【Block总结】MRFA,大卷积感受野,提高小目标检测的利器|即插即用|ICCV 2025
论文信息
- 标题:UniConvNet: Expanding Effective Receptive Field while Maintaining Asymptotically Gaussian Distribution for ConvNets of Any Scale
- 代码:https://github.com/aipaperwithcode/UniConvNe
- 核心问题:当前的大核卷积神经网络(ConvNets)虽然能获得大的有效感受野(ERF),但存在参数量和计算量(FLOPs)高昂的问题,并且会破坏ERF应有的渐近高斯分布(AGD)特性,即“距离中心越近的像素影响越大”的直觉。
- 目标:提出一种高效且有效的方法,在扩展ERF的同时,严格保持其AGD特性,从而提升模型在各种视觉任务上的性能。
创新点
- 提出新范式:论文挑战了“越大越好”的大核设计思路,提出了一种替代范式——通过合理组合多个较小的卷积核(如7x7, 9x9, 11x11)来扩展ERF,这种方法比直接使用单一极大卷积核更有效、更高效。
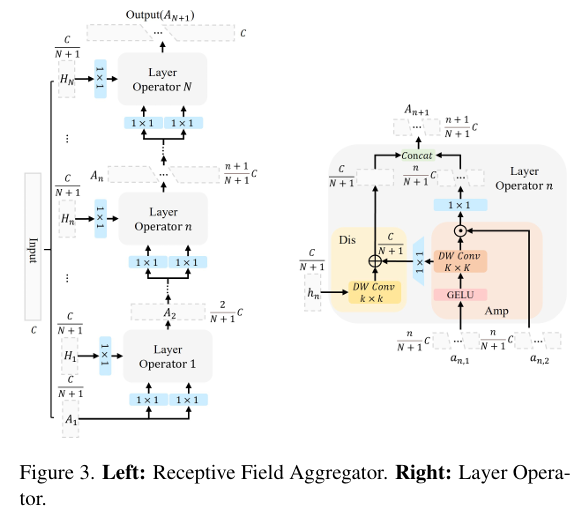
- 引入感受野聚合器(RFA):设计了一个名为RFA的模块,能够在单个浅层模块内就为不同尺度的感受野分配判别性影响,从而直接构建出符合AGD的多层感受野结构。
- 设计层算子(LO):作为RFA的核心组件,LO由**放大器(Amp)和判别器(Dis)**构成。Amp通过门控机制放大感受野内像素的影响,Dis则引入小尺度的新像素信息,二者协同工作以构建一个具有两层AGD的复合感受野。
- 构建通用模型UniConvNet:将三层RFA作为即插即用模块,集成到现有先进CNN架构(如InternImage)中,构建了适用于任意规模的通用ConvNet模型。
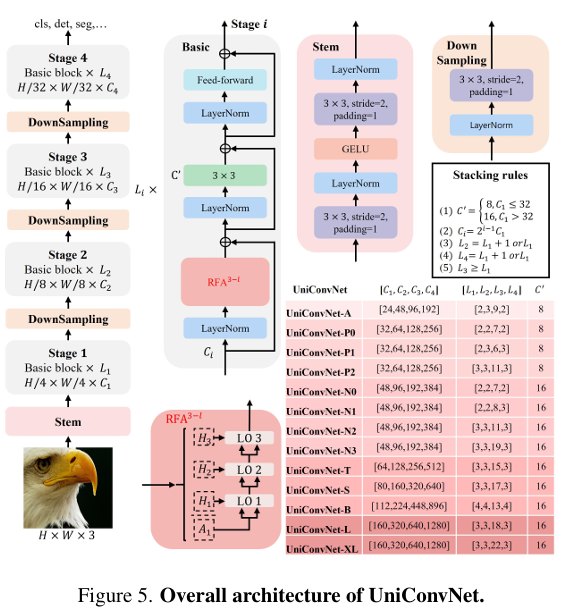
方法
- 整体架构:基于三层RFA模块构建UniConvNet。对于224x224的输入,RFA将输入通道分为4份(N+1=4)。
- 数据流:
- 第一阶段:处理第一份通道,通过7x7卷积提取上下文,并与第二份通道交互,输出通道数为C/2。
- 第二阶段:将上一阶段的输出与第三份通道交互,通过9x9卷积进一步扩大感受野,输出通道数为3C/4。
- 第三阶段:将上一阶段的输出与第四份通道交互,通过11x11卷积最终扩大感受野,并恢复到完整的C通道。
- 核心机制:
- 通道划分与金字塔增量:输入通道被划分,中间特征的通道数呈金字塔式递增,有助于降低计算成本。
- 门控调制:在每个阶段,使用一个分支生成门控权重,对上下文特征进行调制,以突出重要信息。
- 残差注入:在处理每个新的“四分块”时,会注入来自上下文分支的信息,形成残差连接,增强信息流动。
代码
import torch
import torch.nn as nn
import torch.nn.functional as Fclass LayerNorm(nn.Module):"""支持 channels_first ([N, C, H, W]) 和 channels_last ([N, H, W, C]) 两种格式的 LayerNorm。"""def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):super().__init__()# 可学习的缩放参数 γ 和偏移参数 βself.gamma = nn.Parameter(torch.ones(normalized_shape))self.beta = nn.Parameter(torch.zeros(normalized_shape))self.eps = epsself.channel_format = data_formatif self.channel_format not in ["channels_last", "channels_first"]:raise NotImplementedError("仅支持 'channels_last' 或 'channels_first'")# 用于 F.layer_norm 的 normalized_shape 必须是 tupleself.normalized_shape = (normalized_shape,)def forward(self, x):if self.channel_format == "channels_last":# 使用 PyTorch 内置的 layer_norm(适用于 [N, H, W, C])return F.layer_norm(x, self.normalized_shape, self.gamma, self.beta, self.eps)else:# 手动实现 channels_first 的 LayerNorm([N, C, H, W])# 在通道维度(dim=1)上计算均值和方差chan_mean = x.mean(dim=1, keepdim=True) # [N, 1, H, W]chan_var = (x - chan_mean).pow(2).mean(dim=1, keepdim=True) # [N, 1, H, W]# 归一化x_norm = (x - chan_mean) / torch.sqrt(chan_var + self.eps)# 应用可学习参数:γ 和 β 需要扩展到 [C, 1, 1] 以匹配 [N, C, H, W]return self.gamma[:, None, None] * x_norm + self.beta[:, None, None]class MRFA(nn.Module):"""多阶段感受野聚合模块(Multi-stage Receptive Field Aggregation)。将输入通道划分为 4 个等份(quarters),分阶段逐步融合上下文信息,每一阶段使用更大的卷积核(7x7 → 9x9 → 11x11)扩大感受野,并通过门控机制调制特征,最终恢复原始通道数。"""def __init__(self, dim):super().__init__()self.channels_total = dim # 输入通道总数 C# ========== 第一阶段:处理前 1/4 通道,输出 C/2 = C/4 + C/4 ==========self.ln_stage1 = LayerNorm(dim, eps=1e-6, data_format="channels_first")# 上下文分支:对第一个四分块进行 1x1 升维 + GELU + 7x7 深度卷积(扩大感受野)self.ctx_branch_s1 = nn.Sequential(nn.Conv2d(dim // 4, dim // 4, kernel_size=1),nn.GELU(),nn.Conv2d(dim // 4, dim // 4, kernel_size=7, padding=3, groups=dim // 4))# 门控分支:生成与上下文特征同尺寸的门控权重(逐通道调制)self.gate_branch_s1 = nn.Conv2d(dim // 4, dim // 4, kernel_size=1)# 门控后线性投影(无激活)self.post_gate_s1 = nn.Conv2d(dim // 4, dim // 4, kernel_size=1)# 对第二个四分块进行预处理和 3x3 深度卷积细化self.prep_quarter2 = nn.Conv2d(dim // 4, dim // 4, kernel_size=1)self.refine3x3_s1 = nn.Conv2d(dim // 4, dim // 4, kernel_size=3, padding=1, groups=dim // 4)# ========== 第二阶段:融合前两个四分块 + 第三个四分块,输出 3C/4 = C/4 + C/2 ==========self.ln_stage2 = LayerNorm(dim // 2, eps=1e-6, data_format="channels_first")self.ctx_branch_s2 = nn.Sequential(nn.Conv2d(dim // 2, dim // 2, kernel_size=1),nn.GELU(),nn.Conv2d(dim // 2, dim // 2, kernel_size=9, padding=4, groups=dim // 2))self.gate_branch_s2 = nn.Conv2d(dim // 2, dim // 2, kernel_size=1)self.post_gate_s2 = nn.Conv2d(dim // 2, dim // 2, kernel_size=1)# 对第三个四分块进行预处理和细化self.prep_quarter3 = nn.Conv2d(dim // 4, dim // 4, kernel_size=1)self.refine3x3_s2 = nn.Conv2d(dim // 4, dim // 4, kernel_size=3, padding=1, groups=dim // 4)# 将第二阶段的上下文特征(C/2)投影到 C/4,以便与第三个四分块相加self.proj_ctx_to_q3 = nn.Conv2d(dim // 2, dim // 4, kernel_size=1)# ========== 第三阶段:融合前三部分 + 第四个四分块,输出完整 C 通道 ==========self.ln_stage3 = LayerNorm(dim * 3 // 4, eps=1e-6, data_format="channels_first")self.ctx_branch_s3 = nn.Sequential(nn.Conv2d(dim * 3 // 4, dim * 3 // 4, kernel_size=1),nn.GELU(),nn.Conv2d(dim * 3 // 4, dim * 3 // 4, kernel_size=11, padding=5, groups=dim * 3 // 4))self.gate_branch_s3 = nn.Conv2d(dim * 3 // 4, dim * 3 // 4, kernel_size=1)self.post_gate_s3 = nn.Conv2d(dim * 3 // 4, dim * 3 // 4, kernel_size=1)# 对第四个四分块进行预处理和细化self.prep_quarter4 = nn.Conv2d(dim // 4, dim // 4, kernel_size=1)self.refine3x3_s3 = nn.Conv2d(dim // 4, dim // 4, kernel_size=3, padding=1, groups=dim // 4)# 将第三阶段的上下文特征(3C/4)投影到 C/4,以便与第四个四分块相加self.proj_ctx_to_q4 = nn.Conv2d(dim * 3 // 4, dim // 4, kernel_size=1)def forward(self, x):# 第一阶段归一化x = self.ln_stage1(x)# 将输入通道均分为 4 份,每份 C/4quarters = torch.split(x, self.channels_total // 4, dim=1) # [B, C/4, H, W] × 4# ---------------- 第一阶段:融合 quarters[0] 和 quarters[1] ----------------# 上下文特征:从 quarters[0] 提取大感受野信息ctx_feat = self.ctx_branch_s1(quarters[0])# 门控调制:用 quarters[0] 生成门控权重,调制 ctx_featgated_feat = ctx_feat * self.gate_branch_s1(quarters[0])gated_feat = self.post_gate_s1(gated_feat)# 处理 quarters[1]:先 1x1 卷积,再 3x3 深度卷积细化,并加上原始 ctx_feat(残差)s1_q2 = self.refine3x3_s1(self.prep_quarter2(quarters[1]))s1_q2 = s1_q2 + ctx_feat# 拼接:细化后的 q2 + 门控调制特征 → C/2s1_out = torch.cat((s1_q2, gated_feat), dim=1)# ---------------- 第二阶段:引入 quarters[2] ----------------s1_out = self.ln_stage2(s1_out)# 从 C/2 特征中提取更大感受野(9x9)上下文ctx_feat = self.ctx_branch_s2(s1_out)gated_feat = ctx_feat * self.gate_branch_s2(s1_out)gated_feat = self.post_gate_s2(gated_feat)# 处理 quarters[2]s2_q3 = self.refine3x3_s2(self.prep_quarter3(quarters[2]))# 将 ctx_feat 投影到 C/4 后与 q3 相加s2_q3 = s2_q3 + self.proj_ctx_to_q3(ctx_feat)# 拼接:q3 + 门控特征(C/2)→ 3C/4s2_out = torch.cat((s2_q3, gated_feat), dim=1)# ---------------- 第三阶段:引入 quarters[3] ----------------s2_out = self.ln_stage3(s2_out)# 从 3C/4 特征中提取最大感受野(11x11)上下文ctx_feat = self.ctx_branch_s3(s2_out)gated_feat = ctx_feat * self.gate_branch_s3(s2_out)gated_feat = self.post_gate_s3(gated_feat)# 处理 quarters[3]s3_q4 = self.refine3x3_s3(self.prep_quarter4(quarters[3]))s3_q4 = s3_q4 + self.proj_ctx_to_q4(ctx_feat)# 拼接:q4 + 门控特征(3C/4)→ 完整 C 通道s3_out = torch.cat((s3_q4, gated_feat), dim=1)return s3_out# 测试代码
if __name__ == '__main__':input = torch.randn(1, 32, 64, 64) # [B, C=32, H=64, W=64]model = MRFA(dim=32)output = model(input)print("输入张量形状:", input.shape)print("输出张量形状:", output.shape)
效果
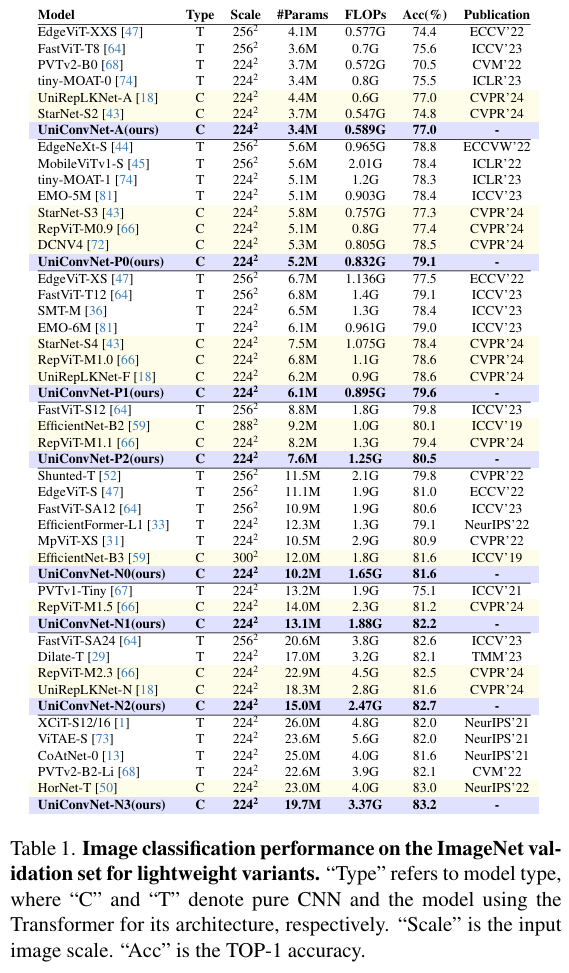
论文在ImageNet-1K、COCO2017和ADE20K等多个基准数据集上进行了大量实验,结果表明:
- 图像分类:UniConvNet在轻量级和大规模模型上均取得了SOTA性能。例如,UniConvNet-T(30M参数,5.1G FLOPs)在ImageNet上达到了**84.2%的Top-1准确率;UniConvNet-XL更是达到了88.4%**的惊人准确率。
- 下游任务:在目标检测、实例分割和语义分割等任务上,UniConvNet同样大幅领先于当前最先进的CNN和ViT模型。
- 效率与吞吐量:在取得卓越性能的同时,UniConvNet的参数量、FLOPs和吞吐量与同类模型相当甚至更优,证明了其设计的高效性。
总结
该论文通过深入分析有效感受野(ERF)的分布特性,指出了当前大核ConvNets的局限性,并创新性地提出了感受野聚合器(RFA)这一模块。RFA通过分阶段、渐进式地融合多尺度上下文信息,在显著扩展ERF的同时,成功保持了其符合人类直觉的渐近高斯分布(AGD)。基于此构建的UniConvNet模型,无论是在轻量级还是超大规模场景下,都在多项视觉任务上实现了性能突破,为未来ConvNet的设计提供了一个强大且高效的通用范式。这项工作强调了感受野的质量(分布)与大小同等重要,为卷积网络的研究开辟了新的方向。