百度亮相 SREcon25:搜索稳定背后的秘密,微服务雪崩故障防范
近日,全球 SRE 领域具有高度影响力的国际会议 SREcon25 在爱尔兰都柏林举行。该会议由计算机科学领域权威机构 USENIX 主办,已成为全球可靠性工程师(SRE)交流的顶级盛会。本届大会汇聚了来自 Google、Meta、AWS、百度等全球领先企业的技术专家,共同探讨分布式系统的稳定性演进、可观测性与自治运维的未来方向。
在此次大会上,百度智能云运维部与百度搜索架构部联合发表主题报告 《Preventing Avalanche Failures in Large-Scale Microservice Systems》(《大规模微服务系统中的雪崩故障防范》),系统阐述了团队在微服务稳定性治理、系统级防崩溃机制及韧性架构设计方面的实践成果,标志着百度在全球 SRE 领域的工程创新与可靠性治理能力获得国际同行认可。
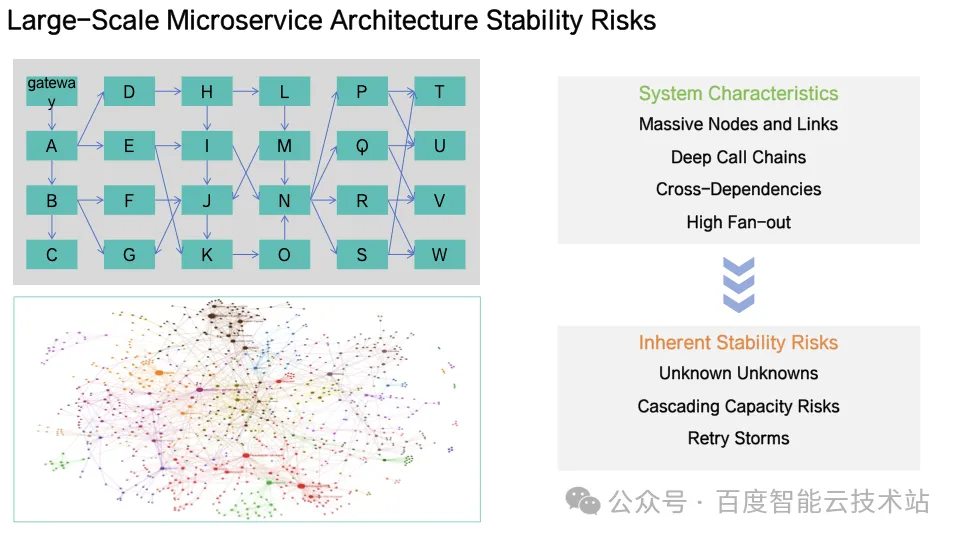
1. 从灵活到脆弱:复杂微服务系统的雪崩故障风险
分布式技术使得系统具备高并发、高弹性、可扩展能力,但同时复杂的调度链、耦合的高可用机制也使得系统在特定场景下变得更加脆弱,带来了新的故障模式,其脆弱性体现在:
-
系统边界行为不可知:在突发场景中,系统不同机制耦合导致的系统行为不可预测;
-
级联容量风险:单一服务故障可能沿调用链放大其影响;
-
高可用机制的副作用:部分高可用机制(如重试)在极端情况下放大负载,加剧系统恶化;
2. 雪崩并非突发,而是「非稳态」的必然结果
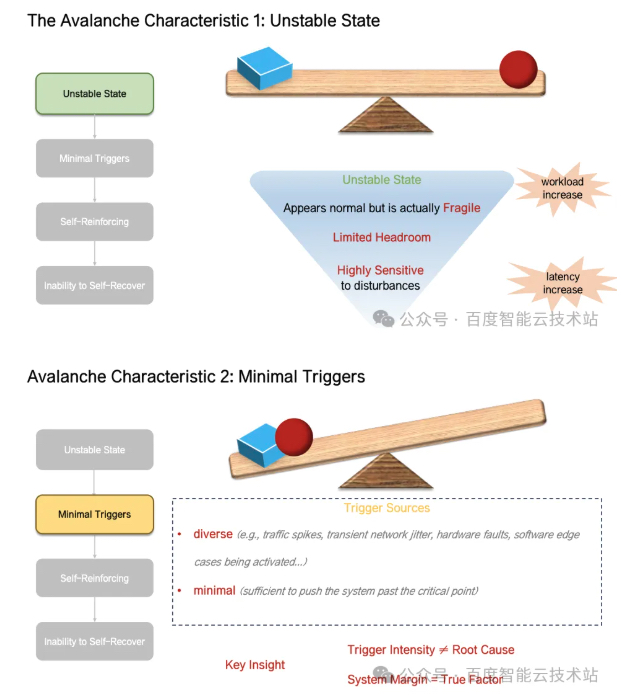
雪崩故障生命周期大致可划分为四个阶段:
-
系统进入非稳态:此阶段系统表面指标正常,但系统已接近雪崩临界点,处于非稳态,任何一个扰动都有可能使得系统越过临界点;
-
扰动触发雪崩:轻微扰动(流量抖动、网络抖动、缓存失效、小的故障等)导致系统跨越雪崩临界点,系统可用性进入不可逆的死亡螺旋;
-
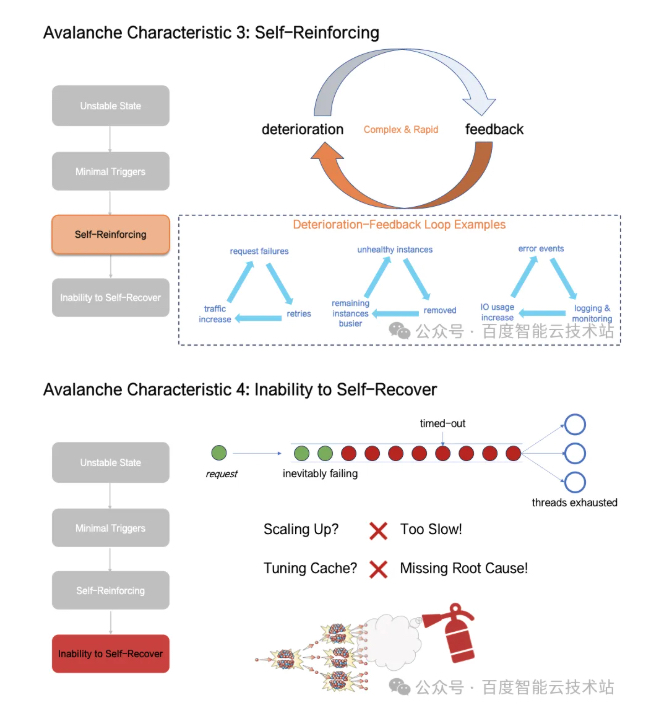
雪崩发展:此阶段系统高可用机制相互作用形成正反馈环路,如可用性下降 → 重试 → 负载增加 → 可用性继续下降的死亡螺旋;
-
彻底雪崩:此阶段系统做无效计算,有效吞吐大幅下降,系统无法依靠自身恢复,必须通过外力打破正反馈通路才能恢复系统;
在快速且复杂的雪崩故障发展路径中,雪崩触发源事件并非雪崩的根本原因,而在于系统在多种机制耦合作用下的脆弱性、系统整体反馈强度越过了系统服务能力边界。
3. 理论模型:系统极限吞吐模型
为刻画系统极限吞吐,基于 Little’s Law(利特法则) 构建了系统吞吐约束模型。
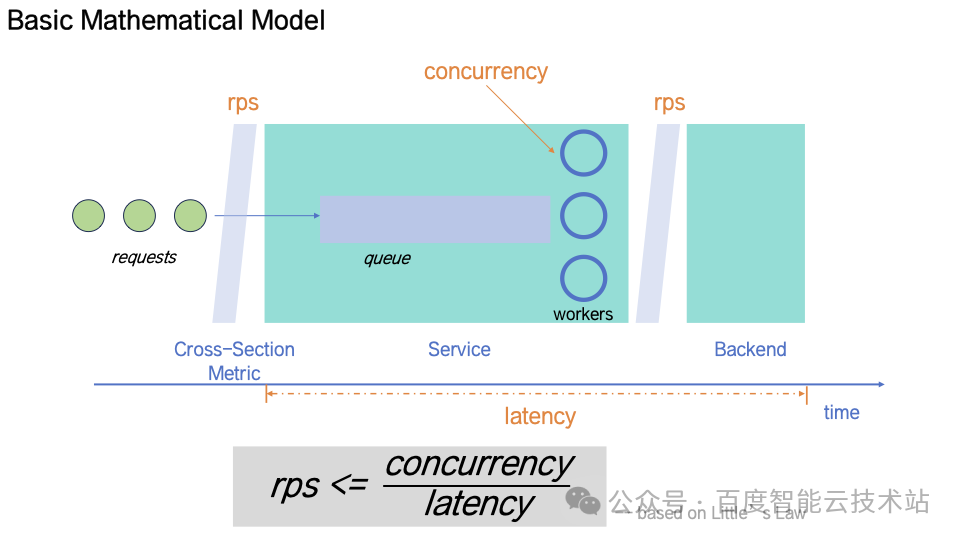
在此模型下,每个微服务的吞吐上限由「线程并发度」和「请求延迟」共同决定。一旦局部延迟上升、线程被占满,RPS 约束被打破,整个系统链路将进入「正反馈不稳定区」。
该模型被进一步扩展为将服务视为连续的「请求队列 + 工作线程 + 后端依赖」三层结构,使得该模型可以在深调度链中适用。
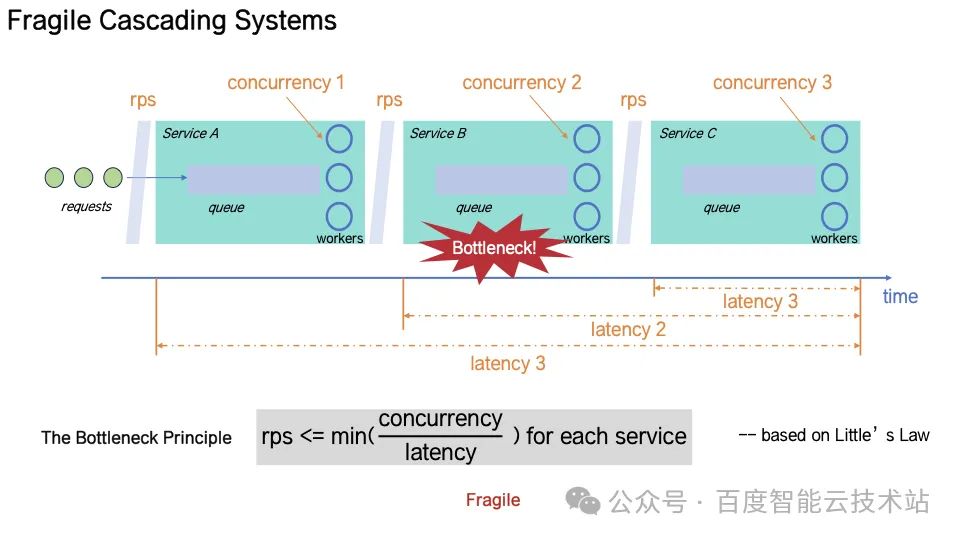
4. 微观视角的系统雪崩过程
以「网关 → 服务 A → 服务 B → 服务 C」的典型调用链为例,当服务 C 出现延迟上升时:
-
服务 A 和 B 的线程利用率与延迟几乎同时飙升,这是原始故障的直接传导过程;
-
服务 B 的队列长度开始积压,服务 A 的队列也出现同步增长,系统进入队列积压阶段;
-
由于 B 超时,A 对 B 触发重查,导致 B 负载进一步上升,系统有效吞吐下降,进入「反馈 - 恶化 - 反馈」的正反馈结构;
-
最终网关超时,触发对 A 的重查,B 上收到的流量进一步增加,系统有效吞吐继续下降,持续处于「反馈 - 恶化 - 反馈」的正反馈结构;
-
系统在这种「自我强化机制」下迅速走向无有效吞吐且不可自我恢复,系统彻底崩溃;

以上所有过程可在数十秒内完成,传统的可用性手段已无法应对如此快速的故障发展过程,抑制雪崩故障的关键在于抑制或打破此类指数级的反馈结构。
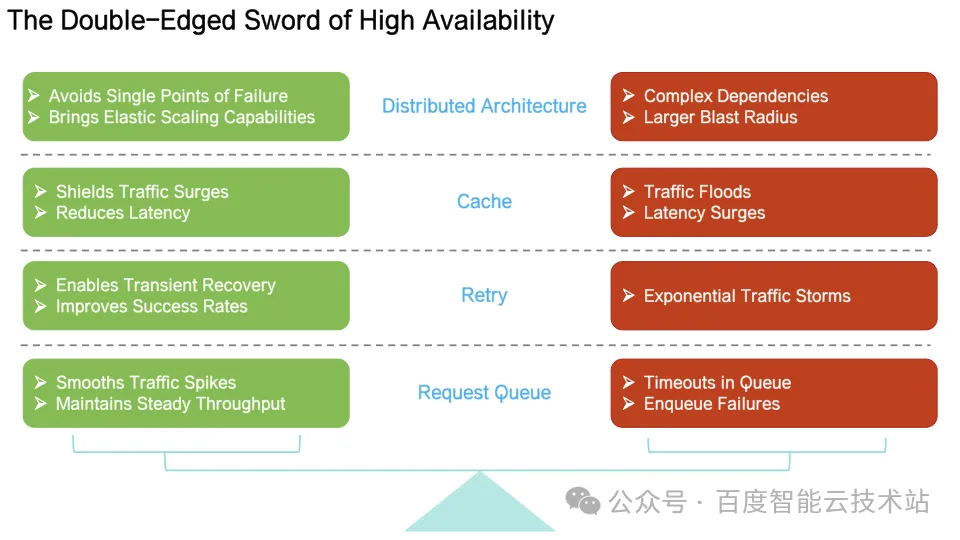
5. 防雪崩工程实践 —— 让系统「自愈」而非「被救」
早期预警:发现非稳态
为了在雪崩发生前发现早期信号,团队构建了一套多层监控体系,实时跟踪系统健康指标,包括:
-
全链路失败数与请求延迟分布;
-
队列长度、线程使用率;
-
各关键服务的百分位延迟(P95/P99)。
这些指标均以秒级粒度采集,并结合异常检测模型进行自动告警,实现「秒级检测、分钟级处置」。
核心干预措施:抑制雪崩发展、加速雪崩退出
基于雪崩生命周期不同阶段的特点,建设了一套系统化的干预框架,从系统微观机制层面改造反馈通路,抑制反馈强度,确保系统在常态下具有正常反馈,在故障场景下反馈强度适度。
-
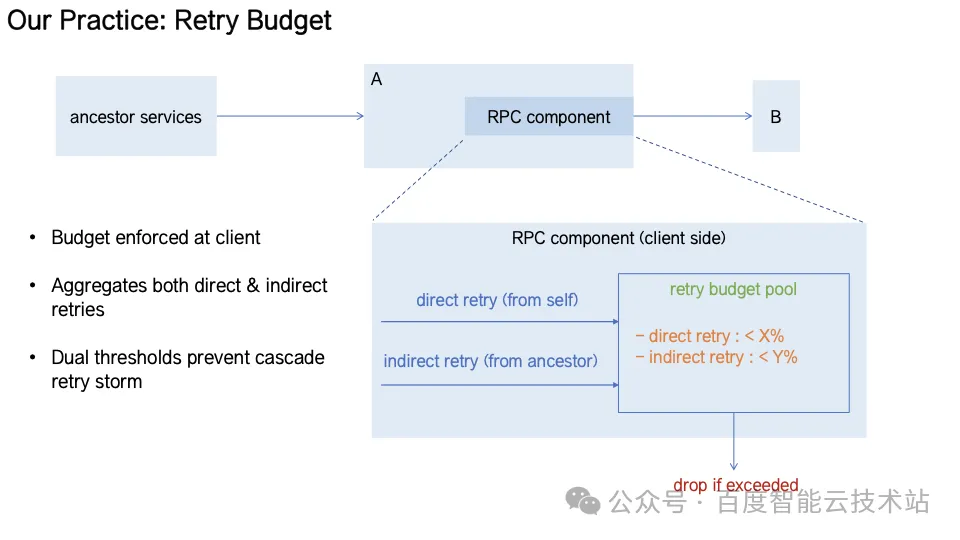
Retry Budget(重试预算)通过在 RPC 组件层实现全链路重试预算池,区分「直接重试」和「间接重试」,并为不同来源设定预算阈值。当预算耗尽时自动快速失败,从机制层面抑制重查风暴,系统重试流量从指数增长退化为线性增长。
-
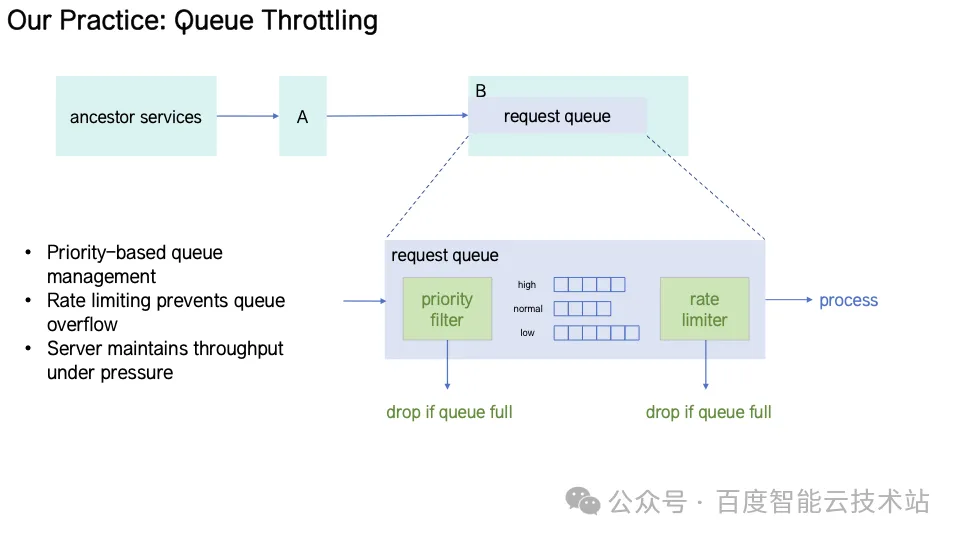
Queue Throttling(队列节流)服务端请求队列按优先级划分,拥塞时仅保留高优任务。限流器根据实时处理速率自适应调整放行,同时清除超时请求,避免队列堵塞。
-
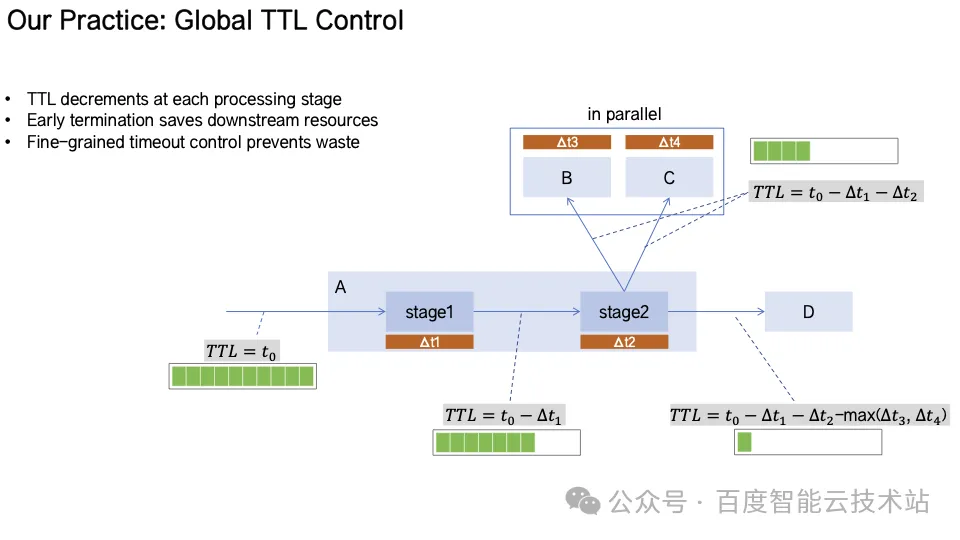
Global TTL Control(全局 TTL 控制)每个请求自入口携带生命周期 TTL,沿调用链传播并动态递减。当 TTL 耗尽时,后续请求自动终止,避免无效调用消耗宝贵计算资源。
-
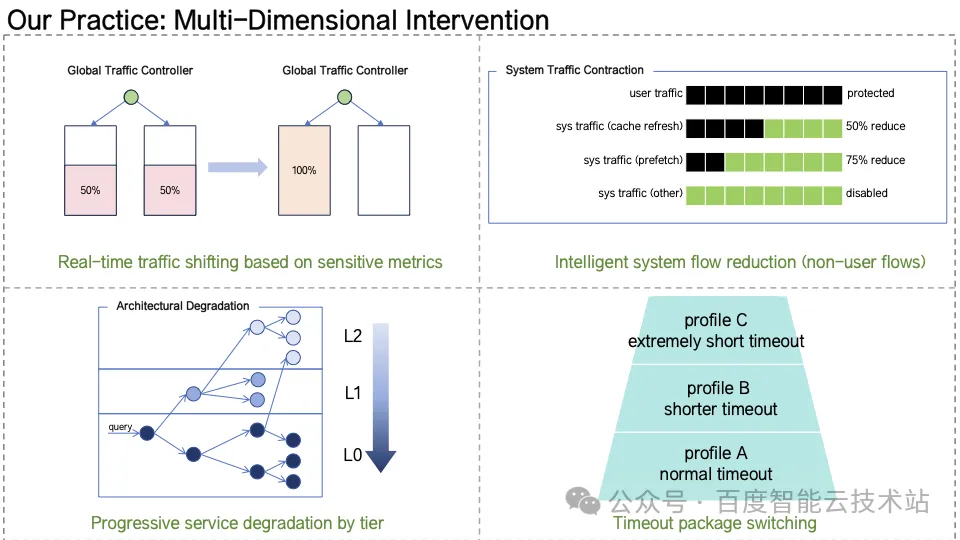
Multi-Dimensional Intervention(多层干预体系)当系统检测到关键指标(P99 延迟、失败率、线程利用率等)越界时,触发快速干预机制,包括跨 IDC 流量切换、系统内部流量裁剪、服务策略裁剪、动态砍超时重查。通过「秒级决策 + 自动执行」实现系统自愈。
上述机制的设计理念是:不试图消除反馈结构,而是控制反馈强度。
6. 结语
历经体系化治理,百度搜索已实现大规模微服务体系的稳定性跃升。通过微观机制改造、预案建设并经生产环境验证,百度在过去多个季度中消除了系统雪崩事件。
本次 SREcon25 的主题分享,不仅展现了团队在微服务可靠性与韧性架构领域的系统化研究成果,也向国际同行展示了百度工程团队在大规模系统稳定性治理上的深厚积累与方法论创新。
未来,运维部与搜索架构部将继续深耕自治运维、稳定性建模与智能化自愈机制的研究,携手全球 SRE 社区,共同推动可靠性工程从经验驱动走向科学驱动,为 AI 时代的基础设施稳定性奠定坚实基石。
更多技术细节 大规模微服务系统中的雪崩故障防治。