ASR+TTS
概述
关于ASR和TTS模型,之前汇总过:
- 语音转文本ASR工具合集
- 文本转语音TTS工具合集(上)
- 文本转语音TTS工具合集(下)
Chatterbox
Resemble AI推出的开源(GitHub,14K Star,1.8K Fork)项目Chatterbox,摘下首个支持情感夸张控制的开源TTS桂冠,更在盲测中击败ElevenLabs等商业系统,重新定义开源语音合成的技术天花板。HF Demo,Demo。
从阿拉伯语的喉音到斯瓦希里语的节奏,从韩语的语调起伏到中文的四声变化,基于0.5B Llama架构的模型展现出惊人的跨语言能力。不同于传统多语言模型需要为每种语言单独微调,采用一次训练全语言覆盖策略,通过对齐训练技术让不同语言共享底层语音特征。实测显示,在无参考音频时,模型生成的日语发音自然度达到母语者可接受水平;切换至阿拉伯语时,能自动适配从右至左的语言特性带来的韵律变化。这种能力源自其独特的"对齐感知推理"机制,可动态调整音素时长与语调曲线。
零样本语音克隆:只需3-5秒的参考音频,就能捕捉说话人的声纹特征、语速习惯甚至微表情带来的语调变化。在对比测试中,78%的听众无法区分克隆语音与真人原声。技术实现上,模型通过Perceiver模块提取参考音频的深层特征,结合S3 Tokenizer的音素解析,在保持内容清晰度的同时,完美复刻说话人的个性特质。这种克隆能力可无缝迁移到23种语言,既能保持原语言的声线,又符合新语言的发音规则。
引入情感夸张控制为语音合成带来新维度,通过简单调整参数:
- 将exaggeration调至0.7,可生成戏剧化的播报语气
- 降低
cfg_weight至0.3,配合0.5的exaggeration,能模拟娓娓道来的讲述风格 - 极端值组合(exaggeration=2.0+
cfg_weight=0.1)甚至可生成动画角色般的夸张语音
这种可控性源自模型独特的双路径架构:文本编码器负责语义准确性,语音风格编码器则处理情感表达,两者通过交叉注意力机制动态融合。
作为生产级开源项目,内置多项企业级特性:
- PerTh水印技术:所有生成音频含不可察觉水印,支持MP3压缩和剪辑后仍可检测
- 超低延迟:优化后的推理管线可实现200ms以内响应,满足实时交互需求
- 稳定性保障:通过50万小时清洗数据训练,极端文本输入也能避免崩音
安装:pip install chatterbox-tts
VibeVoice
技术报告,微软开源,9.8K Star,1.2K Fork,专注于生成长时、多说话人、高表现力的对话式音频,支持长达90分钟、包含4名说话人的复杂对话场景。VibeVoice-1.5B TTS。
特性:
- 超低帧率连续语音Tokenize,双Tokenizer架构:
- 声学Tokenizer:保留音色、韵律等声学特征;
- 语义Tokenizer:捕捉对话上下文语义
- 混合生成框架
- LLM理解上下文:大型语言模型解析文本语义与对话结构,确保逻辑连贯性
- 扩散模型生成细节:基于扩散模型的解码器合成高保真声学细节,实现接近人声的自然度
- 多说话人控制:通过说话人嵌入向量(Speaker Embedding)区分角色,在长对话中维持不同说话人的音色稳定性,突破传统TTS的1-2人限制。
TEN
官网,开源(GitHub,8.4K Star,972 Fork)、支持实时对话、多模态输入与输出、ASR+TTS、多模型支持(远端+本地)、Dify+Coze+OceanBase PowerRAG集成、MCP集成、多平台、多语言SDK。体验。
体验
模型切换
可和第三方平台集成:

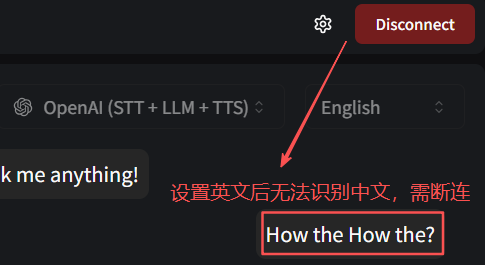
体验下来的几个问题:
- 需提前设置好待识别语音
- ASR识别不太准确
- 未提供submit提交按钮,导致一句话没说完自动发起Query
- TTS表现不太行,如断句,中英文混杂发音
如下图,系统默认语言为英文,中文语言强制识别为英文,错误百出:
支持本地部署:
docker
# 源码
git clone
cd TEN-framework
cp .env.example .env
vim .env
# 构建
task use
# 启动
task run
WhisperLiveKit
基于OpenAI Whisper的开源(GitHub,8K Star,730 Fork)实时语音转录框架,WhisperLiveKit完美诠释现代语音处理系统的三大核心要素:
- 算法先进性
- 集成2025年最新SOTA算法SimulStreaming
- 支持WhisperStreaming (2023 SOTA)实时处理
- 融合Streaming Sortformer说话人识别技术
- 工程实用性
- 支持多种Whisper后端:原版、faster-whisper、MLX-whisper
- WebSocket实时通信架构
- 企业级并发处理能力
- 商业应用价值
- 会议转录、客服系统、教育平台
- 多语言支持,全球化部署就绪
- 开源免费,降低企业成本
架构
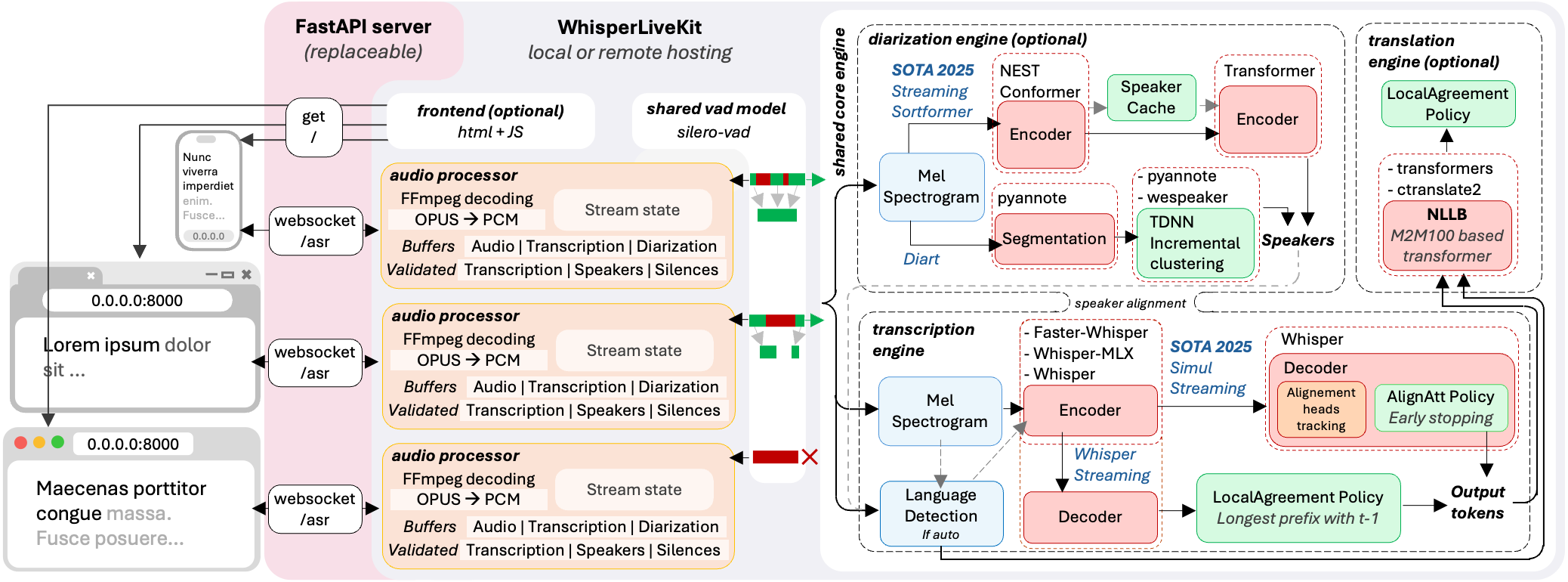
实战
实时流式处理架构
from whisperlivekit import TranscriptionEngine, AudioProcessor
import asyncioclass RealTimeTranscriber:def __init__(self):self.engine = TranscriptionEngine(model="medium",diarization=True, # 说话人识别language="auto" # 自动语言检测)async def process_stream(self, audio_stream):"""实时处理音频流的核心逻辑"""processor = AudioProcessor(transcription_engine=self.engine)async for result in processor.stream_transcribe(audio_stream):yield {"text": result.text,"confidence": result.confidence,"speaker": result.speaker_id,"timestamp": result.timestamp}
WebSocket全双工通信实现
from fastapi import FastAPI, WebSocket
from contextlib import asynccontextmanager@asynccontextmanager
async def lifespan(app: FastAPI):# 应用启动时初始化AI引擎global transcription_enginetranscription_engine = TranscriptionEngine(model="large-v3")yield# 应用关闭时清理资源app = FastAPI(lifespan=lifespan)@app.websocket("/realtime-asr")
async def websocket_endpoint(websocket: WebSocket):await websocket.accept()audio_processor = AudioProcessor(transcription_engine)try:while True:# 接收音频数据audio_data = await websocket.receive_bytes()# 实时转录result = await audio_processor.transcribe_chunk(audio_data)# 立即返回结果await websocket.send_json({"type": "transcription","data": result})except WebSocketDisconnect:print("客户端断开连接")
多模型性能优化策略
# 1. 开发测试环境 - 追求速度
whisperlivekit-server --model tiny --language en
# 2. 生产环境 - 平衡性能
whisperlivekit-server --model medium --diarization --warmup-file warmup.wav
# 3. 高精度场景 - 追求准确度
whisperlivekit-server --model large-v3 --language auto --ssl-certfile cert.pem
前端集成
// 现代化的前端实现
class MeetingAssistant {constructor() {this.websocket = new WebSocket('ws://localhost:8000/asr');this.mediaRecorder = null;this.transcripts = [];}async startRecording() {const stream = await navigator.mediaDevices.getUserMedia({audio: true});this.mediaRecorder = new MediaRecorder(stream);this.mediaRecorder.ondataavailable = (event) => {if (event.data.size > 0) {this.websocket.send(event.data);}};this.websocket.onmessage = (event) => {const result = JSON.parse(event.data);this.displayTranscript(result);};this.mediaRecorder.start(1000); // 每秒发送一次数据}displayTranscript(result) {const transcriptDiv = document.getElementById('transcripts');transcriptDiv.innerHTML += `<div class="transcript-item"><span class="speaker">${result.speaker_id || '未知说话人'}</span><span class="text">${result.text}</span><span class="time">${new Date(result.timestamp).toLocaleTimeString()}</span></div>`;}
}
// 使用
const assistant = new MeetingAssistant();
document.getElementById('start-btn').onclick = () => assistant.startRecording();
会议纪要生成
# 添加会议纪要生成功能
import openai
from datetime import datetimeclass MeetingSummarizer:def __init__(self):self.transcripts = []self.client = openai.OpenAI()def add_transcript(self, text, speaker, timestamp):self.transcripts.append({'speaker': speaker,'text': text,'timestamp': timestamp})def generate_summary(self):meeting_text = "\n".join([f"{t['speaker']}: {t['text']}" for t in self.transcripts
])response = self.client.chat.completions.create(model="gpt-3.5-turbo",messages=[{"role": "user","content": f"请为以下会议内容生成结构化纪要:\n{meeting_text}"}])return response.choices[0].message.content
NeuTTS Air
HF,开源(GitHub,3.7K Star,352 Fork),Neuphonic发布的NeuTTS Air,基于Qwen 0.5B构建,CPU可运行、具备即时语音克隆能力,只支持英文?
特性:
- 超真实语音:尽管体积不大,输出的语音在自然度与人声接近程度上表现优异;
- 本地运行:提供GGUF/GGML格式模型,可在CPU上推理,适合手机、笔记本、树莓派等设备;
- 即时语音克隆:仅需约3秒钟参考音频,就能生成该说话人的音色与语调;
- 轻量且高效架构:采用语言模型+编解码器的组合设计,成为在速度、质量和资源占用之间的折中方案;
- 水印机制:所有生成音频都带有Perth(水印机制),用于责任追踪与版权保护;
- 优化功耗与延迟:针对移动与嵌入式设备做功耗优化与实时推理优化。
用户只需要提供两类输入:一段参考语音(即样本音频)与目标文本。模型从参考语音中提取音色、语调特征,再将输入文本合成出与之匹配的语音。
技术:
- 音频编解码器:NeuCodec,专有神经音频编解码器,使用单个码本在低比特率下实现卓越的音频质量;
实战
安装:
git clone https://github.com/neuphonic/neutts-air.git
cd neuttsair
pip install -r requirements.txt
# 安装espeak
https://github.com/espeak-ng/espeak-ng/blob/master/docs/guide.md
命令行示例:
python -m examples.basic_example --input_text "..." --ref_audio samples/dave.wav --ref_text samples/dave.txt
SDK
from neuttsair.neutts import NeuTTSAir
import soundfile as sftts = NeuTTSAir( backbone_repo="neuphonic/neutts-air-q4-gguf", backbone_device="cpu", codec_repo="neuphonic/neucodec", codec_device="cpu")
input_text = "..."ref_text = "samples/dave.txt"
ref_audio_path = "samples/dave.wav"ref_text = open(ref_text, "r").read().strip()
ref_codes = tts.encode_reference(ref_audio_path)wav = tts.infer(input_text, ref_codes, ref_text)
sf.write("test.wav", wav, 24000)
最佳实践:
- 参考音频样本:单声道,16-44 kHz采样率,时长3至15秒,
.wav格式,干净(无背景噪音极小甚至没有),自然连续的语音——就像独白或对话一样,几乎没有停顿,因此模型可有效地捕捉语调。
Step-Audio-2
阶跃星辰开源(GitHub,1.2K Star,83 Fork),论文。
系列包括两款模型
- Mini
- Mini-Base
可处理从语音输入到语音输出的完整交互链,包括语义理解、副语言信息捕捉、工具调用等。能力包括:语音识别、语音翻译(文本输出和语音输出)、语音理解、多轮语音问答(文本输出和语音输出)等。
Paralinguistic information understanding,副语言信息理解,包括:Gender、Age、Timbre、Scenario、Event、Emotion、Pitch、Rhythm、Speed、Style、Vocal。
URO-Bench,understanding, reasoning, and oral conversation。
Sayathing
KanthorLabs开源(GitHub,68 Star)的TTS平台,使用先进的AI模型,结合Kokoro TTS引擎。
核心模块:
- HTTP服务:基于FastAPI构建的REST API
- 任务队列:使用SQLite实现的后台任务处理系统
- TTS引擎:集成强大Kokoro TTS语音合成引擎
- 数据库:采用SQLAlchemy ORM和异步SQLite
- 依赖注入:通过容器管理服务,模块之间解耦清晰
| 功能 | 说明 |
|---|---|
| RESTful API | 提供清晰的API接口,方便调用 |
| 异步处理 | 支持后台任务队列,高效处理多个请求 |
| 多种音色 | 提供多种语音风格和语言选择 |
| Web控制台 | 可视化监控任务状态和系统运行情况 |
| Docker支持 | 支持容器化部署,易于上线 |
| 依赖注入 | 架构清晰,模块化设计 |
| 高并发支持 | 多worker架构,轻松应对高并发 |
| 稳定性强 | 内置重试机制和错误处理 |
实战
支持多种安装方式:
git clone https://github.com/kanthorlabs/sayathing.git
cd sayathing
# 基于uv
uv sync
uv run python main.py
# 基于pip
python -m venv venv
source venv/bin/activate
pip install -e .
python main.py
# 基于Docker
docker build -t sayathing .
docker run -p 8000:8000 sayathing
浏览器打开http://localhost:8000/ui/dashboard查看Web UI,打开http://localhost:8000/docs查看REST API文档。
curl命令:
# 获取支持的语音列表
curl "http://localhost:8000/api/voices"
# tts
curl -X POST "http://localhost:8000/api/tts" \-H "Content-Type: application/json" \-d '{"text": "Hello, world! This is SayAThing speaking.","voice_id": "kokoro.af_heart"}'
其他命令
# 测试
make test # 运行所有测试
make test-coverage # 带覆盖率的测试
make test-integration # 集成测试
make check # 代码检查 + 测试
# 开发
uv run python main-dev.py # 自动重载的开发服务器
# 参数
uv run python main.py --primary-workers 2 --retry-workers 1 # 指定 worker 数量
uv run python main.py --no-http # 只运行后台任务
uv run python main.py --help # 查看帮助信息
LFM2-Audio
Liquid AI推出LFM2-Audio-1.5B,一款紧凑的音频-语言基础模型,能够通过单一的端到端架构理解和生成语音与文本。旨在为资源受限的设备提供低延迟、实时助手功能,同时将LFM2家族扩展到音频领域,保持小巧的体积。
将1.2B参数的LFM2语言骨干网络扩展到音频和文本,将它们视为一级序列标记。该模型分离音频表示:输入是直接从原始波形块(约80毫秒)投影的连续嵌入,而输出是离散的音频代码。避免输入路径上的离散化伪影,同时保持输出路径上两种模态的自回归训练和生成。
大多数全能堆栈将ASR→LLM→TTS耦合在一起,会增加延迟,导致接口脆弱。LFM2-Audio的单一骨干设计,具有连续的输入嵌入和离散的输出代码,减少粘合逻辑,并允许交错解码以提前发出音频。对于开发者来说,更简单的管道和更快的感知响应时间,同时仍然支持ASR、TTS、分类和对话代理,所有这些功能都来自一个模型。
组件和特性:
- 骨干网络:LFM2(混合卷积+注意力),1.2B参数(仅语言模型)
- 音频编码器:FastConformer(约1.15亿参数,canary-180m-flash)
- 音频解码器:RQ-Transformer,预测离散的Mimi编码器标记(8个码本)
- 上下文:32768个标记;
- 词汇表:65536(文本)/2049×8(音频)
- 精度:bfloat16;
两种生成模式用于实时代理
- 交错生成:用于实时语音到语音聊天,模型交替使用文本和音频标记,以最小化感知延迟。
- 顺序生成:用于ASR/TTS(按轮次切换模态)。
VoiceBench:九项音频助手评估,包括AlpacaEval、CommonEval、WildVoice、AMI、LibriSpeech-clean、ASR WER、
安装:pip install liquid-audio