论文阅读——Segment Anything(Meta AI)——SAM

前言
SAM (Segment Anything Model) 是一个可提示的通用图像分割基础模型,其核心目标是通过统一的提示接口实现对任意对象的零样本分割能力。
论文地址:https://arxiv.org/abs/2304.02643
代码地址:https://github.com/facebookresearch/segment-anything
Demo 与数据集SA-1B地址:https://segment-anything.com/
背景
受 NLP 中“foundation models + prompt”成功启发,作者提出把这种思想推广到图像分割上:定义一个“promptable segmentation”任务,设计一个分离式模型(image encoder + prompt encoder + mask decoder),并用模型-驱动的数据引擎构建超大规模掩码数据集(SA-1B),以训练得到能做零样本/交互式分割的基础模型 SAM。
-
作者首先把背景放到“foundation models 的时代”——语言模型通过大规模数据与 prompt 能够零样本泛化,这给视觉任务带来启发(段落中提到 CLIP/ALIGN 等作为视觉-文本的对应)。目的很明确:把“prompt + 大数据 +通用模型”这套方法应用到分割问题上。优势:为图像分割引入新的范式(promptable),从而降低任务依赖与定制化训练成本。
-
关键问题陈列(文中用三问形式列出):哪个任务能促成零样本泛化?何种模型架构支持 prompt?有哪些数据?这三者被看作相互联系,需要联合设计。这样的陈述清晰,给后文结构化展开奠定了框架。
-
批评/思考点:把 NLP 的成功直接类比到分割上是合理但不自动成立——图像分割需要明确的像素级标签,且“什么是一个有效 prompt”在视觉里可能更具歧义(论文也意识到并讨论了 ambiguity)。作者通过“多掩码输出”和“prompt 类型多样化”来应对,但这一点会影响评估协议与实际应用(例如自动标注可能把小物体或语义边界漏掉)。
Overview
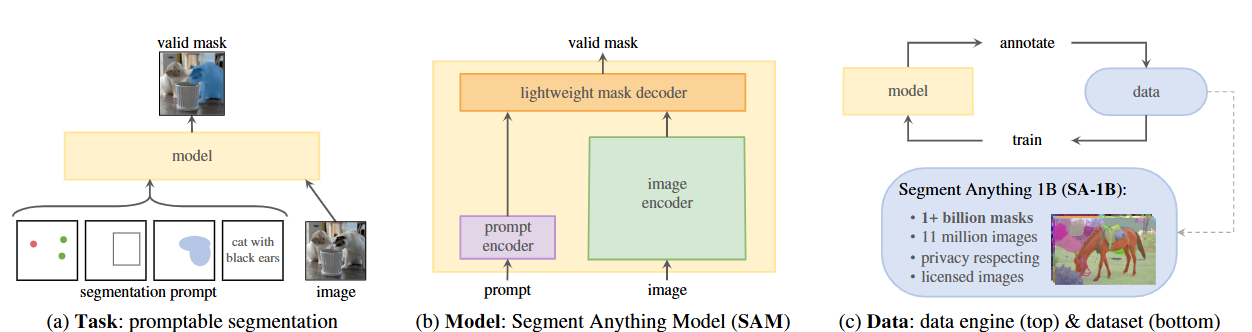
提出 SA 项目:任务(promptable segmentation)、模型(SAM)、数据引擎与大数据集(SA-1B:11M 图像 + 1.1B masks),并宣称 SAM 在零样本下对若干分割相关任务表现出色。论文同时开源模型与数据。
-
概览层面,作者把“任务—模型—数据”三要素并列为整个工作的核心,并且把“模型用来生产数据,数据用来训练模型”的闭环(data engine)作为可扩展数据收集策略,这是工程上很实用的做法(可以把 human-in-the-loop 逐步替换为自动化)。
-
论文宣称“零样本表现往往接近甚至超过先前监督方法”——这是个强命题,后文需要检查具体任务与基线。注意“零样本”在这里的定义:测试时不在目标数据集上微调,而是通过 prompt(点、框、掩码或文本)直接推断。
-
开源承诺(模型 + 数据 + demo)是推动后续研究和复现的重要贡献。
Motivation(研究动机 / 为什么要做 promptable segmentation)
现有分割任务种类繁多(语义、实例、全景、交互等),且标签稀缺且昂贵。通过定义“promptable segmentation”可以把很多任务用 prompt 统一表达,从而用一个模型和大规模通用数据来解决多样任务。
-
作者把“任务统一化”作为主要动机:如果能把分割任务参数化为“给出一个 prompt → 输出 mask”,就能把这些任务通过 prompt engineering 组合或复用已有模块(例如检测器+SAM 做实例分割)。这是工程上对模块化与复用性的强调。
-
此外,动机也包含数据稀缺问题:像素级标注难以大量获取,因此需要一种能被放大(scaleable)的数据生成策略(即 data engine)。这是推动他们提出半自动/自动标注 pipeline 的重要原因。
-
动机成立且切中痛点。但风险是 prompt 设计本身可能成为新的“工程瓶颈”——尤其当 prompt 需要和下游任务严格对齐时。通过支持点、框、掩码与文本多种 prompt 类型来减轻该问题。
系统结构概述
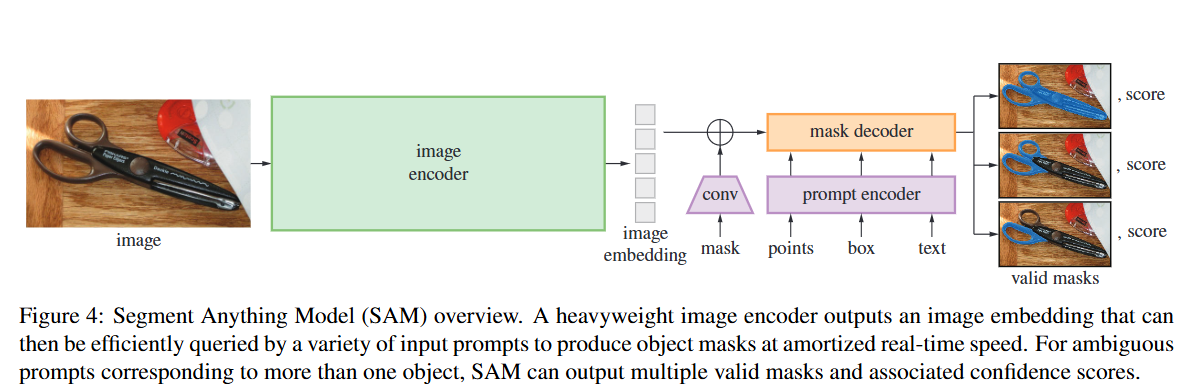
SAM 将模型拆成三部分:heavy image encoder(计算 image embedding),prompt encoder(把点/框/掩码/文本映射到向量),和轻量级 mask decoder(基于 image embedding + prompt 产生掩码)。设计目标是:灵活 prompt、实时(交互级别)、ambiguity-aware(可输出多个候选掩码)。

-
设计思想:把昂贵的图像编码(可复用)与便捷的 prompt 查询分离,从而允许在同一张图像上快速对不同 prompt 做出响应(实用性高,延迟低)。这种分离设计和“可缓存图像嵌入”的思路对交互式工具非常重要(例如浏览器端 demo)。
-
Prompt encoder 的职责是支持不同类型的 prompt(点、框、mask、文本)。实现上论文展示了如何把这些多模态 prompt 映射成同一 embedding 空间并送入 decoder;这样可以用统一 decoder 处理不同 query。
-
Ambiguity-aware:设计能返回多个 mask(并附置信度),这是处理单点可能对应多个语义对象(shirt vs person)的实用策略,也利于下游选择或人工复核。
-
这种模块化很直观,但 decoder 的具体设计(如何做到高精度又快速)是关键。
训练与数据引擎、模型训练流程
-
任务化预训练:为每个样本模拟多种 prompt(点/框/mask),模型要在这些 prompt 下输出有效掩码;训练损失和样本策略要支持 ambiguity。
-
数据引擎三阶段:assisted-manual(人机协作)、semi-automatic(半自动)、fully automatic(全自动)。最终在 fully automatic 阶段,用 SAM 自己以规则化点网格生成大量高质量掩码(平均 ~100 masks/图像)。
-
SA-1B 数据集:11M 授权/隐私保护图像,1.1B 掩码,平均 ~100 masks/图像。模型用这种规模进行训练以提高泛化。
实现细节
-
预训练策略:论文借鉴 interactive segmentation 的思路,但目标不同:不是通过不断追加 user input 最终收敛,而是要求对任意 prompt 都能直接产生合理掩码。训练中他们模拟点、框和掩码 prompts;并用针对性的损失(例如掩码交并比相关的损失)让输出对模糊 prompt 产生多样解。
-
技术要点:如何平衡正负样本、如何生成“合理但多样”的目标掩码(尤其在人造自动标注时)是挑战;论文通过多掩码输出与置信度评分来部分解决。
-
-
数据引擎设计:从人工辅助到完全自动化的阶段化流程很务实:先让人工在 SAM 辅助下标注、再利用模型自动补全、最终自动在格点/候选点上提示生成掩码。这样既保证了早期质量,也能放大规模。
-
风险点:自动阶段生成的掩码质量依赖于中间模型,如果模型存在系统性偏差(例如对某些物体类别弱),这些偏差会被放大到整个数据集。论文提到做了质量评估与人类验证以缓解这个问题。ar5iv
-
-
训练细节(论文中有具体实现、损失与超参节,建议你若要复现可直接看 Section 3 & Appendix):关键在于使模型既能对单点输出准确掩码,又能在点模糊时给多种合理掩码;训练中需要用到 mask-wise loss、对多输出的匹配策略(Hungarian 或者交并比匹配)等。
实验评估
-
在 23 个分割数据集上做单点提示的评估,SAM 常常能从单点生成接近人工标注的掩码(性能仅略低于人工 GT)。
-
在多种下游任务(边缘检测、proposal generation、实例分割、text-to-mask 初探等)下进行零样本迁移评估,结果显示 SAM 在很多场景中“直接可用”且在某些任务上接近或超过先前的监督方法。ar5iv
逐段解析与关键评注:
-
评估协议:论文采用“零样本(zero-shot)”设置,即不在目标数据集上微调,只用 prompt(例如单点或边界框)从 SAM 生成掩码并比较质量。这样的协议评价的是“模型的可移植性”。优点是直接反映可复用性,缺点是并不衡量在少量上微调后的潜能。
-
结果解读:在很多常规的实例/物体分割上,SAM 从单点能产出高质量掩码,这说明模型学到了很强的“形状与边界”先验。但在需要细粒度语义分割(例如医学影像里细小结构或语义上细微区分的类别)时,prompt-only 可能不够——论文也指出仍有改进空间(Section 8)。ar5iv
-
比较基线:对比对象包括传统的交互分割方法(需要多交互)与任务专用模型。SAM 的优势在于“一致性”和“通用性”;专用模型在特定指标/任务上仍可能领先。
-
附带实验:论文还展示了将 SAM 与检测器结合做实例分割、用作候选掩码生成器等应用场景,指出 SAM 在系统级集成中的价值(作为“模块”)。这体现了作者最初提出的“可组合性”动机。
论文总结
作者报告了对 SA-1B 的地域/经济多样性统计与模型在不同人群上的性能分析,声称模型在不同群体上表现“相似”。同时强调数据为授权并隐私保护的图像。
-
论文有意识地加入 Responsible AI 的讨论并做了一些跨群体性能检查,这值得肯定。公开数据集与代码、数据卡/模型卡也有助于透明性。
-
然而,规模大的自动化数据集仍可能隐含偏差(来源域偏好、视觉语义偏差、被低估的小众对象类别等)。“表现相似”需要具体指标与置信区间来判断,且即便总体相似,也可能在子类别或罕见场景出现显著差异。
SAM 展示了“promptable 分割 + 大规模数据”路线的可行性,可用于交互分割、自动标注、和作为系统组件的多种任务。作者也承认仍有改进空间(精细语义、rare classes、文本-到-掩码 的进一步能力等),并鼓励社区在此基础上继续研究。
-
贡献回顾:定义任务、提出模块化模型、提出并验证 data engine,收集超大数据集并释放资源。贡献既有方法论(任务 + prompt 思想)也有工程/资源(SA-1B 与 SAM 模型)。这组合推动了“分割领域的 foundation model”方向。
-
局限与后续方向:
-
语义层次:SAM 偏向“形状/前景-背景”分割,不总是解决语义类别区分(例如同类别内的细粒度语义划分仍需额外模块或微调)。
-
Prompt 设计:prompt engineering 成为使用门槛,如何自动化或学习有效 prompt(尤其文本 prompt 的增强)是未来工作方向。
-
数据偏差放大:自动生成的数据集虽然规模大,但如果模型的初始偏差没有被发现并修正,会被放大。需要持续的质量监控与多样性度量。
-
-
研究延展建议:把 SAM 与强语义判别模型(如 CLIP)更紧密结合做 text→mask;或者研究少样本微调的小型 adapter,使 SAM 在特定领域如医学或遥感上更可用。
针对论文中关键技术点的深度注释
-
Prompt types 支持:点(foreground/background)、box、mask、文本(初步)——训练中对各种 prompt 做模拟。
-
多掩码输出:用于处理 ambiguity(同一点多对象可能性)。输出多个 mask + 置信度分数。
-
图像嵌入可复用:heavy image encoder → 产生一次 embedding,后续 prompt 查询 amortized 成本低(适合交互/浏览器 demo)。
-
Data engine 三步法:assisted → semi-auto → fully-auto(grid of foreground points 生成大量掩码)。
-
数据规模:SA-1B:11M 图像、>1.1B 掩码(平均 ~100 masks/图像)。这是论文宣称的“迄今最大分割数据集”。