李宏毅机器学习笔记35
目录
摘要
1. Deep reinforcement Learning(RL)
2.训练方法
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是Deep reinforcement Learning相关基本概念,训练的过程及如何控制actor的行为。
1. Deep reinforcement Learning(RL)
RL面向的问题与我们之前所学的supervised learning不同,supervised learning是给一个输入,告诉它应该输出什么。而RL是当给机器一个输入时,我们不知道最佳输出是什么。假设教机器下围棋,我们根本不知道下一步下在哪里是最好的。当收集标注资料很困难,或者正确答案人类也不知道时,就可以考虑使用RL。
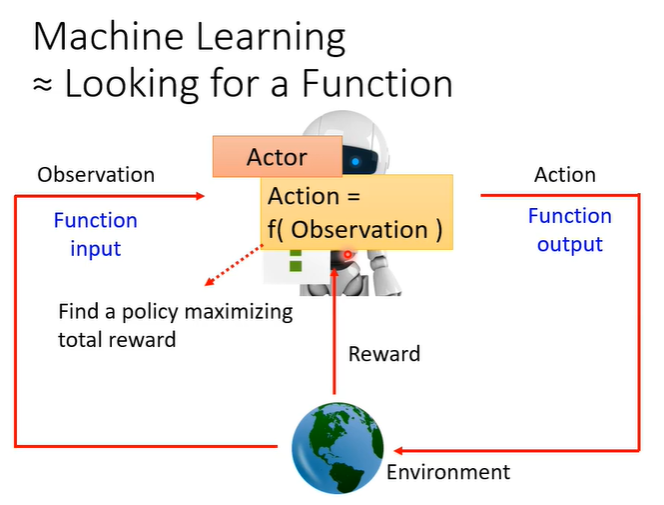
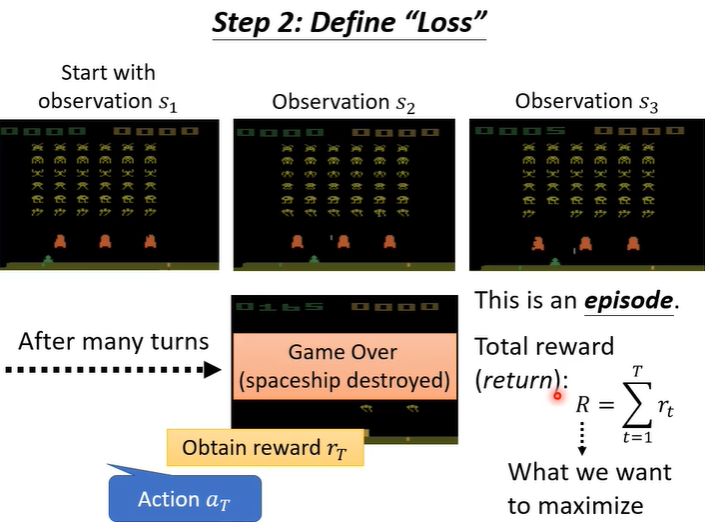
机器学习就是找function,RL找的函数就是下图中的actor,在RL中有actor和environment,他们会进行交互,environment会给actor一个observation作为actor输入,action作为输出会影响environment,这个过程中environment还会不断给actor一些reward(让actor判断action是好是坏),而actor这个function的目标是maximize从environment获得的reward的总和。
以space invader为例,让机器去玩这个简单的小游戏。游戏玩法:下图中,绿色的部分是被操纵的东西,可以左右移动和射击(action),要做的事情就是击杀上面的外星人(黄色部分),橙色部分是防护罩,会被自己射击打掉,也会抵挡外星人攻击,击杀外星人会得到分数(reward),当所有外星人被击杀时或绿色部分被击杀时,游戏结束。
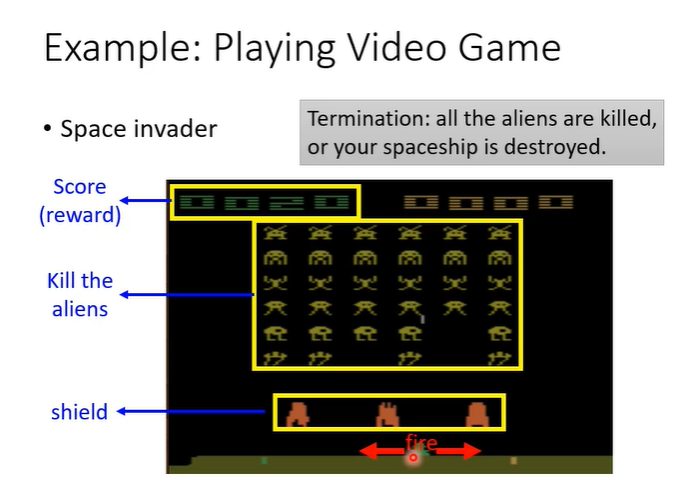
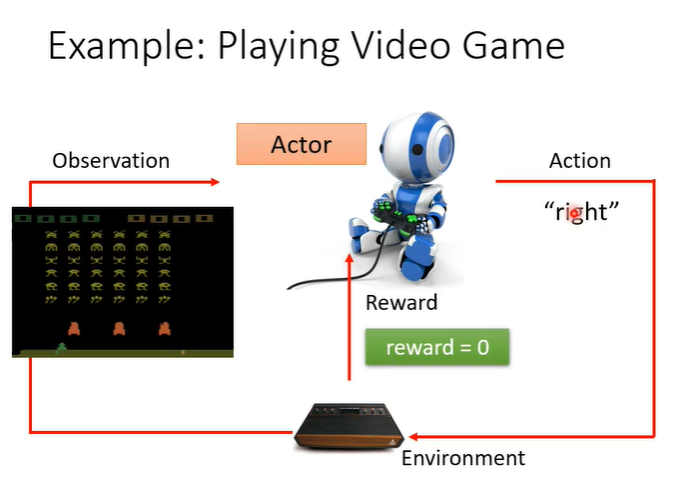
actor就是机器,environment就是游戏,observation是游戏画面,可以采取的行为action是“左”“右”“开火”,得到的分数为reward。当action为“右”,reward则为0(向右并不会击杀外星人)。
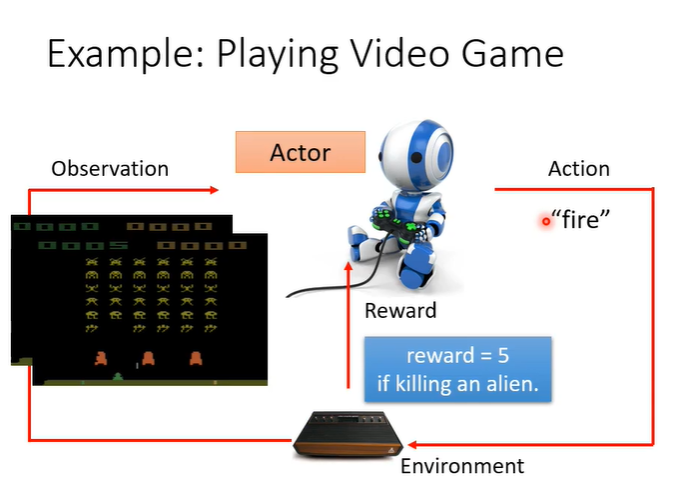
此时有新的画面作为输入,那么会输出新的action为“开火”,假设杀掉一个外星人为5分,得到分数,此时reward为5。学习的目标就是使用actor在游戏中可以得到的reward总和最大。
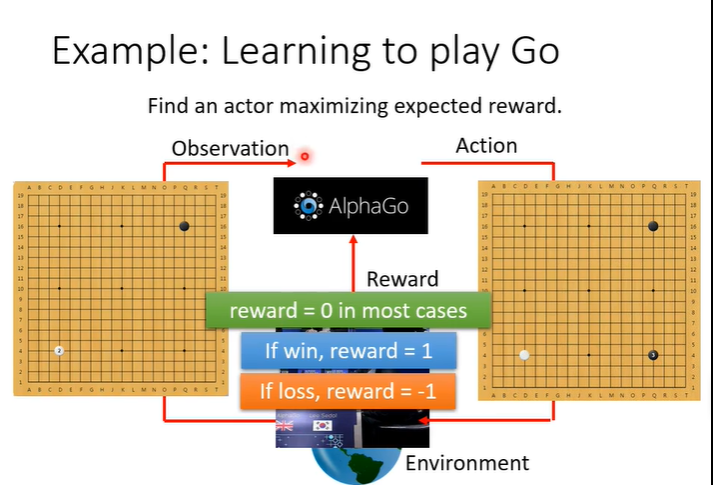
对于下围棋来说,输入就是棋盘,输出就是下一步落子的位置,然后环境在下白子,作为新的输入,这样反复下去可以让机器下围棋。但是在下围棋时,我们采取的任何行为都没办法得到reward,通常会定义赢了得到1分,输了得到-1分,只有在游戏结束时才能得到reward。
2.训练方法
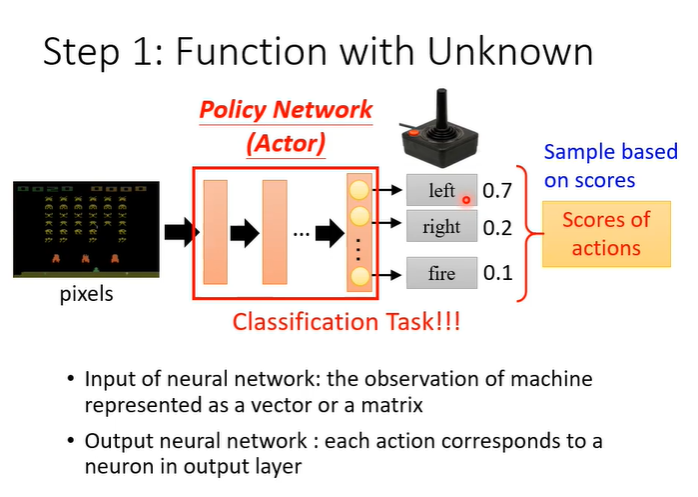
在RL中,actor就是network,通常称为policy network,输入就是游戏画面,输出就是每一个可以采取的行为的分数,根据分数采取行为,通常将分数当作几率,如下图所示70%向左,20%向右,10%开火,这样的好处是,当遇到同样的游戏画面时,做出的行为略有不同,这样的随机性对游戏也许是重要的。
从游戏开始到结束(称为episode),游戏会采取很多行为,,每一个行为都可能得到reward,所有的reward集合起来得到total reward(R)。我们训练的目标就是R越大越好。那我们定义RL的loss就可以是-R。
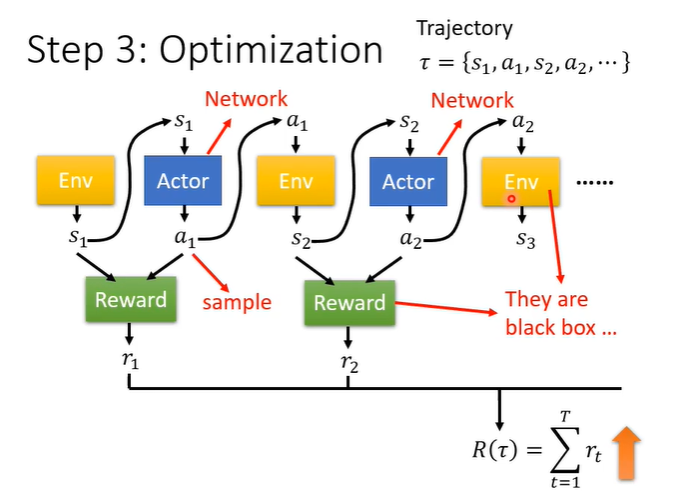
整个游戏过程如下图所示,环境env把画面s1输入actor,actor输出a1给env,env在输出s2给actor作为输入,如此反复直到游戏结束,这个过程产生的序列称为trajectory,根据互动过程会得到reward,将reward作为一个函数,输入是画面s和行为a,输出为r,所有的r集合起来得到R。optimization的问题是找一组actor的参数,让R越大越好。但是存在其他的问题,首先是actor的输出是随机的,同样的s不一定产生一样的a;还有一个更大的问题是,env和reward不算network且也可能具有随机性,他们只是一个黑盒子。
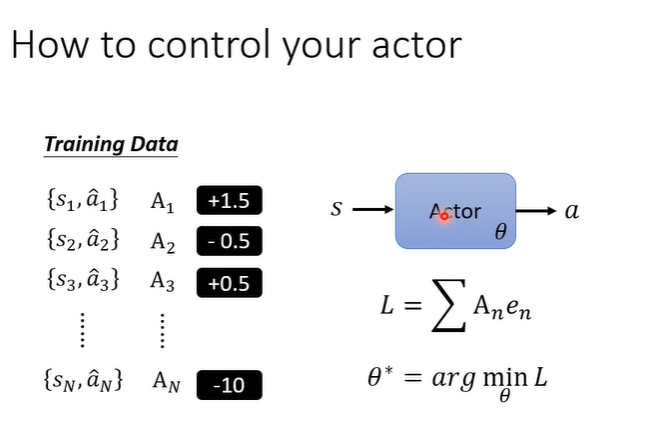
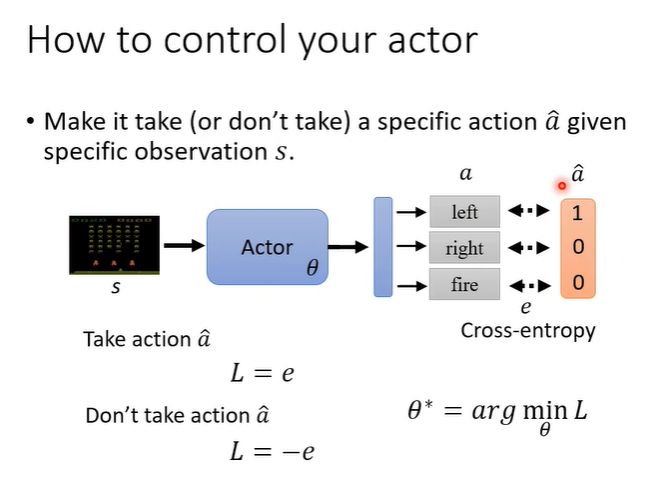
解决问题之前,先看我们如何控制actor。假设我们想要让actor看到s就向左,距离用cross-entropy计算,我们就会定义一个loss,让输出a与“向左”之间的loss最小;如果我们不想让actor做什么,就可以反过来,定义loss为-L,让输出与行为之间的loss最大。
将这两种loss相加就可以达成控制actor的效果。
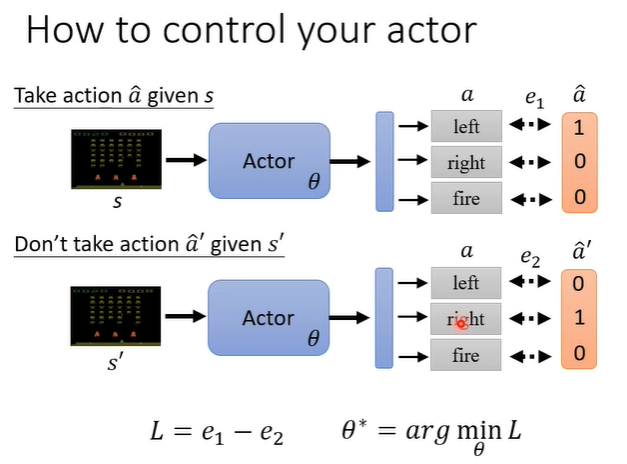
也可以进行扩展,不在局限于1和-1,希望在两种行为之间有更强烈的偏向意愿。在L求和前,乘上An。这样训练下去就得到一个我们期待行为的actor。