transformer结构
文章目录
- 前言
- 一、transformer结构
- 1.1 模型输入
- Tokenizer(分词/令牌化)
- Embedding(词嵌入)
- Positional Encoding(位置编码,PE)
- 1.2 编码器-解码器结构
- 注意力机制
- 编码器
- 解码器
- 1.3 模型输出
- 总结
前言
序列建模是自然语言处理(NLP)、语音识别、时间序列预测等领域的核心任务,其目标是学习输入序列(如一句话)中元素之间的依赖关系,并据此生成输出(如下一句话、翻译结果等)。其核心特点是:当前输出不仅依赖当前输入,还依赖历史输入(或未来输入)。
下图为seq2seq形式的序列建模任务
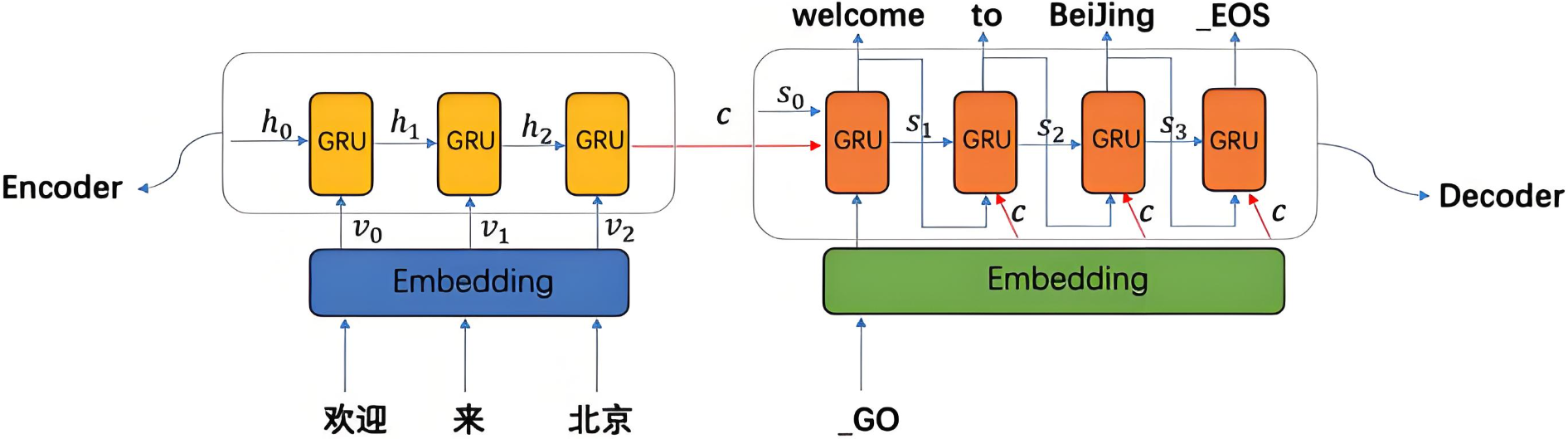
在 Transformer 出现之前,循环神经网络(RNN)及其变体(如 LSTM、GRU)是处理序列建模任务的主流方法。它们通过“循环”结构逐个处理序列中的元素,并维护一个隐藏状态来传递历史信息。
然而,RNN 类模型存在两个关键瓶颈:
- 无法有效建模长距离依赖:由于信息需要一步步传递,当序列很长时,早期信息在传递过程中会逐渐衰减甚至消失(即“梯度消失”问题),导致模型难以捕捉远距离词之间的语义关系。
- 无法并行计算:RNN 必须按顺序处理序列中的每个元素,这严重限制了训练速度,尤其是在处理长序列或大规模数据集时。
- 信息瓶颈:编码器会将整个输入序列压缩为一个固定长度的向量,可能导致信息丢失,灵活度太低。
在这样的背景下,Transformer 模型于 2017 年横空出世,其论文《Attention Is All You Need》提出了一种完全基于自注意力机制的架构,彻底摒弃了循环结构,从根本上解决了上述问题。
一、transformer结构
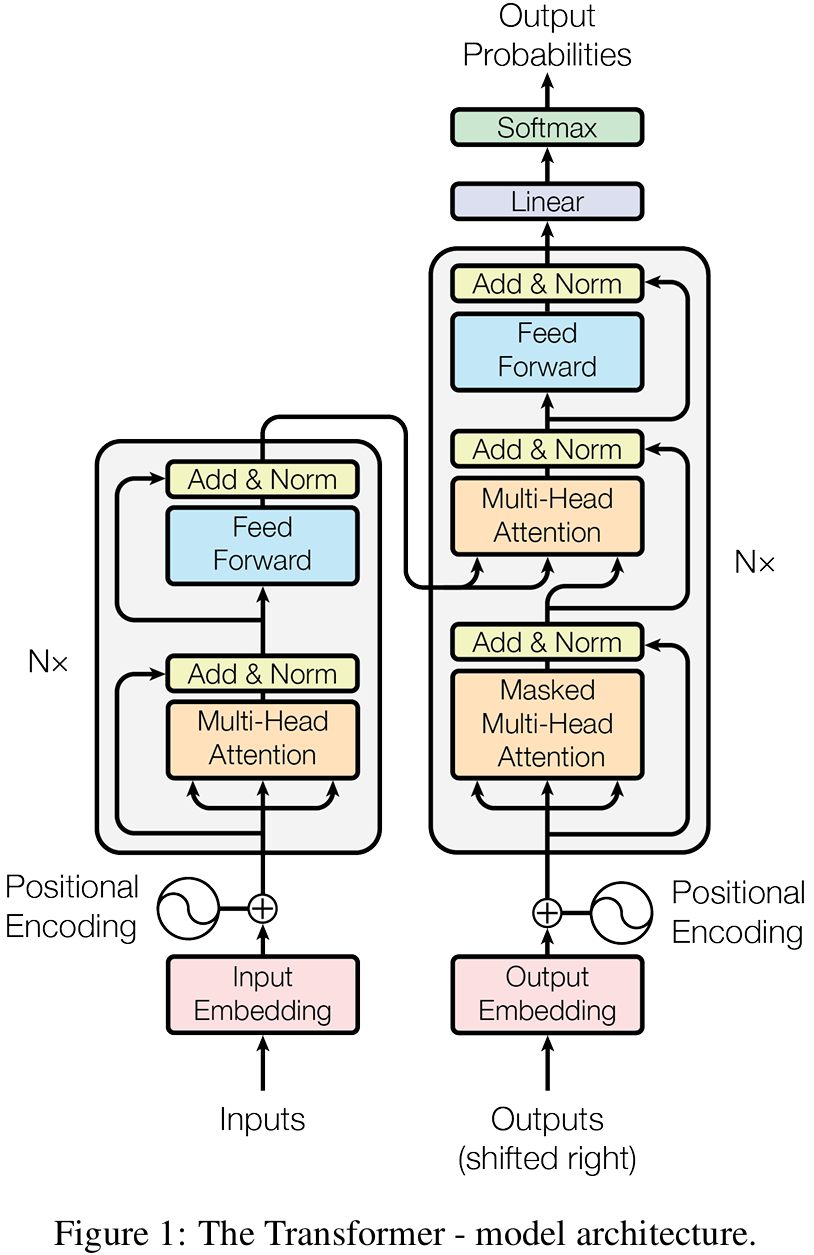
1.1 模型输入
输入部分的目标是:将原始的文本序列(一串字符)转换为富含语义和位置信息的数值化表示(一个向量序列),以便后续的编码器进行处理。
整个过程可以分为三个主要步骤,我们以一个例句 “I love you.” 为例来讲解。
Tokenizer(分词/令牌化)
由于模型无法直接理解单词,它只能处理数字。所以我们需要先将句子拆分成更小的单位,然后再将其映射为数字。
Tokenizer的实现通常按粒度可分为三大类:Word-based、Character-based、Subword-based。其中Word-based(词级)与Character-based (字符级)常用于早期 RNN/LSTM,而Subword-based(子词级)成为了当前最主流、最有效的分词方法,它完美地权衡了词级和字符级的优缺点。
常用的算法有:BPE(Byte-Pair Encoding)、BBPE、WordPiece、Unigram LM、SentencePiece等。
| Subword 分词方法 | 典型模型 |
|---|---|
| BPE/BBPE | GPT, DeepSeek, GPT-2, GPT-Neo, RoBERTa, LLaMA |
| WordPiece | BERT, DistilBERT, MobileBERT |
| Unigram | AIBERT, T5, mBART, XLNet |
模型内部有一个词表,这是一个巨大的映射表,包含了所有它“认识”的 token。分词器将每个 token 映射到其在词表中的唯一 ID。我们的句子变成了一个 ID 序列:[101, 1045, 2293, 2017, 119, 102]。
Embedding(词嵌入)
ID 本身没有意义,例如1045 和 1046 在数值上接近,但代表的词可能毫无关联。我们需要一种方式让模型知道“king”和“queen”的语义关系比“king”和“apple”更近。所以我们需要将每个 token 的 ID转换为一个连续、稠密的向量,这个向量能够在高维空间中表示该 token 的语义信息。
在模型内部,有一个可学习的矩阵,称为 Embedding 矩阵,其维度为 (词表大小V,
嵌入维度dmodeld_{model}dmodel)。dmodeld_{model}dmodel 是 Transformer 模型的一个关键超参数(例如 512、768等),它定义了每个 token 表示的向量长度。
查找过程:Embedding 层实际上是一个查找表。对于 ID 为 iii 的 token,我们就在 Embedding 矩阵中找到第 iii 行,然后将这一行向量拿出来,作为该 token 的嵌入向量。例如:输入一个长度为 L 的 ID 序列 [101, 1045, 2293, 2017, 119, 102],则输出一个形状为 (L, dmodeld_{model}dmodel) 的矩阵。其中每一行都是一个 token 的向量表示。
Positional Encoding(位置编码,PE)
此时,我们已经有了词的语义表示,但由于模型同时处理所有 token,例如,输入的“我欠张三100块”和“张三欠我100块”在此时并无区别。故此时我们还缺少一个关键信息:顺序。因此,我们需要为输入序列中的每个 token 注入其位置信息。 生成一个与 Token Embedding 维度相同(dmodeld_{model}dmodel)的位置编码向量,然后直接与 Embedding 后的 Token 相加,即最终输入 = Token Embedding + Positional Encoding。
原论文使用了一组固定的、由正弦和余弦函数生成的编码。对于在序列中位置为 pos 的 token,其位置编码向量的第 iii 个维度(iii是维度索引,从0到dmodeld_{model}dmodel-1)的值计算如下: PE(pos,2i)=sin(pos100002i/dmodel),PE(pos,2i+1)=cos(pos100002i/dmodel)\text{PE}_{(\text{pos}, 2i)} = \sin\left( \frac{\text{pos}}{10000^{2i / d_{\text{model}}}} \right), \quad \text{PE}_{(\text{pos}, 2i+1)} = \cos\left( \frac{\text{pos}}{10000^{2i / d_{\text{model}}}} \right)PE(pos,2i)=sin(100002i/dmodelpos),PE(pos,2i+1)=cos(100002i/dmodelpos)
这个设计的精妙之处在于:
- 唯一性:每个位置都有独一无二的编码。
- 泛化到更长序列:由于是三角函数,它甚至可以外推到在训练时从未见过的序列长度。
1.2 编码器-解码器结构
注意力机制
tranformer的是缩放点积注意力,公式为Attention(Q,K,V)=softmax(QK⊤dk)V\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^\top}{\sqrt{d_k}} \right) VAttention(Q,K,V)=softmax(dkQK⊤)V。
为什么要点积而非加性注意力?
- 矩阵乘法非常适合 GPU 并行计算,计算效率高。
为什么要缩放?
- 当维度dkd_{k}dk很大时,点积的结果可能非常大,这将 Softmax 函数推入梯度极小的区域,导致梯度消失问题。除以dk\sqrt{d_k}dk可以缓解这个问题,使训练更稳定。

只使用一个注意力头,模型可能只学到一种固定的关系模式。可以使用多组不同的 Q、K、V 投影矩阵,让模型在不同的表示子空间中学习不同的关系。
多头自注意力机制不代表将输入切成多份,而是将注意力机制应用多次,虽然每次输入相同,但期望模型从中学到不同关系模式,最终将各头的输出拼接并线性变换,以增强模型的表达能力。
公式:
MultiHead(Q,K,V)=Concat(head1,…,headh)WOwhereheadi=Attention(QWiQ,KWiK,VWiV)\begin{aligned} \text{MultiHead}(Q, K, V) &= \text{Concat}(\text{head}_1, \dots, \text{head}_h) W^O \\ \text{where} \quad \text{head}_i &= \text{Attention}(Q W_i^Q, K W_i^K, V W_i^V) \end{aligned}MultiHead(Q,K,V)whereheadi=Concat(head1,…,headh)WO=Attention(QWiQ,KWiK,VWiV)
编码器
编码器包含两个关键子层,即多头自注意力加上前馈神经网络(一个简单的两层网络,中间有一个 ReLU 激活函数)。具体来讲就是将输入适用多头自注意力后,将其输出与原本输入相加作残差链接后进行层归一化,然后再输入前馈神经网络。这就是一个编码器的完整流程

公式:
X1=LayerNorm(MultiHeadSelfAttention(Xinput)+Xinput)Output1=LayerNorm(FFN(X1)+X1)\begin{aligned} \mathbf{X}_1 &= \mathrm{LayerNorm}\left( \mathrm{MultiHeadSelfAttention}(\mathbf{X}_{\text{input}}) + \mathbf{X}_{\text{input}} \right) \\ \mathbf{Output}_1 &= \mathrm{LayerNorm}\left( \mathrm{FFN}(\mathbf{X}_1) + \mathbf{X}_1 \right) \end{aligned}X1Output1=LayerNorm(MultiHeadSelfAttention(Xinput)+Xinput)=LayerNorm(FFN(X1)+X1)
解码器
解码器与编码器大体相似,但是包含以下三个关键子层:
- 掩码多头自注意力
相较于编码器的多头自注意力,新增了Mask(掩码)。先Mask,后通过 softmaxsoftmaxsoftmax 得到归一化的注意力权重。
掩码确保在计算位置 iii 的注意力时,模型只能"看到"位置 1 到 iii 的 token,而不能看到位置 i+1i+1i+1 及之后的 token。如果没有掩码,解码器在预测第 i 个位置时,会"看到"整个目标序列,包括未来的token。这会造成信息泄露,使模型在训练时表现良好,但在推理时表现糟糕。

Z=softmax(QKTdq+M)VM∈Rn×nZ = \text{softmax}\left( \frac{Q K^T}{\sqrt{d_q}} + M \right) V \\ M \in \mathbb{R}^{n \times n}Z=softmax(dqQKT+M)VM∈Rn×n
其中Mask矩阵是一个 L×LL\times LL×L 的上三角矩阵(L为序列长度),数学表示如下:
Mij={0,if i≥j−∞,if i<jM_{ij} = \begin{cases} 0, & \text{if } i \geq j \\ -\infty, & \text{if } i < j \end{cases}Mij={0,−∞,if i≥jif i<j
其中:
- Mij=0当i≥jM_{ij} = 0 \quad 当 i \geq jMij=0当i≥j,即当前位置 iii 可以看到自己及之前的所有位置。
- Mij=−∞当i<jM_{ij} = -\infty \quad 当i < jMij=−∞当i<j,即当前位置 iii 不允许看到未来的任何位置。
- 多头交叉注意力
这是连接编码器和解码器的桥梁,也是解码器最重要的组成部分之一。作用为让解码器在生成每个目标 token 时,能够有选择地"关注"源序列中相关的部分。相较于普通的多头自注意力,其主要不同之处在于使用不同来源的Q、K、V。
查询(Q):来自解码器上一层的输出(即掩码自注意力层的输出)。这代表"解码器当前想要生成什么"。
键(K)和值(V):来自编码器的最终输出。这代表"源序列提供了什么信息"。

- 前馈神经网络
与编码器中的前馈网络完全相同,这里不再赘述。
1.3 模型输出
使用一个简单的全连接层,用于将隐藏状态的维度从 dmodeld_{model}dmodel 投影到词表大小 vocabsizevocabsizevocabsize,其形状 [dmodeld_{model}dmodel , vocabsizevocabsizevocabsize]。
映射后得到形如[batchbatchbatch, LLL, vocabsizevocabsizevocabsize]的logits矩阵,其中每个位置对词表中每个词的"原始分数"或"未归一化的置信度"。
然后使用 Softmax 将 logits 转换为概率分布,使得所有词的概率之和为 1。在生成时,我们只关心当前要生成的位置的概率分布 如果已经生成了 n 个 token,我们只取第 n+1 个位置的概率分布。
如何从概率分布中选择下一个 token:
- 贪婪搜索: 直接选择概率最高的 token。
- 束搜索: 在每一步保留 k 个最有可能的候选序列,可以利用贝叶斯计算序列概率。
- 采样策略:
- 随机采样:根据概率分布随机选择下一个 token。
- Top-k 采样:只从概率最高的 k 个 token 中采样。 Top-p 采样:从累积概率达到 p 的最小 token 集合中采样。
总结
本文主要讲解了transformer论文中的模型结构。