DeepSeek-OCR 论文精读与实践:用“光学上下文压缩”把长文本变成图片,再由 VLM 高效还原
关键词:DeepSeek-OCR、视觉-文本压缩、长上下文、MoE、OCR、文档解析、vLLM、Transformers
一、写在前面(5 点速览)
- 研究动机:LLM 处理超长上下文时计算与显存成本会随序列长度急剧上升。DeepSeek-OCR 提出把长文本转为高分辨率图像,再用视觉 token替代海量文本 token,从而显著降低成本。
- 总体架构:一个DeepEncoder(视觉编码器) + 一个3B MoE 解码器。DeepEncoder 以窗口注意力 + 16×卷积压缩 + 全局注意力串联,既能吃高分辨率,又能把视觉 token 压到很少;解码器负责从少量视觉 token 还原出文本/Markdown 等。
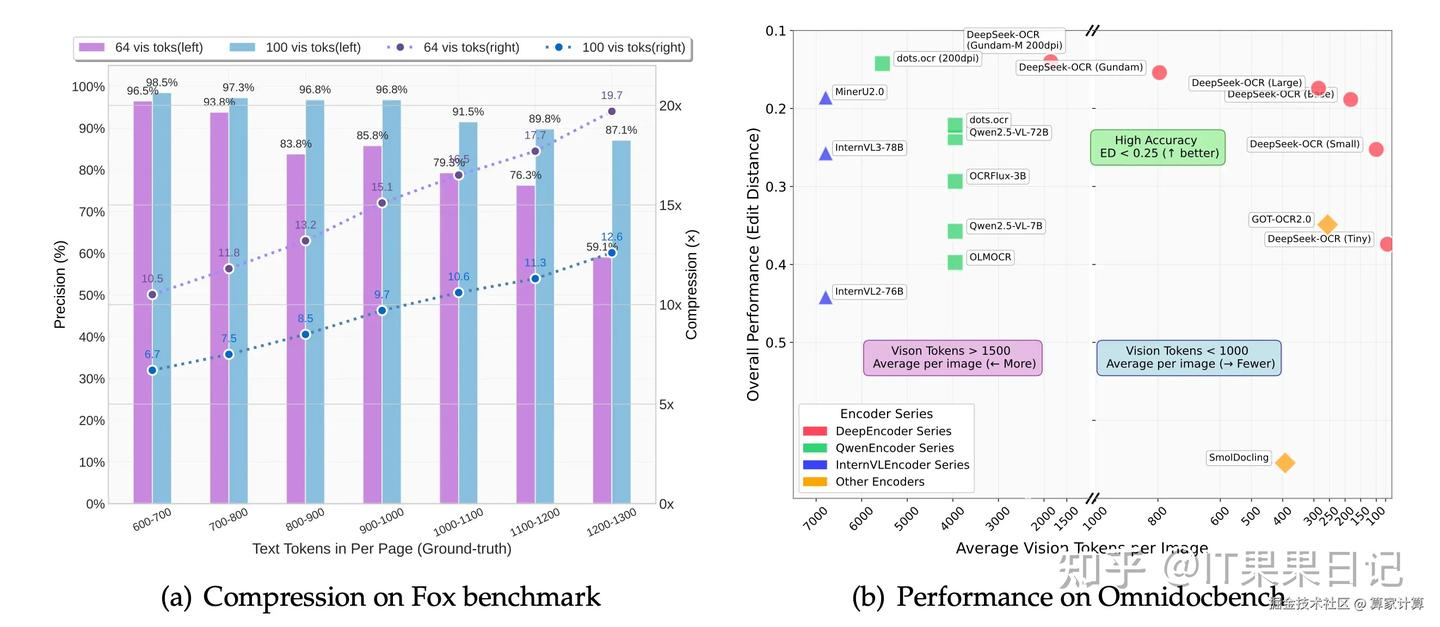
- 压缩-精度权衡(来自论文的量化结论):在10×压缩下可达约 96%/97% OCR 准确率;极限到20×时仍能保持约 60%。意味着能用更少 token 涵盖更多历史内容。
- 实际表现:在 OmniDocBench 等文档基准上,以更少的视觉 token达到或超越同类端到端 OCR/VLM;生产侧可做大规模文档数据生成(单张 A100-40G 即可高吞吐处理)。
- 开源易用:已提供 Transformers / vLLM 推理脚本、多分辨率模式(Tiny/Small/Base/Large/Gundam)、常见 prompt 模板与批量 PDF 处理示例,直接落地工程。
二、为什么“把文本变图片”有意义?
LLM 的时间/显存复杂度通常随文本序列长度上升(例如注意力机制近似二次/线性-常数优化仍有限)。而图像是一种天然的“稠密表达”——一张图能承载成百上千字。如果我们有一个足够强的视觉编码器,能把高分辨率图像 → 少量但信息密度高的视觉 token,再配合一个语言解码器把信息解码回文本,那么:
- 压缩收益:同等信息量下,视觉 token 数量可显著小于文本 token 数量;
- 成本优势:训练与推理中,上下文长度可大幅缩短,从而降低显存与时间开销;
- 统一范式:“文档版面/表格/图表/化学式/多语言”在图像域的统一建模,简化传统“检测+识别+版面分析”的多模型流水线。
OCR 在这里不仅是“识别字符”,更是作为可量化试验台:压缩多少视觉 token,仍能还原多少文本信息(带标准答案可评估)。
三、方法总览:DeepSeek-OCR 的整体设计
DeepSeek-OCR 是一个端到端 VLM,包含:
-
DeepEncoder(≈380M 参数)
- 前半段:窗口注意力主导(基于 SAM-base),以较低激活成本消化高分辨率细节;
- 中间:2 层 3×3、stride=2 的卷积压缩模块,把视觉 token 16×下采样(例如 4096 → 256);
- 后半段:全局注意力(基于 CLIP-large),在更少 token 下做全局建模;
- 多分辨率/动态分辨率模式,让工程上能“按预算”灵活切换。
-
解码器:DeepSeek-3B-MoE(激活参数 ≈570M)
- 以MoE(多专家)提升表达/效率;
- 解码目标是文本/Markdown/结构化输出;支持一些输出约束(如 NGram 处理、表格标签白名单等)。
输入/输出:输入为单页/多页文档图像(或截图),输出可为纯文本、Markdown、结构化块(表格、代码、图示说明)等。
四、DeepEncoder 细节解剖:高分辨率、低激活、少 token
目标:在高分辨率下,既吃得下,又压得好。
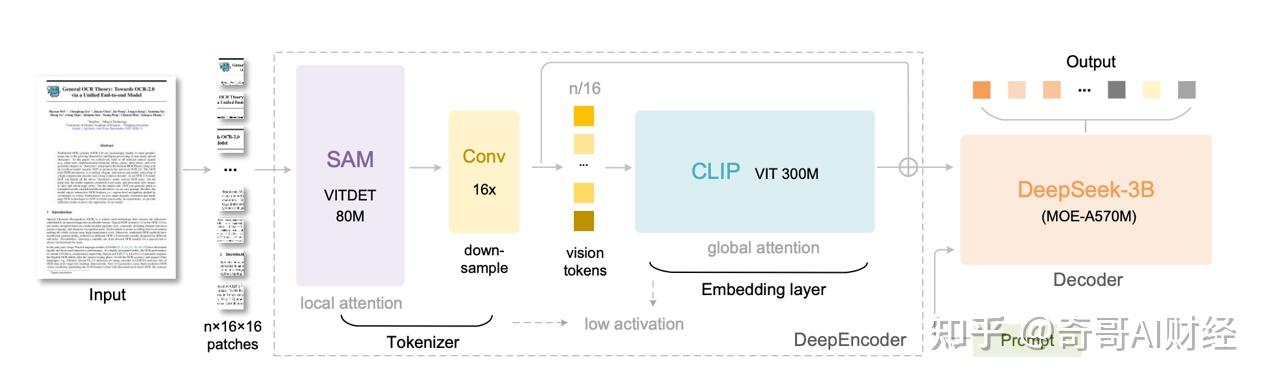
-
局部-全局两阶段
- 阶段 A(局部/窗口注意力):以 SAM-base 为骨干(patch size 16)。对 1024×1024 输入,初始产生 4096 个 patch token。窗口注意力激活低、可并行,适合首先吃掉海量局部细节。
- 阶段 B(16×卷积压缩):2 层 3×3/stride=2 卷积,通道 256→1024,把 token 从 4096 压到 256。
- 阶段 C(全局注意力):把压缩后的 token 输入 CLIP-large(移除了首个 patch-embed,因为输入已是 token),在较少 token上做全局建模。
-
多分辨率/动态分辨率模式(示例)
| 模式 | 原生分辨率 | 典型视觉 token 数 |
|---|---|---|
| Tiny | 512×512 | 64 |
| Small | 640×640 | 100 |
| Base | 1024×1024 | 256 |
| Large | 1280×1280 | 400 |
| Gundam(动态) | 1×1024×1024 + n×640×640 | 256 + n×100 |
工程含义:你可以按显存/吞吐预算选择模式;需要更细粒度时使用 Gundam(主视图 + 若干局部高密度裁剪)。
五、MoE 解码器与输出约束
- 3B MoE / 激活 570M:在保持推理效率的同时获得更强表达能力。
- 输出约束(可选):为减少“胡写”,可用 NGramPerReqLogitsProcessor 等策略限制输出 n-gram 或对表格专用 token做白/黑名单约束(如只放行
<td> / </td>),提升结构化输出的稳定性。
六、数据与训练:两阶段、8192 序列、三类数据源
- 数据配比(示例):OCR 数据 ~70%、通用视觉数据 ~20%、文本-only ~10%;序列长度通常在 8192。
- 训练流程(2 阶段):
1)先独立训练 DeepEncoder,把“高分辨率 → 少 token”这件事做到稳而准;
2)再端到端训练 DeepSeek-OCR,让解码器学会从视觉 token 还原文本/Markdown/表格。 - 能力扩展:除文本外,对图表/化学式/简单几何图等也有专门解析能力,工程上更实用。
七、效果与指标:压缩-精度曲线 & 基准对比(论文结论)
- 压缩 vs 准确率(以 Fox 等基准为例):
- ≈9–10× 压缩:OCR 解码≈96%+;
- ≈10–12×:≈90%;
- ≈20×:≈60%。
- 基准对比(OmniDocBench):在更少视觉 token的前提下,达到或超越 GOT-OCR2.0、MinerU 等端到端方案。
- 生产吞吐:单张 A100-40G 可达每日 20 万+ 页;规模化集群(如 20 台 × 8 卡)可达数千万页/日的训练语料生成与处理能力。
工程解读:**中低压缩(≤10×)**已经非常可用;如果业务能够容忍部分损失,可进一步上调压缩比换更高吞吐/更低成本。
八、与传统 OCR / 通用 VLM 的对比
| 维度 | 传统 OCR(检测+识别) | 通用 VLM(端到端解析) | DeepSeek-OCR(本工作) |
|---|---|---|---|
| 范式 | 多模型流水线 | 单模型端到端 | 单模型端到端,但显式追求“视觉-文本压缩”效率最优 |
| 对长上下文 | 依赖外部拼接 | 仍受文本 token 长度限制 | 用视觉 token 替代文本 token,显著降本 |
| 版面/表格 | 需专门模块 | 依赖指令/微调 | 内建图表/结构化解析能力更强 |
| 工程易用性 | 成熟 | 快速迭代 | 已提供开源脚本/多分辨率模式/vLLM 集成 |
| 可能的弱项 | 复杂维护 | token 多、成本高 | 超高压缩会降精度;对布局/清晰度仍有要求 |
九、快速上手(GPU:8GB+ 更佳;建议 BF16 + FlashAttention)
下列示例已在官方仓库/模型卡给出,可直接粘贴运行。
9.1 依赖环境(Transformers 路线)
# Python 3.12.9 + CUDA 11.8(示例)
pip install "torch==2.6.0" "transformers==4.46.3" "tokenizers==0.20.3" einops addict easydict
pip install "flash-attn==2.7.3" --no-build-isolation
9.2 最小推理脚本(Transformers)
from transformers import AutoModel, AutoTokenizer
import torch, os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"model_name = "deepseek-ai/DeepSeek-OCR"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name,_attn_implementation="flash_attention_2",trust_remote_code=True,use_safetensors=True
).eval().cuda().to(torch.bfloat16)# 典型 OCR 指令(无版面/结构):
# prompt = "<image>\nFree OCR."# 保留版面/表格(Markdown 输出)更常用:
prompt = "<image>\n<|grounding|>Convert the document to markdown."image_file = "your_image.jpg"
output_path = "outputs"# infer(self, tokenizer, prompt='', image_file='', output_path=' ',
# base_size=1024, image_size=640, crop_mode=True, test_compress=False, save_results=False)
res = model.infer(tokenizer,prompt=prompt,image_file=image_file,output_path=output_path,base_size=1024, # Baseimage_size=640,crop_mode=True, # Gundam 动态分辨率save_results=True,test_compress=True # 输出压缩相关信息(可选)
)print(res)
9.3 vLLM 路线(高吞吐/批量 PDF)
# vLLM 最新版(当前需 nightly,具体以官方说明为准)
uv venv && source .venv/bin/activate
uv pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Imagellm = LLM(model="deepseek-ai/DeepSeek-OCR",enable_prefix_caching=False,mm_processor_cache_gb=0,logits_processors=[NGramPerReqLogitsProcessor], # n-gram/白名单约束
)image_1 = Image.open("1.png").convert("RGB")
image_2 = Image.open("2.png").convert("RGB")
prompt = "<image>\nFree OCR."model_input = [{"prompt": prompt, "multi_modal_data": {"image": image_1}},{"prompt": prompt, "multi_modal_data": {"image": image_2}},
]sampling_param = SamplingParams(temperature=0.0,max_tokens=8192,extra_args=dict(ngram_size=30,window_size=90,whitelist_token_ids={128821, 128822}, # 例如只允许 <td> 与 </td>),skip_special_tokens=False,
)outs = llm.generate(model_input, sampling_param)
for o in outs:print(o.outputs[0].text)
批量 PDF/评测脚本:官方仓库含
run_dpsk_ocr_pdf.py、run_dpsk_ocr_eval_batch.py,并给出并发与吞吐参考。
9.4 分辨率/模式与显存建议
- Tiny(512):64 token,超快,但细节损失多;
- Small(640):100 token,适合轻量部署;
- Base(1024):256 token,综合性价比高;
- Large(1280):400 token,复杂版面/小字更稳;
- Gundam(动态):主图 + 多裁剪,对小字/表格/脚注特别友好。
工程建议:先用 Base/Gundam 打基准,再按成本/精度切 Tiny/Small 或 Large。
十、Prompt 小抄(可直接复用)
# 文档转 Markdown(含版面)
<image>
<|grounding|>Convert the document to markdown.# 纯 OCR(只要文本,不要结构)
<image>
Free OCR.# 解析图表/示意图
<image>
Parse the figure.# 指定定位/引用
<image>
Locate <|ref|>“配料表”<|/ref|> in the image.
十一、应用场景与落地建议
- 票据/合同/发票/规范:结构保持、表格解析、页眉页脚处理;
- 扫描书籍/论文/专利:Markdown 保版式,适配后续 RAG/检索/标注;
- 多语言 OCR:跨语言混排(中英/日英等)鲁棒;
- 图表/公式/化学式:可抽取文本描述与结构标签,利于后处理。
结合工程实践的小贴士:
1)输入预处理:去噪、畸变矫正、对比度增强,尤其是手机拍照/曲面纸张;
2)大页/小字:优先 Gundam 或 Large;
3)表格提取:使用输出约束(表格标签白名单);
4)吞吐优化:vLLM + BF16 + FlashAttention;批量任务固定 base_size/image_size,方便缓存命中;
5)一致性评估:对压缩比-精度做网格搜索,找业务最优 sweet spot。
十二、局限与展望
- 超高压缩的损失:20× 压缩下的还原准确率明显下降(但可用于召回/预标注/粗读)。
- 格式与语义一致性:不同标注/输出规范会带来“格式差异 ≠ 识别错误”的评估偏差,需定制评测。
- 更广的长上下文验证:论文也提出未来会做**“数字-光学交错预训练”、“针堆测试(Needle-in-a-Haystack)”**等,以系统性验证“光学上下文记忆/遗忘”的价值。
十三、复现实验 Checklist(拿来即用)
- 环境:CUDA 11.8、PyTorch 2.6.0、Transformers 4.46.3、FlashAttention 2.7.3
- 硬件:≥8GB 显存(Base/Gundam 更推荐 20–40GB)
- 模式:先 Base/Gundam 打基线,再按预算调 Tiny/Small/Large
- 指令:Markdown 输出优先
<|grounding|>Convert the document to markdown. - 结构化:表格白名单/约束(如
<td>) - 批量:用 vLLM 脚本处理 PDF,记录压缩比-精度-时延三元组
十四、结语
DeepSeek-OCR 的关键不只在“识别的准”,而是把文档理解统一到一个“先压缩、再解码”的范式,让长上下文处理从堆长度(长文本 token)变为堆密度(视觉 token)。这条路一旦打通,LLM 的“记忆与成本”将被系统性重构。
参考资料(官方与社区,建议随文保留)
下面给出方便复制的链接(纯文本/代码块,不会在 CSDN 里触发公式/渲染问题)。
论文(arXiv):https://arxiv.org/abs/2510.18234
GitHub: https://github.com/deepseek-ai/DeepSeek-OCR
HuggingFace: https://huggingface.co/deepseek-ai/DeepSeek-OCR
vLLM 用法: https://docs.vllm.ai (站内搜索 DeepSeek-OCR 或参考 GitHub README)
更多第三方 UI/工具(示例):https://github.com/fufankeji/DeepSeek-OCR-Webhttps://github.com/newlxj/DeepSeek-OCR-Web-UI