面向光学引导热红外无人机图像超分辨率的引导解耦网络
面向光学引导热红外无人机图像超分辨率的引导解耦网络
作者:Zhicheng Zhao a,b , Juanjuan Gu b,c, Chenglong Li 等
发表期刊:ISPRS Journal of Photogrammetry and Remote Sensing
论文地址:https://doi.org/10.48550/arXiv.2410.20466
Guidance disentanglement network for Optics-Guided thermal UAV image super-resolution
摘要 光学引导热红外无人机图像超分辨率(OTUAV-SR)由于其在安全检查、农业测量和目标检测方面的潜在应用而引起了广泛的研究兴趣。现有方法通常采用单一引导模型从光学图像中生成引导特征,以辅助热红外无人机图像超分辨率。然而,单一引导模型难以在无人机场景中的有利和不利条件下生成有效的引导特征,从而限制了OTUAV-SR的性能。为了解决这一问题,我们提出了一种新颖的引导解耦网络(GDNet),该网络根据典型的无人机场景属性对光学图像表示进行解耦,以形成有利和不利条件下的引导特征,从而实现鲁棒的OTUAV-SR。此外,我们设计了一个属性感知融合模块来组合所有基于属性的光学引导特征,这可以形成更具判别性的表示并适应属性无关的引导过程。为了促进复杂无人机场景中的OTUAV-SR研究,我们引入了VGTSR2.0,这是一个大规模基准数据集,包含在不同条件和场景下捕获的3,500对配准的光学-热红外图像对。在VGTSR2.0上的大量实验表明,GDNet相比最先进的方法显著提高了OTUAV-SR性能,特别是在无人机场景中常见的具有挑战性的弱光和雾天环境下。数据集和代码将在https://github.com/Jocelyney/GDNet公开发布。
2. 相关工作
在本节中,我们回顾与我们研究最相关的研究,包括单图像超分辨率方法和引导图像超分辨率方法。
2.1. 单图像超分辨率方法
单图像超分辨率(SISR)旨在将退化的低分辨率(LR)图像重建为相应的高分辨率(HR)图像,而无需额外的辅助模态。早期方法基于数学先验知识,如随机森林理论(Liu et al., 2017)、回归理论(He and Siu, 2011)和字典学习(Yang et al., 2012)。然而,这些传统的基于先验的方法在提取和学习特征的能力上存在局限性,导致在恢复不同场景中的复杂图像时缺乏鲁棒性和有效性。卷积神经网络(CNNs)的引入显著推进了SISR技术。SRCNN(Dong et al., 2015)首次将CNNs引入超分辨率重建领域,取得了比传统方法更好的结果。虽然早期基于CNN的方法(Haris et al., 2018; Zhang et al., 2018c; Dai et al., 2019; Lim et al., 2017; Zhang et al., 2018a; Niu et al., 2020)主要专注于光学图像超分辨率任务,但它们也具有用于热图像超分辨率的潜力。CNNs使用共享权重的卷积核来确保局部连接性和平移不变性,但它们受到卷积操作固有局部性的约束,限制了其捕获大尺度结构和建模长程依赖关系的能力。为了解决这一局限性,研究人员引入了Transformer(Vaswani et al., 2017),它使用自注意力机制来捕获图像内的全局依赖关系。这种更广阔的视角使得能够检测大尺度结构和复杂细节,有效克服了CNNs局部感受野的限制。具体而言,Liang et al.(2021)基于Swin Transformer(Liu et al., 2021)提出了SwinIR,在SISR任务中取得了进一步的改进。在此基础上,Chen et al.(2023)引入了混合注意力Transformer(HAT)模型,该模型集成了通道注意力和自注意力机制,以激活更广泛范围的输入像素,实现更有效的重建。在遥感图像超分辨率领域,Lei et al.(2021)提出了TransENet,这是一种基于Transformer的多阶段增强结构,旨在融合多尺度特征以增强图像分辨率。Xiao et al.(2024b)提出了TTST,一种旨在提高效率的选择性Transformer,而Hao et al.(2024)提出了尺度感知反向投影Transformer(SPT),它结合了反馈机制以更好地处理遥感图像中的尺度变化。这些进展突显了基于Transformer的模型在增强图像分辨率和跨各种应用的重建方面日益增长的潜力。随着GAN(Goodfellow et al., 2020)的引入,研究人员发现GAN在生成任务中表现优异。随后,基于GAN的方法逐渐被应用于图像超分辨率任务。例如,Ledig et al.(2017)引入了SRGAN,这是一种开创性的基于GAN的单图像超分辨率方法。EEGAN(Jiang et al., 2019)通过引入边缘增强子网络增强了基于GAN的超分辨率,实现了更清晰、更鲁棒的卫星图像重建。Kong et al.(2023)开发了一种双GAN方法来提升历史Landsat图像的分辨率,以改进植被监测的空间分辨率。最近,Mamba(Guo et al., 2024)和扩散模型(Rombach et al., 2022)获得了广泛关注,并在遥感中得到广泛应用。EDiffSR(Xiao et al., 2023)采用扩散概率模型进行高效准确的遥感图像超分辨率,在视觉质量和计算效率方面都优于其他模型。FMSR(Xiao et al., 2024a)引入了一种为大规模遥感图像超分辨率量身定制的状态空间模型,整合了频率和空间线索以增强重建质量。尽管取得了这些进展,从低分辨率图像中重建高频细节仍然具有挑战性。这一挑战在无人机图像中尤为突出,复杂的操作场景进一步揭示了现有SISR方法的局限性。开发能够可靠地恢复精细细节并在各种条件下保持鲁棒性能的算法仍然是当务之急。
1. 引言
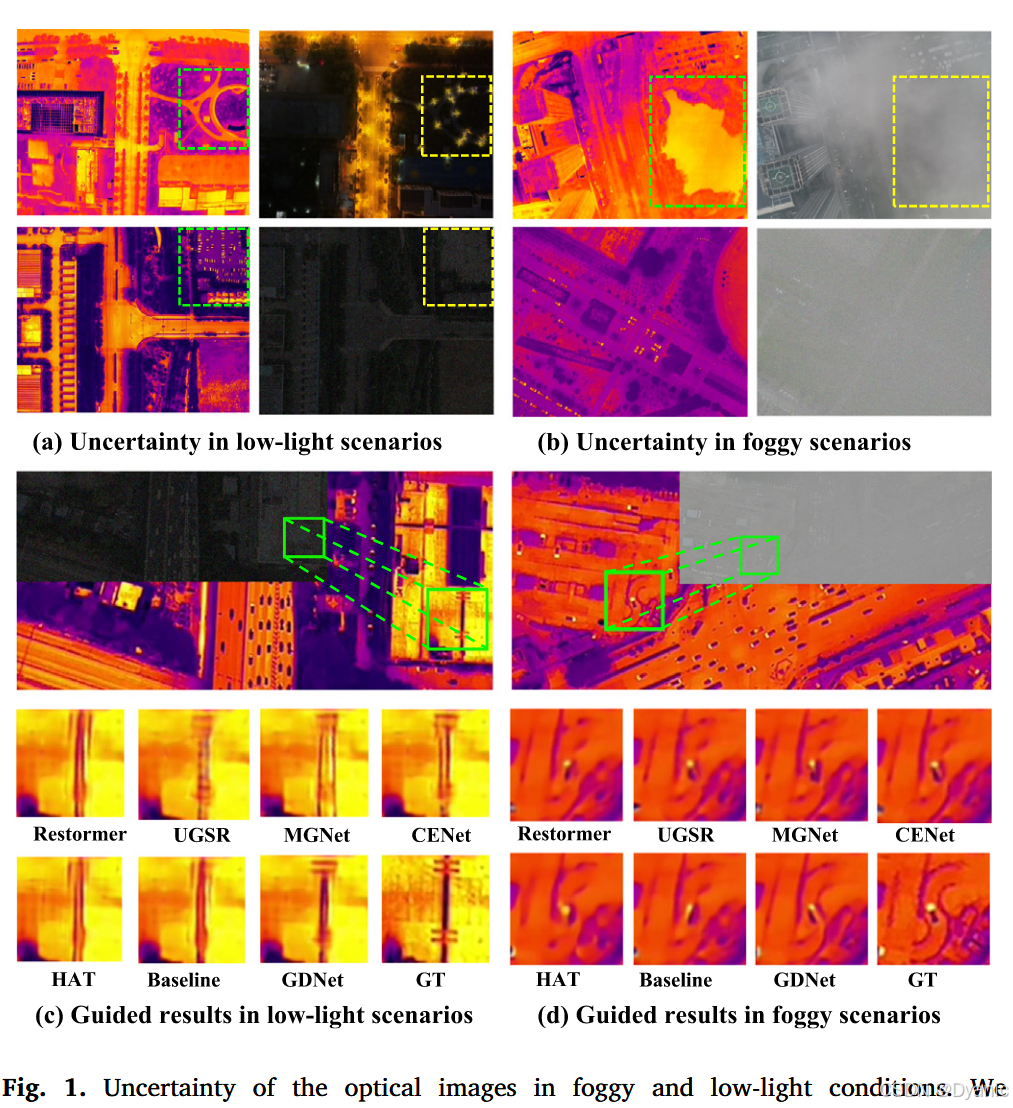
无人机(UAV)热成像技术能够捕获物体发射的红外辐射,由于其在安全检查(Zhou et al., 2022)、农业测量(Peng et al., 2023)和目标检测(Zhou et al., 2024)等各种应用中的独特优势,已成为遥感领域的研究热点。热成像的全天候、全天时作业能力使无人机能够在具有挑战性的环境中捕获关键信息。然而,受机载热成像设备的物理成像机制和技术限制的约束,无人机获取的原始热图像通常分辨率较低。因此,这些热图像缺乏光学图像中存在的丰富纹理细节和精细结构,阻碍了它们满足后续高级语义理解任务的质量要求。这一局限性凸显了对有效的热成像无人机图像超分辨率技术的需求,以弥合原始低分辨率热图像与具有增强纹理细节的期望高分辨率图像之间的差距。为了提高热图像的分辨率和质量,研究人员开发了各种单图像超分辨率(SISR)算法(Zhang et al., 2018b; Liang et al., 2021; Zamir et al., 2022; Qiu et al., 2023)。然而,现有的SISR方法往往难以准确重建热图像中的精细细节和纹理。这种困难源于热图像的固有特性,即缺乏明显的边缘信息和丰富的纹理。热图像平滑且对比度低,导致高频信息有限。因此,当前的SISR方法在恢复复杂细节和产生高保真重建方面面临重大挑战,特别是在复杂的无人机环境中,图像质量会因大气干扰和传感器限制等因素而进一步恶化。and Debeir, 2018; Gupta and Mitra, 2020, 2021; Zhao et al., 2023, 2024)利用高分辨率光学图像来引导热图像超分辨率过程。这种光学引导的热成像无人机图像超分辨率(OTUAV-SR)方法利用光学图像中固有的优越纹理和边缘信息,在重建精细细节和增强图像质量方面表现出显著改进。然而,尽管这些OTUAV-SR方法可以产生出色的超分辨率结果,但仍存在不足。一个值得注意的问题是,这些方法严重依赖理想的高质量光学图像输入,而这在实践中并不总是可用的。在具有挑战性的无人机场景中,例如雾天或低光照条件下,现有OTUAV-SR方法的性能会显著下降。如图1(a)和(b)所示,无人机在夜间和雾天条件下捕获的光学图像表现出显著的不确定性,使得难以在低光照和路灯干扰下辨别道路和车辆群(图1(a)),以及被浓雾遮蔽的湖泊(图1(b))。利用这些退化的光学数据可能导致重建热图像中出现不准确的纹理信息和伪影。在某些情况下,这些结果甚至不如SISR方法产生的结果。如图1(c)所示,光学引导的热超分辨率方法在低光照条件下无法准确恢复纹理信息。在浓雾场景中,如图1(d)所示,SISR和引导超分辨率方法都无法重建弯曲道路的热图像。此外,许多OTUAV-SR方法在所有场景中采用统一框架,导致模型无法有效应对不同的环境挑战。在具有挑战性的条件下,现有方法不仅无法有效利用光学引导信息,而且容易引入错误和伪影。这些发现突出表明,当前方法缺乏必要的场景自适应能力,在复杂的无人机环境中不够鲁棒。因此,在具有挑战性的无人机场景中开发针对特定场景的增强技术成为研究的优先事项。
在本文中,我们提出了一种新颖的引导解耦网络(GDNet)用于鲁棒的OTUAV-SR。GDNet根据典型的无人机场景属性解耦光学图像表示,然后在有利和不利条件下生成有效的引导特征。无人机捕获的光学图像经常遇到低照度和雾气遮挡等问题。为了解决这些问题,我们提出了属性特定引导模块(AGM),包含三个不同的引导分支。具体而言,我们采用Retinex分解网络(Cai et al., 2023)来增强低光照光学图像,并设计了一个用于去噪的注意力块。此外,我们引入了一个门控注意力模块来引导网络关注与大气雾霾相关的特征。这些模块利用transformer架构的先进建模能力,使网络能够适应不同的光照和可见度条件。为了自适应地聚合来自多个引导分支的特征,我们引入了属性感知融合模块(AFM)。该模块使网络能够基于学习到的表示选择性地激活和利用最相关的特征分支,确保在不同场景中的鲁棒性。受近期基于窗口的自注意力方法研究(Huang et al., 2021; Patel et al., 2022; Chen et al., 2023)的启发,我们设计了重叠多头交叉注意力层(OMCL)来增强跨窗口热信息连接并扩展光学信息的感受野,促进多模态信息的更有效整合。为了支持复杂无人机场景下OTUAV-SR的研究,我们引入了VGTSR2.0,这是一个大规模、精确对齐的多模态无人机数据集,包含3500对在不同场景、高度、光照条件和雾气水平下捕获的精确对齐的光学和热图像。在VGTSR2.0上的大量实验证明了我们提出方法的优越性。总之,本文的主要贡献如下:
• 我们提出了引导解耦网络(GDNet),这是一个新颖的框架,根据各种挑战的特征分解光学特征。这种方法在多个具有挑战性的场景中实现了鲁棒的光学表示,有效克服了现有单一引导模型在不同无人机环境中表现不佳的局限性。
• 我们提出了属性特定引导模块(AGM),它由三个不同的结构组成,用于对各种场景中的光学表示进行建模。此外,我们引入了属性感知融合模块(AFM)和一种训练策略,旨在自适应地聚合来自多个引导分支的特征。
• 为了促进复杂无人机场景下OTUAV-SR的研究,我们引入了VGTSR2.0。据我们所知,VGTSR2.0是专门为OTUAV-SR任务设计的最大的精确对齐多模态无人机数据集。与VGTSR1.0相比,VGTSR2.0显著扩展了数据集的规模和多样性,以更好地代表真实世界的无人机环境。
• 在VGTSR2.0上进行的大量定量和定性实验表明,我们的GDNet显著优于现有的最先进的SISR和OTUAV-SR方法。
2. 相关工作
在本节中,我们回顾与我们的研究最相关的研究,包括单图像超分辨率方法和引导图像超分辨率方法。
2.1. 单图像超分辨率方法
单图像超分辨率(SISR)旨在将退化的低分辨率(LR)图像重建为相应的高分辨率(HR)图像,而无需额外的辅助模态。早期方法基于数学的先验知识,如随机森林理论(Liu et al., 2017)、回归理论(He and Siu, 2011)和字典学习(Yang et al., 2012)。然而,这些传统的基于先验的方法在提取和学习特征的能力上存在局限性,导致在恢复不同场景中的复杂图像时缺乏鲁棒性和有效性。卷积神经网络(CNNs)的引入显著推进了SISR技术。SRCNN(Dong et al., 2015)首次将CNNs引入超分辨率重建领域,取得了比传统方法更好的结果。虽然早期基于CNN的方法(Haris et al., 2018; Zhang et al., 2018c; Dai et al., 2019; Lim et al., 2017; Zhang et al., 2018a; Niu et al., 2020)主要专注于光学图像超分辨率任务,但它们也具有热图像超分辨率的潜力。CNNs使用共享权重的卷积核来确保局部连接性和平移不变性,但它们受到卷积操作固有局部性的限制,限制了其捕获大尺度结构和建模长程依赖关系的能力。为了解决这一局限性,研究人员引入了Transformer(Vaswani et al., 2017),它使用自注意力机制来捕获图像内的全局依赖关系。这种更广阔的视角使得能够检测大尺度结构和复杂细节,有效克服了CNNs局部感受野的局限性。具体而言,Liang et al. (2021)基于Swin Transformer(Liu et al., 2021)提出了SwinIR,在SISR任务中取得了进一步的改进。在此基础上,Chen et al. (2023)引入了混合注意力Transformer(HAT)模型,该模型整合了通道注意力和自注意力机制,以激活更广泛范围的输入像素,实现更有效的重建。在遥感图像超分辨率领域,Lei et al. (2021)提出了TransENet,这是一个基于Transformer的多阶段增强结构,旨在融合多尺度特征以增强图像分辨率。Xiao et al. (2024b)提出了TTST,一种旨在提高效率的选择性Transformer,而Hao et al. (2024)提出了尺度感知反向投影Transformer(SPT),它结合了反馈机制以更好地处理遥感图像中的尺度变化。这些进展突显了基于Transformer的模型在各种应用中增强图像分辨率和重建方面日益增长的潜力。随着GAN(Goodfellow et al., 2020)的引入,研究人员发现GAN在生成任务中表现优异。随后,基于GAN的方法逐渐被应用于图像超分辨率任务。例如,Ledig et al. (2017)引入了SRGAN,一种开创性的基于GAN的单图像超分辨率方法。EEGAN(Jiang et al., 2019)通过引入边缘增强子网络增强了基于GAN的超分辨率,使卫星图像重建更加清晰和鲁棒。Kong et al. (2023)开发了一种双GAN方法来升级历史Landsat图像,以提高空间分辨率并增强植被监测。最近,Mamba(Guo et al., 2024)和扩散模型(Rombach et al., 2022)获得了显著关注,并在遥感领域得到了广泛应用。EDiffSR(Xiao et al., 2023)采用扩散概率模型实现高效准确的遥感图像超分辨率,在视觉质量和计算效率方面均优于其他模型。FMSR(Xiao et al., 2024a)引入了一种为大规模遥感图像超分辨率量身定制的状态空间模型,整合频率和空间线索以增强重建质量。尽管取得了这些进展,从低分辨率图像重建高频细节仍然具有挑战性。这一挑战在无人机图像中尤为突出,复杂的操作场景进一步揭示了现有SISR方法的局限性。开发能够可靠恢复精细细节并在各种条件下保持鲁棒性能的算法仍然是必要的。
2.2. 引导图像超分辨率方法
为了解决单图像超分辨率的固有局限性,引导超分辨率方法被提出作为一种解决方案,通过利用额外的信息或先验知识有效提高图像分辨率和视觉质量。作为首个提出引导超分辨率的工作,Lutio et al. (2019)将其概念化为像素到像素的映射任务。在后续发展中,超分辨率技术主要依赖于CNN架构。Han et al. (2017)提出了一种基于CNN的算法,使用光学图像对低光环境中的近红外图像进行超分辨率处理。Fu et al. (2019)提出了一种不需要预训练或监督的引导超分辨率方法。Chen et al. (2016)使用了颜色引导的热图像超分辨率算法。此外,其他研究(Guo et al., 2018; Wen et al., 2018; Song et al., 2020)在配对的高分辨率RGB图像的辅助下,从低分辨率结果重建高分辨率深度图。然而,这些基于CNN的方法主要对不同模态特征进行简单融合,限制了网络恢复图像细节和结构的能力。为了增强模型的性能,一些研究探索了更有效整合引导信息的新颖架构。Zhong et al. (2023)提出了一个注意力核学习模块,将结构信息从引导图像转移到目标图像。Yanshan et al. (2022)提出了一种基于U-Net架构的光学引导SAR图像超分辨率网络,产生的结果与真实的高分辨率SAR图像非常相似。在引导信息的选择上,由于丰富的纹理和结构信息,光学图像受到许多研究人员的青睐。Almasri and Debeir (2018)使用基于GAN的模型在RGB图像引导下增强热图像分辨率。Gupta and Mitra (2021)设计了两个模型来解决可见光图像对齐以引导热图像的问题。Zhao et al. (2023)采用可见光图像中的外观、边缘和语义线索来引导无人机热图像。此外,Zhao et al. (2024)提出了共同学习超分辨率和模态转换任务,进一步增强了生成的高分辨率热图像的质量。虽然当前方法已经展示了利用额外信息增强图像重建的潜力,但通过OTUAV-SR方法追求卓越图像引导仍然受到现实场景中遇到的复杂多变条件的阻碍。光照的快速变化、遮挡以及航空图像的动态性质需要能够在各种条件下提供一致引导的自适应和鲁棒超分辨率技术。
3. 方法论
在本节中,我们首先在3.1节介绍引导解耦超分辨率框架。随后,3.2节和3.3节分别描述数据退化和GDNet模型架构,包括其关键内部模块的设计和实现细节。最后,3.4节和3.5节讨论GDNet的训练算法和损失函数。
3.1. 整体框架
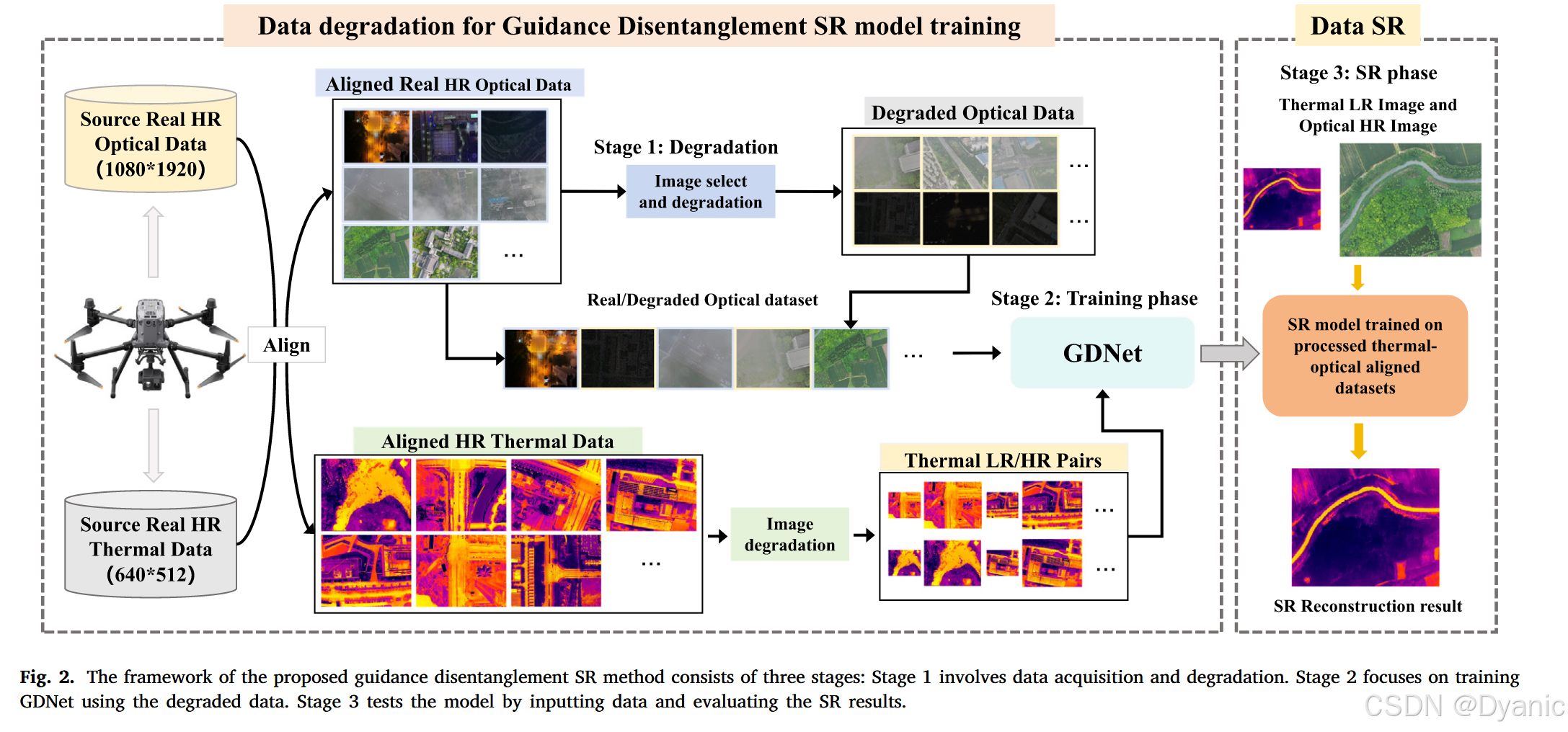
高质量数据是训练有效模型的先决条件。然而,根据我们的调查,目前还没有专门针对复杂场景的无人机热图像超分辨率数据集。因此,在这项工作中,我们首先创建了一个满足以下要求的新数据集:(1)位置一致性。在无人机场景中,由于相机之间的视差,获取的多模态数据存在空间位置差异。为了解决这个问题,我们首先通过手动配准消除这些位置差异;(2)数据平衡。在我们的数据集中,我们控制真实场景数据与合成数据的比例为2:1,所有数据中正常光照、暗光和雾天数据的比例为1:1:1;(3)数据多样性。为了提高训练模型的鲁棒性和泛化能力,具有不同退化程度的多样化数据集至关重要。然而,获取和对齐具有严重退化的数据构成了重大挑战。为了克服这一问题,我们选择一部分对齐良好的数据,并应用合成退化算法来获得严重退化且对齐的数据。整体框架如图2所示,包括三个主要阶段。在获得无人机捕获的原始高分辨率多模态数据后,我们手动对齐不同模态数据的空间位置。首先,我们对部分光学图像数据进行退化操作,并将其与真实数据合并,以生成具有多个退化级别的光学引导数据,我们将其用作训练数据。同时,我们对高分辨率热图像进行下采样操作以生成训练数据。随后,我们利用构建的数据集来训练GDNet。最后,将LR热图像和HR光学图像输入到训练好的超分辨率模型中,以生成高分辨率热图像。
3.2. 数据退化
我们通过使用双三次插值(BI)和模糊下采样(BD)退化模型生成LR-HR热图像对。用户可以使用这些模型进一步退化高分辨率热图像,以生成满足特定要求的低分辨率图像。对于光学图像退化,低光图像与正常光照图像显示出两个主要差异:照明和噪声。为了模拟低光图像,我们应用线性和伽马变换的组合,可以表示如下:
ILL,i=ηi×(ζi×Iin,i)θi,i∈{R,G,B},(1)I_{LL,i} = \eta_i \times (\zeta_i \times I_{in,i})^{\theta_i}, \quad i \in \{R, G, B\},\tag{1}ILL,i=ηi×(ζi×Iin,i)θi,i∈{R,G,B},(1)
其中ζi\zeta_iζi、ηi\eta_iηi和θi\theta_iθi是从均匀分布中采样的参数:ζi∼U(0.6,0.9)\zeta_i \sim U(0.6, 0.9)ζi∼U(0.6,0.9),ηi∼U(0.3,0.5)\eta_i \sim U(0.3, 0.5)ηi∼U(0.3,0.5),以及θi∼U(3,5)\theta_i \sim U(3, 5)θi∼U(3,5)。
此外,暗光场景通常涉及噪声,这是复杂且信号相关的。真实噪声分布与高斯分布有显著差异。因此,我们采用高斯-泊松噪声模型(Guo et al., 2019)来模拟原始数据噪声和光子传感器产生的噪声。这可以计算为:
Iout=R(B−1(Pσp2(B(R−1(ILL))+Nσg2))),(2)I_{out} = \mathcal{R}\left(\mathcal{B}^{-1}\left(\mathcal{P}_{\sigma_p^2}\left(\mathcal{B}\left(\mathcal{R}^{-1}(I_{LL})\right) + \mathcal{N}_{\sigma_g^2}\right)\right)\right),\tag{2}Iout=R(B−1(Pσp2(B(R−1(ILL))+Nσg2))),(2)
其中Pσp2(⋅)\mathcal{P}_{\sigma_p^2(\cdot)}Pσp2(⋅)表示添加方差为σp2\sigma_p^2σp2的泊松噪声,Nσg2\mathcal{N}_{\sigma_g^2}Nσg2表示方差为σg2\sigma_g^2σg2的加性高斯白噪声,B(⋅)\mathcal{B}(\cdot)B(⋅)是将RGB图像转换为Bayer模式图像的函数,R(⋅)\mathcal{R}(\cdot)R(⋅)是逆相机响应函数。对于雾霾模拟,我们随机将基于大气散射模型和掩码的算法应用于每个图像,以减轻神经网络的过拟合。使用大气散射原理模拟的雾霾图像可以表示为:
Ihazy=Iimg⋅e−β⋅d+A⋅(1−e−β⋅d),(3)I_{hazy} = I_{img} \cdot e^{-\beta \cdot d} + A \cdot (1 - e^{-\beta \cdot d}),\tag{3}Ihazy=Iimg⋅e−β⋅d+A⋅(1−e−β⋅d),(3)
其中β\betaβ是表示大气介质散射系数的正参数,ddd表示图像中每个像素到雾霾中心的距离,AAA表示大气照明的强度。e−β⋅de^{-\beta \cdot d}e−β⋅d描述了关于距离的指数衰减。
3.3. GDNet架构
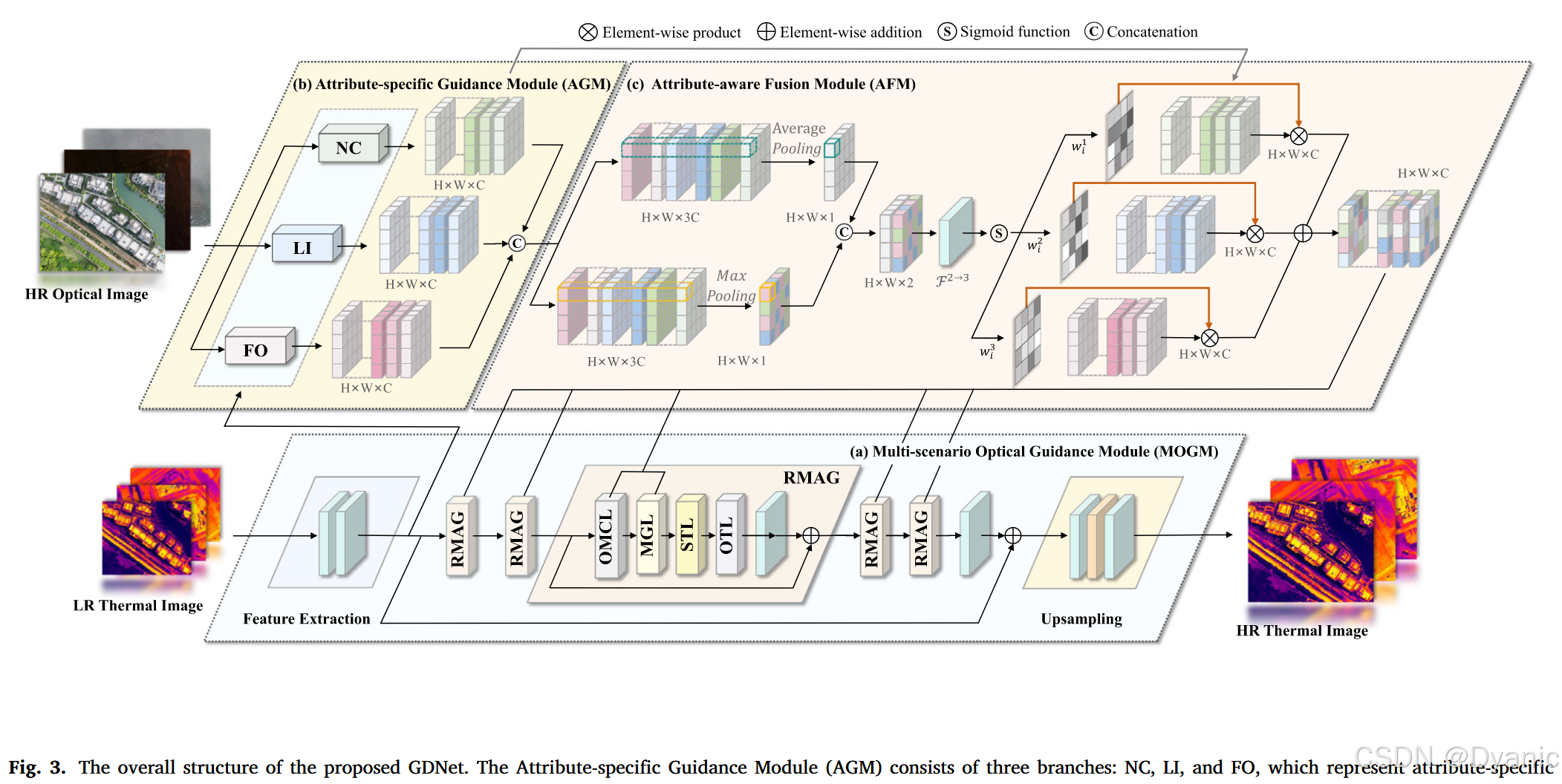
提出的GDNet架构如图3所示。从源传感器图像模拟的退化LR-HR热图像对和对齐良好的真实-人工光学图像被输入到GDNet进行训练。对于热图像,初始浅层特征图通过由单个3×33 \times 33×3卷积层组成的特征提取器获得,这也增加了通道数:
Finitial=Conv(XLR)∈RH×W×C,(4)F_{initial} = \text{Conv}(X_{LR}) \in \mathbb{R}^{H \times W \times C},\tag{4}Finitial=Conv(XLR)∈RH×W×C,(4)
其中Conv(⋅)\text{Conv}(\cdot)Conv(⋅)表示3×33 \times 33×3卷积操作,Finitial∈RH×W×CF_{initial} \in \mathbb{R}^{H \times W \times C}Finitial∈RH×W×C表示提取的特征图。光学图像同时被送入预训练的属性特定引导模块(AGM)以获得三个属性特定且解耦的表示:
Fn=fNC(Y)∈RH×W×C,(5)F_n = f_{NC}(Y) \in \mathbb{R}^{H \times W \times C},\tag{5}Fn=fNC(Y)∈RH×W×C,(5)
Fl=fLI(Y)∈RH×W×C,(6)F_l = f_{LI}(Y) \in \mathbb{R}^{H \times W \times C},\tag{6}Fl=fLI(Y)∈RH×W×C,(6)
Ff=fFO(Y)∈RH×W×C,(7)F_f = f_{FO}(Y) \in \mathbb{R}^{H \times W \times C},\tag{7}Ff=fFO(Y)∈RH×W×C,(7)
其中fNC(⋅)f_{NC}(\cdot)fNC(⋅)、fLI(⋅)f_{LI}(\cdot)fLI(⋅)和fFO(⋅)f_{FO}(\cdot)fFO(⋅)分别表示图3(b)中的正常条件(NC)、低照明(LI)和雾遮挡(FO)操作。Fn,l,f∈RH×W×CF_{n,l,f} \in \mathbb{R}^{H \times W \times C}Fn,l,f∈RH×W×C表示增强的光学特征图,这些特征图擅长处理特定属性。然而,属性标注在训练期间可用但在测试期间缺失,这在OTUAV-SR中产生了关于激活哪个融合分支的不确定性。为了应对这一挑战,我们引入了属性感知融合模块(AFM)来有效聚合属性特定特征,如图3(c)所示。为了有效建立长程依赖关系并充分利用来自热图像的浅层信息和增强的光学引导信息,残差多重注意力组(RMAG)被纳入GDNet。AFM后的初始热特征和聚合光学特征被送入每个RMAG,其中第iii个RMAG的特征图描述为:
Fi=fRMAGi(Fi−1,fAFM(Foptic))+WiFinitial,(8)F_i = f_{RMAG_i}(F_{i-1}, f_{AFM}(F_{optic})) + W_i F_{initial},\tag{8}Fi=fRMAGi(Fi−1,fAFM(Foptic))+WiFinitial,(8)
其中FopticF_{optic}Foptic表示光学特征图,通过连接FnF_nFn、FlF_lFl和FfF_fFf获得。fAFM(⋅)f_{AFM}(\cdot)fAFM(⋅)表示AFM,如图3(c)所示,Fi−1F_{i-1}Fi−1和FiF_iFi分别表示第iii个RMAG的输入和输出特征,fRMAGi(⋅)f_{RMAG_i}(\cdot)fRMAGi(⋅)表示第iii个RMAG,WiW_iWi是可学习参数。最后,输出被上采样以生成最终的超分辨率结果,如下所示:
XSR=Conv(fpixel−shuffle(Conv(FI))),(9)X_{SR} = \text{Conv}(f_{pixel-shuffle}(\text{Conv}(F_I))),\tag{9}XSR=Conv(fpixel−shuffle(Conv(FI))),(9)
其中FIF_IFI是最后一个RMAG的输出特征,Conv(⋅)\text{Conv}(\cdot)Conv(⋅)表示3×33 \times 33×3卷积操作,fpixel−shuffle(⋅)f_{pixel-shuffle}(\cdot)fpixel−shuffle(⋅)表示PixelShuffle上采样方法。
3.3.1. 属性特定引导模块
为了增强在不同天气条件下光学特征的提取,我们提出了一个属性特定引导模块(AGM),包括三个具有不同架构的分支,每个分支都旨在应对特定挑战。NC分支促进光学和热特征之间的交互,能够提取更有价值的信息。LI分支旨在基于具有Transformer架构的Retinex理论提高低光条件下暗区的可见性。FO分支选择性地保留雾天图像中的详细信息,有助于恢复雾霾遮挡图像的清晰度和细节。
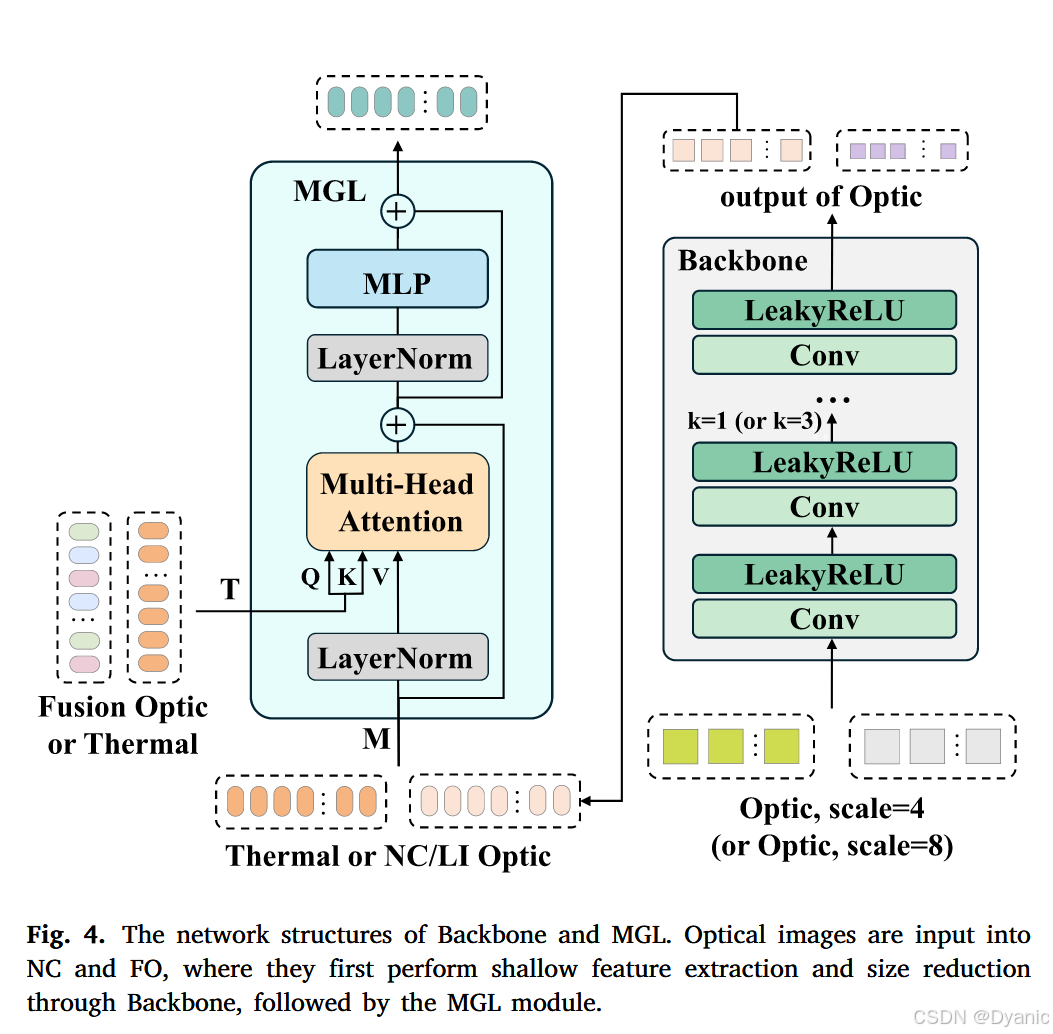
正常条件分支。 在正常光照条件下无人机捕获的热图像和光学图像中的噪声随着高度增加而增加。为了缓解这个问题,我们采用整合热特征的交叉注意力机制。该机制促进光学和热特征之间的全面交互,从而减少光学图像中的大气噪声。NC分支由一个基本的CNN骨干网络和两个多模态引导层(MGL)组成,这些层结合了交叉注意力和移位窗口机制来增强引导信息。光学图像最初由由多个3×33 \times 33×3卷积层组成的基本骨干网络处理,然后是LeakyReLU激活函数。随后,输出特征通过采用滑动窗口机制的多头交叉注意力(MCA)层,如图4所示。在MCA中,这些操作计算如下:
Q=YWQ,K=YWK,V=XWV,(10)Q = YW^Q, \quad K = YW^K, \quad V = XW^V,\tag{10}Q=YWQ,K=YWK,V=XWV,(10)
其中WQW^QWQ、WKW^KWK和WVW^VWV是在不同窗口间共享的可学习投影矩阵,XXX表示光学特征,YYY表示热特征。注意力矩阵从局部窗口内的自注意力或交叉注意力机制计算如下:
Attention(Q,K,V)=softmax(QKT/dk+B)V,(11)\text{Attention}(Q, K, V) = \text{softmax}(QK^T/\sqrt{d_k} + B)V,\tag{11}Attention(Q,K,V)=softmax(QKT/dk+B)V,(11)
其中BBB是可学习的相对位置编码矩阵,dkd_kdk是查询KKK的维度。Attention(⋅)\text{Attention}(\cdot)Attention(⋅)表示交叉注意力操作。在MCA中,QQQ和KKK来自热特征,而VVV来自光学特征。MGL的完整流程如下:
M=(LeakyReLU(Conv(M)))×k,M = (\text{LeakyReLU}(\text{Conv}(M)))_{\times k},M=(LeakyReLU(Conv(M)))×k,
Ml′=MCA(LN(Ml,T))+Ml,M'_l = \text{MCA}(\text{LN}(M_l, T)) + M_l,Ml′=MCA(LN(Ml,T))+Ml,
Ml+1=MLP(LN(Ml′))+Ml′+Ml,(12)M_{l+1} = \text{MLP}(\text{LN}(M'_l)) + M'_l + M_l,\tag{12}Ml+1=MLP(LN(Ml′))+Ml′+Ml,(12)
其中kkk表示Conv+LeakyReLU操作的数量,MLP和LN分别指多层感知器和层归一化,TTT表示热特征。MlM_lMl和Ml+1M_{l+1}Ml+1分别表示层lll的MCA和MLP的输入和输出特征。
低照明分支。 我们的LI分支由三个组件组成:预训练的Retinex分解网络、基本CNN骨干网络和六个MGL,而不是使用简单的特征提取器。Retinex分解网络是一个灵活的网络,可以基于任何图像分解模型(Cai et al., 2023; Fan et al., 2023; Yi et al., 2023)。我们可以使用配对输入从头开始训练分解网络,或者简单地加载公开可用的预训练权重。在通过直接加载RetinexNet的公开可用预训练权重构建Retinex分解网络后,我们观察到结果在合成数据上表现良好,但在真实数据上表现不佳。为了更好地模拟无人机在低光条件下的视觉场景,我们基于RetinexFormer(Cai et al., 2023)从头开始训练分解网络,该网络通过Transformer结构对反射率和照明图中的噪声进行建模,提供了更鲁棒的特征表示。具体来说,我们仔细选择了VGTSR2.0训练集中三分之一的光学图像和DroneVehicle(Sun et al., 2022)数据集中的1000张图像。然后,使用非深度Dark ISP方法将这些图像合成为低光和正常光照条件下的图像对。此外,为了更好地接近现实场景中遇到的低光环境,我们引入了LOLv2(Yang et al., 2021)数据集来增强分解模型的泛化性和鲁棒性。
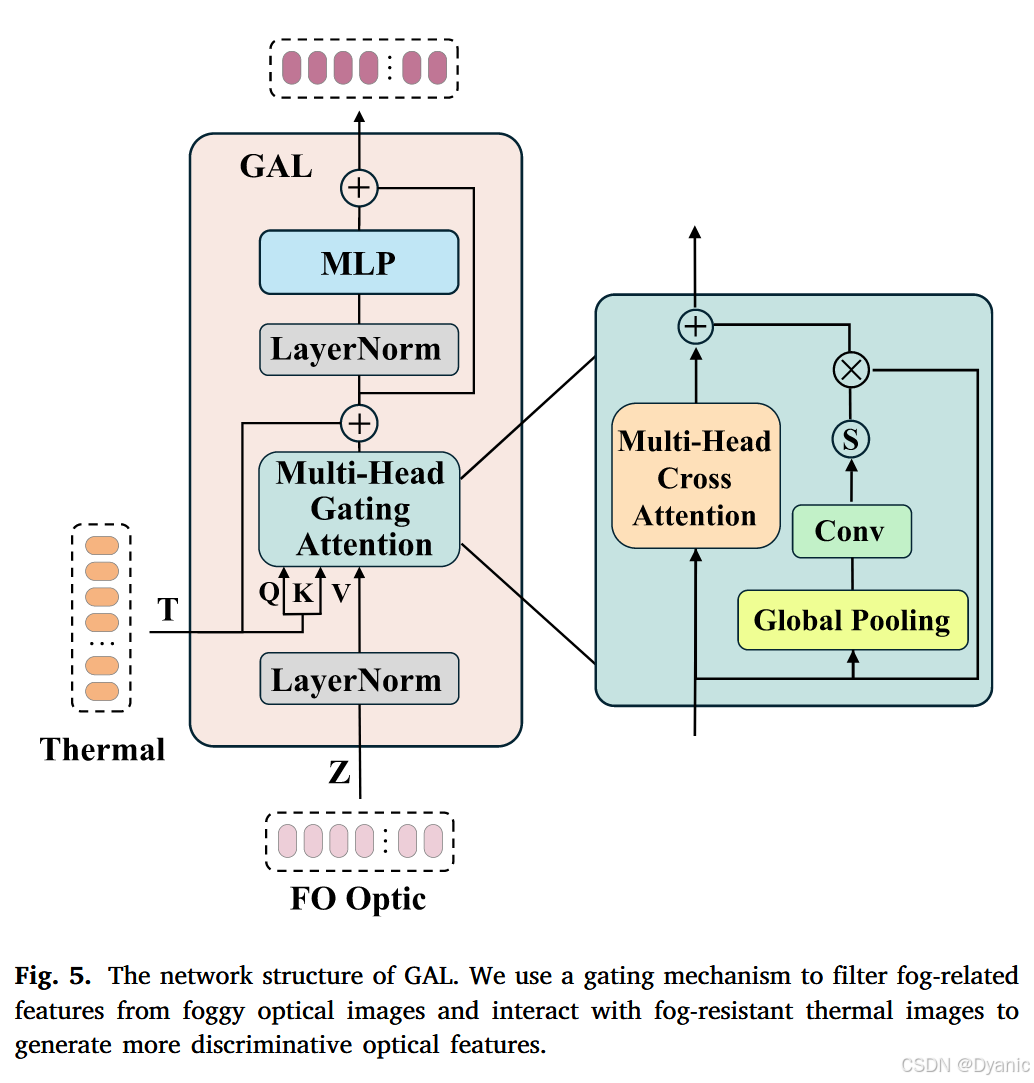
雾遮挡分支。 在雾天条件下,图像的局部细节变得模糊和遮挡。为了增强清晰的代表性区域并抑制雾天区域,我们将门控机制集成到原始Transformer架构中。我们的FO分支包括一个骨干网络和四个门控注意力层(GAL),如图5所示。输入特征图的空间维度首先被压缩成通道描述符。然后为每个通道生成权重矩阵,反映其重要性。最后,对每个通道的特征图进行加权以增强关键特征。FO中的整个过程表述如下:
Z=(LeakyReLU(Conv(Z)))×k,Z = (\text{LeakyReLU}(\text{Conv}(Z)))_{\times k},Z=(LeakyReLU(Conv(Z)))×k,
ZLN′=LN(Z),Z'_{LN} = \text{LN}(Z),ZLN′=LN(Z),
ZGAB′=fsig(Conv(fgp(ZLN′)))×ZLN′,Z'_{GAB} = f_{sig}(\text{Conv}(f_{gp}(Z'_{LN}))) \times Z'_{LN},ZGAB′=fsig(Conv(fgp(ZLN′)))×ZLN′,
Zl′=MCA(LN(ZLN′,T))+ZGAB′+T,Z'_l = \text{MCA}(\text{LN}(Z'_{LN}, T)) + Z'_{GAB} + T,Zl′=MCA(LN(ZLN′,T))+ZGAB′+T,
Zl+1=MLP(LN(Zl′))+Zl′+ZLN′,(13)Z_{l+1} = \text{MLP}(\text{LN}(Z'_l)) + Z'_l + Z'_{LN},\tag{13}Zl+1=MLP(LN(Zl′))+Zl′+ZLN′,(13)
其中ZLN′Z'_{LN}ZLN′、ZGAB′Z'_{GAB}ZGAB′和Zl′Z'_lZl′表示中间特征。函数fsig(⋅)f_{sig}(\cdot)fsig(⋅)和fgp(⋅)f_{gp}(\cdot)fgp(⋅)分别表示Sigmoid和全局池化函数。MLP和LN分别指多层感知器和层归一化函数。Zl+1Z_{l+1}Zl+1表示层lll的MCA模块、GAB模块和MLP模块的输出特征。
3.3.2. 属性感知融合模块
在通过AGM获得对应于不同属性的三个特征后,我们采用属性感知融合模块(AFM)对它们进行自适应融合操作。与SKNet(Li et al., 2019)沿通道维度整合信息不同,我们的方法在空间维度上自适应地聚合这三个特征,如图3(c)所示。这种方法更好地保留了特征图的空间结构,使模型在执行自适应聚合时能够更加关注图像的局部细节。整个AFM过程可以描述如下:
Foptic=Concate(Fn,Fl,Ff),F_{optic} = \text{Concate}(F_n, F_l, F_f),Foptic=Concate(Fn,Fl,Ff),
Attn=Concate(Pavg(Foptic),Pmax(Foptic)),\text{Attn} = \text{Concate}(\mathcal{P}_{\text{avg}}(F_{optic}),\mathcal{P}_{ \text{max}}(F_{optic})),Attn=Concate(Pavg(Foptic),Pmax(Foptic)),
Attn^i=fsig(F2→3(Attni)),i=1,2,3,\hat{\text{Attn}}_i = f_{sig}(\mathcal{F}^{2 \to 3}(\text{Attn}_i)), \quad i = 1, 2, 3,Attn^i=fsig(F2→3(Attni)),i=1,2,3,
S=F(Attn^1⋅Fn+Attn^2⋅Fl+Attn^3⋅Ff),(14)S = \mathcal{F}(\hat{\text{Attn}}_1 \cdot F_n + \hat{\text{Attn}}_2 \cdot F_l + \hat{\text{Attn}}_3 \cdot F_f),\tag{14}S=F(Attn^1⋅Fn+Attn^2⋅Fl+Attn^3⋅Ff),(14)
其中FopticF_{optic}Foptic表示通过连接FnF_nFn、FlF_lFl和FfF_fFf获得的光学特征图,Pavg(⋅)\mathcal{P}_{\text{avg}}(\cdot)Pavg(⋅)和Pmax(⋅)\mathcal{P}_{\text{max}}(\cdot)Pmax(⋅)分别表示平均和最大池化,C(⋅)\mathcal{C}(\cdot)C(⋅)表示应用于加权结果的卷积。
3.3.3. 多场景光学引导模块
为了促进光学和热特征之间的有效交互,我们设计了一个多场景光学引导模块(MOGM)。MOGM包括四个残差多重注意力组(RMAG),每个组包含OMCL、MGL、STL和OTL,如图3(a)所示。
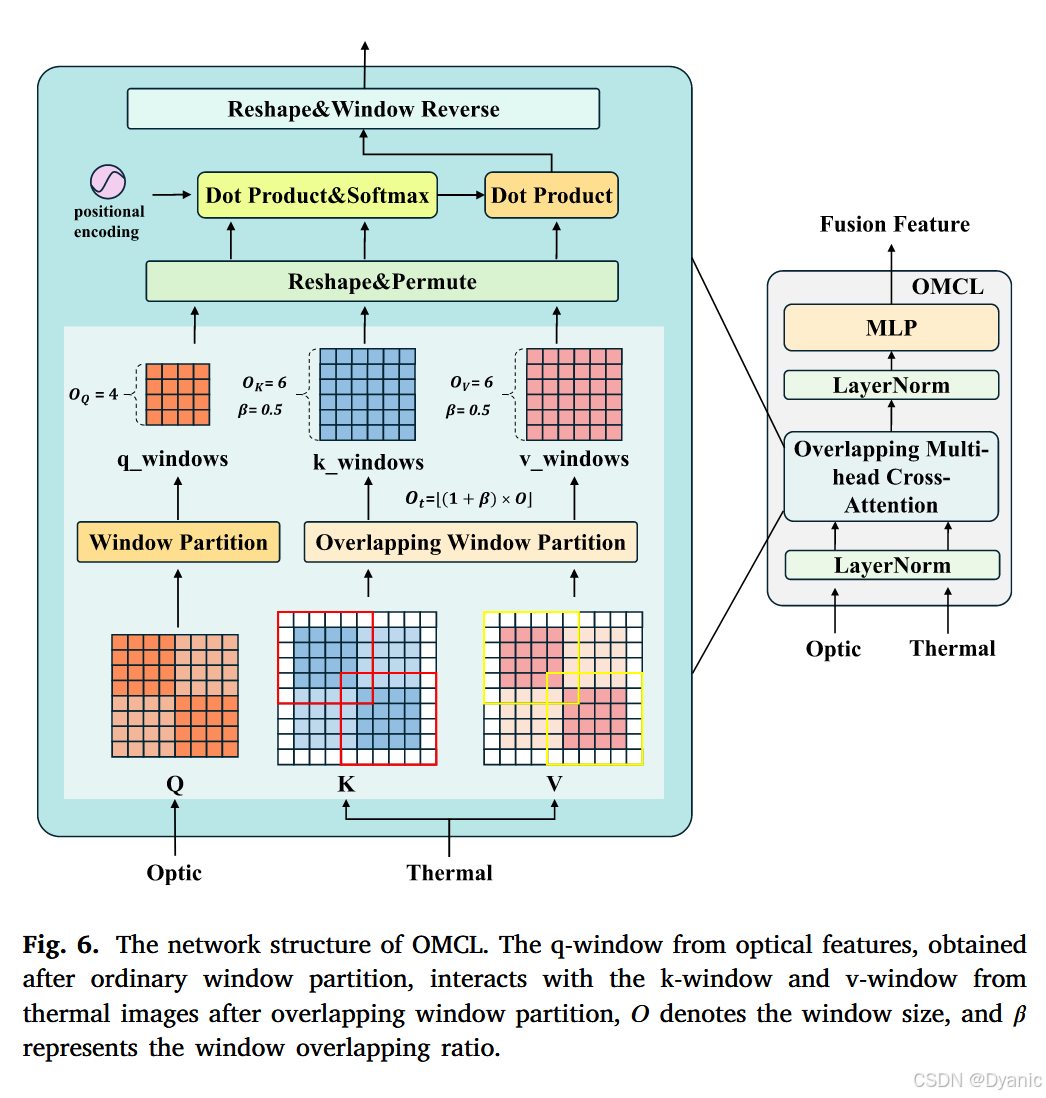
重叠多头交叉注意力层。 受到优秀工作HAT(Chen et al., 2023)的启发,我们将重叠多头交叉注意力层(OMCL)引入模型。在OMCL中,我们结合了多模态重叠多头交叉注意力(OMCA),它确保光学信息可以查询更大的窗口,并在多模态融合过程中扩展窗口连接性,类似于传统Swin Transformer的架构,如图6所示。
重叠Transformer层。 我们采用HAT(Chen et al., 2023)中的原始重叠Transformer层(OTL),其中该注意力机制中的Q、K和V来自单个输入模态的特征。此外,我们的消融实验表明OMCL实现了优越的性能。
多模态引导层。 3.3.1节详细介绍了MGL的结构和计算。主要区别在于MCA计算,其中XXX表示热特征,YYY表示光学融合特征。具体来说,QQQ和KKK来自光学特征,而VVV来自热特征。
Swin Transformer层。 为了捕获长程依赖关系并建模全局上下文信息,Swin Transformer层(STL)采用自注意力和移位窗口机制来进一步增强融合信息。STL中的整个过程表述如下:
t^l=MSA(LN(tl−1))+tl−1,\hat{t}^l = \text{MSA}(\text{LN}(t^{l-1})) + t^{l-1},t^l=MSA(LN(tl−1))+tl−1,
tl=MLP(LN(t^l))+t^l,(15)t^l = \text{MLP}(\text{LN}(\hat{t}^l)) + \hat{t}^l,\tag{15}tl=MLP(LN(t^l))+t^l,(15)
其中tlt^ltl表示第lll个STL的输出。MSA表示多头自注意力函数,MLP和LN分别表示多层感知器和层归一化函数。
3.4. 训练算法
在训练阶段,必须解决三个关键问题。首先,如果直接使用整个训练集来训练网络,低光和雾条件引入的误差将通过所有分支传播。其次,由于场景在测试阶段是未知的,因此预测OTUAV-SR任务中光学表示所带来的具体挑战是不可行的。我们的最终目标是增强利用新兴光学表示的能力,同时抑制对未表示特征的响应。为了解决这些问题,我们提出了一个三阶段训练策略,以促进复杂场景中引导热超分辨率任务的高效学习。
骨干网络训练: 在第一阶段,我们使用所有VGTSR2.0训练数据来训练一般天气条件下光学图像的特征提取(如图4中的骨干网络所示)。该模块包括4组卷积层和LeakyReLU激活函数用于×4\times 4×4超分辨率,以及6组用于×8\times 8×8超分辨率。请注意,所有三个引导分支和属性感知融合层都被移除,主要目标是训练一个用于所有属性分支的通用特征提取器。
所有属性特定分支的训练: 在获得训练好的特征提取器后,我们使用相应的属性特定训练数据依次训练每个分支中的三个剩余属性特定模块,以学习属性特定的光学表示。在此过程中,所有其他参数都被冻结。在训练LI分支之前,我们按照3.3.1节中概述的基于RetinexFormer预训练Retinex分解网络。请注意,在训练特定分支时,仅使用来自相应场景的数据。来自其他场景的数据及其分支结构都从网络中排除。训练设置与第一阶段保持一致。
属性感知融合模块的训练和MOGM的微调: 在获得学习到的特征提取器和三个属性特定分支后,我们使用所有数据来训练属性感知融合模块并微调MOGM,同时冻结所有其他参数。属性感知融合模块和MOGM的学习率分别设置为10−410^{-4}10−4和0.5×10−40.5 \times 10^{-4}0.5×10−4。其他训练设置保持不变。
3.5. 损失函数
整个网络通过最小化预测的无人机热图像与真实GT热图像之间的L1损失来优化。损失计算如下:
L(Φ)=1M∑j=1M∥Fjout−FjGT∥1,(16)\mathcal{L}(\Phi) = \frac{1}{M} \sum_{j=1}^{M} \|F_j^{out} - F_j^{GT}\|_1,\tag{16}L(Φ)=M1j=1∑M∥Fjout−FjGT∥1,(16)
其中L(Φ)\mathcal{L}(\Phi)L(Φ)表示损失函数,Φ\PhiΦ表示GDNet内要优化的参数集。FjoutF_j^{out}Fjout表示GDNet产生的输出热图像的第jjj个像素,FjGTF_j^{GT}FjGT对应于真实热图像的第jjj个像素。
4. 数据集
在本节中,我们将介绍我们的可见光图像引导热图像超分辨率-2.0(VGTSR2.0)数据集,包括现有数据集、数据收集和分析,以及数据集挑战。
4.1. 现有数据集
关于OTUAV-SR的现有研究通常依赖于FLIR-ADAS(Gupta and Mitra, 2021)和CATS(Treible et al., 2017)等数据集,这些数据集来自手持设备。这些数据集提供高分辨率光学图像和较低分辨率热图像,但存在对齐问题。此外,它们受到设备拍摄角度和条件的限制,使其不太适合复杂场景。VGTSR1.0数据集在多模态图像超分辨率方面取得了进展,特别是在图像对齐和质量方面。然而,它在场景多样性和天气条件方面受到限制,主要集中在校园和街道场景,并且缺乏在各种光照和雾天条件下的大量图像对。为了解决这些局限性并增强热图像超分辨率算法在不同环境中的鲁棒性评估,我们引入了VGTSR2.0数据集。这个新数据集旨在支持在具有挑战性条件下高分辨率热图像的超分辨率研究。VGTSR2.0与一些常见超分辨率数据集的比较如表1所示。
4.2. 数据收集和分析
VGTSR2.0数据集包含3500对高分辨率光学和热图像,使用大疆M30T和Matrice 3TD无人机获取,后者专为大疆Dock 2平台设计。这些无人机配备了非制冷VOx微测辐射热计传感器,能够进行详细的热成像,在标准模式下具有1080×19201080 \times 19201080×1920的可调分辨率,在超分辨率模式下具有1280×10241280 \times 10241280×1024的分辨率。为了确保图像的对齐和真实性,所有光学图像都被调整大小并裁剪以匹配热图像的640×512640 \times 512640×512分辨率。在裁剪过程中执行手动对齐以满足多模态研究方法的要求,保持整个数据集的一致性。在VGTSR2.0数据集中,我们对图像对进行了全面的统计分析。如图7所示,VGTSR2.0包含在各种光照条件下捕获的大量图像,例如明亮的日光、夜间的低光环境,以及黄昏和黎明时的复杂光照变化。这种多样性有效地测试了OTUAV-SR算法在不同光照环境中的适应性和性能。此外,我们在不同浓度的雾霾下捕获图像,从轻雾到重雾,反映了雾霾对图像清晰度和细节捕获所带来的挑战。该数据集还支持低光增强和去雾等任务。为了丰富数据集并增强其挑战性,原始VGTSR1.0数据集被均匀分成三部分。两部分用于人工生成雾天和低光图像,而第三部分保留在正常光照条件下捕获的图像。我们保持真实数据与合成数据2:1的比例,确保数据集的真实性和可靠性,同时扩大其多样性。如图8所示,VGTSR2.0中的场景更加多样化,不再局限于校园和街道。具体场景包括小屋、摩天大楼、停车场、农田、池塘、湖泊、街道和学校,所有场景都在不低于200米的高度拍摄。这种多样性和复杂性为OTUAV-SR带来了独特的挑战。建筑风格、植被和地形的多样性,以及水体和陆地表面之间热特性的显著差异,都导致了复杂的热模式,对OTUAV-SR任务构成了重大挑战。在VGTSR2.0数据集上训练GDNet网络的数据分配如表2所示。这种分配确保了在不同照明和能见度条件下评估超分辨率算法的平衡数据集。
4.3. 数据集挑战
由于其独特的特性,VGTSR2.0数据集与原始数据集相比引入了几个新挑战:
• 图像质量退化: 无人机捕获的热图像通常对比度较低且纹理细节减少,而光学图像经常受到高度和振动导致的噪声增加的影响。这些因素对超分辨率过程产生负面影响,并可能引入伪影。
• 小物体恢复: 无人机图像通常包含小物体,例如车辆和行人,使得在超分辨率任务期间恢复边缘
表5
在DroneVehicle(Sun et al., 2022)数据集上超分辨率方法(在VGTSR2.0数据集上训练)的定量比较,采用BD退化模型进行×8\times 8×8超分辨率。粗体字表示最佳性能。
细节比手持相机捕获的更简单场景更具挑战性。
• 环境可变性: 数据集包含在不同光照条件(白天、夜间和黄昏/黎明)和不同雾霾浓度(从轻雾到重雾)下捕获的图像,为超分辨率算法的适应性提供了全面评估。
• 场景多样性: 数据集涵盖广泛的场景,包括摩天大楼、停车场、农田、池塘、湖泊、街道和学校,所有场景都在至少200米的高度拍摄。建筑风格、植被和各种表面热特性的多样性增加了超分辨率任务的复杂性。
此外,VGTSR2.0结合了合成和真实图像,增强了数据集的多样性和复杂性。合成图像通过模拟雾和低光等条件的算法生成,为测试算法提供了受控但具有挑战性的环境。
5. 实验
在本节中,我们在VGTSR2.0数据集上对所提出的GDNet和其他最先进的方法进行全面评估。首先,将在5.1节中介绍GDNet的实现细节。然后在5.2节中研究我们的GDNet的有效性,最后在5.3节中报告消融实验和可视化结果。
5.1. 实现细节
我们使用PyTorch实现GDNet。对于三种条件下的光学图像输入分支,我们使用640×512640 \times 512640×512的光学图像。热图像输入分支的输入是通过退化模型模拟的低分辨率热图像。我们使用所提出的三阶段训练方案训练整个网络。MOGM包括四个残差多重注意力组(RMAG),每个组包含一个MGL、六个STL、一个OMCL和一个OTL。在我们提出的GDNet中,卷积核大小、嵌入维度、窗口大小、注意力头数和块大小通常分别设置为3×33 \times 33×3、96、8、6、1。我们将块的分辨率设置为与SwinIR基线和其他超分辨率方法相同:48×4848 \times 4848×48。对于×4\times 4×4超分辨率,从LR热图像中裁剪48×4848 \times 4848×48像素区域,并从HR光学图像上相应位置裁剪192×192192 \times 192192×192像素区域作为输入。对于×8\times 8×8超分辨率,同样从LR热图像中裁剪48×4848 \times 4848×48像素区域,而从HR光学图像上相应位置取384×384384 \times 384384×384像素区域作为输入。模型使用Adam优化器进行训练(β1=0.9\beta_1 = 0.9β1=0.9,β2=0.99\beta_2 = 0.99β2=0.99,ϵ=10−8\epsilon = 10^{-8}ϵ=10−8)。学习率初始设置为10−410^{-4}10−4,然后每200个epoch减半。批次大小设置为8。
5.2. 定量和定性评估
为了验证GDNet的有效性,我们在VGTSR2.0数据集上进行了×4\times 4×4和×8\times 8×8超分辨率实验。我们报告了八种最先进的SISR方法的结果,包括基于CNN的模型D-DBPN(Haris et al., 2018)、RDN(Zhang et al., 2018c)、SAN(Dai et al., 2019)、EDSR(Lim et al., 2017)、RCAN(Zhang et al., 2018a)、HAN(Niu et al., 2020);以及基于Transformer的模型TransENet(Lei et al., 2021)、SPT(Hao et al., 2024)、SwinIR(Liang et al., 2021)、HAT(Chen et al., 2023)和Restormer(Zamir et al., 2022)。此外,我们比较了三种OTUAV-SR方法:UGSR(Gupta and Mitra, 2021)、MGNet(Zhao et al., 2023)和CENet(Zhao et al., 2024),其中CENet目前实现了最佳性能。我们保存了所有模型的最佳图像结果,并使用参考和无参考评估指标一致地评估图像质量。
表3展示了在整个VGTSR2.0数据集上使用BD和BI退化模型进行×4\times 4×4和×8\times 8×8超分辨率的结果。对于×4\times 4×4超分辨率,我们的方法在BI模型下PSNR提高0.09 dB,SSIM提高0.0013,在BD模型下PSNR提高0.14 dB,SSIM提高0.0014。对于×8\times 8×8超分辨率,BI模型产生0.1 dB的PSNR和0.0053的SSIM增强,而BD模型获得0.17 dB的PSNR和0.0066的SSIM增加。此外,我们的方法在LPIPS和NIQE指标上都实现了最佳性能,展示了其在不同尺度和指标上的渐进优势。
表6展示了PSNR、SSIM和LPIPS的定量结果,粗体文本表示每个指标的最佳性能。GDNet在×4\times 4×4和×8\times 8×8超分辨率的两种退化类型中实现了最高的平均PSNR、SSIM和最低的LPIPS。具体而言,对于×4\times 4×4超分辨率,GDNet在BI和BD模型中分别实现了0.07 dB和0.14 dB的PSNR增益。对于×8\times 8×8超分辨率,PSNR在BI退化模型中提高了0.17 dB,在BD退化模型中提高了0.21 dB,突显了GDNet在真实光学引导热超分辨率中的有效性能。
此外,为了评估GDNet的泛化能力,我们在DroneVehicle(Sun et al., 2022)数据集上进行×8\times 8×8超分辨率重建实验。如表5所示,在VGTSR2.0数据集上训练的GDNet展示了出色的跨数据集性能,在PSNR(21.52 dB)、SSIM(0.6520)和LPIPS(0.4328)方面优于现有方法。这些结果证实了我们模型的泛化能力和鲁棒性。
不同的单图像超分辨率方法表现出非常接近的性能。然而,基于Transformer的超分辨率方法通常优于基于CNN的方法。在引导超分辨率中,UGSR通过融合方法从光学图像转移纹理时引入噪声,导致较低的PSNR和SSIM。MGNet和CENet分别结合了边缘、语义和外观线索,以及模态转换和任务辅助超分辨率,相比其他方法具有显著优势。通过解耦光学表示并利用自适应融合,我们的GDNet实现了最优性能。
为了进一步验证我们方法的有效性,我们使用从VGTSR2.0捕获的真实光学图像引导热图像进行超分辨率处理。我们使用NIQE(Mittal et al., 2012b)和BRISQUE(Mittal et al., 2012a)进行无参考图像质量评估,定量结果总结在表4中。实验结果表明,与其他方法相比,我们的GDNet在NIQE和BRISQUE指标上都显著提高了性能。与其他单图像超分辨率模型和引导超分辨率模型相比,我们的模型在参数效率方面表现出优势。表4还展示了基于模型大小、FLOPs、推理时间和性能的不同超分辨率方法的比较。具体而言,与MGNet相比,我们的模型减少了36%的参数数量。GDNet以11.9M参数的模型大小、32.07G FLOPs和53.1 ms的推理时间实现了具有竞争力的性能。这些结果表明,我们的方法不仅保持了与领先模型CENet相当的参数规模,而且实现了更优越的性能。
为了评估GDNet在噪声条件下对各种数据分布的适应性,我们基于LF图像退化模型(Wang et al., 2024)进行实验,该模型全面整合了三个关键组成部分:模糊核、噪声和下采样操作。如表7所示,在不同的模糊核大小下,GDNet保持良好的性能,评估指标波动最小,展示了优越的泛化能力和鲁棒性。
我们的模型不仅在PSNR和SSIM等评估指标上表现出优越的性能,而且在感知质量方面也表现出显著的改进。如图9所示,单图像超分辨率方法难以恢复详细纹理,引导图像超分辨率方法在处理未知纹理和外观时面临挑战。相比之下,我们提出的GDNet仍然可以在雾天条件下使用光学图像重建更好的细节。如图10、11和12所示,即使在BD和BI退化模型的低光条件下,我们提出的GDNet恢复的纹理最接近真实热图像,而光学引导热超分辨率方法甚至引入了错误的纹理信息。特别值得注意的是,我们的GDNet在由BD模型退化的无人机热图像的×8\times 8×8超分辨率中实现了实质性增强。
我们在各种环境条件下获取和模拟光学数据,包括强光、雨、雪和良好照明条件。在这些场景中进行了光学引导结果的定性比较。如图14所示,与其他方法相比,GDNet通过在具有挑战性的环境中生成增强的视觉清晰度,展示了卓越的重建能力。此外,GDNet获得的超分辨率结果表现出最接近GT的温度分布。如图13(a)所示,GDNet实现了高质量结果,平均温度值与GT相同,中位数差异小于1°C。此外,如图13(b)所示,与双三次模型相比,GDNet与GT的温度差异更小。
5.3. 消融实验
属性特定引导模块的有效性。 为了进一步定量评估每个属性特定分支在处理相应场景属性方面的功效,我们使用基于属性的VGTSR2.0进行比较研究。如表8所示,术语Normal、Fog和Low-light分别表示正常光照、雾天和低光条件的数据集。每个属性特定分支在其相应属性上实现了优越的性能,表明我们的GDNet可以通过利用属性信息有效地构建针对不同天气条件定制的光学外观表示。此外,我们观察到多个分支的组合结果至少与单个分支获得的结果相当。这表明为不同属性设计分支有效地解决了在不同天气条件下各自的光学外观挑战,而多个分支的整合有效地缓解了多种天气条件下的光学表示挑战。
我们同时可视化了通过LI和FO分支处理的光学信息的中间特征。如图15所示,受到路灯曝光的影响,道路的详细信息被遮挡,Decom产生了更清晰的结构,而LI进一步减少了噪声。如图16所示,在使用FO之前,雾天条件下的光学特征难以渲染。然而,结合4层块产生了噪声减少和纹理清晰度增强的光学特征,证明了FO模块的有效性。
融合模块和OMCL的有效性。 为了验证所提出的AFM的有效性,我们比较了各种融合方法,包括逐元素加法、连接和基于SKNet的改进SKFusion,用于整合来自不同分支的引导特征。如表10所示的结果表明,我们的AFM实现了最佳性能。如图18所示,使用AFM融合模块恢复的车辆轮廓明显更清晰。
为了进一步评估OMCL的有效性并将其与原始OTL进行比较,我们对OMCL进行添加和删除操作。实验设置在表9中概述。与MGL+STL相比,添加OMCL在PSNR上提高了0.07,在SSIM上提高了0.0008。此外,按照HAT方法在末尾加入OTL,仅导致PSNR增加0.02。我们设计的OMCL提供了明显更好的性能。在可视化中,如图17所示,使用OMCL的超分辨率结果包含更多的细节和纹理信息。
不同参数和对齐的影响。 我们使用PSNR、SSIM和LPIPS指标评估不同配置。如表11所示,GDNet以11.9M参数、嵌入维度96、6个注意力头实现最优性能(PSNR = 31.40,SSIM = 0.9134,LPIPS = 0.0504)。在嵌入维度为64和注意力头数设置为8的情况下,与CENet相比,GDNet在PSNR和SSIM方面表现出明显的性能差异,同时在LPIPS方面表现出更显著的降低,反映了其在高效架构设计方面的明显优势。
我们对光学图像进行非刚性变形、旋转和裁剪操作,并使用严重未对齐的光学信息来引导热图像超分辨率。如表11所示,CENet和GDNet的性能在非对齐条件下降低,图19说明了对齐策略的视觉效果。从左到右的比较清楚地表明,对齐策略显著提高了小目标车辆检测和交通信号灯识别的质量。没有对齐时,可以观察到明显的变形和模糊;而有对齐时,目标显得正常和清晰。光学引导结果特别证明了对齐机制在增强细节保留和边缘清晰度方面的重要性。
5.4. 下游任务比较
为了验证GDNet的实用性,我们对下游任务进行了一系列实验,特别关注超分辨率结果上的语义分割和目标检测。如图20所示,我们的方法在城市建筑分割和耕地地块提取方面产生了接近真实值的结果。此外,如图21所示,与当前主流方法(如HAT和SwinIR)相比,GDNet成功检测到更多目标车辆,这些方法表现出更高的漏检率。
此外,我们从DroneVehicle(Sun et al., 2022)中选择1300对RGB-T图像对,以进一步验证GDNet在下游检测任务上的有效性。为了公平比较,我们在所有超分辨率结果中采用了带有定向边界框(OBB)的预训练YOLOv8s模型作为基础检测器。该模型在包含超过50,000张车辆检测图像的综合数据集上训练,涵盖红热红外、白热红外和可见光光谱。检测性能使用四个标准指标进行评估:mAP50、mAP、精确度§和召回率®。我们将在GitHub上发布数据集和预训练模型,网址为https://github.com/Jocelyney/GDNet。
如表12所示,我们提出的GDNet在所有评估指标上都显著优于所有竞争方法。具体而言,GDNet实现了88.8%的mAP50,比第二名表现者(MGNet的85.9%)大幅提高了2.9%。同样,对于mAP,GDNet展示了79.6%的卓越性能,超过MGNet(75.7%)3.9%。精确度和召回率分别为97.1%和78.5%。
对于分割任务,我们使用四个广泛采用的指标IOU、DICE、ACC和ASSD在DroneVehicle和VGTSR2.0数据集上评估性能。如表13所示,在VGTSR2.0数据集上,与最接近的竞争对手MGNet相比,GDNet在IoU上提高了0.56个百分点,在DICE上提高了0.49个百分点,在准确度上提高了0.46个百分点,同时将ASSD降低了0.51(越低越好)。在DroneVehicle数据集上的性能提升更加显著。
为了进一步验证我们方法的有效性,我们对下游任务进行定性比较。图22展示了DroneVehicle数据集上的目标检测结果,在具有挑战性的光照条件(极暗、低光、良好照明和雾天RGB图像)下比较了各种超分辨率技术。所提出的GDNet方法展示了优越的车辆检测性能,特别是在保留精细细节和边界定义方面,比竞争方法更接近真实值(GT)质量。
图23显示了相应的二值分割结果,前两行显示DroneVehicle数据集上的分割,后两行显示VGTSR2.0数据集上的结果。黄色虚线区域突出显示了我们的GDNet方法与替代方法相比实现了更准确的结构保留和更清晰的目标边界的区域,特别是在车辆密集的复杂城市环境中。这些发现证明了GDNet在下游任务(包括语义分割和目标检测)中的优越性。
6. 结论
本文提出VGTSR2.0综合基准数据集,用于光学引导的热成像无人机图像超分辨率(OTUAVSR)研究。该数据集包含3500组精准对齐的光热图像对,这些图像在多样化且具有挑战性的环境与场景中采集。为解决现有方法在不同无人机条件下生成有效引导特征的局限性,我们提出了一种新型引导解耦网络(GDNet)。该网络通过属性特异性引导模块(AGM)实现光学特征解耦,其针对弱光、雾霾及正常光照条件分别设置专用分支,从而在多重复杂环境中保持模型鲁棒性。此外,属性感知融合模块(AFM)通过整合三个解耦特征空间的信息,实现复杂场景下光学特征的自适应融合。定量与定性实验表明,在VGTSR2.0数据集上,GDNet显著超越了最先进的单图超分辨率与OTUAV-SR方法,并在下游任务中展现出强劲性能。未来研究将进一步探索不同分辨率下的非对齐引导超分辨率方法。