Agent记忆框架(三)
概述
AI、LLM、Agent实在是太火爆,关于为LLM增加记忆能力的研究也层出不穷。参考:
- Agent记忆理论与实现:Mem0、MemU、MemOS
- Agent记忆框架(二):Memvid、Memary、MemoryOS
本文继续搜集整理一些项目。
Zep
论文,官网,GitHub,3.7K Star,549 Fork。
Graphiti
GitHub,19.5K Star,1.8K Fork。官方文档
Graphiti是Zep的核心组件,支持对接多家模型提供商。本身不是一个图存储,需集成三方图数据库,如Neo4j或FalkorDB。
核心
- Instant updates:新数据即时更新
- Bi-temporal tracking:既知道事情发生的时间,也知道被记录的时间
- Hybrid retrieval:融合Semantic Search(语义)、Keyword Search(关键词)和Graph Traversal(图遍历,关系结构)
安装:
pip install graphiti-core
uv add graphiti-core
示例
from graphiti_core import Graphiti
from graphiti_core.driver.neo4j_driver import Neo4jDriverdriver = Neo4jDriver(uri="bolt://localhost:7687",user="neo4j",password="password",database="graphiti_demo"
)
graphiti = Graphiti(graph_driver=driver)
episode = {"event": "purchase","user": "johnny","item": "Adidas","timestamp": "2025-10-16T09:00:00Z"
}
graphiti.add_episode(episode)results = graphiti.search("Who bought Adidas?")
print(results)
FalkorDB
官网,GitHub。
MIRIX
论文,GitHub,2.2K Star,225 Fork,官网。
模块化的多智能体记忆系统(Multi-Agent Memory System),MIRIX突破文本的限制,融入丰富的视觉和多模态体验,使记忆在现实场景中真正变得有用。
MIRIX由六种不同的经过精心设计的记忆类型组成,并搭配多智能体框架,能够动态控制和协调更新与检索。使智能体能够大规模地持久保存、推理并准确检索多样化、长期的用户数据。
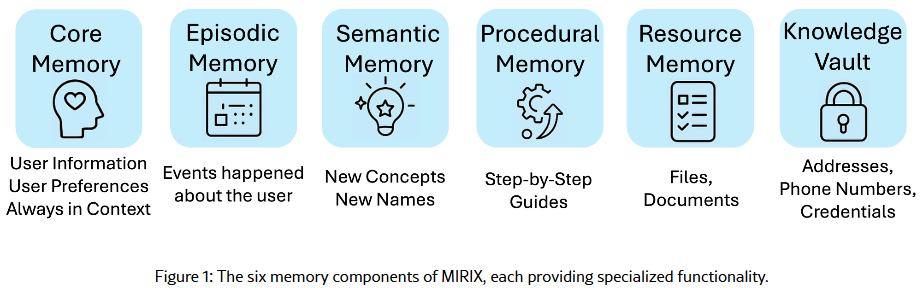
- Core:核心记忆,存储始终对智能体可见的高优先级、持久信息,分为人格和人类两个模块。
- Episodic:情景记忆,存储时间戳事件和基于时间的交互,类似于结构化的日志或日历。
- Semantic:语义记忆,存储与特定时间或事件无关的抽象知识和事实信息;以树状结构展示,适合层级关系等
- Procedural:程序记忆,存储结构化的、目标导向的过程,如操作流程和交互脚本。以列表形式展示,适合任务步骤等
- Resource:资源记忆,处理用户正在积极参与的文档、转录或多媒体文件。
- Knowledge Vault:知识库,知识库作为敏感信息(如凭证、地址、联系信息和API密钥)的安全存储库。
检索设计:MIRIX支持多种检索功能,包括嵌入匹配、BM25匹配和字符串匹配,并正在扩展更多多样化的检索策略。
记忆更新工作流
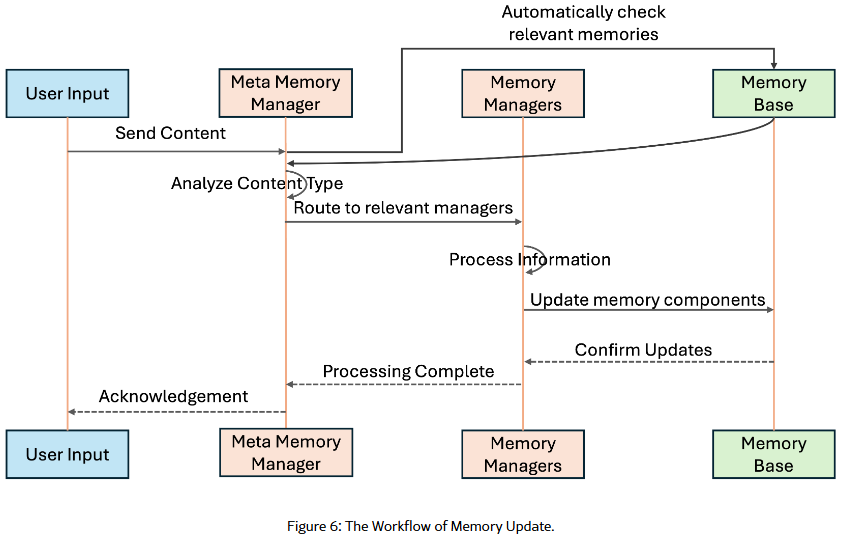
接收到用户请求后,首先在记忆库中进行搜索,然后将检索到的信息和用户输入传递给元记忆管理器,由其分析内容并确定相关记忆组件,将输入路由到相应的记忆管理器进行并行更新。
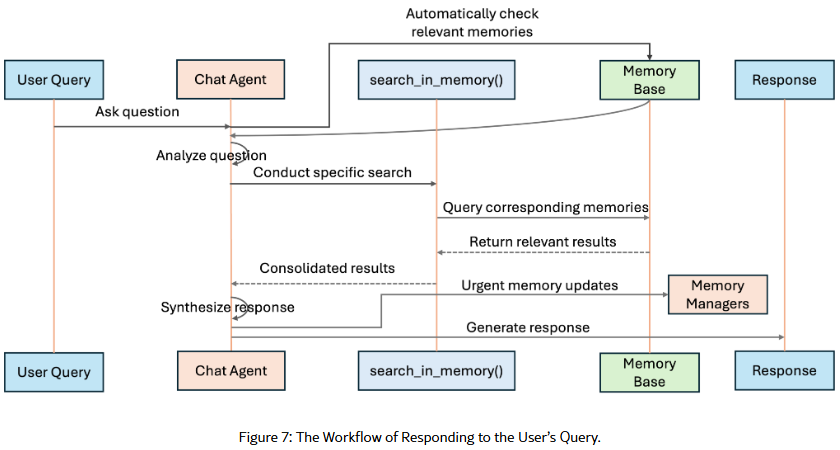
测评
- ScreenshotVQA:包含近2w张高分辨率计算机屏幕截图的多模态基准测试,需要深度的上下文理解能力;
- LOCOMO:一个单模态文本输入的长篇对话基准测试
Memobase
官网,GitHub,2.3K Star,167 Fork,官方文档。
基于用户档案的AI记忆系统,提供一套全面的特性,专为实用、生产就绪的AI记忆设计:
| 特性 | 描述 |
|---|---|
| 档案记忆 | 结构化表示用户偏好、人口统计信息、兴趣等 |
| 事件记忆 | 基于时间的用户重要经历和活动的记录 |
| 批量处理 | 高效处理批量对话,而非实时处理 |
| 多语言SDK | 原生支持Python、TS/JS和Go |
| 热门集成 | 提供与OpenAI、Ollama、LiveKit等的现成集成 |
| 自托管或云服务 | 运行您自己的实例或使用Memobase Cloud的免费层级 |
以用户为中心的设计,区别于其他智能体记忆解决方案。
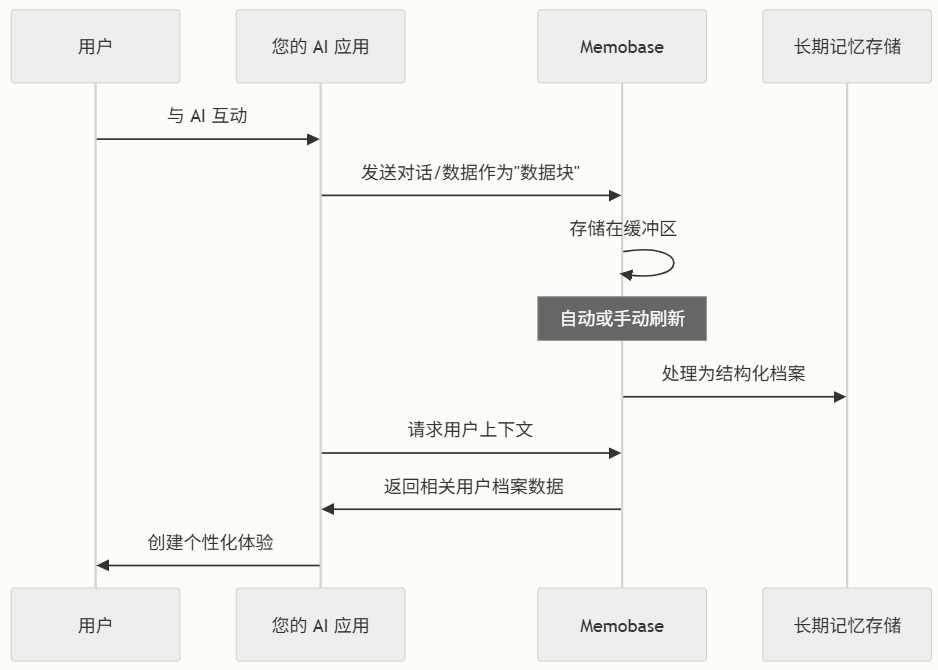
工作流程:
- 捕获数据:应用将对话历史或其他用户数据作为数据块发送到Memobase
- 处理记忆:Memobase分析这些数据以提取有意义的用户信息
- 构建档案:信息被组织成结构化、可查询的用户档案
- 访问上下文:应用在需要时检索相关用户详细信息
- 创建体验:使用这些记忆来提供个性化互动
内存管理系统,处理、存储和检索用户交互,以随时间构建丰富、持久的用户画像。由多个相互连接的组件组成,旨在为AI应用创建一个有效的内存系统。
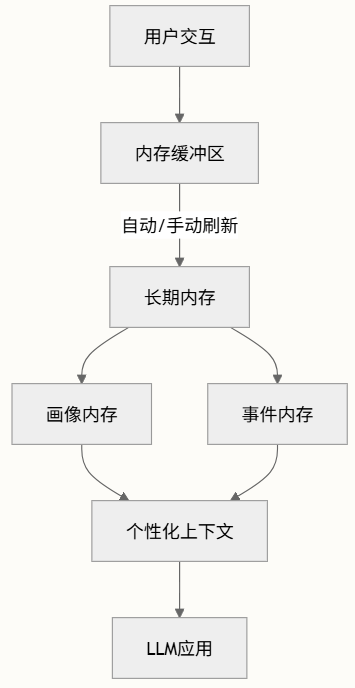
实战
官方playground体验,左侧边栏如下,主要是超链接和
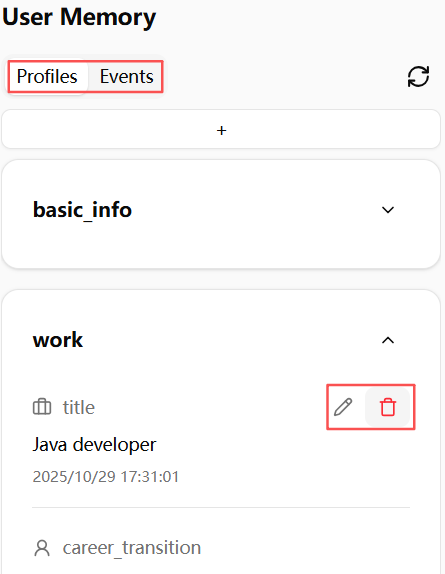
中间是一个聊天对话框:

右侧会近实时展示记忆内容:
安装:pip install memobase。
以Python为例:
from memobase import MemoBaseClient, ChatBlobclient = MemoBaseClient(project_url="http://localhost:8019", # 或使用Memobase Cloudapi_key="xxx",
)
user_id = client.add_user()
# 对话记录
messages = [{"role": "user", "content": "你好,我是来自西雅图的亚历克斯"},{"role": "assistant", "content": "很高兴见到你,亚历克斯!"},
]
blob = ChatBlob(messages=messages)
user = client.get_user(user_id)
blob_id = user.insert(blob)
# 处理数据到记忆
user.flush(sync=True)
# 检索用户档案
profile = user.profile(need_json=True)
print(profile)
JS SDK安装:npm install @memobase/memobase
或通过JSR安装:npx jsr add @memobase/memobase
GO SDK安装:go get github.com/memodb-io/memobase/src/client/memobase-go
此外,还可通过源码或Docker Compose安装。
Memobase为不同用例提供多个预配置模板:
| 模板 | 描述 | 用例 |
|---|---|---|
profile_for_assistant | 优化用于AI助手 | 通用AI助手 |
profile_for_education | 专注于学习相关属性 | 教育应用 |
profile_for_companion | 优化用于伴侣式交互 | AI伴侣和聊天机器人 |
event_tag | 启用时间属性跟踪 | 需要时间感知记忆的应用 |
only_strict_profile | 仅收集明确设计的档案 | 注重隐私的应用 |
jina_embedding | 使用Jina嵌入进行事件搜索 | OpenAI嵌入的替代方案 |
LightMem
论文,GitHub,233 Star。
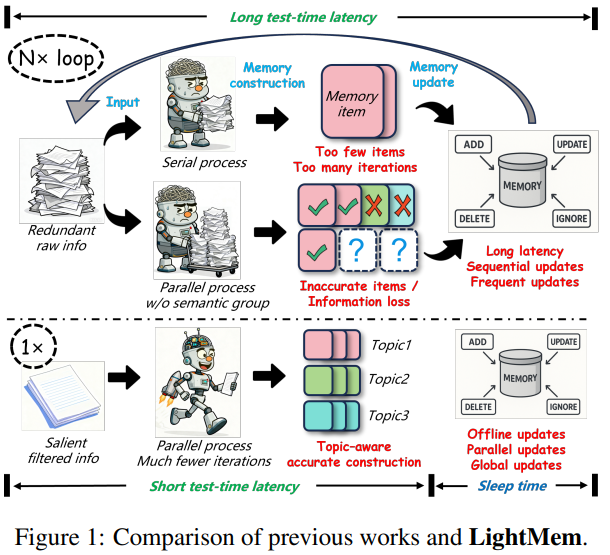
LightMem和其他框架的对比
Atkinson-Shiffrin模型把记忆分为:
| 阶段 | 功能 | 对应LLM痛点 |
|---|---|---|
| 感觉记忆 | 毫秒级过滤无关刺激 | 冗余Token |
| 短期记忆 | 秒-分钟级主题整合 | 语义混杂 |
| 长期记忆 | 睡眠时离线巩固 | 实时更新延迟 |
转换示意图
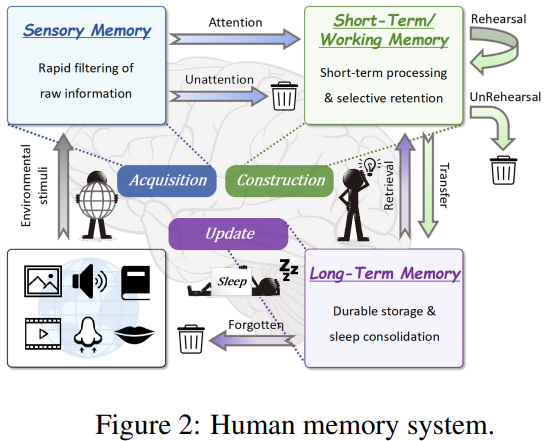
Atkinson-Shiffrin模型:
- 维基百科
- 百度百科-多贮存模型
搜索该记忆模型时,发现多年前还有一篇高引用的论文XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model,提出一种长视频对象分割方法。
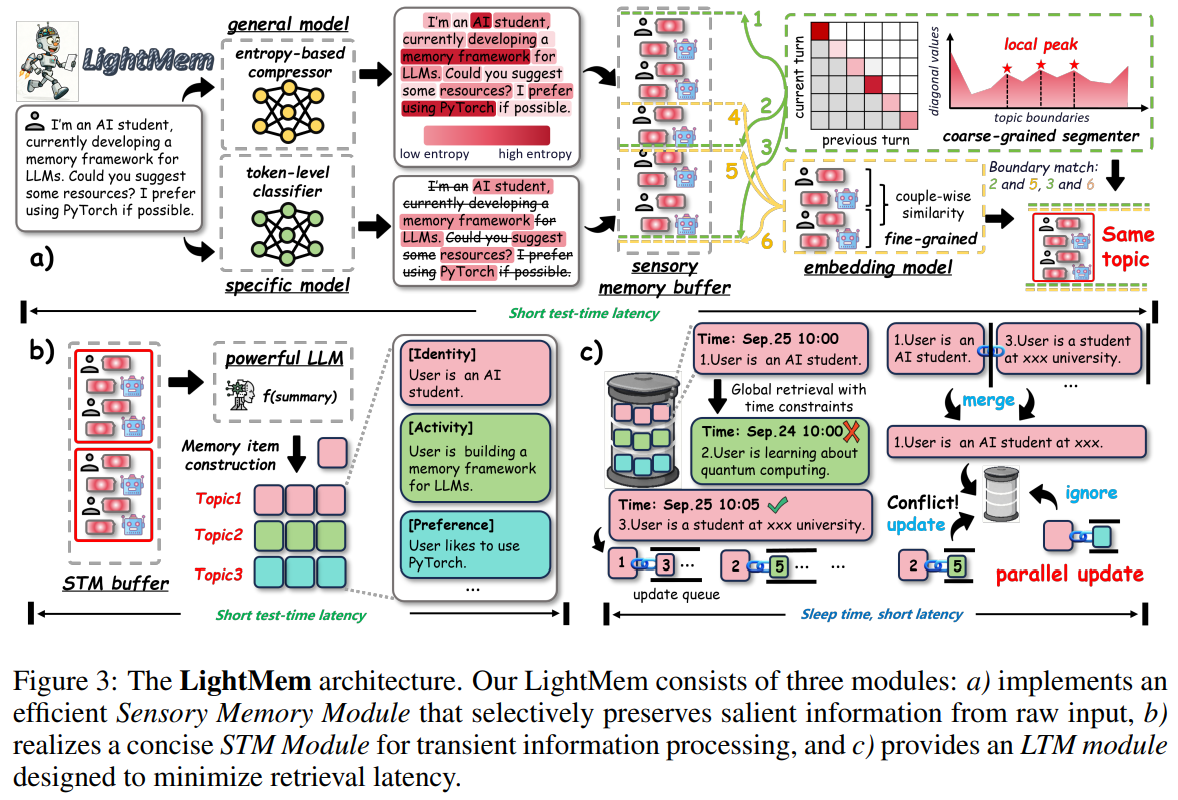
三个阶段:
- Light1:预压缩 + 主题分段
- Light2:主题级短期记忆
- Light3:睡眠期离线合并
- 在线阶段只做追加写,零延迟
- 离线阶段并行执行读-改-写:每条记忆维护一个更新队列Q(ei)Q(e_i)Q(ei),仅与更高时间戳的条目合并,可批量并行,总延迟从O(N)O(N)O(N)→O(1)O(1)O(1)。
LangMem
LangChain官方开源(GitHub,1.1K Star,131 Fork)的智能体记忆系统,官方文档。
记忆类型
| 记忆类型 | 目的 | 代理示例 | 人类示例 | 典型存储方式 |
|---|---|---|---|---|
| 语义记忆 | 知识与事实 | 用户偏好、知识三元组 | 知道Python是一种编程语言 | 配置文件或集合 |
| 事件(情节)记忆 | 过去经历 | 少量示例、过去对话的总结 | 记得第一天上班的情景 | 集合 |
| 程序记忆 | 系统行为 | 核心个性和响应模式 | 知道如何骑自行车 | 提示规则或集合 |
实战
安装:pip install -U langmem
实例
from langgraph.prebuilt import create_react_agent
from langgraph.store.memory import InMemoryStore
from langmem import create_manage_memory_tool, create_search_memory_tool# 设置存储
store = InMemoryStore(index={"dims": 1536,"embed": "openai:text-embedding-3-small",}
)
agent = create_react_agent("anthropic:claude-3-5-sonnet-latest",tools=[# 使用LangGraph的BaseStore进行持久化create_manage_memory_tool(namespace=("memories",)),create_search_memory_tool(namespace=("memories",)),],store=store,
)
agent.invoke({"messages": [{"role": "user", "content": "记住我喜欢深色模式。"}]}
)
response = agent.invoke({"messages": [{"role": "user", "content": "我的照明偏好是什么?"}]}
)
print(response["messages"][-1].content)
A-MEM
论文,对应的开源地址是个人GitHub,或AGI-Research-GitHub,两者仓库地址不一样,但代码文件和README几乎一样;没有一行行对比,没有必要,因为作者也在往后面这个仓库提交代码。后者最后更新时间更靠前。
借鉴著名的卡片盒笔记法 (Zettelkasten,一种知识管理技术),强调创建相互关联的笔记网络,而非孤立的信息孤岛。
架构
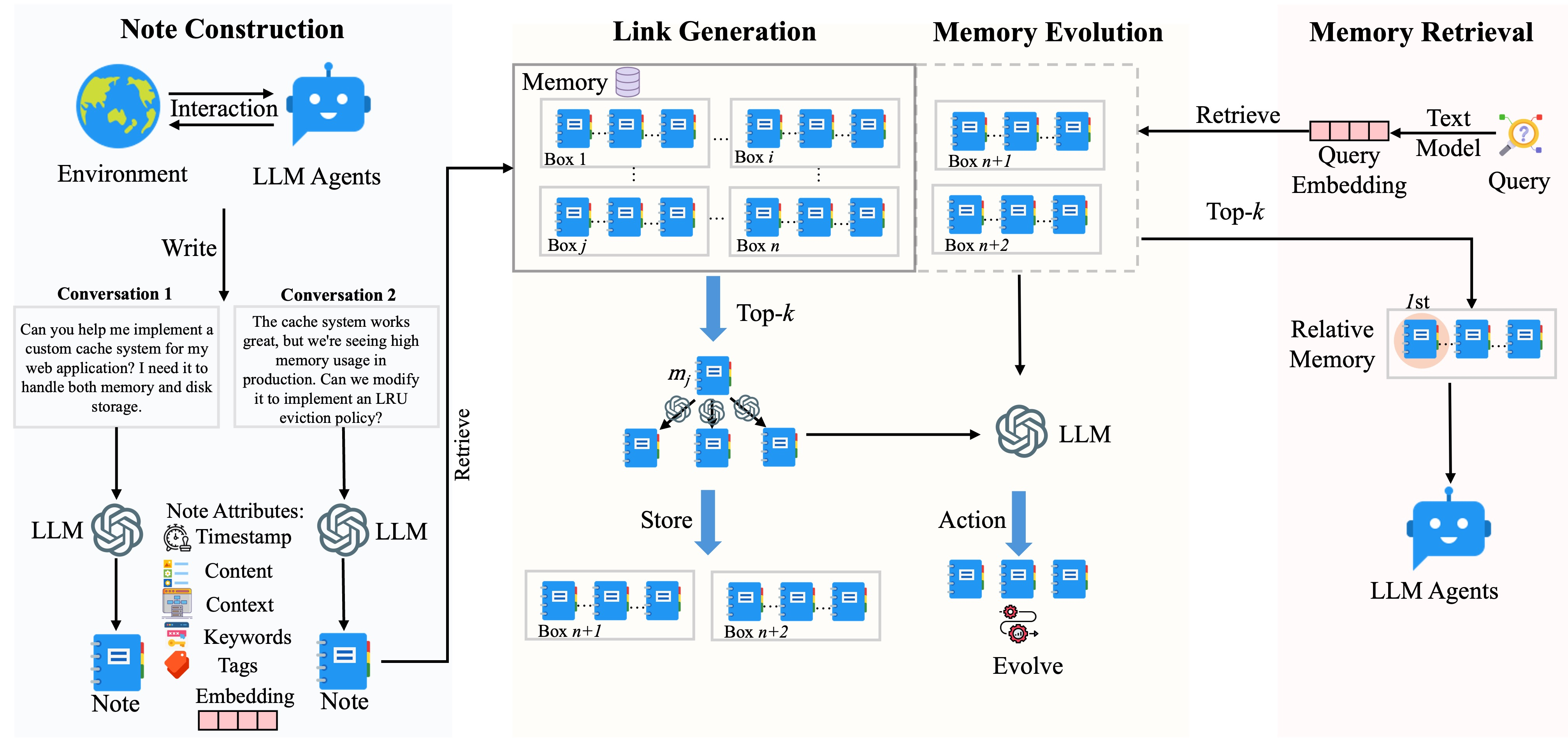
主要特性
- 动态记忆组织:与静态记忆系统不同,A-MEM根据语义关系主动组织记忆。当您添加新记忆时,系统会:
- 使用LLM分析内容,提取关键词、上下文和标签
- 在向量数据库中搜索语义相关的记忆
- 在相关记忆之间创建有意义的链接
- 根据新连接可能更新现有记忆
- 智能记忆进化:系统最具创新性的特性是其随时间进化记忆的能力。通过复杂的提示词和LLM分析,它可以:
- 加强相关记忆之间的连接
- 根据新信息更新现有记忆的上下文和标签
- 当出现模式时整合记忆
- 维护记忆的进化历史
- 混合搜索能力:A-MEM结合多种搜索策略提供全面的检索功能:
- 基于向量的搜索实现语义相似性
- 元数据过滤实现精确分类
- 链接记忆遍历探索知识网络
- 丰富的元数据管理:每个记忆笔记包含全面的元数据:
- 核心内容和唯一标识符
- 时间信息(创建和访问时间)
- 语义元数据(关键词、上下文、标签)
- 关系数据(与其他记忆的链接)
- 使用统计(检索次数)
- 进化跟踪(变更历史)
工作流程:
进阶
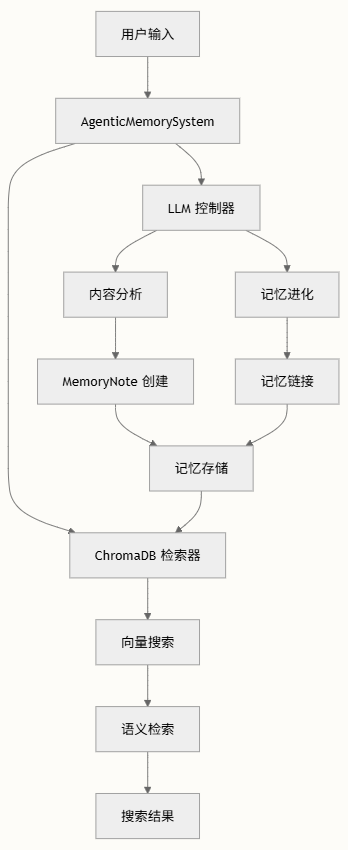
记忆系统围绕三个主要组件构建,三者协同工作以创建一个智能自组织的知识库:
- MemoryNote:信息存储的基本单元,一个超越简单文本存储的复杂数据结构,不仅封装内容,还包含支持智能记忆管理的丰富元数据集。
- AgenticMemorySystem:管理记忆操作的核心协调器
- Retrieval System:结合向量相似性和语义理解的混合搜索系统
MemoryNote维护多个维度的信息:
- 核心内容:主要文本信息
- 语义元数据:通过LLM分析提取的关键词、上下文和标签
- 时间信息:创建时间戳和最后访问时间
- 关系数据:指向相关记忆的链接,形成知识图谱
- 使用统计:表示记忆重要性的检索计数
- 演变历史:记录记忆随时间变化的轨迹
这种丰富的元数据结构使系统能够不仅理解记忆包含的内容,还能理解它与其他记忆的关系以及使用频率。
note = MemoryNote(content="深度学习神经网络使用反向传播",keywords=["深度学习", "神经网络", "反向传播"],context="机器学习",tags=["ML", "神经网络"],category="技术",links=["memory_id_123"] # 链接到相关记忆
)
AgenticMemorySystem,作为架构的中枢神经系统,协调所有记忆操作并实现使该系统独特的代理行为。协调四个关键功能:
- 记忆生命周期管理:创建、检索、更新和删除(CRUD操作)
- 内容分析:自动提取语义元数据
- 记忆演变:基于关系的动态重组
- 混合检索:结合向量相似性和语义搜索
真正使这个系统脱颖而出的是其记忆演变能力。与静态记忆系统不同,主动分析记忆之间的关系,并根据语义连接重新组织它们。
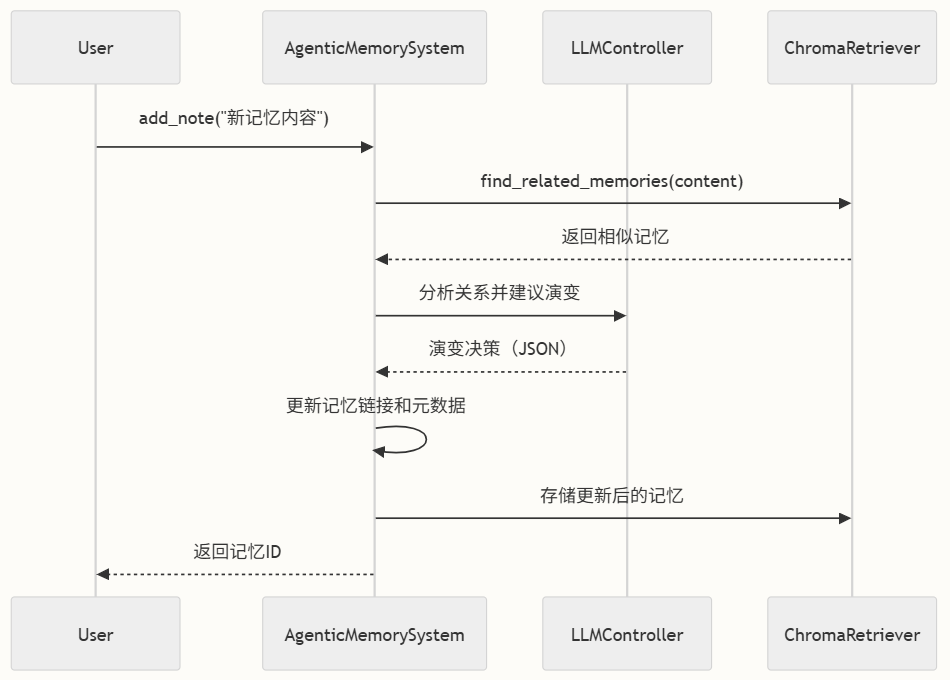
演变过程遵循以下步骤:
- 关系分析:添加新记忆时,系统查找语义相关的记忆
- 基于LLM的决策:LLM分析关系并决定记忆应如何演变
- 动态更新:根据分析结果更新记忆的链接、标签和上下文
- 整合:定期重组确保最佳记忆结构
检索系统采用混合方法,结合向量相似性搜索和语义理解的优势,在记忆检索中同时提供精确性和召回率。
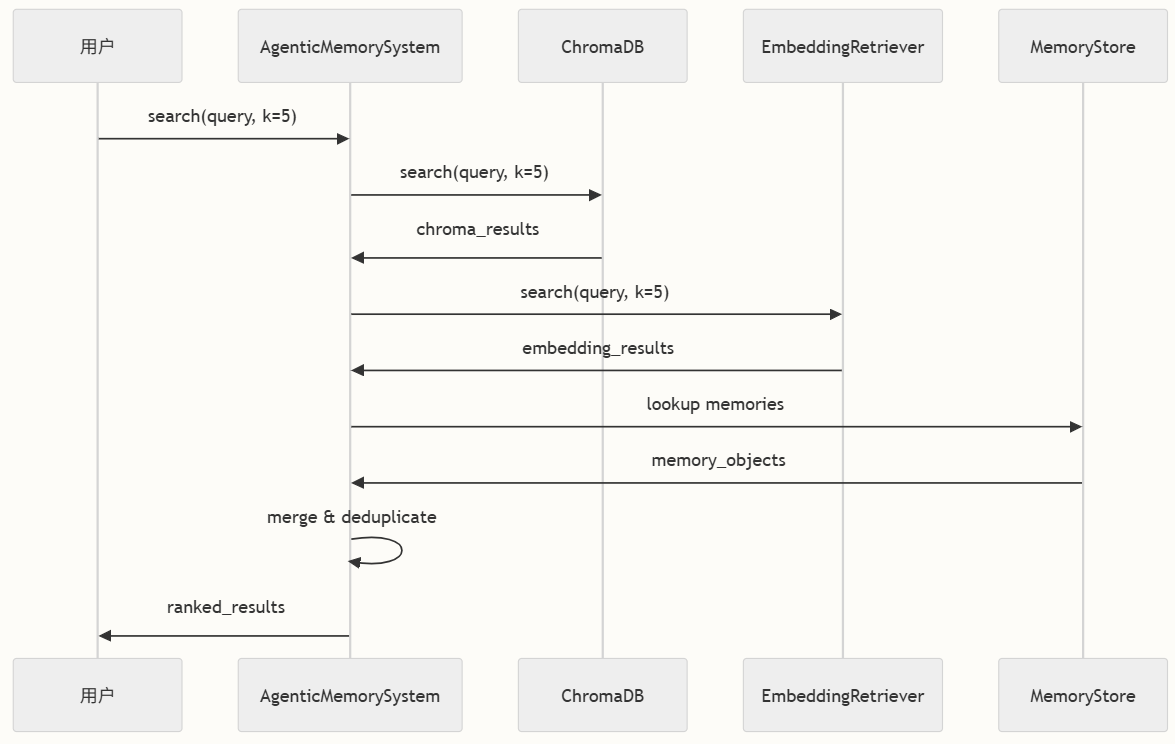
实现多种搜索策略以满足不同用例:
- 基础搜索:使用ChromaDB的简单向量相似性
- 代理搜索:包含链接记忆和关系的增强搜索
- 原始搜索:返回未处理结果用于内部演变过程
ChromaDB提供:
- 高效向量存储:针对高维嵌入优化
- 语义相似性:基于含义而非仅关键词查找记忆
- 元数据处理:与向量一起存储和检索丰富的记忆元数据
实战
安装:
git clone https://github.com/agiresearch/A-mem.git
cd A-mem
python -m venv .venv
source .venv/bin/activate
pip install .
官方示例:
from agentic_memory.memory_system import AgenticMemorySystemmemory_system = AgenticMemorySystem(model_name='all-MiniLM-L6-v2', # 嵌入模型llm_backend="openai", # 可选项:openai、ollamallm_model="gpt-4o-mini"
)
memory_id = memory_system.add_note(content="机器学习项目需要仔细的数据预处理",tags=["ml", "project"],category="Research"
)
results = memory_system.search_agentic("数据预处理", k=3)
for result in results:print(f"内容: {result['content']}")print(f"标签: {result['tags']}")
MemTool
论文,没有开源
MemTool内置三种不同的工作模式,目的是找到最适合本轮Query的工具集,对于每一轮Query:
- 纯Agent:Agent自主决定增加和删除工具;
- Workflow:让第三方LLM增加和删除工具,Agent不做这件事;
- 混合:让第三方LLM删除工具,Agent可自主决定增加哪些工具。