【数据工程】14. Stream Data Processing
流数据处理(Stream Data Processing)
流数据处理(Stream Data Processing)是现代数据工程中非常关键的一环。
不同于传统的“批量数据处理”,流处理的目标是在数据产生的瞬间就能对其进行分析和响应。
这一技术如今已经广泛应用在金融欺诈检测、网络安全、物联网传感器、广告推荐以及实时监控等领域。
一、为什么需要流数据处理?
设想一家银行每天要处理上百万笔交易。
系统必须实时识别“可疑交易”——例如一个澳大利亚账户突然在巴西发生消费。
在这种情况下,如果等交易都写入数据库再统一分析,用户的资金可能已经被盗。
因此,这类场景要求系统必须实时检测、低延迟响应,并且能够处理海量的事件流。
这就是流数据处理要解决的核心问题:
让数据在“流动的过程中(data in motion)”就能被处理,而不是像传统数据库那样“静态地存储后再分析(data at rest)”。
二、什么是数据流(Data Stream)
所谓数据流,就是一个可能无限的、持续到达的数据序列。
每个数据元素可以理解为一个“事件”(tuple),它带有时间戳、来源、内容等属性。
在现实世界中,几乎所有数据最终都会变成流的形式:
- 事务型数据流:信用卡消费、供应链记录、点击日志;
- 测量型数据流:网络流量监控、传感器数据、交通流量数据。
数据流的特点是:
- 连续不断;
- 无边界(unbounded);
- 实时变化;
- 速率可能极高且波动大。
这类数据无法用传统数据库查询来分析,因为数据库假设数据是“静止的、可完全存储的”。
而数据流是“永不结束”的。
三、为什么传统数据库不适用
数据库管理系统(DBMS)设计之初是为静态存储而生。
查询都是在已保存的数据上执行的,例如:
SELECT * FROM transaction WHERE amount > 1000;
这种模式被称为“data at rest”。
问题在于:
- 它无法处理持续变化的实时数据;
- 每次分析都需要先写入再查询;
- 查询是一次性的,而不是持续的。
所以,当数据流动速度极快、数据量巨大时,DBMS 的架构就不再合适。
我们需要一个能够“边接收边计算”的系统。
四、数据流管理系统(DSMS)
为了解决这个问题,研究人员提出了数据流管理系统(Data Stream Management System, DSMS)。
它的核心思想是:
- 用户注册一个持续查询(continuous query);
- 数据源不断输入事件流;
- 系统实时更新查询结果。
例如,一个银行风控系统可以注册一个持续查询:
SELECT account_id FROM transactions
WHERE amount > 5000 AND country != home_country;
然后每当新的交易流入时,系统立即检查条件是否匹配,并触发警报。
DSMS 相当于为流数据提供了 SQL 级别的实时计算支持。
五、数据库与流系统的区别
| 特征 | 传统数据库 (DBMS) | 数据流系统 (DSMS) |
|---|---|---|
| 数据类型 | 持久关系(静态) | 临时事件流(动态) |
| 数据规模 | 有限 | 无界 |
| 查询模式 | 一次性查询 | 持续查询 |
| 数据更新 | 修改与删除 | 不断追加 |
| 查询结果 | 精确结果 | 近似或实时结果 |
| 数据顺序 | 可预测 | 不可预测 |
流系统的查询不是“执行一次拿结果”,而是“持续执行、结果不断更新”。
例如监控系统会持续输出“当前温度平均值”或“最近5分钟内的异常事件数”。
六、现代流处理架构(Modern Stream Processing Architecture)
流处理架构需要解决两个问题:
- 能够使用恒定的事件流,理想情况下具有QoS保证
- 能够对具有清晰语义的流数据执行查询处理
现代的流数据(Stream Data)处理体系通常由两个主要部分组成:
1. 发布 / 订阅系统(Publish/Subscribe Messaging System)
该系统负责数据的流动与分发。
它的作用是将生产者(Producer)产生的数据实时推送到消费者(Consumer),从而实现数据解耦。
核心功能:
- 传输数据流:持续接收并传递数据事件;
- 支持多订阅者:同一条消息可被多个消费者订阅;
- 实现异步通信:生产者和消费者不必同时在线;
- 解耦数据流与计算逻辑。
常见实现:
- Apache Kafka:目前业界标准的高性能分布式消息队列,具备高吞吐、容错性强的特征;(维护来自一个或多个生产者的消息提要)
三个关键能力
- 发布和订阅记录流
- 能否以容错的方式存储记录流
- 让应用程序在记录流出现时处理它们
- MQTT:轻量级的发布/订阅协议,常用于物联网设备之间的数据交换。
import paho.mqtt.subscribe as subscribe
broker = ip-address
def print_msg(client, userdata, message):print("%s : %s" % (message.topic, message.payload))
subscribe.callback(print_msg, "MyTopic", hostname=broker)
MQTT主题
- 主题区分大小写
- MQTT接受多层主题
- CSBldg / level3 /温度
- MQTT接受通配符主题
- 单级通配符:+
- CSBldg / + /温度
- 多级通配符:#
- CSBldg/level3/#:所有传感器和子主题
- 单级通配符:+
MQTT Publisher
import paho.mqtt.publish as publish
broker = …
publish.single("MyTopic", "TheMessage", hostname=broker)
默认情况下,MQTT代理不存储任何消息。
发布消息时,可以设置保留消息标志。这个标志告诉代理存储您发送的最后一条消息。
服务质量(消息处理保证)
- 最多一次(QoS 0):每条消息最多处理一次,但不保证
- 至少1次(QoS 1):不忽略任何消息
- 只处理一次(QoS 2):系统保证每条消息只处理一次
默认使用QoS 0
为什么消息处理保证如此复杂?
- 复杂性来自于故障期间的系统行为。由于各种故障情况,消息可能会丢失或重复,包括:
- 生产者发布失败
- 消息系统故障
- 消费者处理失败
- 示例:在数据库写入过程中消费者崩溃,或者代理耗尽磁盘空间。
- 这些故障不是假设的-它们在所有环境中都会发生,包括生产环境。
七、Apache Kafka:分布式发布/订阅系统(Distributed Pub/Sub Systems)
在大规模流数据处理任务中,我们需要一种可扩展(scalable)的发布/订阅系统,用来传输和存储连续到达的数据流。Kafka 就是这种系统的代表。
1. Kafka 的定义
Apache Kafka 是一个 分布式的(distributed)发布/订阅系统(Pub/Sub system),专门设计用于处理大规模的数据流(data streaming)。
Kafka 将数据流(stream)拆分为一系列独立的数据记录(data records),也称为 消息(messages)。
这些记录被组织成一种结构化的日志(structured commit log),采用 追加写(append-only) 的方式持续增长。
换句话说,Kafka 就像一个“只追加的日志文件系统”,所有新消息都依次写入日志末尾。
2. Kafka 与 MQTT 的区别
| 特征 | Kafka | MQTT |
|---|---|---|
| 数据组织 | 为每个主题(topic)维护一个数据流或队列 | 直接基于消息传递 |
| 消费顺序 | 每个消费者(consumer)按队列顺序依次读取数据 | 无严格顺序保证 |
| 生产者行为 | 生产者不断将新消息写入队列 | 实时推送给订阅者 |
| 容错性 | 可容错地存储数据流 | 轻量但不持久 |
Kafka 的独特之处在于:
- 每个主题(topic)对应一个有序的数据流;
- 每个消费者按序读取消息;
- 生产者可以随时向队列中追加数据;
- 系统能以容错方式保存这些数据记录(支持副本)。
八、Kafka 的主题(Kafka Topics)
Kafka 将数据以 主题(topic) 为单位进行组织,每个主题都维护一个分区日志(partitioned log)。
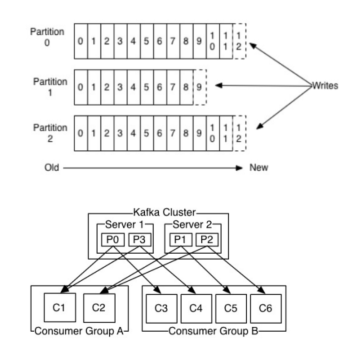
1. 日志分区(Partitioned Log)
- 每个主题被划分为多个分区(partitions),每个分区是一个有序的消息序列;
- 新消息总是被写入每个分区的末尾;
- 日志可在多台服务器间复制,以保证可靠性(replication)。
2. 多订阅者机制(Multi-Subscriber)
Kafka 支持多个消费者组(consumer groups)同时订阅同一主题:
- 每条消息会被发送到每个订阅组中的一个消费者实例(consumer instance);
- 每个消费者组之间互不干扰;
- 消费者实例可以运行在不同的进程或不同的机器上。
这意味着 Kafka 不仅能让多个用户订阅同一个数据流,还能保证每个组内部的消息不会重复消费。
九、Kafka 的一致性与可靠性保证(Guarantees from Kafka)
Kafka 在设计上提供了多种严格的可靠性保证:
-
消息顺序性(Message Ordering)
- 来自同一个生产者(producer)的消息会按发送顺序被写入对应的主题;
- Kafka 会将消息持久化存储durably stored在磁盘上;
- 因此,即使系统崩溃,消息也可以重放(replayed later)。
-
消费顺序性(Consumer Order)
- 消费者读取消息时,会按照消息在日志中的顺序依次接收;
- 即保证了顺序一致性(FIFO consistency)。
-
副本容错(Replication Fault Tolerance)
- 若主题的副本因子(replication factor)为 N,系统可以在最多 N–1 台服务器失效的情况下仍保持数据不丢失;
- 即只要还有一个副本可用,所有已提交的记录都安全。
-
至少一次(At least once)语义
- 每条消息在被发布后,Kafka 会先将其“提交(commit)”到日志;
- 这保证消息不会丢失;
- 但如果消费者在处理过程中崩溃,重新读取时可能会读到同一条消息两次。
→ 所以是“至少一次”,而不是“恰好一次”。
十、Kafka 的典型应用:实时数据接入(Real-Time Data Ingestion)
在实际应用中,Kafka 通常被当作一个**实时数据管道(data pipe)**使用。
它持续从不同来源接收数据,并把这些数据推送到需要的系统中,而不需要等待批处理(batch job)调度。
1. 关键组成部分
| 组件 | 功能 |
|---|---|
| Producers(生产者) | 负责产生数据,如 Web 服务器、移动应用、IoT 传感器、数据库等。 |
| Kafka Brokers(代理服务器) | Kafka 集群中的服务器,接收来自生产者的数据并按主题(topic)进行存储。 |
| Consumers(消费者) | 从 Kafka 读取数据的系统,例如分析平台、机器学习模型或实时告警系统。 |
2. Kafka 的优势
- 可靠性(Durability):所有数据都写入磁盘并可复制;
- 可扩展性(Scalability):轻松应对大规模数据流;
- 低延迟(Low latency):能在毫秒级响应;
- 数据重放(Reprocessing):消费者可以从任意时间点重新读取或处理数据。
总结:Kafka 的角色与特征
| 特征 | 说明 |
|---|---|
| 架构类型 | 分布式发布/订阅系统 |
| 数据模型 | 主题(topic)+ 分区(partition)日志 |
| 通信模式 | 生产者 → Broker → 消费者 |
| 消息顺序 | 保证同分区内的顺序 |
| 可靠性 | 持久化 + 多副本 |
| 消息语义 | 至少一次(at least once) |
| 典型用途 | 实时数据接入、日志分析、监控流处理 |