部署DeepSeek-OCR
一、下载项目
1.将github上的项目下载到本地。
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git2.将项目从本地上传至服务器(注:以下操作均默认代码在服务器里)。
二、配置conda环境
1.根据readme文件的介绍,创建、激活deepseek-ocr环境。
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr安装torch、 torchvision、 torchaudio。
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
2.下载vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl,地址为:Release v0.8.5 · vllm-project/vllm。安装包在页面的最下边:
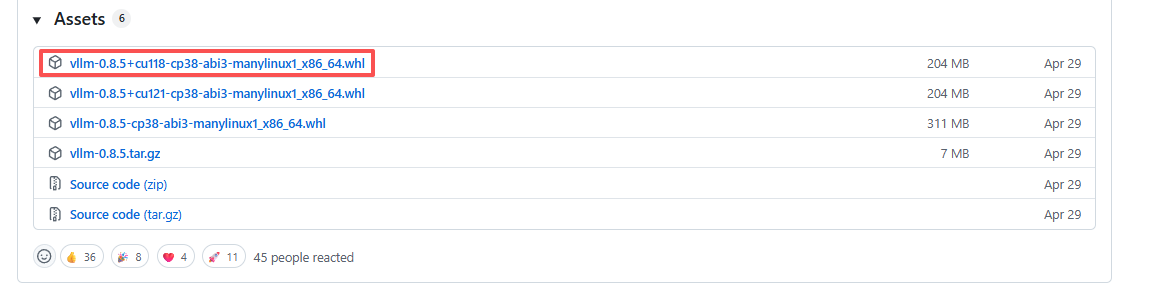
将安装包下载到本地后,从本地上传到服务器上的项目根目录,即“./DeepSeek-OCR-main/”目录下。再在conda环境中执行安装命令:
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
3.下载环境依赖:
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation注意: 安装过程中会遇到以下报错,但不用管。

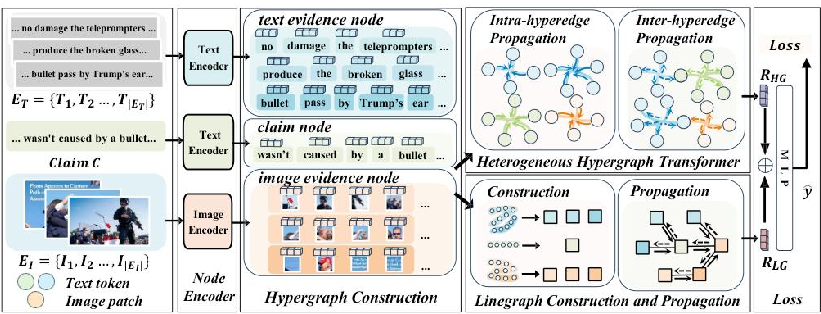
三、vLLM推理
1.介绍
(1)核心特点:
vLLM 是一种 高性能大语言模型推理引擎,它专门为加速 LLM 推理而设计。
DeepSeek-OCR 利用它来获得 更快的推理速度 和 更高的 GPU 内存利用率。
(2) 优点:
-
速度更快:vLLM 使用「PagedAttention」技术,减少显存碎片和冗余计算。
-
显存占用更低:比 transformers 推理更节省 VRAM。
-
支持批处理:可以同时处理多张图片或多段文本。
-
支持多 GPU 并行。
-
生产部署友好:适合在服务器上提供 API 接口或批量处理。
(3)缺点:
-
环境复杂(依赖 flash-attn、CUDA、vLLM 编译等)。
-
对版本要求严格(CUDA ≥ 11.8,PyTorch ≥ 2.1)。
-
不太方便调试和二次开发。
(4) 适用场景:
✅ 部署模型做高性能推理(比如你要做 OCR 服务或批量识别图片)
2.图片OCR(支持.jpg、.png等):流式输出
(1)更改DeepSeek-OCR的模型加载路径为本地加载路径。
即从huggingface上下载的DeepSeek-OCR的模型参数位置。具体地,在DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py中,将
MODEL_PATH = 'deepseek-ai/DeepSeek-OCR'
改为:
MODEL_PATH = '/opt/models/DeepSeek-OCR'(2)更改DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py中的图片输入输出路径。
例如输入图片为DeepSeek-OCR-main/assets/show2.jpg,新建一个output文件夹,输入输出的对应路径改为:
INPUT_PATH = '/workspace/lcc/DeepSeek-OCR-main/assets/show2.jpg'
OUTPUT_PATH = '/workspace/lcc/DeepSeek-OCR-main/output/show2'
(3)在终端运行代码,执行以下命令:
python run_dpsk_ocr_image.py(4)输入输出示例
输入:
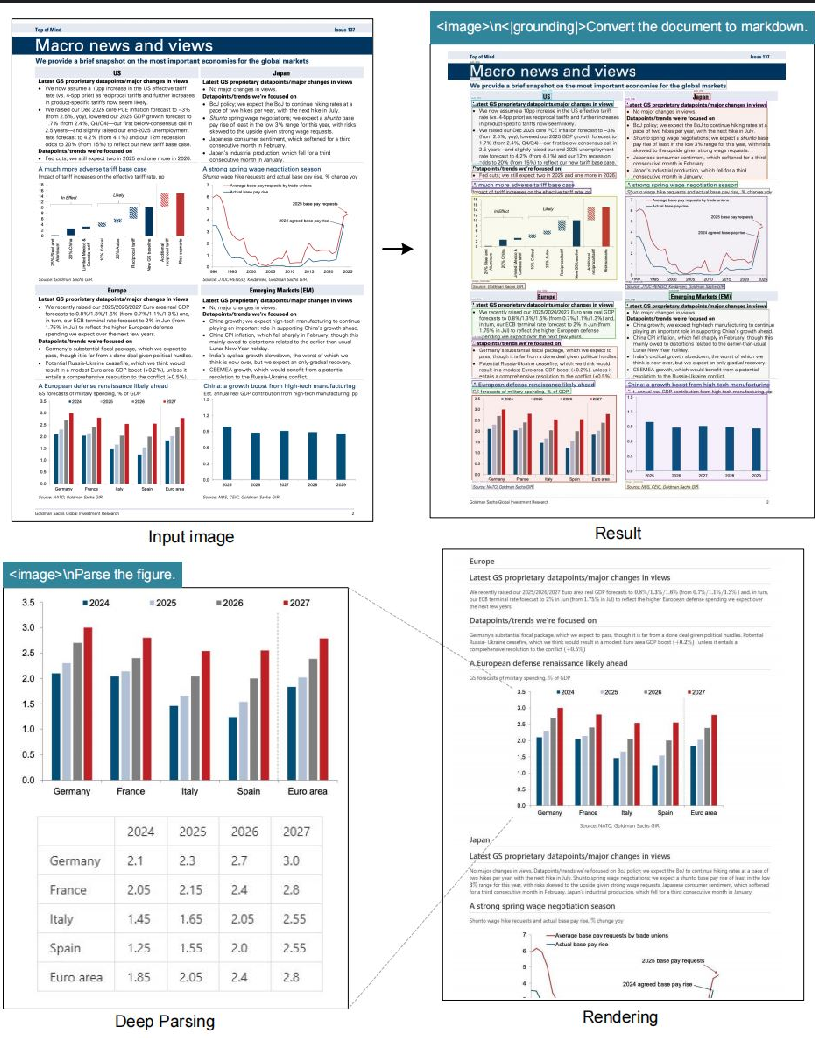
输出:
①result_with_boxes.jpg
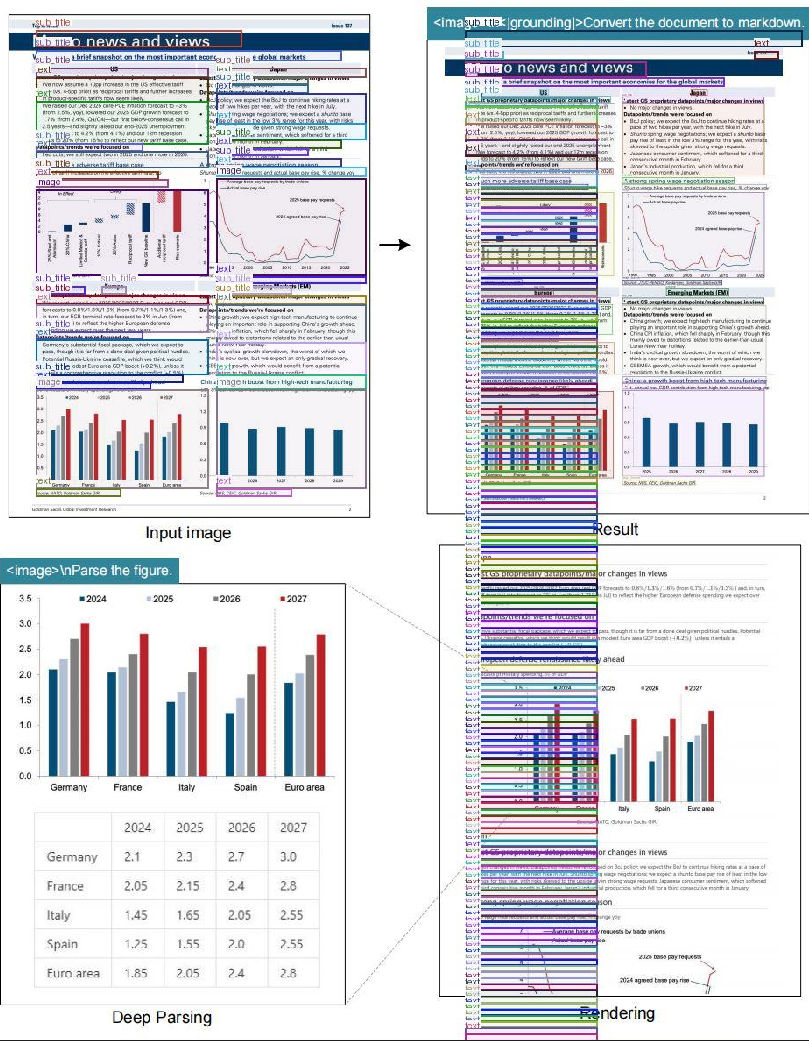
②images文件夹:0.jpg、1.jpg、2.jpg、3.jpg
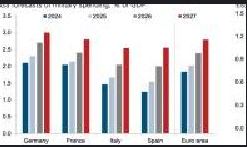
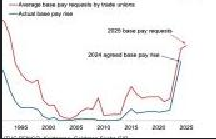
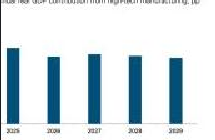
③result_ori.mmd(原始文件)、④result.mmd


3.PDF OCR(支持.pdf):并发度约2500个token/每秒(使用A100-40G)
(1)从本地随意选择一个pdf,放进服务器里/workspace/lcc//DeepSeek-OCR-main/assets。
同上,更改DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py中的PDF输入输出路径。例如:
INPUT_PATH = '/workspace/lcc/DeepSeek-OCR-main/assets/pdf_AAAI25.pdf'
OUTPUT_PATH = '/workspace/lcc/DeepSeek-OCR-main/output/pdf_AAAI25'
(2)在终端运行代码,执行以下命令:
python run_dpsk_ocr_image.py(3)输入输出示例
输入:

输出:
①images文件夹:0_0.jpg、2_0.jpg、3_0.jpg、6_0.jpg(包含了图片所在章节,及章节中第几张图的信息)
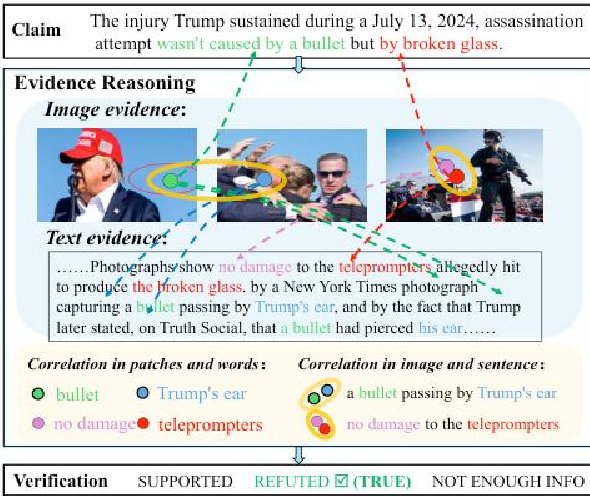
②mmd_AAAI25.mmd、③pdf_AAAI25_det.mmd


④pdf_AAAI25_layouts.pdf

3.评估
batch eval for benchmarks
四、Transformers推理
1.介绍
(1)核心特点:
这是使用 HuggingFace Transformers 库自带的模型加载与推理方式。
实现简单,兼容性强,几乎不需要额外安装复杂依赖。
(2)优点:
-
容易上手:几行代码就能运行。
-
依赖少:只要
transformers+torch。 -
更容易修改模型代码:方便调试、研究或二次开发。
(3)缺点:
-
速度较慢:相比 vLLM 推理延迟更高。
-
显存占用大:特别是大模型容易爆显存。
-
不太适合部署:适合开发与研究,而不是线上高并发推理。
(4)适用场景:
✅ 本地测试、小规模实验或模型研究(比如你只是想识别几张图或看效果)
2.图片OCR
与vLLM类似
(1)更改DeepSeek-OCR的模型加载路径为本地加载路径,改变图片输入输出路径。
即从huggingface上下载的DeepSeek-OCR的模型参数位置。具体地,在DeepSeek-OCR-master/DeepSeek-OCR-hf/run_dpsk_ocr.py中,改完后为:
MODEL_PATH = '/opt/models/DeepSeek-OCR'
image_file = '/workspace/lcc/DeepSeek-OCR-main/assets/show2.jpg'
output_path = '/workspace/lcc/DeepSeek-OCR-main/output/show2'(2)在终端运行代码,执行以下命令:
python run_dpsk_ocr.pyOK,齐活!!!