DDR功能拓展之NVME数据处理
一、 概述
NVMe协议支持多个队列(通常为多个提交队列和完成队列),可以同时处理大量I/O请求。当应用程序发起多个读取请求时,这些请求可能会被同时发送到SSD,并且由于SSD内部并行性(多个通道、多个芯片)和负载均衡,先完成的请求不一定是先发起的请求。这就导致了数据返回的顺序与请求顺序可能不一致。
可以利用DDR内存作为缓冲区,对返回的数据进行乱序重排,以保证用户(应用程序)看到的数据顺序是正确的。
本设计基于支持pcie gen2的FPGA实现的nvme控制器,同时支持gen3和gen4。
二、 乱序重排设计
用户测试接口:
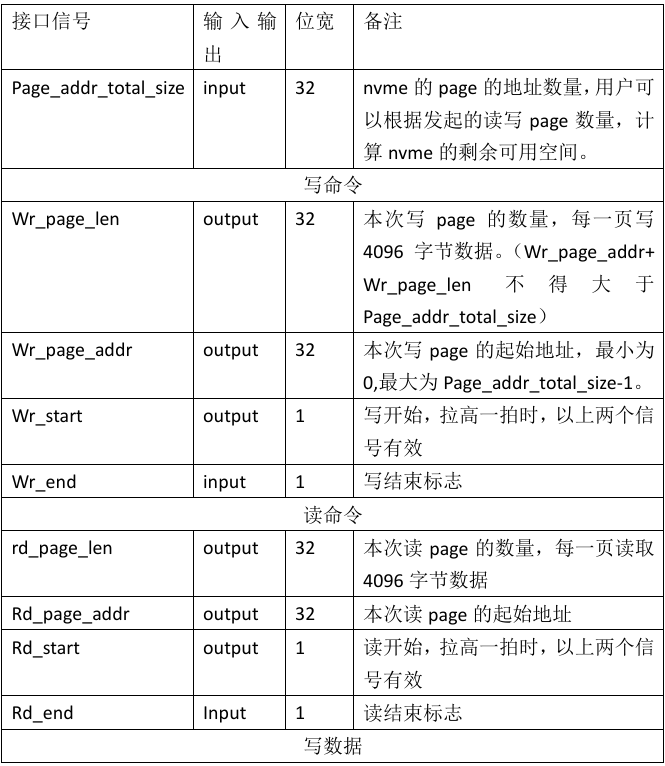
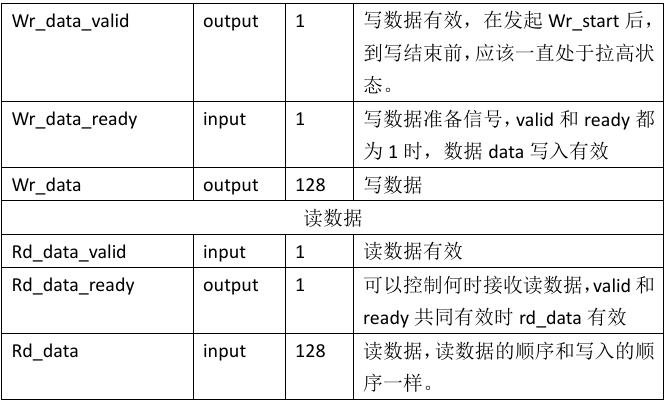
设计思路:
在DDR内存中分配足够大小的缓冲区,用于存储从NVMe SSD读取的数据。对于DDR的写地址,根据当前接收到的乱序页地址-NVME读数据页基地址-本次发起读请求的页初始地址,得到DDR的写突发地址,每次写DDR的突发数据固定为1页(4096Byte),
当DDR缓冲区存满数据后,再通过读DDR来实现对数据的顺序读出。对于DDR缓冲区的大小,在这里使用的是1Gbyte的缓冲区,那么在接收到用户的读nvme请求后,把请求的page_len和page_addr分解为每次最多请求1G字节,这样把分解后的请求发给nvme,当这1G字节被用户读出后,之后如果还有剩余len需要读,就再次发起nvme的读。
乱序重排架构:
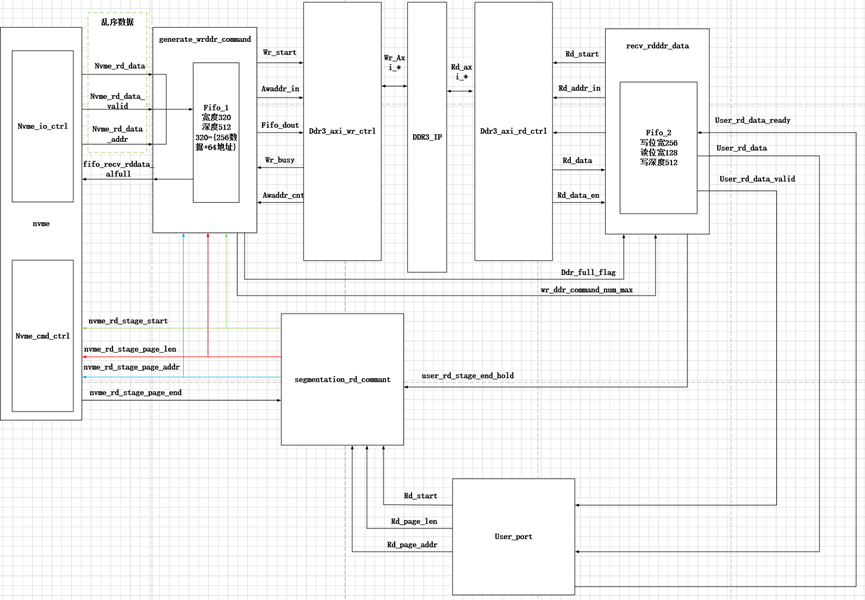
模块说明:
Segmentation_rd_commant模块:
Rd_start、rd_page_len、rd_page_addr为用户请求。
其中rd_page_len为请求读页的数量,rd_page_addr为请求读页的地址。
固定ddr最大存储1G字节数据,那么每次发起的nvme_rd_stage_page_len最大为’h40000。每次的nvme_rd_stage_page_addr最多增加’h40000。当nvme_rd_stage_page_end拉高后表示本次读nvme的数据已经从硬盘中读出,之后检测到user_rd_stage_end_hold的上升沿后,表示用户接收到了本次读nvme的数据。之后如果还有剩余len需要读,就再次发起nvme的读。
Generate_wrddr_command模块:
本次最多能接收1G字节的乱序数据,不用担心ddr会写溢出。只要fifo_1中的数据数量大于等于’d128,也就是1页的数据,就发起一次写突发,突发长度128。突发地址=乱序页地址-nvme读数据页基地址-本次读nvme的页初始地址。
nvme_rd_stage_page_len的数量也就是wr_ddr的突发次数。因为每次ddr固定突发写1页的数据。如果ddr_wr_start的数量等于nvme_rd_stage_page_len时,并且最后一次写突发完成。,拉高一个ddr_full_flag标志,这个标志拉高后表示可以读ddr3了。
防止fifo_1会写满溢出,fifo_1中数据大于等于’d384时,拉低pcie_axis_rx_ready,不接收数据。
recv_rdddr_data模块:
当ddr_full_flag拉高后,开始读ddr,只要fifo_2中的数据小于等于’d384,就发起ddr读突发,直到读ddr的次数等于wr_ddr_command_num_max。
当ddr_rd_start的数量等于wr_ddr_command_num_max,并且最后的读突发完成后,如果fifo_2也空,表示这次的读nvme完成。此时拉高user_rd_stage_end_hold拍保持10拍。通知Segmentation_rd_commant模块用户已经将本次发送的nvme读请求读完成。
三、 测试结果展示
本次使用pcie gen2的板子进行的nvme读写测试。
先向nvme中写入100G字节递增数。



递增数由0递增至’h18fffffff,在ila中显示了本次写nvme的时钟计数。Nvme的用户时钟为125MHz,那么根据计数值计算出写nvme的速率。

得到nvme写数据速率为1492MB/s。
读出NVME数据


对于测试数据,每读出一个数,测试数据+1,测试数据作为递增数,与nvme读出的数据比较,读出的数据与测试数据相同,证明已经乱序重排成功。
四、 总结
该设计的核心在于利用大容量DDR内存作为缓存,将NVMe SSD固有的乱序、不确定的数据返回,转换为一个对用户而言稳定、顺序、高性能的数据流。非常适合需要处理NVMe乱序数据的应用场景,如高速数据采集、大规模并行计算等。
有想学习获得NVME 源码可以找威三学社 私信联系!!!