式写入,避免内存溢出EasyExcel.write(filePath, clazz).registerWriteHandler(new DictDataWriteHandler(dictConverter)).sheet("数据").doWrite(new PaginatedDataList<>(dataList, 10000));// 更新任务状态updateTaskStatus(taskId, "SUCCESS", filePath);} catch (Exception e) {updateTaskStatus(taskId, "ERROR", e.getMessage());}});return taskId;} /*** 导入数据*/public <T> ImportResult importData(MultipartFile file,Class<T> clazz,ImportExportTemplate<T> template,Map<String, Object> params) {List<T> dataList = new ArrayList<>();List<ImportError> errors = new ArrayList<>();// 使用EasyExcel读取文件,设置监听器处理数据EasyExcel.read(file.getInputStream(), clazz, new DataImportListener<T>(dataList, errors, getValidators(clazz), dictConverter)).sheet().doRead(); // 处理验证通过的数据if (errors.isEmpty()) {return template.processImportData(dataList, params);} else {return ImportResult.fail(errors);}} // 其他辅助方法...
}4.4 数据验证框架
/*** 验证结果*/
public class ValidationResult {private boolean success;private String message;private int rowIndex;private String fieldName; // 构造方法、getter和setter
}/*** 验证器工厂*/
public class ValidatorFactory {private final Map<String, DataValidator<?>> validators = new HashMap<>(); public <T> DataValidator<T> getValidator(String validatorName) {return (DataValidator<T>) validators.get(validatorName);} public void registerValidator(String name, DataValidator<?> validator) {validators.put(name, validator);} public <T> List<DataValidator<T>> getValidatorsByAnnotation(Field field) {ExcelField excelField = field.getAnnotation(ExcelField.class);List<DataValidator<T>> result = new ArrayList<>(); if (excelField != null && excelField.validators().length > 0) {for (String validatorName : excelField.validators()) {DataValidator<T> validator = getValidator(validatorName);if (validator != null) {result.add(validator);}}}return result;}
}/*** 常用验证器实现*/
public class RequiredValidator<T> implements DataValidator<T> {@Overridepublic ValidationResult validate(T data, int rowIndex) {if (data == null) {return new ValidationResult(false, "字段值不能为空", rowIndex, "");}return null; // 验证通过}
}public class NumberRangeValidator<T extends Number> implements DataValidator<T> {private final double min;private final double max; public NumberRangeValidator(double min, double max) {this.min = min;this.max = max;} @Overridepublic ValidationResult validate(T data, int rowIndex) {if (data != null) {double value = data.doubleValue();if (value < min || value > max) {return new ValidationResult(false,String.format("数值必须在%s-%s之间", min, max),rowIndex, "");}}return null;}
}4.5 字典翻译实现
/*** 字典管理器*/
public class DictManager {private final DictService dictService;private final LoadingCache<String, Map<String, String>> dictCache; public DictManager(DictService dictService) {this.dictService = dictService;// 初始化缓存,设置过期时间this.dictCache = CacheBuilder.newBuilder().expireAfterWrite(1, TimeUnit.HOURS).build(new CacheLoader<String, Map<String, String>>() {@Overridepublic Map<String, String> load(String dictType) {return dictService.getDictMapByType(dictType);}});}/*** 获取字典值*/public String getDictName(String dictType, String code) {try {Map<String, String> dictMap = dictCache.get(dictType);return dictMap != null ? dictMap.get(code) : code;} catch (ExecutionException e) {log.error("获取字典失败", e);return code;}} /*** 刷新字典缓存*/public void refreshDictCache(String dictType) {dictCache.invalidate(dictType);}
}/*** 字典数据写入处理器*/
public class DictDataWriteHandler implements CellWriteHandler {private final DictManager dictManager; public DictDataWriteHandler(DictManager dictManager) {this.dictManager = dictManager;} @Overridepublic void afterCellDispose(WriteSheetHolder writeSheetHolder,WriteTableHolder writeTableHolder,Cell cell,Head head,Integer relativeRowIndex,Boolean isHead) {if (!isHead && cell.getCellType() == CellType.STRING) {// 获取当前单元格对应的字段信息Field field = getFieldByHead(head);if (field != null) {Dict dict = field.getAnnotation(Dict.class);if (dict != null) {// 进行字典翻译String code = cell.getStringCellValue();String name = dictManager.getDictName(dict.value(), code);cell.setCellValue(name);}}}} private Field getFieldByHead(Head head) {// 根据表头信息获取对应的字段// 实现略...return null;}
}五、性能优化策略
5.1 内存优化
- 流式处理:使用SAX模式逐行读取和写入,避免一次性加载全部数据到内存
- 批量处理:设置合理的批处理大小,控制内存占用
- 临时文件:对于超大文件,使用临时文件缓存中间结果
- 对象复用:在处理过程中复用对象,减少GC压力
// 分页数据列表实现,避免一次性加载全部数据
public class PaginatedDataList<T> implements ReadOnlyList<T> {private final List<T> dataList;private final int pageSize; public PaginatedDataList(List<T> dataList, int pageSize) {this.dataList = dataList;this.pageSize = pageSize;} @Overridepublic int size() {return dataList.size();} @Overridepublic T get(int index) {// 按需加载或处理数据return dataList.get(index);}
}5.2 多线程处理
- 数据分片:将大数据集分成多个小片段,并行处理
- 线程池优化:使用自定义线程池,合理设置核心线程数和最大线程数
- 异步任务:将耗时操作异步化,提高系统吞吐量
/*** 多线程数据处理器*/
public class MultiThreadDataProcessor<T> implements DataProcessor<T> {private final int threadCount;private final ExecutorService executorService;private final DataProcessor<T> delegateProcessor; public MultiThreadDataProcessor(int threadCount, DataProcessor<T> delegateProcessor) {this.threadCount = threadCount;this.delegateProcessor = delegateProcessor;this.executorService = new ThreadPoolExecutor(threadCount,threadCount * 2,60L,TimeUnit.SECONDS,new LinkedBlockingQueue<>(1000),new ThreadPoolExecutor.CallerRunsPolicy());} @Overridepublic List<T> batchProcess(List<T> dataList) {if (dataList.size() <= threadCount) {// 数据量较小时,直接单线程处理return delegateProcessor.batchProcess(dataList);} // 计算每个线程处理的数据量int batchSize = dataList.size() / threadCount;List<Future<List<T>>> futures = new ArrayList<>(); // 分片并行处理for (int i = 0; i < threadCount; i++) {final int start = i * batchSize;final int end = (i == threadCount - 1) ? dataList.size() : (i + 1) * batchSize;futures.add(executorService.submit(() -> {List<T> subList = dataList.subList(start, end);return delegateProcessor.batchProcess(subList);}));} // 合并结果List<T> result = new ArrayList<>(dataList.size());for (Future<List<T>> future : futures) {try {result.addAll(future.get());} catch (Exception e) {throw new RuntimeException("多线程处理失败", e);}}return result;}
}5.3 数据库优化
- 分页查询:使用游标或分页机制查询数据,避免一次性查询过多记录
- 索引优化:确保查询条件使用了合适的索引
- 批量操作:使用JDBC批处理或ORM框架的批量操作功能
- 连接池:配置合理的数据库连接池参数
六、异步任务管理
6.1 任务调度器
/*** 异步任务调度器*/
public class AsyncTaskScheduler {private final ExecutorService executorService;private final TaskStore taskStore; public AsyncTaskScheduler(int corePoolSize, TaskStore taskStore) {this.executorService = new ThreadPoolExecutor(corePoolSize,corePoolSize * 2,60L,TimeUnit.SECONDS,new LinkedBlockingQueue<>(10000),new ThreadFactoryBuilder().setNameFormat("import-export-task-%d").build(),new ThreadPoolExecutor.CallerRunsPolicy());this.taskStore = taskStore;} /*** 提交任务*/public String submitTask(Callable<?> task, String taskType, String userId) {String taskId = UUID.randomUUID().toString();// 创建任务记录TaskInfo taskInfo = new TaskInfo();taskInfo.setTaskId(taskId);taskInfo.setTaskType(taskType);taskInfo.setUserId(userId);taskInfo.setStatus(TaskStatus.RUNNING);taskInfo.setCreateTime(new Date()); taskStore.save(taskInfo);// 提交到线程池executorService.submit(() -> {try {task.call();taskInfo.setStatus(TaskStatus.SUCCESS);taskInfo.setEndTime(new Date());} catch (Exception e) {taskInfo.setStatus(TaskStatus.FAILED);taskInfo.setErrorMessage(e.getMessage());taskInfo.setEndTime(new Date());log.error("Task {} failed", taskId, e);} finally {taskStore.update(taskInfo);}});return taskId;} /*** 获取任务状态*/public TaskInfo getTaskStatus(String taskId) {return taskStore.getById(taskId);}
}6.2 任务进度监控
/*** 任务进度管理器*/
public class TaskProgressManager {private final ConcurrentHashMap<String, AtomicLong> progressMap = new ConcurrentHashMap<>();private final ConcurrentHashMap<String, Long> totalMap = new ConcurrentHashMap<>(); /*** 更新任务进度*/public void updateProgress(String taskId, long increment) {progressMap.computeIfAbsent(taskId, k -> new AtomicLong(0)).addAndGet(increment);} /*** 设置任务总数*/public void setTotal(String taskId, long total) {totalMap.put(taskId, total);} /*** 获取进度百分比*/public int getProgressPercentage(String taskId) {Long total = totalMap.get(taskId);Long progress = progressMap.getOrDefault(taskId, new AtomicLong(0)).get();if (total == null || total == 0) {return 0;} return (int) (progress * 100 / total);} /*** 清理任务进度*/public void cleanProgress(String taskId) {progressMap.remove(taskId);totalMap.remove(taskId);}
}七、应用实战案例
7.1 通用导出实现
@RestController
@RequestMapping("/api/export")
public class ExportController { @Autowiredprivate ImportExportManager importExportManager; @Autowiredprivate AsyncTaskScheduler taskScheduler; /*** 普通导出*/@GetMapping("/user/list")public void exportUserList(HttpServletResponse response, @RequestParam Map<String, Object> params) {try {// 设置响应头response.setContentType("application/vnd.ms-excel");response.setCharacterEncoding("utf-8");String fileName = URLEncoder.encode("用户列表", "UTF-8");response.setHeader("Content-disposition", "attachment;filename=" + fileName + ".xlsx");// 获取数据List<User> userList = userService.queryUserList(params);// 导出数据importExportManager.exportData(response, User.class, userList, fileName);} catch (Exception e) {throw new RuntimeException("导出失败", e);}} /*** 异步大数据导出*/@PostMapping("/user/list/async")public Result<String> asyncExportUserList(@RequestBody Map<String, Object> params, Principal principal) {String taskId = taskScheduler.submitTask(() -> {// 创建导出模板ImportExportTemplate<User> template = new UserExportTemplate(userService);// 执行异步导出return importExportManager.asyncExportData(User.class, params, template);}, "USER_EXPORT", principal.getName());return Result.success(taskId);} /*** 获取导出任务状态*/@GetMapping("/task/status/{taskId}")public Result<TaskInfo> getTaskStatus(@PathVariable String taskId) {TaskInfo taskInfo = taskScheduler.getTaskStatus(taskId);return Result.success(taskInfo);}
}7.2 通用导入实现
@RestController
@RequestMapping("/api/import")
public class ImportController { @Autowiredprivate ImportExportManager importExportManager; /*** 导入用户数据*/@PostMapping("/user/list")public Result<ImportResult> importUserList(@RequestParam("file") MultipartFile file) {try {// 创建导入模板ImportExportTemplate<User> template = new UserImportTemplate(userService);// 执行导入ImportResult result = importExportManager.importData(file,User.class,template,new HashMap<>()); if (result.isSuccess()) {return Result.success(result);} else {return Result.fail(result.getErrorMessage());}} catch (Exception e) {throw new RuntimeException("导入失败", e);}} /*** 下载导入模板*/@GetMapping("/user/template")public void downloadTemplate(HttpServletResponse response) {try {response.setContentType("application/vnd.ms-excel");response.setCharacterEncoding("utf-8");String fileName = URLEncoder.encode("用户导入模板", "UTF-8");response.setHeader("Content-disposition", "attachment;filename=" + fileName + ".xlsx");// 创建模板文件EasyExcel.write(response.getOutputStream(), User.class).sheet("用户信息").doWrite(Collections.emptyList());} catch (Exception e) {throw new RuntimeException("下载模板失败", e);}}
}7.3 自定义导入导出模板
/*** 用户导出模板*/
public class UserExportTemplate implements ImportExportTemplate<User> { private final UserService userService; public UserExportTemplate(UserService userService) {this.userService = userService;} @Overridepublic List<User> getExportData(Map<String, Object> params) {// 根据参数查询数据,可以实现分页查询return userService.queryUserListByPage(params);} @Overridepublic ImportResult processImportData(List<User> dataList, Map<String, Object> params) {// 批量保存用户数据int successCount = userService.batchSaveUser(dataList);return ImportResult.success(successCount);}
}八、功能扩展与进阶应用
8.1 动态字段配置
/*** 动态字段配置管理器*/
public class DynamicFieldManager {private final FieldConfigService fieldConfigService; /*** 获取用户配置的导出字段*/public List<String> getUserExportFields(String userId, String entityType) {return fieldConfigService.getUserExportFields(userId, entityType);} /*** 根据配置的字段创建导出对象*/public <T> List<T> createExportObjectsByConfig(List<Map<String, Object>> sourceData,Class<T> targetClass,List<String> fieldNames) {List<T> result = new ArrayList<>();for (Map<String, Object> dataMap : sourceData) {T targetObject = BeanUtils.instantiateClass(targetClass);for (String fieldName : fieldNames) {try {Field field = targetClass.getDeclaredField(fieldName);field.setAccessible(true);field.set(targetObject, dataMap.get(fieldName));} catch (Exception e) {log.error("设置字段值失败", e);}}result.add(targetObject);}return result;}
}8.2 高级数据验证
/*** 自定义验证注解*/
@Target({ElementType.FIELD, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Constraint(validatedBy = CustomValidator.class)
public @interface CustomValidation {String message() default "验证失败";Class<?>[] groups() default {};Class<? extends Payload>[] payload() default {};String rule() default "";
}/*** 动态验证规则引擎*/
public class ValidationRuleEngine {private final Map<String, ValidationRule> ruleMap = new HashMap<>(); public void registerRule(String ruleName, ValidationRule rule) {ruleMap.put(ruleName, rule);} public ValidationResult executeRule(String ruleName, Object value, Map<String, Object> context) {ValidationRule rule = ruleMap.get(ruleName);if (rule == null) {throw new IllegalArgumentException("未知的验证规则: " + ruleName);}return rule.validate(value, context);}
}/*** 验证规则接口*/
public interface ValidationRule {ValidationResult validate(Object value, Map<String, Object> context);
}8.3 多格式支持
/*** 导出格式枚举*/
public enum ExportFormat {EXCEL(".xlsx"),CSV(".csv"),PDF(".pdf"),JSON(".json"),XML(".xml"); private final String extension; ExportFormat(String extension) {this.extension = extension;}public String getExtension() {return extension;}
}/*** 格式转换器工厂*/
public class FormatConverterFactory {private final Map<ExportFormat, DataFormatConverter<?>> converters = new HashMap<>();public <T> DataFormatConverter<T> getConverter(ExportFormat format) {return (DataFormatConverter<T>) converters.get(format);} public void registerConverter(ExportFormat format, DataFormatConverter<?> converter) {converters.put(format, converter);}
}九、部署与监控
9.1 配置最佳实践
1. 线程池配置:根据服务器CPU核心数设置合理的线程池参数
import-export:thread-pool:core-size: 4max-size: 8queue-capacity: 1000keep-alive-seconds: 602. 内存配置:为大数据处理预留足够的内存空间
-Xms4g -Xmx8g -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=512m3. 临时文件配置:设置合理的临时文件目录和大小限制
import-export:temp-file:directory: /data/tempmax-size: 10gcleanup-interval: 36009.2 监控指标
- 任务成功率:监控导入导出任务的成功和失败比例
- 平均处理时间:跟踪任务的平均执行时间,及时发现性能问题
- 内存占用:监控JVM内存使用情况,避免内存溢出
- 线程池状态:监控线程池的活跃度、队列长度等指标
- 文件大小统计:记录导入导出文件的大小分布
十、总结与展望
本文提出的大数据导入导出功能设计方案具有以下优势:
- 通用性:通过注解驱动和接口抽象,实现了高度通用的导入导出框架
- 可扩展性:支持自定义验证器、处理器、字典转换器等组件的扩展
- 高性能:采用流式处理、多线程、异步任务等技术,确保大数据处理的性能
- 易用性:提供简洁的API和丰富的配置选项,降低使用门槛
- 健壮性:完善的数据验证和错误处理机制,保证数据质量和系统稳定性
未来的优化方向包括:
- 支持更多的数据格式,如大数据格式(Parquet、ORC等)
- 集成分布式计算框架,处理超大规模数据
- 提供可视化的导入导出配置界面
- 支持数据映射和转换的复杂规则配置
- 增强安全性,实现细粒度的权限控制
通过本方案的实施,可以显著提高系统处理大数据导入导出的能力,为业务部门提供高效、可靠的数据交互工具。