End-To-End之于推荐-快手OneRec系列三(OneRec-Think)
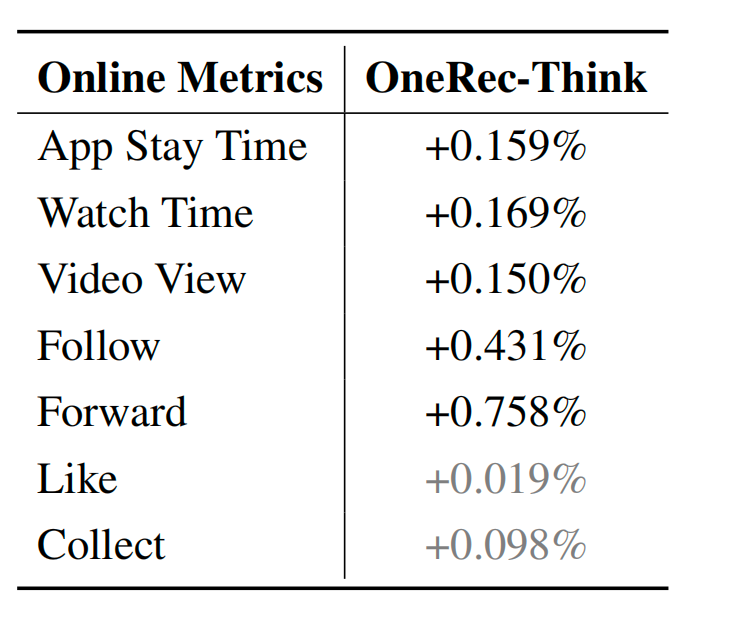
快手OneRec系列的第三个公开的工作,增加了COT(Chain of thought) 相关应用,用了1.29% 的流量跑了一周,APP停留时长提升了0.159%,其他也有一定效果。
之前的两个工作OneRec~OneRec2,是大模型Scaling-law的扩展,形成了end-to-end 的 item 生成,但其本质依然是黑盒预测(implicit predictors):没有推理链路; 无法解释推荐原因; 难以人工干预和控制
这个工作就是把大语言模型(LLM)在 推理(Chain-of-Thought) 领域的突破,引入推荐,让系统先思考,再推荐。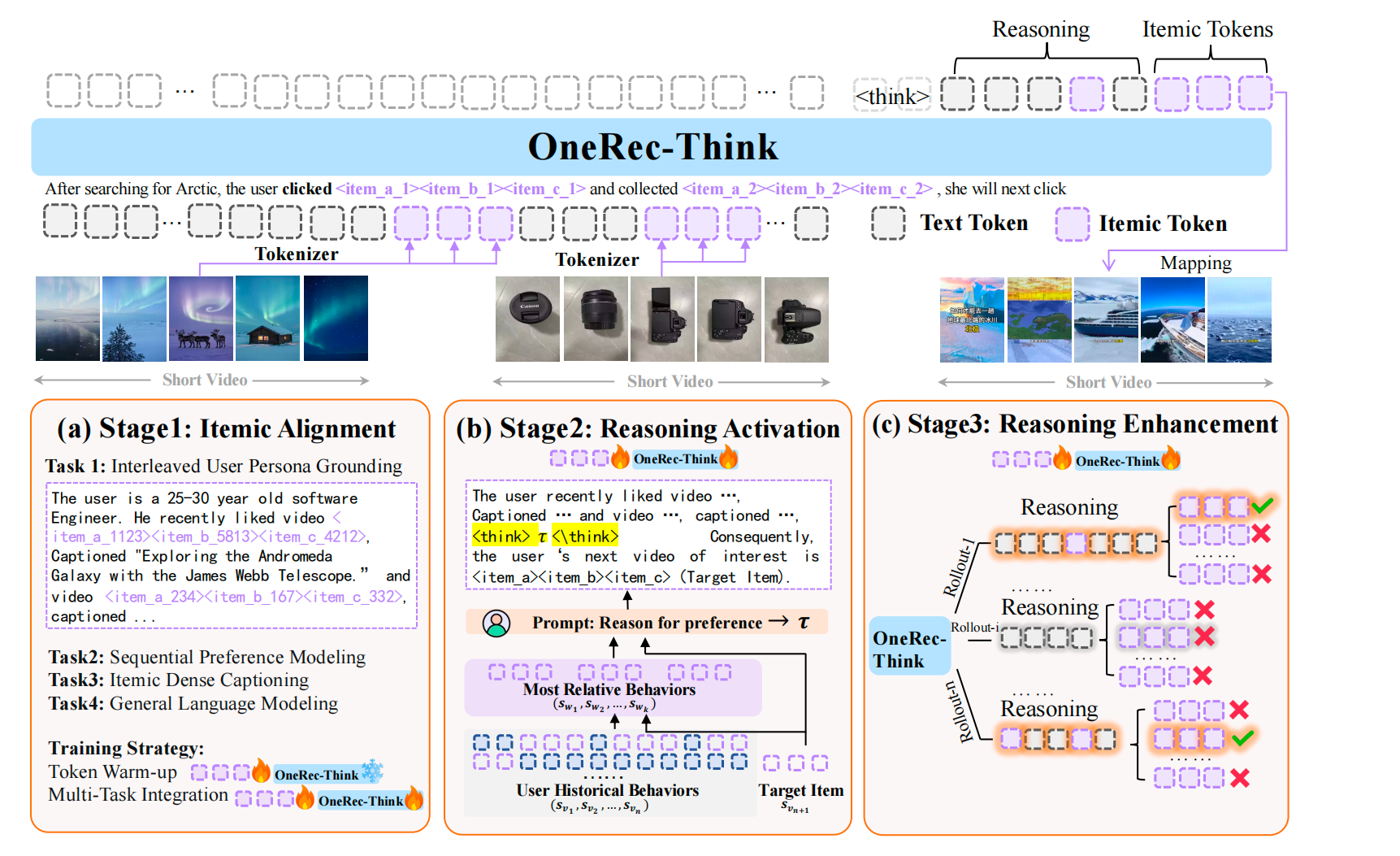
由上图看到,模型主要由三个模块构成:
- Itemic Alignment: 将语义token作为LLM额外的词表去做预训练, 让Item语义(semantic)token对齐LLM的文本token embedding空间,本质上是让ID成为一种大模型可以理解的新模态,并且能让大模型认识ID的内部含义(就像一个人一样,看了视频,知道视频说啥,底层表达的什么,不仅仅是一个sequence 序列)
- Reasoning Activation: 在推荐上下文中激活模型的推理能力
- Reasoning Enhancement: 利用特定于推荐的奖励函数来捕获用户偏好的多样性(multi-validity)
用户的interaction history表示:
Su=(Sv1,...,Svn)S_u = (S_{v1}, ... , S_{vn})Su=(Sv1,...,Svn)
一 Itemic Alignment怎么做的
1. Itemic Tokenize
这个和OneRec一样,对每个Item使用了3 * 8192个语义ID来量化, 共有24,576个语义Token。
某个Item的Tokenized结果:Sv=<|item_begin|>< item_a_1123><item_b_5813><item_c_4212><|item_end|>
下图是一个视频的例子:

2. 多任务预训练实现Item语义对齐(Itemic Alignment with Multi-Task Pre-training)
设计了四个任务
1)交错式用户画像基础(Interleaved User Persona Grounding):
包含了基础用户画像描述、近期行为(如搜索、点赞、评论、关注)描述、用户主次兴趣刻画,其中Interleave 是关键,这些行为或者是描述并不是单一存在的,而是放到一起,这样item token应该也是一种语言。
 从这个里面可以看到,用户画像的描述中包含了tokenized产品信息。
从这个里面可以看到,用户画像的描述中包含了tokenized产品信息。
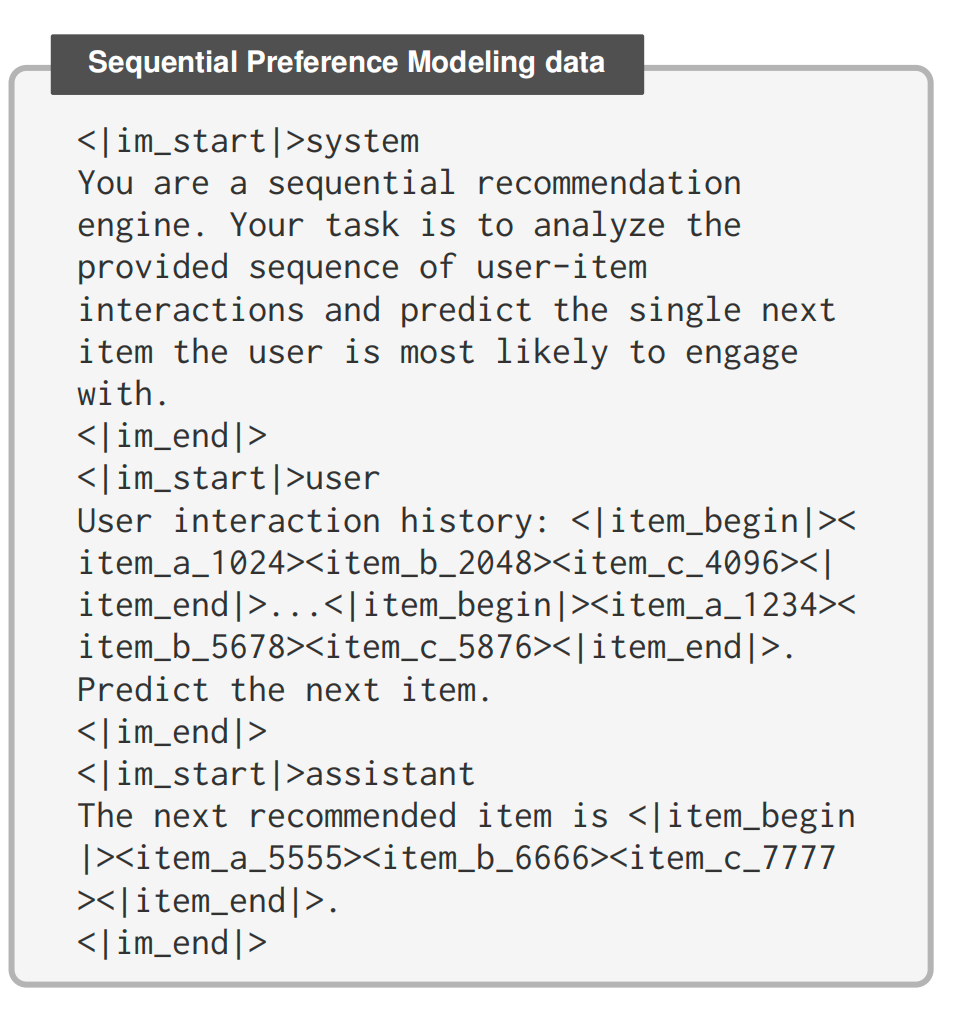
2)序列偏好模型(Sequential Preference Modeling)
从用户的历史序列中预测后续的交互Item。
3)生成Item描述信息 (Itemic Dense Captioning)
Itemic tokens—》Description of Item
任务是从Item的tokens中解析Item的描述性内容,以此任务来获得LLM对Item token的语义理解,如下图所示,左边的内容,模型能给出类似右边的描述。

4)通用语言模型(General Language Modeling)
主要包含一些预训练和Instruction fine-tune的通用语料(general corpurs), 主要是为了维持模型的基础认知,不要为了订制化任务失去大模型的基础能力。
训练步骤
- 两个考虑点:1是要让大模型有对Itemic token有认知,认识这种语言;2 在训练大模型认知的过程中不能丢失原有信息。
- 训练基础模型:Qwen-8B作为Backbone model
- 训练方法:为了满足这两点,设定了两步走
Token Warm-up
这一步只是训练Embedding表证!!!
- 目标: 主要训练新引入的itemic token embed,确保这些语义token能对齐原有LLM text token embed空间
- 操作: 使用6B的用户画像数据, 训练时冻结原LLM的参数,只训练新引入的itemic token的Embedding。
- 学习率: 使用较高的学习率(如 5 x 10-4),以便新的token embedding能快速收敛
Multi-task Intergration
推荐任务的能力在这一步体现!!!
- 目标: 将上面的4个数据任务结合起来,共同训练模型。
- 数据混合: 将不同任务的数据按照一定的比例混合,确保模型在训练过程中能够同时学习到语言生成能力和推荐任务所需的能力。
- 学习率: 基于LoRA(实际使用,在公开数据集使用的是全参数微调),解冻 backbone,只对少量 LoRA adapter 权重做更新,其他参数保持冻结,同时使用较低的学习率(如3 x 10-4), 以确保模型在微调过程中能够稳定地适应新的任务。

二 推理激活(Reasoning Activation)

这一部分是显式的让模型学会先思考,再输出。
通过Bootstrapping with Pruned Contexts
1 训练数据:Target item svn+1s_{v_{n+1}}svn+1 and form a contexttarget pair <(sv1,...,svn),svn+1><(s_{v_1} , . . . , s_{v_n}), s_{v_{n+1}}><(sv1,...,svn),svn+1>
2 先从历史交互序列中检索出来topK相似的
g((sv1,...,svn),svn+1)=(sw1,...,swk).g((s_{v_1}, . . . , s_{v_n}), s_{v_{n+1}} ) = (s_{w_1}, . . . , s_{w_k}).g((sv1,...,svn),svn+1)=(sw1,...,swk).
3 用这些相关的items,应用之前的aligned model生成解释目标交互的理论依据τ\tauτ
,其中Pτ(a,b)P\tau(a, b)Pτ(a,b) 是生成为什么与item a产生交互的用户会与item b 也产生交互.

Prompt&Answer
<|im_start|>system
You are an expert recommendation analyst.
Given a user’s relevant interaction
history, provide a step-by-step reasoning
process explaining why a specific target
item aligns with their preferences.
<|im_end|>
<|im_start|>userUser’s relevant interaction history:
<|item_begin|><item_a_1111><item_b_2222><item_c_3333><|item_end|> - Beginner’s guide to sourdough bread making
<|item_begin|><item_a_2947><item_b_8156><item_c_3402><|item_end|> - Professional chef knife skills tutorial
<|item_begin|><item_a_5618><item_b_3927><item_c_7084><|item_end|> - Italian pasta recipes from scratch
<|item_begin|><item_a_7293><item_b_5471><item_c_1836><|item_end|> - Kitchen organization and meal prep tips
<|item_begin|><item_a_9105><item_b_6248><item_c_4519><|item_end|> - Comparison of stand mixers for home baking
Target item: <|item_begin|><item_a_3672><item_b_9814><item_c_2657><|item_end|> -Advanced French pastry techniques and
equipment guide
Explain why this target item matches the
user’s interests. <|im_end|><|im_start|>assistant
Reasoning: The user’s viewing history shows a strong interest in advanced
cooking techniques and kitchen equipment, with engagement in sourdough baking,
handmade pasta, and stand mixer comparisons. The user has progressed from
basic skills to time-intensive culinary projects, demonstrating commitment to
mastering traditional cooking methods. French pastry represents a natural next
step that combines their baking experience with technical precision.
Therefore, the user would very likely click on candidate videos with similar
themes <|item_begin|><item_a_3672><item_b_9814><item_c_2657><|item_end|>.
<|im_end|>
Learning to Reason from Noisy Sequences
从用户的全部序列出发,激活推理过程,包含了两部分损失:
第一部分是推理序列对应损失,第二部分是Target Item的L个语义token所对应的损失,negative log-likelihood作为损失函数。
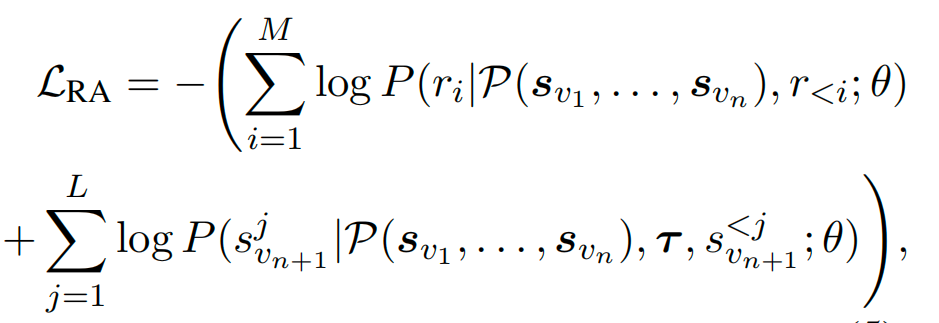
通过优化这两部分损失,让模型学会自己蒸馏相关的信息,并建立推理链接。
Prompt&Answer:
<|im_start|>system
You are an intelligent recommendation system. Given a user’s complete
interaction history, provide reasoning for your recommendation and
then suggest the most appropriate next item.
<|im_end|>
<|im_start|>user
User’s complete interaction history:
<|item_begin|><item_a_1847><item_b_6392><
item_c_5104><|item_end|>, <|item_begin|><
item_a_9263><item_b_4571><item_c_8026><|
item_end|>, <|item_begin|><item_a_1111><
item_b_2222><item_c_3333><|item_end|>, <|
item_begin|><item_a_5419><item_b_8736><
item_c_2948><|item_end|>, <|item_begin|><
item_a_3082><item_b_7145><item_c_6379><|
item_end|>, <|item_begin|><item_a_2947><
item_b_8156><item_c_3402><|item_end|>, <|
item_begin|><item_a_7651><item_b_2493><
item_c_1087><|item_end|>, <|item_begin|><
item_a_5618><item_b_3927><item_c_7084><|
item_end|>, <|item_begin|><item_a_8304><
item_b_9672><item_c_4215><|item_end|>, <|
item_begin|><item_a_7293><item_b_5471><
item_c_1836><|item_end|>, <|item_begin|><
item_a_4926><item_b_1358><item_c_8740><|
item_end|>, <|item_begin|><item_a_9105><
item_b_6248><item_c_4519><|item_end|>, <|
item_begin|><item_a_1537><item_b_8904><
item_c_3261><|item_end|>
What item should be recommended next?
Explain your reasoning first.
<|im_end|>
<|im_start|>assistant
<think>
The user’s viewing history shows a strong
interest in advanced cooking techniques
and kitchen equipment, with engagement in
sourdough baking, handmade pasta, and
stand mixer comparisons. The user has
progressed from basic skills to timeintensive culinary projects,
demonstrating commitment to mastering
traditional cooking methods. French
pastry represents a natural next step
that combines their baking experience
with technical precision. Therefore, the
user would very likely click on candidate
videos with similar themes <|item_begin
|><item_a_3672><item_b_9814><item_c_2657
><|item_end|>.
</think>
Recommendation: <|item_begin|><
item_a_3672><item_b_9814><item_c_2657><|
item_end|>
<|im_end|>
三 推理增强(Reasoning Enhancement)
这一部分类似于大模型的强化学习微调阶段,用于提升最终推荐精度,作者基于beam search结果定义了一种新的奖励机制,称为Rollout-Beam奖励:使用beam search在每次推理时生成top-k条推理路径,给这些路径分别计算reward,用最优路径的奖励来反向优化模型。
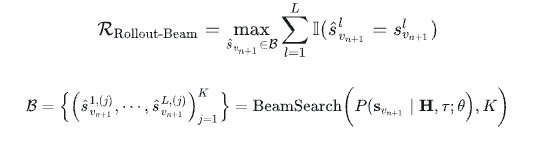
基于上述Reward, 使用GRPO算法优化模型微调:
学习率1e-5
beam search: K=32
CoT paths: [G]=16
KL divergence系数: β=0.001\beta=0.001β=0.001
裁剪比率: ϵ=0.2\epsilon=0.2ϵ=0.2
四 实际应用落地的trick
推荐系统要求的时延很低,但是大模型如果需要思考推理的话对硬件和时间都是有需求的,如何平衡这两点,是能否真正落地的关键。
为了解决这一个矛盾体,改方案提出了Think-Ahead Inference Architecture,离线阶段提前预估出语义ID的前两位, 在线阶段使用线上的OneRec模型预估语义ID的最后一位,具体的:
- Reasoning Path synthesis:为每个用户生成几个推理路径,代表用户的兴趣
- Constrianed Prefix Generation:基于推理路径,生成前2个用户可能感兴趣的itemic token
- Semantic Space Materiallizaion:将所有生成的前缀合并,形成用户的个性化候选空间, 主要包含一些用户感兴趣的集合。
- Online Inference Stage: 当用户发起请求时,从分布式存储系统中检索CuC_uCu
使用实时更新的OneRec模型进行最终的解码。
Ref:
1. 代码开源
2. paper
3. 知乎解读
4. 快手技术分享