RocketMQ 生产环境性能调优实战:从 0 到 1 打造高可用消息队列系统
引言
在分布式系统架构中,消息队列作为解耦、削峰、异步通信的核心组件,其性能和稳定性直接影响整个系统的可用性。RocketMQ 作为阿里开源的分布式消息中间件,凭借其高吞吐、低延迟、高可靠的特性,已成为众多企业级应用的首选。然而,默认配置的 RocketMQ 在生产环境中往往难以发挥最佳性能,需要进行系统性的优化。
本文将从生产者、消费者、Broker、存储、JVM 等多个维度,全面解析 RocketMQ 生产环境的优化策略,既有底层原理剖析,又有可直接落地的实战方案,帮助你构建一个高性能、高可用的 RocketMQ 集群。
一、生产者优化
生产者是消息的源头,其性能直接影响整个消息链路的效率。生产者优化的核心目标是提高消息发送吞吐量、降低延迟,并确保消息可靠投递。
1.1 异步发送优化
RocketMQ 提供同步、异步和单向三种发送方式。在高吞吐场景下,异步发送是首选,因为它不会阻塞当前线程,能极大提高发送效率。
import com.alibaba.fastjson2.JSON;
import com.google.common.collect.Maps;
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.client.producer.SendCallback;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.spring.core.RocketMQTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.util.ObjectUtils;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import java.util.Map;/*** 优化后的异步消息生产者** @author ken*/
@Slf4j
@RestController
@RequestMapping("/optimized-producer")
@Tag(name = "优化后的消息生产者接口", description = "采用异步发送模式提高吞吐量")
public class OptimizedProducerController {@Autowiredprivate RocketMQTemplate rocketMQTemplate;/*** 异步发送消息** @param message 消息内容*/@PostMapping("/async-send")@Operation(summary = "异步发送消息", description = "使用异步发送提高吞吐量,不阻塞主线程")public void asyncSendMessage(@RequestBody Map<String, Object> message) {if (ObjectUtils.isEmpty(message)) {log.error("消息内容不能为空");return;}String topic = "optimized_topic";// 使用异步发送,并指定回调函数处理发送结果rocketMQTemplate.asyncSend(topic, JSON.toJSONString(message), new SendCallback() {@Overridepublic void onSuccess(SendResult sendResult) {log.info("消息发送成功,消息ID: {}", sendResult.getMsgId());}@Overridepublic void onException(Throwable e) {log.error("消息发送失败", e);// 实现自定义重试逻辑handleSendFailure(topic, message, e);}});}/*** 处理消息发送失败的情况** @param topic 主题* @param message 消息内容* @param e 异常信息*/private void handleSendFailure(String topic, Map<String, Object> message, Throwable e) {// 这里可以实现更复杂的重试策略,如指数退避重试// 注意:避免无限重试导致消息风暴Map<String, Object> retryMessage = Maps.newHashMap();retryMessage.put("originalMessage", message);retryMessage.put("retryCount", 1);retryMessage.put("errorMsg", e.getMessage());// 发送到重试队列rocketMQTemplate.send("retry_topic", JSON.toJSONString(retryMessage));}
}
异步发送的底层原理是通过 Netty 的 NIO 通信模式,将消息发送请求放入 IO 线程池处理,主线程无需等待响应即可返回,从而提高了并发处理能力。
1.2 批量发送优化
对于高频小消息场景,批量发送能显著减少网络交互次数,提高吞吐量。RocketMQ 支持将多条消息打包成一个批量消息发送,但需要注意总大小不超过 4MB。
import com.alibaba.fastjson2.JSON;
import com.google.common.collect.Lists;
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.spring.core.RocketMQTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.util.CollectionUtils;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import java.util.List;
import java.util.Map;/*** 批量消息生产者** @author ken*/
@Slf4j
@RestController
@RequestMapping("/batch-producer")
@Tag(name = "批量消息生产者接口", description = "通过批量发送减少网络开销,提高吞吐量")
public class BatchProducerController {@Autowiredprivate RocketMQTemplate rocketMQTemplate;// 批量消息最大大小,默认不超过4MBprivate static final int BATCH_MAX_SIZE = 4 * 1024 * 1024;/*** 批量发送消息** @param messages 消息列表*/@PostMapping("/batch-send")@Operation(summary = "批量发送消息", description = "将多条消息打包发送,减少网络交互")public void batchSendMessages(@RequestBody List<Map<String, Object>> messages) {if (CollectionUtils.isEmpty(messages)) {log.error("消息列表不能为空");return;}String topic = "batch_topic";List<Message> messageList = Lists.newArrayList();for (Map<String, Object> msg : messages) {Message message = new Message(topic,JSON.toJSONString(msg).getBytes());messageList.add(message);}// 分割大批次为多个小批次List<List<Message>> batches = splitBatchMessages(messageList);for (List<Message> batch : batches) {SendResult sendResult = rocketMQTemplate.syncSend(topic, batch);log.info("批量消息发送成功,消息数量: {}, 消息ID: {}", batch.size(), sendResult.getMsgId());}}/*** 将消息列表分割为符合大小限制的批次** @param messages 消息列表* @return 分割后的消息批次列表*/private List<List<Message>> splitBatchMessages(List<Message> messages) {List<List<Message>> batches = Lists.newArrayList();List<Message> currentBatch = Lists.newArrayList();int currentSize = 0;for (Message message : messages) {int messageSize = message.getBody().length;// 如果当前消息大小超过单批最大限制,单独发送if (messageSize > BATCH_MAX_SIZE) {if (!currentBatch.isEmpty()) {batches.add(currentBatch);currentBatch = Lists.newArrayList();currentSize = 0;}batches.add(Lists.newArrayList(message));continue;}// 如果添加当前消息会超过限制,则先提交当前批次if (currentSize + messageSize > BATCH_MAX_SIZE) {batches.add(currentBatch);currentBatch = Lists.newArrayList();currentSize = 0;}currentBatch.add(message);currentSize += messageSize;}// 添加最后一个批次if (!currentBatch.isEmpty()) {batches.add(currentBatch);}return batches;}
}
批量发送的优化原理是减少网络往返次数。假设单条消息发送的网络开销是 1ms,发送 1000 条消息,逐条发送需要 1000ms,而批量发送可能只需要 10ms,效率提升显著。
1.3 生产者配置优化
合理配置生产者参数能显著提升性能,以下是关键配置项的优化建议:
rocketmq:producer:# 发送超时时间,根据网络情况调整,默认3000mssend-message-timeout: 5000# 同步发送失败重试次数,建议2-3次retry-times-when-send-failed: 2# 异步发送失败重试次数retry-times-when-send-async-failed: 2# 消息体压缩阈值,超过该大小则压缩,建议1024*1024(1MB)compress-message-body-threshold: 1048576# 最大消息大小,默认4MB,根据Broker配置调整max-message-size: 4194304# 客户端回调线程池大小,建议CPU核心数*2callback-executor-core-pool-size: 16# 启用VIP通道,生产环境建议关闭vip-channel-enabled: false
生产者配置优化的底层逻辑:
- 超时时间设置过短会导致正常网络波动下的误判,过长则会增加失败响应时间
- 重试次数过多可能导致消息重复,过少则降低成功率
- 压缩阈值设置合理能减少网络传输量,但压缩解压会消耗 CPU
1.4 消息重试机制优化
消息发送失败时,合理的重试策略能提高消息投递成功率,但需要避免无效重试导致的资源浪费。
import com.alibaba.fastjson2.JSON;
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.client.producer.SendCallback;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.spring.core.RocketMQTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.util.ObjectUtils;
import java.util.Map;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;/*** 带指数退避重试的消息发送器** @author ken*/
@Slf4j
@Component
public class ExponentialBackoffSender {@Autowiredprivate RocketMQTemplate rocketMQTemplate;// 最大重试次数private static final int MAX_RETRY_COUNT = 3;// 初始重试延迟时间(毫秒)private static final long INITIAL_RETRY_DELAY = 1000;private final Lock lock = new ReentrantLock();/*** 带指数退避策略的异步发送** @param topic 主题* @param message 消息内容*/public void sendWithBackoff(String topic, Map<String, Object> message) {if (ObjectUtils.isEmpty(message) || ObjectUtils.isEmpty(topic)) {log.error("主题或消息内容不能为空");return;}sendWithBackoff(topic, message, 0);}/*** 递归实现指数退避重试** @param topic 主题* @param message 消息内容* @param retryCount 当前重试次数*/private void sendWithBackoff(String topic, Map<String, Object> message, int retryCount) {if (retryCount >= MAX_RETRY_COUNT) {log.error("消息超过最大重试次数,消息内容: {}", JSON.toJSONString(message));// 发送到死信队列或进行人工处理saveToDeadLetterQueue(topic, message);return;}rocketMQTemplate.asyncSend(topic, JSON.toJSONString(message), new SendCallback() {@Overridepublic void onSuccess(SendResult sendResult) {log.info("消息发送成功,重试次数: {}, 消息ID: {}", retryCount, sendResult.getMsgId());}@Overridepublic void onException(Throwable e) {log.error("消息发送失败,准备重试,重试次数: {}", retryCount, e);// 计算指数退避延迟时间: 初始延迟 * (2^重试次数)long delay = INITIAL_RETRY_DELAY * (long) Math.pow(2, retryCount);// 使用定时任务进行重试rocketMQTemplate.getProducer().getDefaultMQProducerImpl().executeTaskLater(() -> {try {lock.lock();sendWithBackoff(topic, message, retryCount + 1);} finally {lock.unlock();}}, delay, TimeUnit.MILLISECONDS);}});}/*** 将无法发送的消息保存到死信队列** @param originalTopic 原主题* @param message 消息内容*/private void saveToDeadLetterQueue(String originalTopic, Map<String, Object> message) {String deadLetterTopic = "dead_letter_topic_" + originalTopic;rocketMQTemplate.send(deadLetterTopic, JSON.toJSONString(message));log.info("消息已保存到死信队列,队列名称: {}", deadLetterTopic);}
}
指数退避重试的优势在于:
- 避免短时间内大量重试导致的网络拥堵
- 给 Broker 恢复的时间窗口
- 通过逐渐增加重试间隔,平衡时效性和资源消耗
二、消费者优化
消费者是消息处理的终端,其优化重点在于提高消息处理吞吐量、减少消费延迟,并确保消息准确处理。
2.1 消费模式选择
RocketMQ 提供集群消费和广播消费两种模式。生产环境中,集群消费是主流选择,它能实现消息负载均衡,提高整体处理能力。
import com.alibaba.fastjson2.JSON;
import com.google.common.collect.Maps;
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.spring.annotation.RocketMQMessageListener;
import org.apache.rocketmq.spring.core.RocketMQListener;
import org.springframework.stereotype.Component;
import org.springframework.util.ObjectUtils;
import java.util.Map;/*** 集群模式消费者** @author ken*/
@Slf4j
@Component
@RocketMQMessageListener(topic = "optimized_topic",consumerGroup = "optimized_consumer_group",// 集群消费模式,消息会被 consumerGroup 内的一个消费者处理messageModel = MessageModel.CLUSTERING,// 消费模式:推模式consumeMode = ConsumeMode.CONCURRENTLY,// 消费线程池核心线程数consumeThreadMin = 10,// 消费线程池最大线程数consumeThreadMax = 20,// 批量消费最大消息数consumeMessageBatchMaxSize = 32
)
public class ClusteringConsumer implements RocketMQListener<String> {@Overridepublic void onMessage(String message) {if (ObjectUtils.isEmpty(message)) {log.error("接收到空消息");return;}try {Map<String, Object> msgMap = JSON.parseObject(message, Map.class);log.info("接收到消息,开始处理,消息内容: {}", msgMap);// 处理消息业务逻辑processMessage(msgMap);log.info("消息处理成功");} catch (Exception e) {log.error("消息处理失败", e);// 抛出异常,触发重试机制throw new RuntimeException("消息处理失败,需要重试", e);}}/*** 处理消息业务逻辑** @param message 消息内容*/private void processMessage(Map<String, Object> message) {// 实际业务处理逻辑// 例如:更新数据库、调用外部服务等try {// 模拟业务处理耗时Thread.sleep(100);} catch (InterruptedException e) {Thread.currentThread().interrupt();throw new RuntimeException("业务处理被中断", e);}}
}
两种消费模式的区别:
- 集群消费:同一条消息只会被消费组内的一个消费者消费,适合负载均衡场景
- 广播消费:同一条消息会被消费组内的所有消费者消费,适合通知类场景
2.2 并发消费优化
通过合理配置消费线程池和批量消费参数,能显著提高消费吞吐量。
import com.alibaba.fastjson2.JSON;
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.spring.annotation.RocketMQMessageListener;
import org.apache.rocketmq.spring.core.RocketMQListener;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import java.util.List;
import java.util.Map;/*** 批量并发消费者** @author ken*/
@Slf4j
@Component
@RocketMQMessageListener(topic = "batch_topic",consumerGroup = "batch_consumer_group",messageModel = MessageModel.CLUSTERING,// 并发消费模式consumeMode = ConsumeMode.CONCURRENTLY,// 消费线程池参数优化consumeThreadMin = 20,consumeThreadMax = 50,// 批量消费大小,根据消息处理耗时调整consumeMessageBatchMaxSize = 64,// 消费超时时间,单位分钟consumeTimeout = 15
)
public class BatchConsumer implements RocketMQListener<List<String>> {@Overridepublic void onMessage(List<String> messages) {if (CollectionUtils.isEmpty(messages)) {log.error("接收到空的消息列表");return;}log.info("接收到批量消息,数量: {}", messages.size());try {// 批量处理消息batchProcessMessages(messages);log.info("批量消息处理成功");} catch (Exception e) {log.error("批量消息处理失败", e);// 抛出异常,触发重试throw new RuntimeException("批量消息处理失败,需要重试", e);}}/*** 批量处理消息** @param messages 消息列表*/private void batchProcessMessages(List<String> messages) {// 解析所有消息List<Map<String, Object>> messageMaps = JSON.parseArray(JSON.toJSONString(messages), Map.class);// 批量处理逻辑,例如批量插入数据库// 这里使用MyBatis-Plus的批量插入// batchMapper.batchInsert(messageMaps);// 模拟批量处理耗时try {Thread.sleep(500);} catch (InterruptedException e) {Thread.currentThread().interrupt();throw new RuntimeException("批量处理被中断", e);}}
}
并发消费优化的关键参数:
- consumeThreadMin/consumeThreadMax:消费线程池大小,根据 CPU 核心数和消息处理类型调整
- consumeMessageBatchMaxSize:批量消费大小,IO 密集型可设大些,CPU 密集型应设小些
- consumeTimeout:消费超时时间,确保大于消息处理的最大耗时
2.3 消息重试机制优化
消费失败时,合理的重试策略能保证消息最终被正确处理。RocketMQ 默认提供了重试机制,但需要根据业务场景进行优化。
import com.alibaba.fastjson2.JSON;
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.spring.annotation.RocketMQMessageListener;
import org.apache.rocketmq.spring.core.RocketMQListener;
import org.apache.rocketmq.spring.core.RocketMQPushConsumerLifecycleListener;
import org.springframework.stereotype.Component;
import org.springframework.util.ObjectUtils;
import java.util.Map;/*** 自定义重试策略的消费者** @author ken*/
@Slf4j
@Component
@RocketMQMessageListener(topic = "retry_topic",consumerGroup = "retry_consumer_group",messageModel = MessageModel.CLUSTERING,// 顺序消费模式,确保重试消息的顺序性consumeMode = ConsumeMode.ORDERLY,// 最大重试次数maxReconsumeTimes = 5
)
public class RetryOptimizedConsumer implements RocketMQListener<String>, RocketMQPushConsumerLifecycleListener {@Overridepublic void onMessage(String message) {if (ObjectUtils.isEmpty(message)) {log.error("接收到空消息");return;}try {Map<String, Object> msgMap = JSON.parseObject(message, Map.class);log.info("接收到消息,开始处理,消息内容: {}", msgMap);// 处理消息业务逻辑processMessage(msgMap);log.info("消息处理成功");} catch (Exception e) {log.error("消息处理失败,准备重试", e);// 抛出异常,触发重试throw new RuntimeException("消息处理失败,需要重试", e);}}/*** 处理消息业务逻辑** @param message 消息内容*/private void processMessage(Map<String, Object> message) {// 实际业务处理逻辑// ...}/*** 自定义消费者配置,设置重试时间间隔*/@Overridepublic void prepareStart(DefaultMQPushConsumer consumer) {// 设置重试时间间隔,单位毫秒// 第1次重试延迟1秒,第2次3秒,第3次5秒,第4次10秒,第5次20秒int[] delayLevels = {1000, 3000, 5000, 10000, 20000};consumer.setDelayLevelWhenNextConsume(delayLevels);try {// 订阅重试主题consumer.subscribe("retry_topic", "*");log.info("自定义重试策略消费者初始化完成");} catch (MQClientException e) {log.error("消费者初始化失败", e);throw new RuntimeException("消费者初始化失败", e);}}
}
消息重试的最佳实践:
- 区分可重试异常和不可重试异常,避免无效重试
- 重要业务设置合理的重试次数和间隔,确保最终一致性
- 超过最大重试次数的消息应进入死信队列,进行人工干预
2.4 消费者配置优化
消费者的核心配置优化如下:
rocketmq:consumer:# 消费组名称,必须唯一group: optimized_consumer_group# 消费者拉取消息的超时时间pull-timeout: 10000# 一次拉取的消息数量,根据消息大小和处理能力调整pull-batch-size: 32# 消费模式:集群模式message-model: CLUSTERING# 最大重试次数max-reconsume-times: 5# 消费位点策略:从最后位置开始消费consume-from-where: CONSUME_FROM_LAST_OFFSET# 消费线程池核心线程数consume-thread-min: 10# 消费线程池最大线程数consume-thread-max: 20# 批量消费最大消息数consume-message-batch-max-size: 32
消费者配置的底层逻辑:
- 拉取批次大小与处理能力要匹配,过大会导致内存占用过高,过小则效率低
- 线程池大小应根据 CPU 核心数和消息处理类型(CPU 密集型 / IO 密集型)调整
- 重试次数设置需平衡消息可靠性和系统资源消耗
三、Broker 配置优化
Broker 作为消息的存储和转发中心,其配置优化对整个 RocketMQ 集群的性能至关重要。
3.1 内存配置优化
Broker 的内存配置直接影响消息处理性能和稳定性,以下是关键配置:
# broker.conf
# JVM 堆内存配置,建议设置为物理内存的50%左右,不超过32GB
# 例如:-Xms16g -Xmx16g -Xmn8g# 堆外内存配置,用于Netty缓冲区等
transientStorePoolEnable=true
transientStorePoolSize=5
# 单位:页,每页4KB,总大小=fileReservedTime * mappedFileSizeCommitLog / 4096
mappedFileSizeCommitLog=1073741824
mappedFileSizeConsumeQueue=300000# 内存锁定,防止JVM将内存交换到磁盘
useLockMemory=true# 发送消息线程池配置
sendMessageThreadPoolNums=64# 拉取消息线程池配置
pullMessageThreadPoolNums=64
内存配置优化原理:
- 堆内存过大会导致 GC 时间过长,过小则可能频繁 GC
- 启用 transientStorePool 能显著提高消息写入性能,通过堆外内存减少 JVM GC 压力
- 合理设置线程池大小,避免线程过多导致的上下文切换开销
3.2 持久化配置优化
RocketMQ 提供同步刷盘和异步刷盘两种持久化策略,需要根据业务对消息可靠性的要求进行选择。
# broker.conf
# 刷盘策略:ASYNC_FLUSH(异步刷盘)或SYNC_FLUSH(同步刷盘)
flushDiskType=ASYNC_FLUSH# 异步刷盘相关配置
# 刷盘线程数
flushThreadPoolSize=4
# CommitLog刷盘间隔,单位毫秒
flushIntervalCommitLog=500
# ConsumeQueue刷盘间隔,单位毫秒
flushIntervalConsumeQueue=60000
# 刷盘水位线,当缓存消息达到该值时触发刷盘
commitLogReservedSize=1073741824
consumeQueueReservedSize=10485760# 同步复制策略,主从复制方式
# SYNC_MASTER(同步复制)或ASYNC_MASTER(异步复制)
brokerRole=SYNC_MASTER# 主从复制刷盘配置
haMasterAddress=192.168.1.101:10911
haListenPort=10912
haSendHeartbeatInterval=5000
haHousekeepingInterval=20000
持久化策略选择建议:
- 金融级高可靠场景:SYNC_FLUSH + SYNC_MASTER
- 一般可靠性要求:ASYNC_FLUSH + SYNC_MASTER
- 高吞吐低延迟场景:ASYNC_FLUSH + ASYNC_MASTER
刷盘策略的性能对比:
+----------------+--------------+----------------+----------------+
| 刷盘策略 | 写入吞吐量 | 消息可靠性 | 系统开销 |
+----------------+--------------+----------------+----------------+
| 同步刷盘 | 低 | 最高 | 高 |
| 异步刷盘 | 高 | 较高 | 低 |
+----------------+--------------+----------------+----------------+
3.3 网络配置优化
Broker 的网络配置直接影响消息传输效率,以下是优化建议:
# broker.conf
# 监听端口
listenPort=10911# Netty相关配置
# 接收线程数,建议等于CPU核心数
nettySelectorThreads=8
# 工作线程数,建议为CPU核心数的2倍
nettyWorkerThreads=16
# 发送缓冲区大小
nettySocketSndBufSize=65536
# 接收缓冲区大小
nettySocketRcvBufSize=65536# 最大消息大小,单位字节
maxMessageSize=6553600# 心跳检测间隔,单位秒
clientChannelMaxIdleTimeSeconds=120# 超时时间配置
sendMessageTimeOut=3000
pullMessageTimeOut=10000
网络配置优化原理:
- 合理设置 Netty 线程池大小,充分利用 CPU 资源,避免线程过多导致的调度开销
- 调整 Socket 缓冲区大小,平衡内存占用和网络吞吐量
- 适当延长超时时间,减少网络波动导致的误判
3.4 流量控制配置
为防止 Broker 被过载请求压垮,需要配置合理的流量控制策略:
# broker.conf
# 流量控制开关
enableFlowControl=true# 生产者流量控制
maxSendMsgQueueSize=100000
sendThreadPoolQueueCapacity=10000# 消费者流量控制
maxPullMsgQueueSize=100000
pullThreadPoolQueueCapacity=10000# 消息堆积阈值,超过则触发流控
queueMaxSize=200000# 流量控制限流阈值,消息生产TPS限制
maxProducerSendMsgTPS=10000# 消费者拉取频率限制,单位:次/秒
pullThresholdForQueue=1000
流量控制的核心目的是:
- 保护 Broker 不被突发流量击垮
- 防止消息过度堆积导致的内存溢出
- 平衡生产者和消费者的速度,避免资源浪费
四、合理设置 Topic 的队列数
Topic 的队列数是影响 RocketMQ 并行处理能力的关键因素,合理设置队列数能显著提升系统吞吐量。
4.1 队列数与性能的关系
RocketMQ 的消息处理是基于队列的并行处理,队列数越多,理论上能支持的并发处理能力越强。但队列数并非越多越好,过多的队列会增加 Broker 的负担和消费者的调度开销。
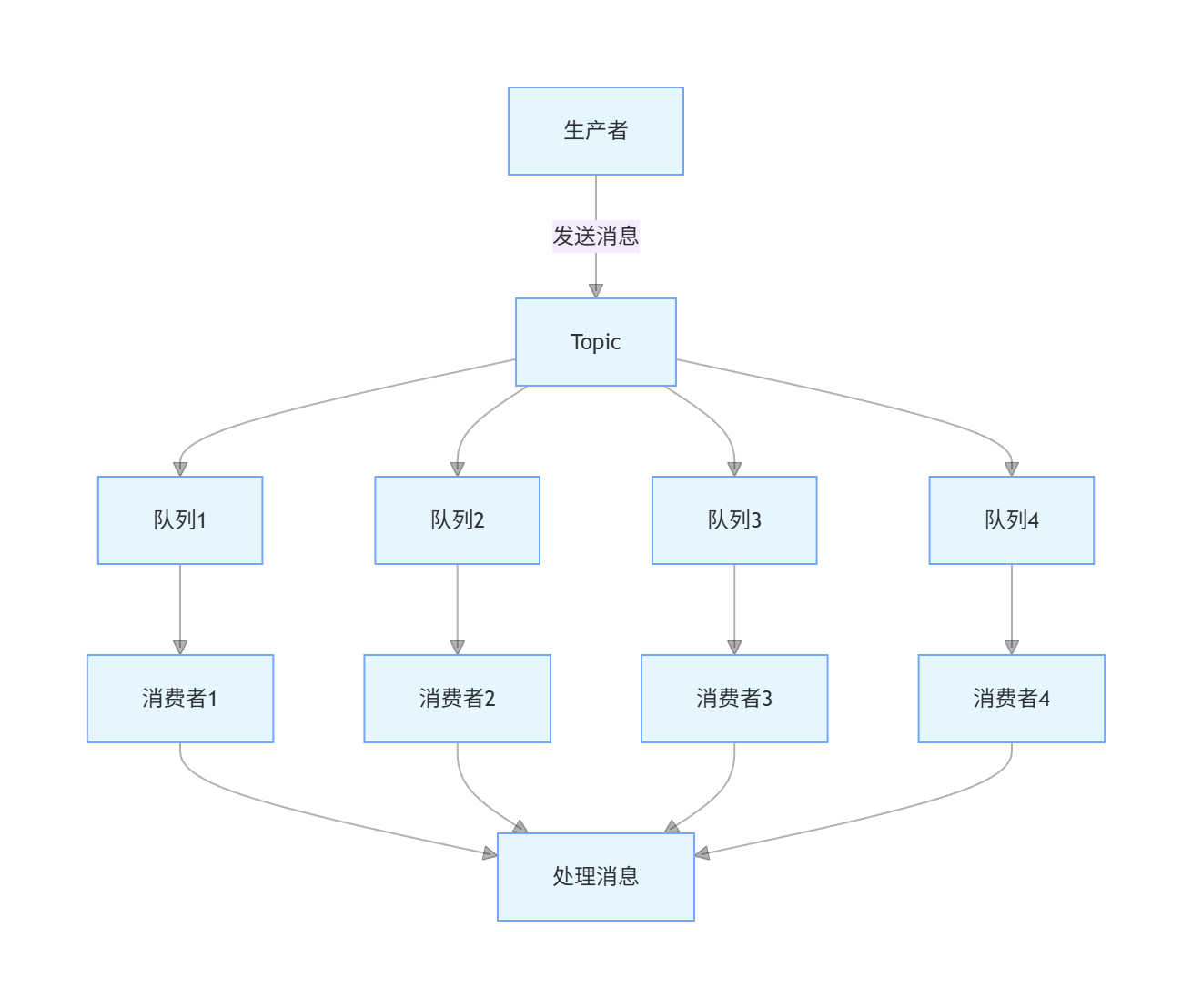
队列数设置的基本原则:
- 队列数应大于等于消费者实例数,确保负载均衡
- 队列数建议设置为 2 的幂次方,如 8、16、32 等,便于负载均衡计算
- 单个 Topic 的队列数不宜过多,建议不超过 1024
4.2 队列数设置实战
创建 Topic 时,合理设置队列数的示例:
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.client.admin.AdminClient;
import org.apache.rocketmq.client.admin.CreateTopicRequest;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.common.admin.TopicStatsTable;
import org.apache.rocketmq.common.message.MessageQueue;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.util.Set;/*** Topic管理器,负责创建和调整Topic队列数** @author ken*/
@Slf4j
@Component
public class TopicManager {@Value("${rocketmq.name-server}")private String nameServer;@Value("${rocketmq.broker.address}")private String brokerAddress;private AdminClient adminClient;@PostConstructpublic void init() {try {// 初始化AdminClientadminClient = AdminClient.createDefault(nameServer);log.info("AdminClient初始化成功,nameServer: {}", nameServer);// 检查并创建关键TopicensureTopicCreated("order_topic", 16);ensureTopicCreated("payment_topic", 8);ensureTopicCreated("log_topic", 32);} catch (MQClientException e) {log.error("AdminClient初始化失败", e);throw new RuntimeException("AdminClient初始化失败", e);}}/*** 确保Topic已创建,并设置合理的队列数** @param topicName Topic名称* @param queueNum 队列数量*/public void ensureTopicCreated(String topicName, int queueNum) {try {// 检查Topic是否已存在boolean topicExists = adminClient.topicExists(topicName);if (!topicExists) {// 创建TopicCreateTopicRequest request = new CreateTopicRequest();request.setTopic(topicName);request.setQueueNum(queueNum);request.setBrokerAddr(brokerAddress);adminClient.createTopic(request);log.info("创建Topic成功,名称: {}, 队列数: {}", topicName, queueNum);} else {// 检查当前队列数TopicStatsTable topicStats = adminClient.examineTopicStats(topicName);Set<MessageQueue> queues = topicStats.getOffsetTable().keySet();int currentQueueNum = queues.size();if (currentQueueNum != queueNum) {// 调整队列数CreateTopicRequest request = new CreateTopicRequest();request.setTopic(topicName);request.setQueueNum(queueNum);request.setBrokerAddr(brokerAddress);adminClient.createTopic(request);log.info("调整Topic队列数成功,名称: {}, 旧队列数: {}, 新队列数: {}", topicName, currentQueueNum, queueNum);} else {log.info("Topic已存在,队列数符合要求,名称: {}, 队列数: {}", topicName, queueNum);}}} catch (Exception e) {log.error("处理Topic失败,名称: {}", topicName, e);}}
}
4.3 队列数动态调整策略
在实际生产环境中,业务流量可能会动态变化,因此需要动态调整队列数以适应流量变化:
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.client.admin.TopicStatsTable;
import org.apache.rocketmq.common.message.MessageQueue;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.util.Set;
import java.util.concurrent.TimeUnit;/*** 队列数动态调整器** @author ken*/
@Slf4j
@Component
public class QueueDynamicAdjuster {@Autowiredprivate TopicManager topicManager;@Autowiredprivate AdminClient adminClient;/*** 每小时检查一次队列数,动态调整*/@Scheduled(fixedRate = 3600000)public void adjustQueueNums() {log.info("开始动态调整Topic队列数");try {// 检查订单TopicadjustTopicQueueNum("order_topic", 1000, 5000);// 检查支付TopicadjustTopicQueueNum("payment_topic", 500, 2000);// 检查日志TopicadjustTopicQueueNum("log_topic", 2000, 10000);} catch (Exception e) {log.error("动态调整队列数失败", e);}}/*** 调整指定Topic的队列数** @param topicName Topic名称* @param minTps 最小TPS阈值* @param maxTps 最大TPS阈值*/private void adjustTopicQueueNum(String topicName, int minTps, int maxTps) throws Exception {// 获取当前队列数TopicStatsTable topicStats = adminClient.examineTopicStats(topicName);Set<MessageQueue> queues = topicStats.getOffsetTable().keySet();int currentQueueNum = queues.size();// 计算过去5分钟的平均TPSdouble tps = calculateTopicTps(topicName, 5, TimeUnit.MINUTES);log.info("Topic: {}, 当前队列数: {}, 当前TPS: {}", topicName, currentQueueNum, tps);// 根据TPS调整队列数if (tps > maxTps && currentQueueNum < 1024) {// TPS过高,增加队列数(翻倍,但不超过1024)int newQueueNum = Math.min(currentQueueNum * 2, 1024);topicManager.ensureTopicCreated(topicName, newQueueNum);log.info("Topic: {} TPS过高,已调整队列数从 {} 到 {}", topicName, currentQueueNum, newQueueNum);} else if (tps < minTps && currentQueueNum > 4) {// TPS过低,减少队列数(减半,但不低于4)int newQueueNum = Math.max(currentQueueNum / 2, 4);topicManager.ensureTopicCreated(topicName, newQueueNum);log.info("Topic: {} TPS过低,已调整队列数从 {} 到 {}", topicName, currentQueueNum, newQueueNum);} else {log.info("Topic: {} 队列数适中,无需调整", topicName);}}/*** 计算Topic在指定时间内的平均TPS** @param topicName Topic名称* @param duration 时间长度* @param unit 时间单位* @return 平均TPS*/private double calculateTopicTps(String topicName, int duration, TimeUnit unit) throws Exception {// 实际实现中,这里应该从监控系统获取指定时间内的消息总量// 这里为了示例,返回一个模拟值return 2000 + Math.random() * 3000;}
}
队列数动态调整的优势:
- 高峰期自动增加队列数,提高处理能力
- 低峰期自动减少队列数,节约系统资源
- 适应业务流量的动态变化,保持系统最佳性能
五、消费设置长轮询模式
长轮询(Long Polling)是 RocketMQ 推荐的消费模式,相比短轮询能显著减少无效请求,降低网络开销。
5.1 长轮询原理
长轮询的工作原理是:消费者发送拉取请求到 Broker,如果当前有消息则立即返回;如果没有消息,Broker 不会立即返回空结果,而是保持连接一段时间(默认 30 秒),在这段时间内如果有新消息到达,则立即返回给消费者。
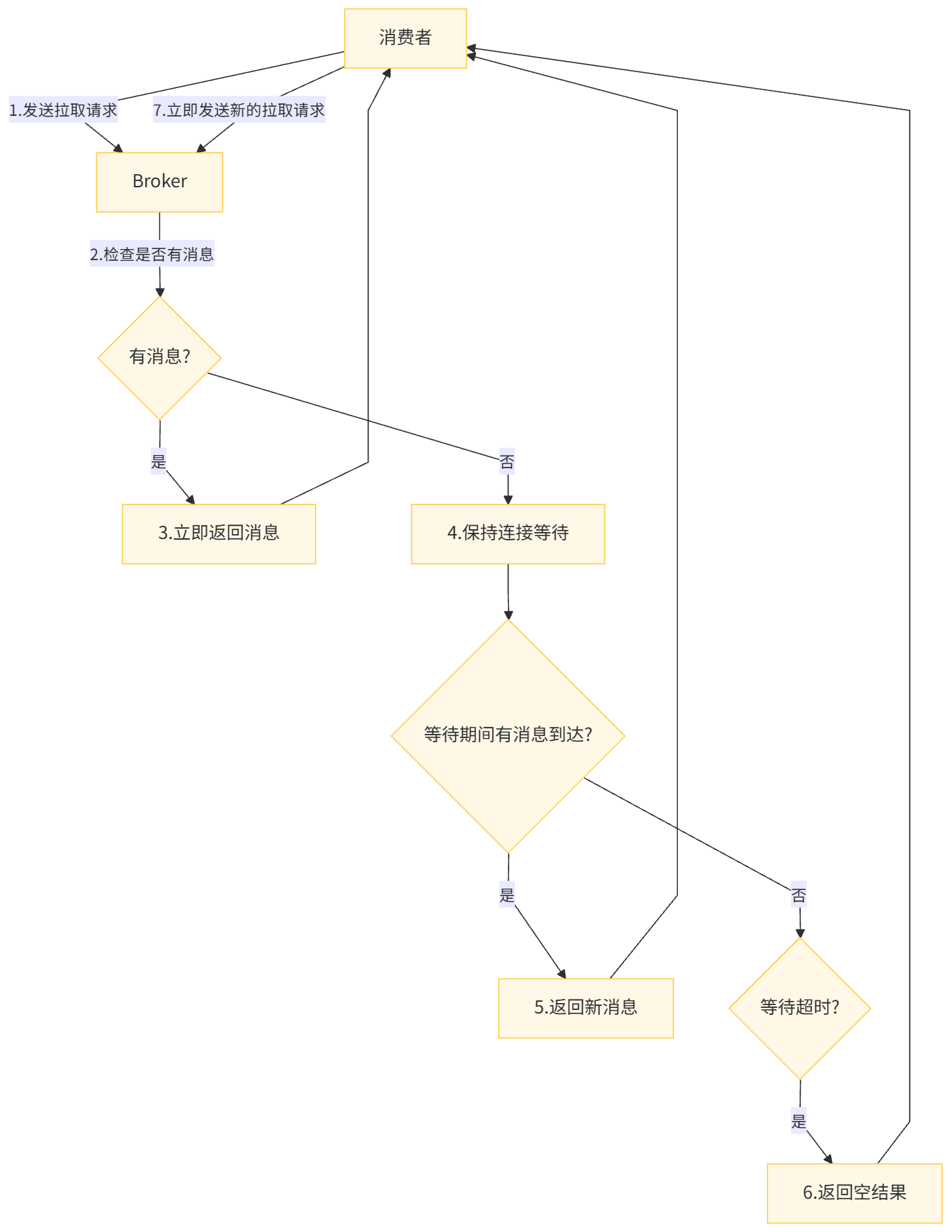
长轮询相比短轮询的优势:
- 减少无效请求,降低网络带宽消耗
- 消息到达后能更快被消费,降低延迟
- 减轻 Broker 的请求处理压力
5.2 长轮询配置
在 RocketMQ 中,消费者默认使用长轮询模式,以下是关键配置优化:
rocketmq:consumer:# 长轮询等待时间,单位毫秒,默认30000mslong-polling-timeout: 30000# 拉取消息的间隔时间,长轮询模式下该值作用不大pull-interval: 0# 一次拉取的消息数量pull-batch-size: 32# 消费线程池配置consume-thread-min: 10consume-thread-max: 20
Broker 端的长轮询配置:
# broker.conf
# 长轮询最大等待时间,单位毫秒
longPollingEnable=true
# 长轮询等待时间,应大于等于消费者配置的long-polling-timeout
longPollingWaitTimeMills=35000
# 长轮询期间检查新消息的频率,单位毫秒
shortPollingTimeMills=1000
5.3 长轮询实战优化
以下是一个优化后的长轮询消费者示例:
import com.alibaba.fastjson2.JSON;
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.spring.annotation.RocketMQMessageListener;
import org.apache.rocketmq.spring.core.RocketMQListener;
import org.apache.rocketmq.spring.core.RocketMQPushConsumerLifecycleListener;
import org.springframework.stereotype.Component;
import org.springframework.util.ObjectUtils;
import java.util.Map;/*** 长轮询模式消费者** @author ken*/
@Slf4j
@Component
@RocketMQMessageListener(topic = "long_polling_topic",consumerGroup = "long_polling_consumer_group",messageModel = MessageModel.CLUSTERING,consumeMode = ConsumeMode.CONCURRENTLY
)
public class LongPollingConsumer implements RocketMQListener<String>,RocketMQPushConsumerLifecycleListener {@Overridepublic void onMessage(String message) {if (ObjectUtils.isEmpty(message)) {log.error("接收到空消息");return;}try {Map<String, Object> msgMap = JSON.parseObject(message, Map.class);log.info("接收到消息,开始处理,消息内容: {}", msgMap);// 处理消息业务逻辑processMessage(msgMap);log.info("消息处理成功");} catch (Exception e) {log.error("消息处理失败", e);throw new RuntimeException("消息处理失败,需要重试", e);}}/*** 处理消息业务逻辑** @param message 消息内容*/private void processMessage(Map<String, Object> message) {// 实际业务处理逻辑try {// 模拟业务处理Thread.sleep(50);} catch (InterruptedException e) {Thread.currentThread().interrupt();throw new RuntimeException("业务处理被中断", e);}}/*** 配置消费者的长轮询参数*/@Overridepublic void prepareStart(DefaultMQPushConsumer consumer) {try {// 设置长轮询超时时间,单位毫秒consumer.setConsumerPullTimeoutMillis(30000);// 设置拉取批次大小consumer.setPullBatchSize(32);// 设置消费失败重试策略consumer.setMaxReconsumeTimes(3);log.info("长轮询消费者配置完成");} catch (Exception e) {log.error("长轮询消费者配置失败", e);}}
}
长轮询的最佳实践:
- 根据业务场景调整长轮询超时时间,消息实时性要求高的场景可适当缩短
- 合理设置拉取批次大小,平衡网络传输和处理效率
- 确保 Broker 和 Consumer 的长轮询配置匹配,避免不兼容问题
六、JVM 优化
RocketMQ 服务端和客户端的 JVM 配置优化,对系统稳定性和性能有重要影响。
6.1 Broker 的 JVM 优化
Broker 作为消息存储和转发中心,对 JVM 配置要求较高:
# runbroker.sh 中的JVM配置
JAVA_OPT="${JAVA_OPT} -server -Xms16g -Xmx16g -Xmn8g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
JAVA_OPT="${JAVA_OPT} -XX:+UseG1GC -XX:G1HeapRegionSize=16m -XX:G1ReservePercent=25 -XX:InitiatingHeapOccupancyPercent=30 -XX:SoftRefLRUPolicyMSPerMB=0"
JAVA_OPT="${JAVA_OPT} -verbose:gc -Xlog:gc*:../logs/gc.log:time,tags:filecount=10,filesize=102400"
JAVA_OPT="${JAVA_OPT} -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=../logs/heapdump.hprof"
JAVA_OPT="${JAVA_OPT} -XX:-OmitStackTraceInFastThrow"
JAVA_OPT="${JAVA_OPT} -XX:+AlwaysPreTouch"
JAVA_OPT="${JAVA_OPT} -XX:MaxDirectMemorySize=15g"
Broker 的 JVM 配置解析:
- 堆内存设置:建议 16-32GB,新生代与老年代比例 1:1
- GC 收集器:推荐使用 G1,兼顾吞吐量和延迟
- 元空间:设置合理大小,避免动态扩展带来的性能波动
- 直接内存:设置与堆内存相当的大小,减少 IO 操作的 GC 影响
6.2 NameServer 的 JVM 优化
NameServer 作为路由中心,资源消耗相对较小,但仍需合理配置:
# runserver.sh 中的JVM配置
JAVA_OPT="${JAVA_OPT} -server -Xms2g -Xmx2g -Xmn1g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
JAVA_OPT="${JAVA_OPT} -XX:+UseG1GC -XX:G1HeapRegionSize=16m -XX:G1ReservePercent=25 -XX:InitiatingHeapOccupancyPercent=30"
JAVA_OPT="${JAVA_OPT} -verbose:gc -Xlog:gc*:../logs/namesrv_gc.log:time,tags:filecount=5,filesize=102400"
JAVA_OPT="${JAVA_OPT} -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=../logs/namesrv_heapdump.hprof"
NameServer 的 JVM 配置特点:
- 内存需求较小,一般 2-4GB 足够
- 同样推荐 G1 收集器,确保低延迟
- 配置详细的 GC 日志,便于问题排查
6.3 客户端 JVM 优化
生产者和消费者作为客户端,JVM 配置应根据业务规模调整:
# 客户端JVM配置示例
JAVA_OPTS="-server -Xms4g -Xmx4g -Xmn2g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m"
JAVA_OPTS="$JAVA_OPTS -XX:+UseG1GC -XX:G1HeapRegionSize=8m -XX:G1ReservePercent=20"
JAVA_OPTS="$JAVA_OPTS -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./logs/heapdump.hprof"
JAVA_OPTS="$JAVA_OPTS -Xlog:gc*:./logs/client_gc.log:time,tags:filecount=5,filesize=51200"
JAVA_OPTS="$JAVA_OPTS -XX:+DisableExplicitGC"
客户端 JVM 配置要点:
- 避免设置过大的堆内存,防止 GC 停顿过长
- 禁用显式 GC,避免业务代码调用 System.gc () 影响性能
- 配置合适的新生代比例,减少老年代 GC 频率
6.4 JVM 监控与调优实践
通过监控 JVM 指标,持续优化配置:
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.lang.management.*;
import java.util.List;/*** JVM监控组件,定期收集JVM指标** @author ken*/
@Slf4j
@Component
public class JvmMonitor {private final MemoryMXBean memoryMXBean;private final List<MemoryPoolMXBean> memoryPoolMXBeans;private final GarbageCollectorMXBean youngGenGcBean;private final GarbageCollectorMXBean oldGenGcBean;private final OperatingSystemMXBean osMXBean;public JvmMonitor() {memoryMXBean = ManagementFactory.getMemoryMXBean();memoryPoolMXBeans = ManagementFactory.getMemoryPoolMXBeans();List<GarbageCollectorMXBean> gcBeans = ManagementFactory.getGarbageCollectorMXBeans();// 区分年轻代和老年代GC收集器if (gcBeans.size() >= 2) {youngGenGcBean = gcBeans.get(0);oldGenGcBean = gcBeans.get(1);} else {youngGenGcBean = gcBeans.get(0);oldGenGcBean = gcBeans.get(0);}osMXBean = ManagementFactory.getOperatingSystemMXBean();}/*** 每30秒收集一次JVM指标*/@Scheduled(fixedRate = 30000)public void collectJvmMetrics() {// 内存使用情况MemoryUsage heapMemoryUsage = memoryMXBean.getHeapMemoryUsage();MemoryUsage nonHeapMemoryUsage = memoryMXBean.getNonHeapMemoryUsage();// GC情况long youngGcCount = youngGenGcBean.getCollectionCount();long youngGcTime = youngGenGcBean.getCollectionTime();long oldGcCount = oldGenGcBean.getCollectionCount();long oldGcTime = oldGenGcBean.getCollectionTime();// 系统信息int availableProcessors = osMXBean.getAvailableProcessors();double systemCpuLoad = ((com.sun.management.OperatingSystemMXBean) osMXBean).getSystemCpuLoad();// 打印监控信息log.info("JVM监控信息 - 堆内存: 已用={}MB, 最大={}MB; 非堆内存: 已用={}MB, 最大={}MB",heapMemoryUsage.getUsed() / 1024 / 1024,heapMemoryUsage.getMax() / 1024 / 1024,nonHeapMemoryUsage.getUsed() / 1024 / 1024,nonHeapMemoryUsage.getMax() / 1024 / 1024);log.info("JVM监控信息 - 年轻代GC: 次数={}, 时间={}ms; 老年代GC: 次数={}, 时间={}ms",youngGcCount, youngGcTime, oldGcCount, oldGcTime);log.info("JVM监控信息 - 可用CPU核心数={}, 系统CPU负载={}",availableProcessors, systemCpuLoad);// 检查是否需要报警checkAndAlert(heapMemoryUsage, youngGcCount, oldGcCount);}/*** 检查JVM指标是否超出阈值,如需则报警*/private void checkAndAlert(MemoryUsage heapMemoryUsage, long youngGcCount, long oldGcCount) {// 计算堆内存使用率double heapUsageRate = (double) heapMemoryUsage.getUsed() / heapMemoryUsage.getMax();// 堆内存使用率超过80%报警if (heapUsageRate > 0.8) {log.warn("JVM报警: 堆内存使用率过高,使用率={}%", heapUsageRate * 100);// 实际应用中,这里可以发送报警通知到监控系统}// 其他报警逻辑...}
}
JVM 调优的最佳实践:
- 定期分析 GC 日志,优化 GC 参数
- 监控内存使用趋势,及时发现内存泄漏
- 根据业务负载变化,动态调整 JVM 配置
- 避免过早优化,先解决明显的性能瓶颈
七、消息存储优化
RocketMQ 的消息存储机制直接影响消息读写性能和可靠性,合理的存储优化能显著提升系统性能。
7.1 存储路径优化
RocketMQ 的消息存储路径应合理规划,避免磁盘 IO 瓶颈:
# broker.conf
# 存储根路径,建议使用独立磁盘
storePathRootDir=/data/rocketmq/store# CommitLog存储路径
storePathCommitLog=/data/rocketmq/store/commitlog# ConsumeQueue存储路径
storePathConsumeQueue=/data/rocketmq/store/consumequeue# 索引存储路径
storePathIndex=/data/rocketmq/store/index# checkpoint文件路径
storeCheckpoint=/data/rocketmq/store/checkpoint# abort文件路径
abortFile=/data/rocketmq/store/abort
存储路径优化建议:
- 使用高性能 SSD 存储 CommitLog,提高读写性能
- 不同类型的文件(CommitLog、ConsumeQueue 等)可考虑存储在不同磁盘,分散 IO 压力
- 确保存储磁盘有足够的空间,避免磁盘满导致服务异常
7.2 刷盘策略优化
根据业务对消息可靠性和性能的要求,选择合适的刷盘策略:
# broker.conf
# 刷盘策略:ASYNC_FLUSH(异步刷盘)或SYNC_FLUSH(同步刷盘)
flushDiskType=ASYNC_FLUSH# 异步刷盘配置
# 刷盘线程数
flushThreadPoolSize=4
# CommitLog刷盘间隔,单位毫秒
flushIntervalCommitLog=500
# 当缓存的消息达到该大小时触发刷盘,单位字节
commitLogReservedSize=1073741824
# 批量刷盘的页数
batchFlushSize=4# 同步刷盘配置
# 同步刷盘时,等待刷盘完成的超时时间
syncFlushTimeout=5000
刷盘策略选择指南:
- 金融交易等核心业务:使用 SYNC_FLUSH 确保消息不丢失
- 日志收集等非核心业务:使用 ASYNC_FLUSH 提高性能
- 异步刷盘时,合理设置刷盘间隔和触发阈值,平衡性能和可靠性
7.3 文件过期清理优化
RocketMQ 会定期清理过期的消息文件,释放磁盘空间:
# broker.conf
# 消息保存时间,单位小时,默认72小时
fileReservedTime=72# 清理过期文件的时间窗口,默认凌晨4点到5点
deleteWhen=04# 每次清理的最大文件数
deleteFilesInterval=10# 磁盘空间阈值,低于该值则触发清理,单位百分比
diskMaxUsedSpaceRatio=88
文件清理优化建议:
- 根据磁盘容量和消息量,合理设置 fileReservedTime
- 清理时间窗口选择在业务低峰期,减少对正常业务的影响
- 设置合理的磁盘空间阈值,避免磁盘空间耗尽
7.4 存储优化实战
以下是一个监控消息存储状态的工具类:
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.common.MixAll;
import org.apache.rocketmq.common.message.MessageExt;
import org.apache.rocketmq.store.DefaultMessageStore;
import org.apache.rocketmq.store.MessageStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.io.File;
import java.text.DecimalFormat;/*** 消息存储监控工具** @author ken*/
@Slf4j
@Component
public class MessageStoreMonitor {@Autowiredprivate MessageStore messageStore;private final DecimalFormat df = new DecimalFormat("0.00");/*** 每10分钟监控一次消息存储状态*/@Scheduled(fixedRate = 600000)public void monitorStoreStatus() {if (!(messageStore instanceof DefaultMessageStore)) {log.warn("不支持的MessageStore类型,无法监控存储状态");return;}DefaultMessageStore store = (DefaultMessageStore) messageStore;// 获取存储统计信息long commitLogSize = store.getCommitLog().getMaxOffset();long consumeQueueSize = calculateConsumeQueueSize(store.getMessageStoreConfig().getStorePathConsumeQueue());long indexSize = calculateIndexSize(store.getMessageStoreConfig().getStorePathIndex());// 获取磁盘使用情况File storeRoot = new File(store.getMessageStoreConfig().getStorePathRootDir());long totalSpace = storeRoot.getTotalSpace();long freeSpace = storeRoot.getFreeSpace();double usedPercent = 100.0 - (freeSpace * 100.0 / totalSpace);// 获取消息数量统计long messageCount = store.getMessageTotalSize();long tps = calculateTps(store);// 打印监控信息log.info("消息存储监控 - CommitLog大小: {}GB, ConsumeQueue大小: {}MB, Index大小: {}MB",df.format(commitLogSize / 1024.0 / 1024 / 1024),df.format(consumeQueueSize / 1024.0 / 1024),df.format(indexSize / 1024.0 / 1024));log.info("消息存储监控 - 磁盘总空间: {}GB, 剩余空间: {}GB, 使用率: {}%",df.format(totalSpace / 1024.0 / 1024 / 1024),df.format(freeSpace / 1024.0 / 1024 / 1024),df.format(usedPercent));log.info("消息存储监控 - 消息总数: {}, 最近1分钟TPS: {}", messageCount, tps);// 检查是否需要报警if (usedPercent > 85) {log.warn("磁盘使用率过高,可能影响服务正常运行,使用率: {}%", df.format(usedPercent));// 发送报警通知}}/*** 计算ConsumeQueue总大小*/private long calculateConsumeQueueSize(String path) {File dir = new File(path);return calculateDirectorySize(dir);}/*** 计算Index总大小*/private long calculateIndexSize(String path) {File dir = new File(path);return calculateDirectorySize(dir);}/*** 计算目录总大小*/private long calculateDirectorySize(File dir) {if (!dir.exists() || !dir.isDirectory()) {return 0;}long size = 0;File[] files = dir.listFiles();if (files != null) {for (File file : files) {if (file.isDirectory()) {size += calculateDirectorySize(file);} else {size += file.length();}}}return size;}/*** 计算最近1分钟的TPS*/private long calculateTps(DefaultMessageStore store) {// 实际实现中,这里应该通过监控store的消息增长情况计算TPS// 这里为示例返回一个模拟值return (long) (Math.random() * 1000 + 500);}
}
消息存储优化的最佳实践:
- 定期监控存储使用情况,提前扩容
- 根据业务特点调整刷盘策略和过期时间
- 使用高性能存储设备,如 SSD,提升读写性能
- 实施存储分层,热数据和冷数据分离存储
八、监控和告警
完善的监控和告警体系是保障 RocketMQ 稳定运行的关键,能及时发现并解决问题。
8.1 核心监控指标
RocketMQ 需要监控的核心指标包括:
生产者指标
- 消息发送 TPS
- 消息发送成功率
- 消息发送延迟
消费者指标
- 消息消费 TPS
- 消息消费成功率
- 消息堆积量
- 消费延迟
Broker 指标
- 消息存储大小
- 磁盘使用率
- 刷盘耗时
- 主从同步状态
JVM 指标
- 堆内存使用率
- GC 频率和耗时
- 线程数
8.2 监控系统搭建
使用 Prometheus + Grafana 搭建 RocketMQ 监控系统:
<!-- pom.xml 依赖 -->
<dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-exporter</artifactId><version>0.0.2</version>
</dependency>
<dependency><groupId>io.prometheus</groupId><artifactId>simpleclient</artifactId><version>0.16.0</version>
</dependency>
<dependency><groupId>io.prometheus</groupId><artifactId>simpleclient_spring_boot</artifactId><version>0.16.0</version>
</dependency>
RocketMQ Exporter 配置:
rocketmq:namesrv-addr: 192.168.1.100:9876;192.168.1.101:9876exporter:port: 5557enable-all-metrics: truepull-thread-num: 20cluster-name: rocketmq-cluster
Prometheus 配置:
scrape_configs:- job_name: 'rocketmq'static_configs:- targets: ['192.168.1.100:5557', '192.168.1.101:5557']scrape_interval: 10s
8.3 告警配置
设置关键指标的告警阈值,及时发现异常:
import io.prometheus.client.CollectorRegistry;
import io.prometheus.client.Gauge;
import io.prometheus.client.exporter.PushGateway;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;/*** 告警管理器** @author ken*/
@Slf4j
@Component
public class AlarmManager {@Value("${rocketmq.cluster.name}")private String clusterName;@Value("${prometheus.pushgateway.url}")private String pushGatewayUrl;@Autowiredprivate RocketMQMetricCollector metricCollector;// 告警指标private final Gauge messageBacklogGauge = Gauge.build().name("rocketmq_message_backlog").labelNames("cluster", "topic", "consumerGroup").help("消息堆积量").register();private final Gauge sendFailedRateGauge = Gauge.build().name("rocketmq_send_failed_rate").labelNames("cluster", "topic").help("消息发送失败率").register();private final Gauge consumeFailedRateGauge = Gauge.build().name("rocketmq_consume_failed_rate").labelNames("cluster", "topic", "consumerGroup").help("消息消费失败率").register();private final Gauge diskUsageGauge = Gauge.build().name("rocketmq_disk_usage").labelNames("cluster", "broker").help("Broker磁盘使用率").register();/*** 每5分钟检查一次指标,触发告警*/@Scheduled(fixedRate = 300000)public void checkMetricsAndAlarm() {try {// 收集指标Map<String, Map<String, Long>> backlogMetrics = metricCollector.collectMessageBacklog();Map<String, Double> sendFailedRateMetrics = metricCollector.collectSendFailedRate();Map<String, Map<String, Double>> consumeFailedRateMetrics = metricCollector.collectConsumeFailedRate();Map<String, Double> diskUsageMetrics = metricCollector.collectDiskUsage();// 更新告警指标updateBacklogMetrics(backlogMetrics);updateSendFailedRateMetrics(sendFailedRateMetrics);updateConsumeFailedRateMetrics(consumeFailedRateMetrics);updateDiskUsageMetrics(diskUsageMetrics);// 推送指标到PushGatewaypushMetricsToGateway();// 检查是否需要触发告警checkAndTriggerAlarm(backlogMetrics, sendFailedRateMetrics, consumeFailedRateMetrics, diskUsageMetrics);} catch (Exception e) {log.error("检查指标并告警失败", e);}}/*** 检查指标是否超过阈值,触发告警*/private void checkAndTriggerAlarm(Map<String, Map<String, Long>> backlogMetrics,Map<String, Double> sendFailedRateMetrics,Map<String, Map<String, Double>> consumeFailedRateMetrics,Map<String, Double> diskUsageMetrics) {// 检查消息堆积for (Map.Entry<String, Map<String, Long>> topicEntry : backlogMetrics.entrySet()) {String topic = topicEntry.getKey();for (Map.Entry<String, Long> consumerEntry : topicEntry.getValue().entrySet()) {String consumerGroup = consumerEntry.getKey();long backlog = consumerEntry.getValue();// 消息堆积超过10000条触发告警if (backlog > 10000) {sendAlarm("消息堆积告警", String.format("集群: %s, 主题: %s, 消费组: %s, 堆积量: %d条", clusterName, topic, consumerGroup, backlog));}}}// 检查消息发送失败率for (Map.Entry<String, Double> entry : sendFailedRateMetrics.entrySet()) {String topic = entry.getKey();double failedRate = entry.getValue();// 发送失败率超过1%触发告警if (failedRate > 0.01) {sendAlarm("消息发送失败率告警", String.format("集群: %s, 主题: %s, 发送失败率: %.2f%%", clusterName, topic, failedRate * 100));}}// 检查磁盘使用率for (Map.Entry<String, Double> entry : diskUsageMetrics.entrySet()) {String broker = entry.getKey();double usage = entry.getValue();// 磁盘使用率超过85%触发告警if (usage > 85) {sendAlarm("磁盘使用率告警", String.format("集群: %s, Broker: %s, 磁盘使用率: %.2f%%", clusterName, broker, usage));}}// 其他告警检查...}/*** 发送告警通知*/private void sendAlarm(String title, String content) {log.warn("【{}】{}", title, content);// 实际应用中,这里可以对接短信、邮件、钉钉等告警渠道// 例如调用告警API: alarmService.sendAlarm(title, content);}/*** 推送指标到PushGateway*/private void pushMetricsToGateway() throws IOException {PushGateway pg = new PushGateway(pushGatewayUrl);Map<String, String> groupingKey = new HashMap<>();groupingKey.put("cluster", clusterName);pg.pushAdd(CollectorRegistry.defaultRegistry, "rocketmq_alarm", groupingKey);}// 其他更新指标的方法...private void updateBacklogMetrics(Map<String, Map<String, Long>> backlogMetrics) {// 实现指标更新逻辑}private void updateSendFailedRateMetrics(Map<String, Double> sendFailedRateMetrics) {// 实现指标更新逻辑}private void updateConsumeFailedRateMetrics(Map<String, Map<String, Double>> consumeFailedRateMetrics) {// 实现指标更新逻辑}private void updateDiskUsageMetrics(Map<String, Double> diskUsageMetrics) {// 实现指标更新逻辑}
}
8.4 监控与告警最佳实践
关键指标告警阈值设置建议:
- 消息堆积:根据业务容忍度设置,一般 1-10 万条
- 发送失败率:超过 0.1% 告警
- 消费失败率:超过 1% 告警
- 磁盘使用率:超过 85% 告警
- GC 耗时:单次 GC 超过 1 秒告警
告警渠道选择:
- 严重告警:电话、短信
- 一般告警:钉钉、企业微信
- 提示性告警:邮件
监控数据保留策略:
- 近期详细数据(1 周内):保留原始数据
- 中期数据(1 个月内):5 分钟聚合一次
- 长期数据(1 年内):1 小时聚合一次
定期分析监控数据:
- 每周生成性能报告
- 每月进行容量规划评估
- 每季度进行性能优化评审
九、消息压缩
对于大消息场景,消息压缩能显著减少网络传输量和存储占用,提高系统性能。
9.1 压缩算法选择
RocketMQ 支持多种压缩算法,各有优缺点:
| 压缩算法 | 压缩率 | 压缩速度 | 解压速度 | 适用场景 |
|---|---|---|---|---|
| ZIP | 中 | 中 | 中 | 通用场景 |
| LZ4 | 低 | 快 | 快 | 对速度要求高的场景 |
| ZSTD | 高 | 较快 | 较快 | 对压缩率要求高的场景 |
| Snappy | 低 | 快 | 快 | 对速度要求高的场景 |
9.2 消息压缩配置
生产者端配置消息压缩:
rocketmq:producer:# 消息压缩阈值,超过该大小则压缩,单位字节compress-message-body-threshold: 1048576 # 1MB# 压缩算法,可选值:ZIP, LZ4, ZSTD, Snappycompression-type: LZ4
压缩消息发送示例:
import com.alibaba.fastjson2.JSON;
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.spring.core.RocketMQTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import java.util.Map;/*** 支持压缩的消息生产者** @author ken*/
@Slf4j
@RestController
@RequestMapping("/compressed-producer")
@Tag(name = "压缩消息生产者接口", description = "自动压缩超过阈值的消息")
public class CompressedProducerController {@Autowiredprivate RocketMQTemplate rocketMQTemplate;/*** 发送可能被压缩的消息** @param message 消息内容*/@PostMapping("/send")@Operation(summary = "发送可能被压缩的消息", description = "超过压缩阈值的消息会自动被压缩")public void sendCompressedMessage(@RequestBody Map<String, Object> message) {String topic = "compressed_topic";String messageStr = JSON.toJSONString(message);// 计算消息大小int messageSize = messageStr.getBytes().length;log.info("发送消息,大小: {}KB", messageSize / 1024);// 发送消息,超过阈值会自动压缩rocketMQTemplate.syncSend(topic, messageStr);log.info("消息发送成功");}
}
9.3 压缩策略优化
消息压缩的最佳实践:
合理设置压缩阈值:
- 过小的阈值会导致大量小消息被压缩,浪费 CPU 资源
- 过大的阈值则无法有效减少网络传输和存储
- 建议阈值设置为 1KB-1MB,根据业务消息大小分布调整
压缩算法选择:
- 对性能要求高的场景选择 LZ4 或 Snappy
- 对带宽和存储敏感的场景选择 ZSTD
- 通用场景选择 ZIP
大消息处理策略:
- 避免发送超大消息(超过 10MB)
- 超大消息建议采用 "消息体 + 文件存储" 模式,消息中只包含文件 ID
- 批量发送小消息,减少压缩解压开销
压缩监控:
- 监控压缩率:压缩后大小 / 压缩前大小
- 监控压缩解压耗时
- 监控因压缩节省的网络流量
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.util.concurrent.atomic.AtomicLong;/*** 消息压缩监控器** @author ken*/
@Slf4j
@Component
public class CompressionMonitor {// 压缩前总大小private final AtomicLong totalOriginalSize = new AtomicLong(0);// 压缩后总大小private final AtomicLong totalCompressedSize = new AtomicLong(0);// 压缩总耗时private final AtomicLong totalCompressTime = new AtomicLong(0);// 解压总耗时private final AtomicLong totalDecompressTime = new AtomicLong(0);// 压缩消息数量private final AtomicLong compressedMessageCount = new AtomicLong(0);// 总消息数量private final AtomicLong totalMessageCount = new AtomicLong(0);/*** 记录压缩统计信息*/public void recordCompressionStats(int originalSize, int compressedSize, long compressTime) {totalOriginalSize.addAndGet(originalSize);totalCompressedSize.addAndGet(compressedSize);totalCompressTime.addAndGet(compressTime);compressedMessageCount.incrementAndGet();totalMessageCount.incrementAndGet();}/*** 记录解压统计信息*/public void recordDecompressionStats(long decompressTime) {totalDecompressTime.addAndGet(decompressTime);}/*** 记录未压缩消息*/public void recordUncompressedMessage(int size) {totalOriginalSize.addAndGet(size);totalCompressedSize.addAndGet(size);totalMessageCount.incrementAndGet();}/*** 每小时打印一次压缩统计信息*/@Scheduled(fixedRate = 3600000)public void printCompressionStats() {long originalSize = totalOriginalSize.get();long compressedSize = totalCompressedSize.get();long compressTime = totalCompressTime.get();long decompressTime = totalDecompressTime.get();long compressedCount = compressedMessageCount.get();long totalCount = totalMessageCount.get();if (totalCount == 0) {log.info("消息压缩统计: 暂无消息数据");return;}// 计算压缩率double compressionRatio = (double) compressedSize / originalSize;// 计算平均压缩耗时double avgCompressTime = compressedCount > 0 ? (double) compressTime / compressedCount : 0;// 计算平均解压耗时double avgDecompressTime = compressedCount > 0 ? (double) decompressTime / compressedCount : 0;// 计算压缩比例double compressedPercent = (double) compressedCount / totalCount * 100;// 计算节省的空间long savedSize = originalSize - compressedSize;log.info("消息压缩统计 - 总消息数: {}, 压缩消息数: {}({}%), 总原始大小: {}MB, 总压缩后大小: {}MB",totalCount,compressedCount,String.format("%.2f", compressedPercent),originalSize / 1024 / 1024,compressedSize / 1024 / 1024);log.info("消息压缩统计 - 平均压缩率: {}%, 节省空间: {}MB, 平均压缩耗时: {}ms, 平均解压耗时: {}ms",String.format("%.2f", compressionRatio * 100),savedSize / 1024 / 1024,String.format("%.2f", avgCompressTime),String.format("%.2f", avgDecompressTime));// 重置计数器resetCounters();}/*** 重置计数器*/private void resetCounters() {totalOriginalSize.set(0);totalCompressedSize.set(0);totalCompressTime.set(0);totalDecompressTime.set(0);compressedMessageCount.set(0);totalMessageCount.set(0);}
}
十、总结
RocketMQ 生产环境优化是一个系统工程,需要从生产者、消费者、Broker、存储、JVM 等多个维度进行全面优化。本文详细介绍了各个方面的优化策略和实战方案,包括:
- 生产者优化:异步发送、批量发送、合理配置参数、优化重试机制
- 消费者优化:选择合适的消费模式、优化并发消费、合理配置重试策略
- Broker 配置优化:内存配置、持久化策略、网络配置、流量控制
- 队列数设置:根据业务场景合理设置队列数,并支持动态调整
- 长轮询模式:相比短轮询能显著减少无效请求,降低延迟
- JVM 优化:针对 Broker、NameServer 和客户端的 JVM 配置优化
- 消息存储优化:存储路径规划、刷盘策略选择、文件过期清理
- 监控和告警:核心指标监控、监控系统搭建、告警配置
- 消息压缩:压缩算法选择、压缩策略优化、压缩效果监控
通过实施这些优化策略,能够显著提升 RocketMQ 的性能、可靠性和稳定性,满足不同业务场景的需求。在实际应用中,还需要根据具体的业务特点和性能瓶颈,持续调优,不断优化系统配置,才能充分发挥 RocketMQ 的潜力,构建一个高性能、高可用的消息队列系统。