C++ 从零实现Json-Rpc 框架
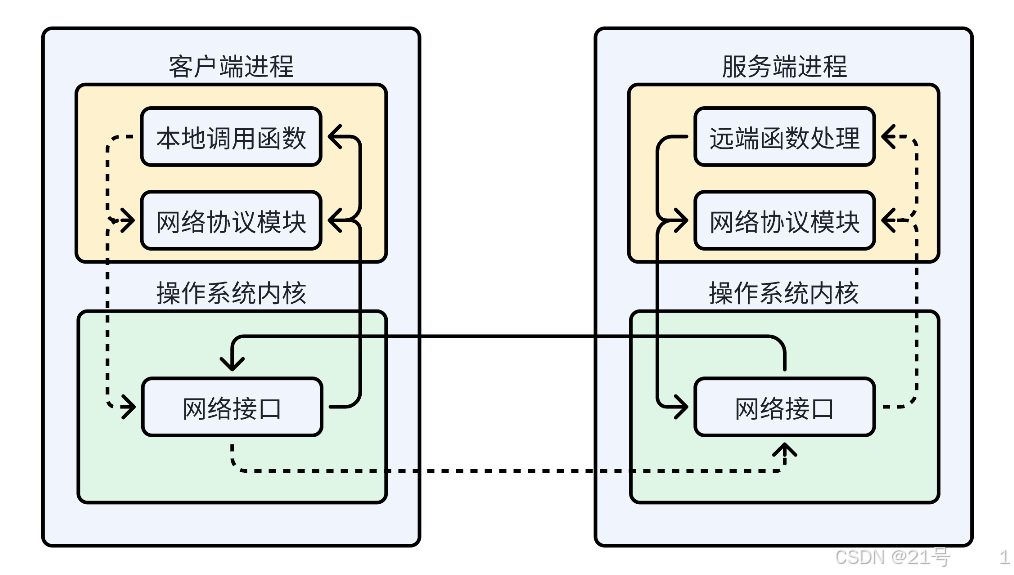
1.Json-Rpc 简介
车/飞机赶到约定的地点
2.技术选型
1.目前RPC的实现方案有两种:
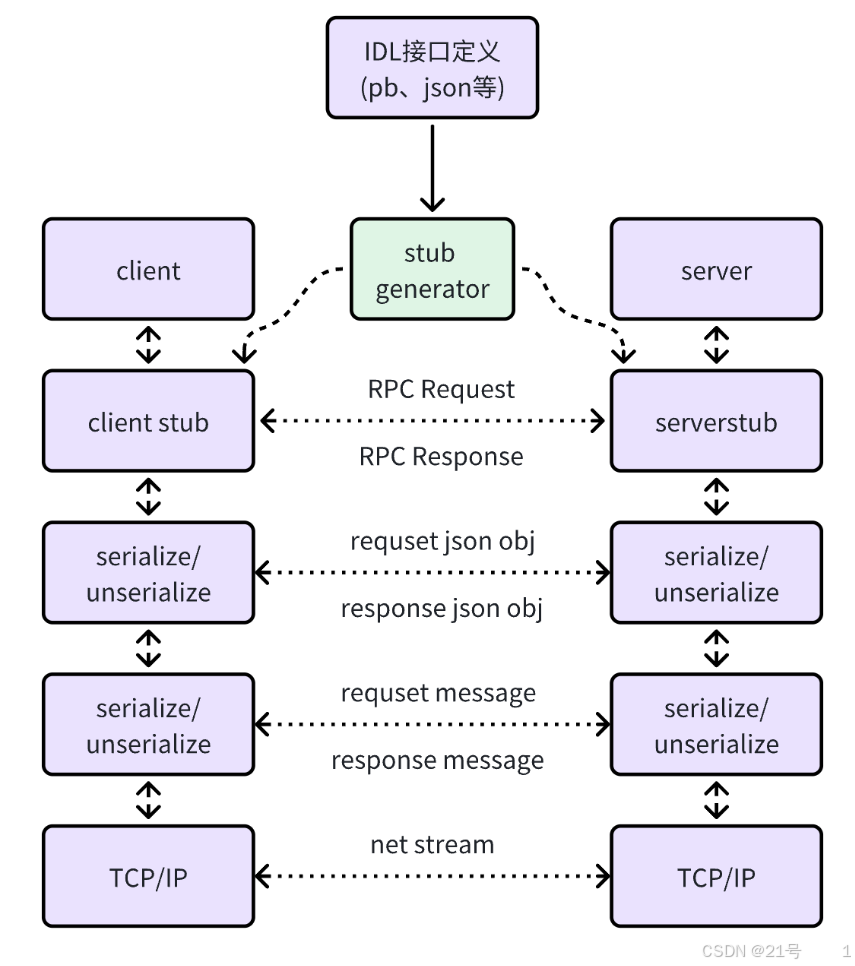
2.网络传输的参数和返回值怎么映射到对应的 RPC 接口上?
1.使⽤protobuf的反射机制
3.网络传输怎么做?
1.原⽣socket - 实现难度较⼤, 暂不考虑
2.Boost asio库的异步通信 - 需要扩展boost库
4.序列化和反序列化
3.开发环境
1.Linux(Ubuntu-22.04)
2.VSCode/Vim
3.g++/gdb
4.Makefile
4.环境搭建
1.安装wget(⼀般情况下默认会自带)
[zsc@node ~]$ sudo apt-get install wget2.更换国内软件源
[zsc@node ~]$ sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak添加软件源⽂件内容,新增以下内容
deb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal main restricted universe
multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe
multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-security main restricted
universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe
multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted
universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe
multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted
universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe
multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted
universe multiverse
#添加清华源
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted
universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted
universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main
restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main
restricted universe multiverse新增完毕后,更新源:
[zsc@node ~]$ sudo apt-get update3.安装lrzsz 传输工具
[zsc@node ~]$ sudo apt-get install lrzsz
[zsc@node ~]$ rz --version
rz (lrzsz) 0.12.204.安装编译器gcc/g++
[zsc@node ~]$ sudo apt-get install gcc g++5.安装项目构建工具make
[zsc@node ~]$ sudo apt-get install make6.安装调试器gdb
[zsc@node ~]$ sudo apt-get install gdb7.安装git
[zsc@node ~]$ sudo apt-get install git
[zsc@node ~]$ git --version8.安装cmake
[zsc@node ~]$ sudo apt-get install cmake
[zsc@node ~]$ cmake --version
cmake version 3.22.19.安装jsoncpp
[zsc@node ~]$ sudo apt-get install libjsoncpp-dev10.安装Muduo
1.下载源码
# git⽅式
[zsc@node ~]$ git clone https://github.com/chenshuo/muduo.git
2.安装依赖环境
[zsc@node ~]$ sudo apt-get install libz-dev libboost-all-dev
3.运⾏脚本编译安装
[zsc@node muduo-master]$ unzip muduo-master.zip
[zsc@node muduo-master]$ ./build.sh
[zsc@node muduo-master]$ ./build.sh install5.第三方库使用介绍
1.JsonCpp库
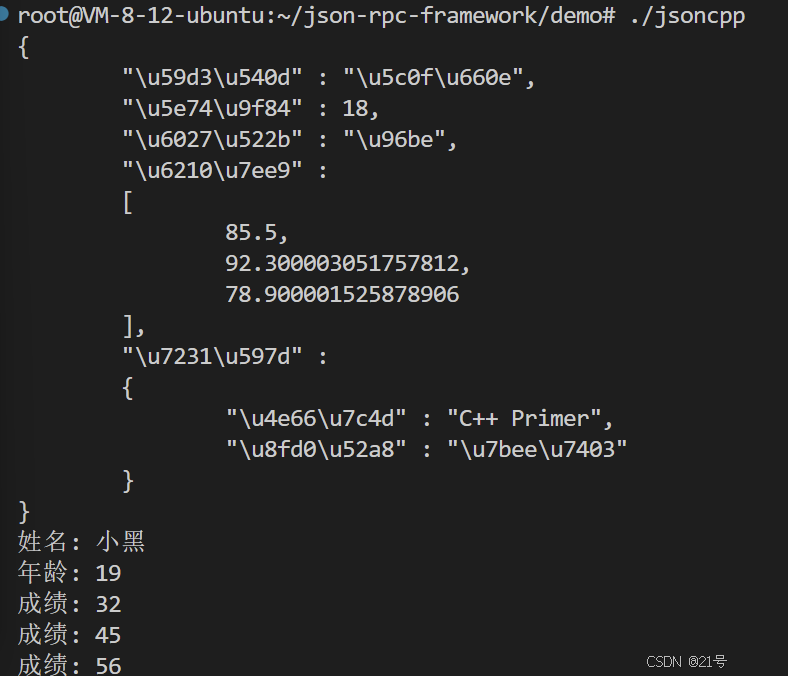
1.Json数据格式
Json 是⼀种数据交换格式,它采⽤完全独⽴于编程语⾔的⽂本格式来存储和表⽰数据。
例如: 我们想表⽰⼀个同学的学⽣信息
C 代码表⽰
char* name = "xx";
int age = 18;
float score[3] = {88.5, 99, 58};Json 表示
{“姓名” :“xx”,“年龄” :18,“成绩” : [88.5, 99, 58],"爱好" :{"书籍" :“西游记”"运动" :“打篮球”}
}2.JsonCpp介绍
Json 数据对象类的表示
1.Json::Value类:中间数据存储类
如果要将数据对象进行序列化,就需要先存储到Json::Value对象中;
如果要将数据进行反序列化,就是解析后,将数据对象放入到Json::Value对象中。
class Json::Value{Value &operator=(const Value &other); //Value重载了[]和=,因此所有的赋值和获取
数据都可以通过Value& operator[](const std::string& key);//简单的⽅式完成 val["name"] =
"xx";Value& operator[](const char* key);Value removeMember(const char* key);//移除元素const Value& operator[](ArrayIndex index) const; //val["score"][0]Value& append(const Value& value);//添加数组元素val["score"].append(88); ArrayIndex size() const;//获取数组元素个数 val["score"].size();std::string asString() const;//转string string name =
val["name"].asString();const char* asCString() const;//转char* char *name =
val["name"].asCString();Int asInt() const;//转int int age = val["age"].asInt();float asFloat() const;//转float float weight = val["weight"].asFloat();bool asBool() const;//转 bool bool ok = val["ok"].asBool();
};2.Json::StreamWrite类
用于进行数据序列化
class JSON_API StreamWriter { /write()序列化函数virtual int write(Value const& root, std::ostream* sout) = 0;
}/工厂,用于生产Json::StreamWrite 对象
class JSON_API StreamWriterBuilder : public StreamWriter::Factory {virtual StreamWriter* newStreamWriter() const;
}3.Json::CharReader类
反序列化类
class JSON_API CharReader { /parse 反序列化函数virtual bool parse(char const* beginDoc, char const* endDoc, Value* root, std::string* errs) = 0;
}/工厂类,用于生产CharReader对象
class JSON_API CharReaderBuilder : public CharReader::Factory {virtual CharReader* newCharReader() const;
}jsoncpp.cpp
服了是乱码ovo
6.Muduo库
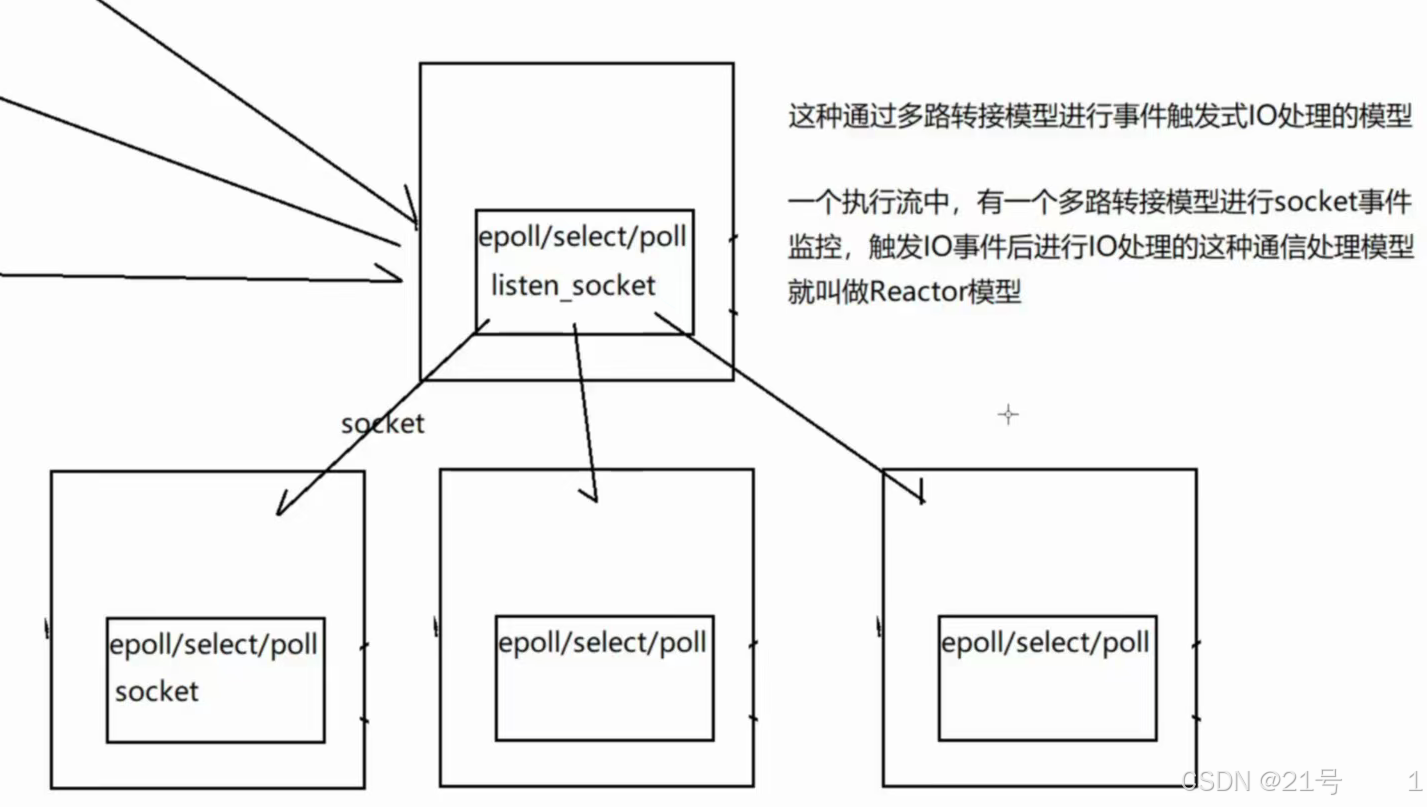
1.⼀个线程只能有⼀个事件循环(EventLoop), ⽤于响应计时器和IO事件
2.⼀个⽂件描述符只能由⼀个线程进⾏读写,换句话说就是⼀个TCP连接必须归属于某个EventLoop 管理
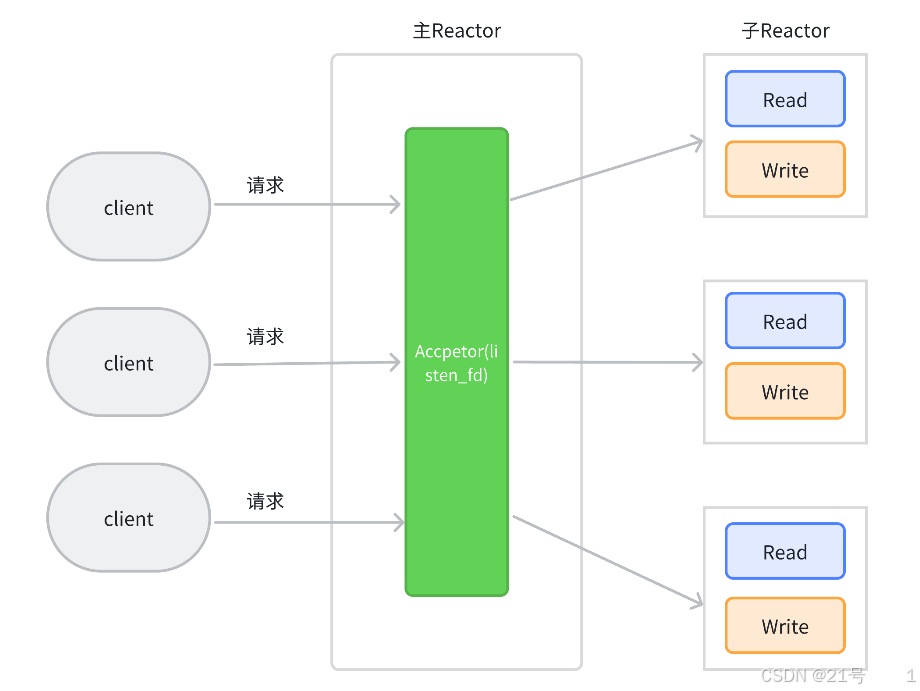
Muduo库常见接口介绍
1.TcpServer类介绍
typedef std::shared_ptr<TcpConnection> TcpConnectionPtr;
typedef std::function<void (const TcpConnectionPtr&)> ConnectionCallback;
typedef std::function<void (const TcpConnectionPtr&,Buffer*,Timestamp)> MessageCallback;
class InetAddress : public muduo::copyable
{
public:InetAddress(StringArg ip, uint16_t port, bool ipv6 = false);
};
class TcpServer : noncopyable
{
public:enum Option{kNoReusePort,kReusePort,
};TcpServer(EventLoop* loop,const InetAddress& listenAddr,const string& nameArg,Option option = kNoReusePort);void setThreadNum(int numThreads);void start();->启动服务器/// 当⼀个新连接建⽴成功的时候被调⽤void setConnectionCallback(const ConnectionCallback& cb) -->设置连接建立/关闭时的回调函数{ connectionCallback_ = cb; }/// 消息的业务处理回调函数---这是收到新连接消息的时候被调⽤的函数void setMessageCallback(const MessageCallback& cb) -->设置消息处理回调函数{ messageCallback_ = cb; }
};2.EventLoop类介绍
class EventLoop : noncopyable
{
public:/// Loops forever./// Must be called in the same thread as creation of the object.void loop(); -->开始事件监控循环/// Quits loop./// This is not 100% thread safe, if you call through a raw pointer,/// better to call through shared_ptr<EventLoop> for 100% safety.void quit(); -->停止循环TimerId runAt(Timestamp time, TimerCallback cb); -->定时任务/// Runs callback after @c delay seconds./// Safe to call from other threads.TimerId runAfter(double delay, TimerCallback cb);/// Runs callback every @c interval seconds./// Safe to call from other threads.TimerId runEvery(double interval, TimerCallback cb);/// Cancels the timer./// Safe to call from other threads.void cancel(TimerId timerId);
private:std::atomic<bool> quit_;std::unique_ptr<Poller> poller_;mutable MutexLock mutex_;std::vector<Functor> pendingFunctors_ GUARDED_BY(mutex_);
};3.TcpConnection类介绍
class TcpConnection : noncopyable,public std::enable_shared_from_this<TcpConnection>
{
public:/// Constructs a TcpConnection with a connected sockfd////// User should not create this object.TcpConnection(EventLoop* loop,const string& name,int sockfd,const InetAddress& localAddr,const InetAddress& peerAddr);bool connected() const { return state_ == kConnected; } -->判断当前链接是否正常bool disconnected() const { return state_ == kDisconnected; }void send(string&& message); // C++11 -->发送数据void send(const void* message, int len);void send(const StringPiece& message);// void send(Buffer&& message); // C++11void send(Buffer* message); // this one will swap datavoid shutdown(); // NOT thread safe, no simultaneous calling -->关闭连接void setContext(const boost::any& context){ context_ = context; }const boost::any& getContext() const{ return context_; }boost::any* getMutableContext(){ return &context_; }void setConnectionCallback(const ConnectionCallback& cb){ connectionCallback_ = cb; }void setMessageCallback(const MessageCallback& cb){ messageCallback_ = cb; }
private:enum StateE { kDisconnected, kConnecting, kConnected, kDisconnecting };EventLoop* loop_;ConnectionCallback connectionCallback_;MessageCallback messageCallback_;WriteCompleteCallback writeCompleteCallback_;boost::any context_;
};4.TcpClient类介绍
因为Client的connect接口是一个非阻塞操作,所以有可能出现另一种意外情况:
connect连接没有建立完成的情况下,调用connection接口获取连接,Send发送数据class TcpClient : noncopyable
{
public:// TcpClient(EventLoop* loop);// TcpClient(EventLoop* loop, const string& host, uint16_t port);TcpClient(EventLoop* loop,const InetAddress& serverAddr,const string& nameArg);~TcpClient(); // force out-line dtor, for std::unique_ptr members.void connect();//连接服务器 -- 非阻塞接口void disconnect();//关闭连接void stop();//获取客⼾端对应的通信连接Connection对象的接⼝,发起connect后,有可能还没有连接建⽴成
功TcpConnectionPtr connection() const{MutexLockGuard lock(mutex_);return connection_;}Muduo库的客户端也是通过Eventloop进行IO事件监控IO处理的/ 连接服务器成功时的回调函数void setConnectionCallback(ConnectionCallback cb){ connectionCallback_ = std::move(cb); }/ 收到服务器发送的消息时的回调函数void setMessageCallback(MessageCallback cb){ messageCallback_ = std::move(cb); }
private:EventLoop* loop_;ConnectionCallback connectionCallback_;MessageCallback messageCallback_;WriteCompleteCallback writeCompleteCallback_;TcpConnectionPtr connection_ GUARDED_BY(mutex_);
};
/*
需要注意的是,因为muduo库不管是服务端还是客⼾端都是异步操作,
对于客⼾端来说如果我们在连接还没有完全建⽴成功的时候发送数据,这是不被允许的。
因此我们可以使⽤内置的CountDownLatch类进⾏同步控制
*/
/做计数同步操作的类
class CountDownLatch : noncopyable
{
public:
explicit CountDownLatch(int count);void wait(){ -->计数大于0则阻塞 MutexLockGuard lock(mutex_);while (count_ > 0){condition_.wait();}}void countDown(){ -->计数--,为0时唤醒waitMutexLockGuard lock(mutex_);--count_;if (count_ == 0){condition_.notifyAll();}}int getCount() const;
private:mutable MutexLock mutex_;Condition condition_ GUARDED_BY(mutex_);int count_ GUARDED_BY(mutex_);
};5.Buffer类介绍
class Buffer : public muduo::copyable
{
public:static const size_t kCheapPrepend = 8;static const size_t kInitialSize = 1024;explicit Buffer(size_t initialSize = kInitialSize): buffer_(kCheapPrepend + initialSize),readerIndex_(kCheapPrepend),writerIndex_(kCheapPrepend);void swap(Buffer& rhs)size_t readableBytes() const -->获取缓冲区可读数据大小size_t writableBytes() const const char* peek() const -->获取缓冲区中数据的起始地址const char* findEOL() constconst char* findEOL(const char* start) constvoid retrieve(size_t len)void retrieveInt64()void retrieveInt32() -->数据读取位置向后偏移4字节,本质上就是删除起始位置的4字节数据void retrieveInt16()
void retrieveInt8()string retrieveAllAsString() -->从缓冲区中读取所有数据,当作string返回,并删除缓冲区中的数据string retrieveAsString(size_t len) -->从缓冲区中去除len长度的数据,当作string返回,并删除缓冲区中的数据void append(const StringPiece& str)void append(const char* /*restrict*/ data, size_t len)void append(const void* /*restrict*/ data, size_t len)char* beginWrite()const char* beginWrite() constvoid hasWritten(size_t len)void appendInt64(int64_t x)void appendInt32(int32_t x)void appendInt16(int16_t x)void appendInt8(int8_t x)int64_t readInt64()int32_t readInt32()int16_t readInt16()int8_t readInt8()int64_t peekInt64() constint32_t peekInt32() const -->尝试从缓冲区获取4字节数据,进行网络字节序转换为整型但是数据并不从缓冲区删除int16_t peekInt16() constint8_t peekInt8() constvoid prependInt64(int64_t x)void prependInt32(int32_t x)void prependInt16(int16_t x)void prependInt8(int8_t x)void prepend(const void* /*restrict*/ data, size_t len)
private:std::vector<char> buffer_;size_t readerIndex_;size_t writerIndex_;static const char kCRLF[];
};server.cpp
_baseloop的作用
在 muduo 网络库中,muduo::net::EventLoop _baseloop; 声明了一个 EventLoop 类型的对象 _baseloop,它是整个事件驱动模型的核心组件之一,主要作用如下:
事件循环的载体:
EventLoop代表一个事件循环,它不断地从内部的事件队列中获取并处理各种事件(如 I/O 事件、定时器事件、信号事件等),是 muduo 库实现 Reactor 模式的关键。I/O 多路复用的封装:
EventLoop内部封装了 epoll(Linux 下)等 I/O 多路复用机制,负责监听注册到其上的文件描述符(如 socket)的 I/O 事件,并在事件发生时回调相应的处理函数。事件的调度与处理:它维护了一个待处理的事件列表,通过
runInLoop()、queueInLoop()等方法可以将任务(回调函数)派发到事件循环中执行,确保线程安全地处理事件。定时器管理:提供了定时器功能,可以通过
runAfter()、runEvery()等方法注册定时任务,由EventLoop在指定时间触发。线程关联:每个
EventLoop对象通常与一个线程绑定(称为 I/O 线程),_baseloop常作为主线程的事件循环,在多线程模型中可能还会有其他子线程的EventLoop实例(如EventLoopThreadPool中的子循环)。
在服务器程序中,_baseloop 通常作为基础的事件循环,负责监听服务器的监听 socket,接受新连接,并可能将新连接的 I/O 事件分发给其他子 EventLoop 处理,从而实现高并发处理。
client.cpp
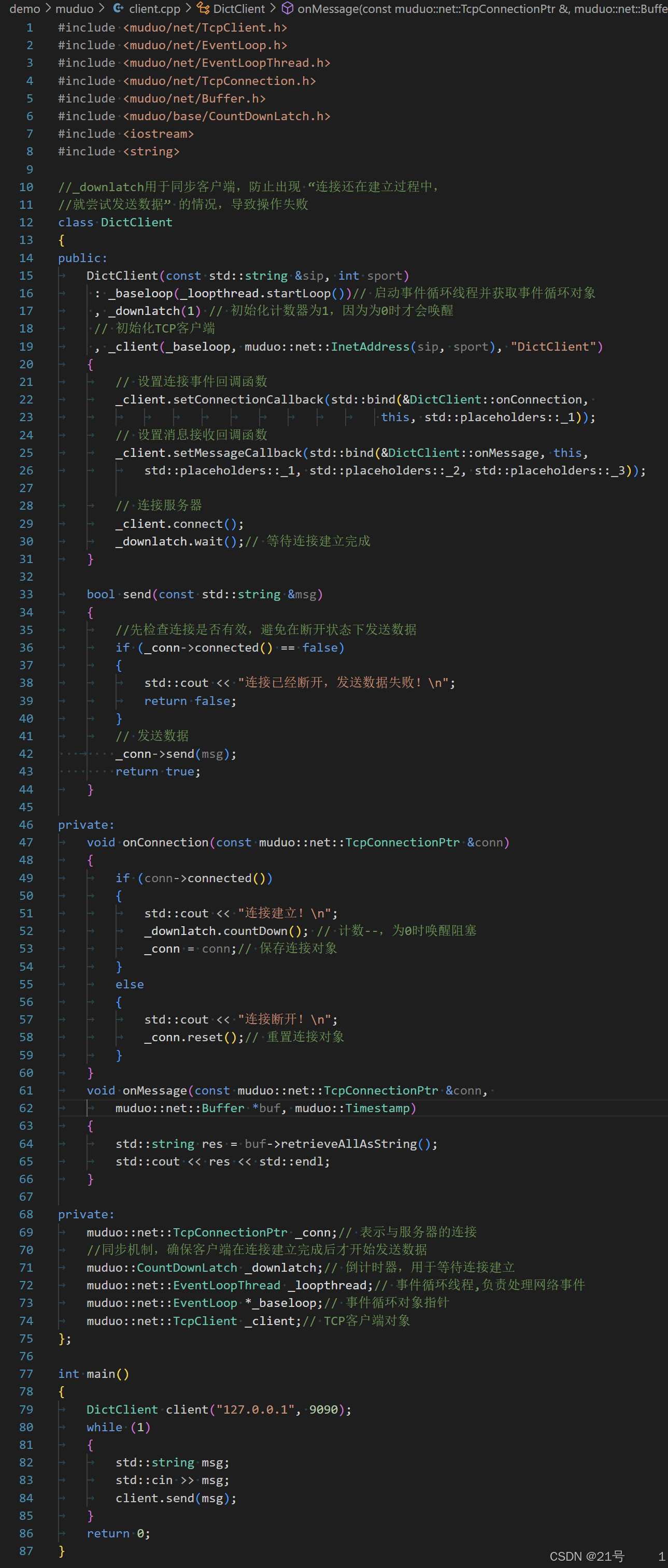
server.cpp p22中bind的作用
绑定成员函数
&DictServer::onConnection是要绑定的成员函数指针。由于成员函数必须通过对象(或指针)调用,因此需要传入this作为第一个参数,指定调用该函数的对象实例。占位符
std::placeholders::_1
表示该位置的参数将在回调函数被调用时由_server传入。假设onConnection的原型是:void DictServer::onConnection(const muduo::net::TcpConnectionPtr& conn);这里的
_1就对应参数const muduo::net::TcpConnectionPtr& conn,即当连接事件发生时,_server会自动将连接对象作为参数传入。适配回调类型
setConnectionCallback通常要求传入一个特定签名的函数(例如只接受TcpConnectionPtr参数的函数),而DictServer::onConnection作为成员函数,其实际签名包含隐含的this指针(第一个参数)。通过std::bind绑定this并保留参数占位符后,生成的绑定器可以匹配setConnectionCallback所需的回调类型。
简单说,这段代码的作用是:当 _server 触发连接事件时,自动调用当前 DictServer 对象的 onConnection 方法,并将连接对象作为参数传入。std::bind 在这里起到了 “适配函数签名” 和 “保存上下文(this)” 的作用。
makefile
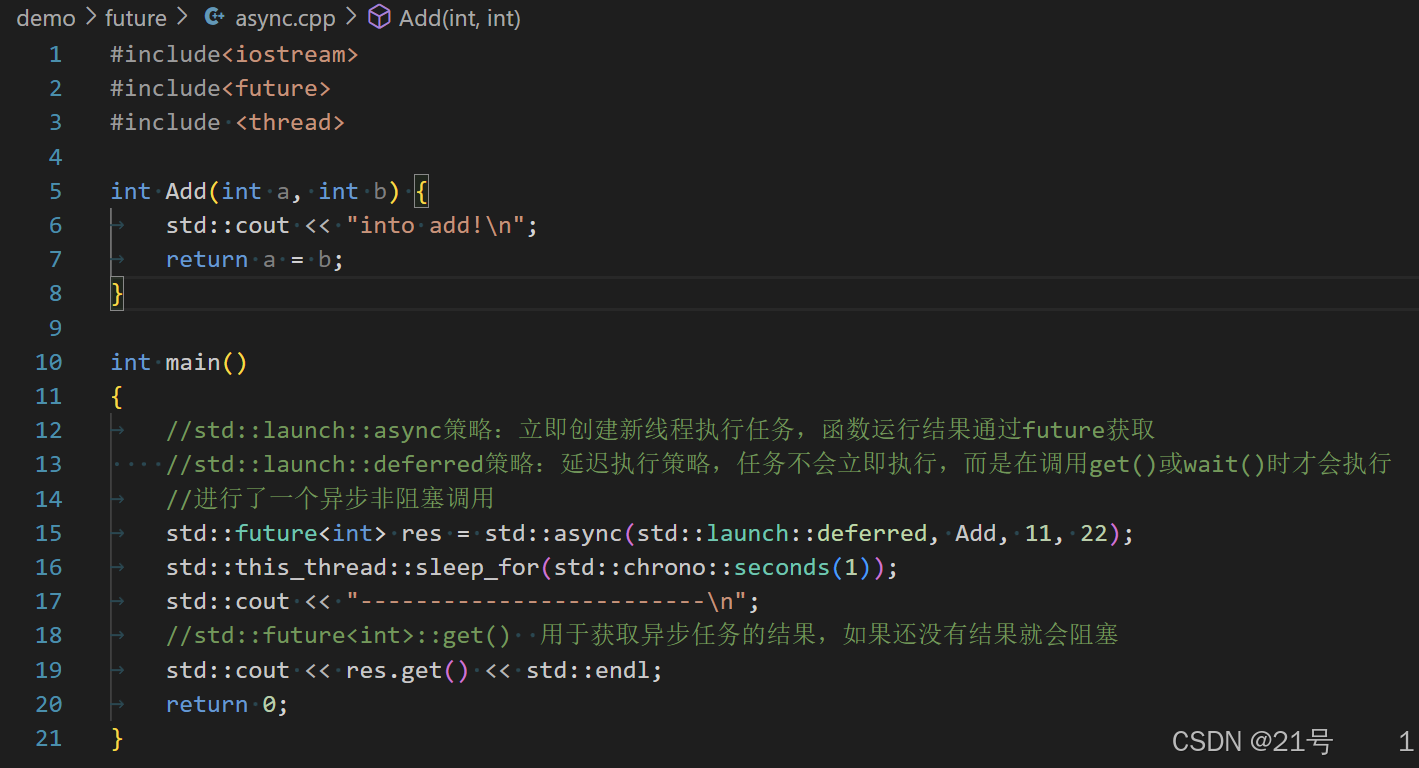
7.C++11 异步操作
1.std::future
2.使用 std::async关联异步任务
异步执行一个函数,内部会创建线程执行异步任务, 返回一个future对象用于获取函数结果
1.std::launch::deferred 表明该函数会被延迟调⽤,
直到在future上调⽤get()或者wait()才会开始执⾏任务2.std::launch::async 表明函数会在⾃⼰创建的线程上运⾏3.std::launch::deferred | std::launch::async 内部通过系统等条件⾃动选择策略async.cpp

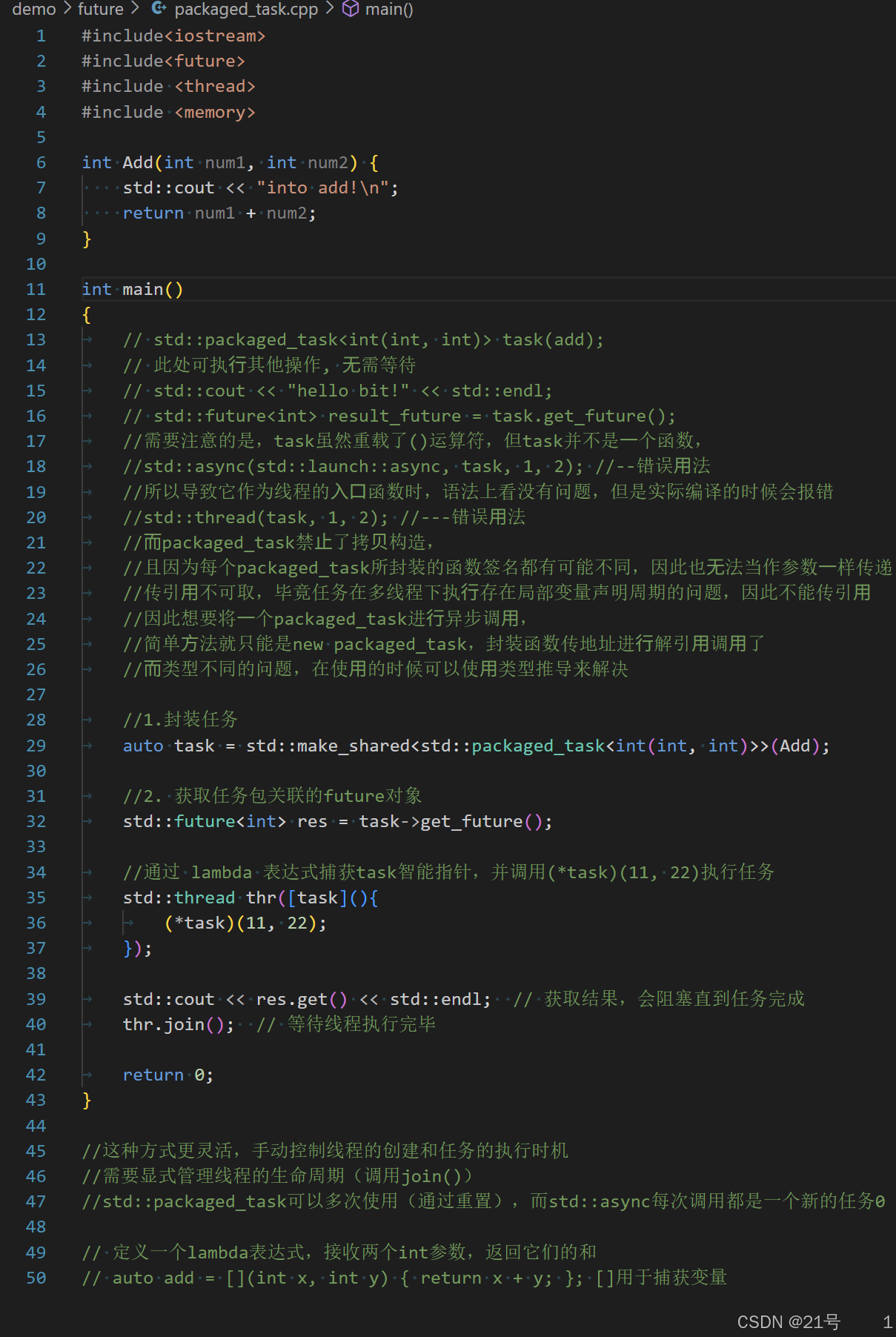
3.使用std::packaged_task 和 std::future配合
packaged_task.cpp

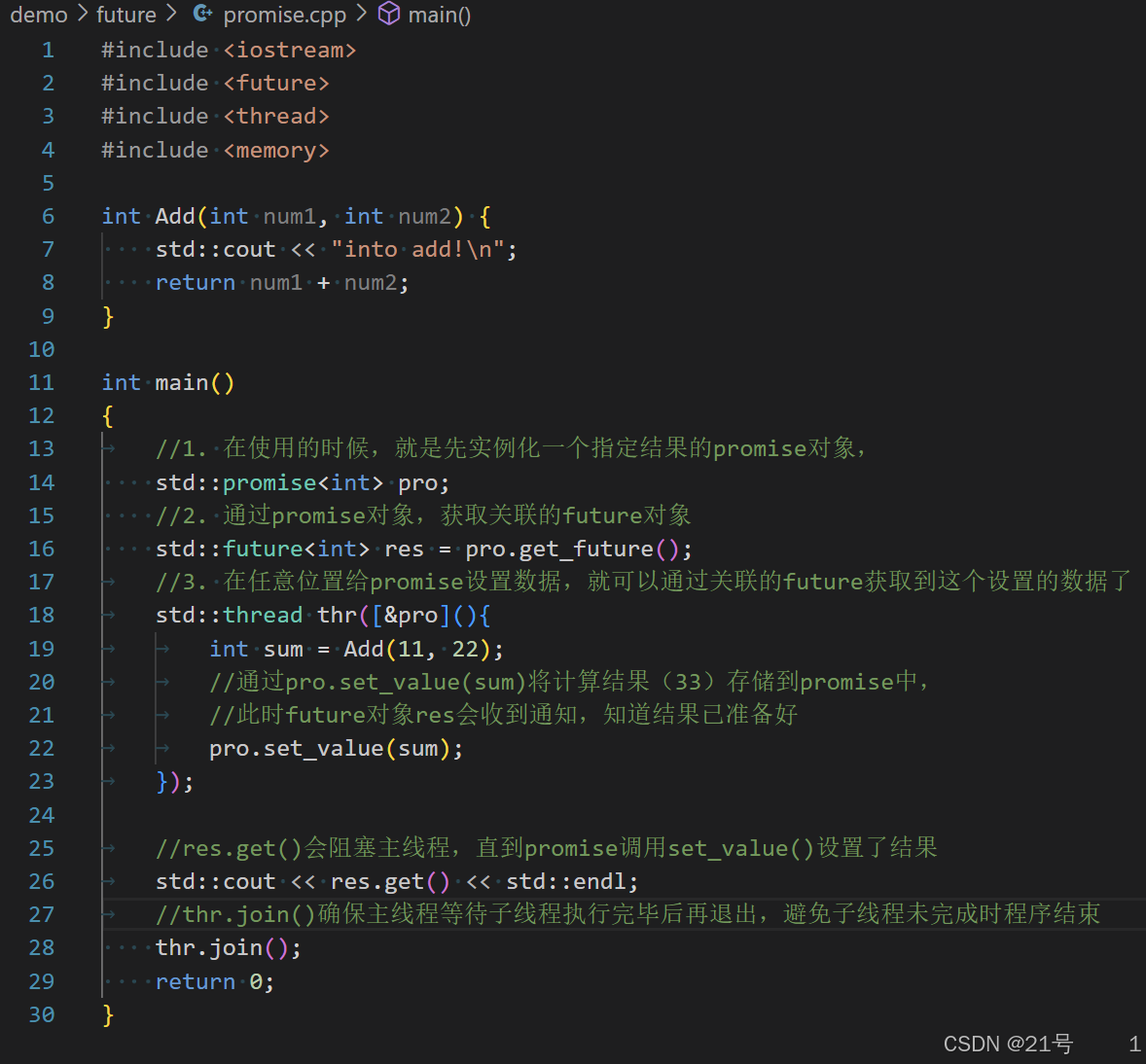
4.使用std::promise 和 std::future配合
std.:.promise类模板:实例化的对象可以返回一个future,在其他线程中向promise对象设置数据,其他线程的关联future就可以获取数据
promise.cpp
8.项目设计
1.理解项目功能
实现rpc(远端调用)思想上并不复杂,甚⾄可以说是简单,其实就是客⼾端想要完成某个任务的处理,但是这个处理的过程并不⾃⼰来完成,⽽是,将请求发送到服务器上,让服务器来帮其完成处理过程,并返回结果,客⼾端拿到结果后返回。
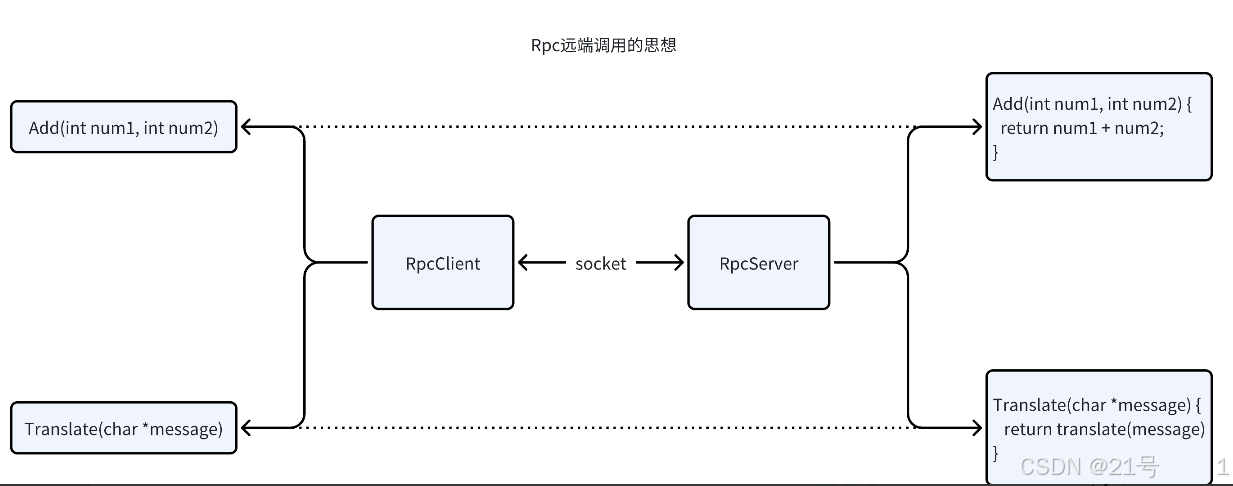
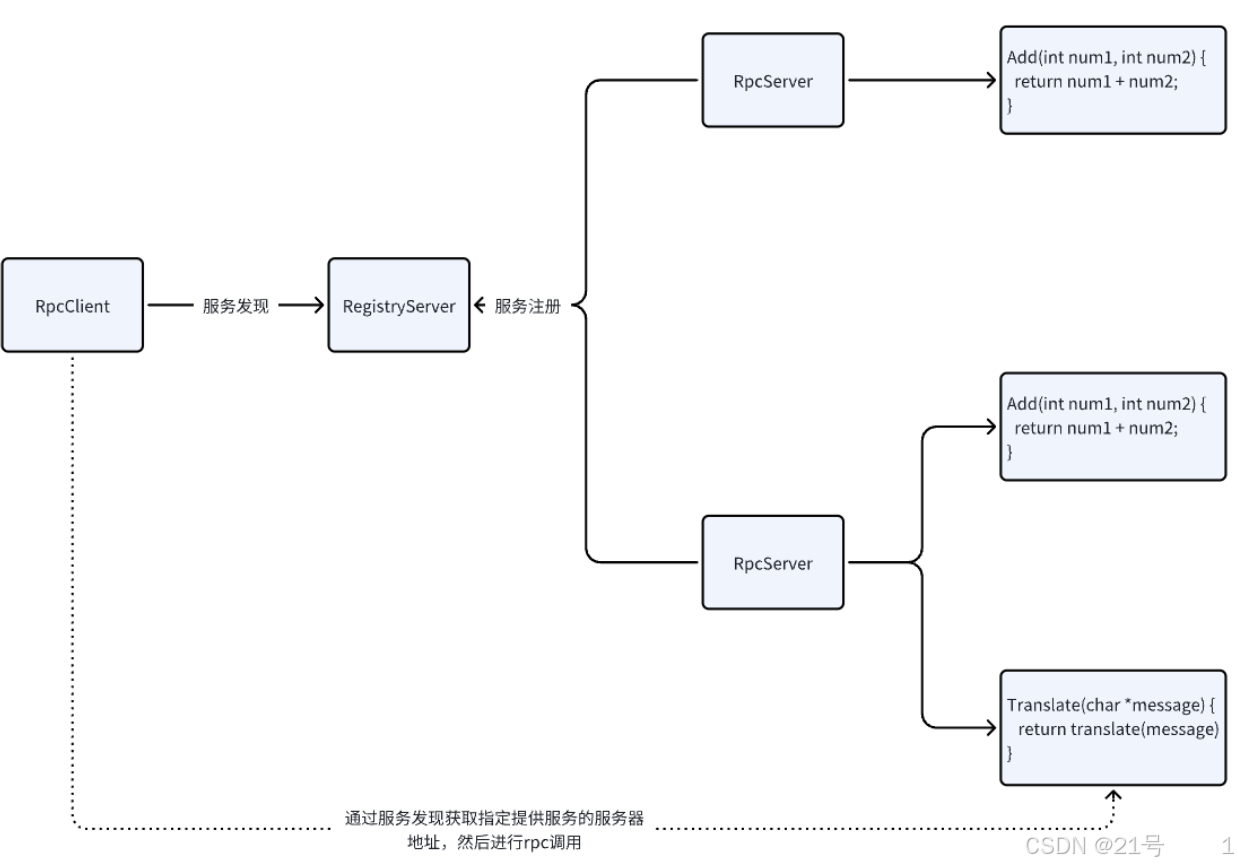
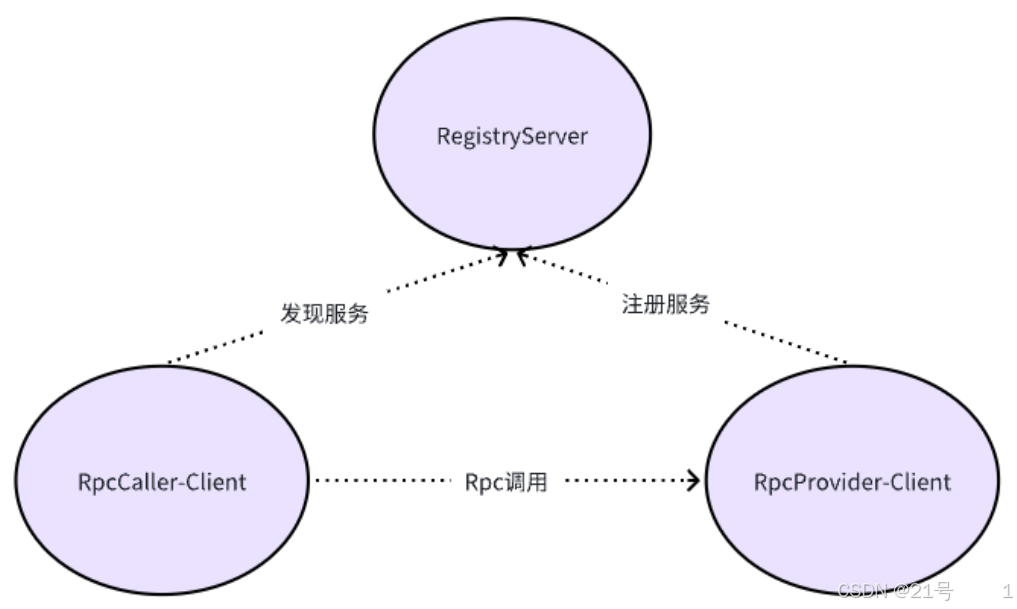
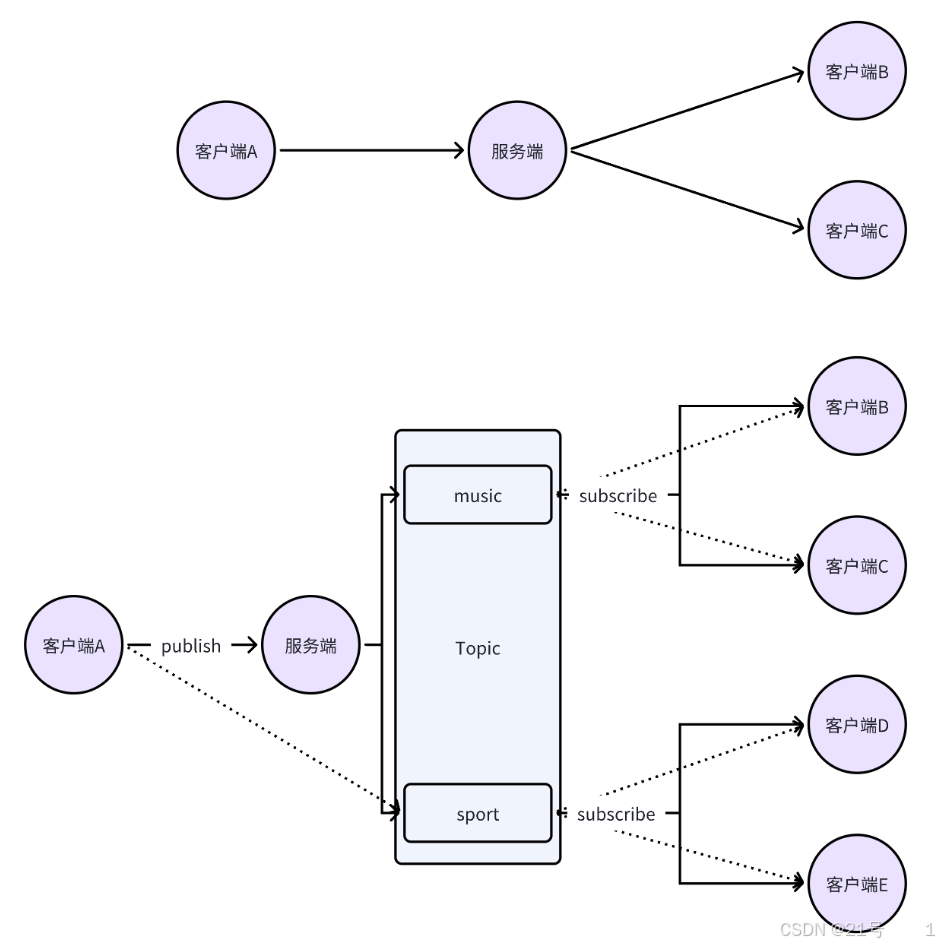
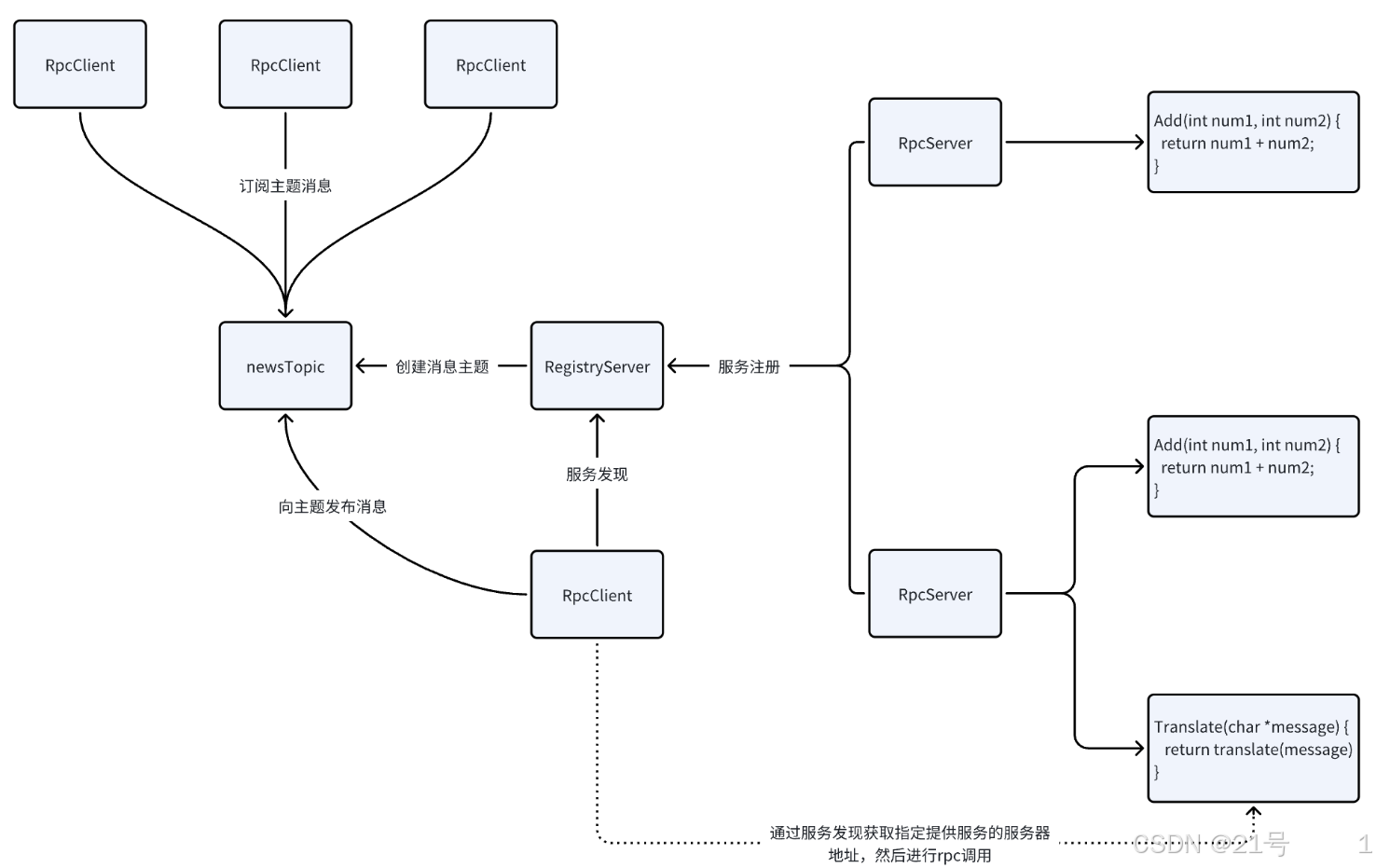
项目的三个主要功能:
1.rpc调用
2.服务的注册与发现以及服务的下线/上线通知
3.消息的发布订阅
2.框架设计
1.服务端模块划分
服务端的功能请求:
1.基于网络通信接收客户端的请求,提供rpc服务
2.基于网络通信接收客户端的请求,提供服务注册与发现,上线&下线通知
3.基于网络通信接收客户端的请求,提供主题操作(创建/删除/订阅/取消),消息发布
1.Network
2.Protocol

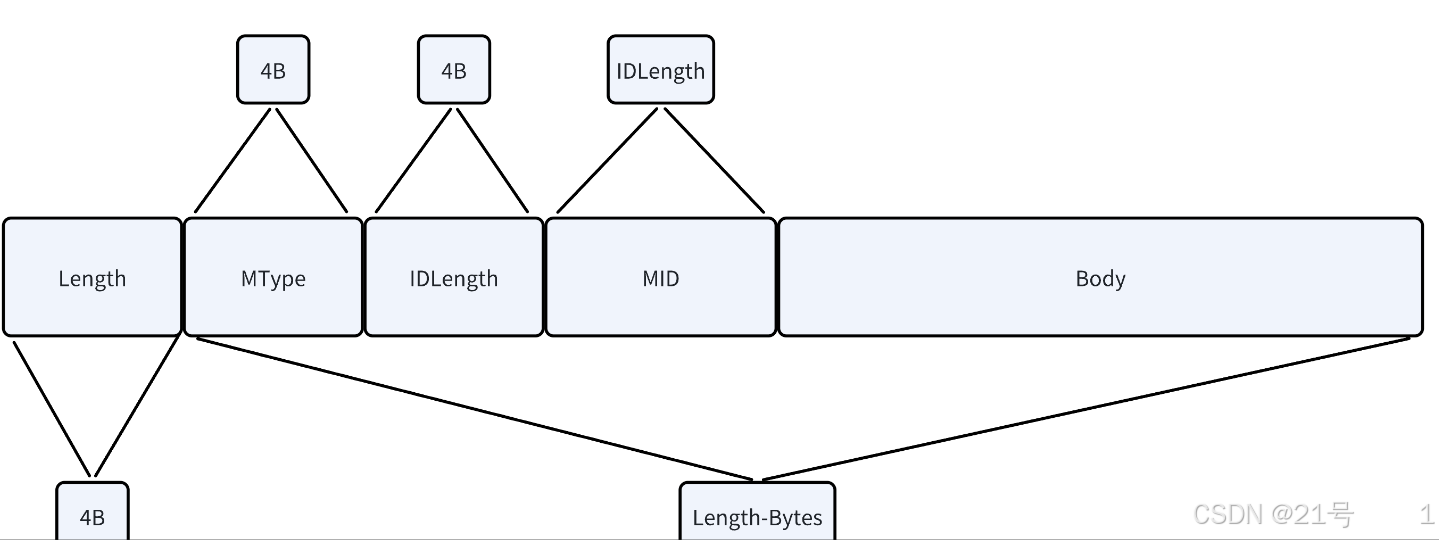
3.Dispatcher
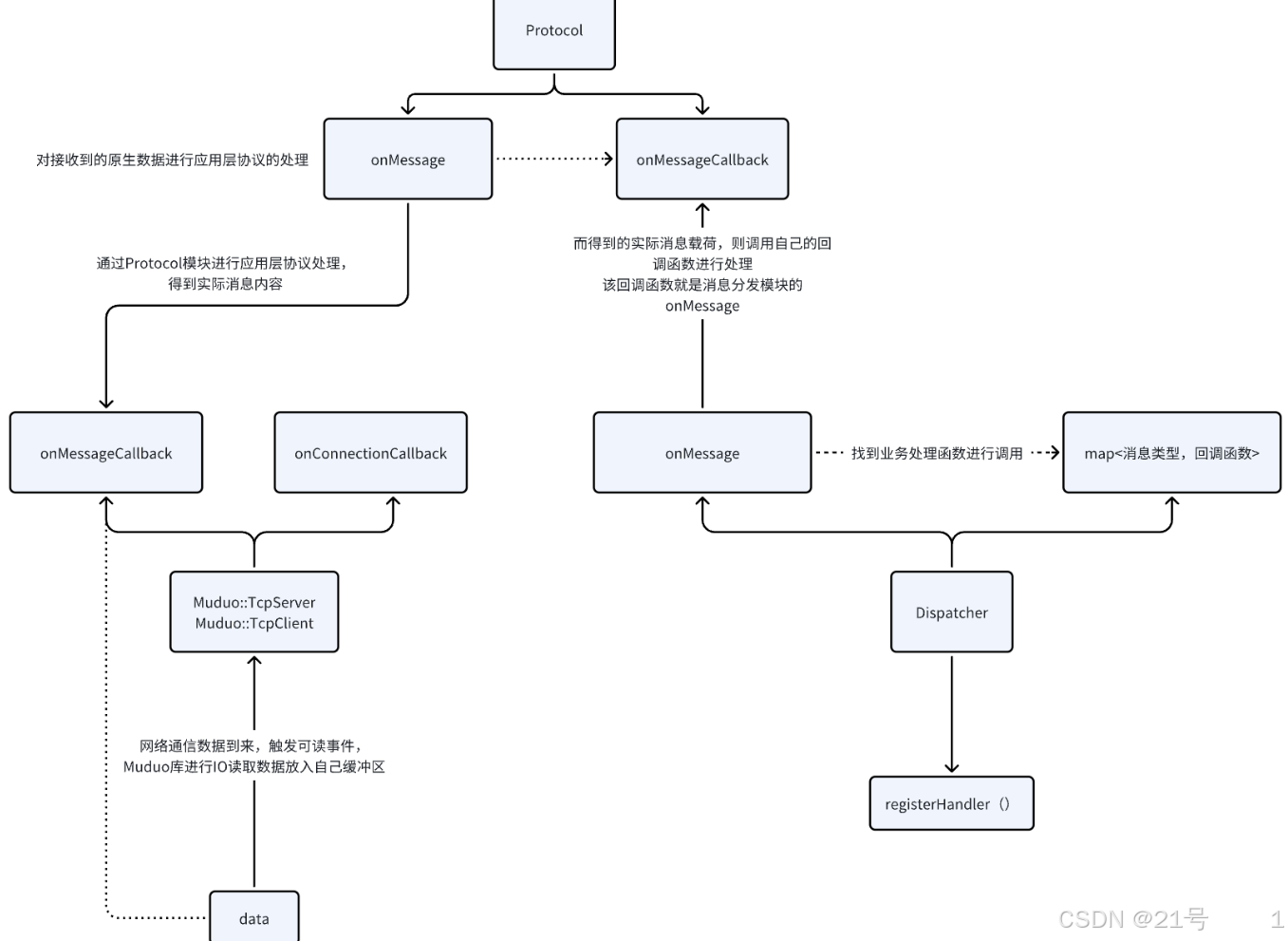
消息类型:
1.rpc请求&响应
2.服务注册/发现/上线/下线请求&响应
3.主题创建/删除/订阅/取消订阅请求&响应,消息发布的请求&响应
4.RpcRouter
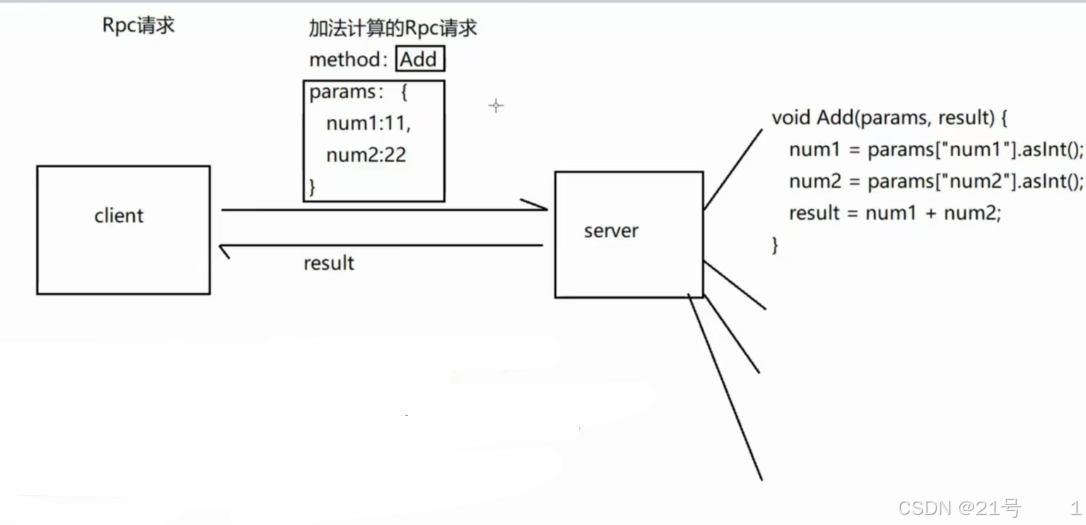
//RPC-request
{"method" : "Add","parameters" : {"num1" : 11,"num2" : 22}
}//RPC-response
{"rcode" : OK,"result": 33
}{"rcode" : ERROR_INVALID_PARAMETERS
}
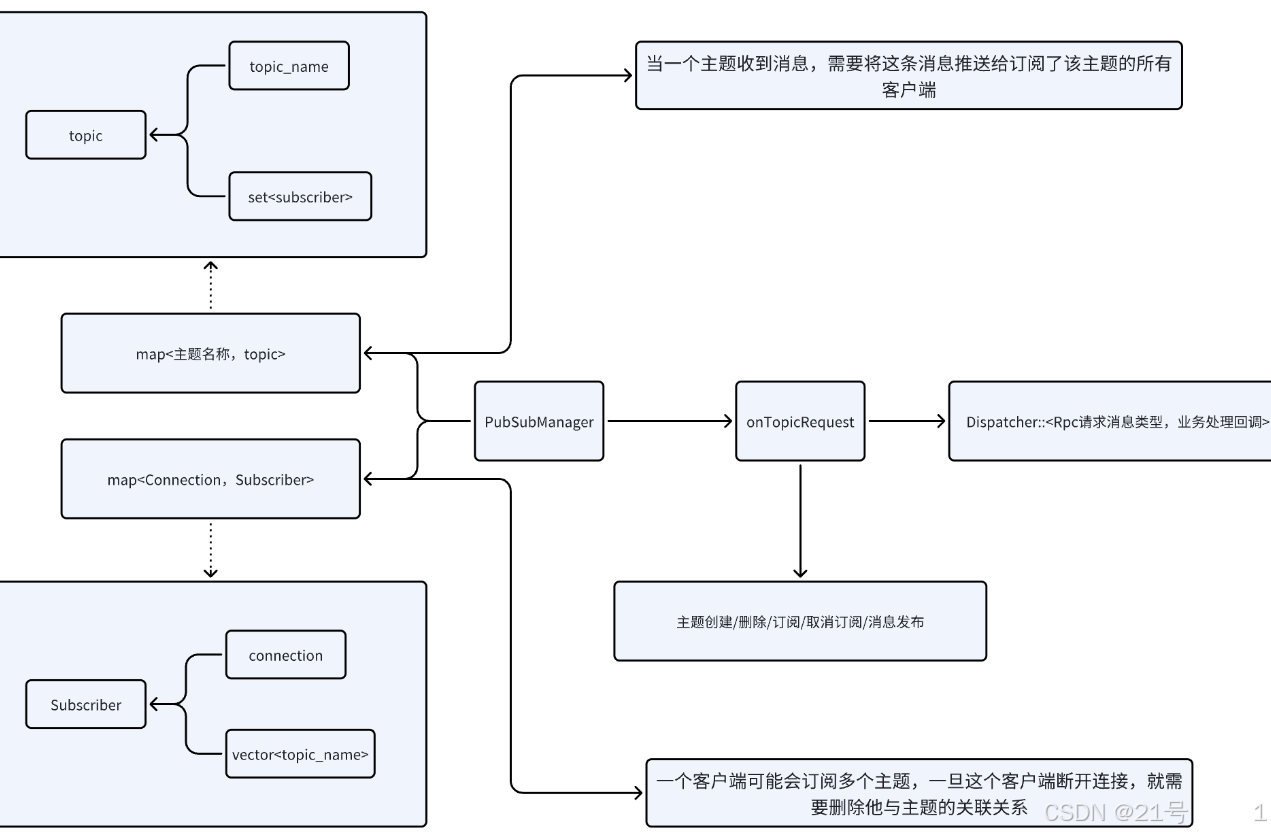
5.Publish-Subscovery
//Topic-request
{"key" : "music", //主题名称// 主题操作类型"optype" :
TOPIC_CRAETE/TOPIC_REMOVE/TOPIC_SUBSCRIBE/TOPIC_CANCEL/TOPIC_PUBLISH,//TOPIC_PUBLISH请求才会包含有message字段"message" : "Hello World"
}//Topic-response
{"rcode" : OK,
}{"rcode" : ERROR_INVALID_PARAMETERS,
}设计实现:
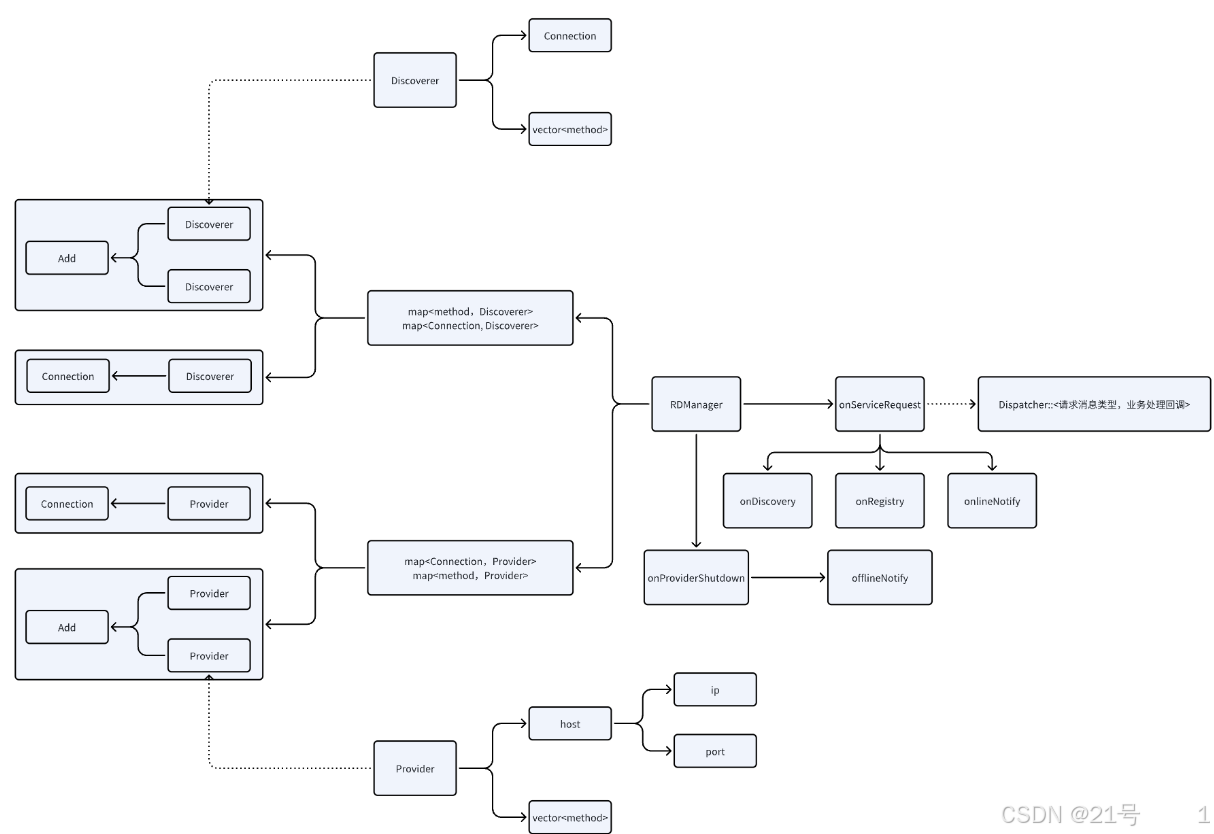
6.Registry-Discovery
//RD--request
{//SERVICE_REGISTRY-Rpc-provider进⾏服务注册//SERVICE_DISCOVERY - Rpc-caller进⾏服务发现
//SERVICE_ONLINE/SERVICE_OFFLINE 在provider下线后对caller进⾏服务上下线通知"optype" :
SERVICE_REGISTRY/SERVICE_DISCOVERY/SERVICE_ONLINE/SERVICE_OFFLINE,"method" : "Add",//服务注册/上线/下线有host字段,发现则⽆host字段"host" : {"ip" : "127.0.0.1","port" : 9090}
}
//Registry/Online/Offline-response
{"rcode" : OK,
}
//error-response
{"rcode" : ERROR_INVALID_PARAMETERS,
}
//Discovery-response
{"method" : "Add","host" : [{"ip" : "127.0.0.1","port" : 9090},{"ip" : "127.0.0.2","port" : 8080}]
}
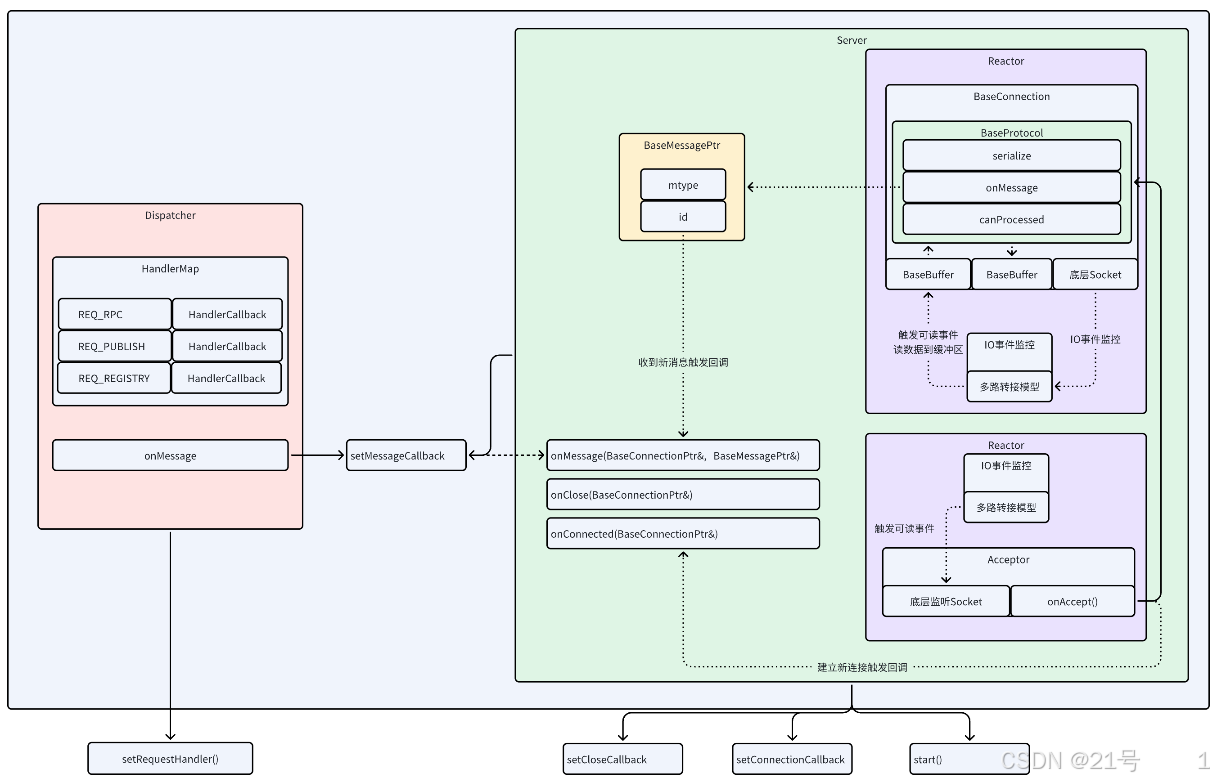
7.Server
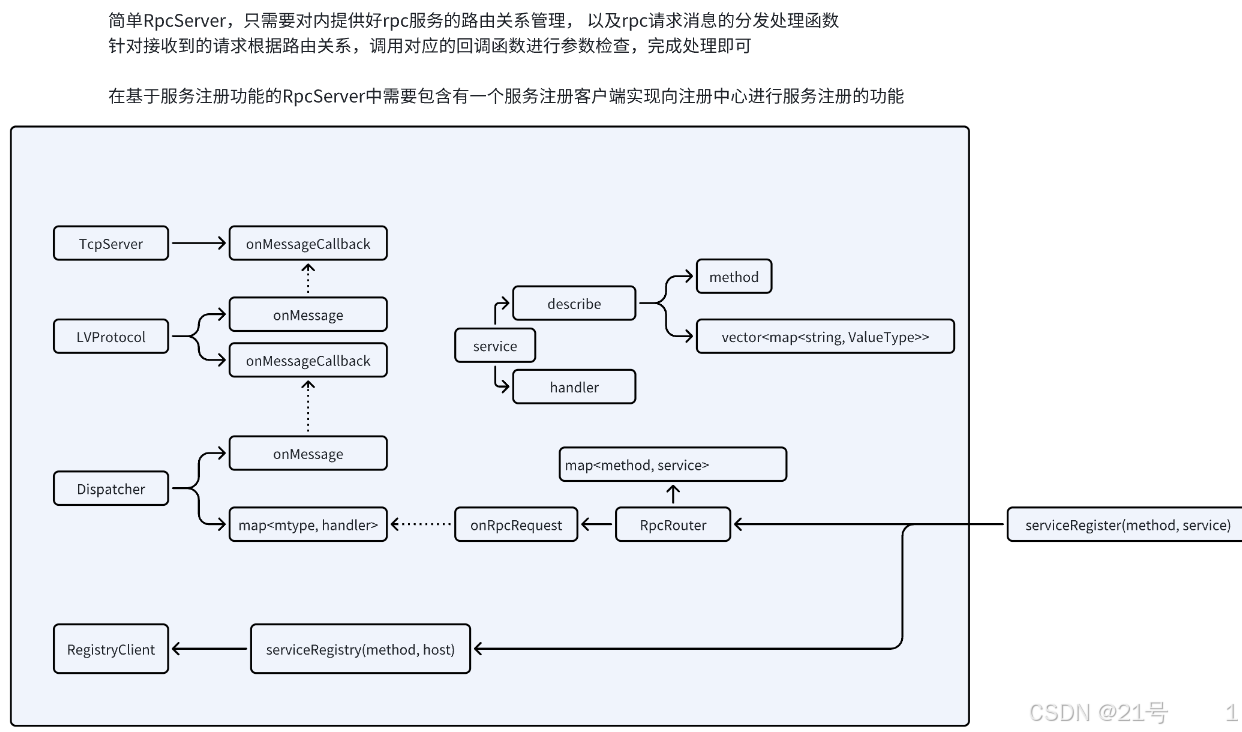
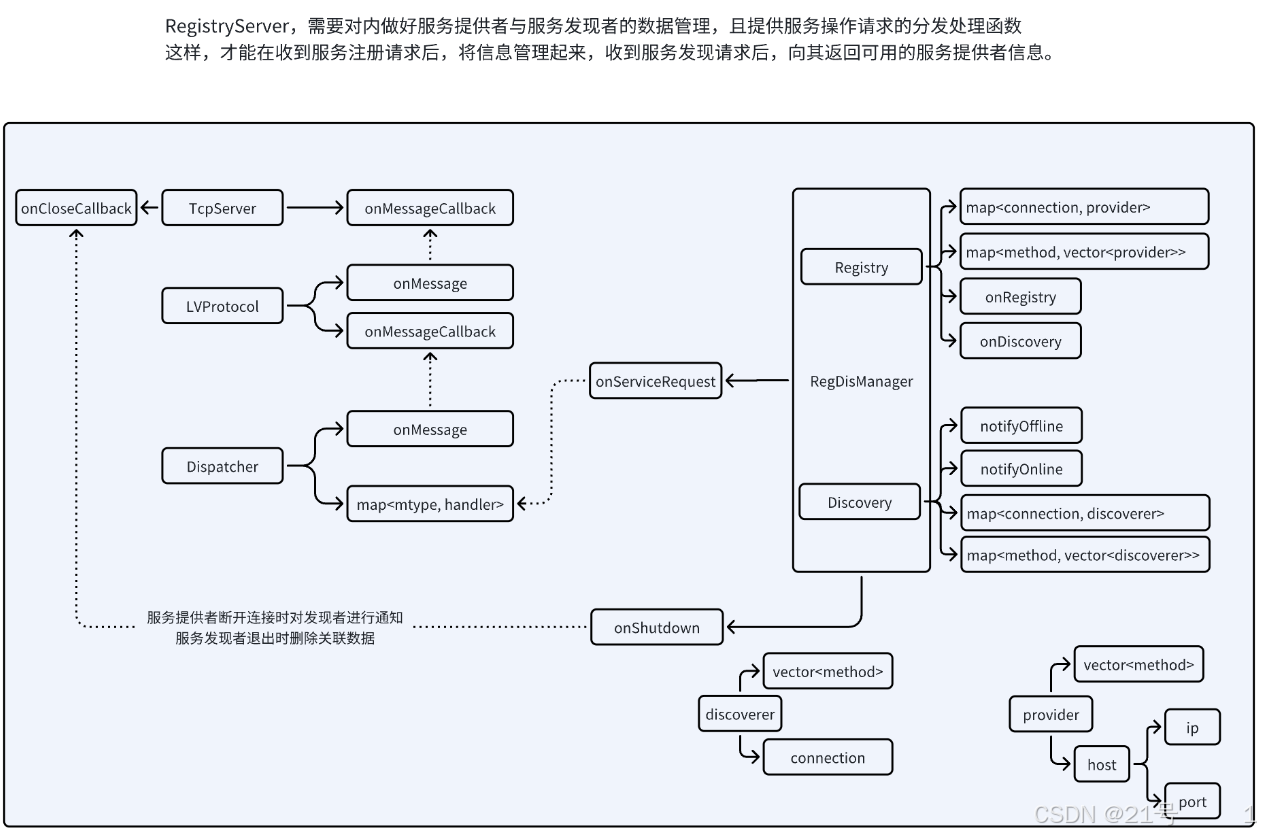
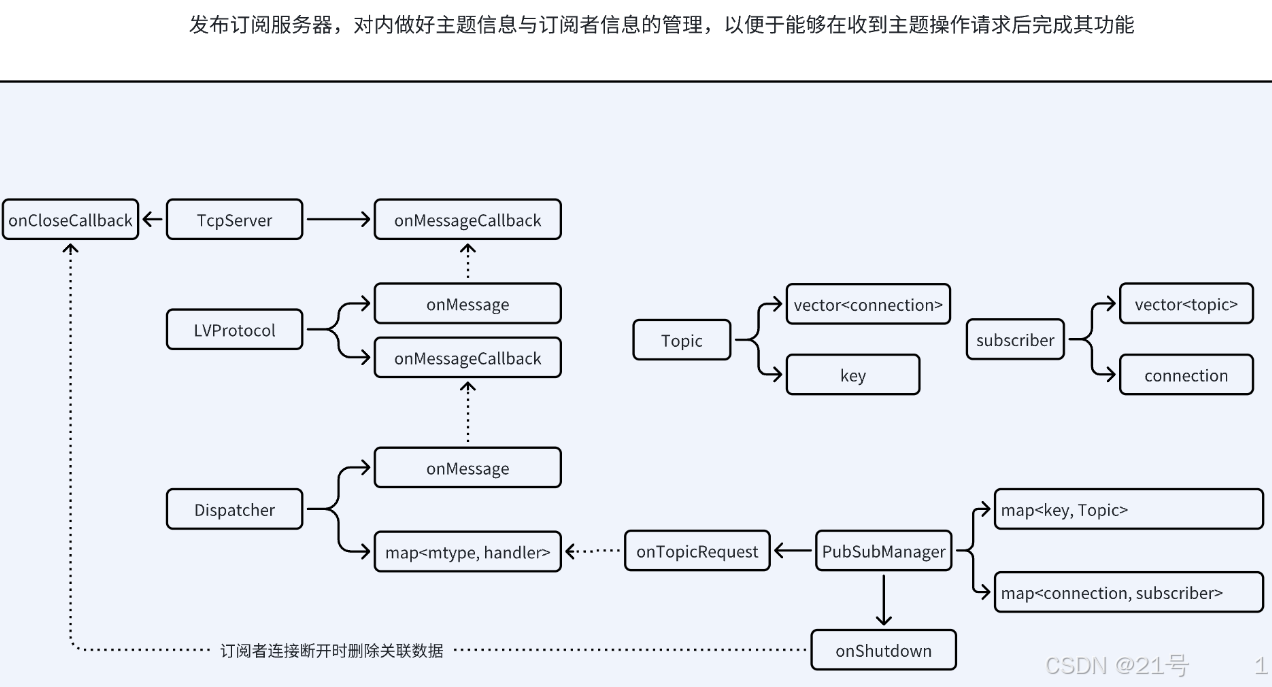
2.客户端模块划分
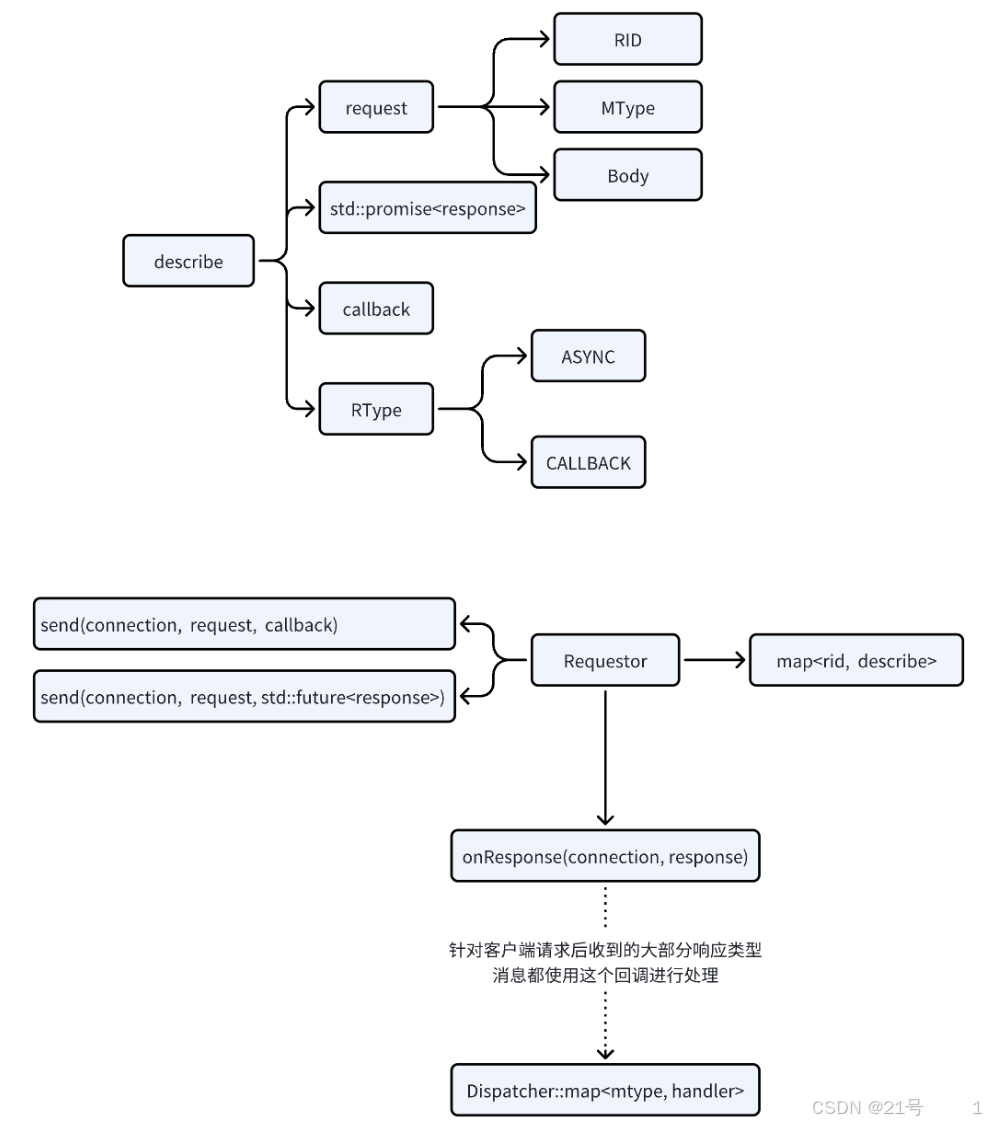
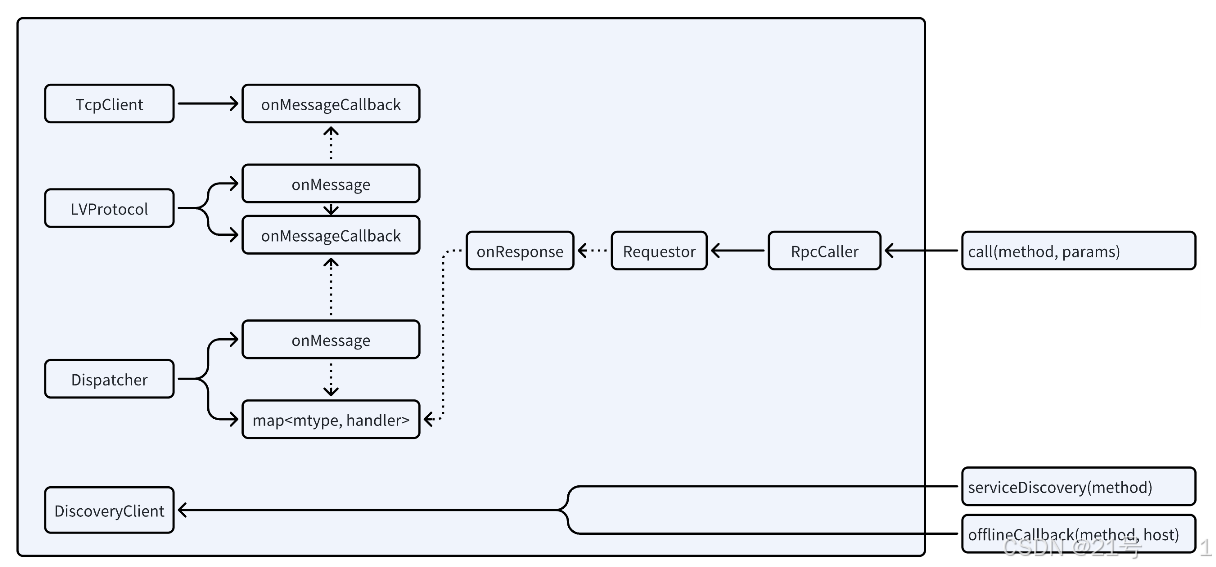
4.Requestor
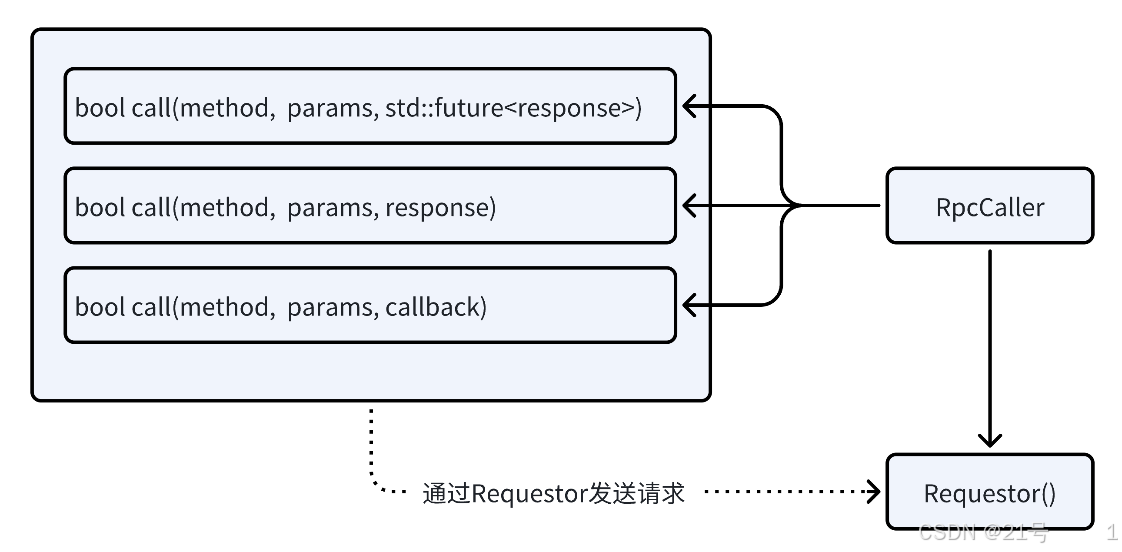
5.RpcCaller
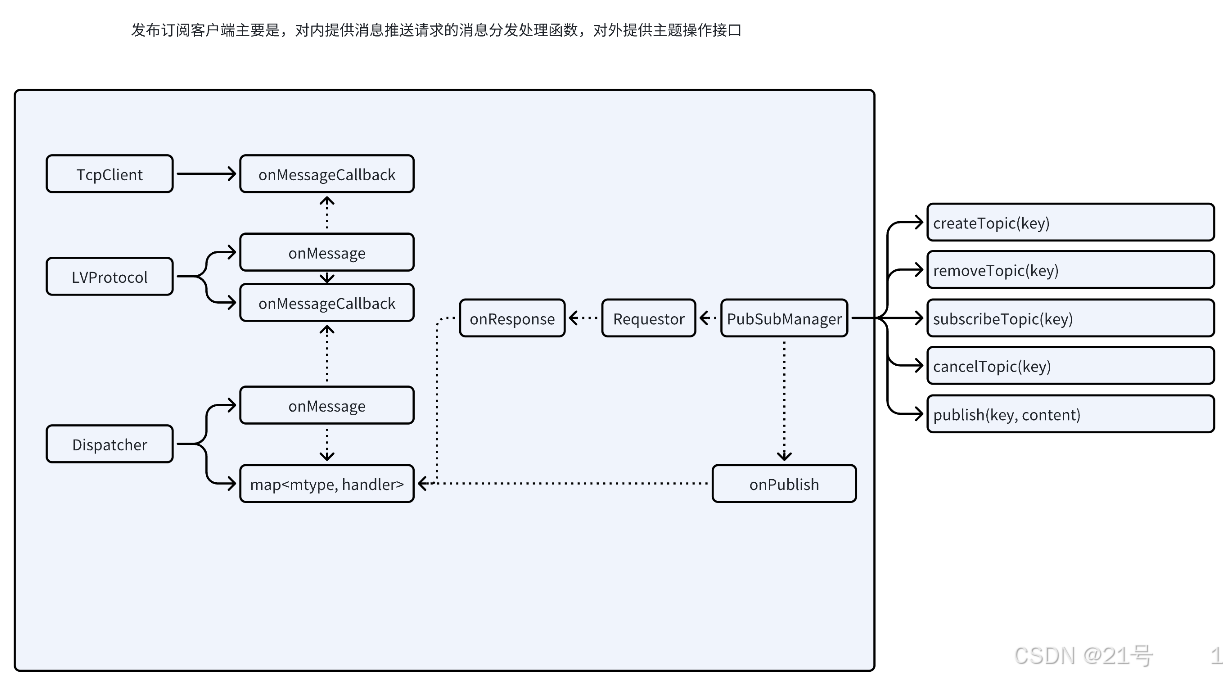
6.Publish-Subscribe
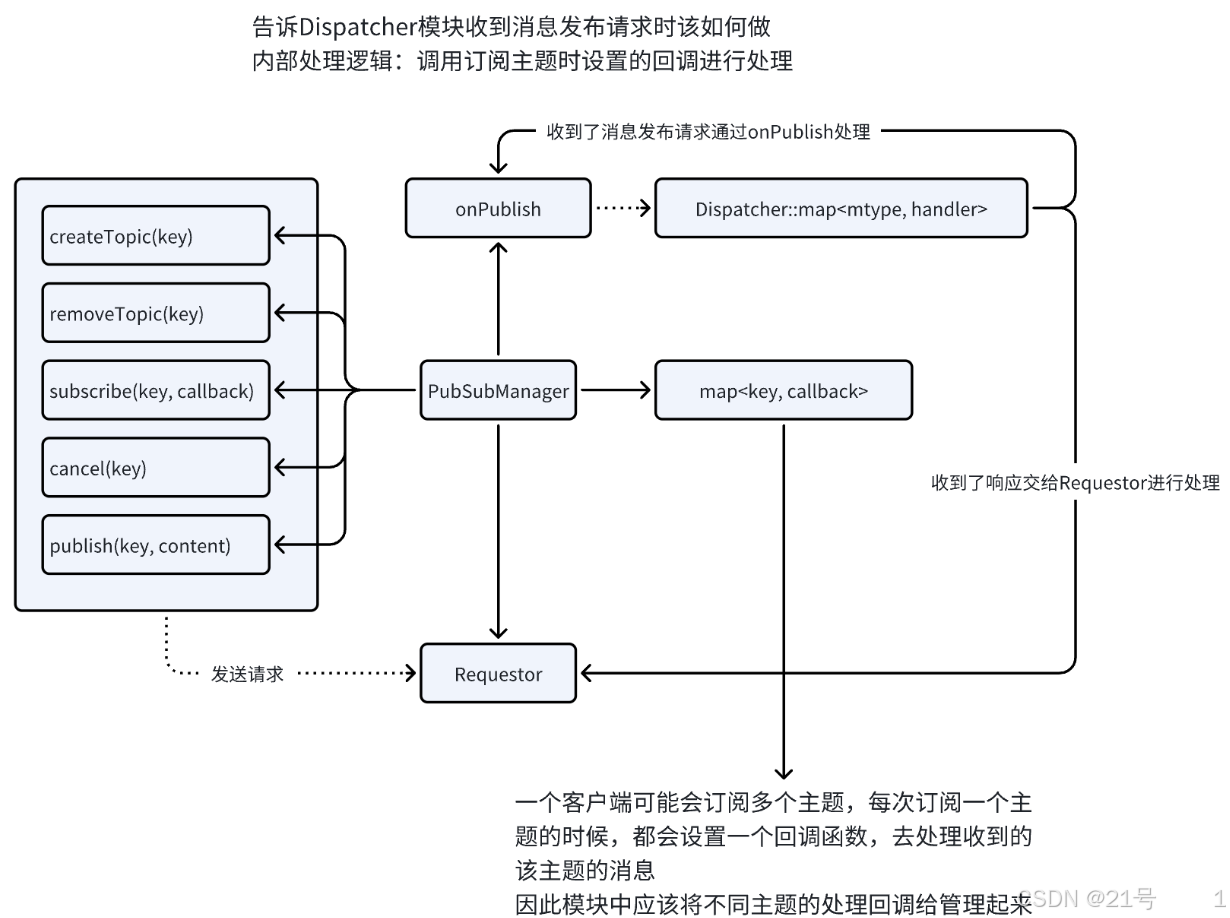
7.Registry-Discovery
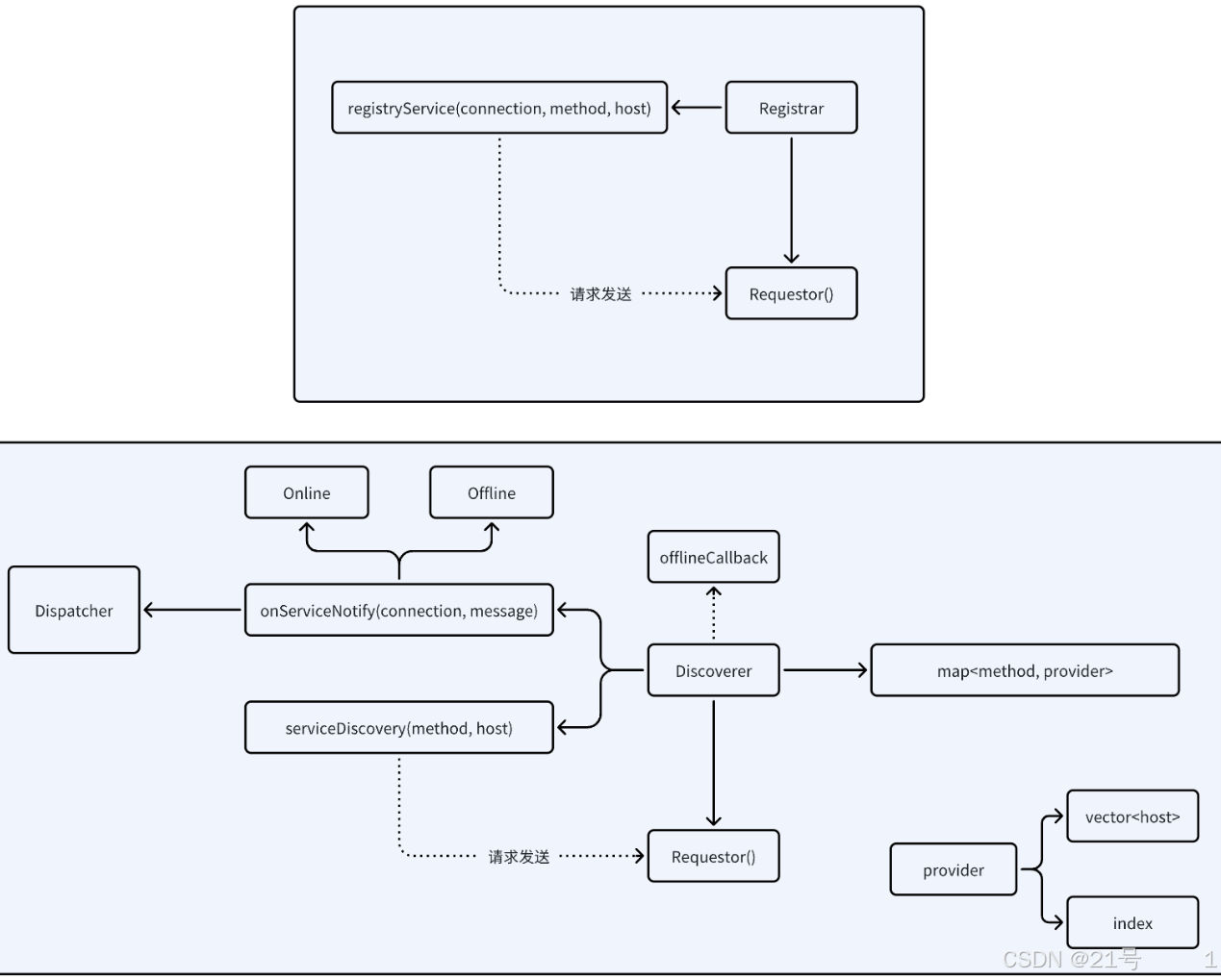
8.Client
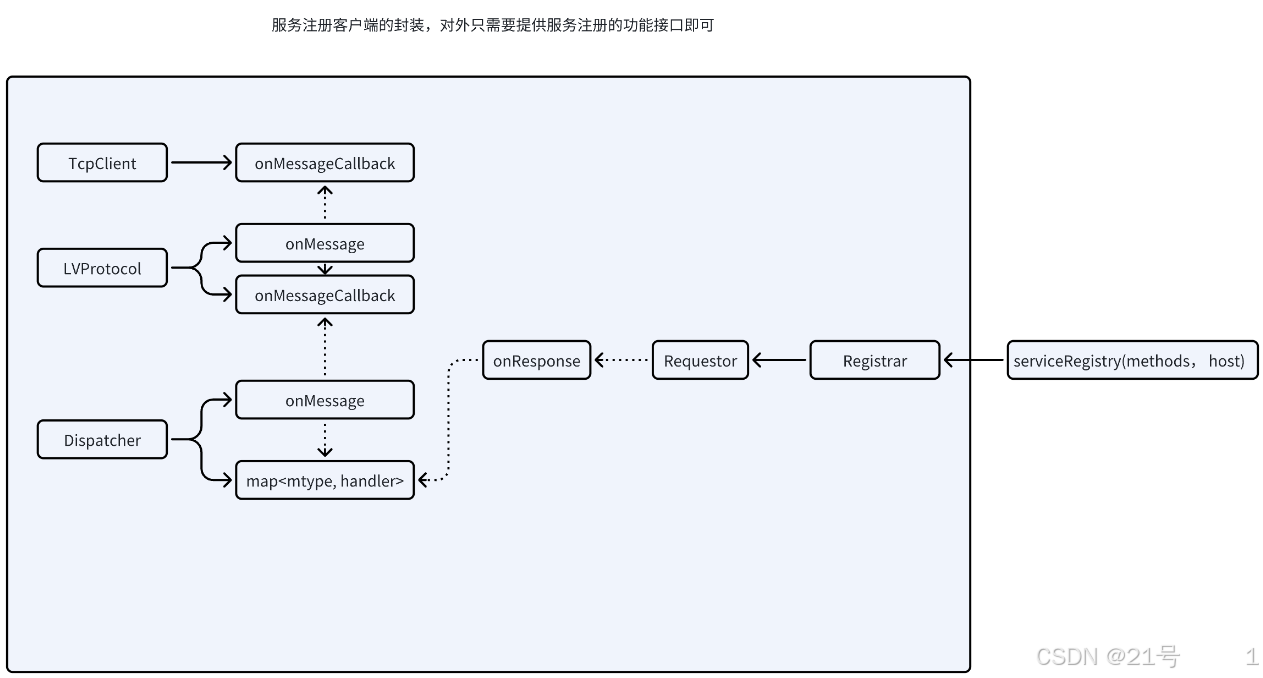
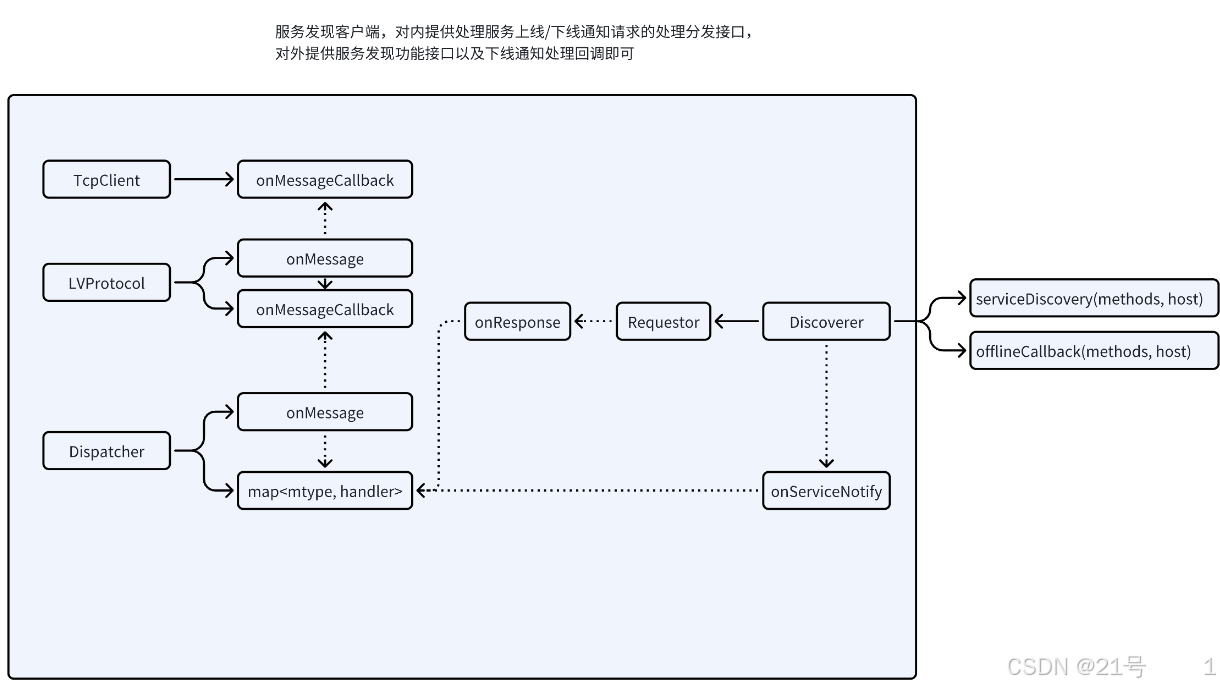
框架设计:
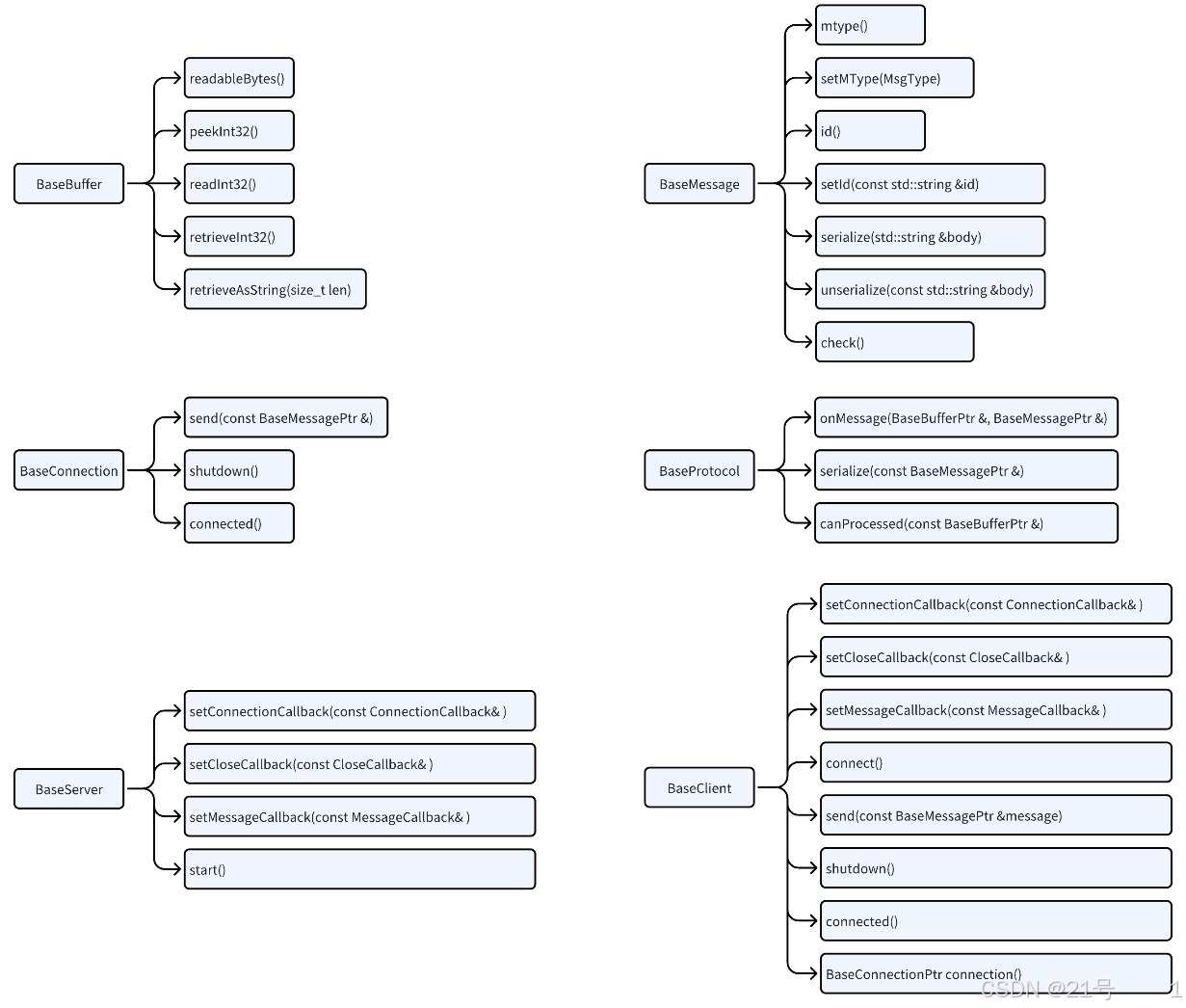
3.抽象层
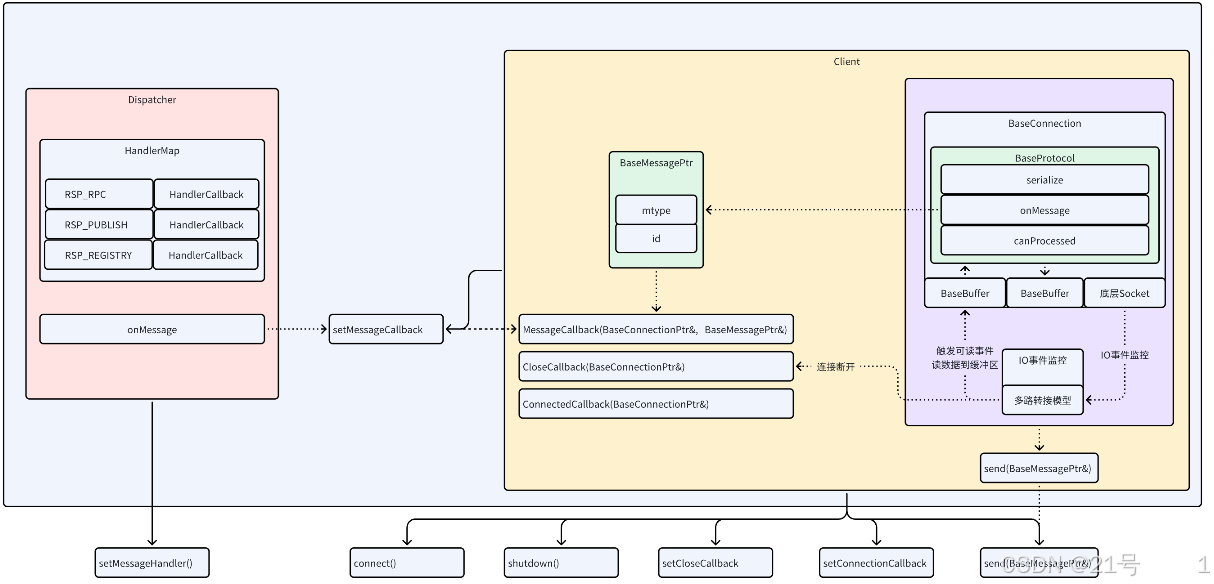
4.具象层
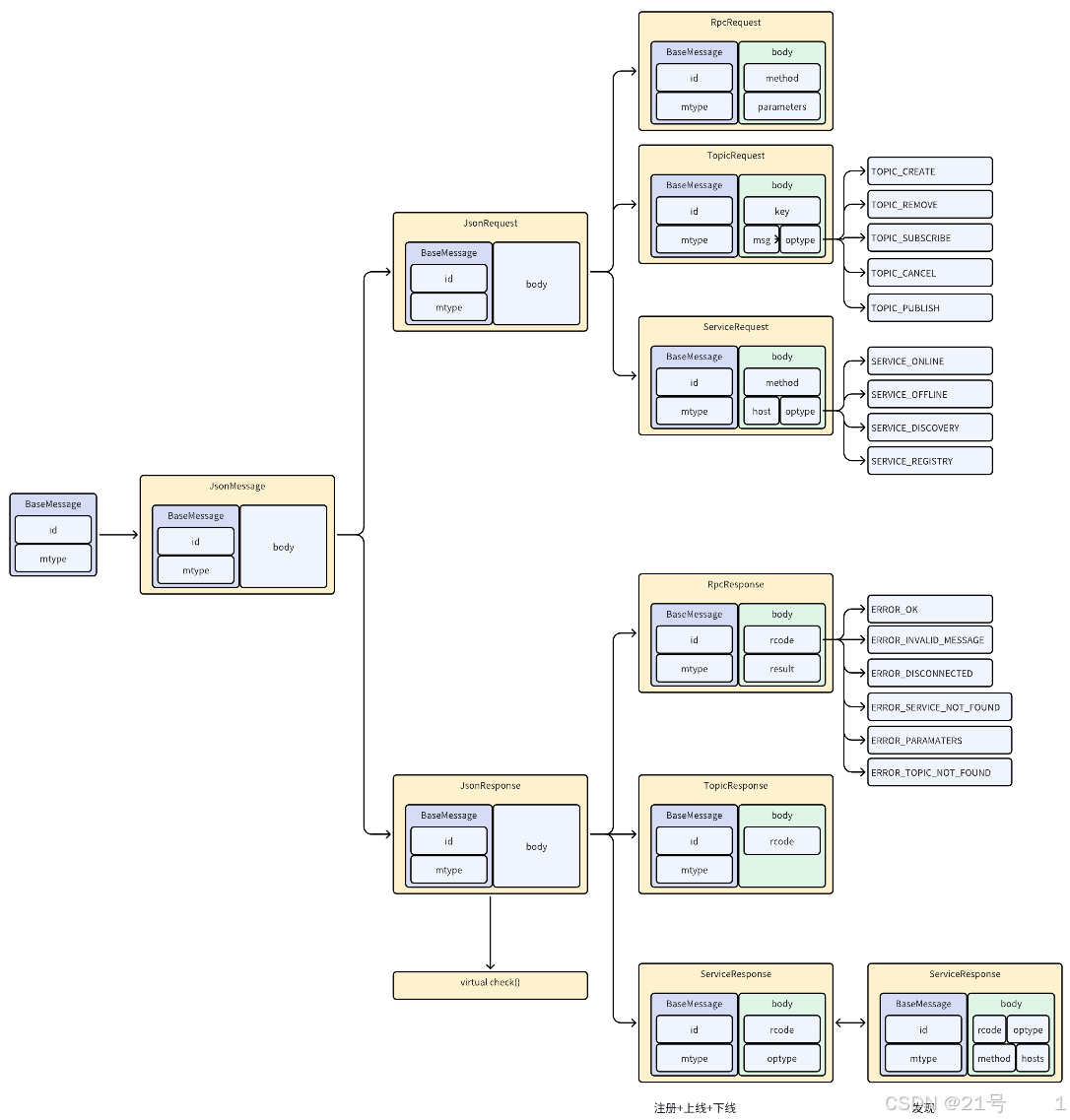
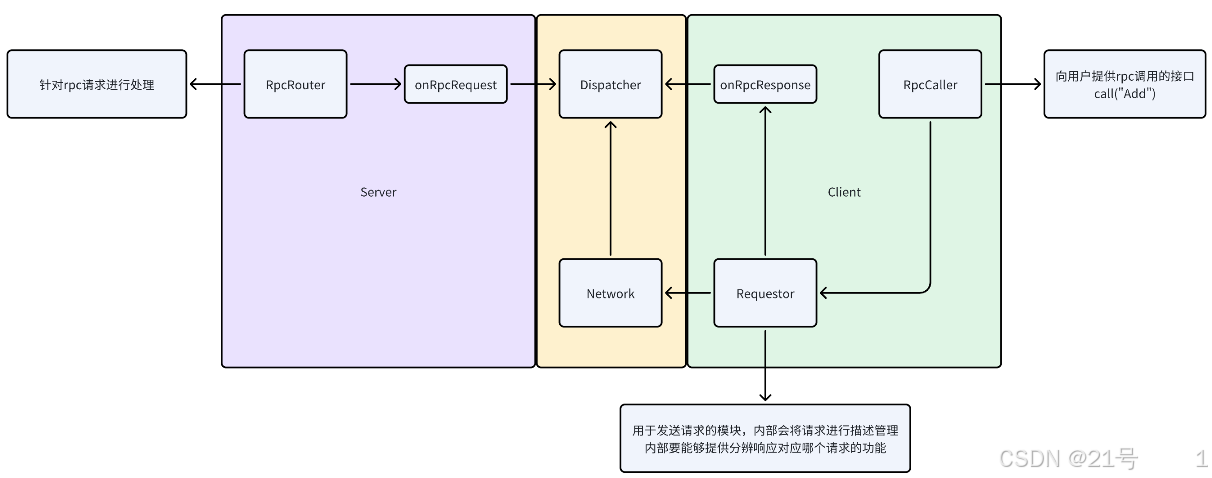
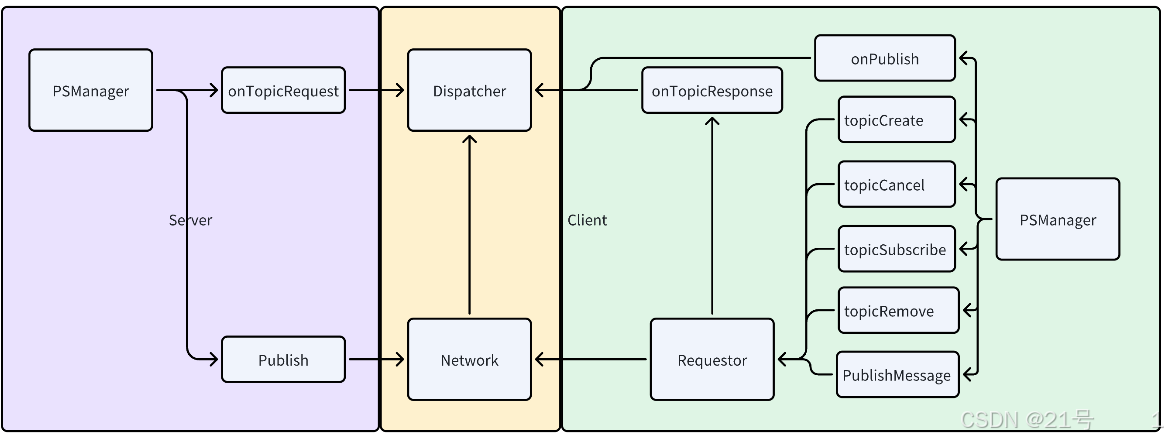
5.业务层
Rpc
发布订阅
服务注册&发现
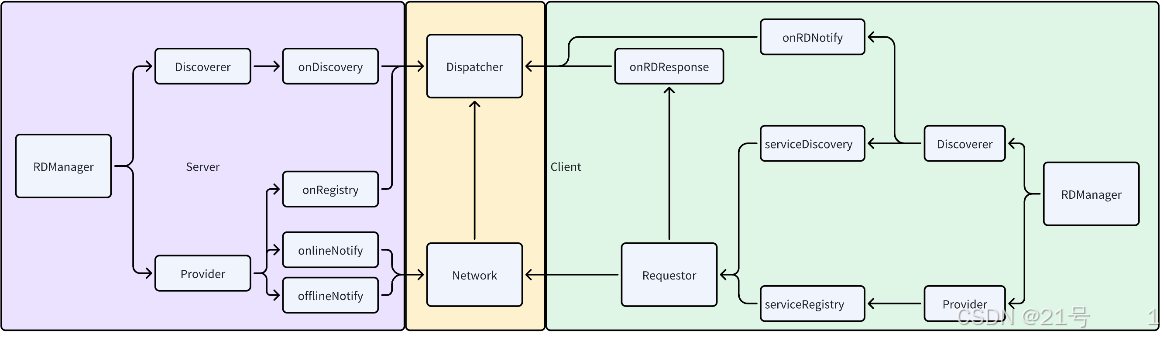
整体框架设计
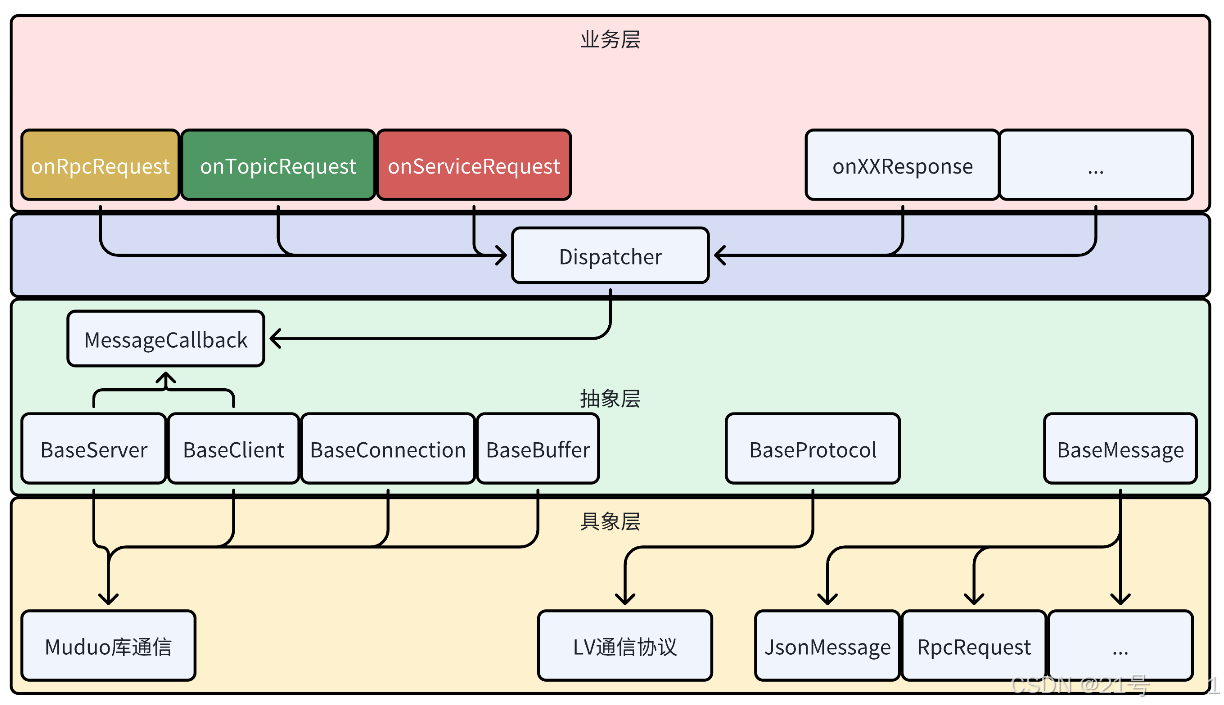
9.项目实现
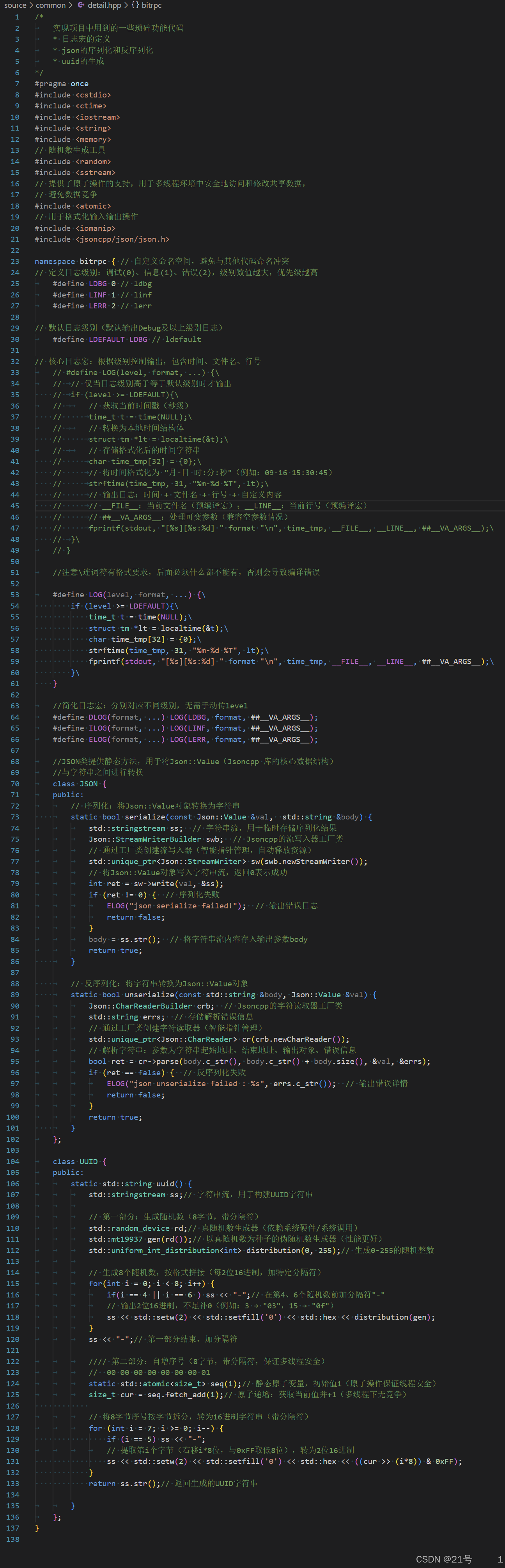
1.常用的零碎功能实现
1.简单日志宏实现
Json序列化/反序列化
UUID生成
UUID(Universally Unique Identifier), 也叫通⽤唯⼀识别码,通常由32位16进制数字字符组成。 UUID的标准型式包含32个16进制数字字符,以连字号分为五段,形式为8-4-4-4-12的32个字符, 如:550e8400-e29b-41d4-a716-446655440000。 在这⾥,uuid⽣成,我们采⽤⽣成8个随机数字,加上8字节序号,共16字节数组⽣成32位16进制字符的组合形式来确保全局唯⼀的同时能够根据序号来分辨数据。
detail.hpp
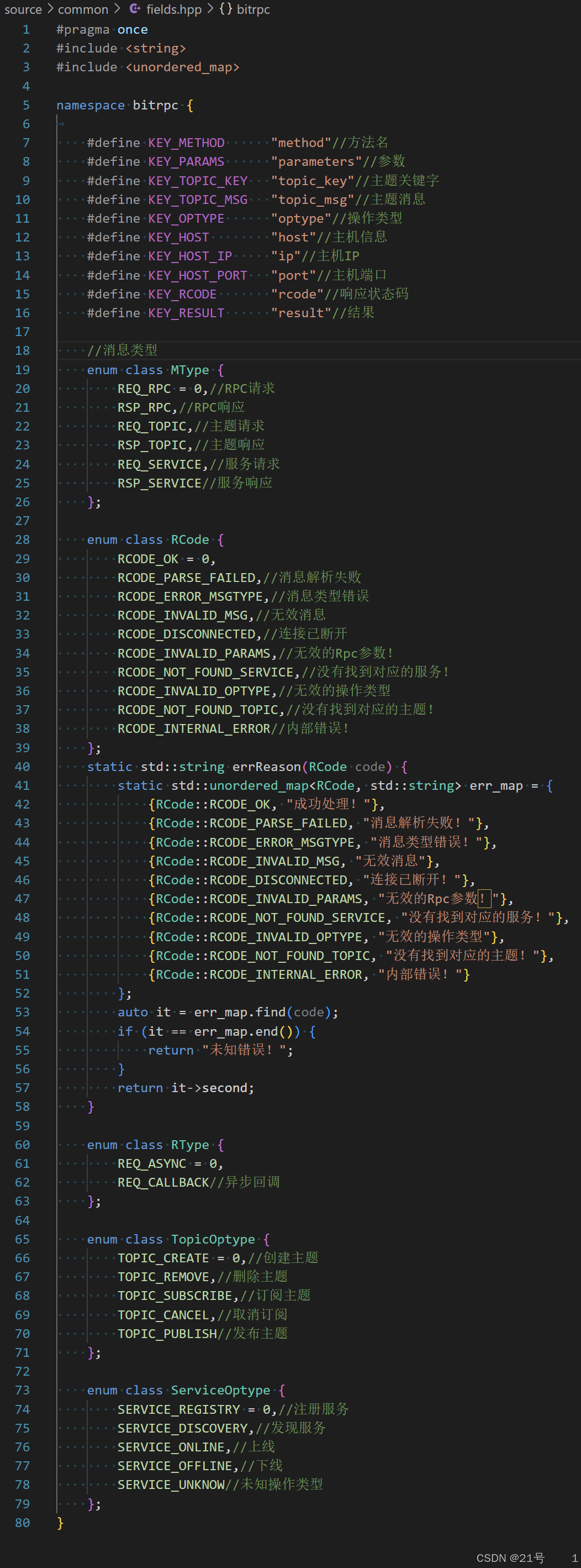
2.项目消息类型字段信息定义
1.请求字段宏定义
#define KEY_METHOD "method"#define KEY_PARAMS "parameters"#define KEY_TOPIC_KEY "topic_key"#define KEY_TOPIC_MSG "topic_msg"#define KEY_OPTYPE "optype"#define KEY_HOST "host"#define KEY_HOST_IP "ip"#define KEY_HOST_PORT "port"#define KEY_RCODE "rcode"#define KEY_RESULT "result"
2.消息类型定义
enum class MType {REQ_RPC = 0,RSP_RPC,REQ_TOPIC,RSP_TOPIC,REQ_SERVICE,RSP_SERVICE
};
3.响应码类型定义
enum class RCode {RCODE_OK = 0,RCODE_PARSE_FAILED,RCODE_ERROR_MSGTYPE,RCODE_INVALID_MSG,RCODE_DISCONNECTED,RCODE_INVALID_PARAMS,RCODE_NOT_FOUND_SERVICE,RCODE_INVALID_OPTYPE,RCODE_NOT_FOUND_TOPIC,RCODE_INTERNAL_ERROR
};
static std::string errReason(RCode code) {static std::unordered_map<RCode, std::string> err_map = {{RCode::RCODE_OK, "成功处理!"},{RCode::RCODE_PARSE_FAILED, "消息解析失败!"},{RCode::RCODE_ERROR_MSGTYPE, "消息类型错误!"},{RCode::RCODE_INVALID_MSG, "⽆效消息"},{RCode::RCODE_DISCONNECTED, "连接已断开!"},{RCode::RCODE_INVALID_PARAMS, "⽆效的Rpc参数!"},{RCode::RCODE_NOT_FOUND_SERVICE, "没有找到对应的服务!"},{RCode::RCODE_INVALID_OPTYPE, "⽆效的操作类型"},{RCode::RCODE_NOT_FOUND_TOPIC, "没有找到对应的主题!"},{RCode::RCODE_INTERNAL_ERROR, "内部错误!"}};auto it = err_map.find(code);if (it == err_map.end()) {return "未知错误!";}return it->second;
}
4.RPC请求类型定义
enum class RType {REQ_ASYNC = 0,REQ_CALLBACK
};
5.主题操作类型定义
enum class TopicOptype {TOPIC_CREATE = 0,TOPIC_REMOVE,TOPIC_SUBSCRIBE,TOPIC_CANCEL,TOPIC_PUBLISH
};
6.服务操作类型定义
enum class ServiceOptype {SERVICE_REGISTRY = 0,SERVICE_DISCOVERY,SERVICE_ONLINE,SERVICE_OFFLINE,SERVICE_UNKNOW
};fields.hpp
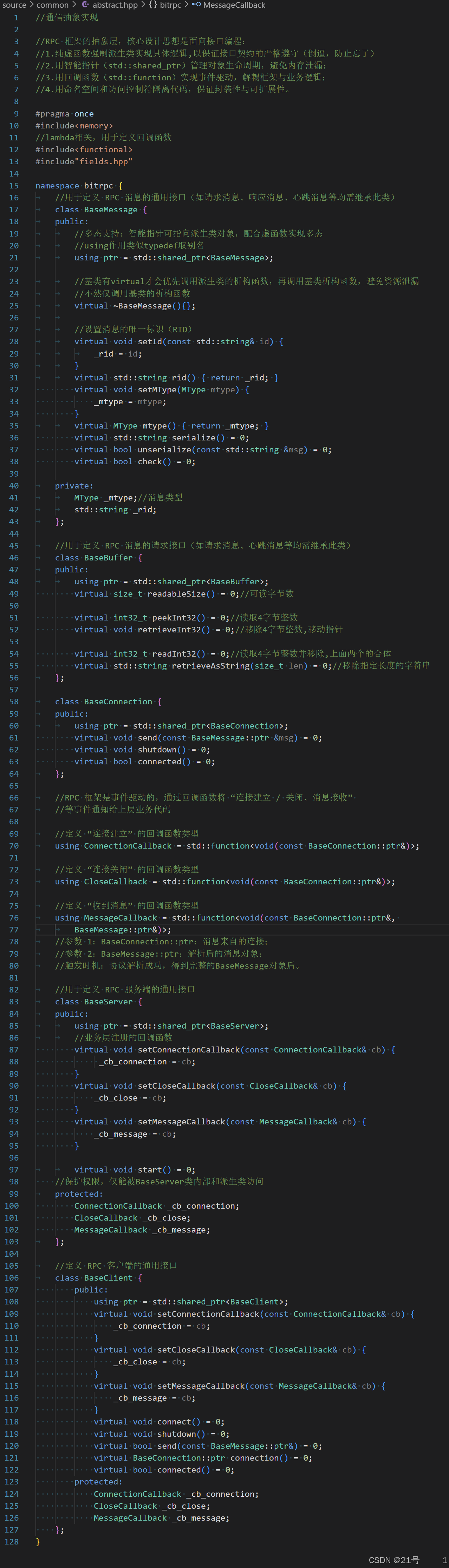
3.通信抽象实现
abstract.hpp
4.消息具体实现
message.hpp

5.通信-Muduo封装实现
防备一种情况:缓冲区中数据有很多很多。但是因为数据错误,导致数据又不足一条完整消息,也就是一条消息过大,针对这种情况,直接关闭连接
net.hpp

6.消息-不同消息封装实现
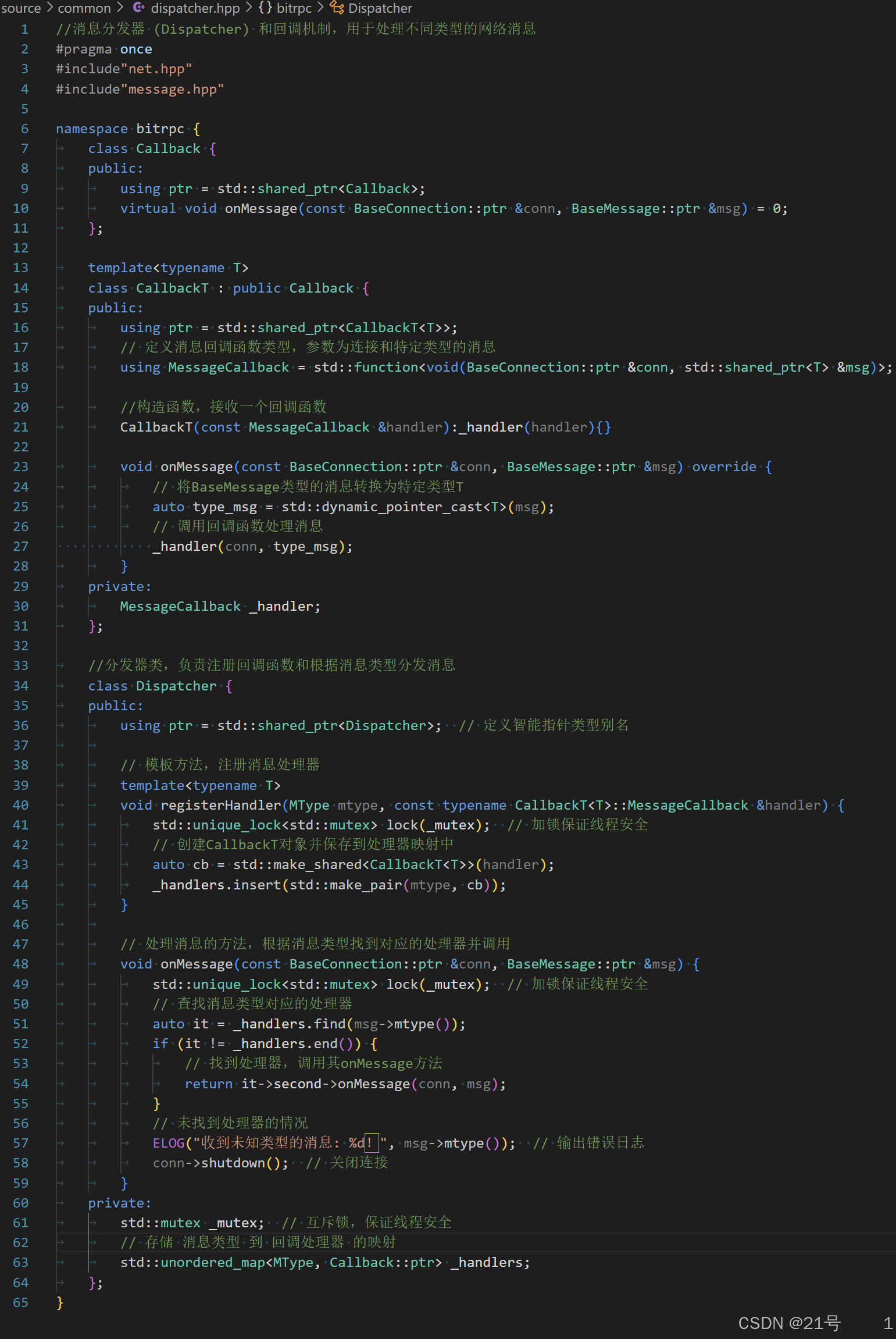
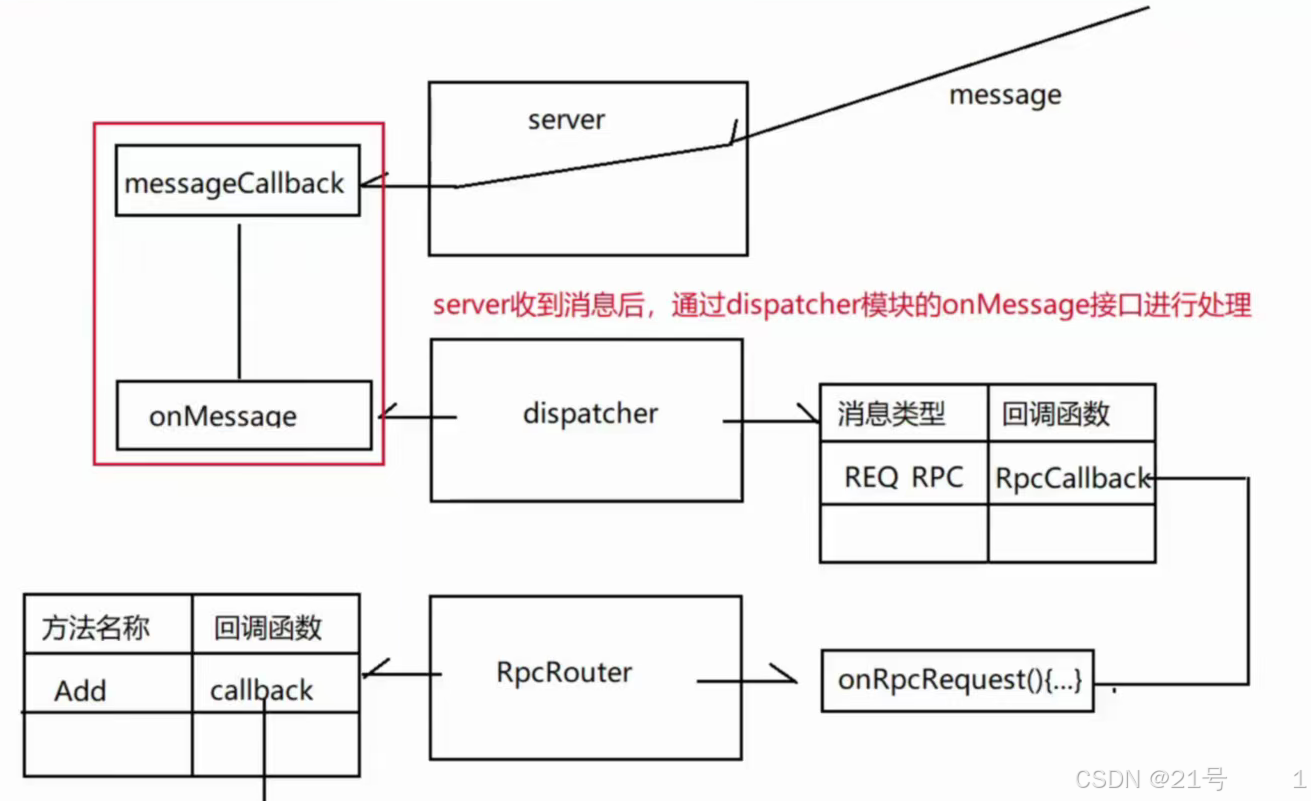
7.Dispatcher实现
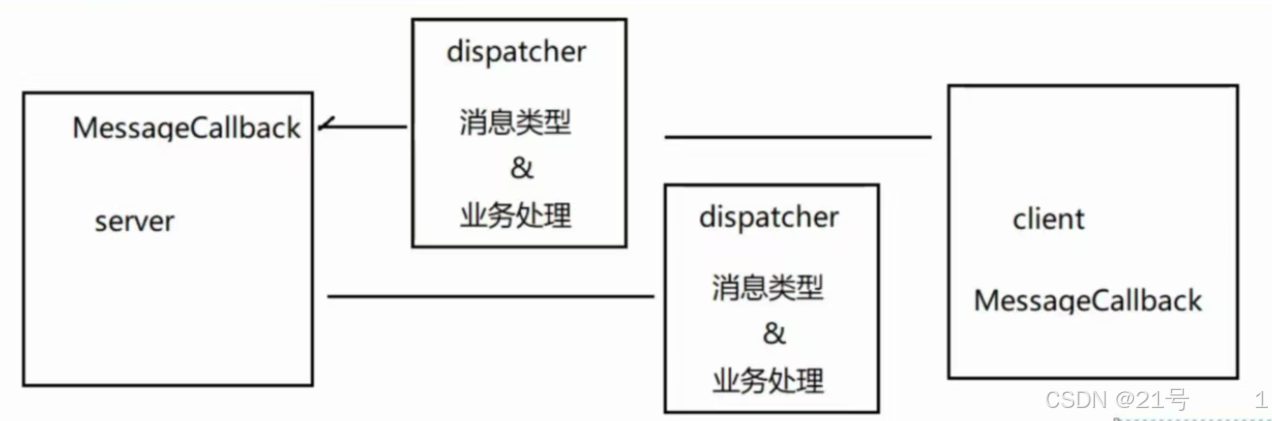
服务端会收到不同类型的请求,客户端会收到不同类型的响应(因为请求和响应都具有多样性)
因此在回调函数中,就需要判断消息类型,根据不同类型的消息做出不同的处理;如果单纯使用if语句做分支处理,是一件非常不好的事
程序设计中需要遵守一个原则:开闭原则 --- 对修改关闭,对扩展开放
当后期维护代码或新增功能时:不去修改以前的代码,而是新增当前需要的代码
Dispatcher模块就是基于开闭原则设计的;目的就是建立消息类型与业务回调函数的映射关系;如果后期新增功能,不需要修改以前的代码,只需要增加一个映射关系即可
Dispatcher.hpp
8.服务端-RpcRouter实现
在rpc请求中,可能会有大量不同的rpc请求:比如加法,翻译... 作为服务端,首先要对自己所能提供的服务进行管理,以便于收到请求后,能够明确判断自身能否提供客户端所请求的服务。
能提供服务,则调用接口进行处理,返回结果;
不能提供服务,则响应客户端请求的服务不存在。
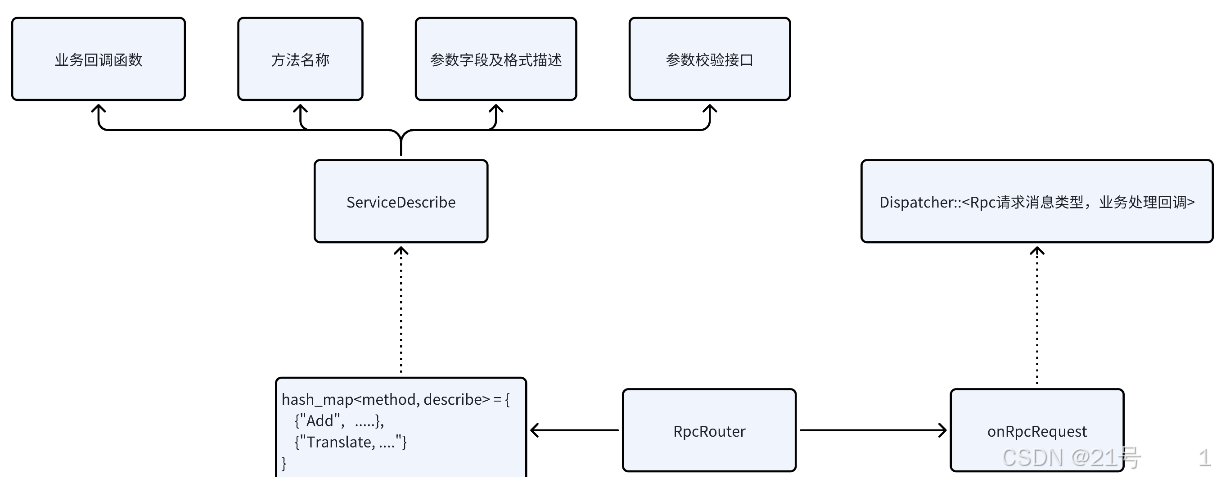
RpcRouter模块:一共枚举四个类
1.枚举类:枚举出rpc请求参数的类型(布尔,整形,浮点型,浮点数,字符串,数组,对象)
2.服务描述类:
1.业务回调函数 --- Add处理回调函数
2.参数信息描述 --- pair<参数字段名称,参数字段类型> {<“num1”,int>,<“num2”,int>}
3.返回值类型描述 --- int
4.提供参数校验接口 --- 针对请求中的参数,判断是否包含有num1字段,其类型是否是整形;处理逻辑:收到一个rpc请求后,取出方法名称,参数信息;通过方法名称Add,找到Add服务的描述对象,先进行参数校验,校验参数中是否有num1字段,且类型是整形... 判断都没问题则调用回调函数进行处理。
3.服务管理类:服务端会提供很多方法服务,需要进行良好的管理
std::hash_map<方法名称,服务描述> 通过这个hash_map就可以很容易判断能否提供服务
4.对外RpcRouter类
1.服务注册接口; 2.提供给dispatcher模块的rpc请求处理回调函数
rpc_router.hpp
9.服务端-Publish&Subscribe实现
rpc_topic.hpp

10.服务端-Registry&Discovery实现
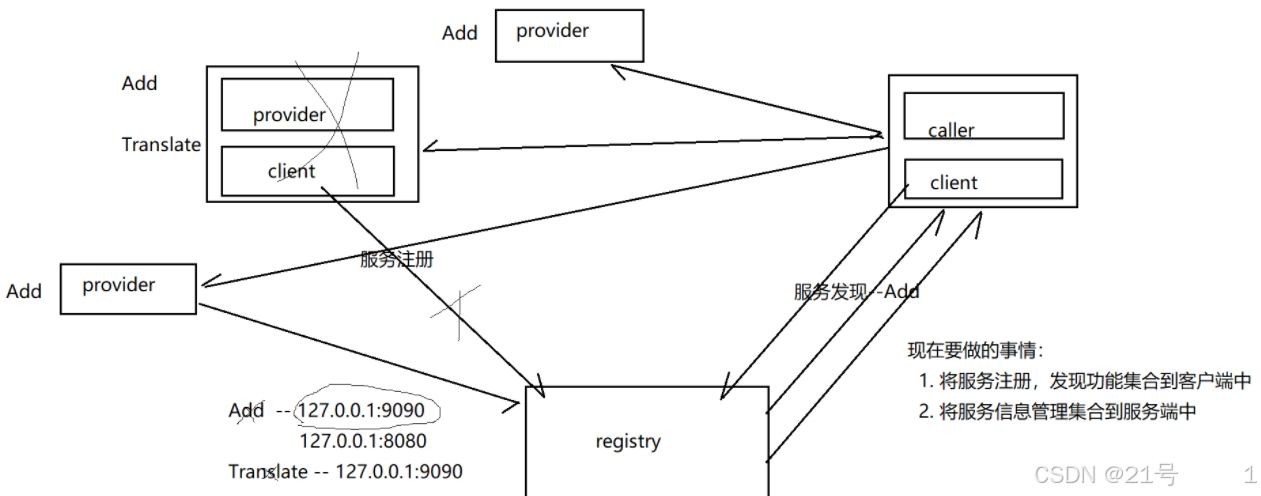
1.为什么要注册服务,服务注册是要做什么?
服务注册是要实现分布式系统,让系统更加强壮;一个节点主机,将自己所能提供的服务,在注册中心进行登记。
2.为什么要服务发现,服务发现要做什么?
rpc调用者需要知道哪个节点主机能够为自己提供指定服务;服务发现其实就是询问注册中心,谁能为自己提供指定的服务,将节点信息给保存起来以待后用。
3.服务下线
当前使用长连接进行服务主机是否在线的判断,一旦服务提供方断开连接,查询这个主机提供了哪些服务,分析哪些调用者进行过这些服务发现,则进行服务下线通知。
4.服务上线
因为服务发现是一锤子买卖(调用方不会进行二次服务发现),因此一旦中途有新主机可以提供指定服务,调用方是不知道的;因此,一旦某个服务上线了,则对发现过这个服务的主机进行一次服务上线通知。
服务端要能够提供服务注册,发现的请求业务处理
- 需要将 哪个服务 能够由 哪个主机提供 管理起来 hash<method, vector<provider>>
实现当由 caller 进行服务发现的时候,告诉 caller 谁能提供指定的服务 - 需要将 哪个主机 发现过 哪个服务 管理起来
当进行服务通知的时候,都是根据谁发现过这个服务,才会给谁通知 <method,vector<discoverer>> - 需要将 哪个连接 对应哪个 服务提供者 管理起来 hash<conn, provider>
当一个连接断开的时候,能够知道哪个主机的哪些服务下线了,然后才能给发现者通知 xxx 的 xxx 服务下线了 - 需要将 哪个连接 对应哪个 服务发现者 管理起来 hash<conn, discoverer>
当一个连接断开的时候,如果有服务上线下线,就不需要给他进行通知了
rpc_registry.hpp

11.服务端-整合封装Server(有点问题)
rpc_server.hpp
12.客户端-Requestor实现
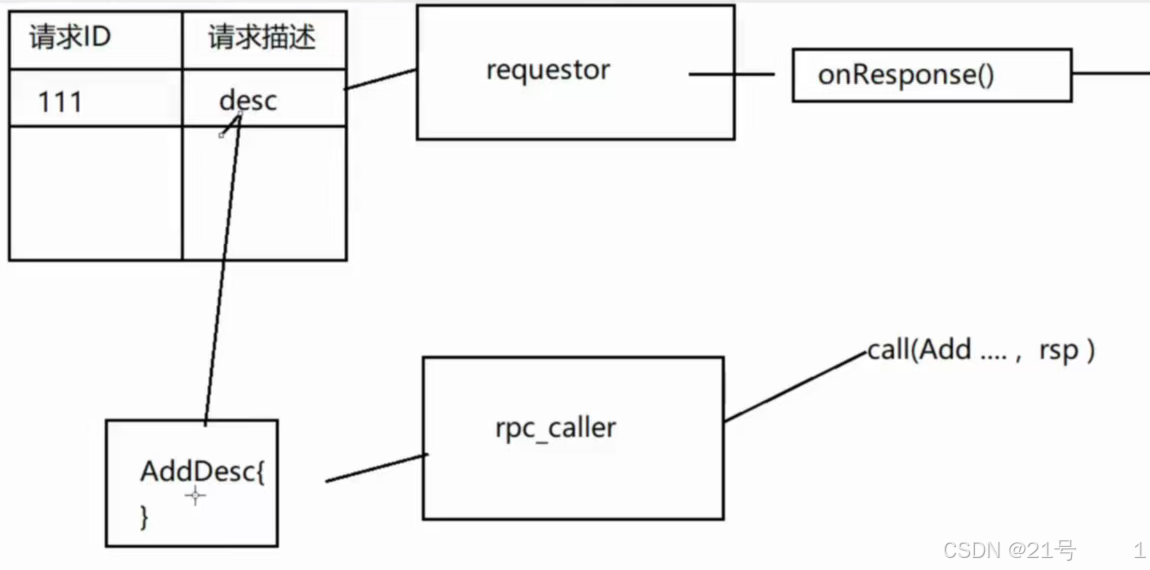
requestor.hpp
13.客户端-RpcCaller实现
rpc_caller.hpp
14.客户端-Publish&Subscribe实现
rpc_topic.hpp
15.客户端-Registry&Discovery实现
客户端的功能比较分离,注册端跟发现端根本就不在同一个主机上。
因此客户端的注册与发现功能是完全分离的
- 作为服务提供者 --- 需要一个能够进行服务注册的接口
连接注册中心,进行服务注册, - 作为服务发现者 --- 需要一个能够进行服务发现的接口,需要将获取到的能够提供指定服务的主机信息管理起来
hash<method, vector<host>> 一次发现,多次使用,没有的话再次进行发现。
需要进行服务上线 / 下线通知请求的处理(需要向 dispatcher 提供一个请求处理的回调函数)
因为客户端在一次服务发现中,会一次获取多个能够提供服务的主机地址信息,到底请求谁合理?
负载均衡的思想:RR 轮转
rpc_registry.hpp
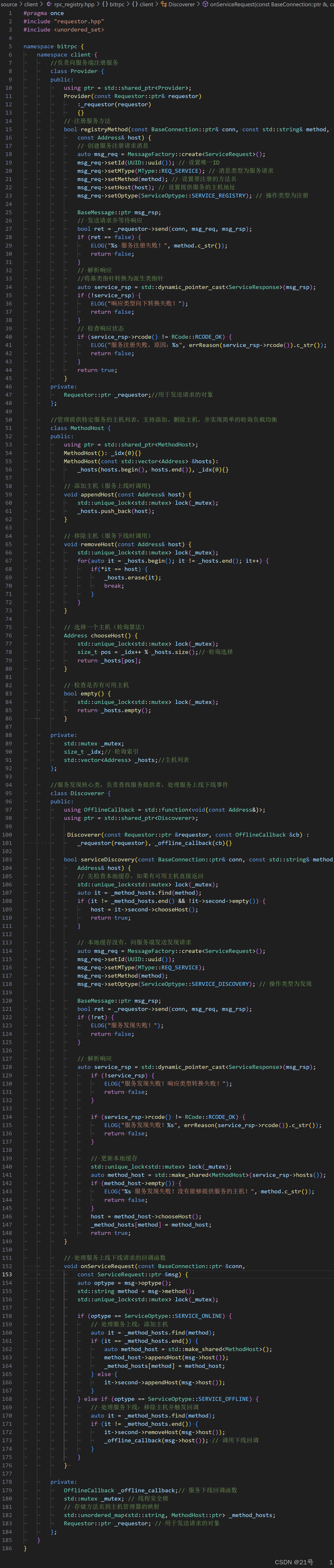
16.客户端-整合封装Client
rpc_client.hpp

17.整合封装RpcServer & RpcClient
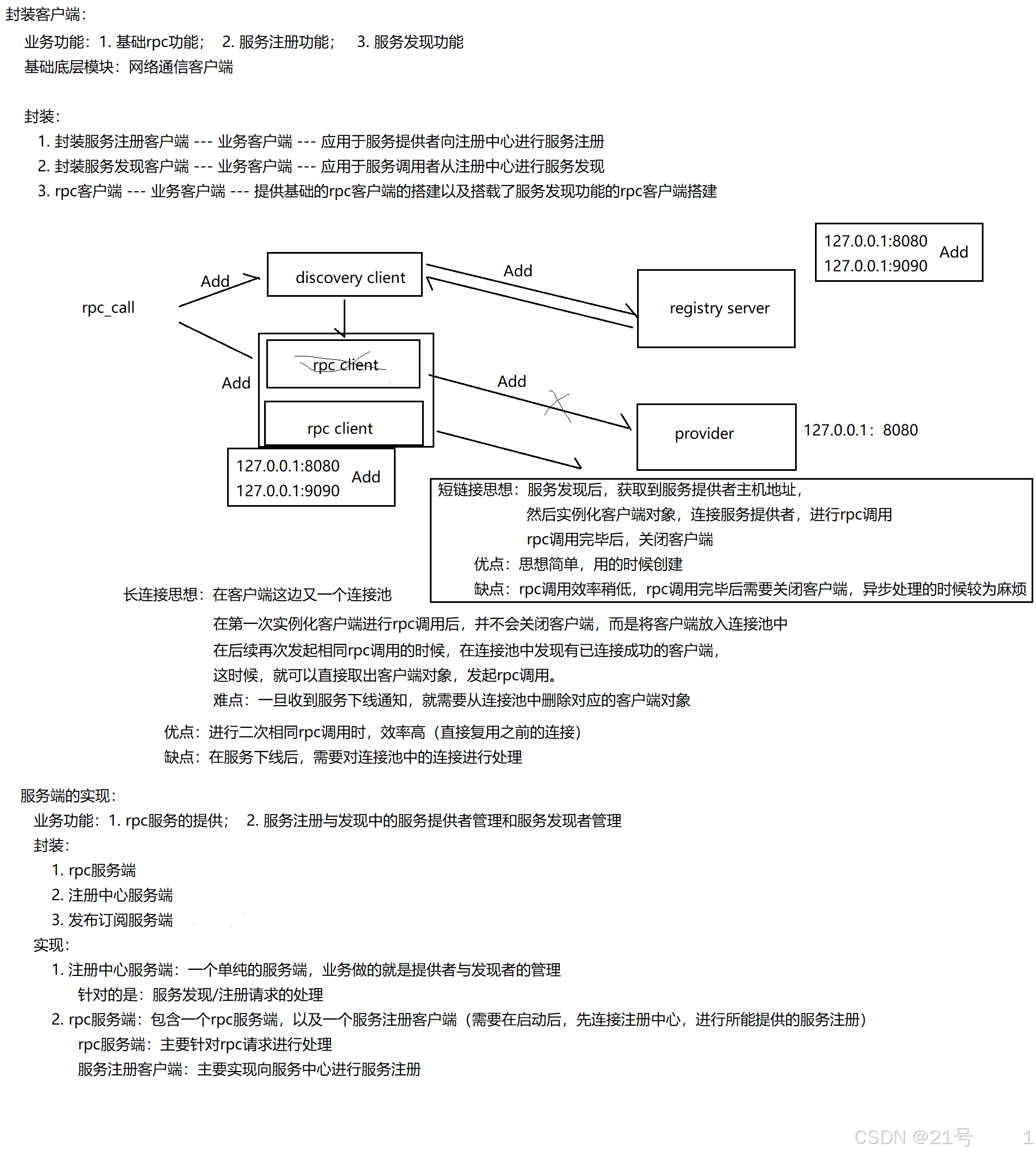
附录:
1.工厂模式
工厂模式是创建型设计模式的核心之一,其核心思想是 “封装对象的创建过程”,通过一个统一的 “工厂” 类或方法来生成目标对象,而非让客户端直接使用 new 关键字创建。这样可以降低客户端与具体产品类的耦合度,提高代码的可扩展性和可维护性。
一、为什么需要工厂模式?(解决的问题)
在直接使用 new 创建对象的场景中,客户端需要知道具体产品类的完整名称(如 new ApplePhone()),且一旦产品类发生变化(如类名修改、构造逻辑调整),所有使用该类的客户端代码都需要修改 —— 这违反了设计模式的 “开闭原则”(对扩展开放、对修改关闭)。
工厂模式通过以下方式解决问题:
- 客户端只需请求工厂 “生产” 对象,无需知道对象的具体创建细节;
- 新增产品时,只需扩展工厂,无需修改现有客户端代码;
- 统一管理对象创建逻辑(如初始化参数、依赖注入、单例控制等),避免代码重复。
二、工厂模式的三种核心实现形式
工厂模式根据复杂度和适用场景,分为简单工厂模式、工厂方法模式和抽象工厂模式,三者层层递进,满足不同规模的需求(详细介绍请查看相关文献)
| 特性 | 简单工厂模式 | 工厂方法模式 | 抽象工厂模式 |
|---|---|---|---|
| 核心能力 | 生产单一产品族的所有产品 | 生产单一产品族的单个产品 | 生产多个相关产品族的所有产品 |
| 工厂数量 | 1 个(单一工厂) | N 个(1 个产品对应 1 个工厂) | M 个(1 个产品族对应 1 个工厂) |
| 开闭原则兼容性 | 不兼容(新增产品需改工厂) | 兼容(新增产品只需加工厂) | 兼容产品族,不兼容产品等级 |
| 适用场景 | 产品固定且少 | 产品频繁新增 | 需统一产品族 |
四、工厂模式的实际应用场景
- 框架底层设计:如 Spring 框架的
BeanFactory(创建 Bean 对象)、MyBatis 的SqlSessionFactory(创建 SqlSession); - 跨平台组件创建:如游戏引擎的 “图形渲染工厂”(Windows 用 DirectX 工厂,Linux 用 OpenGL 工厂);
- 插件化架构:如 IDE 的 “插件工厂”(不同插件对应不同工厂,动态创建插件实例);
- 复杂对象创建:如对象需要多步初始化(如连接数据库、加载配置),工厂统一管理创建逻辑,避免客户端重复代码
通过工厂模式,代码的 “创建逻辑” 与 “使用逻辑” 分离,更符合 “高内聚、低耦合” 的设计目标,是大型项目中最常用的设计模式之一。
枚举enum
枚举的核心价值是 “用有意义的名字替代无意义的数字”
| 特性 | 传统枚举(Plain Enum) | 强类型枚举(Scoped Enum) |
|---|---|---|
| 作用域 | 成员暴露在当前作用域 | 成员隔离在枚举作用域内 |
| 命名冲突 | 易冲突 | 无冲突 |
| 隐式转换 | 支持(转 int) | 不支持(需显式转换) |
| 底层类型自定义 | C++11 后支持,但语法繁琐 | 直接支持(: 类型) |
| 推荐度 | 不推荐(仅兼容旧代码) | 强烈推荐(类型安全、清晰) |
2.完美转发回顾
“完美转发(Perfect Forwarding)” 是 C++11 及后续版本中,借助右值引用和模板参数推导,实现的一种能让函数模板 “精准传递” 参数值类别(左值 / 右值)的技术。它的核心目的是:让模板函数接收到的参数,能以和原始调用时完全一致的 “值类别”,传递给内部调用的其他函数,避免不必要的拷贝或移动,同时保留参数的 “左值 / 右值” 属性。
一、为什么需要完美转发?
在模板编程中,函数模板的参数往往是万能引用(T&&,结合模板参数推导时,既可以绑定左值,也可以绑定右值)。但如果直接传递这些参数,可能会丢失原始的 “左值 / 右值” 属性,导致:
- 本该移动(
move)的右值,被当作左值进行拷贝,造成性能浪费。 - 内部函数无法根据参数的 “左值 / 右值” 属性,选择最优的重载版本(如
std::vector::push_back对左值做拷贝,对右值做移动)。
二、完美转发的实现:std::forward
std::forward 是 <utility> 头文件中的模板函数,专门用于 “恢复” 参数的原始值类别。它的核心逻辑是:
- 若模板参数
T推导为左值引用(如int&),则std::forward<T>(arg)会将参数以左值形式转发。 - 若模板参数
T推导为非引用类型或右值引用(如int或int&&),则std::forward<T>(arg)会将参数以右值形式转发。
三、代码示例:理解完美转发
#include <iostream>
#include <utility>
#include <string>// 模拟一个需要区分左值/右值的函数
void processValue(int& val) {std::cout << "处理左值,值为:" << val << std::endl;
}void processValue(int&& val) {std::cout << "处理右值,值为:" << val << std::endl;
}// 模板函数:使用完美转发
template <typename T>
void forwardValue(T&& val) {// 关键:用 std::forward 转发参数,恢复原始值类别processValue(std::forward<T>(val));
}int main() {int x = 10;// 情况1:传递左值forwardValue(x); // 输出:处理左值,值为:10// 情况2:传递右值(临时对象)forwardValue(20); // 输出:处理右值,值为:20// 情况3:传递右值引用(延长临时对象生命周期)int&& rref = 30;forwardValue(std::move(rref)); // 输出:处理右值,值为:30return 0;
}
四、步骤拆解(以 forwardValue(20) 为例)
模板参数推导:
调用forwardValue(20)时,20是右值,模板参数T会被推导为int(因为T&&结合右值推导为int&&,但T本身是int)。std::forward<T>(val)的作用:
此时T是int,std::forward<int>(val)会将val(原本是右值20)以右值形式转发给processValue,因此调用processValue(int&& val)版本。如果不用完美转发:
若直接写processValue(val),val在forwardValue内部是左值(因为有名字的变量都是左值),会调用processValue(int& val),无法利用右值的移动语义,也不符合 “传递右值” 的意图。
五、典型应用场景:工厂模式 / 容器插入
完美转发在需要传递参数到其他函数,且需要保留参数值类别的场景中非常有用,比如:
- 工厂类创建对象时,传递构造参数(如前面的
MessageFactory::create<T>(Args&&... args),需要将参数精准传递给T的构造函数)。 - 容器插入元素时(如
std::vector::emplace_back,直接在容器内构造对象,避免拷贝)。
六、总结
完美转发是 C++ 模板编程中 “精准传递参数值类别” 的关键技术,核心依赖:
- 右值引用(实现万能引用,让模板参数能绑定左值或右值)。
std::forward(根据模板参数推导结果,恢复参数的原始左值 / 右值属性)。
它解决了模板中参数值类别丢失的问题,让模板函数能像普通函数一样,根据参数的 “左值 / 右值” 选择最优的处理逻辑,同时避免不必要的性能开销。
3.建造者模式
建造者模式的核心是 **“分步构建复杂对象,通过不同的构建步骤或细节组合,生成不同表现的对象”**。它专注于解决 “如何创建具有多个组成部分、构建步骤复杂的对象”(如 “定制电脑”“复杂文档”)。
1. 核心思想
将复杂对象的 “构建过程” 与 “对象表示” 分离:客户端无需关心对象的具体构建步骤,只需通过 “指挥者” 指定构建流程,或直接通过 “建造者” 控制细节。
2. 核心角色
- 产品(Product):待构建的复杂对象(如 “电脑”,包含 CPU、内存、显卡等部件)。
- 抽象建造者(Abstract Builder):定义构建产品的 “分步接口”(如
buildCPU()、buildMemory()),以及返回产品的接口(getProduct())。 - 具体建造者(Concrete Builder):实现抽象建造者,负责具体部件的构建(如 “游戏本建造者”“办公本建造者”)。
- 指挥者(Director):可选角色,封装 “标准构建流程”(如 “先装 CPU→再装内存→最后装显卡”),避免客户端重复编写流程。
优点:
- 解耦构建与表示:同一构建流程可生成不同产品(如 “游戏本”“办公本”)。
- 灵活控制构建细节:客户端可自定义构建步骤(如先装内存再装 CPU)。
- 便于扩展:新增产品(如 “设计本”)只需新增具体建造者,无需修改其他类。
缺点:
- 结构复杂:需新增多个建造者类,适合复杂对象;简单对象使用会增加冗余。
- 产品需有共性:建造者针对的是 “同一类产品的不同配置”,若产品差异过大则不适用。
适用场景:
- 对象包含多个部件,且部件组合不同会产生不同表现(如定制电脑、汽车、文档)。
- 构建步骤复杂或需灵活调整步骤顺序。
- 需隔离对象的构建细节与使用逻辑。
| 维度 | 工厂模式 | 建造者模式 |
|---|---|---|
| 核心目标 | 快速创建 “同家族的不同对象” | 分步构建 “复杂对象的不同配置” |
| 关注重点 | “创建什么”(对象类型) | “怎么创建”(构建步骤与细节) |
| 产品特点 | 产品是 “不同类型但同接口”(如 iPhone、华为) | 产品是 “同一类型但不同配置”(如游戏本、办公本) |
| 构建流程 | 无显式步骤,一次性创建完毕 | 有明确分步步骤,可控制顺序和细节 |
| 角色核心 | 工厂(负责对象创建逻辑) | 建造者(负责部件构建)+ 指挥者(可选,控流程) |
| 典型场景 | 生成不同品牌的手机、数据库驱动 | 定制电脑、汽车组装、复杂文档生成 |
4.异步响应与事件驱动
异步响应就是 “不傻等” 的回应方式—— 发起请求后,不用一直盯着等结果,可以先去做别的事,结果出来了再 “通知” 你
“去餐厅吃饭” 对比 “点外卖”,就能秒懂 “同步” 和 “异步” 的区别;去餐厅吃饭点完菜后,什么都做不了,只能盯着服务员 / 后厨,一直等菜端上桌,哈哈哈。而点外卖后,照样该干啥干啥,外卖小哥快到了,APP 会发消息提醒你 “快取餐”(这就是事件驱动),这时你再去门口拿就行。
异步响应解决了 “不阻塞” 的问题,事件驱动解决了 “怎么知道该处理结果了” 的问题。
没有事件驱动,异步响应很难高效实现(总不能靠 “一直问” 来等结果);而事件驱动的设计,也往往是为了支撑更灵活的异步交互(否则同步模式下,直接顺序执行就行,不需要 “事件” 来触发)
“异步响应依赖事件驱动,事件驱动服务于异步响应” 的紧密关系”
5.dynamic_pointer_cast
dynamic_pointer_cast 是智能指针库中的一个函数模板,用于在共享指针(std::shared_ptr)之间进行动态类型转换
它的主要作用是:
- 在继承层次结构中安全地将基类类型的
std::shared_ptr转换为派生类类型的std::shared_ptr - 进行运行时类型检查,如果转换失败,会返回一个空的
std::shared_ptr
使用 dynamic_pointer_cast 需要注意:
- 被转换的类型必须具有多态性(即至少有一个虚函数)
- 转换失败时不会抛出异常,而是返回空指针
- 它位于
<memory>头文件中,属于std命名空间 - 相比
static_pointer_cast,dynamic_pointer_cast会进行运行时类型检查,因此更安全但也有一定的性能开销
如果要转换 std::unique_ptr,则没有对应的 dynamic_pointer_cast,因为 unique_ptr 不支持这种转换(由于其独占所有权的特性)。
6.服务端中rpc_topic.hpp中为什么既要用结构体锁,又要用全局锁?
为什么要用结构体锁?
1. 避免 “全局大锁” 导致的性能瓶颈
TopicManager 本身已经有一个全局锁 _mutex,用于保护 _topics 和 _subscribers 这两个核心映射表。但如果仅依赖这个全局锁,会导致:
- 任何涉及主题或订阅者的操作(如订阅、发布、取消订阅)都需要竞争同一把锁,大量并发操作会被阻塞,形成性能瓶颈。
- 例如:两个完全无关的主题(如 “topicA” 和 “topicB”)的操作(如分别向它们发布消息),本可以并行执行,却会因为全局锁而串行化,效率低下。
结构体级别的锁(Subscriber::_mutex 和 Topic::_mutex)将锁的范围缩小到单个对象内部,使得不同对象的操作可以并行进行。
2. 保护结构体内部数据的独立修改
Subscriber 和 Topic 都有自己的内部状态需要保护:
Subscriber的topics集合(订阅的主题列表)可能被多个线程同时修改(如同时订阅两个主题、或取消订阅)。Topic的subscribers集合(订阅者列表)也可能被多个线程同时修改(如多个订阅者同时订阅、或一个订阅者取消订阅)。
如果仅依赖 TopicManager 的全局锁,当需要修改这些内部数据时,必须先获取全局锁,这会导致:
- 即使两个操作涉及不同的
Subscriber或Topic,也需要等待全局锁,浪费并发机会。 - 例如:两个不同的订阅者分别取消订阅不同的主题,本可以独立进行,但全局锁会强制它们串行执行。
结构体内部的锁确保:只有修改同一个 Subscriber 或 Topic 时才需要竞争锁,不同对象的修改可以完全并行。
3. 支持更细粒度的 “读 - 写” 分离
在实际场景中,Subscriber 和 Topic 的 “读操作”(如遍历订阅者列表发送消息)可能远多于 “写操作”(如添加 / 删除订阅者)。结构体级别的锁可以:
- 允许对同一对象的 “读操作” 并行执行(如果使用
std::shared_mutex等读写锁)。 - 仅在 “写操作” 时阻塞其他操作,进一步提升并发效率。
例如:Topic::pushMessage(向所有订阅者发送消息)是典型的 “读操作”(遍历 subscribers),如果多个线程同时向不同的 Topic 发送消息,结构体锁可以让这些操作并行执行,而无需等待全局锁。
4. 降低死锁风险
全局锁的过度使用容易导致死锁。例如:
- 线程 1 先持有全局锁,尝试修改
TopicA,此时需要TopicA的内部锁(如果有的话)。 - 线程 2 先持有
TopicA的内部锁,尝试获取全局锁修改_topics。
这种情况下会产生死锁。而结构体级别的锁通过缩小锁的范围,减少了不同锁之间的交叉依赖,从而降低死锁风险。
总结
结构体级别的锁是 “最小权限原则” 在并发编程中的体现:仅对需要保护的最小范围(单个 Subscriber 或 Topic)加锁,既能保证线程安全,又能最大化并发性能。这对于高并发的发布 - 订阅系统尤为重要,可有效避免全局锁带来的性能瓶颈。
为什么要用全局锁?
在 TopicManager 中,结构体锁(Subscriber::_mutex、Topic::_mutex) 和 全局锁(_mutex) 并非替代关系,而是职责分工不同的互补设计。全局锁的存在是为了保护跨结构体的全局映射关系,这些关系无法被单个结构体的锁覆盖。具体原因如下:
1. 全局锁保护 “跨对象的映射表”
TopicManager 维护了两个核心的全局映射表:
_topics:std::unordered_map<std::string, Topic::ptr>(主题名 → 主题对象)_subscribers:std::unordered_map<BaseConnection::ptr, Subscriber::ptr>(连接 → 订阅者对象)
这些映射表是跨所有结构体的全局数据,其本身的增、删、查操作需要线程安全保证。例如:
- 创建主题时,需要向
_topics插入新的键值对; - 删除主题时,需要从
_topics中删除对应的键值对; - 订阅主题时,需要先从
_topics中查找主题对象,再从_subscribers中查找或创建订阅者对象。
这些操作涉及对全局映射表的修改或查找,而单个 Topic 或 Subscriber 的结构体锁只能保护自身内部数据(如 Topic::subscribers 或 Subscriber::topics),无法保护全局映射表的结构完整性。如果没有全局锁,多个线程同时对 _topics 或 _subscribers 进行插入 / 删除,可能导致哈希表崩溃(如迭代器失效、数据丢失等)。
2. 全局锁保证 “多对象操作的原子性”
很多业务逻辑需要跨多个结构体的操作,这些操作必须作为一个原子步骤完成,否则会出现数据不一致。例如:
示例 1:订阅主题(topicSubscribe)
订阅操作需要同时操作三个对象:
- 从
_topics中查找Topic对象(全局映射); - 从
_subscribers中查找或创建Subscriber对象(全局映射); - 将
Subscriber添加到Topic的订阅者列表(Topic内部数据); - 将
Topic名称添加到Subscriber的主题列表(Subscriber内部数据)。
如果没有全局锁,步骤 1 和步骤 2 可能被其他线程打断(比如在查找 Topic 后,该 Topic 被另一个线程删除),导致后续操作基于无效数据执行(如向已删除的 Topic 中添加订阅者)。全局锁确保 “查找 Topic 和 Subscriber” 这两个跨映射表的操作是原子的,避免中间状态被其他线程干扰。
示例 2:删除主题(topicRemove)
删除主题需要:
- 从
_topics中查找并删除Topic对象(全局映射); - 遍历该
Topic的所有订阅者,从每个订阅者的topics中移除该主题(涉及多个Subscriber内部数据)。
如果没有全局锁,步骤 1 中 “查找 Topic” 和 “删除 Topic” 之间可能插入其他操作(如新增订阅者),导致删除主题后仍有订阅者引用该主题,造成内存泄漏或无效消息发送。
3. 全局锁避免 “结构体锁的滥用与冲突”
结构体锁的作用范围是单个对象内部,如果试图用结构体锁覆盖全局映射表的操作,会导致两个问题:
- 锁粒度失控:为了保护全局映射表,可能需要对所有
Topic或Subscriber加锁,相当于退化为全局锁,且逻辑更复杂; - 死锁风险剧增:例如,线程 A 持有
TopicA的锁,试图获取TopicB的锁;线程 B 持有TopicB的锁,试图获取TopicA的锁,容易形成死锁。
全局锁通过统一保护全局映射表,避免了这种跨对象锁的滥用,降低了死锁概率。
总结:两者的职责边界
| 锁类型 | 保护范围 | 典型场景 |
|---|---|---|
全局锁(_mutex) | 全局映射表 _topics 和 _subscribers 的结构完整性;跨对象操作的原子性。 | 创建 / 删除主题、查找主题 / 订阅者、订阅初始化等。 |
| 结构体锁 | 单个 Topic 或 Subscriber 内部的数据(如 subscribers 列表、topics 列表)。 | 向主题添加 / 删除订阅者、订阅者添加 / 删除主题、向订阅者发送消息等。 |
简言之:全局锁管 “映射关系”,结构体锁管 “对象内部数据”。两者分工协作,既保证了全局数据结构的一致性,又通过细粒度锁提升了并发性能,是高并发场景下线程安全设计的典型实践
7.使用lambda解决bind参数不匹配问题/bind的理解



- 通过一个
_dispatcher(调度器)注册回调函数,用于处理某种响应消息(MType::RSP_SERVICE类型) - 当响应到达时,调度器会调用我们注册的回调函数,最终需要执行
client::Requestor类的onResponse成员函数来处理响应
二、核心问题:回调函数类型不匹配
调度器的registerHandler方法对回调函数的类型有严格要求,而我们的onResponse成员函数直接绑定会出现类型不兼容,具体表现为:
1. 调度器要求的回调类型
_dispatcher->registerHandler<T>()需要的回调函数(MessageCallback)通常定义为:
/ 伪代码:调度器期望的回调类型
using MessageCallback = std::function<void(BaseConnection::ptr&, / 连接对象(非const引用)std::shared_ptr<T> / 消息对象(shared_ptr智能指针)
)>;
2. 我们的onResponse成员函数
假设client::Requestor类中的处理函数是:
class client::Requestor {
public:// 我们的处理函数,参数可能与调度器要求不一致void onResponse(const BaseConnection::ptr& conn, // const引用(与调度器的非const冲突)BaseMessage::ptr& msg // 可能是另一种智能指针类型(与shared_ptr冲突)) {// 实际处理响应的逻辑}
};
3. 直接绑定的问题
当我们用std::bind直接绑定onResponse时:
// 原始绑定方式(会报错)
auto rsp_cb = std::bind(&client::Requestor::onResponse,_requestor.get(),std::placeholders::_1,std::placeholders::_2
);
会因为参数类型不匹配(const修饰符、智能指针类型差异)导致编译错误。
三、解决思路:用 Lambda 作为 "适配器"
核心方案是在调度器要求的回调类型和onResponse之间加一层 Lambda 表达式,解决类型不匹配问题:
1. Lambda 的角色
- 外层:Lambda 的参数严格匹配调度器要求的
MessageCallback类型(保证能被registerHandler接受) - 内层:在 Lambda 内部调用
onResponse,此时可以灵活处理参数类型转换(适配onResponse的参数要求)
2. 具体代码实现
// 1. 创建Lambda表达式作为回调
auto rsp_cb = [requestor = _requestor.get()]( // 捕获Requestor对象的原始指针BaseConnection::ptr& conn, // 第1个参数:严格匹配调度器要求(非const)std::shared_ptr<BaseMessage> msg // 第2个参数:严格匹配调度器要求(shared_ptr)
) {// 2. 在Lambda内部做参数转换,适配onResponse的要求const BaseConnection::ptr& const_conn = conn; // 转换为const引用BaseMessage::ptr msg_ref = msg; // 转换智能指针类型(如果需要)// 3. 调用实际的处理函数requestor->onResponse(const_conn, msg_ref);
};// 3. 注册回调(此时类型完全匹配,编译通过)
_dispatcher->registerHandler<BaseMessage>(MType::RSP_SERVICE, rsp_cb);
四、为什么 Lambda 能解决问题?
- 类型自动匹配:Lambda 的参数列表可以精确匹配
registerHandler的要求,避免std::bind的复杂类型推导问题 - 显式类型转换:在 Lambda 内部可以清晰地处理
const修饰符、智能指针类型等转换,逻辑更直观 - 简化代码:避免
std::placeholders占位符的使用,代码可读性更高 - 灵活性:如果未来
onResponse或调度器的参数有微小调整,只需修改 Lambda 内部的转换逻辑,无需大面积改动
五、总结
问题本质是回调函数的参数类型不匹配,解决方案是用 Lambda 作为中间适配器:
- 外层满足调度器的类型要求
- 内层适配
onResponse的参数需求
这种方式既解决了编译错误,又保证了代码的可读性和可维护性,是现代 C++ 中处理回调绑定的推荐做法。