蚂蚁开源高性能扩散语言模型框架dInfe,推理速度提升十倍
目录
前言
一、扩散模型的“理论翅膀”与“现实枷锁”
二、dInfer如何解开“枷锁”?
2.1 给“短期记忆”一个“好邻居”策略
2.2 让“并行生成”更聪明、更有序
2.3 压榨每一滴性能:系统级的极致优化
三、里程碑式的数据:从理论到现实的飞跃
结语:一个新范式的黎明

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 蚂蚁开源高性能扩散语言模型框架dInfe
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
一直以来,无论我们使用多么先进的AI聊天机器人或写作助手,其背后都有一个共同的工作模式,就像一个一丝不苟的作者在写文章:必须先写下第一个字,然后看着第一个字写第二个,再看着前两个字写第三个……这个过程被称为“自回归”(Autoregressive,AR),它是我们熟知的所有主流大语言模型(如GPT系列、文心一言等)的核心工作原理。
这种“逐字生成”的模式虽然可靠,但也带来了一个天生的瓶颈:速度。无论你的计算机硬件(GPU)并行计算能力有多强,在这条“单行道”上都施展不开拳脚,推理速度的上限被锁得死死的。
然而,在AI研究领域,一直存在着另一种截然不同的思路——“扩散模型”(Diffusion Model)。它的工作方式更像一位修复老照片的艺术家,从一幅完全被噪声覆盖的图像开始,一点点地擦除噪声,最终恢复出清晰的全貌。如果用这种方式生成文本,就相当于从一堆随机的词语开始,一步步迭代,将它们“去噪”成一句通顺、连贯的话。
理论上,这种模式优势巨大:
(1)天生并行:它可以一次性预测和更新句子里的多个词,而不是一个一个来。
(2)全局视野:它的每一步决策都基于对整句话“草稿”的全局理解,而非仅仅依赖已生成的部分。
但多年来,扩散语言模型的这些优势仅仅停留在“理论上很美”。一到实际运行,它就因为种种技术难题,变得异常缓慢和昂贵,其并行生成的潜力沦为“纸上谈兵”。
直到近日,蚂蚁集团开源了业界首个高性能扩散语言模型推理框架——`dInfer`。它通过一系列巧妙的算法和系统优化,一举攻克了扩散模型的推理瓶颈,不仅将推理速度提升了10倍以上,更在最考验性能的单批次推理场景下,历史性地超越了那些被优化到极致的自回归模型。这或许意味着,AI生成内容的方式,真的要从“逐字蹦”进化到“一目十行”了。

一、扩散模型的“理论翅膀”与“现实枷锁”
为什么一个理论上更快的模型,在现实中却跑不快?这主要源于三大“枷锁”:
(1)高昂的计算成本:多步迭代“去噪”的特性,意味着模型需要反复对整个文本序列进行计算,这带来了巨大的算力开销。
(2)关键加速技术“KV缓存”的失效:自回归模型有一个重要的加速“法宝”叫KV缓存。你可以把它理解成模型的“短期记忆”,它会把注意力计算的中间结果存起来,下次就不用重复计算了。但在扩散模型中,由于每一步迭代都会改变所有词语的上下文表示,这个“短期记忆”会立刻“过时”,导致这个强大的加速技术完全失效。
(3)并行生成的“双刃剑”:虽然理论上可以同时生成所有词,但这些“同时出生”的词彼此之间并不知道对方是什么,很容易产生语义上的冲突和矛盾,导致“并行越多,质量越差”的尴尬局面。
正是这三大难题,让扩散语言模型长期被困在实验室里。
二、dInfer如何解开“枷锁”?
蚂蚁的`dInfer`框架,就像一个精密的工具箱,针对上述三大难题,逐一给出了创新的解决方案。
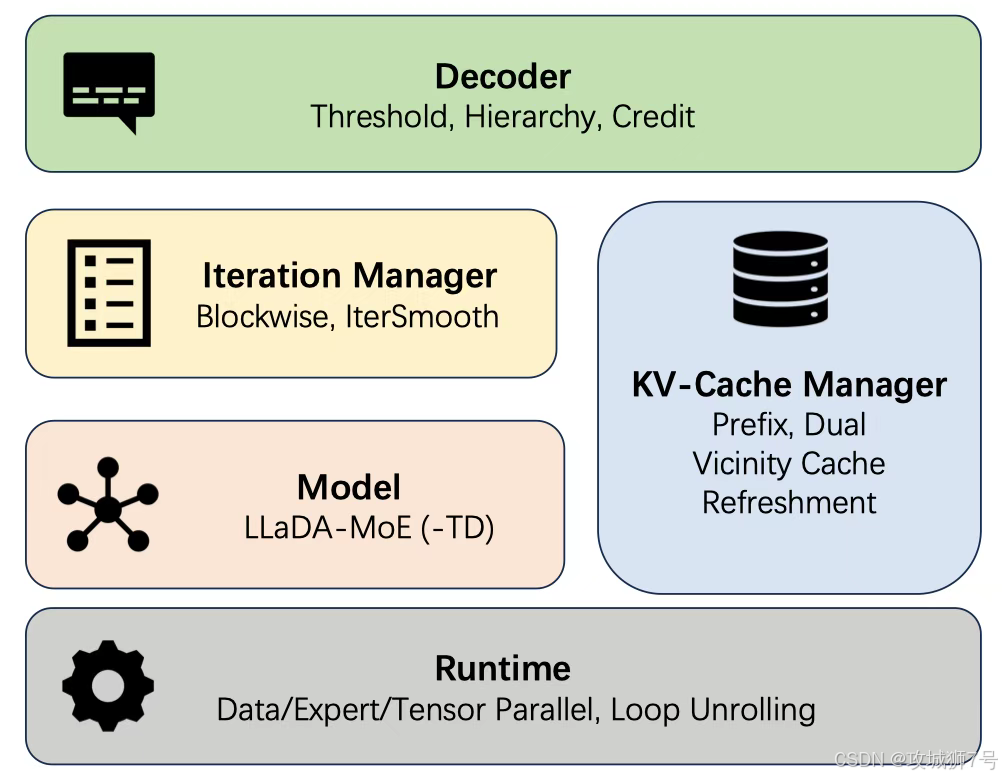
2.1 给“短期记忆”一个“好邻居”策略
为了让KV缓存重新生效,`dInfer`提出了一个非常符合直觉的方案:“邻近KV缓存刷新”(Vicinity KV-Cache Refresh)。
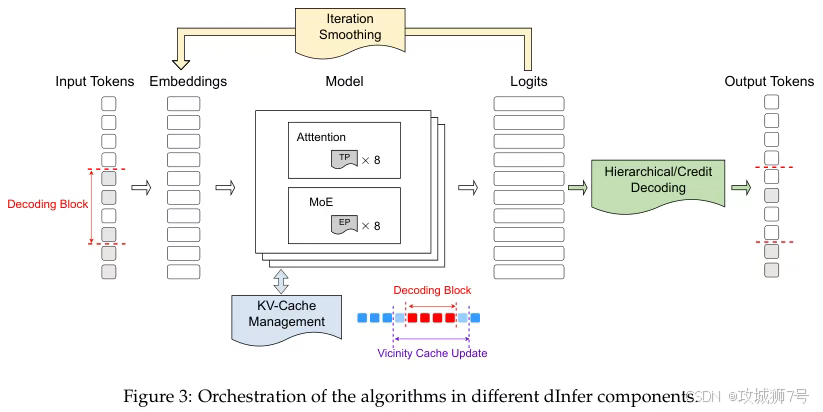
它的核心思想是“语义局部性”:一个词语的改变,对它旁边几个词的影响最大,对远处词语的影响则很小。所以,当`dInfer`解码一小块区域时,它只选择性地重新计算这一块区域及其附近一小圈“邻居”的KV状态,而让远处的缓存保持不变。
这就像你修改文档里的一句话,只需要检查一下上下文是否通顺,没必要把整篇文章从头到尾再读一遍。这个看似简单的策略,漂亮地在计算成本和模型性能之间取得了平衡,首次让KV缓存机制在扩散模型上高效、可靠地运作起来。
2.2 让“并行生成”更聪明、更有序
为了解决并行生成容易“翻车”的问题,`dInfer`拿出了两套全新的解码算法:
(1)层级解码 (Hierarchical Decoding):这个方法借鉴了“分而治之”的思想。它先把要生成的区域一分为二,在每个子区域的中心位置先解码一个词。这样一来,新生成的词在空间上就自然分开了,互相干扰的可能性大大降低。然后,它再递归地对更小的子区域进行同样的操作。这种方式既快又稳,能以近似对数级的复杂度完成多点并行生成。
(2)信用解码 (Credit Decoding):这个想法更进一步。它给每个可能的候选词都设立了一个“信用分”。如果在连续好几轮的迭代中,模型都坚定不移地认为某个位置应该是这个词,那么这个词的“信用分”就会越来越高。在最终做决定时,信用分高的词享有优先权。这有效避免了模型在几个候选词之间摇摆不定,增强了生成结果的稳定性。
2.3 压榨每一滴性能:系统级的极致优化
除了算法上的创新,`dInfer`在系统层面也把优化做到了极致。它通过多卡并行技术(张量并行与专家并行)将计算任务完美分摊,通过编译器优化消除框架自身的开销,通过“循环展开”等技术让GPU“忙得没有一丝喘息之机”,并通过“早停机制”避免在生成结束符后还进行多余的计算。这些看似微小的优化,积少成多,共同将推理速度推向了新的高度。

三、里程碑式的数据:从理论到现实的飞跃
在配备8块NVIDIA H800 GPU的服务器上,`dInfer`的性能表现令人瞩目:
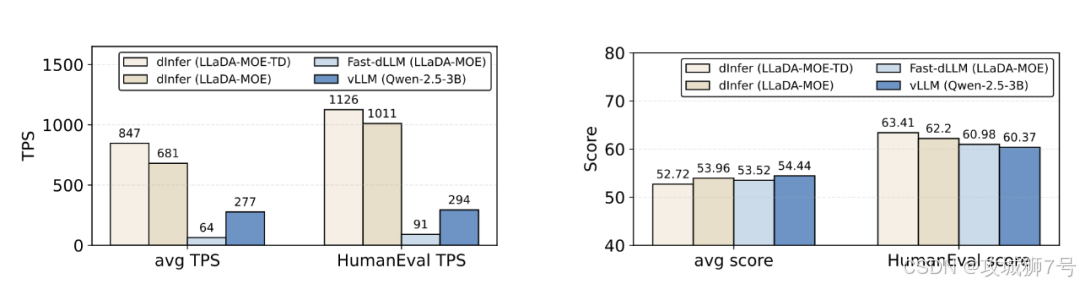
(1)10倍性能提升:与先前的扩散模型推理方案`Fast-dLLM`相比,`dInfer`在模型效果持平的情况下,平均推理速度实现了10.7倍的巨大提升。
(2)超越自回归模型:与在业界顶尖推理框架`vLLM`上运行的、性能相当的自回归模型`Qwen2.5-3B`相比,`dInfer`的平均推理速度是其2.5倍。
(3)突破推理极速:在代码生成任务`HumanEval`上,`dInfer`在单批次推理中创造了1011 tokens/秒的惊人纪录。这是开源社区首次见证,扩散语言模型在延迟最敏感的单批次场景下,速度显著超越了经过高度优化的自回归模型。
更进一步,当结合了“轨迹蒸馏”(一种让模型学会“跳跃式”去噪的后训练优化方法)后,`dInfer`的平均推理速度更是达到了自回归模型的3倍以上。
结语:一个新范式的黎明
`dInfer`的诞生和开源,其意义远不止一个工具的发布。它更像一次对AI语言模型范式的成功试炼:它用无可辩驳的数据证明,扩散语言模型的效率潜力并非空中楼阁,而是可以通过系统性的创新工程来兑现,使其成为通往通用人工智能(AGI)道路上一个极具竞争力的选项。
随着推理速度这一最大的“枷锁”被解开,扩散模型与生俱来的并行生成和全局视野优势,将可以在更复杂的任务中得到释放,例如高质量的代码生成、多模态内容的理解与创作等。
蚂蚁集团将`dInfer`完全开源,为全球的研究者和开发者提供了一个公平、高效的试验场和加速引擎。这标志着扩散语言模型从“理论可行”正式迈向“实践高效”,我们或许正站在一个全新AI范式爆发的前夜。
论文链接: https://arxiv.org/abs/2510.08666
项目地址: https://github.com/inclusionAI/dInfer
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!