Rust宏编程完全指南:从基础到高级的元编程艺术
1. 引言:探索Rust元编程的威力
在编程语言的发展历程中,元编程一直是提升开发效率和代码表现力的重要手段。Rust的宏系统将这一理念推向新的高度,它不仅是简单的文本替换工具,更是集成在编译器内部的语法扩展机制。通过宏,开发者可以在编译期生成代码、创建领域特定语言(DSL),甚至实现复杂的编译时计算。
与C/C++的预处理器宏相比,Rust宏具有卫生性(Hygiene)、类型感知能力和语法树集成等独特优势。这些特性使得Rust宏既强大又安全,能够在保持代码质量的同时显著减少重复工作。本文将深入探讨Rust宏的各个方面,从基础的声明式宏到高级的过程式宏,为你揭示Rust元编程的完整图景。
2. 宏系统架构概览
在深入具体语法之前,让我们先了解Rust宏系统的整体架构:
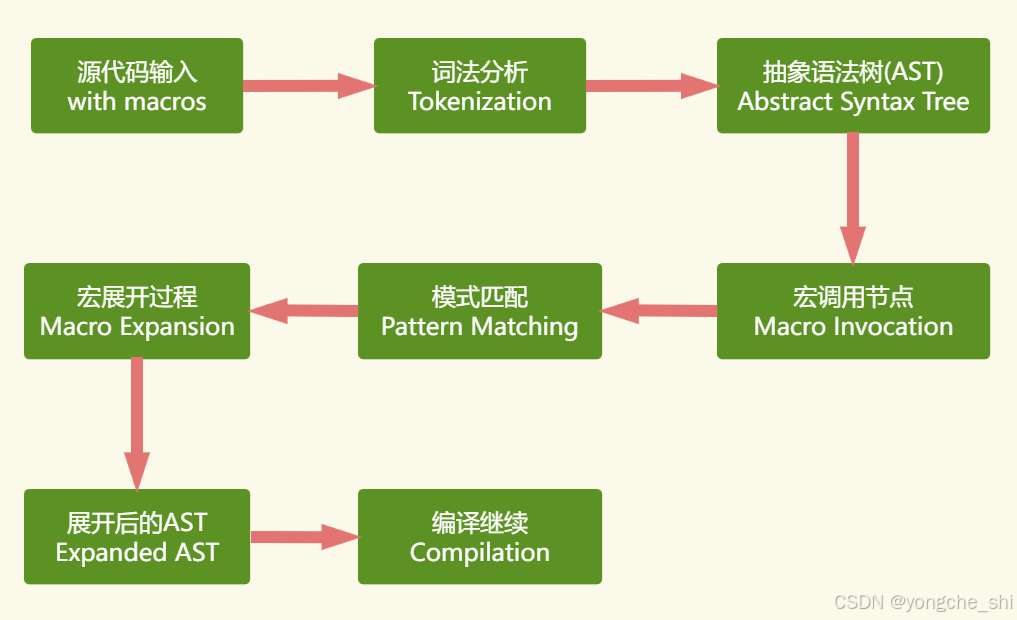
图1:Rust宏处理流程概览
这个架构图展示了宏在编译过程中的位置:源代码首先被解析为抽象语法树,识别出的宏调用会触发相应的宏展开过程,最终生成展开后的AST供后续编译步骤使用。
3. 声明式宏:模式匹配的艺术
3.1 基础语法与结构
声明式宏使用macro_rules!关键字定义,其核心是基于模式的代码生成:
macro_rules! vec {// 基础情况:空向量() => {Vec::new()};// 重复模式:一个或多个元素($($x:expr),+ $(,)?) => {{let mut temp_vec = Vec::new();$(temp_vec.push($x);)+temp_vec}};// 重复模式:指定数量的相同元素($elem:expr; $count:expr) => {{let count = $count;let mut temp_vec = Vec::with_capacity(count);for _ in 0..count {temp_vec.push($elem.clone());}temp_vec}};
}
3.2 模式匹配的工作原理
声明式宏的匹配过程可以理解为一种语法树模式匹配:
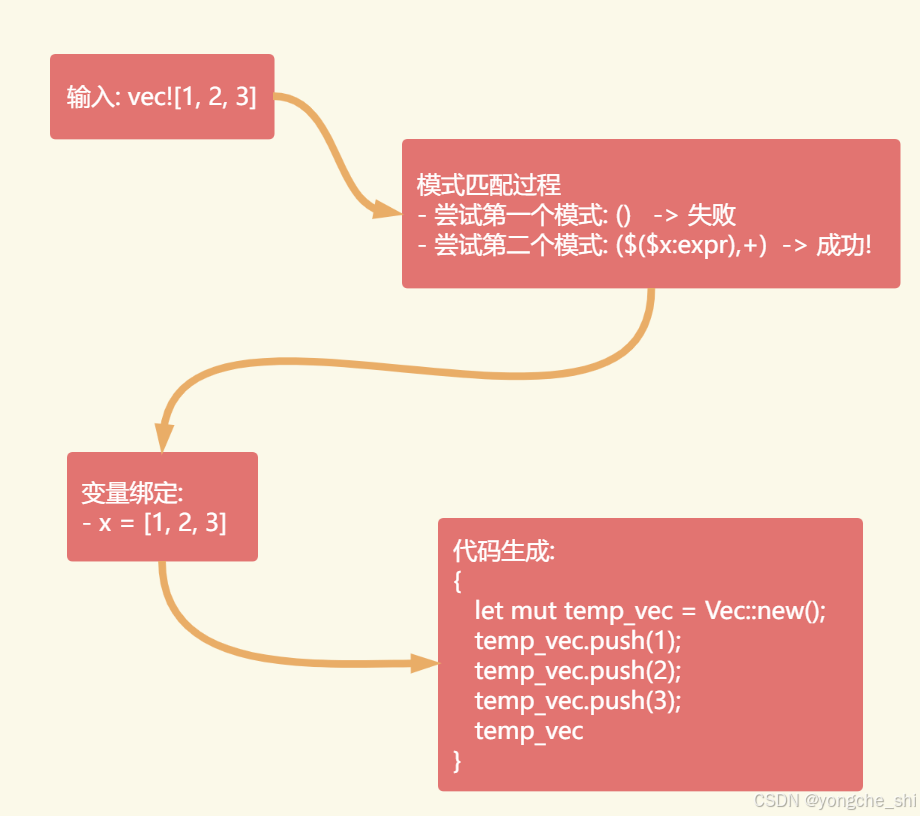
图2:声明式宏模式匹配过程
3.3 重复模式与卫生性
Rust宏的卫生性确保宏内部引入的标识符不会意外污染外部命名空间:
macro_rules! counter {($name:ident) => {{let mut $name = 0;|| {$name += 1;$name}}};
}fn main() {let counter1 = counter!(count); // 创建一个计数器let counter2 = counter!(count); // 创建另一个独立的计数器println!("Counter1: {}", counter1()); // 输出: 1println!("Counter2: {}", counter2()); // 输出: 1// 两个count变量是不同的,互不干扰
}
4. 过程式宏:编译期代码生成
4.1 过程式宏的类型与架构
过程式宏在单独的编译过程中运行,允许在编译期间执行任意Rust代码来生成新的代码:
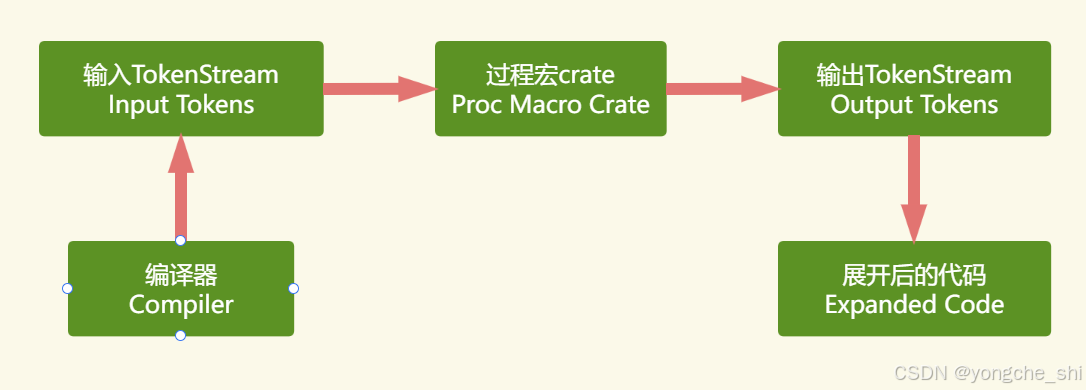
图3:过程式宏执行环境
4.2 派生宏(Derive Macros)
派生宏是最常用的过程宏类型,用于自动为结构体或枚举实现trait:
// 在Cargo.toml中启用过程宏
// [lib]
// proc-macro = trueuse proc_macro::TokenStream;
use quote::quote;
use syn::{parse_macro_input, DeriveInput};#[proc_macro_derive(HelloWorld)]
pub fn hello_world_derive(input: TokenStream) -> TokenStream {let input = parse_macro_input!(input as DeriveInput);let name = input.ident;let expanded = quote! {impl HelloWorld for #name {fn hello_world() {println!("Hello, World! My name is {}", stringify!(#name));}}};TokenStream::from(expanded)
}
4.3 派生宏的详细处理流程
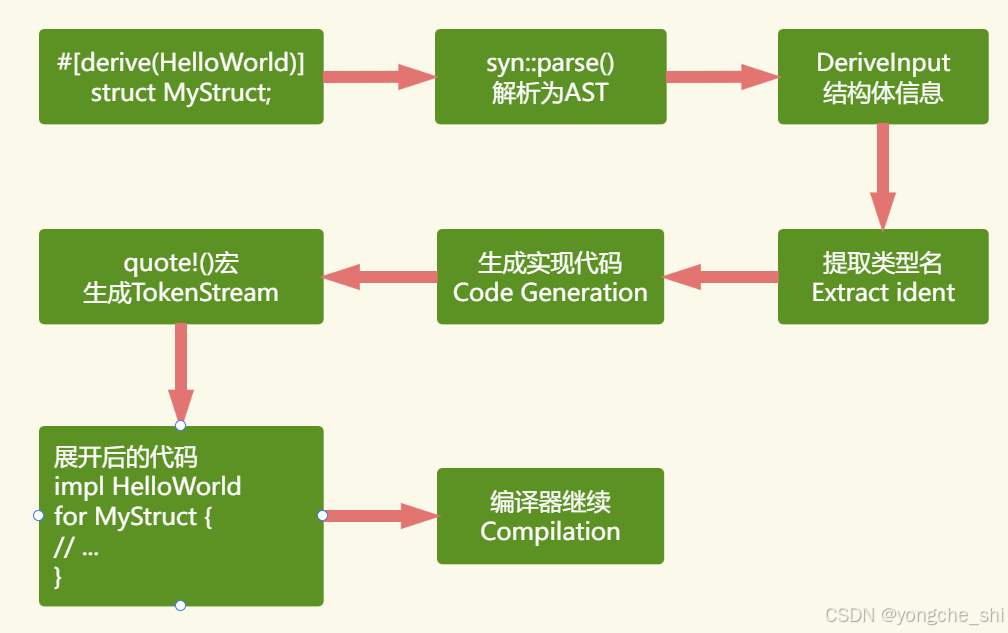
图4:派生宏的完整处理流程
4.4 属性宏(Attribute Macros)
属性宏允许为任意项添加自定义属性,常用于框架和库的开发:
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {let args = parse_macro_input!(attr as AttributeArgs);let input = parse_macro_input!(item as ItemFn);let fn_name = &input.sig.ident;// 解析路径和方法let (path, method) = parse_route_attributes(args);let expanded = quote! {#input// 自动注册到路由系统inventory::submit! {RouteRegistration {path: #path.to_string(),method: #method.to_string(),handler: stringify!(#fn_name),}}};TokenStream::from(expanded)
}
4.5 函数式过程宏(Function-like Procedural Macros)
函数式过程宏提供类似声明式宏的调用语法,但具有更强大的处理能力:
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {let input_str = input.to_string();// 解析SQL查询,进行语法验证let validated_sql = validate_sql_syntax(&input_str).unwrap_or_else(|e| panic!("SQL语法错误: {}", e));// 生成优化的查询结构let expanded = generate_optimized_query(&validated_sql);TokenStream::from(expanded)
}
5. 高级宏技巧与模式
5.1 递归宏
宏可以递归调用自身,用于处理可变长度的参数列表或嵌套结构:
macro_rules! calculate {// 基础情况:单个值($x:expr) => { $x };// 递归情况:加法($x:expr, + $($rest:tt)*) => {$x + calculate!($($rest)*)};// 递归情况:乘法 ($x:expr, * $($rest:tt)*) => {$x * calculate!($($rest)*)};
}// 使用示例
let result = calculate!(1, + 2, * 3, + 4); // => 1 + 2 * 3 + 4 = 11
5.2 增量TT muncher模式
TT(Token Tree)咀嚼器模式用于逐步处理输入标记:
macro_rules! parse_args {// 基础情况:处理最后一个参数(@inner $acc:expr, $arg:expr) => {$acc.process($arg)};// 递归情况:处理参数并继续(@inner $acc:expr, $arg:expr, $($rest:tt)*) => {parse_args!(@inner $acc.process($arg), $($rest)*)};// 公开接口($($args:tt)*) => {parse_args!(@inner ArgumentProcessor::new(), $($args)*)};
}
5.3 宏的调试与测试
调试宏需要特殊的工具和技术:
// 使用log_syntax!宏调试(仅限nightly)
#![feature(log_syntax)]
macro_rules! debug_macro {($($t:tt)*) => {log_syntax!($($t)*); // 在编译时输出参数};
}// 使用cargo-expand查看宏展开
// $ cargo install cargo-expand
// $ cargo expand#[cfg(test)]
mod tests {use super::*;#[test]fn test_builder_macro() {let builder = MyStruct::builder();// 测试宏生成的代码}
}
6. 性能优化与最佳实践
6.1 编译期性能考虑
宏虽然强大,但不当使用会影响编译时间。以下是一些优化建议:
// 优化:避免在宏内进行重复计算
macro_rules! optimized_hash_map {($($key:expr => $value:expr),* $(,)?) => {{// 预先计算容量提升性能let capacity = [$(stringify!($key)),*].len();let mut map = std::collections::HashMap::with_capacity(capacity);$(map.insert($key, $value);)*map}};
}// 反例:每次展开都重新计算
macro_rules! unoptimized_hash_map {($($key:expr => $value:expr),*) => {{let mut map = std::collections::HashMap::new(); // 动态扩容$(map.insert($key, $value);)*map}};
}
6.2 错误处理与诊断
在过程宏中提供清晰的错误信息至关重要:
fn derive_builder(input: DeriveInput) -> Result<TokenStream, syn::Error> {let struct_name = &input.ident;// 验证输入let fields = match input.data {Data::Struct(data) => data.fields,_ => {return Err(syn::Error::new_spanned(struct_name,"Builder宏只能用于结构体"));}};// 生成代码...Ok(expanded.into())
}
7. 实际应用案例分析
7.1 Serde框架中的宏应用
Serde是Rust中最著名的序列化框架,其宏系统设计精妙:
#[derive(Serialize, Deserialize)]
struct User {#[serde(rename = "userName")]name: String,#[serde(skip_serializing_if = "Option::is_none")]email: Option<String>,#[serde(default = "default_age")]age: u32,
}// Serde宏生成的代码包括:
// - 序列化实现
// - 反序列化实现
// - 字段自定义处理
// - 默认值处理
7.2 Web框架中的路由宏
现代Rust Web框架大量使用属性宏来定义路由:
#[derive(RocketRoute)]
#[get("/users/<id>")]
fn get_user(id: i32) -> Json<User> {// 宏自动处理:// - 路由注册// - 参数解析// - 错误处理// - 响应序列化
}
8. 宏的局限性与替代方案
虽然宏功能强大,但也有其局限性:
-
编译时间:复杂宏会增加编译时间
-
调试难度:宏展开后的代码难以调试
-
学习曲线:宏编程需要深入理解Rust语法树
在某些场景下,可以考虑以下替代方案:
// 替代方案1:使用泛型和trait
trait Builder {type Output;fn build(self) -> Self::Output;
}// 替代方案2:使用声明宏处理简单重复
macro_rules! impl_getter {($field:ident) => {pub fn $field(&self) -> &str {&self.$field}};
}
9. 总结与展望
Rust宏系统代表了元编程技术的现代演进,它将编译期代码生成的能力与语言的安全性紧密结合。通过掌握声明式宏和过程式宏,开发者可以:
-
消除样板代码:自动生成重复的模式代码
-
创建领域特定语言:为特定问题设计专用语法
-
实现编译期优化:在编译时完成计算和验证
-
增强代码安全性:通过宏生成额外的编译期检查
随着Rust语言的发展,宏系统也在不断进化。未来的改进可能包括:
-
更好的调试工具:更直观的宏展开查看器
-
性能优化:更高效的宏展开算法
-
错误诊断:更友好的宏错误信息
掌握宏编程是成为Rust专家的关键一步。虽然学习曲线较陡峭,但投入时间学习宏将为你打开Rust编程的新维度,让你能够编写出更加表达力强、性能优异且易于维护的代码。
记住宏的使用原则:在普通函数和泛型无法优雅解决问题时使用宏。合理使用宏,让你的Rust代码达到新的高度!