企业级SQL审核工具PawSQL介绍(2)- 审核规则体系
目前SQL审核工具普遍存在几个关键痛点:对不同数据库的审核规则支持不一,难以适配多样化的数据库环境;解析能力有限,面对复杂SQL时力不从心;只能机械“报错”,却无法给出真正有效的优化建议。这导致审核过程常常流于形式,开发者疲于应对大量误报与琐碎提示,而真正的性能瓶颈与安全隐患却被忽视。
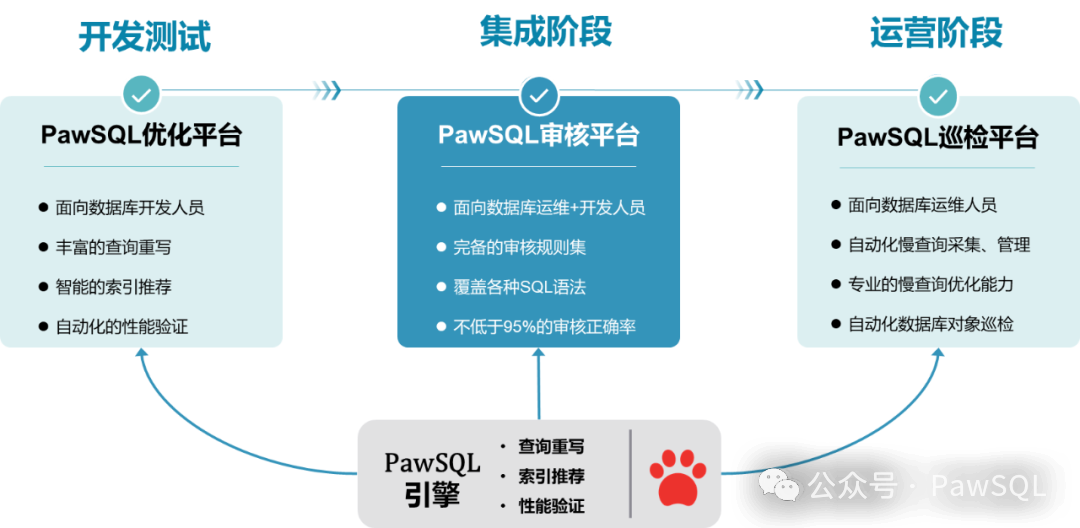
在上一篇文章中,我们介绍了PawSQL在SQL审核方面的六大核心能力。今天,我们将聚焦于PawSQL的审核规则体系,带大家深入了解它是如何帮助企业构建高效、可靠SQL审核流程的。
🧩完备均衡审核规则集
PawSQL在审核规则的全面性与对各类数据库支持的均衡性方面遥遥领先。其规则集全面覆盖SQL开发规范、安全性、可维护性与性能等维度,并在主流数据库上均保持约200条规则,确保无论您使用何种数据库,都能获得统一、专业的审核体验。
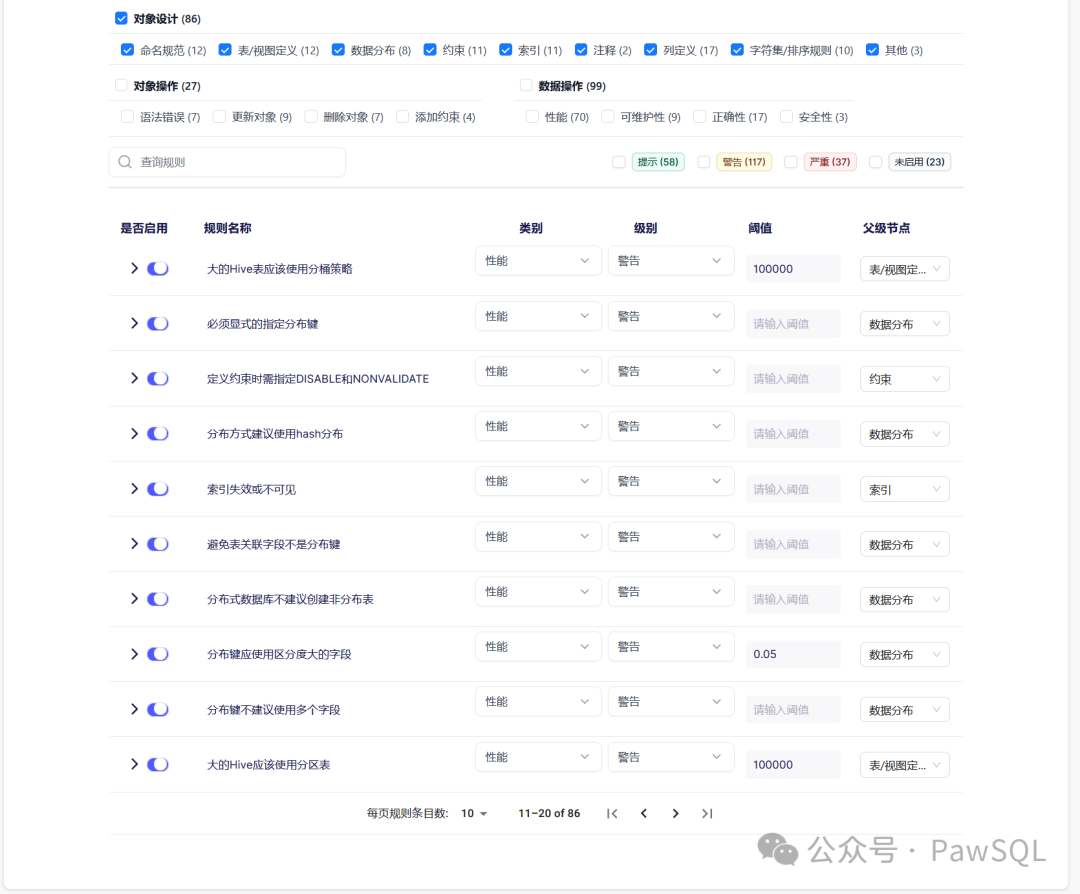
🗂️ 1. 对象设计审核
数据库对象设计是构建高效、安全、可靠数据库系统的关键环节,直接影响数据的完整性、一致性、可维护性与查询性能。
PawSQL的对象设计审核虽以SQL语句为输入,实则关注SQL操作的结果。例如规则“小数建议使用精确浮点数(如decimal/number)”,不仅检查CREATE TABLE语句,也会在ALTER TABLE ADD COLUMN或ALTER TABLE MODIFY COLUMN时生效,确保设计规范的全程贯彻。
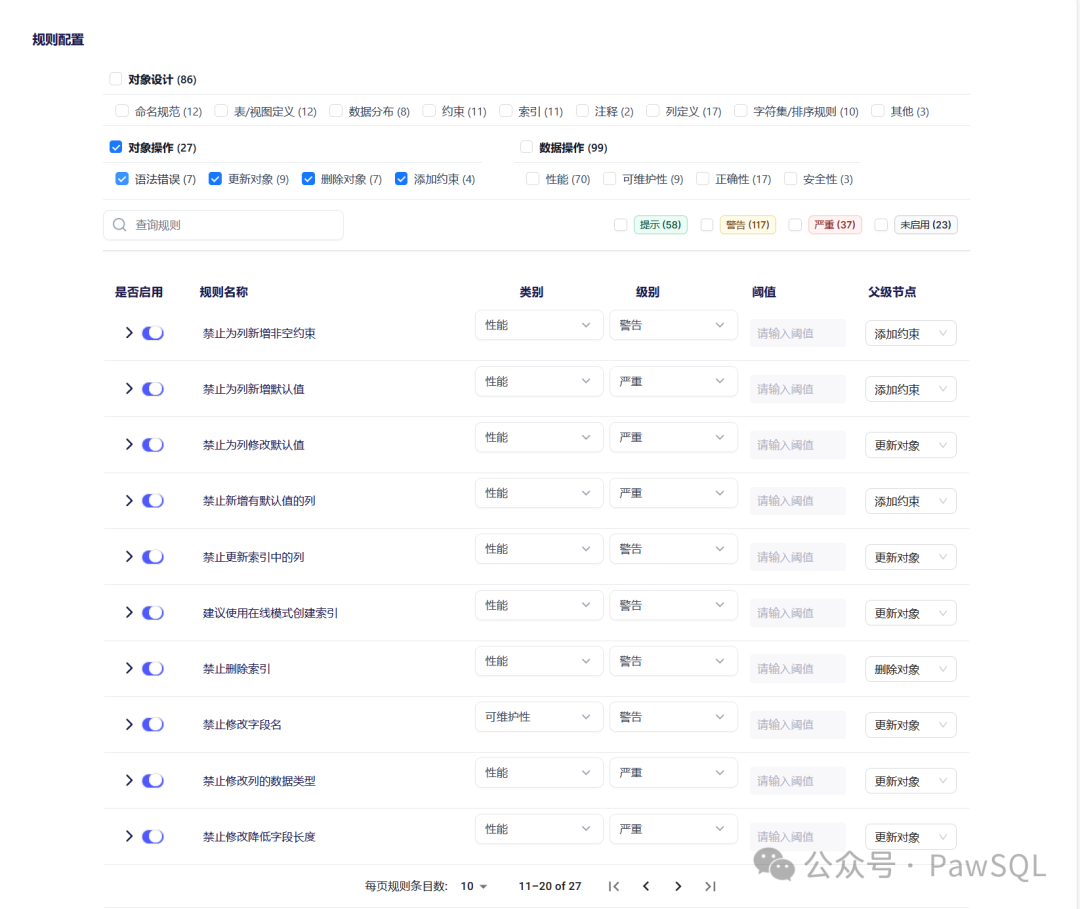
🔁 2. 对象操作审核
对表、视图、索引等数据库对象的增、删、改操作,若处理不当,可能引发应用程序兼容性问题,甚至影响高并发环境下的服务可用性。
PawSQL的对象操作审核规则,精准捕捉那些可能对数据库稳定性与性能产生负面影响的DDL操作,及时发出警示,防患于未然。
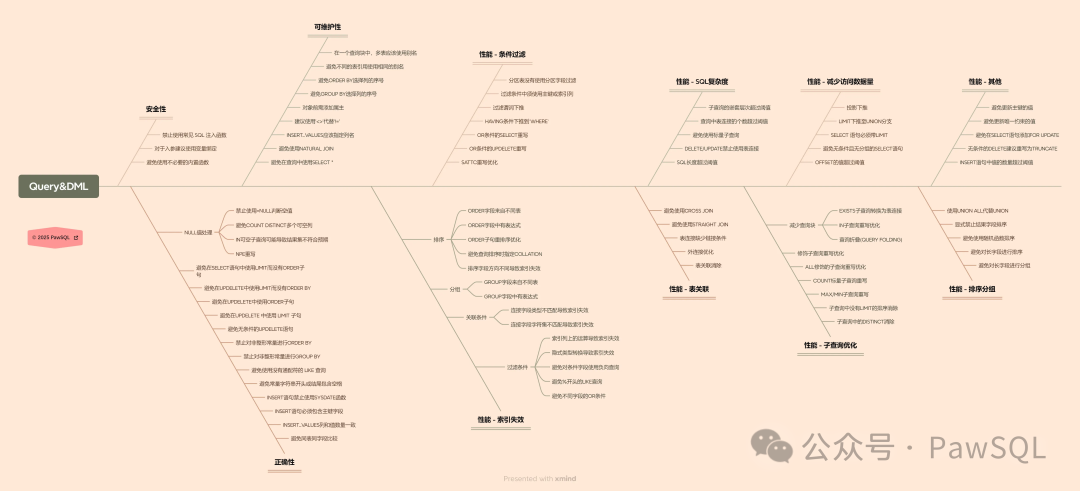
📊 3. 数据操作审核
数据操作语句(DML/DQL)的不当写法,往往是正确性、安全性与性能问题的根源。PawSQL从这四个关键角度出发,共设计了99条审核规则,系统覆盖INSERT、SELECT、UPDATE、DELETE等高频操作场景,帮助开发者从编码阶段规避常见陷阱。
🌐 4. 分布式数据库特有规则
相比传统单机数据库,分布式数据库引入了“数据分布”这一关键维度,对SQL开发与优化提出了更高要求。
PawSQL为分布式数据库定制了与数据分布相关的专项审核规则,助力开发者在分布式环境下实现更优的查询性能与扩展性。
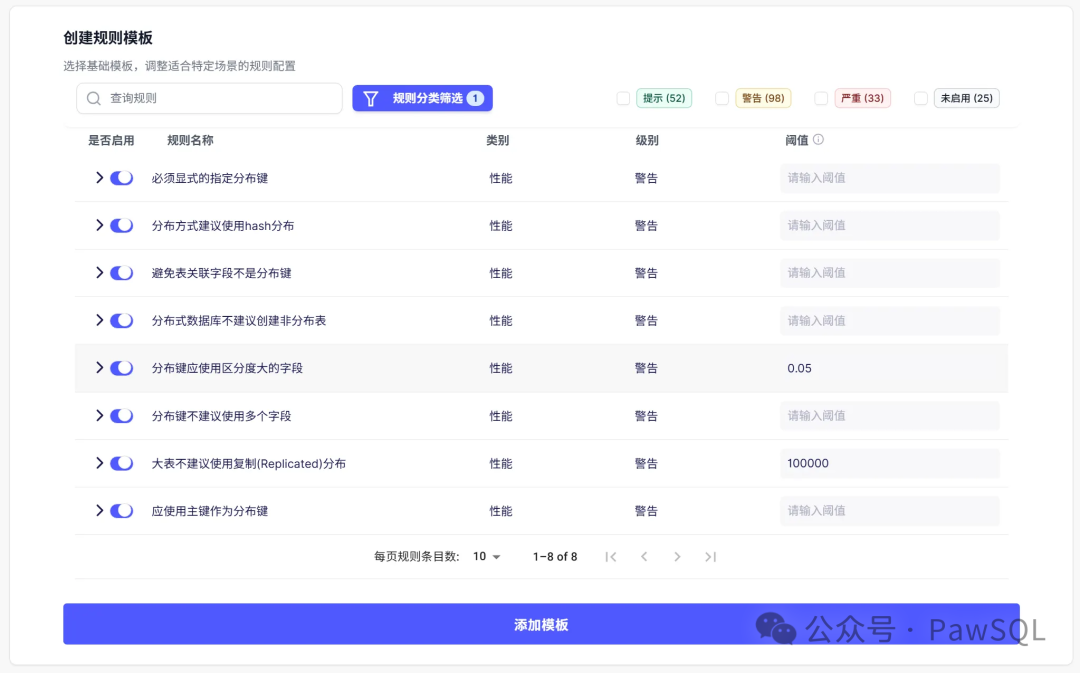
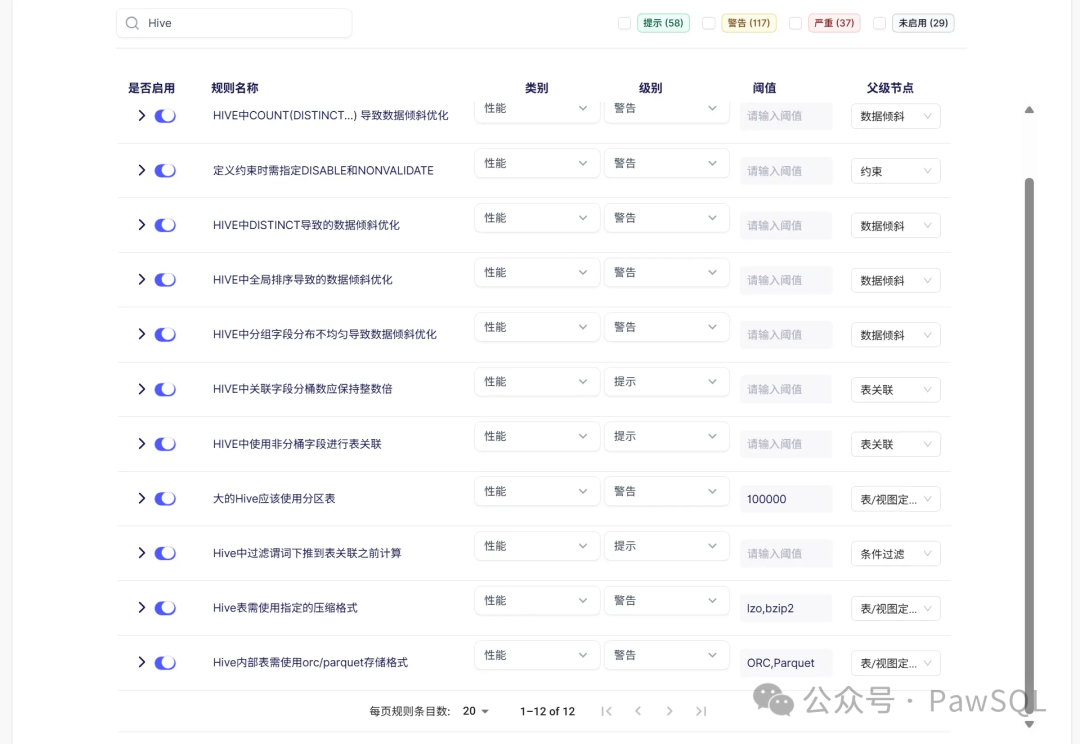
☁️ 5. 大数据平台特有规则(如Hive)
Hive SQL的审核直接关系大数据作业的查询性能、集群资源消耗与成本控制。PawSQL聚焦于分区与分桶策略优化、数据倾斜预防、执行计划调优等关键场景,确保任务高效运行,保障集群稳定、降低成本。
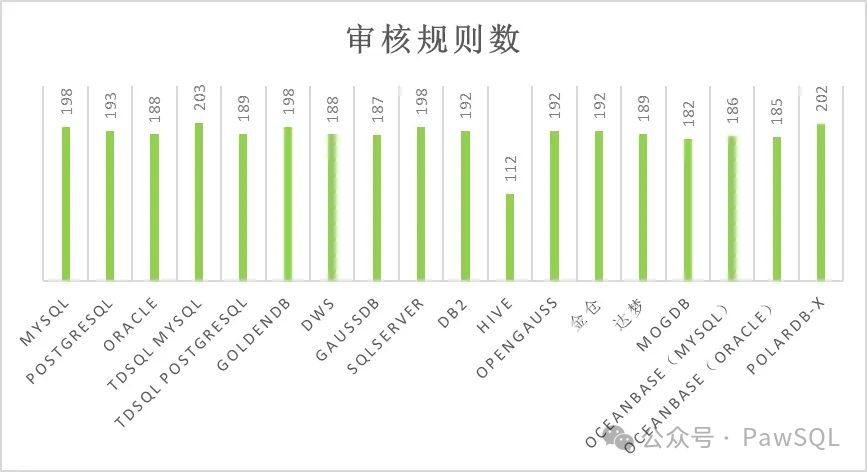
⚖️ 审核规则的均衡性
PawSQL既为大数据和分布式数据库提供专属的规则集,同时确保同类数据库在审核规则上的均衡性与一致性,确保不同数据库厂商的规则数量与质量保持均衡。譬如,对于传统关系型数据库,无论是MySQL、PostgreSQL、Oracle,还是openGauss,GoldenDB,都提供将近190左右的审核规则;而对于TDSQL-X,PolarDB-X等分布式数据库,提供的审核规则数在200个左右。
📐 审核模板管理:将经验沉淀为规范
审核模板是PawSQL中将最佳实践固化为自动化检查的核心机制。用户可根据不同数据库与业务场景,自定义规则集与阈值,从而统一团队SQL编写风格,主动预防性能瓶颈与安全风险,提升开发效率。
🛠️ 如何创建规则模板?
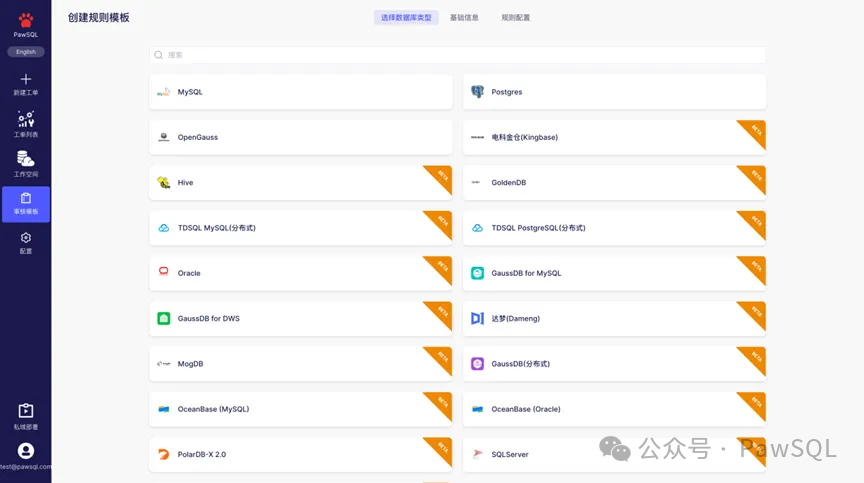
Step1. 选择数据库类型
部分规则仅适用于特定数据库(如数据分布规则仅用于分布式库),因此创建模板时需首先选定目标数据库类型。
-
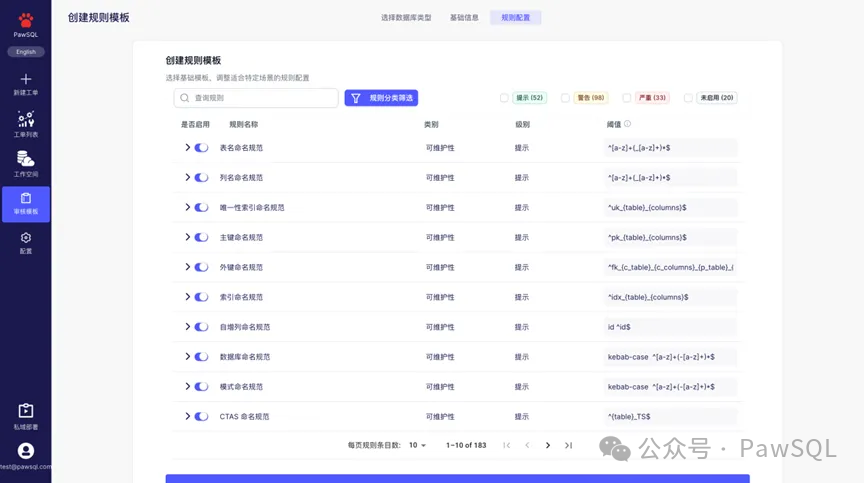
Step2. 启用规则与定制阈值
根据具体业务场景,灵活启用或禁用相关规则,并可对部分规则设置阈值(如索引数量、字段长度等),实现审核策略的精准适配。
🌐关于PawSQL
PawSQL专注于数据库性能优化自动化和智能化,提供的解决方案覆盖SQL开发、测试、运维的整个流程,广泛支持多种主流商用、国产和开源数据库,为开发者和企业提供一站式的创新SQL优化解决方案。