【数据库】表的设计
文章目录
- 三大范式
-
- 第一范式(1NF)
- 第二范式(2NF)
- 第三范式(3NF)
- 三大范式的 “度”
- 表的设计
-
- 一对一关系
- 一对多||多对一关系
- 多对多关系
- 总结
三大范式
刚接触数据库设计时,你是否遇到过这样的问题:同一条信息在表中反复出现(比如客户电话在订单表中重复存储),修改数据时漏改了某条记录导致前后不一致,或者查询一个简单信息却要写复杂的条件语句?其实这些问题,大多可以通过遵循 “数据库范式” 来解决。
数据库范式(Normal Form)是关系型数据库设计的核心准则,它通过规范表的结构,减少数据冗余、避免更新异常(插入、删除、修改时出现的逻辑错误),让数据存储更高效、更严谨。其中最基础也最常用的,就是第一范式(1NF)、第二范式(2NF)和第三范式(3NF)—— 这三大范式堪称数据库设计的 “入门必修课”。
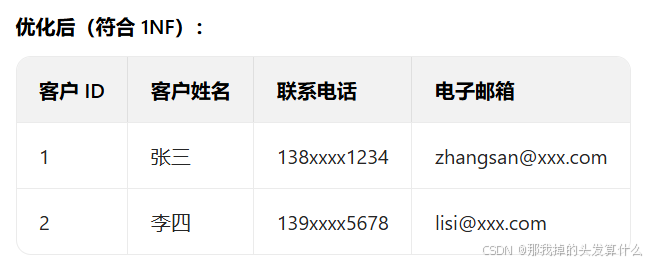
第一范式(1NF)
核心要求:数据表中的每一列都必须是 “原子值”(不可再拆分的最小单位),且列名唯一、顺序无关、每行数据不重复。
简单来说,1NF 要求我们 “拆到不能拆”。比如设计一个 “客户表”,如果直接写 “联系信息” 列,里面包含 “电话 + 邮箱”(如 “138xxxx1234;user@xxx.com”),就违反了 1NF—— 因为 “联系信息” 可以拆分成 “联系电话” 和 “电子邮箱” 两个独立的原子列。
注:如果不能满足第一范式,这个数据表不能作为数据库中的一张表,这张表就是错误的。可以继续拆分在关系型数据库中是不允许的。

第二范式(2NF)
核心要求:在满足 1NF 的基础上,表中的