BLIP 系列全解析与深度面经:从视觉语言统一到跨模态对齐的演进

🧔 这里是九年义务漏网鲨鱼,研究生在读,主要研究方向是人脸伪造检测,长期致力于研究多模态大模型技术;国家奖学金获得者,国家级大创项目一项,发明专利一篇,多篇论文在投,蓝桥杯国家级奖项、妈妈杯一等奖。
✍ 博客主要内容为大模型技术的学习以及相关面经,本人已得到B站、百度、唯品会等多段多模态大模型的实习offer,为了能够紧跟前沿知识,决定写一个“从零学习 RL”主题的专栏。这个专栏将记录我个人的主观学习过程,因此会存在错误,若有出错,欢迎大家在评论区帮助我指出。除此之外,博客内容也会分享一些我在本科期间的一些知识以及项目经验。
🌎 Github仓库地址:Baby Awesome Reinforcement Learning for LLMs and Agentic AI
📩 有兴趣合作的研究者可以联系我:yirongzzz@163.com
BLIP 系列全解析与深度面经:从视觉语言统一到跨模态对齐的演进
摘要
本文深入剖析 Salesforce 提出的 BLIP 系列模型(BLIP、BLIP-2),系统讲解其从图文理解到生成的统一预训练框架、Q-Former 的结构本质,以及其在多模态与大语言模型融合中的核心思想。文章最后附带深度面试问答,帮助你不仅“看懂”,还能“说清楚”模型设计的来龙去脉。
文章目录
- BLIP 系列全解析与深度面经:从视觉语言统一到跨模态对齐的演进
- 一、BLIP:图文统一预训练的开端
- 1.1 模型架构解析
- 1.2 三任务联合预训练目标
- 1.3 CapFilt:自举式数据增强机制
- 二、BLIP-2:冻结模型下的跨模态对齐革命
- 2.1 架构总览
- 2.2 Q-Former 的设计思想
- 2.3 两阶段训练机制
- 阶段一:视觉语言特征学习
- 阶段二:图像到文本生成
- 三、BLIP1 vs BLIP2:从自举到对齐的演进
- 四、Q-Former 与其他对齐方法对比
- 五、面经专栏:核心问题深度解析
- ❓Q1. 为什么要调整 Q-Former?
- ❓Q2. A-Former 的作用是什么?
- ❓Q3. 千问(Qwen-VL)与 BLIP-2 的区别?
- ❓Q4. BLIP1 与 BLIP2 的主要区别?
- ❓Q5. 除了 Q-Former,对齐向量还有哪些方法?
- 六、总结与展望
一、BLIP:图文统一预训练的开端
作者指出,现有的视觉-语言预训练(Vision-Language Pre-training, VLP)模型在语言理解与生成任务上难以同时取得优异表现:一方面,基于编码器(encoder-based)的模型在生成任务中的适应性较差;另一方面,编码器-解码器(encoder-decoder)结构虽然适用于生成任务,但尚未在图文检索等理解任务中取得显著成果。此外,目前广泛采用的数据集仍存在大量文本噪声,进一步限制了模型的性能提升。因此,作者提出BLIP(Bootstrapping Language-Image Pretraining)解决了视觉语言任务中“理解”和“生成”割裂的问题。传统 CLIP 等模型擅长检索(理解),但无法自然生成文本描述;而如 SimVLM、VinVL 虽能生成,但对检索类任务表现欠佳。BLIP 的创新在于统一结构 + 多任务联合训练 + 自举式数据增强(CapFilt)。
1.1 模型架构解析
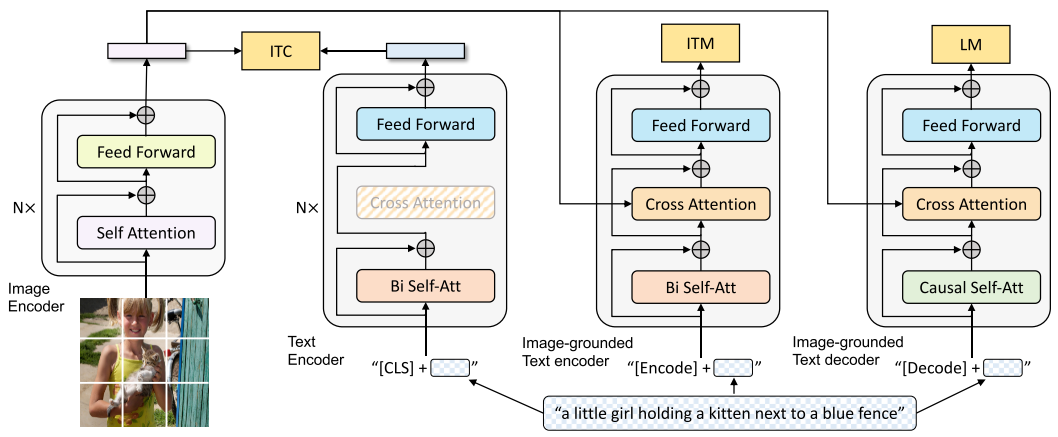
- 图像特征提取模型:
VIT - 文本特征提取模型:
Unimodal encoder;Image-grounded text encoder;Image-grounded text decoder
Unimodal encoder:基于BERT实现;[CLS]为句子的特征表示;
Image-grounded text encoder: Transformer block中,在self-attention(SA)和Feed forward network(FFN)之间加入了Cross Attention(CA),融入图像特征信息,[Encode]为图文对的特征表示;
🧠 为什么加入Cross Attention以及怎么加入的?
- 在标准 Transformer 中,Self-Attention 只能在同一模态内部建模依赖,难以实现多模态融合。为了提升模型对跨模态语义的建模能力,Cross-Attention 被加入到 SA 与 FFN 之间,作为一种跨模态交互机制。其本质是将当前模态的 token 作为 Query,另一模态的 token 作为 Key 和 Value,实现“信息注入”。这种结构广泛用于图文预训练(如 BLIP2 的 Q-Former)、多模态对齐、图文检索等任务中。
Image-grounded text decoder :将Transformer block中bi-directional self-attention layers 改为 causal self-attention layers, [Decode]表示句子的开始,end-of-sequence token表示句子的结束;
🧠 为什么要改为 Causal attention layer?
- 在将原始的图像引导文本编码器改为生成器时,我们将其中的 bi-directional self-attention 改为 causal self-attention。这是因为生成任务要求模型按序预测每一个词,不能访问未来的信息。Causal attention 能保证自回归生成的正确性,使模型适合用作 decoder,实现图像到文本的自然语言生成。这种结构转变常见于图文生成、多模态问答等任务中,例如 BLIP、BLIP-2。
🧠 两种注意力的区别
- Bi-directional 和 causal attention 的实现差异主要在于 attention mask 的构造。双向注意力不使用 mask 或允许所有 token 互相可见,适合语义理解任务。因果注意力则使用下三角 mask,保证每个位置只能看到自己和前面的 token,用于自回归生成任务。它们的核心区别是是否允许访问“未来信息”
综上所述,BLIP 包含三类 Transformer 模块:
| 模块 | 注意力类型 | 作用 | 输出特征 |
|---|---|---|---|
| Unimodal Encoder | 双向 Self-Attention | 提取文本特征 | [CLS] 向量 |
| Image-grounded Text Encoder | Cross-Attention + 双向 Self-Attention | 图文融合与匹配 | 图文对嵌入 |
| Image-grounded Text Decoder | Cross-Attention + Causal Self-Attention | 图像引导文本生成 | 序列 token 概率 |
这种结构等价于在 BERT 基础上,插入跨模态交互层:
# simplified Cross-Attention layer
attn_output, _ = cross_attn(query=text_hidden, key=image_feat, value=image_feat
)
text_hidden = text_hidden + attn_output
💡 Cross-Attention 实现模态交互:文本作为 Query,图像特征作为 Key/Value。
这种设计被 BLIP2、Flamingo、LLaVA、Qwen-VL 等继承,成为统一图文 Transformer 的通用范式。
1.2 三任务联合预训练目标
BLIP 通过三种损失实现全局对齐、局部匹配、语言生成:
| 任务 | 名称 | 核心思想 | 示例 |
|---|---|---|---|
| 对比学习 | ITC (Image-Text Contrastive) | CLIP式全局对齐 | 推动正样本相似度 ↑ |
| 匹配判别 | ITM (Image-Text Matching) | 局部语义判别 | 二分类 Loss |
| 语言建模 | LM (Language Modeling) | 自回归生成 | Cross-Entropy |
示例代码(简化版 InfoNCE):
def itc_loss(img, txt, tau=0.07):logits = img @ txt.T / taulabels = torch.arange(img.size(0), device=img.device)return F.cross_entropy(logits, labels)
1.3 CapFilt:自举式数据增强机制
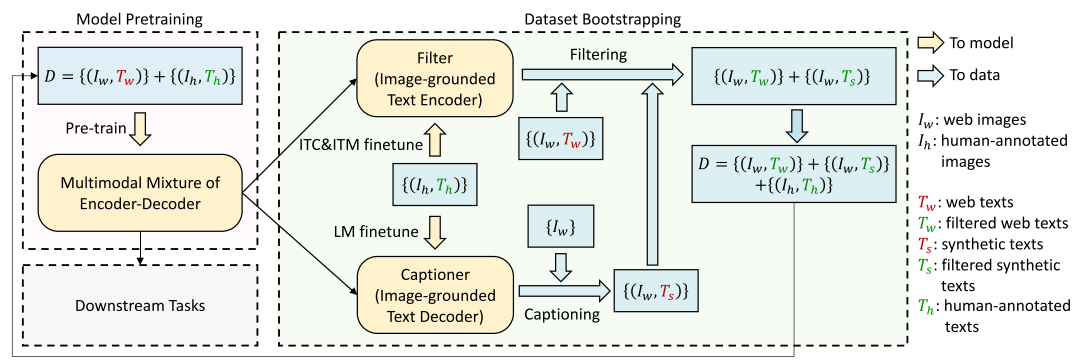
BLIP 的亮点在于 CapFilt 自训练策略,包含了captioner 和 filter 两个模块,这两个模块采用相同的预训练模型,并先用COCO数据集进行微调。captioner 基于Image-grounded text decoder生成图像标题,filter基于Image-grounded text encoder从生成的文本以及原始文本中过滤掉噪声(不匹配)文本,通过 ITC 和 ITM 两个损失函数优化。最后组成一个新的数据集预训练模型。
Captioner生成伪文本(caption);Filter模块根据图文一致性(ITM + ITC)过滤噪声文本;- 将生成的高质量伪样本加入下一轮预训练。
这样,模型能在弱标注数据上自我迭代,显著提升泛化能力。
🧩 这就是 “Bootstrapping” 名称的由来 —— 模型通过自身生成与筛选数据自举成长。
二、BLIP-2:冻结模型下的跨模态对齐革命
BLIP-2(Bootstrapping Language-Image Pretraining with Frozen Image Encoders and Large Language Models)在 2023 年提出,核心目标是:
如何让冻结的视觉编码器与大型语言模型(LLM)高效协同?
2.1 架构总览
BLIP-2 采用“两阶段预训练 + 模型冻结”的轻量架构:
| 阶段 | 模块 | 作用 | 特点 |
|---|---|---|---|
| 阶段一 | Q-Former + 冻结图像编码器 | 图文语义对齐 | 轻量学习 |
| 阶段二 | Q-Former + 冻结 LLM(OPT/T5) | 图文到文本生成 | 无需端到端训练 |
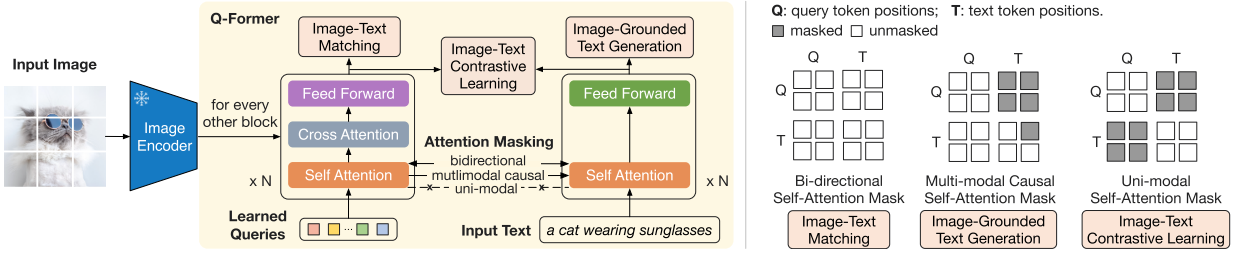
图示:BLIP-2 在冻结 ViT 与 LLM 的前提下,用 Q-Former 作为语义桥梁。
2.2 Q-Former 的设计思想
主要作用就是对齐两个不同模态的冻结预训练模型
🟢 Q-Former包含了两个transformer子模块:(1)Image Transformer (特征提取) (2) Text transformer (作为文本编码器和解码器) ;
🟢 一组可学习的查询嵌入向量作为 Image Transformer 的输入,这些向量在self-attention layer相互联系以及通过 cross-attention layer与预训练的图像模型特征交互; 除此之外,这组可学习的嵌入向量也与文本token进行拼接作为Text transformer的输入;
🟢 将Q-Former初始化为 BERTbase\text{BERT}_{\text{base}}BERTbase, cross-attention layer是随机初始化的;同时查询向量的大小为:(32×76832 \times 76832×768)
# simplified QFormer interaction
Q = self.query_embed # learnable (32, 768)
img_feat = frozen_vit(image)
for block in self.blocks:Q = block(Q, img_feat) # Cross-Attention
return Q.mean(dim=1)
💬 可以理解为:Q-Former 在高维视觉特征空间中,自动学习到最有效的信息瓶颈,从而实现模态压缩与对齐。
2.3 两阶段训练机制
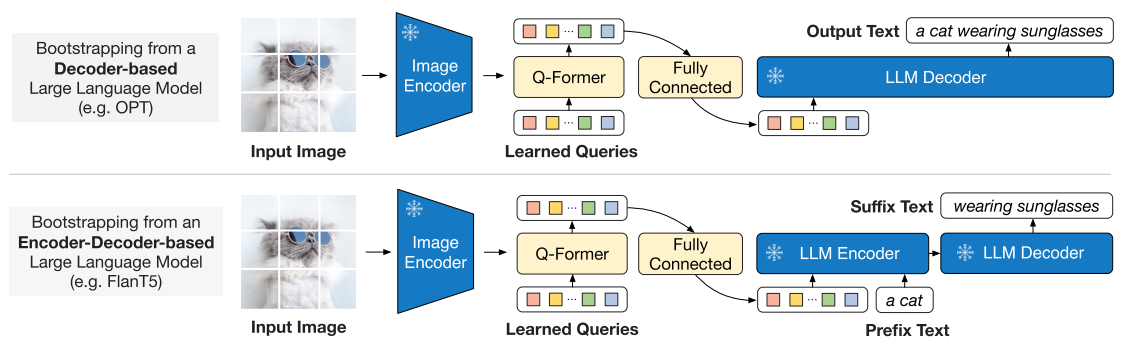
阶段一:视觉语言特征学习
冻结视觉编码器,只训练 Q-Former + 文本头,优化 ITC、ITM、ITG 三任务。
目标是让 Query token 捕获最相关的视觉语义。
阶段二:图像到文本生成
冻结 LLM 参数,只训练视觉到语言映射层(Projection Layer)。
| LLM类型 | 模型示例 | 输入形式 | 说明 |
|---|---|---|---|
| Decoder-only | GPT, OPT | Query token → 前缀 | LLM自回归生成 |
| Encoder-Decoder | T5, BART | Query + 前缀 → 后缀 | Prefix-LM Loss |
这种两阶段设计极大降低了计算成本,同时保留了 LLM 的生成能力。
三、BLIP1 vs BLIP2:从自举到对齐的演进
| 维度 | BLIP | BLIP-2 |
|---|---|---|
| 模型类型 | Encoder-Decoder 混合 | Frozen Encoder + LLM |
| 融合机制 | Cross-Attention | Q-Former |
| 数据增强 | CapFilt 自训练 | 冻结特征蒸馏 |
| 任务侧重 | 图文统一预训练 | 视觉-语言桥接 |
| 训练代价 | 高 | 显著降低 |
| 可扩展性 | 中等 | 极强(兼容任意LLM) |
四、Q-Former 与其他对齐方法对比
| 方法 | 特征对齐策略 | 是否训练图像模型 | 是否训练语言模型 | 代表模型 |
|---|---|---|---|---|
| CLIP | 投影层 + 对比学习 | ✅ | ✅ | CLIP, ALIGN |
| BLIP | Cross-Attention 层 | ✅ | ✅ | BLIP |
| BLIP-2 | Query Token 映射 | ❌ | ❌ | BLIP-2 |
| Flamingo | Perceiver Resampler | ✅ | ✅ | DeepMind Flamingo |
| LLaVA | Linear Projection | ❌ | ✅ | LLaVA, MiniGPT-4 |
| Qwen-VL | Adapter+Alignment Head | ❌ | ✅ | Qwen-VL, InternVL |
💡 Q-Former 本质上是一种查询式模态对齐器(Query-based Alignment Module),区别于线性映射或投影层,更灵活也更具语义压缩力。
五、面经专栏:核心问题深度解析
以下问题均为笔者在面试大厂的问题
❓Q1. 为什么要调整 Q-Former?
答:Q-Former 是唯一可训练部分,它决定了模型如何从冻结视觉编码器中提取语义信息。
调整 Q-Former 相当于在“视觉语义瓶颈”处重新分配通道容量,让 Query token 更精确地捕获图像特征。
若不调整,跨模态对齐会退化为线性映射,导致生成文本质量下降。🔍 面试延伸:面试官常追问“为什么不用 MLP 对齐?” → 因为 MLP 只能线性变换特征,缺乏多层交互与注意力机制,无法建模语义子空间的多头信息。
❓Q2. A-Former 的作用是什么?
答:A-Former 是阿里 Qwen-VL 系列中提出的“Alignment Transformer”,用于图文对齐,类似 Q-Former 的结构。
核心思想相同:通过一组可学习 Query Token 与图像特征交互,从中提取对齐后的多模态特征表示。
不同在于:A-Former 多用于端到端联合训练,而 Q-Former 仅做特征桥接。🔍 对比总结:
- Q-Former:独立模块,可冻结上下游模型;
- A-Former:内嵌对齐结构,偏向 fine-tuning 适配。
❓Q3. 千问(Qwen-VL)与 BLIP-2 的区别?
答:Qwen-VL 借鉴了 BLIP-2 的架构理念,但做了更工程化的改造。
项目 BLIP-2 Qwen-VL 对齐方式 Q-Former A-Former 训练阶段 两阶段(视觉→语言) 单阶段 视觉模型 ViT-L (frozen) EVA2-CLIP-L (tuned) 文本模型 OPT/T5 Qwen LLM 模块接口 Query 输出线性映射 Adapter 融合多模态头
❓Q4. BLIP1 与 BLIP2 的主要区别?
答:核心区别在于“是否端到端训练”与“模态对齐策略”:
- BLIP1:端到端多任务预训练(ITC + ITM + LM),融合层多;
- BLIP2:通过 Q-Former 桥接冻结模型,分离训练阶段;
- 损失:BLIP1 强调三任务联合,BLIP2 分阶段独立优化;
- 代价:BLIP2 显著减少显存和训练时间(减少约90%)。
❓Q5. 除了 Q-Former,对齐向量还有哪些方法?
答:常见方法包括:
- Perceiver Resampler(Flamingo):将高维视觉特征压缩为固定 Query Token;
- Adapter Fusion(Qwen-VL, LLaVA):轻量 Adapter 将图像特征投影到语言模型 embedding 空间;
- Contrastive Projection(CLIP):共享对比学习语义空间;
- Token Merging(Kosmos-2):显式合并语义近似 token 提高效率。
🔍 从研究角度看,这些方法的差异在于是否保留 attention 交互结构:
- Q-Former/Perceiver → 动态交互
- Adapter/Projection → 静态映射
六、总结与展望
BLIP 系列的贡献是多模态模型范式的重大转折点。
- BLIP1 提出统一的图文理解与生成框架;
- BLIP2 进一步实现冻结模型下的轻量对齐;
- 其思想直接启发了 MiniGPT-4, LLaVA, Qwen-VL, InternVL, VisualGLM 等后续模型。
未来方向包括:
- 将 Q-Former 推广至视频、音频模态;
- Agentic RL 中用作多模态状态理解器(Perception Encoder);
- 与强化学习策略网络融合,实现具视觉理解能力的智能体(如视觉问答+动作决策)。
🧩 参考资料
- Salesforce LAVIS 官方实现
- Qwen-VL 技术报告
- MiniGPT-4 论文与源码