STL容器string的模拟实现
在上一节已经学习了string的一些常用的接口,那这些接口如何实现?那下面就来学习string接口的模拟实现过程!!!
1. 构造函数的模拟实现
| 函数名 | 功能说明 |
| string() | 默认构造,构造空字符串 |
| string(const char* s) | 用字符串构造string类型字符串(string不含\0) |
| string(size_t n, char c) | 构造由n个字符c构成的字符串 |
| string(const string&s) | 拷贝构造,用string对象构造另一个string对象 |
主要模拟实现这四个接口:
(1)string()

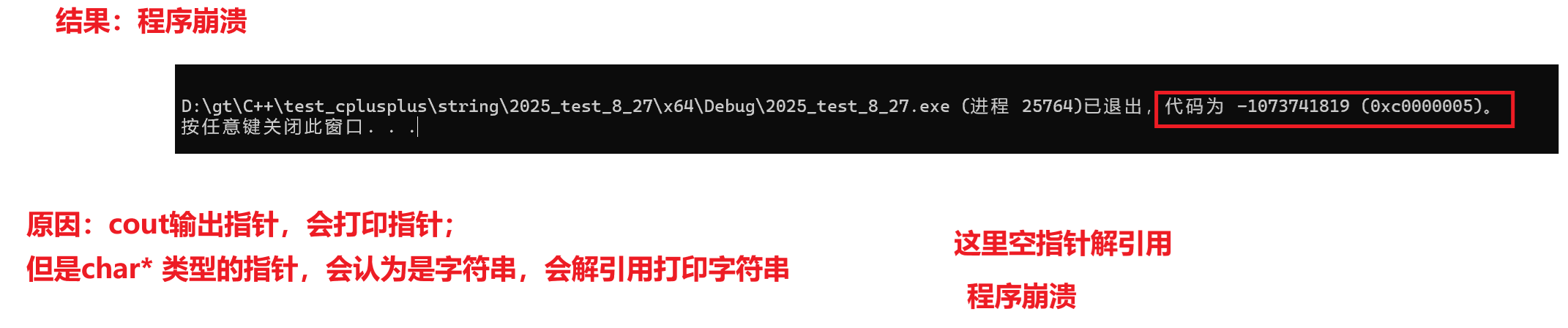
如果_str初始化为nullptr,那么程序会崩溃!!为什么会崩溃呢?
string():_str(new char[1]{'\0'}),_size(0),_capacity(0)
{
}(2)string(const char* s)
这里同样的,在开辟空间的时候要预留一个空间给'\0'!!
如果不给预留空间,而是用nullptr初始化,这里的strlen(s)就会对空指针解引用,导致程序崩溃!
但是这里会报警告:写入_str时缓冲区溢出,原因如下:

string::string(const char* s):_str(new char[strlen(s) + 1]), _size(strlen(s)), _capacity(strlen(s))
{for (size_t i = 0; i < _size; i++){_str[i] = s[i];}_str[_size] = '\0';
} 建议这样写:
string::string(const char* s):_size(strlen(s))
{_capacity = _size;_str = new char[_size + 1];for (size_t i = 0; i < _size; i++){_str[i] = s[i];}_str[_size] = '\0';
} (3)string(size_t n, char c)
string::string(size_t n, char c):_str(new char[n+1]),_size(n),_capacity(n)
{for (size_t i = 0; i < _size; i++){_str[i] = c;}_str[_size] = '\0';
}(4)string(const string&s)(拷贝构造)
//拷贝构造
string::string(const string& s)
{_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;
}2. reserve函数模拟实现
| void reserve (size_t n = 0); |
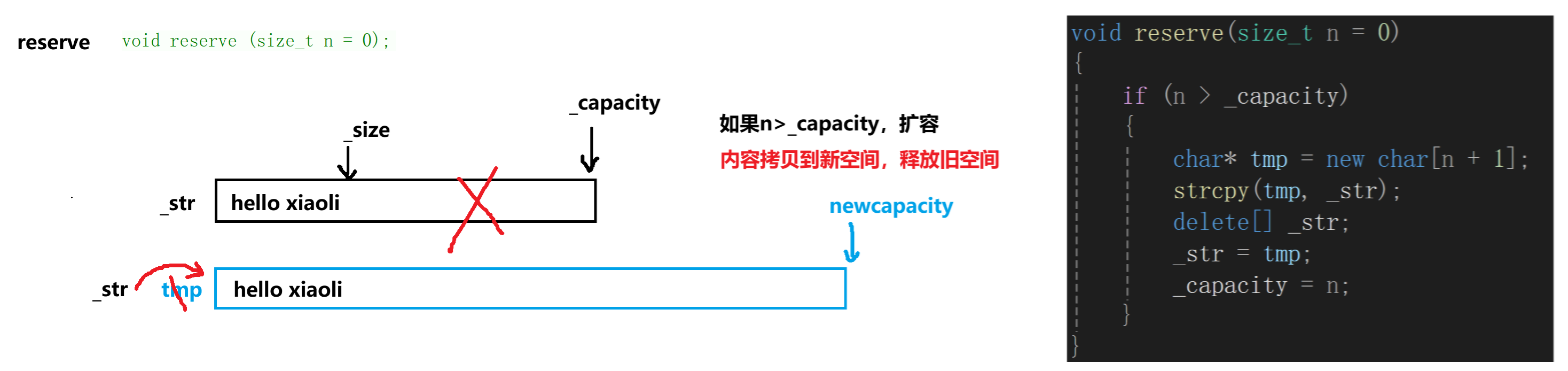
这里的reserve是深拷贝,所以需要新开辟空间马,并把原来的内容拷贝一份。
void string::reserve(size_t n)
{if (n > _capacity){//扩容char* _tmp = new char[n + 1];strcpy(_tmp, _str);delete[] _str;//释放_str = _tmp;_capacity = n;}
}3. push_back的模拟实现
| void push_back(char); |
判断空间容量够不够?
够,直接在_size的位置插入数据,不要忘记‘\0’!!
不够,扩容(一般是2倍扩容)!!

void string::push_back(char ch)
{if (_size + 1 > _capacity){// 扩容reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size] = ch;++_size;_str[_size] = '\0';
}4. append的模拟实现
append:即在末尾追加字符或者字符串!!
| string& append (const string& str); |
| string& append (const char* s); |
| string& append (size_t n, char c); |
第1步:判断空间容量够不够
第2步:不够 - > 扩容
够 - > 直接插入数据
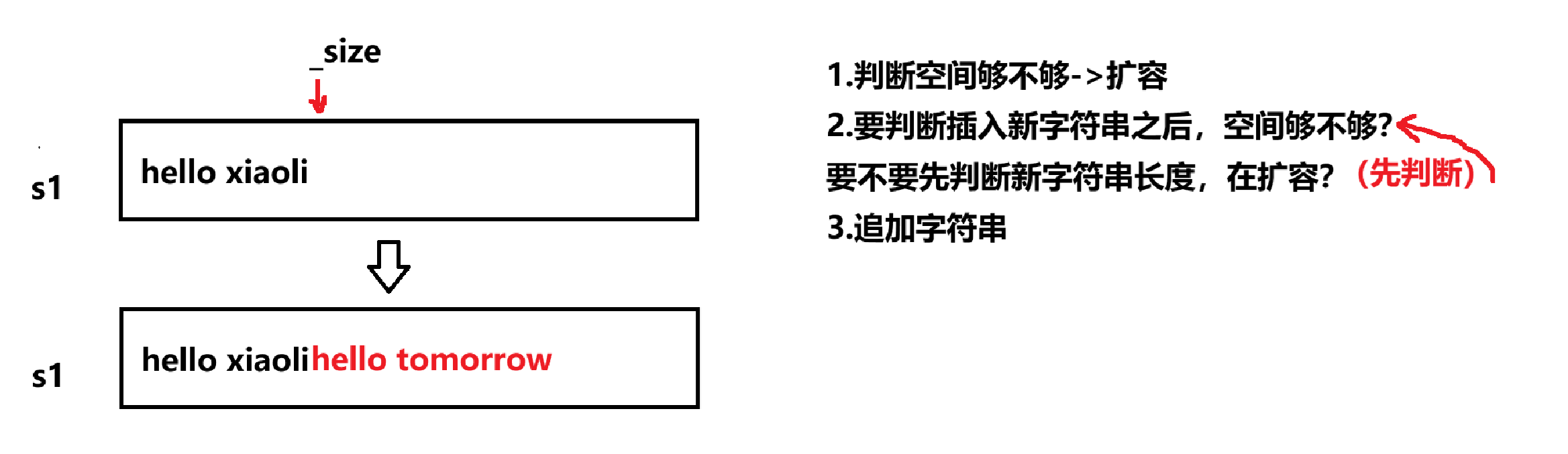
string& string::append(const char* s){size_t len = strlen(s);if (len + _size >= _capacity){// 方法1: 有多大扩多大/*size_t newcapacity = len + _size;reserve(newcapacity);*///方法2: 二倍扩容size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;if (newcapacity <= len + _size){newcapacity = len + _size;}reserve(newcapacity);}for (size_t i = 0; i < len; i++){_str[_size] = s[i];_size++;}_str[_size] = '\0';return *this;}5. insert的模拟实现
| string& insert (size_t pos, size_t n, char c); //在pos位置插入n个字符c |
| string& insert (size_t pos, const char* s); //在pos位置插入字符串 |
| string& insert (size_t pos, const string& str); //在pos位置插入string |
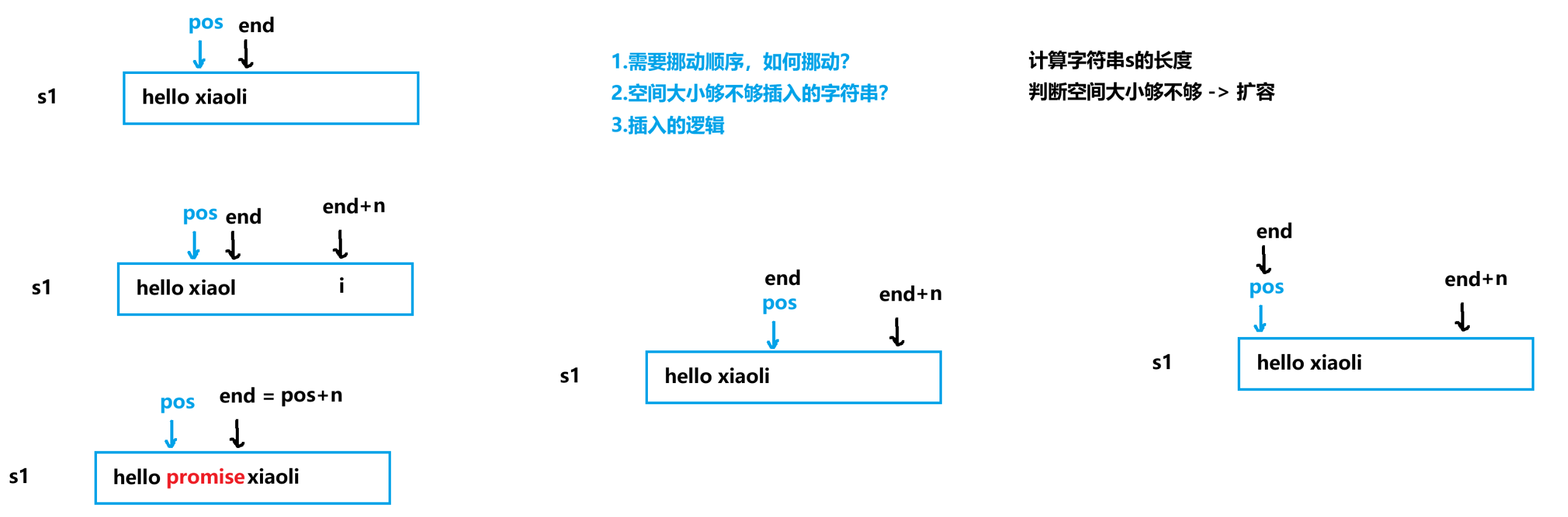
尾插,中间位置插入都是ok的,但是头插的时候程序就会崩溃,这是为什么?
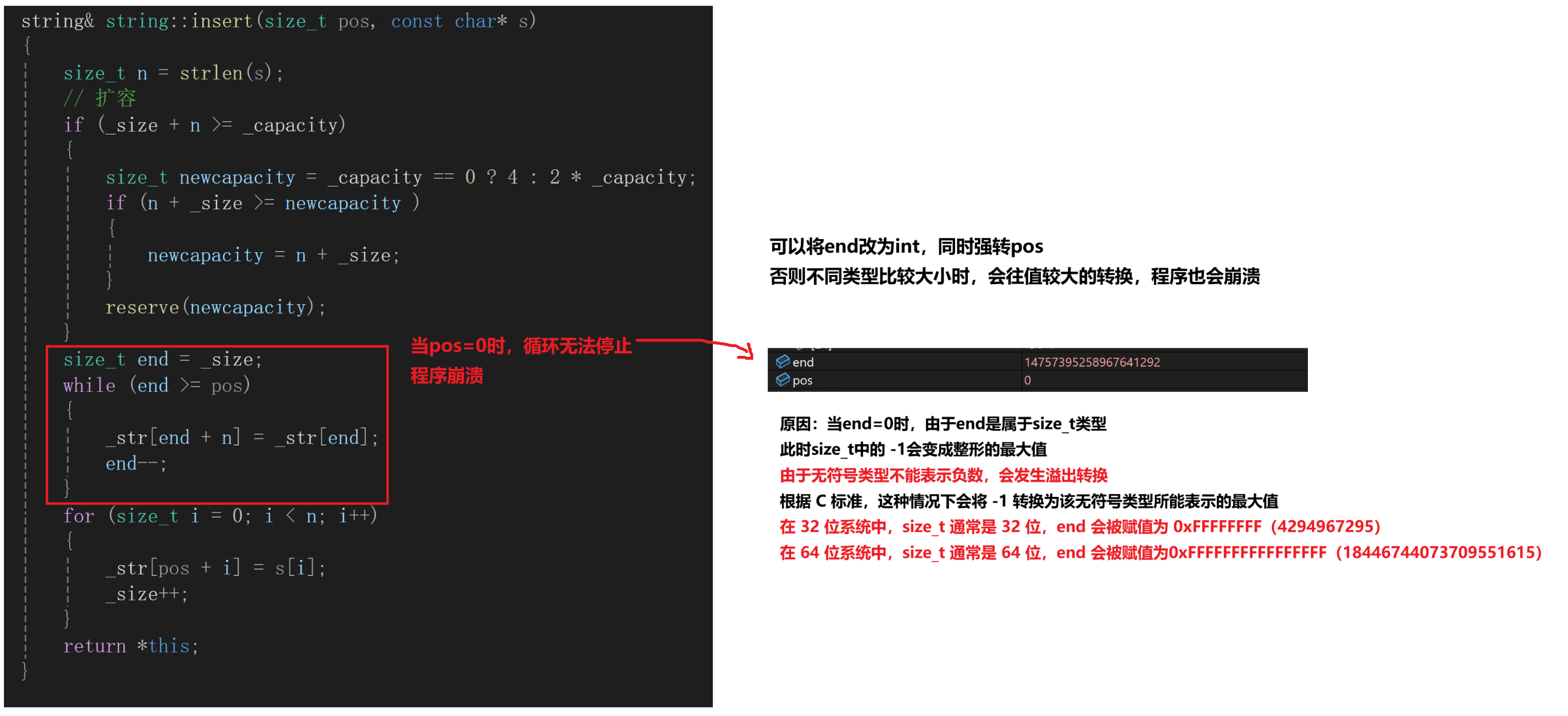
所以,要让数据从前挪到后面
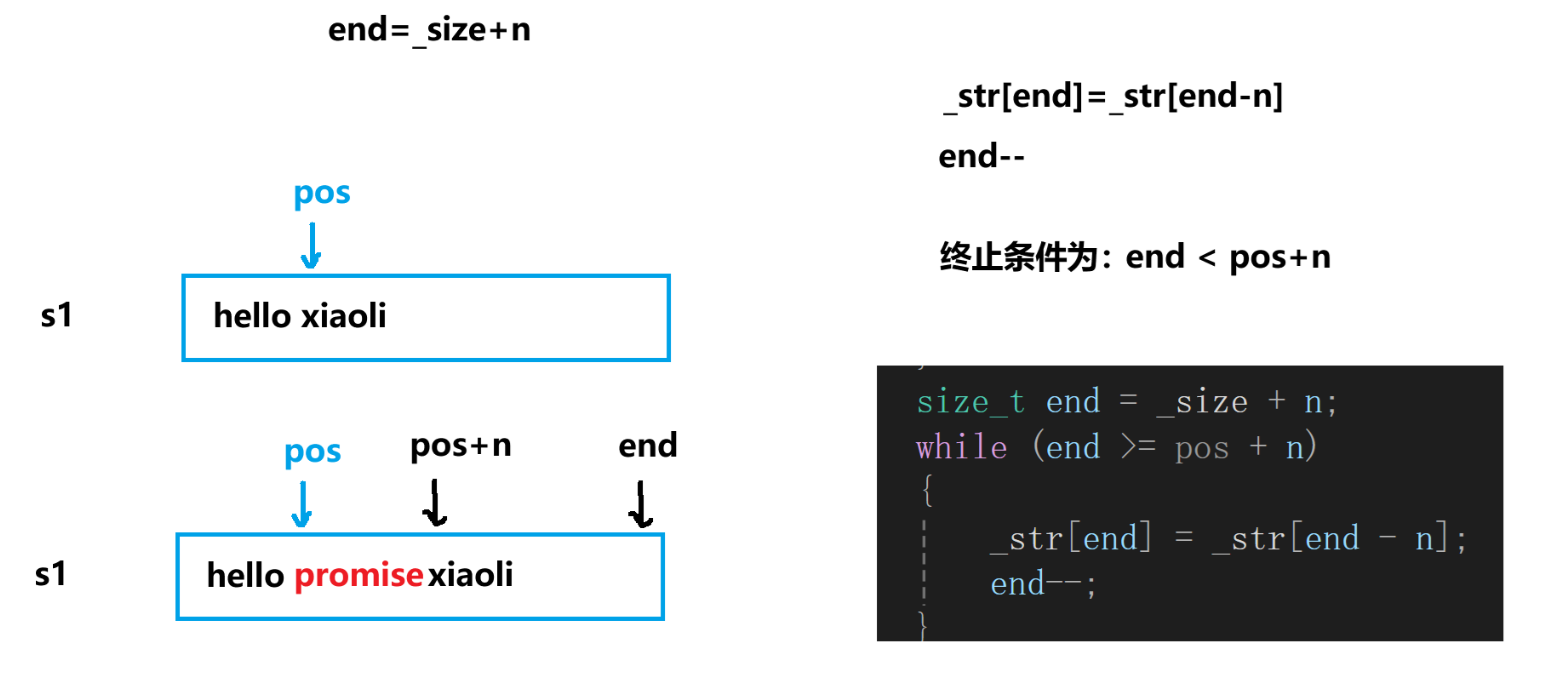
三个版本:
string& string::insert(size_t pos, size_t n, char c){// 先判断空间够不够if (_size + n > _capacity){size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;if (_size + n > newcapacity)reserve(_size + n);elsereserve(newcapacity);}// 开始插入数据 ,这里程序会崩溃,end=0的时候,end--会变成整形的最大值//size_t end = size();//for (size_t i = end; end >= pos; end--)//{// _str[end + n] = _str[end];//}size_t end = size() + n;for (size_t i = end; end >= pos + n; end--){_str[end] = _str[end - n];}for (size_t i = 0; i < n; i++){_str[pos + i] = c;_size++;}return *this;} string& string::insert(size_t pos, const char* s){int n = strlen(s);if (_size + n > _capacity){size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;if (_size + n > newcapacity)reserve(_size + n);elsereserve(newcapacity);}size_t end = size() + n;for (size_t i = end; end >= pos + n; end--){_str[end] = _str[end - n];}for (size_t i = 0; i < n; i++){_str[pos + i] = s[i];_size++;}return *this;} string& string::insert(size_t pos, const string& s){int n = s.size();if (_size + n > _capacity){size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;if (_size + n > newcapacity)reserve(_size + n);elsereserve(newcapacity);}size_t end = size() + n;for (size_t i = end; end >= pos + n; end--){_str[end] = _str[end - n];}for (size_t i = 0; i < n; i++){_str[pos + i] = s._str[i];_size++;}return *this;}6. erase的模拟实现
| string& erase (size_t pos = 0, size_t len = npos); |
对于erase分为两种情况:(1)删除长度大于字符长度;(2)正常删除数据
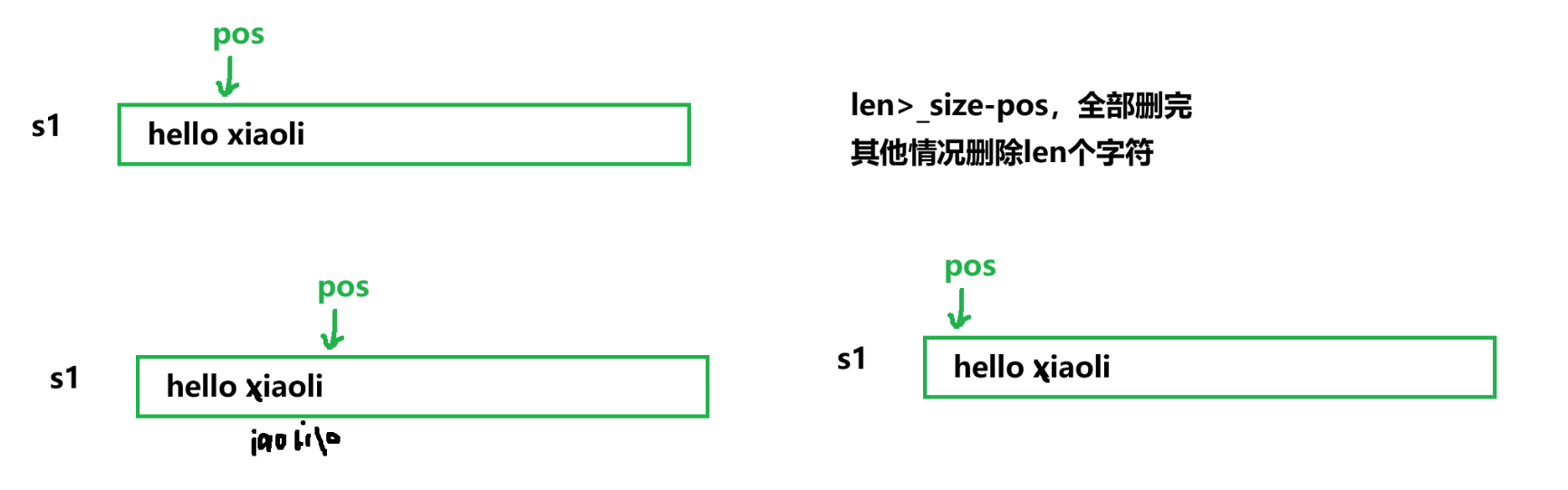
string& string::erase(size_t pos, size_t len){if (len > size() - pos){_str[pos] = '\0';_size = pos;}else{int tail = pos + len;for (size_t i = pos; tail <= _size; i++){_str[i] = _str[tail++];//tail++;}_size -= len;}return *this;}7. find的模拟实现
| size_t find (char c, size_t pos = 0) const; |
| size_t find (const char* s, size_t pos = 0) const; |
| size_t find (const string& str, size_t pos = 0) const; |
find的实现原理很简单,遍历字符串就可以。
size_t string::find(char c, size_t pos) const{for (size_t i = pos; i < _size; i++){if (_str[i] == c){return i;}}return npos;} size_t string::find(const char* s, size_t pos) const{const char* ch = strstr(_str, s);if (ch != nullptr){return ch - _str;}elsereturn npos;}8. operator[ ]的模拟实现
| char& operator[] (size_t pos); |
| const char& operator[] (size_t pos) const; |
operator[ ]的原理和find类似,这里就直接看代码就行
char& string::operator[] (size_t pos){return _str[pos];}9. string容量的模拟实现
这部分很简单,函数套个壳子就行
void string::clear(){_str[0] = '\0';_size = 0;}size_t string::size() const{return _size;}bool string::empty() const{return _capacity == 0;}10. resize的模拟实现
注意区别:
如果n>capacity:扩容+插入数据;
如果size<n<capacity:插入数据;
如果n<size:删除数据。
void string::resize(size_t n, char c){if (n > _capacity){reserve(n);for (size_t i = _size; i < n; i++){push_back(c);}}else if (_size < n && n < _capacity)//不能写成a<b<c(即0/1<c){for (size_t i = _size; i < n; i++){push_back(c);}}else if (n < _size){_str[n] = '\0';_size = _capacity = n;}}11. operator=的模拟实现

//旧版string& string::operator=(const string& s){if (*this != s){char* tmp = new char[s._capacity];strcmp(tmp, s._str);delete[] _str;_str = tmp;_size = s._size;}return *this;}优化改进:
方法1:创建一个临时变量,让临时变量代替完成赋值操作,再把临时变量和目标对象交换,最后出作用域临时变量会自动销毁,同时也完成了赋值操作!!!
void string::swap(string s){std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}优化string& string::operator=(const string& s){string tmp(s);swap(tmp);return *this;}方法2:直接传值调用,利用拷贝构造构造一份临时变量作为形参,代替完成赋值工作,最后和目标对象交换数据即可
//再优化string& string::operator=(string s){swap(s);return *this;}总结:
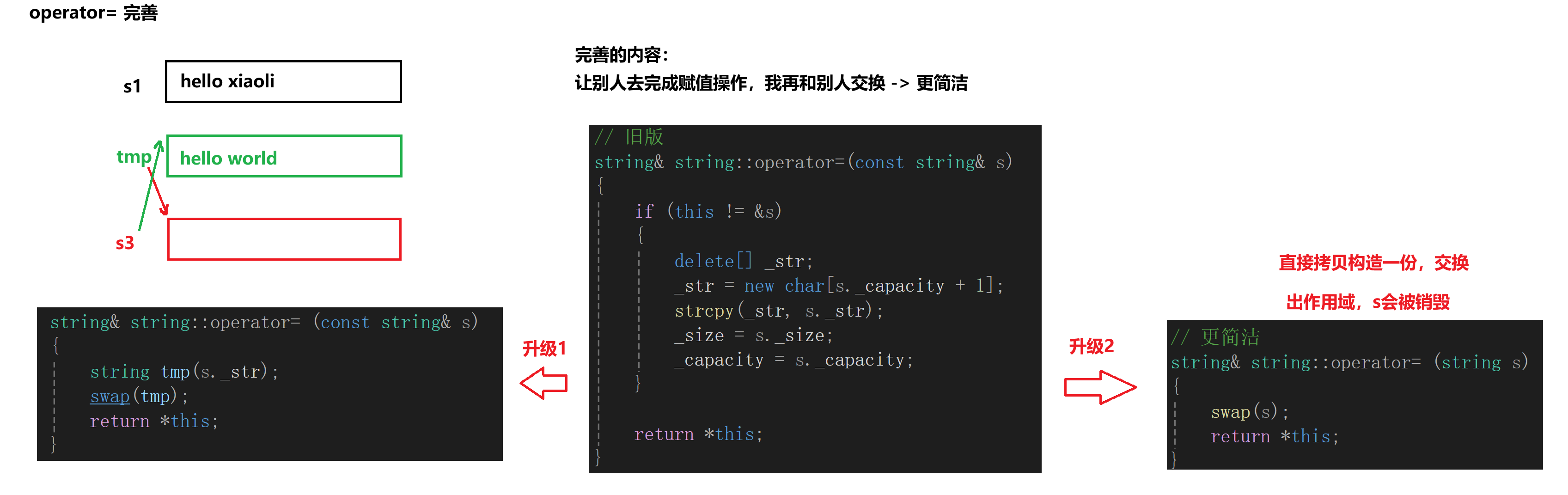
12. operator+=的模拟实现
operator+=类似在末尾追加字符或者字符串。原理和代码与push_back类似,就不详细介绍了。
string& string::operator+= (char c){if (_size == _capacity){size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;reserve(newcapacity);}_str[_size] = c;_size++;_str[_size] = '\0';return *this;} string& string::operator+= (const char* s){size_t n = strlen(s);// 先判断是否需要扩容if (_size + n > _capacity){size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;if (_size + n > newcapacity)reserve(_size + n);elsereserve(newcapacity);}for (size_t i = 0; i < n; i++){_str[_size++] = s[i];}_str[_size] = '\0';return *this;}13. operator>>的模拟实现

原始版本
istream& operator>> (istream& in, string& s){char ch;in >> ch;//会跳过空字符while (ch != '\0' || ch != ' '){s += ch;in >> ch;}return in;}那这个时候我们就得了解三个函数的区别:>> 和 get() 和 getline()三者的区别!!

istream& operator>> (istream& in, string& s){s.clear();//清除原来的数据char ch = in.get();while (ch != '\0' || ch != ' '){s += ch;ch = in.get();}return in;}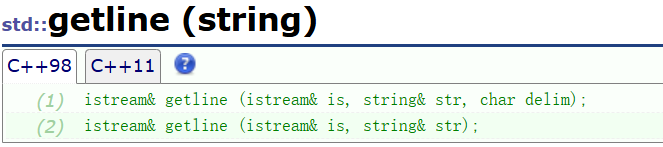

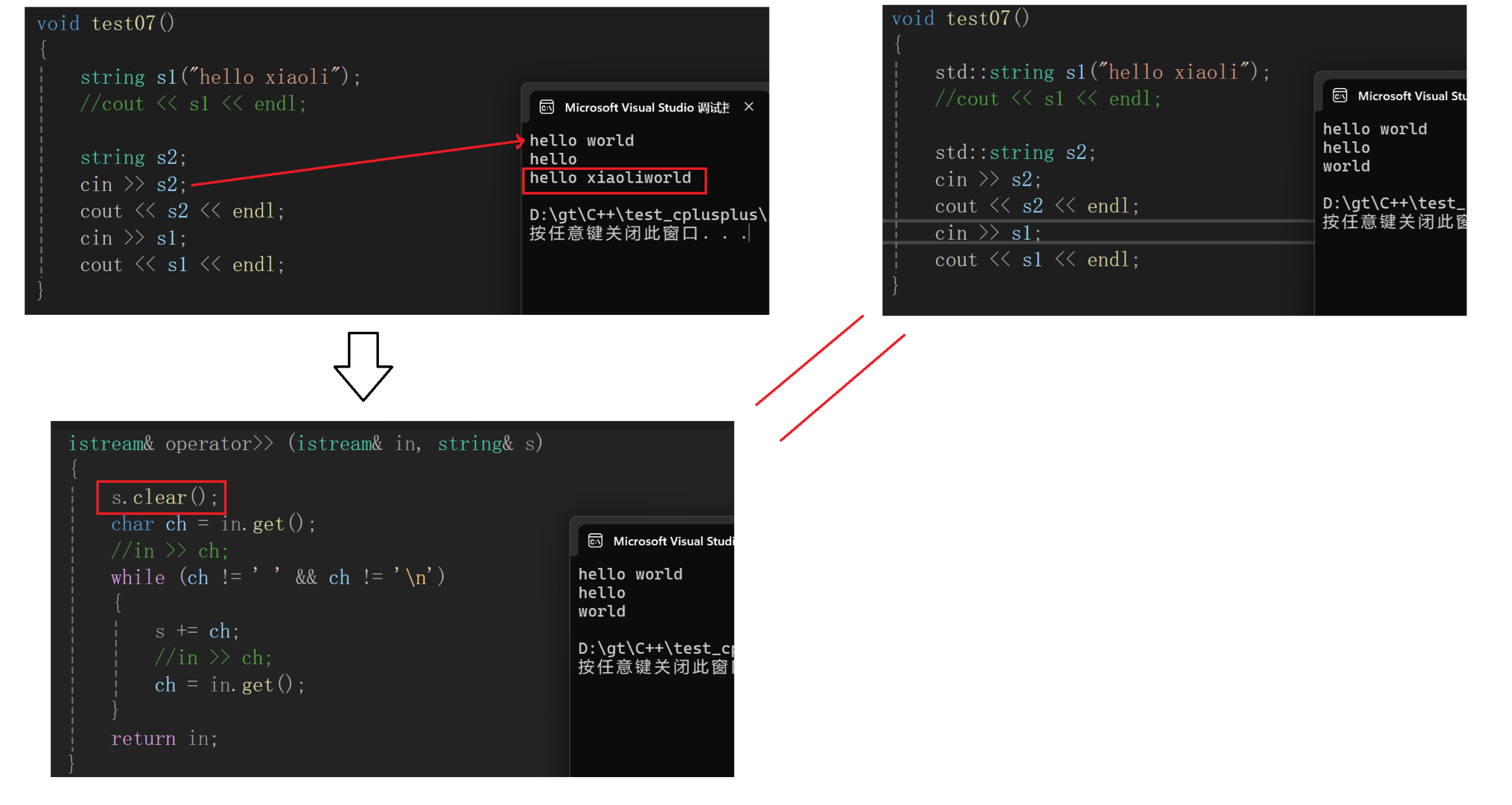
我们知道如果字符过长,那么每次插入都会扩容,就很浪费时间,那如何解决频繁扩容的问题?
于是就提出了缓冲数组,输入的数据先存放到临时数组(可大可小),当临时数组满了再插入数据,如果数据量大,创建一个大空间临时数组;数据量小,创建一个小空间临时数组(也可以不用)。
那代码就可以进一步优化:
优化版本
istream& operator>> (istream& in, string& s)
{s.clear();//为了避免频繁扩容,创建一个缓冲数组int i = 0;char buffer[1024] = "0";//获取字符串char ch = in.get();//输入且能够读取分隔符//while (ch != '\n' && ch != ' ')while (ch != '\n'){buffer[i++] = ch;;if (i == 1023){buffer[0] = '\0';s += buffer;i = 0;}ch = in.get();}//到这里遇到指定符号,停止写入//但是buffer可能还有数组if (i > 0){buffer[i] = '\0';s += buffer;}return in;
}getline版本
istream& getline(istream& in, string& s, char delim)
{s.clear();//为了避免频繁扩容,创建一个缓冲数组int i = 0;char buffer[1024];//获取字符串char ch = in.get();//输入且能够读取分隔符while (ch != delim){buffer[i++] = ch;;if (i == 1023){buffer[0] = '\0';s += buffer;i = 0;}ch = in.get();}//到这里遇到指定符号,停止写入//但是buffer可能还有数组if (i > 0){buffer[i] = '\0';s += buffer;}return in;
}14. string迭代器iterator
在string容器里面,迭代器还不算很难,返回的对应地址。
这里是string里面的迭代器,其中现阶段会频繁使用前两个begin和end。
那这两个底层是如何实现的?其实底层就是反应对应的地址,地址解引用取到数据。如果数据类型是结构体或者类类型就需要重载对应的操作符。
begin:返回首元素的地址;
end:返回最后一个元素的下一位置的地址。

typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return (_str + _size);}const_iterator begin() const{return _str;}const_iterator end() const {return (_str + _size);}15. operator<<的模拟实现
遍历输出即可
ostream& operator<< (ostream& out, const string& s){string::const_iterator it = s.begin();while (it != s.end()){cout << *it << " ";it++;}cout << endl;return out;}16. c_str的模拟实现
注意:string是不包含'\0'的,如果要打印string,那么就得转换为含有'\0'的版本(如果没有,找不到终止符无法停止,程序报错),那么C++就提供了c_str,转换为C语言字符串版本。
const char* c_str() const{return _str;}还有一些大小关系的比较,只需要清楚字符串的比较是按照ascll码进行比较的,按照首字符去比,如果首字符相同,再比较下一个字符!!!
如果想要查看,可以去我的gitee查看:
田野追逐星光 (chasing-starlight-in-the-field) - Gitee.com
那么到这里,string的模拟就实现的差不多了,下一节会讲述一个新的容器vector,敬请期待!!