认识人工智能与大模型应用开发
目录
- 认识
- 大模型应用开发
- 模型部署
- 开放的大模型API
- 在云平台部署私有大模型
- 在本地服务器部署私有大模型
- 调用大模型
- 接口说明
- message
- role
- system(设定角色和任务背景)
- user(用户输入的具体指令)
- assistant(大模型生成的消息)
- 大模型应用
- 大模型应用开发
- 纯Prompt问答
- FunctionCalling
- RAG(检索增强生成)
- Fine-tuning
认识
Transformer,这是一种由多层感知机组成的神经网络模型,是现如今AI高速发展的最主要原因。
Transformer的一种功能:推理预测。
LLM如何生成大语言模型?
根据前文推测出接下来的一个词语后,把这个词语加入前文,再次交给大模型处理,推测下一个字。
大模型应用开发
模型部署
开放的大模型API
在云平台部署私有大模型
在本地服务器部署私有大模型
调用大模型

接口说明
请求方式,一般是POST
请求路径,url
请求参数:model,message(是一个消息数组,包括role,content)
message
role
system(设定角色和任务背景)
user(用户输入的具体指令)
assistant(大模型生成的消息)
比如上一轮对话生成的结果。
每一次发送请求时,都把历史对话中每一轮的User消息、Assistant消息都封装到Messages数组中,一起发送给大模型,这样大模型就会根据这些历史对话信息进一步回答,就像是拥有了记忆一样。
大模型应用
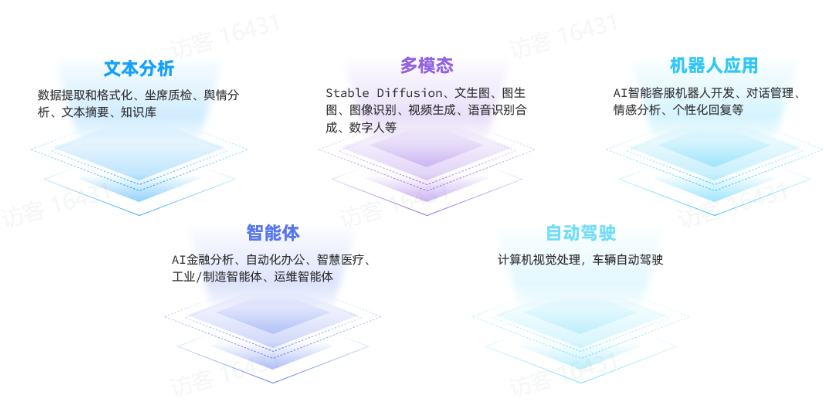
大模型应用开发
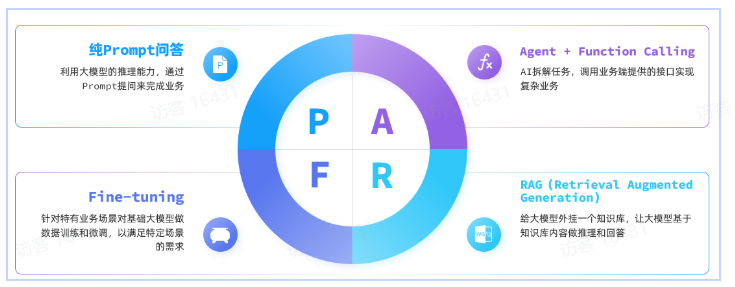
纯Prompt问答
AI应用再在用户的prompt基础上再继续组织优化。
FunctionCalling
传统应用中的部分功能封装成一个个函数(Function),根据prompt自己决定去调用。
RAG(检索增强生成)
- 检索模块(Retrieval):负责存储和检索拓展的知识库
- 文本拆分:将文本按照某种规则拆分为很多片段
- 文本嵌入(Embedding):根据文本片段内容,将文本片段归类存储
- 文本检索:根据用户提问的问题,找出最相关的文本片段
- 生成模块(Generation):
- 组合提示词:将检索到的片段与用户提问组织成提示词,形成更丰富的上下文信息
- 生成结果:调用生成式模型(例如DeepSeek)根据提示词,生成更准确的回答
Fine-tuning
模型微调,在预训练大模型(比如DeepSeek、Qwen)的基础上,通过企业自己的数据做进一步的训练,使大模型的回答更符合自己企业的业务需求。