笔记:理解Yolo网络运行规律并添加自制简易功能(以Yolo11为例)
在学习修改yolo底层代码以达到添加功能的目的之前,我们还需要熟悉yolo的运行步骤,比如在哪个环节调出哪个函数和功能,这些内容的赋值和操作都是什么。然后基于理解不断地搞懂运作原理并着手添加一些简易功能。
目录
一、回顾官方的yolo配置文件
(一)、default.yaml
1.位置
2.文件整体功能
3.重要功能
1)对“权重更新/优化过程”影响大的
2)对“训练资源占用/速度”的影响大的
3)对“结果精度/泛化”影响大的
(二)、botsort.yaml
1.位置
2.文件整体功能
(三)、yolo11.yaml(以v11为例)
1.位置
2.文件整体功能
3.Yolov11结构图
4.重要功能
1)全文格式
2)操作介绍
3)关键操作辨析
二、调试官方代码,查看运行流程
(一)、测试代码
(二)、Debug调试
1. 在model_train.py中打断点
2.在task.py中打断点
3.分析初始化流程
1)读取全局超参
2)准备日志和通道账本
3)取网络
4)推导通道与参数
5)特殊分支处理
6)实例化模块
7)保存通道
8)返回结果
三、在网络层添加自己的内容
(一)、回顾网络层配置
1.位置和格式
2.结构
3.功能库
(二)、添加自建功能类
1.往哪写
2.怎么写
1)添加简易自制模块
2)调用自制模块
3)运行代码
***懒人通道***:现成代码
4)观察结果
四、总结
一、回顾官方的yolo配置文件
如果你还没clone官方的文件到本地,请参照本篇笔记,将ultralytics的官方文件下载到本地笔记:对yolov8网络代码的学习_如何看yolo的源代码-CSDN博客
(一)、default.yaml
1.位置
..\ultralytics-main\ultralytics\cfg注:..省略了放在本地的前置路径,我们只给出再官方文件中的相对路径,后续不再提示。
2.文件整体功能
这是 全局配置 YAML,用来统一控制 YOLO 的 训练(train)/ 验证(val)/ 预测(predict)/ 导出(export)/ 跟踪(track)/ 基准(benchmark) 等流程的行为与超参数。当选择好任务后,如果没有其他声明,则默认在该文件中查找对应参数。中文版的参数名称和功能如下:
# Ultralytics 🚀 全局配置与超参数(训练/验证/预测/导出)
# 文档: https://docs.ultralytics.com/usage/cfg/task: detect # 任务类型:detect(检测)/segment(分割)/classify(分类)/pose(姿态)/obb(旋转框)
mode: train # 运行模式:train/val/predict/export/track/benchmark# ----------------------------- 训练设置 -----------------------------
model: # 模型路径:如 yolov8n.pt 或 yolov8n.yaml
data: # 数据集配置:如 coco8.yaml
epochs: 100 # 训练轮数
time: # 最长训练小时数(设置后优先于 epochs)
patience: 100 # 早停:验证指标 N 个 epoch 无提升则停止
batch: 16 # batch size;-1 表示自动选择(AutoBatch)
imgsz: 640 # 输入尺寸(训练/验证用方形 int;预测/导出可用 [h,w])
save: True # 是否保存训练 checkpoint 与预测结果
save_period: -1 # 每隔 N 个 epoch 额外保存一次;<1 表示关闭
cache: False # 缓存图片:True/‘ram’(内存) 或 'disk'(硬盘);False 关闭
device: # 设备:0 或 [0,1,2,3] 表示 GPU;'cpu'/'mps';-1/[-1,-1] 自动选空闲 GPU
workers: 8 # DataLoader 线程数(DDP 下为每卡的数)
project: # 工程名(结果根目录)
name: # 试验名(结果保存在 'project/name')
exist_ok: False # 若目标目录已存在,是否允许覆盖
pretrained: True # 预训练:True 用官方预训练;或写权重路径字符串
optimizer: auto # 优化器:auto/SGD/Adam/AdamW/Adamax/NAdam/RAdam/RMSProp
verbose: True # 训练/验证日志更详细打印
seed: 0 # 随机种子(复现实验)
deterministic: True # 确定性算子(更可复现,但可能慢)
single_cls: False # 将所有类别视为同一类(单类训练)
rect: False # 训练使用矩形 batch;当 mode='val' 时为矩形验证
cos_lr: False # 余弦学习率调度器
close_mosaic: 10 # 最后 N 个 epoch 关闭 mosaic 增强(0 表示不关闭)
resume: False # 从上一次运行目录的最后一个 checkpoint 恢复训练
amp: True # 自动混合精度 AMP;True 会做能力检查
fraction: 1.0 # 仅用训练集的比例(1.0=全量)
profile: False # 训练期间分析 ONNX/TensorRT 速度(用于日志)
freeze: # 冻结前 N 层(int)或指定层索引列表(list)
multi_scale: False # 多尺度训练(动态变换输入尺寸)
compile: False # torch.compile():True="default";"reduce-overhead"/"max-autotune-no-cudagraphs";False 关闭# 分割专用
overlap_mask: True # 训练时将实例掩码合并为一张(segment only)
mask_ratio: 4 # 掩码下采样比例(segment only)# 分类专用
dropout: 0.0 # 分类头的 dropout(classify only)# ----------------------------- 验证/测试设置 -----------------------------
val: True # 训练过程中是否做验证/测试
split: val # 评估的数据划分:'val'/'test'/'train'
save_json: False # 输出 COCO JSON(用于外部评估)
conf: # 置信度阈值;默认:predict=0.25, val=0.001
iou: 0.7 # NMS 的 IoU 阈值
max_det: 300 # 每张图最大检测框数
half: False # 推理是否用 FP16(支持才生效)
dnn: False # ONNX 推理时使用 OpenCV DNN
plots: True # 训练/验证保存可视化图# ----------------------------- 预测设置 -----------------------------
source: # 输入源:路径/目录/URL/流;'0' 表示摄像头
vid_stride: 1 # 视频抽帧间隔(每 N 帧取一帧)
stream_buffer: False# True 缓存所有帧;False 仅保留最新帧(低时延)
visualize: False # 可视化:predict 显示特征;val 显示 TP/FP/FN 混淆
augment: False # 预测时的测试时增强(TTA)
agnostic_nms: False # 类别无关 NMS
classes: # 只保留这些类别(int 或列表),如 0 或 [0,2,3]
retina_masks: False # 分割:使用高分辨率掩码(segment)
embed: # 返回指定层索引的特征嵌入(list[int])# ----------------------------- 可视化与保存 -----------------------------
show: False # 支持时弹窗显示图像/视频
save_frames: False # 从视频预测中逐帧保存
save_txt: False # 以 .txt(xywh) 保存结果
save_conf: False # 同时保存置信度
save_crop: False # 裁剪出的目标区域另存文件
show_labels: True # 画出类别标签
show_conf: True # 画出置信度数值
show_boxes: True # 画出检测框
line_width: # 线宽;不设则随图像尺寸自适应# ----------------------------- 导出设置 -----------------------------
format: torchscript # 导出格式:torchscript/onnx/openvino/engine/coreml/saved_model/pb/tflite/edgetpu/tfjs/paddle/mnn/ncnn/imx/rknn
keras: False # 仅 TF SavedModel(format=saved_model)时启用 Keras 层
optimize: False # 仅 TorchScript:应用移动端优化
int8: False # INT8/PTQ 量化(openvino/tflite/tfjs/engine/imx);需要校准数据/比例
dynamic: False # 允许动态输入尺寸(torchscript/onnx/openvino/engine)
simplify: True # ONNX/engine:导出前简化图(更干净)
opset: # ONNX/engine:opset 版本;留空用测试过的默认
workspace: # TensorRT:workspace 大小(GiB),如 4
nms: False # 若后端支持,把 NMS 融合到导出模型里;True 时 conf/iou 生效(coreml 除外)# ----------------------------- 训练超参数(损失&增强) -----------------------------
lr0: 0.01 # 初始学习率(SGD=1e-2,Adam/AdamW=1e-3)
lrf: 0.01 # 最终学习率比例;final_lr = lr0 * lrf
momentum: 0.937 # 动量(SGD)/beta1(Adam 系)
weight_decay: 0.0005# 权重衰减(L2 正则)
warmup_epochs: 3.0 # 热身 epoch(可小数)
warmup_momentum: 0.8# 热身起始动量
warmup_bias_lr: 0.1 # 热身时 bias 的学习率
box: 7.5 # box 回归损失权重
cls: 0.5 # 分类损失权重
dfl: 1.5 # 分布式焦点损失权重(DFL)
pose: 12.0 # 姿态任务损失权重
kobj: 1.0 # 关键点目标性损失权重(姿态)
nbs: 64 # 标称 batch size(用于损失归一化)
hsv_h: 0.015 # HSV 色调增强幅度
hsv_s: 0.7 # HSV 饱和度增强幅度
hsv_v: 0.4 # HSV 亮度增强幅度
degrees: 0.0 # 旋转角度(±)
translate: 0.1 # 平移比例(±)
scale: 0.5 # 尺度缩放(±)
shear: 0.0 # 切变角度(±)
perspective: 0.0 # 透视变换强度(典型 0–0.001)
flipud: 0.0 # 纵向翻转概率
fliplr: 0.5 # 横向翻转概率
bgr: 0.0 # RGB↔BGR 交换概率
mosaic: 1.0 # Mosaic 增强概率
mixup: 0.0 # MixUp 概率
cutmix: 0.0 # CutMix 概率
copy_paste: 0.0 # 分割:拷贝粘贴概率
copy_paste_mode: flip # 分割:拷贝粘贴策略(flip/mixup)
auto_augment: randaugment # 分类:自动增强策略(randaugment/autoaugment/augmix)
erasing: 0.4 # 分类:随机擦除概率(0–0.9,小于1.0)
# ----------------------------- 自定义外部配置 -----------------------------
cfg: # 额外 config.yaml 路径(用于覆盖默认)
# ----------------------------- 目标跟踪设置 -----------------------------
tracker: botsort.yaml # 追踪器配置:botsort.yaml 或 bytetrack.yaml
3.重要功能
1)对“权重更新/优化过程”影响大的
-
学习率族:
lr0(初始 LR)、lrf(最终 LR 比例)、cos_lr(调度器是否为 cosine)。学习率直接决定收敛与性能上限,首调优先级最高。 -
动量与权重衰减:
momentum、weight_decay。动量影响梯度平滑与稳定;weight_decay影响正则化与过拟合。 -
热身策略:
warmup_epochs、warmup_momentum、warmup_bias_lr。改善前期不稳定、减少梯度爆炸风险。 -
损失权重:
box/cls/dfl(检测),pose/kobj(姿态)。控制不同任务分量的相对重要性。 -
标称批大小
nbs:影响损失归一化(间接影响学习率调度的等效尺度)。 -
优化器
optimizer:不同优化器的动量/自适应策略不同,影响收敛速度与稳定性。
2)对“训练资源占用/速度”的影响大的
-
imgsz:输入尺寸平方级影响显存与 FLOPs;增大能明显提升显存占用与时间。 -
batch:线性影响显存与吞吐;-1(AutoBatch)自动探测。 -
device、workers、cache:设备/线程/缓存策略,对读盘与吞吐有大影响。Windows 上经常把workers设 0 以避坑。 -
amp(混合精度)与half(半精度推理):可显著降显存、提速(硬件支持时)。 -
compile(torch.compile)与optimizer实现:特定后端可提速,但需留意兼容性。 -
save_period/plots/可视化开关:频繁保存与绘图会拖慢训练并占用磁盘。 -
导出相关
dynamic/int8/simplify:导出阶段的性能/体积影响较大(训练时通常不启)。3)对“结果精度/泛化”影响大的
-
pretrained:是否加载预训练权重;通常对小数据集/冷启动精度影响显著。default
-
epochs/patience:训练时长与早停;不足可能欠拟合,过度则过拟合。default
-
数据增强族:
mosaic/mixup/cutmix/hsv_* / degrees/translate/scale/shear/perspective/flip* / auto_augment/erasing-
Mosaic 对小目标/复杂场景一般有益,但接近收尾期常关闭(
close_mosaic); -
几何/颜色增强调得过激可能伤害定位/类别一致性;
-
分类增强(auto_augment/erasing)仅在分类任务生效;
-
-
imgsz与multi_scale:更高分辨率通常提升召回/小目标,但计算更重;多尺度训练提升适应性。 -
single_cls:强制单类训练可能在你只有一个大类时更稳。 -
验证/预测阈值:
conf/iou/max_det会影响评估阶段的 mAP/PR 曲线表现(注意验证默认低conf以全面统计)。
(二)、botsort.yaml
1.位置
..\ultralytics-main\ultralytics\cfg\trackers2.文件整体功能
这份 YAML 负责控制 YOLOv8 跟踪模式(mode=track) 的行为。这个配置决定了“检测到的目标”在视频中如何被连续追踪成一条条 ID 轨迹,同时平衡了“稳定(少漂移)”与“敏感(不漏检)”之间的关系。
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# BoT-SORT 跟踪器默认配置(mode="track")
# 文档:https://docs.ultralytics.com/modes/track/tracker_type: botsort # (str) 跟踪器类型:botsort | bytetrack;选 botsort 可启用 BoT-SORT 特有功能# ----------------------------- 基本匹配与关联参数 -----------------------------
track_high_thresh: 0.25 # (float) 第一阶段匹配阈值:越高越“干净”,但漏匹配更多;越低越“粘”,但可能漂移
track_low_thresh: 0.1 # (float) 第二阶段低置信度匹配阈值:平衡“目标恢复”与“误匹配”
new_track_thresh: 0.25 # (float) 启动新轨迹的置信度阈值:高→减少假轨迹;低→更易生成新 ID
track_buffer: 30 # (int) 丢失多少帧仍保留轨迹;高→更耐遮挡,但 ID 交换风险大
match_thresh: 0.8 # (float) 匹配相似度(IoU/代价)阈值;根据检测质量调节
fuse_score: True # (bool) 匹配时融合检测得分(score)与运动/IoU;有助于弱检测稳定# ----------------------------- BoT-SORT 特有参数 -----------------------------
gmc_method: sparseOptFlow # (str) 全局运动补偿(GMC)方法:sparseOptFlow | orb | none;# 在摄像机移动的场景下能修正背景位移,提高匹配稳定性# ----------------------------- ReID(外观重识别)相关 -----------------------------
proximity_thresh: 0.5 # (float) 判定两个轨迹“足够接近”以进行 ReID 的最小 IoU;高→更严格
appearance_thresh: 0.8 # (float) ReID 外观相似度阈值;高→避免 ID 混淆,低→容忍更多外观变化
with_reid: False # (bool) 是否启用 ReID 模型;启用后计算更重但 ID 稳定性更好
model: auto # (str) ReID 模型名称或路径;"auto" 表示自动使用检测器特征(无需单独模型)
(三)、yolo11.yaml(以v11为例)
1.位置
..\ultralytics-main\ultralytics\cfg\models\112.文件整体功能
这份 YAML 文件定义了 YOLOv11 的完整 结构、层次与模型缩放逻辑。框架在构建模型时会读取这个 YAML → 调用 parse_model() → 动态搭建 PyTorch 网络。训练、推理、导出时都会根据这个文件结构生成具体模型。
# Ultralytics 🚀 YOLOv11 目标检测模型结构定义文件
# 包含从 P3/8 到 P5/32 的输出层(即三层特征输出)
# 官方文档:https://docs.ultralytics.com/models/yolo11# ---------------------- 基本参数 ----------------------
nc: 80 # 检测类别数量(COCO 为 80 类)scales: # 模型多尺度比例定义(depth, width, max_channels)n: [0.50, 0.25, 1024] # nano 模型:层数减半、通道四分之一s: [0.50, 0.50, 1024] # small 模型m: [0.50, 1.00, 512] # medium 模型:通道全宽但深度减半l: [1.00, 1.00, 512] # large 模型:全深全宽x: [1.00, 1.50, 512] # xlarge 模型:更宽网络,保持最大通道 512 上限# ---------------------- 主干网络 Backbone ----------------------
backbone:# 每一行格式:[from, repeats, module, args]# from:输入来源索引;repeats:重复次数;module:模块类型;args:参数- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 输入→降采样一半- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 特征提取+降采样- [-1, 2, C3k2, [256, False, 0.25]] # C3k2 模块,两个重复,特征聚合- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]] # 提取更深特征- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]] # 启用 shortcut 连接- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]] # 更深语义层- [-1, 1, SPPF, [1024, 5]] # 空间金字塔池化(提取多尺度上下文)- [-1, 2, C2PSA, [1024]] # 通道注意力聚合模块(提升特征表达)# ---------------------- 检测头 Head ----------------------
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 上采样一倍(P5→P4 尺寸)- [[-1, 6], 1, Concat, [1]] # 拼接 backbone 的 P4 层特征- [-1, 2, C3k2, [512, False]] # 聚合后特征精炼(P4 分支)- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 再上采样(P4→P3)- [[-1, 4], 1, Concat, [1]] # 拼接 backbone 的 P3 层特征- [-1, 2, C3k2, [256, False]] # 小目标分支 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]] # 下采样回 P4 尺度- [[-1, 13], 1, Concat, [1]] # 拼接上层 head 特征- [-1, 2, C3k2, [512, False]] # 中目标分支 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]] # 再下采样回 P5 尺度- [[-1, 10], 1, Concat, [1]] # 拼接 backbone 的高层语义特征- [-1, 2, C3k2, [1024, True]] # 大目标分支 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # 检测层:输出 P3, P4, P5 三尺度预测框
3.Yolov11结构图
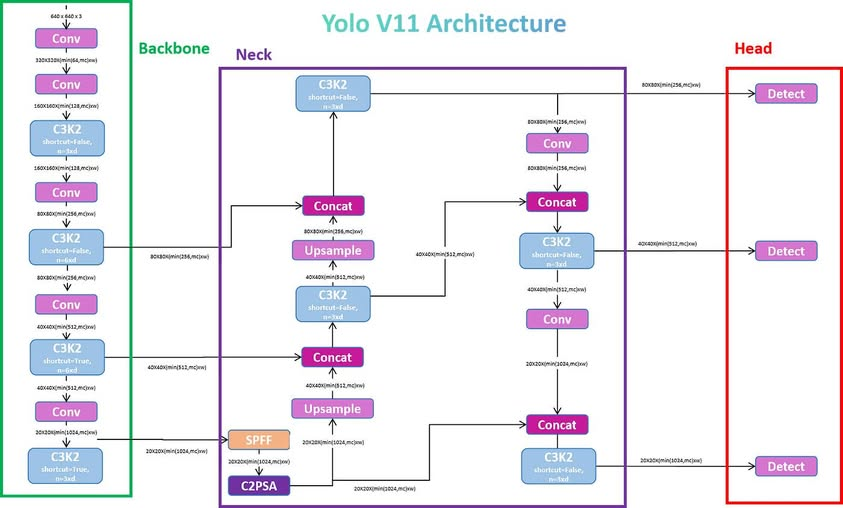
通过这张图我们能够清晰的看到yolov11的系统结构图,虽然在上面分为三个部分,但在代码中,Neck(特征融合颈部)已经并入到Head中,统称为Head(输出检测头),另外就是Backbone(特征提取主干网络)。
从名字我们就能明确三者的功能:
| 英文名称 | 中文常译 | 直观比喻 | 功能核心 |
|---|---|---|---|
| Backbone | 主干网络 / 特征提取骨干 | “身体的骨架” | 负责从原始图像中提取多层次特征(边缘、形状、语义) |
| Neck | 特征融合颈部 / 特征金字塔 | “连接头与身体的颈部” | 融合来自不同层次(分辨率)的特征,形成多尺度特征图 |
| Head | 检测头 / 输出头部 | “大脑和嘴” | 负责根据融合后的特征预测目标位置、类别等结果 |
4.重要功能
1)全文格式
采用如下形式:
[from, repeats, module, args]
from:数据来源 --一般为-1,意为从上一层网络获取输出,可以是多个,如[-1,6],常用于特征融合。
repeats:运行次数 --卷积一般为1,残差一般是2
module:处理操作 --Conv 卷积,C3k2 残差等
args:操作参数 --一般至少有一个,为通道数,若是conv则第二个是卷积核大小,第三个是步长。若是C3k2,则第二个是激活shortcut(残差连接),第三个是expansion ratio(扩展比例),用来调节中层通道数不超过: 扩展比例*max(通道数)。2)操作介绍
卷积、残差、池化、注意力、上采样、特征融合、检测
| 模块名 | arg1 | 含义 | arg2 | 含义 | arg3 | 含义 |
| Conv | 输出通道 c2 | 输出特征图的通道数 | 卷积核大小 k | 卷积核尺寸 | 步幅 stride | 下采样倍数 |
| C3k2 | 输出通道 c2 | 模块输出的通道数 | 是否启用残差 shortcut | 是否添加残差连接 | e(扩展比例) | 控制中间瓶颈通道比例 |
| SPPF | 输出通道 c2 | 输出通道数 | 池化核大小 k | 多尺度池化的最大核尺寸 | × | × |
| C2PSA | 输出通道 c2 | 模块输出通道数 | × | × | × | × |
| Upsample | scale_factor | 上采样倍数 | 模式 mode | 上采样插值方式 | × | × |
| Concat | dim | 拼接维度 | × | × | × | × |
| Detect | nc | 类别数 | × | × | × | × |
3)关键操作辨析
为什么有的残差用了shortcut有的没用?
先搞清残差的优势:
避免梯度消失(稳定训练);
让网络更容易学习“变化”而不是“全部特征”;
保留低频语义信息,提高深层特征一致性。
对于不同部分:
浅层模块(P2、P3) → 不用残差 保留残差,会“混入原图噪声”,反而不利于学习新特征
深层模块(P4、P5) → 启用残差 语义路径更长,容易发生梯度衰减或震荡
Neck 部分(特征融合) → 通常不用残差 残差在多源输入情况下意义不大,还占资源
指标 shortcut=True shortcut=False 梯度稳定性 强 较弱 计算量 (FLOPs) 稍高(多一次 element-wise add) 略低 表达能力 更保守(平滑过渡) 更激进(完全新特征) 适用场景 深层语义层 浅层提特征、融合层 这里有一个例外: Neck的P5层使用了shortcut,是因为P5的特征融合时,特征图已经很小,又包含了backbone生成的最强语义,这里引入是为了:让输出既有新特征,又保留深层原始特征的语义连续性。
为什么只有最底层特征使用了SPPF池化,Backbone的其他层Neck中都没有?
SPPF(Spatial Pyramid Pooling - Fast)做的事是:在固定分辨率下,用多个不同尺寸的池化核(如 5×5、9×9、13×13)叠加后拼接,让每个像素“看到”不同范围的上下文,从而扩大感受野。SPPF 只在 最底层(P5) 使用,因为这时特征图非常小(比如 20×20),池化核覆盖范围很大,能真正捕获到整张图的“全局语义关系”。
而在Backbone中,中层语义掺杂噪音或者边缘纹理,此时池化影响局部特征降低准确率。在Neck中,特征已进行多尺度融合,池化不仅冗余还破坏特征对齐。
C2PSA 为什么可以紧跟在 SPPF 后?
C2PSA 是 YOLOv11 新引入的 轻量化注意力模块。
SPPF 是“全局池化 → 汇总语义”,提供大视野(全局上下文);
C2PSA 是“注意力 → 挑选关键通道与空间区域”,让网络聚焦其中最有价值的部分。
阶段 模块 功能定位 是否降采样 是否带注意力 上下文聚合阶段 SPPF 汇聚多尺度空间上下文 ❌ 否 ❌ 否 注意力聚合阶段 C2PSA 强化重要语义、通道权重 ❌ 否 ✅ 是
为什么Detect有多层输出?
YOLO 的“多尺度检测 (multi-scale detection)”思想,每层 Detect 都在不同的“分辨率空间”里进行预测。Detect 是 YOLOv11 的“决策核心”,承担从特征 → 结果的最终映射。它的设计直接决定模型的定位精度、分类正确率与推理速度。
输出层 特征层 尺度 负责目标 典型通道数 P3 80×80 小目标 人脸、螺丝、车灯等 256 P4 40×40 中目标 人体、车牌等 512 P5 20×20 大目标 整辆车、建筑物等 1024 另外,Yolo会将Detect输出三个特征层各自的预测,拼接成一个大张量,然后进入 后处理阶段 (Post-processing)。
在后处理阶段,每个候选框都会计算一个综合置信度:
然后用一个阈值(如
conf_thres=0.25)筛掉低置信度的框。在这期间,多个 Detect 层的框可能指向同一个目标(比如小人被 P3、P4 同时检测到)。此时 YOLO 用 NMS(Non-Maximum Suppression) 去掉重复检测。
NMS 的逻辑是:
- 按置信度从高到低排序;
- 选置信度最高的框;
- 删除与它 IoU(交并比)过高 的其他框(通常 IoU > 0.45);
- 重复直到没有框剩余。
假设一只狗出现在图像中央,三个检测层预测如下:
层 预测框尺寸 置信度 IoU 是否保留 P3 60×60 0.80 - 保留 P4 62×62 0.78 0.93(与P3框重叠) 删除 P5 70×70 0.65 0.85 删除 检测头一般有如下参数:
参数 作用 默认值 调整效果 conf_thres 最低置信度阈值 0.25 降低会增加框数、误检也多 iou_thres NMS 抑制阈值 0.45 降低会更严格,可能漏检 max_det 每张图最大检测框数 300 限制输出数量 agnostic_nms 类别无关 NMS False 若 True,多类别重叠也抑制 multi_label 是否允许一个框预测多个类别 False 默认每框一个类别
二、调试官方代码,查看运行流程
(一)、测试代码
# model_train.py
from ultralytics import YOLOif __name__ == "__main__":# 1. 加载模型(检测或分割)model = YOLO(r"yolo11.yaml") # 或 yolov11n-seg.pt# 2. 开始训练model.train(data="E:/python project/Yolo_learning/ultralytics-main/people/data.yaml",epochs=5,imgsz=640,batch=8,device=0, # GPU:0,若无GPU则改为 "cpu"workers=0, # Windows 建议设 0 避免多进程报错name="train_person_y11"# 输出保存到 runs/detect/train_person_y11)
注意:应该把data换成自己电脑的绝对路径,并且我们这次用yaml作为model而不是pt,需要把yaml提前放置好然后给出绝对路径。
(二)、Debug调试
1. 在model_train.py中打断点
在model这一行打断点
2.在task.py中打断点
在文件中搜索parse_model函数,在此处打两个断点。task.py 默认位于
..\ultralytics-main\ultralytics\nn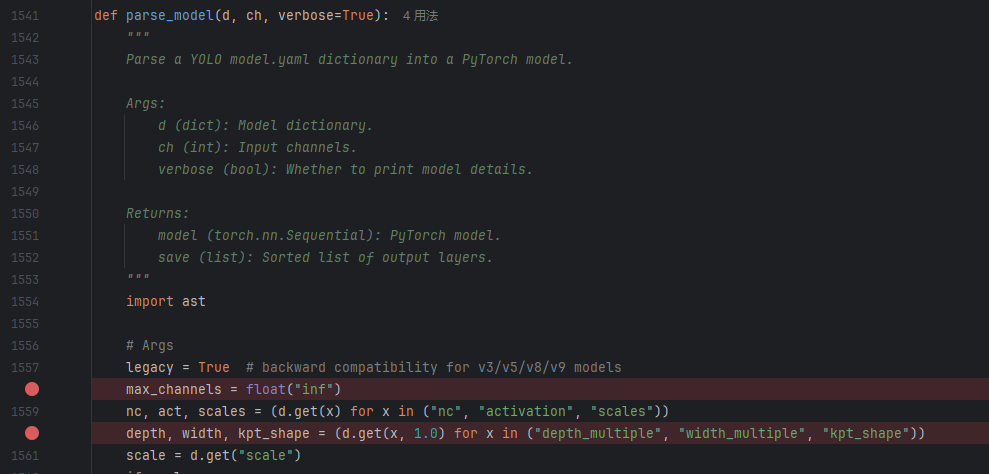
为什么要在这个部位打断点呢?
parse_model是真正构建网络的地方,所以把断点打到这里最稳。如果仅仅在train.py打断点直接步入会进入model.py的__init__函数。在
YOLO.__init__这里“步入”,调试器只会短暂停一下,随即把控制权交给基类Model.__init__,然后一路构建完网络又返回。整体看起来就像是调试器自己关了一样。
3.分析初始化流程
如下为parse_model(模型描述)的全部代码。
def parse_model(d, ch, verbose=True):"""Parse a YOLO model.yaml dictionary into a PyTorch model.Args:d (dict): Model dictionary.ch (int): Input channels.verbose (bool): Whether to print model details.Returns:model (torch.nn.Sequential): PyTorch model.save (list): Sorted list of output layers."""import ast# Argslegacy = True # backward compatibility for v3/v5/v8/v9 modelsmax_channels = float("inf")nc, act, scales = (d.get(x) for x in ("nc", "activation", "scales"))depth, width, kpt_shape = (d.get(x, 1.0) for x in ("depth_multiple", "width_multiple", "kpt_shape"))scale = d.get("scale")if scales:if not scale:scale = tuple(scales.keys())[0]LOGGER.warning(f"no model scale passed. Assuming scale='{scale}'.")depth, width, max_channels = scales[scale]if act:Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = torch.nn.SiLU()if verbose:LOGGER.info(f"{colorstr('activation:')} {act}") # printif verbose:LOGGER.info(f"\n{'':>3}{'from':>20}{'n':>3}{'params':>10} {'module':<45}{'arguments':<30}")ch = [ch]layers, save, c2 = [], [], ch[-1] # layers, savelist, ch outbase_modules = frozenset({Classify,Conv,ConvTranspose,GhostConv,Bottleneck,GhostBottleneck,SPP,SPPF,C2fPSA,C2PSA,DWConv,Focus,BottleneckCSP,C1,C2,C2f,C3k2,RepNCSPELAN4,ELAN1,ADown,AConv,SPPELAN,C2fAttn,C3,C3TR,C3Ghost,torch.nn.ConvTranspose2d,DWConvTranspose2d,C3x,RepC3,PSA,SCDown,C2fCIB,A2C2f,})repeat_modules = frozenset( # modules with 'repeat' arguments{BottleneckCSP,C1,C2,C2f,C3k2,C2fAttn,C3,C3TR,C3Ghost,C3x,RepC3,C2fPSA,C2fCIB,C2PSA,A2C2f,})for i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]): # from, number, module, argsm = (getattr(torch.nn, m[3:])if "nn." in melse getattr(__import__("torchvision").ops, m[16:])if "torchvision.ops." in melse globals()[m]) # get modulefor j, a in enumerate(args):if isinstance(a, str):with contextlib.suppress(ValueError):args[j] = locals()[a] if a in locals() else ast.literal_eval(a)n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gainif m in base_modules:c1, c2 = ch[f], args[0]if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)c2 = make_divisible(min(c2, max_channels) * width, 8)if m is C2fAttn: # set 1) embed channels and 2) num headsargs[1] = make_divisible(min(args[1], max_channels // 2) * width, 8)args[2] = int(max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2])args = [c1, c2, *args[1:]]if m in repeat_modules:args.insert(2, n) # number of repeatsn = 1if m is C3k2: # for M/L/X sizeslegacy = Falseif scale in "mlx":args[3] = Trueif m is A2C2f:legacy = Falseif scale in "lx": # for L/X sizesargs.extend((True, 1.2))if m is C2fCIB:legacy = Falseelif m is AIFI:args = [ch[f], *args]elif m in frozenset({HGStem, HGBlock}):c1, cm, c2 = ch[f], args[0], args[1]args = [c1, cm, c2, *args[2:]]if m is HGBlock:args.insert(4, n) # number of repeatsn = 1elif m is ResNetLayer:c2 = args[1] if args[3] else args[1] * 4elif m is torch.nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)elif m in frozenset({Detect, WorldDetect, YOLOEDetect, Segment, YOLOESegment, Pose, OBB, ImagePoolingAttn, v10Detect}):args.append([ch[x] for x in f])if m is Segment or m is YOLOESegment:args[2] = make_divisible(min(args[2], max_channels) * width, 8)if m in {Detect, YOLOEDetect, Segment, YOLOESegment, Pose, OBB}:m.legacy = legacyelif m is RTDETRDecoder: # special case, channels arg must be passed in index 1args.insert(1, [ch[x] for x in f])elif m is CBLinear:c2 = args[0]c1 = ch[f]args = [c1, c2, *args[1:]]elif m is CBFuse:c2 = ch[f[-1]]elif m in frozenset({TorchVision, Index}):c2 = args[0]c1 = ch[f]args = [*args[1:]]else:c2 = ch[f]m_ = torch.nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace("__main__.", "") # module typem_.np = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type = i, f, t # attach index, 'from' index, typeif verbose:LOGGER.info(f"{i:>3}{str(f):>20}{n_:>3}{m_.np:10.0f} {t:<45}{str(args):<30}") # printsave.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []ch.append(c2)return torch.nn.Sequential(*layers), sorted(save)
这函数给了三个参量,分别是d,ch,werbose:
| 名称 | 类型 | 含义 | 典型来源 | 影响范围 |
|---|---|---|---|---|
d | dict | 解析后的 model.yaml 字典。包含 nc、backbone、head、scales、scale、activation、depth_multiple、width_multiple 等键。 | 由 yaml_load() 或上层 DetectionModel 读入 YAML 后传入 | 决定模型结构、规模缩放、激活函数等;是唯一架构蓝图 |
ch | int | 输入通道数(通常为 3,RGB)。 | 由上层根据输入图像通道数确定 | 初始化通道账本(后续每层输出通道都由它递推) |
verbose | bool | 是否在构建时打印详细表格与激活信息。 | 训练/调试时常设 True | 决定是否 LOGGER.info(...) 输出每层参数/通道等 |
其流程如下,可以分为八个模块:
(注释为了更明显并没采用python注释方式)
1)读取全局超参
legacy = True
/*用于后面 Detect/Segment/Pose 等头的旧版本兼容分支(遇到部分新模块会改为 False)*/max_channels = float("inf")
/*默认最大通道为极大值,如果由scale就用scale*/nc, act, scales = (d.get(x) for x in ("nc", "activation", "scales"))
/*获取类别数、激活字符串、多规格缩放表(n/s/m/l/x → [depth,width,maxc])*/depth, width, kpt_shape = (d.get(x, 1.0) for x in ("depth_multiple", "width_multiple", "kpt_shape"))
/*获取网络深度,宽度的缩放倍率、姿态关键点形态*/scale = d.get("scale")
if scales:if not scale:scale = tuple(scales.keys())[0]LOGGER.warning(f"no model scale passed. Assuming scale='{scale}'.")depth, width, max_channels = scales[scale]
/*指定使用 scales 里的哪个键;未给则默认取 scales 的第一个键并告警*/if act:Conv.default_act = eval(act)if verbose:LOGGER.info(f"{colorstr('activation:')} {act}") # print
if verbose:LOGGER.info(f"\n{'':>3}{'from':>20}{'n':>3}{'params':>10} {'module':<45}{'arguments':<30}")
/*若非空,稍后会用 eval() 设置 Conv.default_act。*/
/*如果要求打印,则输出相关内容:from(来源层)、n(重复)、params(参数量)、module、arguments。*/这一步本质上就是在读default.yaml定超参数,一些默认参量如果yaml中提及了会被覆盖,然后打印模型信息。到这里,每次运行时生成的一大坨东西就输出到这里了:
2)准备日志和通道账本
ch = [ch]
/*ch 是“通道账本”:ch[i] 表示 第 i 层输出通道数。初始化时只有输入通道(通常 3)。*/layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
/*逐层实例化后的模块列表、需要在前向中缓存的来源层索引(跨层会用到)、临时占位(初始化时=输入通道),每层处理后用真实 c2 覆盖*/base_modules = frozenset({Classify,Conv,ConvTranspose,GhostConv,Bottleneck,GhostBottleneck,SPP,SPPF,C2fPSA,C2PSA,DWConv,Focus,BottleneckCSP,C1,C2,C2f,C3k2,RepNCSPELAN4,ELAN1,ADown,AConv,SPPELAN,C2fAttn,C3,C3TR,C3Ghost,torch.nn.ConvTranspose2d,DWConvTranspose2d,C3x,RepC3,PSA,SCDown,C2fCIB,A2C2f,})
/*“常规模块白名单”,落在此集合的模块走相同的 c1/c2 处理套路*/repeat_modules = frozenset( # modules with 'repeat' arguments{BottleneckCSP,C1,C2,C2f,C3k2,C2fAttn,C3,C3TR,C3Ghost,C3x,RepC3,C2fPSA,C2fCIB,C2PSA,A2C2f,})
/*“内部重复型模块白名单”,n(重复数)会注入模块构造参数中,而不是用外层 nn.Sequential 重复*/
/*显然内循环是比外循环快的*/3)取网络
for i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]): # from, number, module, args
/*读取结构为[from, repeats, module, args]*/m = (getattr(torch.nn, m[3:])if "nn." in melse getattr(__import__("torchvision").ops, m[16:])if "torchvision.ops." in melse globals()[m]) # get module
/*若 m 以 "nn." 开头 → 取 torch.nn 下的类(如 nn.Upsample)。*/for j, a in enumerate(args):if isinstance(a, str):with contextlib.suppress(ValueError):args[j] = locals()[a] if a in locals() else ast.literal_eval(a)n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
/*参数中若是字符串(比如 "True"、"[1,2]"、"0.25"、"nn.SiLU()"),尝试转为 Python 对象*/这段本质是在读model.yaml,在本过程中读的是yolo11.yaml。主要是将yaml中标准化的参数实例化成python格式,做的是配置到函数功能的链接。
4)推导通道与参数
if m in base_modules:c1, c2 = ch[f], args[0]
/*输入通道 c1 = ch[f],c2 来自 args[0], args[0] 是 YAML 设定的名义输出通道(比如 256、512…)*/if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)c2 = make_divisible(min(c2, max_channels) * width, 8)
/*若不是 Classify 输出,执行宽度缩放:c2 = min(c2, max_channels) * width和8倍数对齐(能被8整除)*/if m is C2fAttn: # set 1) embed channels and 2) num headsargs[1] = make_divisible(min(args[1], max_channels // 2) * width, 8)args[2] = int(max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2])args = [c1, c2, *args[1:]]
/*自动推导的输入通道 c1 放到参数最前,保证后续 m(*args) 构造函数签名正确。*/if m in repeat_modules:args.insert(2, n) # number of repeatsn = 1
/*若模块在 repeat_modules,把 n 注入到 args 第 3 位,改为内部重复,同时把外层 n 置 1。*/if m is C3k2: # for M/L/X sizeslegacy = Falseif scale in "mlx":args[3] = Trueif m is A2C2f:legacy = Falseif scale in "lx": # for L/X sizesargs.extend((True, 1.2))if m is C2fCIB:legacy = False 这段本质是基于2中的base_modules,基本组件进行对不同层的通道进行设置。并且在下面给出了基于不同组件的微调设置。比如C3K2残差中,如果scale 在 "m"|"l"|"x",把 args[3]=True(意味着强制 shortcut=True,即开启残差链接)。这个分支完成了最重要的 c1/c2 推导、通道缩放与重复注入。(这个c是channel的意思)
到这可能会有点不解,我们举个例子:
[-1, 1, Conv, [64, 3, 2]]/*
f=-1, n=1, m=Conv, args=[64, 3, 2]
c1 = ch[-1](上层输出通道)
c2 = 64(名义输出通道,来自 args[0])
若非分类头:c2 ← min(c2, max_channels) * width,再做 8 对齐(不同 scale 时通道数会变)
组织实参:args = [c1, c2, 3, 2]
实际调用:Conv(c1, c2, k=3, s=2)
*//*这里 repeats=1 完全在 YAML 第二格,不在 args 里。*/[-1, 2, C3k2, [512, False, 0.25]]/*
f=-1, n=2, m=C3k2, args=[512, False, 0.25]
c1 = ch[-1];c2 = 512 →(按 width & max_channels 缩放+对齐)
先排好前两位:args = [c1, c2, False, 0.25]因为 C3k2 在 repeat_modules:
插入 repeats 到第 3 个位置:args.insert(2, n) → [c1, c2, 2, False, 0.25]
并把外层 n 置 1:外层不再 nn.Sequential 重复,由模块内部处理重复。实际调用:C3k2(c1, c2, repeats=2, shortcut=False, e=0.25)这就解释了:repeats 并非 YAML args 的“第二个参数”,而是 YAML 四元组的第二段。只有在“可内部重复”的模块里,parse 时才把它塞进 args 里。
*/这里一定重点注意是否在repeat_modules的白名单中,参考2.模块
5)特殊分支处理
elif m is AIFI:args = [ch[f], *args]
/*将 c1=ch[f] 插入参数首位(保持与其构造签名一致)。*/elif m in frozenset({HGStem, HGBlock}):c1, cm, c2 = ch[f], args[0], args[1]args = [c1, cm, c2, *args[2:]]if m is HGBlock:args.insert(4, n) # number of repeatsn = 1
/*类模块构造函数的前几个参数是 (c1, cm, c2, ...),所以做了位置重排。*/
/*HGBlock 支持内部重复 → 注入 n 并把外层 n=1。*/elif m is ResNetLayer:c2 = args[1] if args[3] else args[1] * 4
/*根据是否使用瓶颈结构(args[3] 布尔)决定输出通道是否乘 4。*/elif m is torch.nn.BatchNorm2d:args = [ch[f]]
/*BN 的 num_features 就是输入通道。*/elif m is Concat:c2 = sum(ch[x] for x in f)
/*f 必须是列表:把所有来源层通道数求和就是拼接后的输出通道。*/elif m in frozenset({Detect, WorldDetect, YOLOEDetect, Segment, YOLOESegment, Pose, OBB, ImagePoolingAttn, v10Detect}):args.append([ch[x] for x in f])if m is Segment or m is YOLOESegment:args[2] = make_divisible(min(args[2], max_channels) * width, 8)if m in {Detect, YOLOEDetect, Segment, YOLOESegment, Pose, OBB}:m.legacy = legacy
/*检测/分割/姿态/旋转框/世界/YOLOE/v10Detect 等头*/
/*将各输入分支的通道列表追加至 args(例如 Detect 需要 [cP3, cP4, cP5])。*/
/*分割头还要对其掩码分支通道 args[2] 做宽度与上限的缩放与对齐。*/
/*legacy 标志挂到模块类上(影响其内部行为分支)。*/elif m is RTDETRDecoder: args.insert(1, [ch[x] for x in f])
/*该解码器要求“通道列表在位置 1”,因此是 insert(1, ...) 而非 append(...)。*/elif m is CBLinear:c2 = args[0]c1 = ch[f]args = [c1, c2, *args[1:]]elif m is CBFuse:c2 = ch[f[-1]]
/*CBLinear:首参为输出通道,显式设置 c1 并重排;CBFuse:输出通道等于最后一个来源层的通道。*/elif m in frozenset({TorchVision, Index}):c2 = args[0]c1 = ch[f]args = [*args[1:]]
/*特定封装的兼容模块,c2 直接取首参,c1 用来源通道,然后去掉多余头参。*/else:c2 = ch[f]
/*未命中的模块默认输出通道等于输入通道(如纯激活/残差加法等无通道改变的层)。*/这些内容并不重要,本质上是处理了功能/函数不在base_modules中的情况,然后做了base和假设中全都不存在兜底处理。
6)实例化模块
m_ = torch.nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
/*若前面已把 n 注入 args(模块在 repeat_modules),这里的 n 一定被置 1 → 单次实例化。*/t = str(m)[8:-2].replace("__main__.", "") # module typem_.np = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type = i, f, t # attach index, 'from' index, typeif verbose:LOGGER.info(f"{i:>3}{str(f):>20}{n_:>3}{m_.np:10.0f} {t:<45}{str(args):<30}")
/*
t 是类型名字符串用于打印;
m_.np 统计参数量;
m_.i/m_.f/m_.type 附加元信息(层序号/来源/类型),便于 model.info() 或可视化。
*/
这个模块本质上处理了网络的repeat问题,决定其是内部还是外部重复,另外设置了一些打印参量。
7)保存通道
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
/*把本层依赖的“非 -1 的来源层”加入保存列表,训练/推理时将缓存这些输出供后续层复用(如 route/concat)。*/layers.append(m_)
/*把“本层输出通道”记到账本里,供后续层引用。*/if i == 0:ch = []ch.append(c2)
/*i==0 时把初始 ch 清空*/
8)返回结果
return nn.Sequential(*layers), sorted(save)
/*Sequential:按 YAML 顺序串起来的整个网络骨架。*/
/*save:已排序的需要缓存的中间层索引(用于前向时的跨层连接)。*/
总之,parse_model 的产出是:(1) 顺序模型骨架 nn.Sequential + (2) 路由缓存表 save。它们被上层任务模型接收,并在前向传播与可视化/统计中使用。
三、在网络层添加自己的内容
(一)、回顾网络层配置
这里我们只做简单回顾,详细回顾请参考:笔记:对yolov8网络代码的学习_github yolov8-CSDN博客
1.位置和格式
yolo11.yaml配置文件默认位于
..\ultralytics-main\ultralytics\cfg\models\11格式默认为:
[from, repeats, module, args]2.结构
- nc:种类数,通过标签可以相互区分的种类,如果不清楚参考:基于pycharm和anaconda的yolo简单部署测试_pyachrm部署yolo-CSDN博客中的2.2标签标注去了解nc是怎么来的。
- scale:规模,用来设置不同模型(n/s/m/l/x)时的缩放因子和最大通道数,最大通道数。
- backbone:主干网络,在这一部分主要负责特征提取。
- head:包括了传统意义上的neck和detect,也就是颈部和检测头,这一部分主要负责特征融合(深层的上采样和浅层的下采样融合)和针对不同大小目标输出检测结果。
3.功能库
参见功能组件附带的_init_.py,里面是所有的功能初始化的内容,其中就包含了从多处引用的功能类/组件(module)例如Conv,C3k2等,位置位于:
..\ultralytics-main\ultralytics\nn\modules\__init__.py(二)、添加自建功能类
写代码主要就是两个问题,“往哪写”和“怎么写”。
1.往哪写
就在上文,3.1.3功能库提到了__init__.py,我们来看看里面都是什么: `
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
"""
Ultralytics neural network modules.This module provides access to various neural network components used in Ultralytics models, including convolution
blocks, attention mechanisms, transformer components, and detection/segmentation heads.Examples:Visualize a module with Netron>>> from ultralytics.nn.modules import Conv>>> import torch>>> import subprocess>>> x = torch.ones(1, 128, 40, 40)>>> m = Conv(128, 128)>>> f = f"{m._get_name()}.onnx">>> torch.onnx.export(m, x, f)>>> subprocess.run(f"onnxslim {f} {f} && open {f}", shell=True, check=True) # pip install onnxslim
"""from .block import (C1,C2,C2PSA,C3,C3TR,CIB,DFL,ELAN1,PSA,SPP,SPPELAN,SPPF,A2C2f,AConv,ADown,Attention,BNContrastiveHead,Bottleneck,BottleneckCSP,C2f,C2fAttn,C2fCIB,C2fPSA,C3Ghost,C3k2,C3x,CBFuse,CBLinear,ContrastiveHead,GhostBottleneck,HGBlock,HGStem,ImagePoolingAttn,MaxSigmoidAttnBlock,Proto,RepC3,RepNCSPELAN4,RepVGGDW,ResNetLayer,SCDown,TorchVision,
)
from .conv import (CBAM,ChannelAttention,Concat,Conv,Conv2,ConvTranspose,DWConv,DWConvTranspose2d,Focus,GhostConv,Index,LightConv,RepConv,SpatialAttention,
)
from .head import (OBB,Classify,Detect,LRPCHead,Pose,RTDETRDecoder,Segment,WorldDetect,YOLOEDetect,YOLOESegment,v10Detect,
)
from .transformer import (AIFI,MLP,DeformableTransformerDecoder,DeformableTransformerDecoderLayer,LayerNorm2d,MLPBlock,MSDeformAttn,TransformerBlock,TransformerEncoderLayer,TransformerLayer,
)__all__ = ("Conv","Conv2","LightConv","RepConv","DWConv","DWConvTranspose2d","ConvTranspose","Focus","GhostConv","ChannelAttention","SpatialAttention","CBAM","Concat","TransformerLayer","TransformerBlock","MLPBlock","LayerNorm2d","DFL","HGBlock","HGStem","SPP","SPPF","C1","C2","C3","C2f","C3k2","SCDown","C2fPSA","C2PSA","C2fAttn","C3x","C3TR","C3Ghost","GhostBottleneck","Bottleneck","BottleneckCSP","Proto","Detect","Segment","Pose","Classify","TransformerEncoderLayer","RepC3","RTDETRDecoder","AIFI","DeformableTransformerDecoder","DeformableTransformerDecoderLayer","MSDeformAttn","MLP","ResNetLayer","OBB","WorldDetect","YOLOEDetect","YOLOESegment","v10Detect","LRPCHead","ImagePoolingAttn","MaxSigmoidAttnBlock","ContrastiveHead","BNContrastiveHead","RepNCSPELAN4","ADown","SPPELAN","CBFuse","CBLinear","AConv","ELAN1","RepVGGDW","CIB","C2fCIB","Attention","PSA","TorchVision","Index","A2C2f",
)
我们发现,此处从Conv,block,head,transform分别引入了好多组件,其中我们常见的,官方yaml中有的:Conv卷积,C3k2残差,SPPF池化和C2PSA注意力等。那我们应该意识到:这里就是对module的调用文件。我们还注意到:所有上述的module必须要在__all__中声明。否则是无法初始化的。
那我们同时也应该意识到,如果想要添加组件必须在这几个文件中写入然后在init文件中声明才能成功添加自己。
同样是功能,写在这几个文件中有什么区别吗?
结论先讲:放在
conv.py、block.py或别的文件都行,只要在__init__.py里把你的类正确导入并加入__all__。这里为了可读性和规模化考虑,还是建议:
卷积/小组件:放
conv.py更合逻辑。复合块 / CSP 类结构:放
block.py更常见。检测/分割/姿态等“头”:放
head.py。Transformer/注意力:放
transformer.py。
我们再来拿Conv.py举例子,位置:
..\ultralytics-main\ultralytics\nn\modules\conv.py看看组件文件里面都写了什么,是怎么对组件类进行撰写的(太长了,拿第一个Conv组件举例子):
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
"""卷积模块(Convolution modules)。"""from __future__ import annotationsimport math
import numpy as np
import torch
import torch.nn as nn__all__ = ("Conv","Conv2","LightConv","DWConv","DWConvTranspose2d","ConvTranspose","Focus","GhostConv","ChannelAttention","SpatialAttention","CBAM","Concat","RepConv","Index",
)def autopad(k, p=None, d=1): # kernel, padding, dilation"""自动计算填充(padding),以保证输出尺寸与输入保持一致。"""if d > 1:# 若使用膨胀卷积 (dilation),计算实际的 kernel 大小k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]if p is None:# 若未指定 padding,则根据 kernel 大小自动计算p = k // 2 if isinstance(k, int) else [x // 2 for x in k]return pclass Conv(nn.Module):"""标准卷积模块,包含卷积层、批归一化层 (BatchNorm) 和激活函数层 (Activation)。属性:conv (nn.Conv2d): 卷积层。bn (nn.BatchNorm2d): 批量归一化层。act (nn.Module): 激活函数层。default_act (nn.Module): 默认激活函数 (SiLU)。"""default_act = nn.SiLU() # 默认激活函数为 SiLUdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""初始化卷积模块。参数:c1 (int): 输入通道数。c2 (int): 输出通道数。k (int): 卷积核大小 (kernel size)。s (int): 步幅 (stride)。p (int, 可选): 填充 (padding),若为 None 则自动计算。g (int): 分组数 (groups),默认为 1。d (int): 膨胀系数 (dilation),控制感受野。act (bool | nn.Module): 激活函数,可为布尔值或自定义模块。"""super().__init__()# 构建卷积层,autopad() 会自动计算 padding,使输出与输入尺寸一致self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)# 批归一化层,稳定训练、加快收敛self.bn = nn.BatchNorm2d(c2)# 激活函数:若 act=True 则使用默认 SiLU,否则使用传入模块或恒等映射self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""前向传播:依次执行卷积、批归一化、激活函数。参数:x (torch.Tensor): 输入张量。返回:torch.Tensor: 输出张量。"""return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):"""在融合 (fuse) 模式下的前向传播:仅执行卷积 + 激活,不进行 BN。(通常用于模型导出或推理阶段,将 BN 参数融合进卷积权重)参数:x (torch.Tensor): 输入张量。返回:torch.Tensor: 输出张量。"""return self.act(self.conv(x))
我们观察到,Conv分为初始化、前向传播、前向融合三个功能,另外在外面还定义了一个autopad函数,这个是Conv.py特有的,是一个小工具函数,用来自动计算卷积层的 padding(填充),使得输出特征图的尺寸与输入保持一致(即所谓的 "same" 卷积)。
2.怎么写
1)添加简易自制模块
假设我们现在要写一个小组件:MyMP类,什么都不干就是在网络运行时输出一行字:“this is MyMP”以及当前的通道数。
需要考虑的内容:
| 内容 | 说明 |
|---|---|
assert c1 == c2 | 确保输入输出通道相同 |
self.identity = nn.Identity() | 不进行任何卷积或激活,仅作为传递模块 |
print("this is MyMP") | 每次网络执行到这一层都会在控制台输出这句话 |
return self.identity(x) | 原样返回输入张量(不改变特征) |
这里要提一句:所有的类的初始化函数,参数必须有c1和c2,这是规定!其他是按功能需求添加。
class MyMP(nn.Module):"""A simple demo module that prints a message when executed."""def __init__(self, c1, c2):"""MyMP module.Args:c1 (int): Input channels.c2 (int): Output channels (same as c1 here)."""super().__init__()assert c1 == c2, "For MyMP demo, input and output channels must be equal"self.c1 = c1 # 保存输入通道信息self.c2 = c2 # 保存输出通道信息self.identity = nn.Identity() # 不做任何计算def forward(self, x):"""Forward pass that just prints a message and returns x unchanged."""print(f"this is MyMP -- channel_in={self.c1}, channel_out={self.c2}")return self.identity(x)
对于此次功能添加,我们一共需要改动六处地方(下文还要补充一处):
- __init__.py 中对from .Conv import 部分,将MyMP添加进去
- __init__.py 中__all__部分,将MyMP添加进去
路径:..\ultralytics-main\ultralytics\nn\modules\__init__.py - Conv.py 中__all__部分,将MyMP添加进去
- Conv.py 中代码部分,在最下方放入完整代码
路径:..\ultralytics-main\ultralytics\nn\modules\conv.py - yolo11.yaml 中backbone/head部分,在其中插入MyMP,注意格式
路径:..\ultralytics-main\people\yolo11.yaml - task.py 最顶端,from ultralytics.nn.modules import 部分中添加MyMP
路径:..\ultralytics-main\ultralytics\nn\tasks.py
一定要注意符号,不要漏写/写错引号和逗号!!!
2)调用自制模块
在前面,我们已经把添加新模块的底层逻辑给整理好了,这里就是在yaml中直接调用就可以了,这里我们对backbone做如下改动:
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 1, MyMP, [128] #改动- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 2, MyMP, [512]] #改动- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 2, C2PSA, [1024]] # 10我们在浅层插入了一个MyMP,深层插入了一个repeat=2的MyMP,基于上面我们对parse_model中的第2步:准备通道账本中提到过,进入repeat_module白名单的组件将会采用内部重复,此处我们的MyMP没有添加到白名单,因此采用的是外部重复(由 Sequential 控制)。
如果你立刻运行,会出现一个问题:TypeError: MyMP.__init__() missing 1 required positional argument: 'c2'
这正中了我们刚提到的准备通道账本,在
parse_model()里,只有当模块在base_modules集合中时,才会把参数重排为:args = [c1, c2, *args[1:]]也就是自动补上
c1=ch[f],并把args[0]当名义c2做宽度缩放/8 对齐后传给构造函数。但我们的 MyMP 还不在base_modules,于是parse_model没有改造args,直接拿原始的[256]去实例化:m(*args) → MyMP(256) # 只给了一个位置参数因此最简单也最符合逻辑的方式就是在task.py中的parse_model函数中的base_module部分加入MyMP。
所以我们要改动的地方从六处变成了七处。
3)运行代码
如果前面的步骤顺下来的话,我们就可以开始运行了。我们采用的数据集链接如下:
https://universe.roboflow.com/objectdetection-1gccs/crowdhuman-dtwxp/dataset/1/
如果不懂数据集怎么放,请参考以下链接的2.3数据集配置部分:
基于pycharm和anaconda的yolo简单部署测试_anaconda yolo-CSDN博客
运行代码如下(同2.1的测试代码):
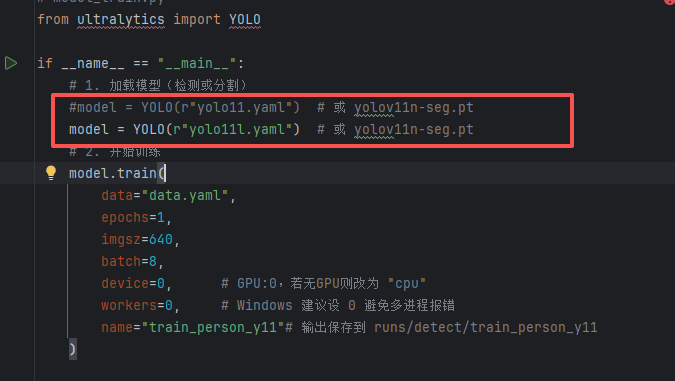
# model_train.py
from ultralytics import YOLOif __name__ == "__main__":# 1. 加载模型(检测或分割)model = YOLO(r"yolo11.yaml") # 或 yolov11n-seg.pt# 2. 开始训练model.train(data="data.yaml",epochs=5,imgsz=640,batch=8,device=0, # GPU:0,若无GPU则改为 "cpu"workers=0, # Windows 建议设 0 避免多进程报错name="train_person_y11"# 输出保存到 runs/detect/train_person_y11)
注意:model和data两个需要调成你需要的绝对路径,也可以相对路径。
***懒人通道***:现成代码
如果你直接点到这里,就是需要一份能运行的代码测试,那我们提供从ultralytics到crowdhuman.v1i数据集和运行代码的全部资料。
注:上传的是ultralytics_main中的内容,上述路径直接相当于相对路径。
https://github.com/zsq1811045559-collab/Train_yolocode
4)观察结果
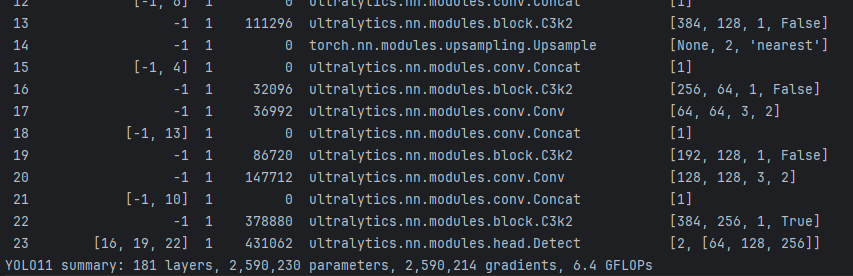
在准备日志阶段,我们已经能看到我们的MyMP被添加到里面了:
from n params module arguments 0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2] 1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2] 2 -1 1 0 ultralytics.nn.modules.conv.MyMP [32, 32] 3 -1 1 6640 ultralytics.nn.modules.block.C3k2 [32, 64, 1, False, 0.25] 4 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2] 5 -1 1 26080 ultralytics.nn.modules.block.C3k2 [64, 128, 1, False, 0.25] 6 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2] 7 -1 1 87040 ultralytics.nn.modules.block.C3k2 [128, 128, 1, True] 8 -1 1 0 ultralytics.nn.modules.conv.MyMP [128, 128] 9 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2] 10 -1 1 346112 ultralytics.nn.modules.block.C3k2 [256, 256, 1, True] 11 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5] 12 -1 1 249728 ultralytics.nn.modules.block.C2PSA [256, 256, 1] 13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 14 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1] 15 -1 1 111296 ultralytics.nn.modules.block.C3k2 [384, 128, 1, False] 16 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 17 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1] 18 -1 1 28000 ultralytics.nn.modules.block.C3k2 [192, 64, 1, False] 19 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2] 20 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1] 21 -1 1 103104 ultralytics.nn.modules.block.C3k2 [320, 128, 1, False] 22 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2] 23 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1] 24 -1 1 378880 ultralytics.nn.modules.block.C3k2 [384, 256, 1, True] 25 [16, 19, 22] 1 408342 ultralytics.nn.modules.head.Detect [2, [128, 64, 128]] 但是我们发现,在日志中还掺杂着我们MyMP的输出,这是为什么呢?
parse_model 的执行逻辑是:
for i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]):...m_ = torch.nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args)也就是说,每构造一个模块(包括 MyMP)都会立即执行它的
__init__(),从而打印出this is MyMP。而logging打印的日志和print两者的 flush 时机不同,再加上既在 构建期(__init__) 打印,又在 前向期(forward) 打印,因此会出现你看到的顺序与多次重复。
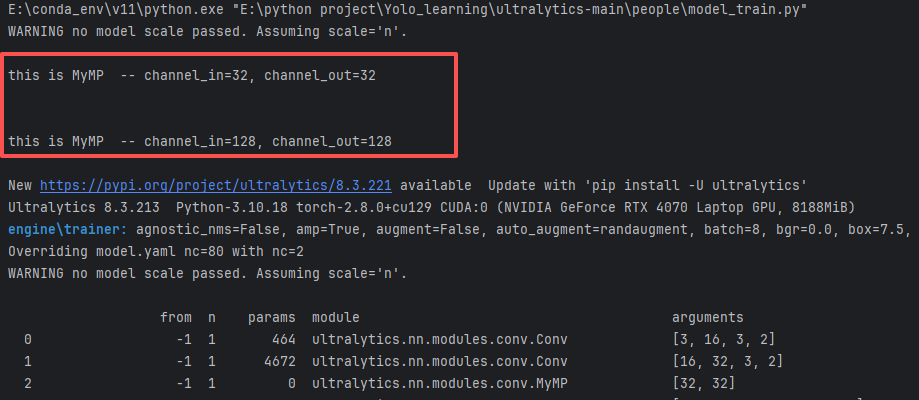
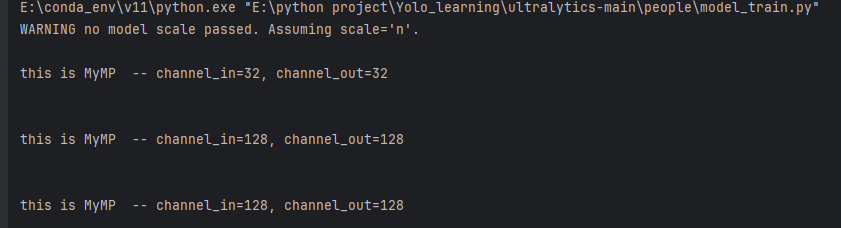
另外,我们还注意到,我们设定的channel是128和512,输出怎么变成32和128了?
通道显示 32 和 128 是因为我们没显式指定
scale,被默认成n型(width_multiple=0.25),把 YAML 里写的名义通道按 0.25 缩小并对齐到 8 的倍数:
写的 128 → 实际 32
写的 512 → 实际 128
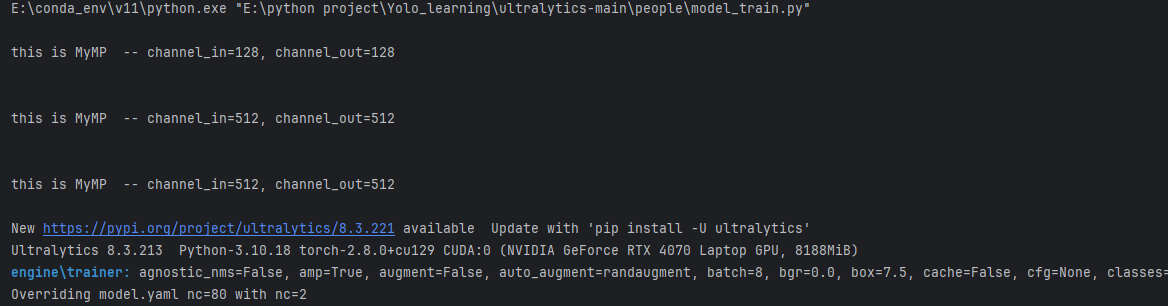
我们的repeat=2的MyMP为什么没有执行两次?
其实和上面问题一样,是模型缩放因子导致的,deepth被乘以0.5了,所以repeat为2的全都变成1了。
在原文model中加一个‘ l ’就好了,程序会自动识别模型,不声明就是n。
加完‘ l ’后warning也没有了,因为识别到模型了。
同理,我们用n,把repeat改成3也能重复两次。
四、总结
本文我们串联了之前的两篇笔记,分别是学会使用Yolo和了解Yolo的网络,基于以上经验,我们仔细学习了task文件中十分重要的模型结构函数:model_prase,并从中获取了组件初始化的规律的方法。
另外通过回顾yolo主要的几个yaml,认识到组件的初始化并不是独立的,不是由一个脚本就完成的,其中串联很多检测的函数以及格式修正内容。另外一些像纳入白名单的组件还可以享受base_modules不一样的功能和方法。
在学习到了模型组件初始化的规律后,我们尝试采用其中的conv文件来添加我们自己的功能函数,并且发现了对于不同模型,我们的repeat是不一定生效的,因为发生了缩放。
总之,本次已经对Yolo底层,尤其是组件有了一个初步理解,日后有机会我们会更深入一点,比如加一些repeat白名单组件或者一些复杂的功能以便创新。