通义DeepResearch技术报告解读
通义深度研究:开源AI研究助手的新里程碑
最近AI研究领域有个很有意思的现象,就是那些最厉害的AI研究助手,比如OpenAI的DeepResearch、谷歌的Gemini DeepResearch,全都是闭源的。这就像大家都在说"我做出了很棒的东西",但就是不告诉你怎么做的。阿里巴巴通义实验室最近开源的通义深度研究(Tongyi DeepResearch)终于打破了这个局面,而且性能还相当能打。
为什么需要开源的深度研究AI?
想象一下,你要写一篇深度报告,需要在互联网上搜索大量资料,整理归纳,最后形成结论。这个过程可能要花你好几个小时。而深度研究AI就是要把这个时间压缩到几分钟,让AI自主完成多步骤推理和信息搜集。
但问题来了,现在市面上能做这事儿的AI系统基本都是黑盒子。你不知道它们是怎么训练的,用了什么数据,采用了什么方法。这对整个学术界和开发者社区来说其实挺不友好的,因为没法复现结果,也没法在此基础上继续改进。
通义深度研究的出现就是为了解决这个问题。它不仅开源了模型,还把完整的训练框架、数据合成方法全都公开了。更厉害的是,它在多个基准测试上都达到了最先进水平,证明开源也能做到业界顶尖。
核心创新:智能体训练的新范式
传统的大语言模型训练主要是让模型学会"说话",但要让它成为一个能自主研究的智能体,光会说话可不够。通义深度研究提出了一个端到端的训练框架,分成两个关键阶段。

智能体中期训练:从"说话"到"做事"
第一阶段叫"智能体中期训练",这其实是在普通预训练和专业智能体能力之间搭了一座桥。你可以把它理解成让模型从"知道怎么说"过渡到"知道怎么做"。
这个阶段最巧妙的地方是它的数据合成方式。研究团队设计了一套完整的智能体工作流程模型,包括怎么规划任务、怎么推理、怎么做决策。然后通过自动化方式生成大量训练数据,完全不需要人工标注。
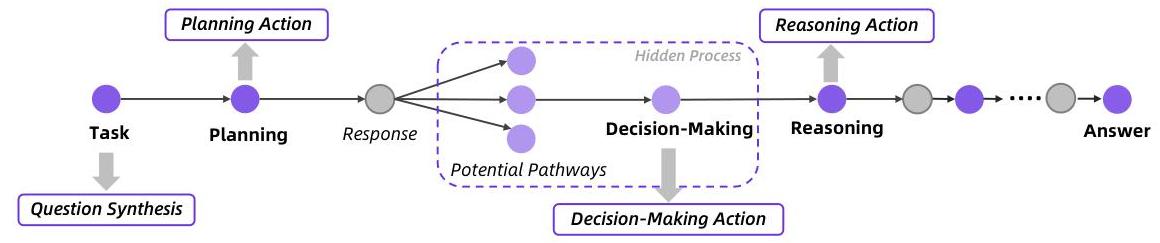
比如说,系统会先生成各种研究领域的复杂问题,然后自动生成智能体应该如何把这个大问题分解成小步骤,每一步该做什么推理,该调用什么工具。这种数据不是简单的问答对,而是完整的"思考-行动"序列,让模型真正学会像研究人员一样工作。
智能体后训练:精益求精
第二阶段包括监督微调和强化学习。这里有个很有意思的设计叫"上下文管理模式"。
做深度研究的时候,上下文会越来越长——你要记住原始问题、已经收集的信息、正在写的报告。如果不加处理,模型很容易"记不住"之前的内容。通义深度研究的做法是给智能体构建一个"工作空间",把最关键的信息(问题、当前报告、即时上下文)组织在一起,这样既不会超出上下文限制,又能保持任务的连贯性。
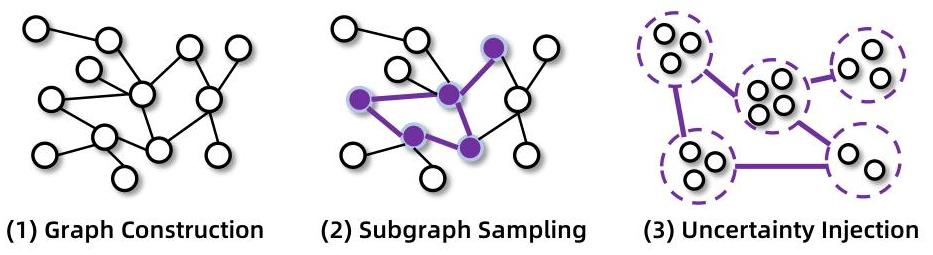
数据生成方面也很讲究。系统先构建知识图谱,然后从中采样子图,再故意增加一些不确定性和难度,生成真正有挑战性的问题。这就像给学生出题,不能太简单,要让它动脑子才行。
强化学习:在三个世界里训练
强化学习阶段的设计尤其巧妙。团队设计了三种环境,每种都有各自的用途。
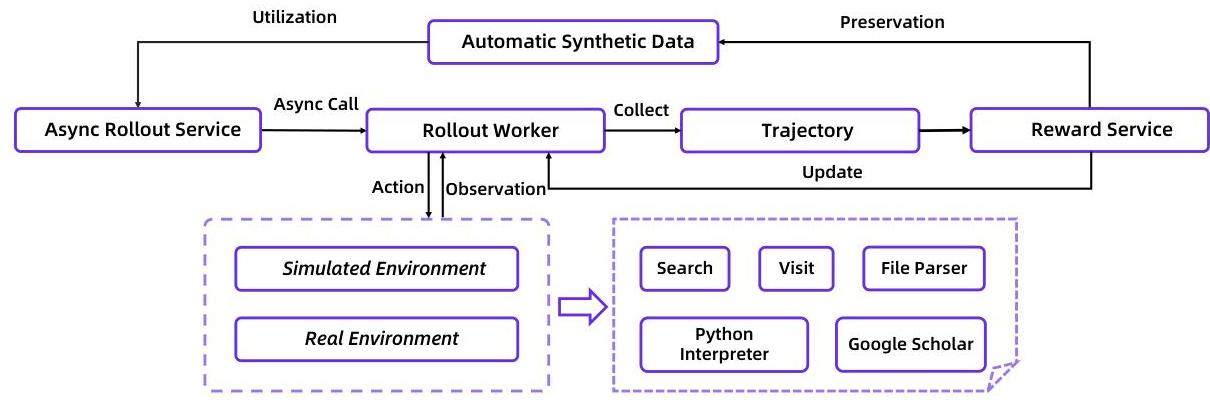
"先验世界"是从模型自己的预训练知识里挖掘出来的,成本低、稳定性好,适合快速迭代。"模拟环境"提供可控的、可重现的交互,让你能快速测试新想法。"真实世界"则直接接入谷歌搜索、网页解析等真实工具,给模型提供真实反馈。
这三种环境配合使用,既保证了训练的稳定性和效率,又确保模型能在真实场景中表现良好。就像飞行员训练一样,有模拟器练基本功,也要真机实飞积累经验。
实战表现:既强大又高效
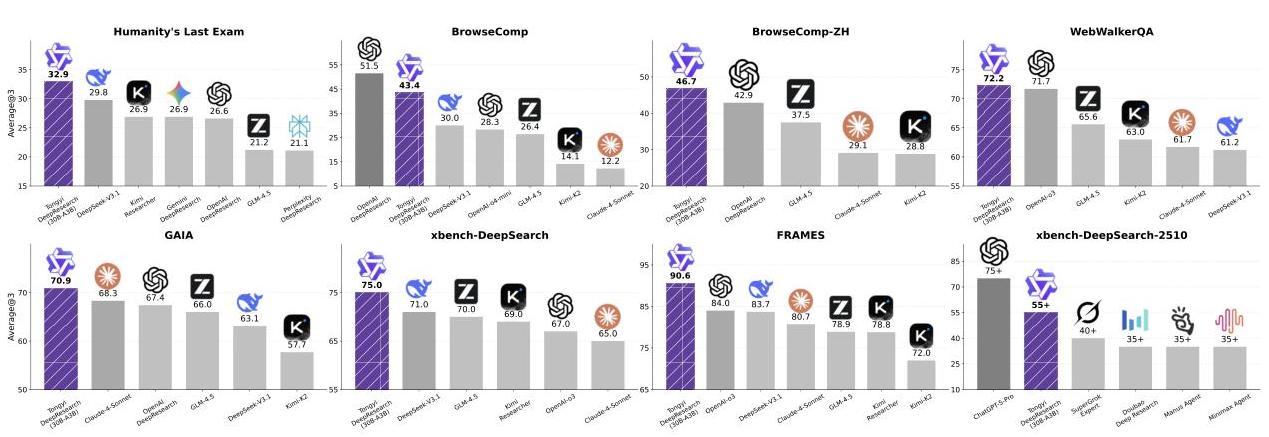
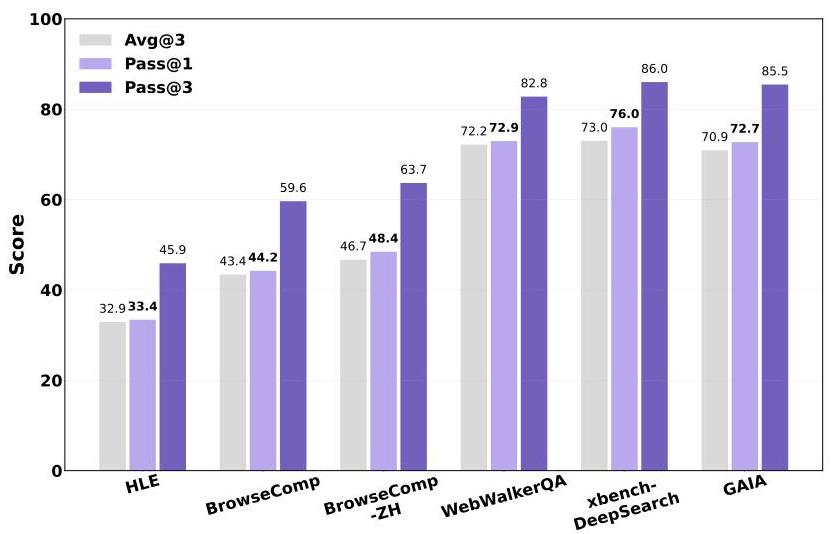
通义深度研究在多个高难度基准上都刷新了记录。在"人类的最后考试"(Humanity’s Last Exam)这个超难的测试中,它拿到了32.9%的成绩,听起来不高,但要知道这个考试难到什么程度——它包含的问题连人类专家都不一定能答对。
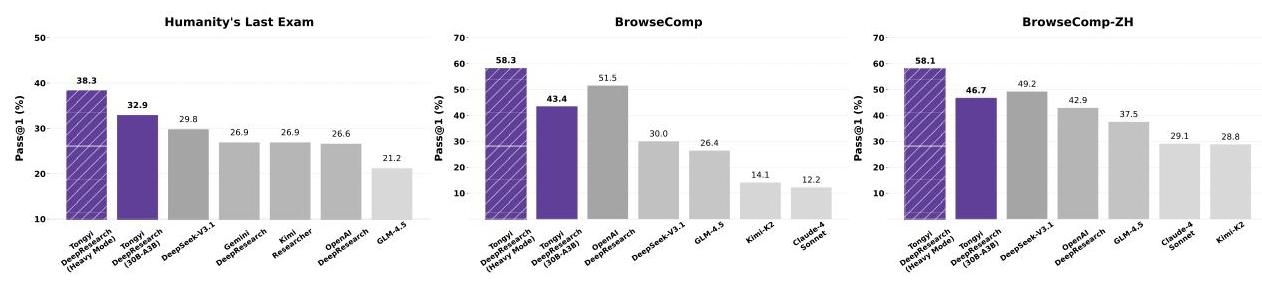
更让人印象深刻的是效率。整个模型基于Qwen3-30B,总参数量305亿,但每个token只激活33亿参数。这意味着它能在相对普通的硬件上运行,不需要像某些大模型那样动辄需要几百张GPU卡。
团队还开发了一个"重度模式",简单说就是同时跑多个智能体并行工作,最后把结果综合起来。这种模式下,"人类的最后考试"的成绩进一步提升到38.3%,在BrowseComp测试中达到58.3%。
训练过程的稳定性
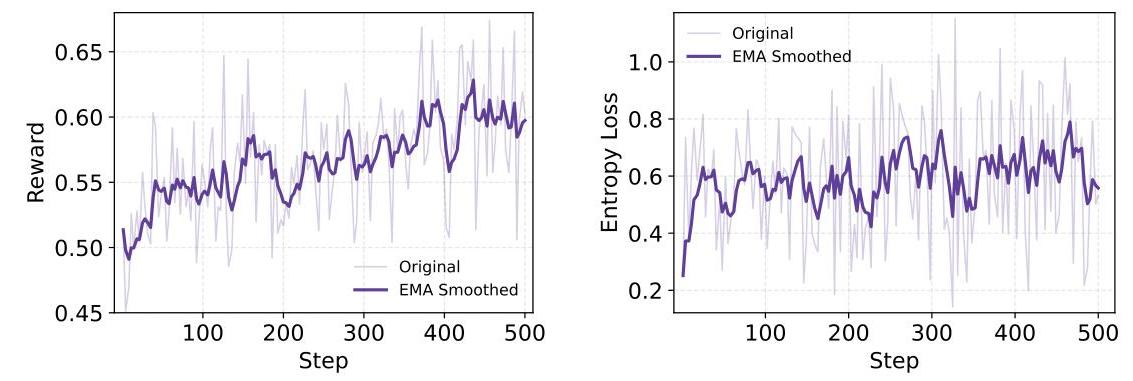
做强化学习最怕的就是训练不稳定,策略容易崩溃。通义深度研究在这方面表现很稳健,从训练曲线可以看出,奖励稳步上升,策略熵(代表探索程度)保持一致,说明模型在学习过程中既能不断进步,又不会忘记之前学到的东西。
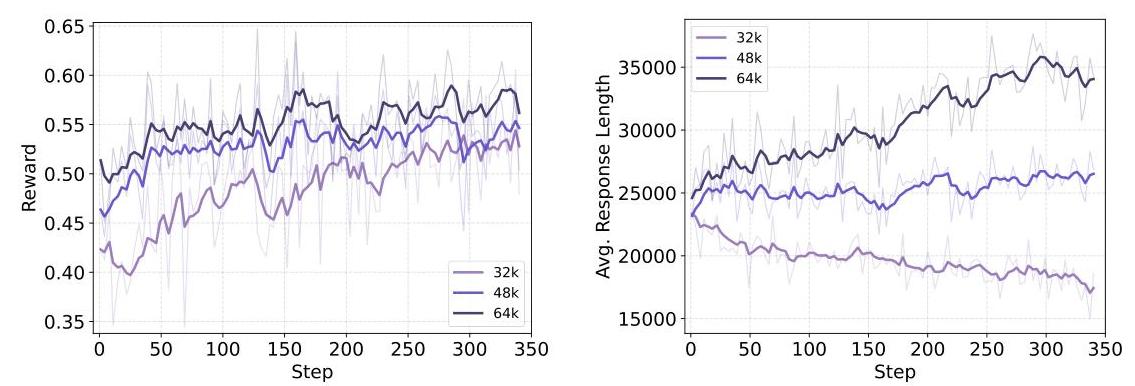
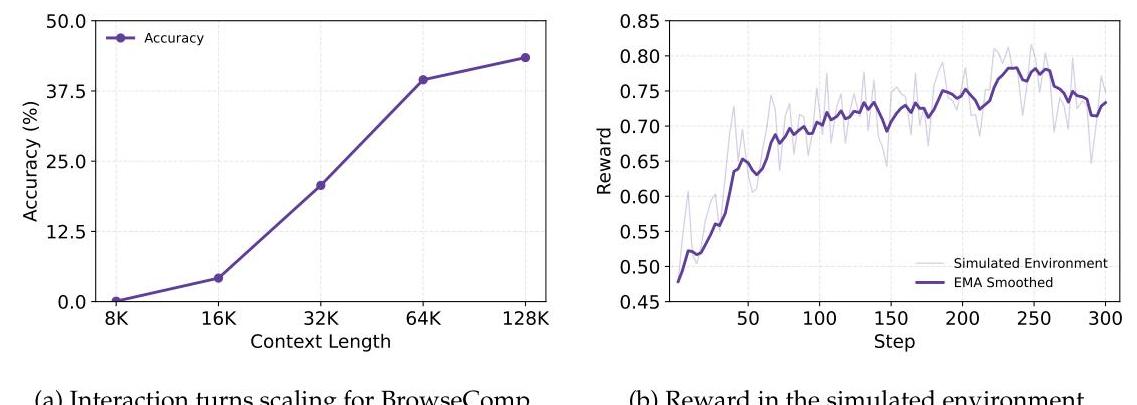
研究团队还做了很多实验分析。比如上下文长度的影响——更长的上下文确实能带来更高的性能上限,但有限上下文的模型也能找到更高效的解决方案。模拟环境和真实环境的奖励曲线高度吻合,证明模拟环境确实是个有效的"实验室"。
对AI研究的意义
通义深度研究的开源不仅仅是发布一个模型那么简单,它代表了几个重要的进步。
首先是方法论的突破。智能体中期训练这个概念可能会成为未来训练智能体模型的标准做法。它明确了如何让语言模型从"能理解"到"能行动"。
其次是数据合成的创新。完全自动化的数据合成管道,不需要人工标注就能生成高质量、多样化的训练数据。这对很多领域的AI开发都有借鉴意义,毕竟人工标注又贵又慢。
再就是效率的提升。33亿激活参数就能达到顶尖水平,这让高级AI能力不再是少数人的专利。你不需要超级计算机,普通服务器就能跑。
最重要的是开放的态度。通过开源模型、框架和完整解决方案,通义深度研究为整个社区提供了一个可以在其基础上继续创新的平台。这才是真正推动技术进步的方式。
讨论
通义深度研究让我们看到了一个可能性:AI助手不仅能回答问题,还能真正像研究人员一样工作——自主规划研究路径,搜集和分析信息,最后形成有深度的结论。
这种能力的普及意味着什么?对普通用户来说,可能意味着几分钟就能完成过去需要几小时的研究工作。对研究人员来说,可以把精力放在更高层次的创造性思考上,让AI处理信息收集和初步分析。对开发者来说,有了一个可以学习和改进的开源基础。
当然,这还不是终点。通义深度研究是迈向通用人工智能的一步,但要让AI真正能在各个领域自主推理和行动,还有很长的路要走。不过至少现在,这条路已经向所有人开放了。