【Linux】HTTP协议
一. 认识URL

- 域名解析
域名功能是隐藏底层的Ip地址,让用户方便记忆同时保证安全,互联网通信最终依赖IP地址来定位服务器,域名解析就是将 “域名” 转换为 “IP 地址” 的过程,一般浏览器自动完成 - 协议与端口的绑定
每个网络协议都有默认的端口,知名网络服务器和端口号必须一一对应的绑定,浏览器一般会内置域名的端口号
协议//域名+:端口号也可以直接访问网页,但一般默认内置了端口号所以不用加 - URL
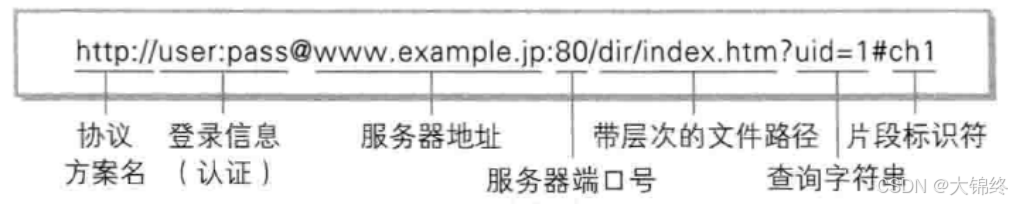
- 文件路径中第一个出现的/可能是网页的根目录或者是相对路径,域名包含在url字符串中(服务器地址)
- URL是统一资源定位符,所有网络上的资源都可以用唯一的url字符串标识到,并且可以用于获取资源
- urlencode和urldecode
url中存在特殊字符,一些情况下提交或获取数据本身可能包含与其冲突的特殊字符,这时候就需要转义编码。当数据需要放入 URL 或 HTTP 请求参数中时,必须先编码;当接收方需要解析这些数据时,必须对应解码。
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式(存在中文的转义)

例如+被转义成了 “%2B” - url编码和解码比较成熟了,一般在网上可以直接查找使用
二. HTTP协议格式
-
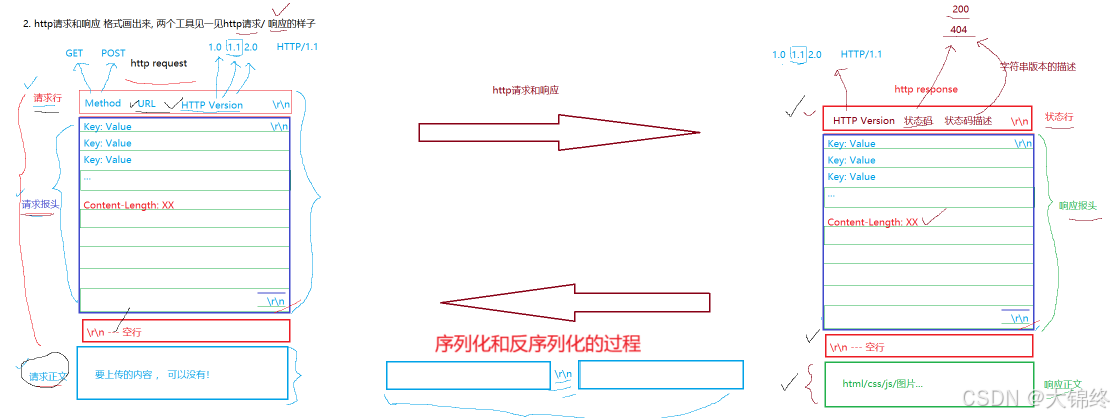
HTTP请求
首行: [方法] + [url] + [版本]
Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示该部分结束
Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度; -
HTTP响应
首行: [版本号] + [状态码] + [状态码解释]
Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示该部分结束
Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页面内容就是在body中. -
客户端访问服务器时,请求中User Agent代表这个客户端是合法安全的,带有操作系统版本等信息
telnate发送请求时,浏览器只会显示正文部分,其他信息由浏览器自行解析
将网页信息单独在文件中实现就不需要关服务器重新更新,下一次读取时会直接刷新
当访问url其中资源路径只有\时,不会把web根目录下的所有资源都返回,而是直返回网页
在浏览器输入承诺书是通过表单去提参的
三. http服务器简单实现
- 可以在Linux本地机器中使用telnet+主机号+端口号或直接使用浏览器充当客户端来访问自己实现的服务器,观察http请求和响应的信息
HttpServer.hpp
http的请求和响应本质上也是解析字符串来发送,log.hpp、Socket.hpp、makefile与复用前几篇文章的
#pragma once
#include<iostream>
#include<string>
#include<pthread.h>
#include<fstream>
#include<vector>
#include<sstream>
#include<sys/types.h>
#include<sys/socket.h>
#include<unordered_map>#include"Socket.hpp"
#include"log.hpp"
const int defaultport=8888;
const string wwwroot="./wwwroot";//预设网站本地根目录
const string sep="\r\n";
const string homepage="index.html";class HttpServer;//前向声明class ThreadData
{
public:ThreadData(int fd,HttpServer*s) :sockfd(fd),svr(s){}
public:int sockfd;HttpServer *svr;
};class HttpRequest
{
public:void Deserialize(std::string req)//反序列化{while(true){size_t pos=req.find(sep);//请求行之间通过\r\n分隔if(pos==string::npos) break;string temp=req.substr(0,pos);//左闭右开if(temp.empty()) break;req_header.push_back(temp);req.erase(0,pos+sep.size());//读取完情空当前报头,为下次做准备}text=req;}void Parse()//请求报头的解析{stringstream ss(req_header[0]);//作用1.数据类型转换 2.字符串拼接与分割ss>>method>>url>>http_version;//用 >> 操作符按空格分割提取信息file_path=wwwroot;if(url=="/"||url=="index.html")//默认首页请求{// ./wwwroot/index.htmlfile_path+="/";file_path+=homepage;}else file_path+=url;// /a/b/c/d.html->./wwwroot/a/b/c/d.html,其他路径请求auto pos=file_path.rfind(".");if(pos==string::npos) suffix=".html";else suffix=file_path.substr(pos);}void DebugPrint(){for(auto &line:req_header){//打印完整的原始请求cout<<"-----------------------------"<<endl;cout<<line<<"\r\n";}//打印解析后的结构化数据cout<<"method: "<<method<<endl;cout<<"url: "<<url<<endl;cout<<"http_version: "<<http_version<<endl;cout<<"file_path: "<<file_path<<endl;cout<<text<<endl;}
public:vector<string> req_header;//存取报头信息string text;//报头正文//解析之后的结果string method;string url;string http_version;string file_path;string suffix;//后缀,用于设置 HTTP 响应头的 Content-Type
};class HttpServer
{
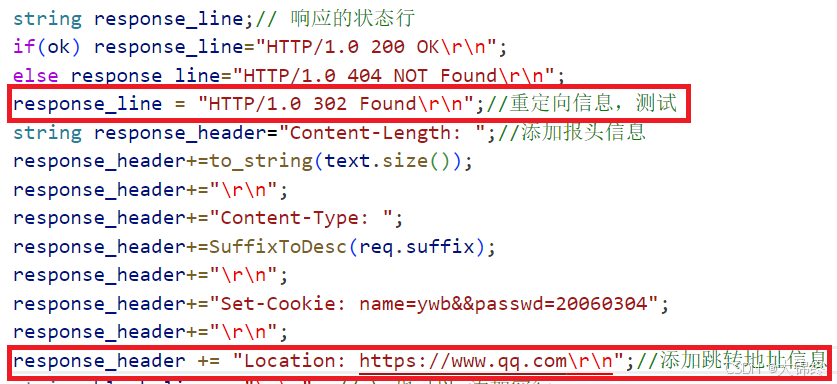
public:HttpServer(uint16_t port=defaultport) :port_(port){//存储对应关系,也可以直接把所有对应关系放到文件中,然后读取文件方式插入content_type.insert({".html", "text/html"});content_type.insert({".png", "image/png"});}bool Start(){listensock_.Socket();listensock_.Bind(port_);listensock_.Listen();while(true)//不断等待客户链接,创建线程去响应{string clientip;uint16_t clientport;int sockfd=listensock_.Accept(&clientip,&clientport);if(sockfd<0) continue;lg(Info, "get a new connect, sockfd: %d",sockfd);pthread_t tid;ThreadData *td=new ThreadData(sockfd,this);//打包线程运行时需要的多个参数pthread_create(&tid,nullptr,ThreadRun,td);}}static string ReadHtmlContent(const string &htmlpath)//读取文本内容{ifstream in(htmlpath,ios::binary);//以二进制方式打开文件并读取,内容保真不修改任何字节if(!in.is_open()) return "";in.seekg(0,ios_base::end); // 将文件指针移动到文件末尾auto len=in.tellg(); // 获取当前指针位置(即文件总字节数)in.seekg(0,ios_base::beg); // 将指针移回文件开头,准备读取string content;content.resize(len);in.read((char*)content.c_str(),content.size());// 一次性读取所有内容in.close();return content;//以下读取方式存在文本模式局限,二进制文件不适用,比如图片或视频,可能因换行符误判导致内容缺失// std::string content;// std::string line;// while(std::getline(in, line)) { content += line; }}string SuffixToDesc(string &suffix){auto iter = content_type.find(suffix);if(iter == content_type.end()) return content_type[".html"];else return content_type[suffix];}void HandlerHttp(int sockfd)//响应处理{char buffer[10240];ssize_t n=recv(sockfd,buffer,sizeof(buffer)-1,0);//bug??if(n>0){buffer[n]=0;//假设读到的就是一个完整独立的请求cout<<buffer<<endl;HttpRequest req;req.Deserialize(buffer);req.Parse();//req.DebugPrint();//返回响应的过程//采取硬编码的方式返回网页//string text="<html><body><h3>hello world</h3></body></html>";string text;//采取读取文本获取网页信息bool ok=true;text=ReadHtmlContent(req.file_path);if(text.empty()){ok=false;// 构建错误页面的路径(假设错误页面err.html放在wwwroot根目录下)string err_html=wwwroot;err_html+="/";err_html+="err.html";// 读取错误页面内容,覆盖texttext=ReadHtmlContent(err_html);}string response_line;// 响应的状态行if(ok) response_line="HTTP/1.0 200 OK\r\n";else response_line="HTTP/1.0 404 NOT Found\r\n";//response_line = "HTTP/1.0 302 Found\r\n";//重定向信息,测试string response_header="Content-Length: ";//添加报头信息response_header+=to_string(text.size());response_header+="\r\n";response_header+="Content-Type: ";response_header+=SuffixToDesc(req.suffix);response_header+="\r\n";response_header+="Set-Cookie: name=ywb";response_header+="\r\n";response_header+="Set-Cookie: hieght=185";response_header+="\r\n";response_header+="Set-Cookie: weight=150";response_header+="\r\n";//response_header += "Location: https://www.qq.com\r\n";//添加跳转地址信息string blank_line = "\r\n"; // \n也可以,添加空行string response=response_line;response+=response_header;response+=blank_line;response+=text;send(sockfd,response.c_str(),response.size(),0);}close(sockfd);}static void *ThreadRun(void *args){pthread_detach(pthread_self());//分离线程,让父进程不用等待ThreadData *td=static_cast<ThreadData *>(args);td->svr->HandlerHttp(td->sockfd);delete td;return nullptr;}~HttpServer(){}
public:Sock listensock_;uint16_t port_;unordered_map<string,string> content_type;//存储文件后缀名与HTTP响应头Content-Type的对应关系
};
HttpServer.cc
#include "HttpServer.hpp"
#include <iostream>
#include <memory>
#include<pthread.h>
#include"log.hpp"using namespace std;
int main(int argc,char*argv[])
{if(argc!=2) exit(1);uint16_t port=stoi(argv[1]);unique_ptr<HttpServer> svr(new HttpServer(port));svr->Start();return 0;
}index.html
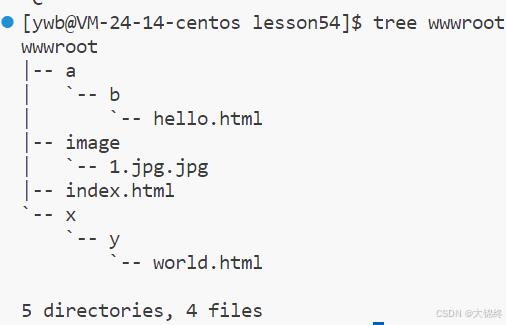
wwwroot 是服务器端用于存储待响应资源的根目录,是处理请求、生成响应的 “资源仓库”,(如 HTML 文件、图片目录 image 等)
<!-- //版本一: -->
<!-- <!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title>
</head>
<body><h1>这个是我们的首页</h1><h1>这个是我们的首页</h1><h1>这个是我们的首页</h1><h1>这个是我们的首页</h1><h1>这个是我们的首页</h1>
</body>
</html> --> <!-- //版本2:网页跳转 -------------------------------------------------------------->
<!-- <!DOCTYPE html>
<html><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title>
<style>
#header {background-color:black;color:white;text-align:center;padding:5px;
}
#nav {line-height:30px;background-color:#eeeeee;height:300px;width:100px;float:left;padding:5px;
}
#section {width:350px;float:left;padding:10px;
}
#footer {background-color:black;color:white;clear:both;text-align:center;padding:5px;
}
</style>
</head><body><div id="header">
<h1>网页跳转</h1>
</div><div id="nav">
</div><div id="section">
<h2>London</h2>
<p>
London is the capital city of England. It is the most populous city in the United Kingdom,
with a metropolitan area of over 13 million inhabitants.
</p>
<p>
Standing on the River Thames, London has been a major settlement for two millennia,
its history going back to its founding by the Romans, who named it Londinium.
</p>
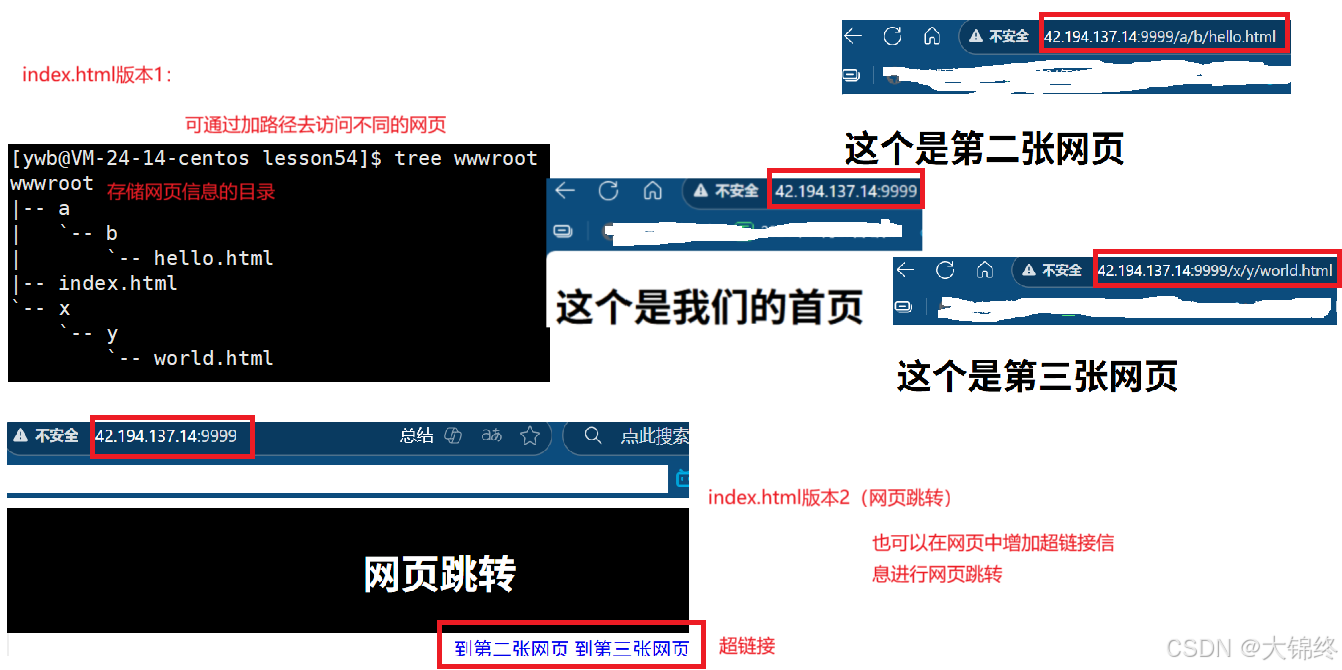
</div><a href="http://42.194.137.14:9999/a/b/hello.html">到第二张网页</a>
<a href="http://42.194.137.14:9999/x/y/world.html">到第三张网页</a><div id="footer">
Copyright ? W3Schools.com
</div></body>
</html> --><!-- 版本3:表单------------------------------------------------------ -->
<!-- <form action="action_page.php" method="post"><fieldset><legend>Personal information:</legend>name:<br><input type="text" name="name"><br>password:<br><input type="text" name="password"><br><br><input type="submit" value="Submit"></fieldset></form> --><!-- 版本4:插入图片 -->
<!DOCTYPE HTML>
<html><head><meta charset="UTF-8"></head>
<body><p>
<h1>这是本人的帅照:</h1>
<img src="/image/1.jpg.jpg" width="128" height="128" />
<!-- <img src="/image/1.jpg.jpg" width="128" height="128" />
<img src="/image/1.jpg.jpg" width="128" height="128" /></p></body>
</html>
测试1:显示网页信息+网页跳转
- 由于网页信息涉及到前端内容,我们主要是后端写服务器的所以可以直接上w3school网站去查找现成的前端网页代码,直接使用测试服务器能正常运行就行
测试2:网页中提交参数
- 在使用网站时(http/https),我们都是通过表单将数据提交給服务器的,再由服务器响应浏览器解析后在网页中显示。同样可直接使用w3school网站的表单网页代码
- url字符串参数中可以带?,?后可以带参数,是你查询的内容本质上是kv键值对
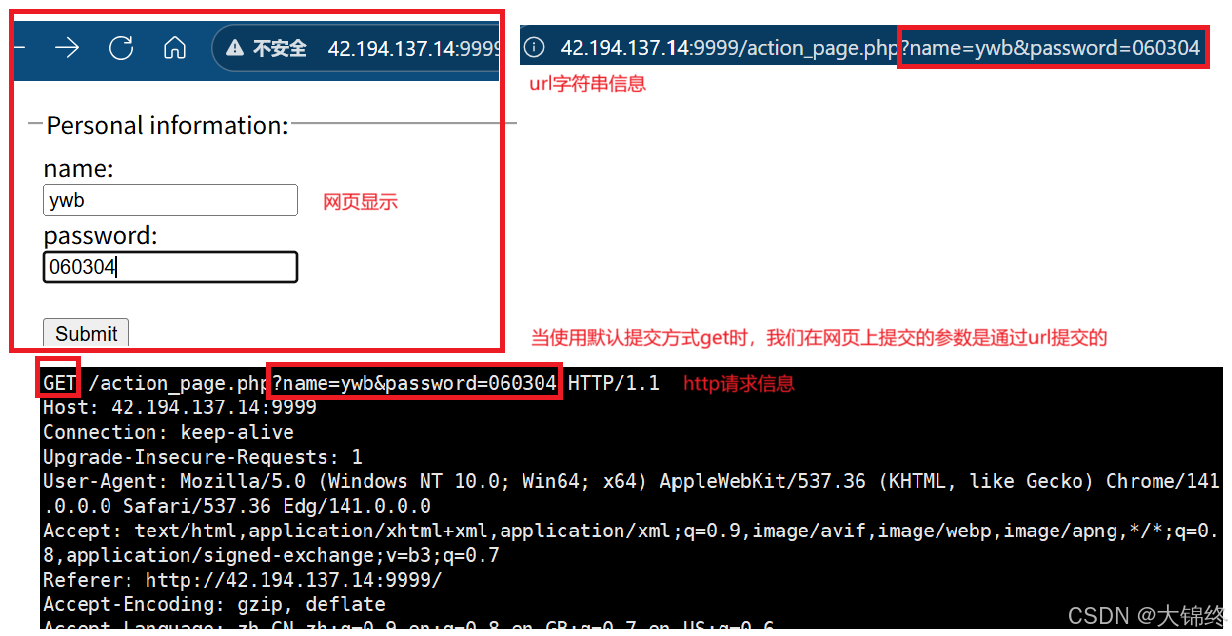
测试3:网页中显示图片
- 用rz指令从本地计算机向远程服务器传输文件的指令(sz 用于从远程服务器下载文件到本地),将图片上传到对应路径中,去W3School中找一个前端显示网页图片的代码,测试服务器是否能正确响应图片
- -b:以二进制方式传输(避免文本文件换行符转换问题,推荐传输非文本文件时使用)。
-e:以 ASCII 方式传输(适用于纯文本文件)
四. http报文细节
http中请求行的方法
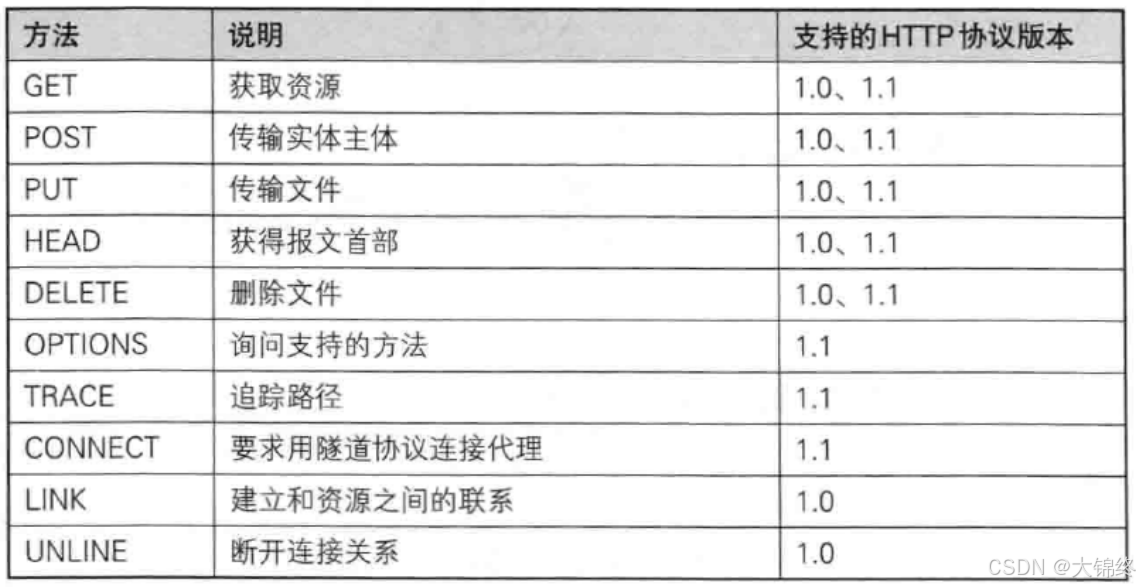
- 在网络中我们的行为主要是从网络中获取信息和向网络上传信息,所以最常用的是get和post方法
- 向网络中发送信息一般使用post方法,但是在网络中提交参数获取服务器响应的信息时,使用post和get方法都可以,存在以下差别:
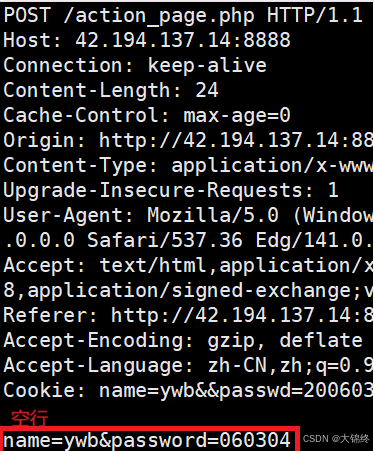
这是通过POST方法传参,采用正文提交参数的方式,相对于GET方法更私密一些。GET方法的提参在测试2中展示过了,参数数量首先(url字符串中有长度限制),不私秘(直接在url中显示了)
http响应中状态码
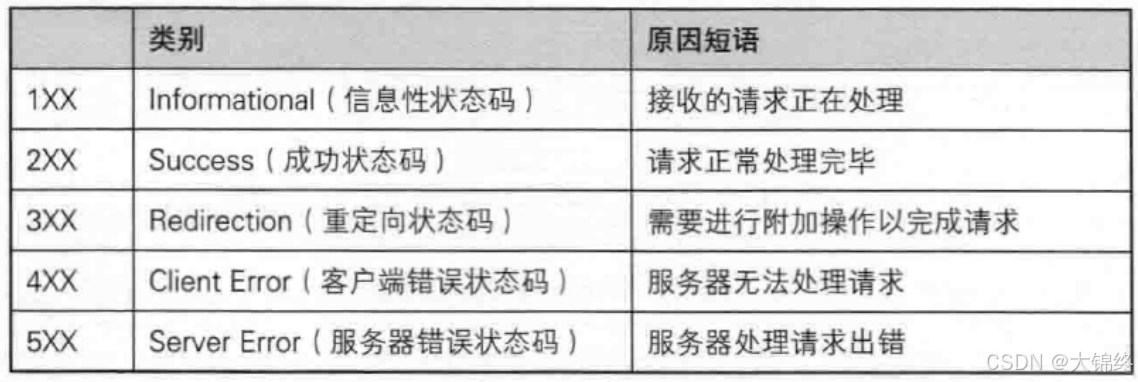
最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
- 重点解释一下3xx重定向状态码
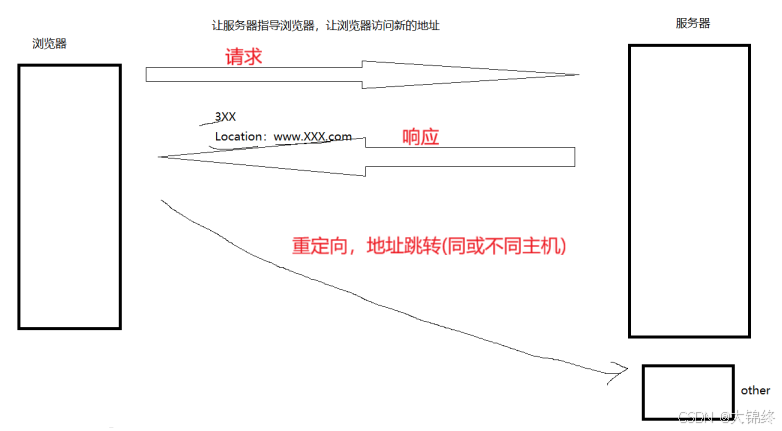
重定向又分为临时重定向和永久重定向 - 当服务器返回 3xx 系列状态码(如代码中的302 Found)时,会在响应头中通过Location字段指定新的目标地址。浏览器在收到这样的响应后,会自动向Location指定的地址发起新的请求,从而实现 “自动跳转”
常见Header
Content-Type: 数据类型(text/html等)
Content-Length: Body的长度
Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
User-Agent: 声明用户的操作系统和浏览器版本信息;
referer: 当前页面是从哪个页面跳转过来的;
location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
- connection信息:
keep-alive:表示希望保持当前 TCP 连接,后续请求可复用该连接,避免频繁建立和关闭连接的开销,是 HTTP/1.1 的默认行为。
close:表示本次请求 / 响应完成后,立即关闭当前 TCP 连接,适用于只需要单次交互的场景。
其他扩展值:有时会携带其他头字段名(如 Connection: Upgrade),用于触发协议升级(如从 HTTP 切换到 WebSocket) - connection的使用场景:
一个网页中会包含非常多的元素,每一个元素就是一个资源,每次打开网页会不断向服务器请求资源(存在优化和缓存机制),所以我们才能看到网页中那么多的广告、新闻或者商品,显示的图片和文字都是响应后的资源。
而一次请求响应一个资源就关闭连接,称为短连接,http\1.0默认支持;建立一个TCP连接,发送和返回多个http的request和response,称为长连接,这些就是connection报头要表示的信息
所以请求和响应中都要带有http版本信息,看是否都支持长连接
cookie
- http协议是默认无状态的,可理解为服务器不会主动记住任何一次http请求的信息,通俗理解你今天登录b站刷视频,退出后明天再看的时候要重新登录

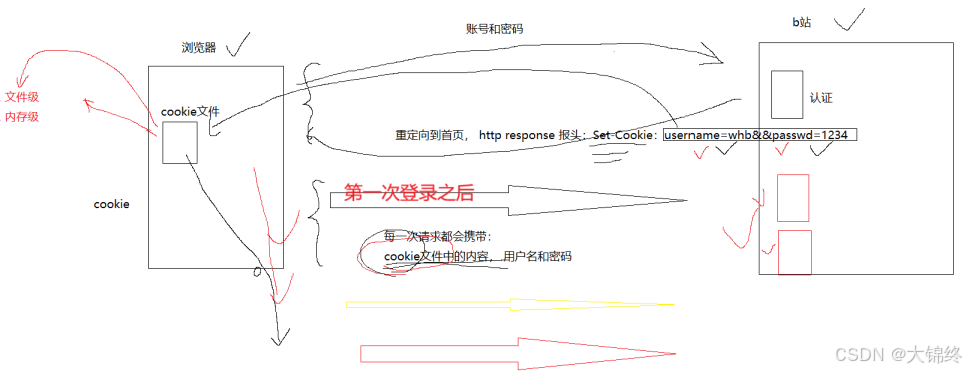
- 当在服务器中第一次登录后,会返回用户登录信息到浏览器,cookie是浏览器中专门保存这些信息的文件,起到对用户的会话保持功能,也就是说在有效期内每次访问时不需要再重新登录,由浏览器、服务器基于http协议自动完成,非常方便

Cookie 的Path属性用于指定 “该 Cookie 在哪些路径下的请求会被携带”。默认情况下,Cookie 的Path为生成它的资源所在的路径(比如请求/image/1.jpg时,若服务器设置 Cookie 未指定Path,则该 Cookie 的Path会被设为/image);而网页的 “根目录 Cookie” 通常是在请求 HTML 页面(如/index.html)时生成的,其Path默认为/
- 但也存在cookie被盗取和个人信息泄漏的问题,由于cookie是保存在浏览器中的,不法分子可以各种手段来盗取私人的cookie信息,这样就可以以被盗者的身份来访问一些软件和网站,为了提高安全性,一般采取cookie-session的解决方案
cookie-session
- 用户在服务器上的一些软件或网站进行第一次登录时,在服务端会形成一个session文件,存储用户与登录相关的合法性信息,同时服务器会为每一个session文件生成一个session id并以此命名session文件,此时与单独使用cookie的解决方案不同,不再返回用户相关登录信息如用户名密码之类的,而是返回session id,由于服务器可以同时允许多人登录,所以对所产生的每一个session文件都要进行管理,先描述再组织!对session文件的管理就变成了对数据结构的管理,在企业一般使用redis来进行管理。当用户再进行登录时,浏览器基于http协议就会向服务器发送session id,此时服务器进行检查,若存在就允许访问。
- 那么是如何提高安全性的?session id是由服务器统一管理分配的,会存在一些安全检查机制,比如登录地和登录时间、不同登录设备,当检查到异常时会要求用户重新登录,所以安全等级会更高一些。
- 服务端的不断完善,还是抵挡不了客户端中个人信息被恶意盗取。以上讲述理论,没有进行代码验证