[Linux]内核队列实现详解
Linux内核队列实现详解
目录
- 1. 概述
- 2. kfifo队列
- 2.1 基本结构
- 2.2 工作原理
- 2.3 主要操作函数
- 2.4 并发控制
- 2.5 应用场景
- 3. 工作队列(Workqueue)
- 3.1 基本结构
- 3.2 工作原理
- 3.3 主要操作函数
- 3.4 应用场景
- 4. 其他队列实现
- 4.1 等待队列(Wait Queue)
- 4.2 请求队列(Request Queue)
- 5. 应用实例
- 5.1 kfifo应用实例
- 5.2 工作队列应用实例
- 6. 最佳实践
- 7. 参考资料
1. 概述
队列是Linux内核中广泛使用的数据结构,用于在不同的内核组件之间传递数据或任务。Linux内核实现了多种队列,每种队列都有其特定的用途和特点。本文档将详细介绍Linux内核中的主要队列实现,包括kfifo队列和工作队列,以及它们的应用场景和最佳实践。
2. kfifo队列
kfifo是Linux内核中一个通用的、高效的先进先出(FIFO)队列实现。它最初由Rusty Russell编写,后来由Stefani Seibold重新设计和实现。kfifo主要用于在生产者和消费者之间传递数据,特别适合于字节流或固定大小元素的缓冲。
2.1 基本结构
kfifo的核心数据结构定义在include/linux/kfifo.h中:
struct __kfifo {unsigned int in; // 写入位置的索引unsigned int out; // 读取位置的索引unsigned int mask; // 缓冲区大小掩码(缓冲区大小-1)unsigned int esize; // 元素大小void *data; // 缓冲区指针
};
kfifo还定义了一系列宏来创建和操作不同类型的队列:
// 声明一个kfifo指针
#define DECLARE_KFIFO_PTR(fifo, type) STRUCT_KFIFO_PTR(type) fifo// 声明一个kfifo对象
#define DECLARE_KFIFO(fifo, type, size) STRUCT_KFIFO(type, size) fifo// 定义并初始化一个kfifo
#define DEFINE_KFIFO(fifo, type, size) \DECLARE_KFIFO(fifo, type, size) = \(typeof(fifo)) { \{ \{ \.in = 0, \.out = 0, \.mask = __is_kfifo_ptr(&(fifo)) ? \0 : \ARRAY_SIZE((fifo).buf) - 1, \.esize = sizeof(*(fifo).buf), \.data = __is_kfifo_ptr(&(fifo)) ? \NULL : \(fifo).buf, \} \} \}
2.2 工作原理
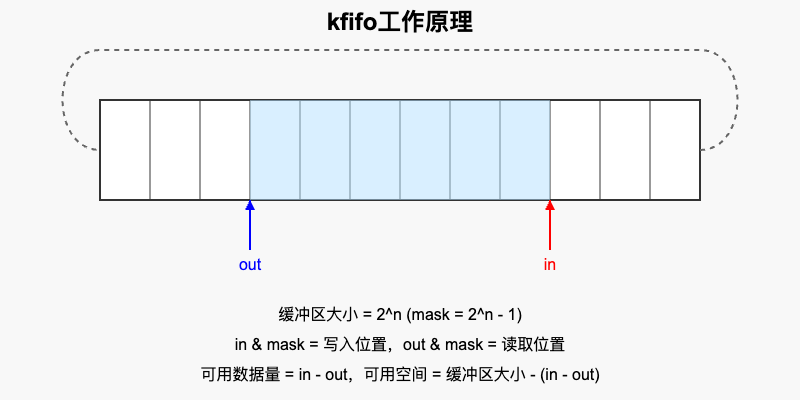
kfifo使用环形缓冲区来实现FIFO队列。环形缓冲区是一个固定大小的数组,通过两个索引(in和out)来跟踪数据的写入和读取位置。
- 初始化 - 缓冲区大小必须是2的幂,这样可以使用位操作代替取模操作
- 入队(写入) - 数据写入
in索引指向的位置,然后in增加 - 出队(读取) - 数据从
out索引指向的位置读取,然后out增加 - 环形操作 - 当
in或out达到缓冲区末尾时,通过与mask进行位与操作实现环形回绕
2.3 主要操作函数
kfifo提供了一系列函数来操作队列:
2.3.1 初始化和销毁
// 分配一个新的kfifo
int kfifo_alloc(struct kfifo *fifo, unsigned int size, gfp_t gfp_mask);// 释放kfifo
void kfifo_free(struct kfifo *fifo);// 使用预分配的缓冲区初始化kfifo
int kfifo_init(struct kfifo *fifo, void *buffer, unsigned int size);// 重置kfifo
void kfifo_reset(struct kfifo *fifo);
2.3.2 数据操作
// 将数据放入kfifo
unsigned int kfifo_in(struct kfifo *fifo, const void *buf, unsigned int len);// 从kfifo获取数据
unsigned int kfifo_out(struct kfifo *fifo, void *buf, unsigned int len);// 查看kfifo中的数据,但不移除
unsigned int kfifo_out_peek(struct kfifo *fifo, void *buf, unsigned int len);// 获取kfifo中的数据长度
unsigned int kfifo_len(struct kfifo *fifo);// 获取kfifo中的可用空间
unsigned int kfifo_avail(struct kfifo *fifo);// 检查kfifo是否为空
int kfifo_is_empty(struct kfifo *fifo);// 检查kfifo是否已满
int kfifo_is_full(struct kfifo *fifo);
2.4 并发控制
kfifo本身不提供锁机制,但它在设计上支持无锁操作:
- 单生产者单消费者 - 在这种情况下,不需要额外的锁
- 多生产者 - 需要在生产者之间使用锁
- 多消费者 - 需要在消费者之间使用锁
kfifo提供了带锁的操作函数,如kfifo_in_spinlocked和kfifo_out_spinlocked,用于多生产者或多消费者场景:
// 在自旋锁保护下将数据放入kfifo
unsigned int kfifo_in_spinlocked(struct kfifo *fifo, const void *buf,unsigned int len, spinlock_t *lock);// 在自旋锁保护下从kfifo获取数据
unsigned int kfifo_out_spinlocked(struct kfifo *fifo, void *buf,unsigned int len, spinlock_t *lock);
2.5 应用场景
kfifo适用于以下场景:
- 字符设备驱动中的缓冲区 - 用于缓冲用户空间和内核空间之间的数据传输
- 网络协议栈中的数据包缓冲 - 用于缓冲网络数据包
- 音频/视频驱动中的数据缓冲 - 用于缓冲音频/视频数据
- 中断处理程序和内核线程之间的通信 - 用于在中断上下文和进程上下文之间传递数据
3. 工作队列(Workqueue)
工作队列是Linux内核中用于异步执行内核函数的机制。它允许内核代码将工作推迟到稍后由专用内核线程(称为工作者线程,worker thread)执行。工作队列特别适合于需要在进程上下文中执行但不能在当前上下文中立即执行的操作。
3.1 基本结构
工作队列的核心数据结构定义在kernel/workqueue.c和include/linux/workqueue.h中:
3.1.1 工作项(work_struct)
struct work_struct {atomic_long_t data;struct list_head entry;work_func_t func;
#ifdef CONFIG_LOCKDEPstruct lockdep_map lockdep_map;
#endif
};
work_struct表示一个工作项,包含要执行的函数和相关数据。
3.1.2 工作队列(workqueue_struct)
struct workqueue_struct {struct list_head pwqs; /* WR: all pwqs of this wq */struct list_head list; /* PR: list of all workqueues */struct mutex mutex; /* protects this wq */int work_color; /* WQ: current work color */int flush_color;/* WQ: current flush color */atomic_t nr_pwqs_to_flush; /* flush in progress */struct wq_flusher *first_flusher; /* WQ: first flusher */struct list_head flusher_queue; /* WQ: flush waiters */struct list_head flusher_overflow; /* WQ: flush overflow list */struct list_head maydays; /* MD: pwqs requesting rescue */struct worker *rescuer; /* I: rescue worker */int nr_drainers;/* WQ: drain in progress */int saved_max_active; /* WQ: saved pwq max_active */struct workqueue_attrs *unbound_attrs; /* PW: only for unbound wqs */struct pool_workqueue *dfl_pwq; /* PW: only for unbound wqs */#ifdef CONFIG_SYSFSstruct wq_device *wq_dev; /* I: for sysfs interface */
#endif
#ifdef CONFIG_LOCKDEPstruct lockdep_map lockdep_map;
#endifchar name[WQ_NAME_LEN]; /* I: workqueue name *//* hot fields used during command issue, aligned to cacheline */unsigned int flags ____cacheline_aligned; /* WQ: WQ_* flags */struct pool_workqueue __percpu *cpu_pwqs; /* I: per-cpu pwqs */struct pool_workqueue __rcu *numa_pwq_tbl[]; /* PWR: unbound pwqs indexed by node */
};
workqueue_struct表示一个工作队列,管理工作项的执行。
3.2 工作原理
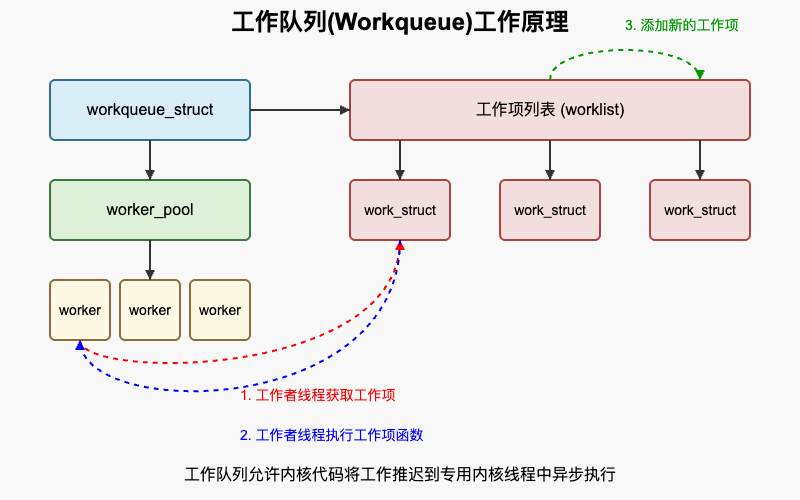
工作队列的工作原理可以概括为以下几个步骤:
- 创建工作队列 - 通过
alloc_workqueue()或create_workqueue()创建一个工作队列 - 初始化工作项 - 通过
INIT_WORK()初始化一个工作项,指定要执行的函数 - 提交工作项 - 通过
queue_work()或queue_delayed_work()将工作项提交到工作队列 - 执行工作项 - 工作者线程从工作队列中取出工作项并执行
- 等待完成 - 可以通过
flush_work()或flush_workqueue()等待工作项完成
3.3 主要操作函数
工作队列提供了一系列函数来操作工作项和工作队列:
3.3.1 工作队列操作
// 创建工作队列
struct workqueue_struct *alloc_workqueue(const char *fmt,unsigned int flags,int max_active, ...);// 销毁工作队列
void destroy_workqueue(struct workqueue_struct *wq);// 刷新工作队列
void flush_workqueue(struct workqueue_struct *wq);// 排空工作队列
void drain_workqueue(struct workqueue_struct *wq);
3.3.2 工作项操作
// 初始化工作项
#define INIT_WORK(_work, _func) \__INIT_WORK((_work), (_func), 0)// 初始化延迟工作项
#define INIT_DELAYED_WORK(_work, _func) \__INIT_DELAYED_WORK(_work, _func, TIMER_INITIALIZER)// 将工作项提交到工作队列
bool queue_work(struct workqueue_struct *wq, struct work_struct *work);// 将工作项提交到特定CPU的工作队列
bool queue_work_on(int cpu, struct workqueue_struct *wq,struct work_struct *work);// 将延迟工作项提交到工作队列
bool queue_delayed_work(struct workqueue_struct *wq,struct delayed_work *dwork,unsigned long delay);// 取消工作项
bool cancel_work_sync(struct work_struct *work);// 取消延迟工作项
bool cancel_delayed_work_sync(struct delayed_work *dwork);// 刷新工作项
bool flush_work(struct work_struct *work);// 刷新延迟工作项
bool flush_delayed_work(struct delayed_work *dwork);
3.4 应用场景
工作队列适用于以下场景:
- 中断处理程序中的耗时操作 - 将耗时操作推迟到工作队列中执行,避免长时间禁用中断
- 设备驱动中的异步操作 - 处理设备事件,如热插拔、状态变化等
- 定时执行任务 - 使用延迟工作项定时执行任务
- 需要在进程上下文中执行的操作 - 工作队列在进程上下文中执行,可以睡眠
4. 其他队列实现
4.1 等待队列(Wait Queue)
等待队列是Linux内核中用于进程等待特定事件的机制。它允许进程在等待条件满足时睡眠,并在条件满足时被唤醒。
4.1.1 基本结构
struct wait_queue_head {spinlock_t lock;struct list_head task_list;
};
typedef struct wait_queue_head wait_queue_head_t;
4.1.2 主要操作函数
// 初始化等待队列头
void init_waitqueue_head(wait_queue_head_t *q);// 等待事件
#define wait_event(wq, condition) \__wait_event(wq, condition)// 可中断的等待事件
#define wait_event_interruptible(wq, condition) \__wait_event_interruptible(wq, condition)// 唤醒等待队列中的一个进程
void wake_up(wait_queue_head_t *q);// 唤醒等待队列中的所有进程
void wake_up_all(wait_queue_head_t *q);
4.2 请求队列(Request Queue)
请求队列是Linux内核中用于块设备I/O请求的队列。它管理对块设备的读写请求,并优化请求的顺序以提高性能。
4.2.1 基本结构
struct request_queue {/** Together with queue_head for cacheline sharing*/struct list_head queue_head;struct request *last_merge;struct elevator_queue *elevator;int nr_rqs[2]; /* # allocated [0] or active [1] reqs */int nr_rqs_elvpriv; /* # allocated elvpriv reqs *//** q->lock is held here, and driver can't access the queue* anymore.*/int dying;/* ... */
};
4.2.2 主要操作函数
// 创建请求队列
struct request_queue *blk_init_queue(request_fn_proc *rfn, spinlock_t *lock);// 销毁请求队列
void blk_cleanup_queue(struct request_queue *q);// 提交请求
void blk_queue_bio(struct request_queue *q, struct bio *bio);// 启动请求队列
void blk_start_queue(struct request_queue *q);// 停止请求队列
void blk_stop_queue(struct request_queue *q);
4.3 网络数据包队列(SKB队列)
SKB队列管理 struct sk_buff 链表,在网络子系统中广泛用于包缓冲与排队。其核心结构与接口定义在 include/linux/skbuff.h 与 net/core/skbuff.c。
4.3.1 基本结构
struct sk_buff_head {struct sk_buff *next;struct sk_buff *prev;__u32 qlen; // 队列长度spinlock_t lock; // 内部自旋锁(可选)
};
4.3.2 主要操作函数
// 初始化队列
void skb_queue_head_init(struct sk_buff_head *list);// 入队(尾部/头部)
void skb_queue_tail(struct sk_buff_head *list, struct sk_buff *newsk);
void skb_queue_head(struct sk_buff_head *list, struct sk_buff *newsk);// 出队(头部)
struct sk_buff *skb_dequeue(struct sk_buff_head *list);// 查看但不移除
struct sk_buff *skb_peek(const struct sk_buff_head *list);// 状态判断
bool skb_queue_empty(const struct sk_buff_head *list);
SKB 队列通常在需要显式并发保护时结合自旋锁使用:要么使用队列内部锁的 API(如 skb_queue_tail),要么在外部加锁再调用 __skb_* 变体以获得更精细控制。
4.4 指针环形队列(ptr_ring)
ptr_ring 是轻量的指针环形队列,适合单生产者/单消费者的高性能场景,广泛用于 virtio-net 等路径。实现位于 lib/ptr_ring.c。
4.4.1 基本结构与特性
- 固定容量环形缓冲,元素为指针
- 可配置的锁策略:完全锁内保护或外部锁配合无锁快路径
- 支持快速判满/判空与批量搬运
4.4.2 主要操作函数
int ptr_ring_init(struct ptr_ring *r, int size, gfp_t gfp);
void ptr_ring_cleanup(struct ptr_ring *r);
int ptr_ring_produce(struct ptr_ring *r, void *ptr);
void *ptr_ring_consume(struct ptr_ring *r);
bool ptr_ring_full(struct ptr_ring *r);
bool ptr_ring_empty(struct ptr_ring *r);
4.5 锁无关链表(llist)
llist 提供无锁、单消费者/多生产者的链表,常与工作队列等机制配合以降低锁开销。定义在 include/linux/llist.h。
4.5.1 主要操作函数
// 生产者添加节点(无锁)
bool llist_add(struct llist_node *new, struct llist_head *head);// 消费者一次性获取并清空所有节点(无锁)
struct llist_node *llist_del_all(struct llist_head *head);
典型用法为:多个生产者将任务结构的 llist_node 无锁追加到队列,单个消费者在安全点调用 llist_del_all() 批量取走并处理。
5. 应用实例
5.1 kfifo应用实例
5.1.1 字符设备驱动中的缓冲区
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/cdev.h>
#include <linux/device.h>
#include <linux/kfifo.h>
#include <linux/slab.h>
#include <linux/uaccess.h>#define DEVICE_NAME "kfifo_example"
#define FIFO_SIZE 1024struct kfifo_example_dev {struct cdev cdev;struct kfifo fifo;struct mutex lock;wait_queue_head_t read_queue;wait_queue_head_t write_queue;
};static struct kfifo_example_dev *example_dev;
static dev_t dev_num;
static struct class *example_class;static int example_open(struct inode *inode, struct file *filp)
{filp->private_data = example_dev;return 0;
}static int example_release(struct inode *inode, struct file *filp)
{return 0;
}static ssize_t example_read(struct file *filp, char __user *buf,size_t count, loff_t *f_pos)
{struct kfifo_example_dev *dev = filp->private_data;unsigned int copied;int ret;if (kfifo_is_empty(&dev->fifo)) {if (filp->f_flags & O_NONBLOCK)return -EAGAIN;ret = wait_event_interruptible(dev->read_queue,!kfifo_is_empty(&dev->fifo));if (ret)return ret;}mutex_lock(&dev->lock);ret = kfifo_to_user(&dev->fifo, buf, count, &copied);mutex_unlock(&dev->lock);if (ret)return ret;wake_up_interruptible(&dev->write_queue);return copied;
}static ssize_t example_write(struct file *filp, const char __user *buf,size_t count, loff_t *f_pos)
{struct kfifo_example_dev *dev = filp->private_data;unsigned int copied;int ret;if (kfifo_is_full(&dev->fifo)) {if (filp->f_flags & O_NONBLOCK)return -EAGAIN;ret = wait_event_interruptible(dev->write_queue,!kfifo_is_full(&dev->fifo));if (ret)return ret;}mutex_lock(&dev->lock);ret = kfifo_from_user(&dev->fifo, buf, count, &copied);mutex_unlock(&dev->lock);if (ret)return ret;wake_up_interruptible(&dev->read_queue);return copied;
}static const struct file_operations example_fops = {.owner = THIS_MODULE,.open = example_open,.release = example_release,.read = example_read,.write = example_write,
};static int __init example_init(void)
{int ret;ret = alloc_chrdev_region(&dev_num, 0, 1, DEVICE_NAME);if (ret < 0)return ret;example_class = class_create(THIS_MODULE, DEVICE_NAME);if (IS_ERR(example_class)) {ret = PTR_ERR(example_class);goto fail_class_create;}example_dev = kmalloc(sizeof(struct kfifo_example_dev), GFP_KERNEL);if (!example_dev) {ret = -ENOMEM;goto fail_alloc;}ret = kfifo_alloc(&example_dev->fifo, FIFO_SIZE, GFP_KERNEL);if (ret) {ret = -ENOMEM;goto fail_kfifo;}mutex_init(&example_dev->lock);init_waitqueue_head(&example_dev->read_queue);init_waitqueue_head(&example_dev->write_queue);cdev_init(&example_dev->cdev, &example_fops);example_dev->cdev.owner = THIS_MODULE;ret = cdev_add(&example_dev->cdev, dev_num, 1);if (ret)goto fail_cdev;device_create(example_class, NULL, dev_num, NULL, DEVICE_NAME);return 0;fail_cdev:kfifo_free(&example_dev->fifo);
fail_kfifo:kfree(example_dev);
fail_alloc:class_destroy(example_class);
fail_class_create:unregister_chrdev_region(dev_num, 1);return ret;
}static void __exit example_exit(void)
{device_destroy(example_class, dev_num);cdev_del(&example_dev->cdev);kfifo_free(&example_dev->fifo);kfree(example_dev);class_destroy(example_class);unregister_chrdev_region(dev_num, 1);
}module_init(example_init);
module_exit(example_exit);MODULE_LICENSE("GPL");
MODULE_AUTHOR("Example Author");
MODULE_DESCRIPTION("kfifo example driver");
5.2 工作队列应用实例
5.2.1 延迟执行任务
#include <linux/module.h>
#include <linux/workqueue.h>
#include <linux/slab.h>
#include <linux/jiffies.h>struct delayed_task {struct work_struct work;struct workqueue_struct *wq;struct delayed_work delayed_work;unsigned long delay_jiffies;
};static struct delayed_task *task;static void work_handler(struct work_struct *work)
{struct delayed_task *task = container_of(work, struct delayed_task, work);printk(KERN_INFO "Regular work executed\n");
}static void delayed_work_handler(struct work_struct *work)
{struct delayed_work *delayed_work = container_of(work, struct delayed_work, work);struct delayed_task *task = container_of(delayed_work, struct delayed_task, delayed_work);printk(KERN_INFO "Delayed work executed after %ld jiffies\n", task->delay_jiffies);
}static int __init workqueue_example_init(void)
{task = kmalloc(sizeof(struct delayed_task), GFP_KERNEL);if (!task)return -ENOMEM;task->wq = create_singlethread_workqueue("example_workqueue");if (!task->wq) {kfree(task);return -ENOMEM;}INIT_WORK(&task->work, work_handler);INIT_DELAYED_WORK(&task->delayed_work, delayed_work_handler);task->delay_jiffies = msecs_to_jiffies(1000); /* 1 second *//* Queue regular work */queue_work(task->wq, &task->work);/* Queue delayed work */queue_delayed_work(task->wq, &task->delayed_work, task->delay_jiffies);return 0;
}static void __exit workqueue_example_exit(void)
{cancel_work_sync(&task->work);cancel_delayed_work_sync(&task->delayed_work);destroy_workqueue(task->wq);kfree(task);
}module_init(workqueue_example_init);
module_exit(workqueue_example_exit);MODULE_LICENSE("GPL");
MODULE_AUTHOR("Example Author");
MODULE_DESCRIPTION("Workqueue example");
5.3 SKB队列应用实例(网络驱动接收路径简化)
#include <linux/netdevice.h>
#include <linux/skbuff.h>struct rx_ctx {struct sk_buff_head rxq; // 接收队列spinlock_t lock; // 外部锁(可选)
};static void rx_ctx_init(struct rx_ctx *ctx)
{skb_queue_head_init(&ctx->rxq);spin_lock_init(&ctx->lock);
}// 生产者:中断/轮询收到数据包
static void rx_produce(struct rx_ctx *ctx, struct sk_buff *skb)
{// 内部带锁版本,简化并发skb_queue_tail(&ctx->rxq, skb);
}// 消费者:NAPI/poll 或后台线程取包处理
static struct sk_buff *rx_consume(struct rx_ctx *ctx)
{return skb_dequeue(&ctx->rxq);
}static void rx_process_all(struct rx_ctx *ctx)
{struct sk_buff *skb;while ((skb = rx_consume(ctx)) != NULL) {// 处理数据包,例如:netif_receive_skb(skb);kfree_skb(skb);}
}
要获得更高性能,驱动可在外部持锁并使用 __skb_queue_tail / __skb_dequeue 成对调用,以减少锁操作次数。
5.4 ptr_ring应用实例(virtio风格生产/消费)
#include <linux/ptr_ring.h>struct io_ring {struct ptr_ring ring;spinlock_t lock; // 若选择外部锁策略
};static int io_ring_init(struct io_ring *r, int size)
{int ret = ptr_ring_init(&r->ring, size, GFP_KERNEL);if (ret)return ret;spin_lock_init(&r->lock);return 0;
}static void io_ring_cleanup(struct io_ring *r)
{ptr_ring_cleanup(&r->ring);
}static int io_produce(struct io_ring *r, void *ptr)
{int ret;spin_lock(&r->lock);ret = ptr_ring_produce(&r->ring, ptr);spin_unlock(&r->lock);return ret; // 0 成功,-ENOSPC 等表示队列已满
}static void *io_consume(struct io_ring *r)
{void *ptr;spin_lock(&r->lock);ptr = ptr_ring_consume(&r->ring);spin_unlock(&r->lock);return ptr; // NULL 表示队列为空
}
在单生产者/单消费者路径中,可选择无需外部锁的配置以进一步降低锁开销。
6. 最佳实践
6.1 kfifo最佳实践
- 选择合适的缓冲区大小 - 缓冲区大小应该是2的幂,并且足够大以容纳预期的数据量
- 正确处理并发 - 在多生产者或多消费者场景中使用适当的锁
- 检查返回值 - 始终检查kfifo操作函数的返回值,以确保操作成功
- 避免数据复制 - 尽可能使用零复制技术,如DMA操作
- 使用类型安全的接口 - 使用类型安全的宏和函数,避免类型转换错误
6.2 工作队列最佳实践
- 选择合适的工作队列类型 - 根据需求选择绑定或非绑定工作队列
- 避免长时间运行的工作 - 工作项应该尽快完成,避免阻塞工作者线程
- 正确处理工作项取消 - 使用
cancel_work_sync()或cancel_delayed_work_sync()安全地取消工作项 - 避免死锁 - 不要在持有锁的情况下等待工作项完成
- 使用系统工作队列 - 对于简单的任务,使用系统提供的工作队列,如
system_wq
7. 参考资料
- Linux内核源代码:include/linux/kfifo.h
- Linux内核源代码:kernel/workqueue.c
- Linux内核文档:Documentation/workqueue.txt
- 《Linux设备驱动程序》,作者:Jonathan Corbet, Alessandro Rubini, Greg Kroah-Hartman
- 《Linux内核设计与实现》,作者:Robert Love