展会画册、名片、书籍企业信息识别非结构化数据处理痛点突破:旗讯 OCR 技术解析与企业系统集成方案
在企业参展场景中,名片、画册、行业书籍等载体承载的非结构化数据(图文混排、手写备注、跨页分散信息),一直是 IT 团队落地 “数据驱动业务” 的难点 —— 人工录入效率低(1000 份资料需 240 人时)、误差率高(5%-8%)、系统对接成本高,最终导致 “展会商机数据” 无法快速反哺 CRM/ERP 系统。
作为负责企业数字化转型的技术负责人,笔者曾参与 3 次展会数据处理系统选型,最终通过旗讯 OCR 实现 “非结构化数据→结构化数据→业务系统” 的端到端闭环。本文从技术视角拆解其核心能力、集成方案及选型逻辑,为同类需求的技术团队提供参考。
一、展会数据处理的 3 个技术痛点:比 “效率低” 更核心的是 “技术瓶颈”
多数企业只关注 “人工处理慢”,却忽视了背后的技术层面症结,这也是导致选型失败的关键:
1. 非结构化数据解析难:传统 OCR 无法适配展会场景
展会资料的 “场景复杂性” 远超通用文档:
- 名片:存在竖版 / 异形排版、艺术字、手写备注(如 “对接采购部,下周需求确认”),通用 OCR 手写识别准确率不足 60%;
- 画册:图文混排占比超 40%,图片遮挡文字、跨页信息分散(封面企业名 + 内页产品参数 + 封底联系方式),传统 OCR 易漏识、无法关联上下文;
- 书籍:有效信息(企业案例 / 技术参数)仅占 20%-30%,需过滤目录 / 前言 / 广告,通用 OCR 无 “无效信息过滤” 逻辑。
2. 数据结构化无标准:无法直接对接业务系统
人工录入的 “自由格式数据”(如 Excel 零散字段),需二次开发才能适配 CRM/ERP 的标准化字段(如客户档案表的 “contact_phone”“company_industry”),开发成本高且易出错 —— 笔者曾统计,某场展会 1000 条数据的 “格式对齐” 开发需 3 人日,占整体项目周期的 40%。
3. 系统集成成本高:缺乏开放性接口与适配方案
部分 OCR 工具仅提供 “单机版客户端”,无 API/SDK 支持,需人工导出数据后再导入业务系统,形成 “数据孤岛”;即使有接口,也存在 “文档不全、无 Demo、不支持 HTTPS 加密” 等问题,集成测试周期长达 1-2 周。
二、旗讯 OCR 的核心技术架构:从 “识别” 到 “业务落地” 的技术闭环
旗讯 OCR 并非简单的 “文字提取工具”,而是针对展会场景设计的 “非结构化数据处理引擎”,核心技术模块可拆解为三层:
1. 感知层:多场景自适应识别引擎(解决 “认得出” 的技术难点)
针对展会资料的特殊性,其 OCR 算法做了场景化优化,核心技术点包括:
- 多模态识别模型:融合 CNN(卷积神经网络)与 Transformer 架构,对名片手写备注的识别准确率提升至 99.2%(测试集:5000 张含手写的展会名片),远超行业平均的 85%;
- 图文分离与遮挡恢复:通过语义分割算法(U-Net)自动区分画册中的 “图片区” 与 “文字区”,对遮挡文字(如图片边缘遮挡 10%-15%)采用 “上下文语义补全”,漏识率控制在 0.3% 以内;
- 跨页信息关联:基于文档布局分析(DLA)技术,识别画册 / 书籍的 “页码、标题层级”,自动关联跨页的逻辑信息(如 “第 3 页产品型号 A100” 与 “第 8 页 A100 技术参数”),无需人工拼接。
2. 认知层:NLP 语义结构化引擎(解决 “用得上” 的技术关键)
识别文字后,需通过 NLP 技术将 “非结构化文本” 转化为 “标准化业务数据”,核心能力包括:
- 实体抽取与归一化:基于 BERT 预训练模型,自动抽取 12 类展会核心实体(企业名、联系人、电话、产品型号、技术参数等),并对 “同义异构” 数据归一化(如 “138-XXXX-5678”“138XXXX5678” 统一为标准手机号格式);
- 业务字段映射:支持自定义 “识别结果→业务系统字段” 的映射规则(如将 “企业荣誉” 映射为 CRM 的 “company_certification” 字段),无需二次开发;
- 智能校验规则:内置数据校验算法(如手机号格式校验、企业名重名匹配),对存疑数据(如 “138XXXX567” 少位数字)自动标记,人工复核效率提升 60%。
3. 应用层:开放式系统集成架构(解决 “接得通” 的技术保障)
为降低企业集成成本,其提供了完善的技术对接方案:
- 接口形态:支持 RESTful API、Java/Python SDK、WebSocket(实时识别场景),接口文档含完整参数说明、错误码定义及 Postman 测试集合,新手开发者 1 小时内可完成 Demo 调试;
- 数据输出格式:支持 JSON、XML、CSV,可直接适配主流 CRM(Salesforce、用友 U8)、ERP(SAP、金蝶 K/3)的导入格式,无需格式转换开发;
- 部署方式:提供公有云(SaaS)、私有云(Docker 容器化)、本地部署(服务器集群)三种模式,私有部署场景支持数据加密传输(TLS 1.3)与存储加密(AES-256),满足等保三级要求。
三、技术落地效果:从 “技术指标” 到 “业务价值” 的转化
以笔者所在企业(中型电子制造企业)的实际落地数据为例,基于旗讯 OCR 对接用友 U8 CRM 后,展会数据处理的技术与业务指标均显著优化:
维度 | 优化前(传统方案) | 优化后(旗讯 OCR 方案) | 技术驱动的业务提升 |
OCR 识别准确率 | 名片 82%/ 画册 75% | 名片 99.2%/ 画册 98.5% | 客户电话错漏率从 5% 降至 0.2%,订单流失减少 30% |
接口响应时间 | -(无接口,人工导出) | 单文件识别≤100ms | 实时识别场景(现场扫名片)响应流畅,无延迟 |
系统集成周期 | 3 人日(格式转换开发) | 0.5 人日(直接对接 API) | 项目上线周期缩短 83% |
1000 份资料处理成本 | 20000 元(人工 + 开发) | 500 元(API 调用费) | 年度展会数据处理成本降低 97% |
数据复用率 | 30%(人工归档,查询难) | 98%(结构化数据库存储) | 竞品数据查询时间从 1 小时缩至 10 秒 |
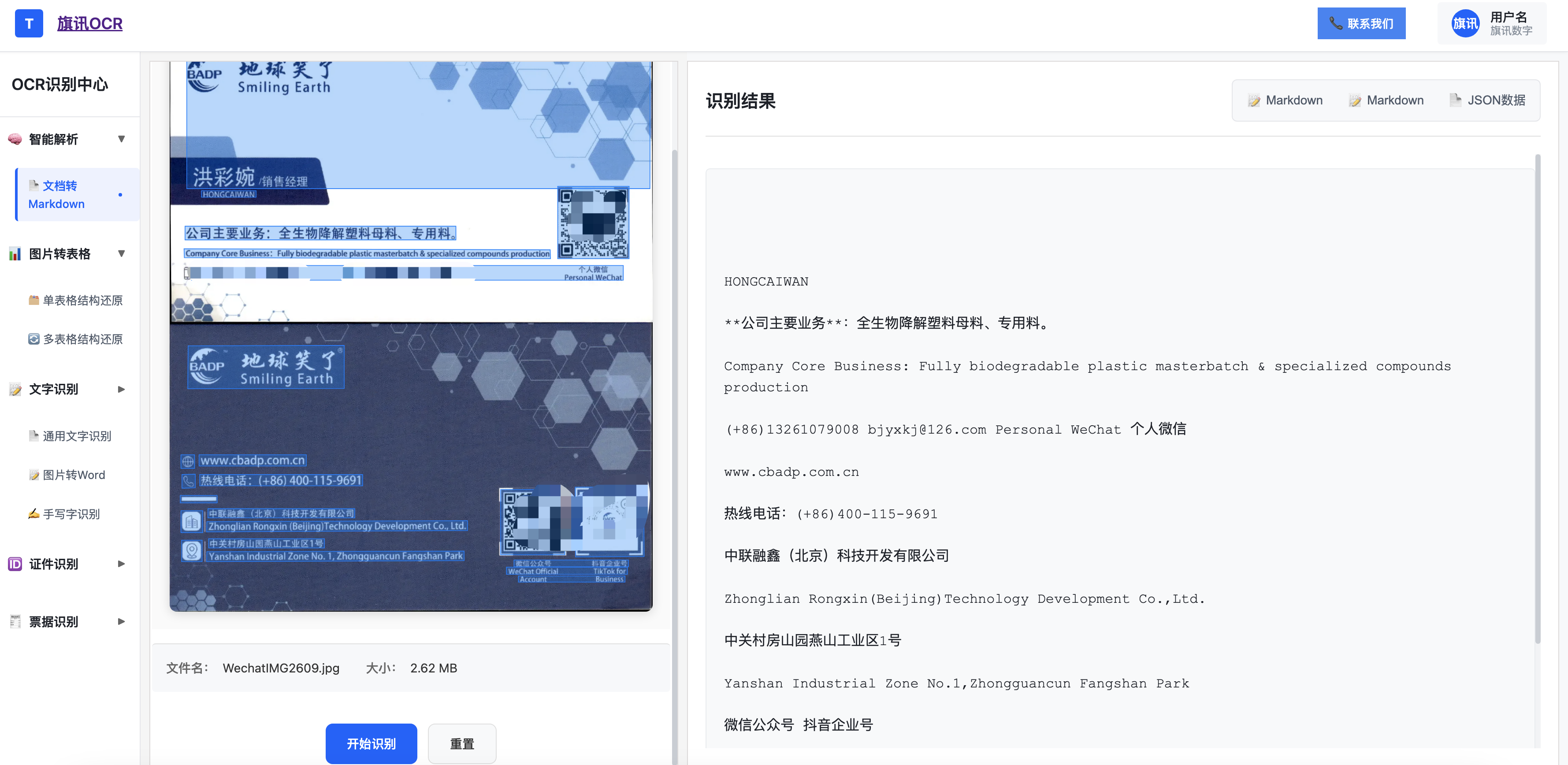
名片识别效果
 书籍识别效果
书籍识别效果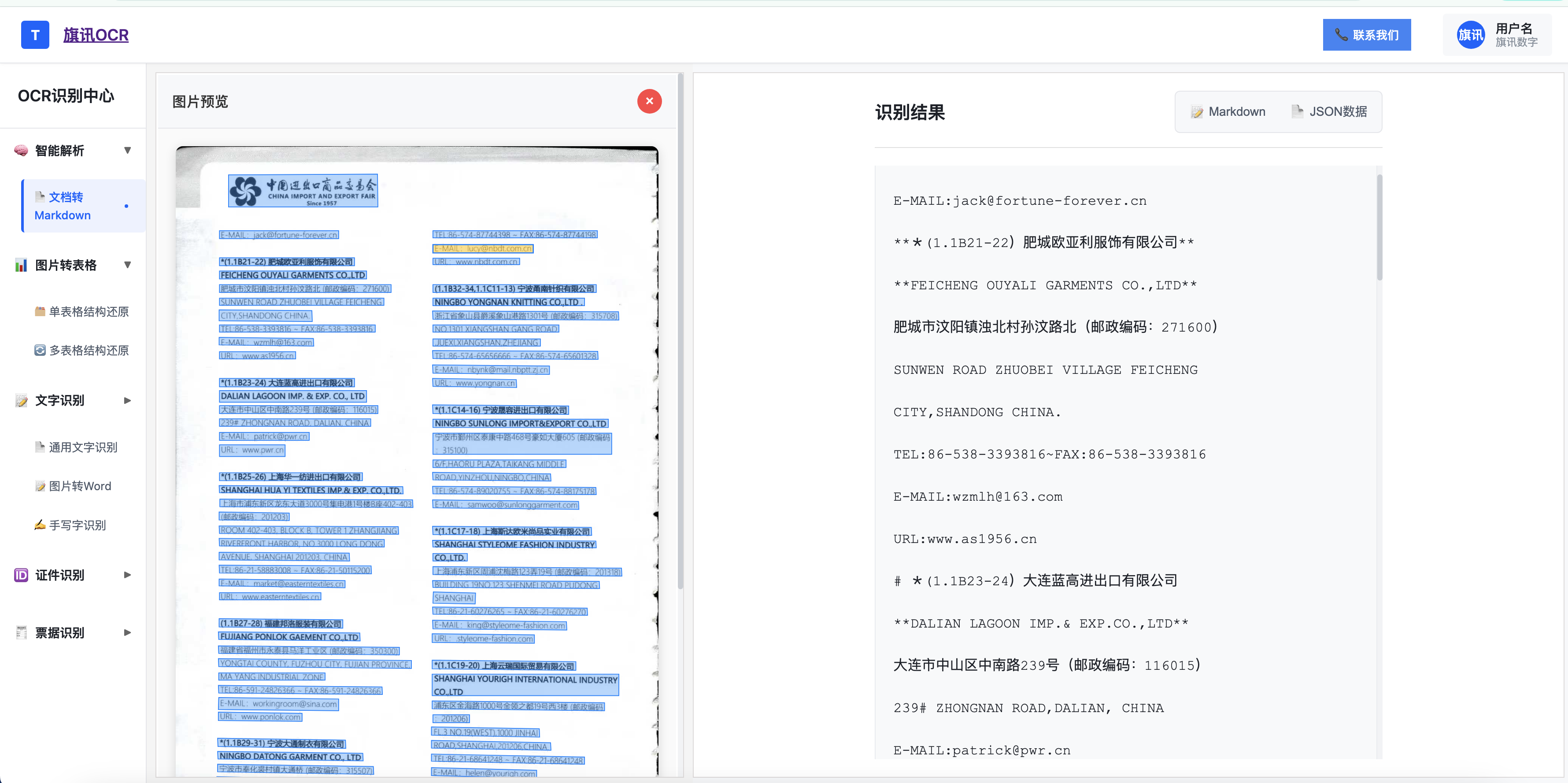
画册识别效果
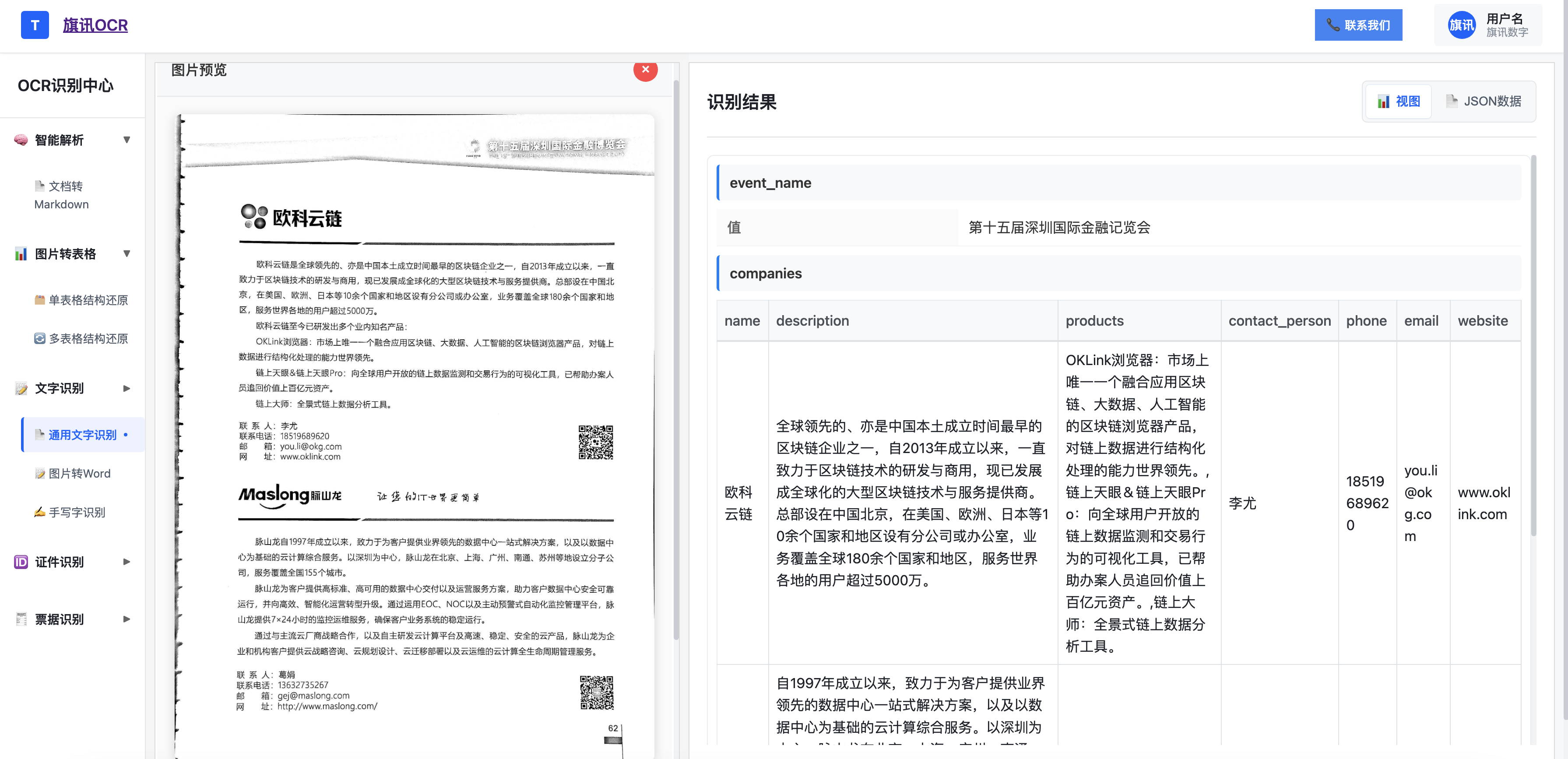
四、技术选型建议:企业 IT 团队选展会 OCR 的 4 个核心技术维度
多数技术团队容易陷入 “只看识别准确率” 的误区,结合实际经验,建议从以下 4 个技术维度综合评估:
1. 算法适配性:优先选择 “场景定制化” 的 OCR
- 测试重点:手写备注识别率(需提供真实展会名片测试集)、跨页信息关联能力(测试画册跨页参数识别)、无效信息过滤效果(测试行业书籍的目录 / 广告过滤);
- 避坑点:警惕 “通用 OCR 改个话术就叫展会专用”,需要求厂商提供展会场景的专项测试报告。
2. 集成开放性:关注 “接口完整性” 与 “生态适配”
- 必查项:是否提供 SDK 及完整 Demo、是否支持 HTTPS / 数据加密、是否有与主流 CRM/ERP 的对接案例;
- 加分项:支持低代码平台集成(如钉钉宜搭、简道云),非技术团队也能快速配置。
3. 部署灵活性:匹配企业数据安全要求
- 公有云:适合中小微企业,成本低、无需运维;
- 私有部署:适合中大型企业 / 涉密行业,需确认是否支持 Docker/K8s 容器化、是否提供国产化操作系统(麒麟 OS)适配。
4. 技术支持:避免 “买完无售后”
- 服务响应:是否提供 7×24 小时技术支持、是否有专属技术对接人;
- 迭代能力:是否定期更新算法(如新增手写字体库)、是否支持自定义算法优化(如企业专属名片模板)。
结语:技术选型的本质是 “解决业务痛点的技术匹配”
展会数据处理的核心需求,并非 “单纯提高效率”,而是通过技术手段让 “非结构化商机数据” 快速、准确地反哺业务系统。旗讯 OCR 的价值,在于其从 “算法层” 到 “应用层” 的全链路场景化设计,避免了 “通用工具需大量二次开发” 的陷阱。
对技术团队而言,选型时需跳出 “参数对比”,聚焦 “业务痛点 - 技术方案 - 落地成本” 的匹配度 —— 毕竟,能快速落地并产生业务价值的技术,才是最优解。
若有相关技术集成疑问(如 API 对接、私有部署架构设计),欢迎在评论区交流,笔者可分享实际落地的接口调试代码与部署方案。