AI推理计算需求飞升,在传统路径外,聚焦异构计算发展
引言
当下,人工智能正以前所未有的速度渗透到我们生活的方方面面。从最初的云端大规模模型训练,到如今智能终端、自动驾驶、推荐系统等诸多前沿应用对本地化、实时化推理能力的迫切需求,AI应用正从传统的云端中心向边缘设备广泛扩展。这一趋势直接导致了推理计算需求的指数级激增,对计算系统的性能、能效和响应速度提出了前所未有的严苛挑战。
然而,面对这些海量且对时延高度敏感的推理任务,传统的单一架构计算模式,如纯粹依赖中央处理器(CPU)的系统,已显得力不从心。它难以在有限的功耗、成本和空间约束下,同时满足高并发、低延迟和高吞吐量的严苛要求。正是在这样的背景下,异构计算——一种整合多种类型处理器协同工作的新型计算模式,正日益成为AI时代破局的关键解决方案。推理计算需求的指数级增长,不仅推动着异构计算从一个新兴概念逐步演变为当今计算领域的主流技术,更预示着它将深刻重塑未来的计算范式,引领我们进入一个更加高效、智能的数字世界。本文将深入探讨异构计算的背景、发展、核心原理及其在AI推理加速中的关键作用,以期为读者全面展现这一变革性技术图景。
- 异构计算的背景及发展概述
人工智能大模型(LLM)的飞速发展,带来了前所未有的计算需求,其规模和复杂度的持续增长,使得推理环节面临巨大挑战。百亿级参数模型对内存的巨大开销、注意力机制和前向传播的计算密集性、对话应用对低延迟的敏感性、以及高并发服务对吞吐量的需求,都让传统通用或同构计算架构难以招架。此外,受限于经典的冯·诺依曼架构,CPU在数据密集型任务中频繁进行数据搬运,不仅效率低下,还造成了巨大的能耗。为突破这一瓶颈,提升整体系统的能效比并有效降低运营成本,业界迫切需要一种更高效的计算范式。

图1: AI推理加速与异构计算的广泛行业应用及合作生态
正是在这一系列挑战的驱动下,异构计算应运而生并迅速发展。异构计算(Heterogeneous Computing)的核心定义,便是在一个计算系统中融合不同类型、指令集和体系架构的计算单元,使它们协同工作。这些计算单元通常包括中央处理器(CPU)、图形处理器(GPU)、现场可编程门阵列(FPGA)和专用集成电路(ASIC)等。它的核心特征在于架构的多样性、任务级的并行处理以及潜在的内存异构性。相较于单一处理器,异构计算能更经济高效地实现高计算能力,具备强大的可扩展性和资源利用率,从而在性能、能效和成本效益上展现出显著优势。

图2: 异构计算系统中的多核处理单元协同工作示意图
异构计算的核心工作原理在于“任务分配与调度”。系统会首先对计算任务进行精细分析和分类,识别其计算特性,例如哪些是顺序逻辑控制、哪些是高并行度的密集计算、哪些需要极致低延迟。随后,系统将任务智能地匹配给最适合的计算单元——CPU擅长复杂逻辑控制,GPU精于大规模并行运算,FPGA则提供定制化的高效加速。通过这种协同工作与动态调整机制,不同类型的硬件各司其职,充分发挥各自的专长,共同完成整体计算任务,最大化系统性能并优化能耗。在主流异构计算架构方面,通用图形处理器(GPGPU)及其CPU-GPU协同模式占据主导地位。NVIDIA公司推出的CUDA(Compute Unified Device Architecture)编程模型是其中最具代表性的软件框架,它为开发者提供了面向GPU通用并行计算的强大编程接口,允许将计算密集型部分卸载到GPU执行,而逻辑控制仍由CPU负责。此外,OpenCL等开放标准也为跨平台异构编程提供了支持,进一步推动了异构计算技术的普及与深入应用。
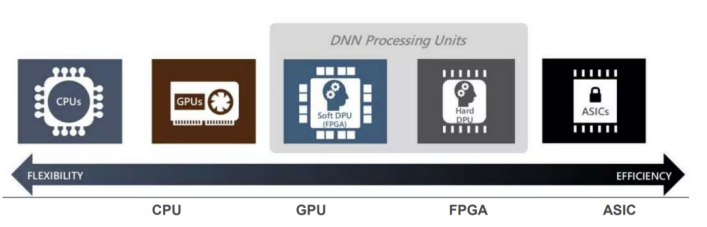
图3: 异构计算中不同处理单元的灵活性与效率权衡
- 异构计算在推理场景中的应用
- 基于HarmonyOS Next的智能驾驶辅助系统
数据采集+实时决策。在车辆行驶过程中,摄像头不断采集道路图像数据。首先,图像数据的解码和预处理任务由CPU负责处理,这些任务涉及到较多的逻辑判断和数据格式转换操作,CPU能够快速高效地完成。然后,对于图像中的目标检测和车道线检测等深度学习任务,系统将其分配到NPU上进行计算。NPU利用其强大的并行计算能力,快速准确地识别出道路上的各种目标和车道线信息。根据检测结果,系统需要进行实时决策,如判断是否需要提醒驾驶员注意前方车辆、是否需要调整车速等。这些决策涉及到一些逻辑判断和简单计算,由CPU来完成。
通过异构计算,这个智能驾驶辅助系统能够实时处理大量的图像数据,快速做出准确的决策,为驾驶员提供及时有效的辅助信息。同时降低了能耗,使得系统可以在车载设备有限的资源条件下稳定运行。
- 快手推出的LaoFe NDP架构
为破解算力瓶颈难题,快手推出了可实现异构计算的LaoFe NDP架构,加速不同场景的计算,并在英特尔硬件上得到最优的性能执行。以推荐业务场景为例,它需要根据用户画像推荐用户感兴趣的内容。首先从海量信息中选择与用户特征相关的结果,再通过“排序”划分内容的优先级别。
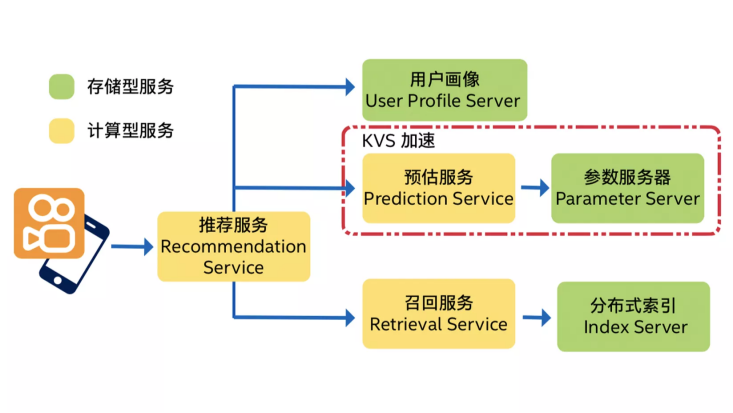
图4: 快手推荐系统
为应对海量数据冲击,快手的推荐系统采用计算与存储分离的架构模式。参数服务器属于存储型服务,该服务要保存和实时更新上亿规模的用户画像、数十亿规模的短视频特征、以及千亿规模的排序模型参数。并且,它不仅受限于容量和带宽,而且还要支撑每秒数亿次的 KV 请求,这会消耗大量 CPU 资源,成为其性能的主要瓶颈。通过使用英特尔至强可扩展处理器、英特尔Agilex™FPGA和英特尔傲腾™持久内存,借助软硬一体化、领域专用加速器设计,使快手的LaoFe NDP近数据架构在计算体系结构上实现创新,从而做到网络、存储、计算三重加速,为各个业务系统提供低延迟、高并发、高吞吐、低总体拥有成本的基础资源。
- 浪潮高端八路服务器-TS860M5
中国科学院某研究所下属的“岩石圈演化国家重点实验室”重点研究大陆岩石圈的形成、改造、破坏过程与机理,但随着地理空间数据指数增长、人工智能应用需求增多,机器学习模型复杂度增加,对高性能计算提出了更高的要求。为此马,景阳雷诺针对客户技术难点,为客户提供了浪潮高端八路服务器-TS860M5,作为集群内的胖节点,以支撑地理空间智能对于计算性能的高需求。

图5: TS860M5服务器
该服务器支持8颗Intel至强81xx系列可扩展处理器,主频最高可达3.6GHz,拥有超高计算能力。最大可支持36T高性能内存,适合作为胖节点用于大内存应用场景。最大可搭配4个双宽GPU, 以支持图像识别的深度学习、决策和推理的机器学习以及超级计算等大规模的并行计算场景。
- 异构计算的挑战、机遇与未来展望
- 当前挑战
将不同指令集架构(ISA)和微架构的计算单元整合于单一系统内,是一项系统工程。尽管前文描述的异构计算理论优势显著,但考虑到软件、硬件、系统等多个层面,在实践中目前还难以做到广泛部署。
一个异构计算系统开发者必须掌握CUDA、OpenCL、SYCL等多种编程模型,不仅提高了开发对人才的高需求门槛,也使得程序的编写、调试和性能优化过程需要在多平台实现。目前一部分编译器可以将算法分解并将其中的计算任务映射到硬件单元,但其遵循的逻辑只是简单的硬件指令是否支持,没有考虑实现全局最优性能。
经过几十年的发展,硬件厂商通常采用高效的私有互联接口和通信协议以保证产品的性能,但这也构建了相对封闭的技术壁垒。异构计算硬件生态呈现出显著的碎片化特征,常常依靠AXI总线实现交互。在物理层面,异构单元拥有独立的内存层次结构(如CPU的DDR和GPU的HBM),这导致数据迁移开销非常大。在不同内存子系统之间读写数据会消耗大量时间和带宽。构建统一内存架构、减少不必要的数据移动。标准化缺失阻碍了不同供应商硬件之间互相操作的灵活性,尽管业界正在积极推动CXL(Compute Express Link)和UCIe(Universal Chiplet Interconnect Express)等开放标准的建立,但要实现不同异构组件间的“即插即用”仍比较困难。
此外,异构计算的性能潜力释放依赖于软硬件的协同设计,硬件架构应针对目标应用负载进行定制,而上层软件则能完全适配底层硬件的计算潜力。目前硬件设计与软件开发流程往往相对脱节,二者存在巨大的产业鸿沟,这常导致硬件的某高级功能因缺乏支持而闲置。
- 机遇与未来展望
早期的异构系统多为CPU与GPU的简单组合。未来的趋势是向着功能更复杂的多异构融合演进。目前的片上系统(SoC)集成CPU、GPU、NPU(神经网络处理单元)、VPU(视觉处理单元)、DSP(数字信号处理器)等多种异构核心,形成一个通用计算平台。这种架构能够在芯片内部完成数据感知、智能推理到决策执行的端到端处理流程,为自动驾驶、具身智能等复杂实时应用提供算力支撑。
Chiplet(芯粒)技术作为异构计算的一大方向,可以将单片集成的大型芯片分解为多个功能独立的模块化裸片(Die),再通过先进的2.5D/3D封装技术进行互联。Chiplet模式降低了超大芯片的设计制造成本,而且提供了开放的硬件模块接口,使得设计者能集成来自不同供应商、采用不同工艺节点的Die。AMD的3D V-Cache技术通过在CPU裸片垂直堆叠一个L3缓存裸片,实现了计算单元与存储单元的三维集成。这种设计缩短了数据访问路径,在游戏等对缓存延迟高度敏感的应用中取得了性能飞跃。
- 总结
我们正处在一个计算架构尝试变革的时代。人工智能为代表的推理密集型计算需求的激增,而异构计算通过为特定任务匹配最优化的计算资源,为持续提升算力与能效提供更有效的支持。对于企业和研究机构而言,未来的核心产品价值将不仅在于单个处理器的设计能力,也在于融入异构计算的能力。这需要对硬件架构、编译器及开放互联标准进行创新,为前沿科学探索和社会数字化转型提供基石性的算力支持。
参考资料:
大模型推理加速技术全景:从框架到异构计算的实战指南 – 天天悦读
GPU异构计算和CUDA程序简介 — 中国科大超级计算中心用户使用手册 :2024-05-18版 文档
(6 封私信 / 14 条消息) 如何用通俗易懂的话解释异构计算? - 知乎
异构计算入门指南:原理、应用与实战解析
【一文看懂】什么是异构计算?_处理_任务_性能
GPU异构计算和CUDA程序简介 — 中国科大超级计算中心用户使用手册 :2024-05-18版 文档
HarmonyOS Next异构计算能力提升应用性能-鸿蒙开发者社区-51CTO.COM
算力新生态,透视异构计算的机会和挑战
异构计算应用案例 | 景阳雷诺科技
异构计算:概念、优势与应用场景全解析
异构计算:技术原理、应用场景与未来趋势-百度开发者中心