CV论文速递:覆盖3D视觉与场景重建、视觉-语言模型(VLM)与多模态生成等方向!(10.20-10.24)
本周精选12篇CV领域前沿论文,覆盖3D视觉与场景重建、视觉-语言模型(VLM)与多模态生成、视频处理与视觉任务优化、视觉应用与安全防御等核心方向。全部200多篇论文感兴趣的自取。
原文 资料 这里

一、3D视觉与场景重建方向
1、Inverse Image-Based Rendering for Light Field Generation from Single Images
作者:Hyunjun Jung, Hae-Gon Jeon
亮点:提出逆图像基渲染方法,仅通过单张图像生成光场,无需复杂3D几何重建或专用设备。设计神经渲染流水线,通过跨注意力机制建模源光线间关系并预测目标光线颜色,迭代更新生成的视外内容以保证遮挡区域一致性。在多种数据集上无需重新训练或微调,性能优于现有新颖视图合成方法。
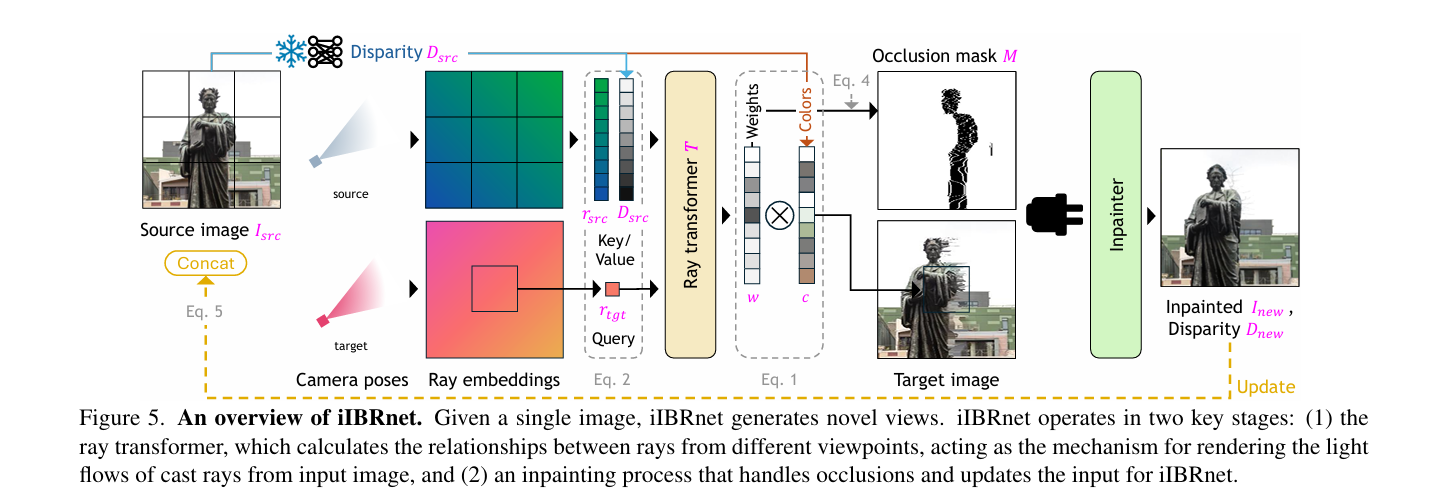
论文:https://arxiv.org/abs/2510.20132
开源代码:https://github.com/lzqsd/InverseRenderingOfIndoorScene
Comments:ICCV2025 Spotlight
2、PoseCrafter: Extreme Pose Estimation with Hybrid Video Synthesis
作者:Qing Mao, Tianxin Huang, Yu Zhu, Jinqiu Sun, Yanning Zhang, Gim Hee Lee
亮点:针对稀疏重叠图像对的相机姿态估计难题,提出混合视频生成(HVG)策略,结合视频插值与姿态条件新颖视图合成模型,生成更清晰的中间帧。设计基于特征匹配的选择器(FMS),从合成结果中筛选适合姿态估计的关键帧。在Cambridge Landmarks、ScanNet等多个数据集上验证,显著提升小重叠或无重叠图像对的姿态估计性能。
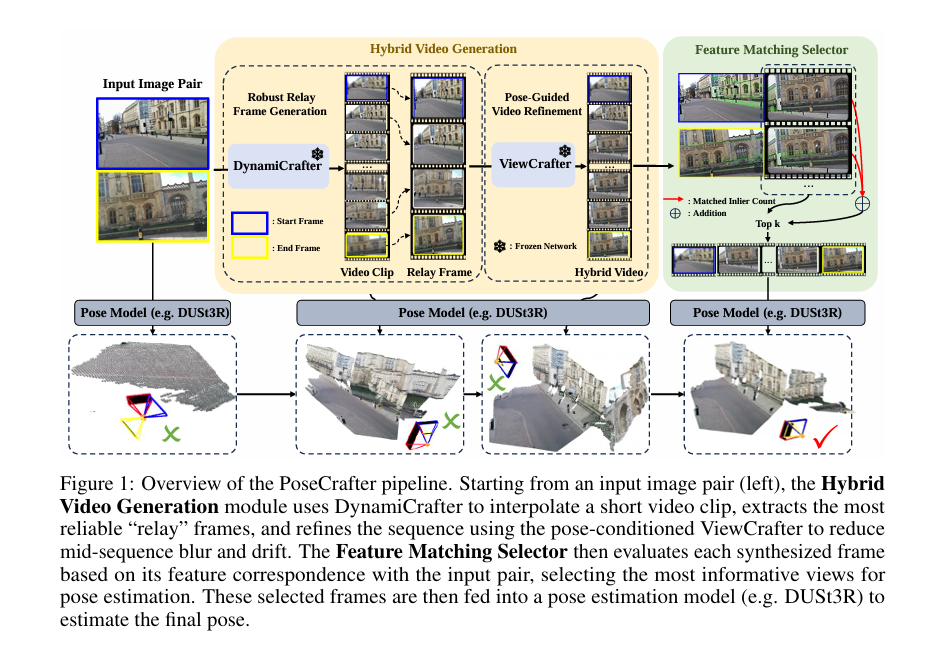
论文:https://arxiv.org/abs/2510.19527
开源代码:https://github.com/maoqingsunny/PoseCrafter
Comments:39th Conference on Neural Information Processing Systems (NeurIPS 2025)
3、PLANA3R: Zero-shot Metric Planar 3D Reconstruction via Feed-Forward Planar Splatting
作者:Changkun Liu, Bin Tan, Zeran Ke, Shangzhan Zhang, Jiachen Liu, Ming Qian, Nan Xue, Yujun Shen, Tristan Braud
亮点:提出无姿态框架PLANA3R,基于双视图无姿态图像实现室内场景度量级平面3D重建。利用视觉Transformer提取稀疏平面基元,估计相对相机姿态,通过平面splatting传播梯度。无需显式平面监督,仅依赖深度和法向标注即可在大规模立体数据集上训练,在3D表面重建、深度估计等任务中表现出强泛化能力,还能实现准确的平面分割。
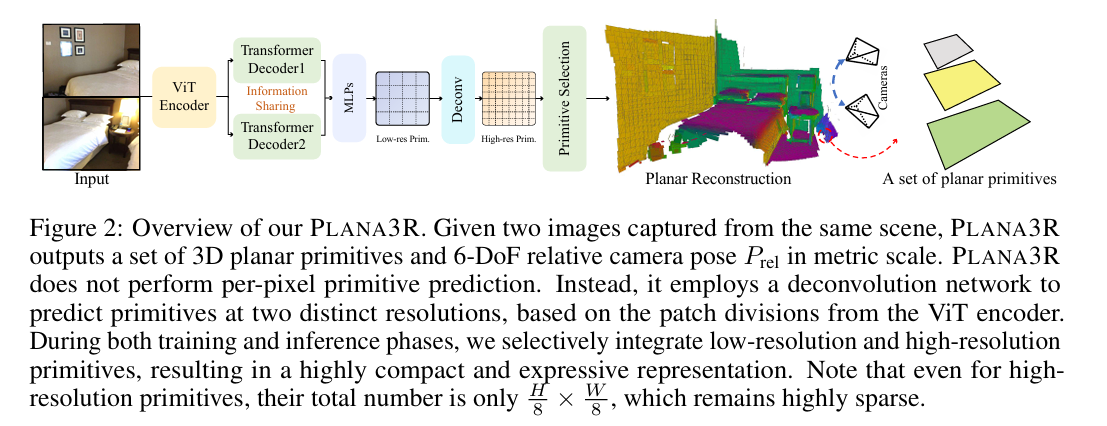
论文:https://arxiv.org/abs/2510.18714
开源代码:https://lck666666.github.io/plana3r/
Comments:39th Conference on Neural Information Processing Systems (NeurIPS 2025).
二、视觉-语言模型(VLM)与多模态生成方向
1、Unified Reinforcement and Imitation Learning for Vision-Language Models
作者:Byung-Kwan Lee, Ryo Hachiuma, Yong Man Ro, Yu-Chiang Frank Wang, Yueh-Hua Wu
亮点:提出统一强化与模仿学习(RIL)算法,用于构建高效轻量型视觉-语言模型(VLM)。融合强化学习与对抗性模仿学习优势,使小型学生模型既能模仿大型教师模型的文本生成能力,又能通过强化信号提升生成性能。引入LLM基鉴别器区分学生与教师输出,结合多教师模型指导保证学习多样性,在多个视觉-语言基准上缩小与顶尖开源/闭源VLM的性能差距,部分场景实现超越。
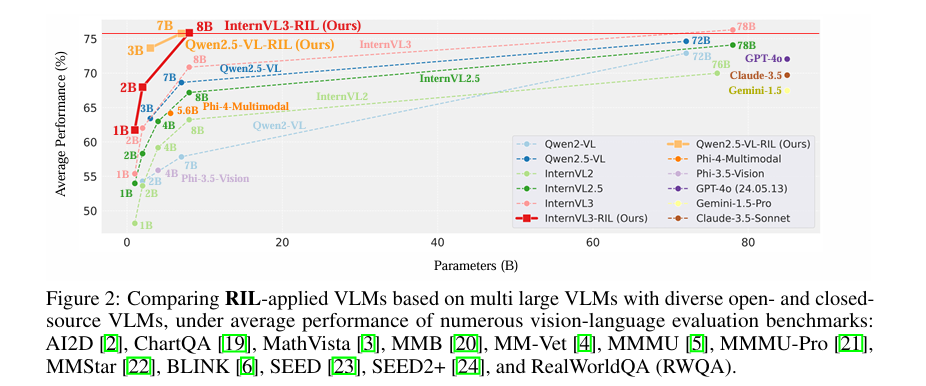
论文:https://arxiv.org/abs/2510.19307
开源代码:https://byungkwanlee.github.io/RIL-page
Comments:NeurIPS 2025, Project page: https://byungkwanlee.github.io/RIL-page
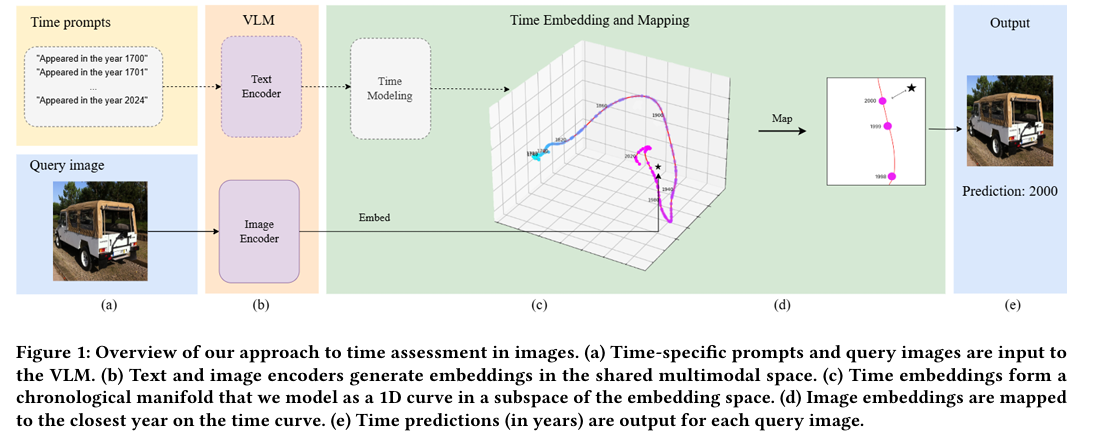
2、A Matter of Time: Revealing the Structure of Time in Vision-Language Models
作者:Nidham Tekaya, Manuela Waldner, Matthias Zeppelzauer
亮点:作者提出VLM的嵌入空间中存在一个低维、非线性的流形结构来编码时间信息,并基于此构建显式的‘时间线’(timeline)表示。该方法无需微调模型,而是通过分析预训练VLM的特征空间提取时间顺序,从而实现高效的时间推理,相比依赖prompt工程的方法更具可扩展性和计算效率
论文:https://arxiv.org/abs/2510.19559
开源代码:https://tekayanidham.github.io/timeline-page/
Comments:Published in Proceedings of the 33rd ACM International Conference on Multimedia (MM ’25). 为VLM的时间推理研究奠定了数据与方法基础,其提出的时间线提取策略为历史图像 Dating、数字档案管理等场景提供了实用解决方案。
三、视频处理与视觉任务优化方向
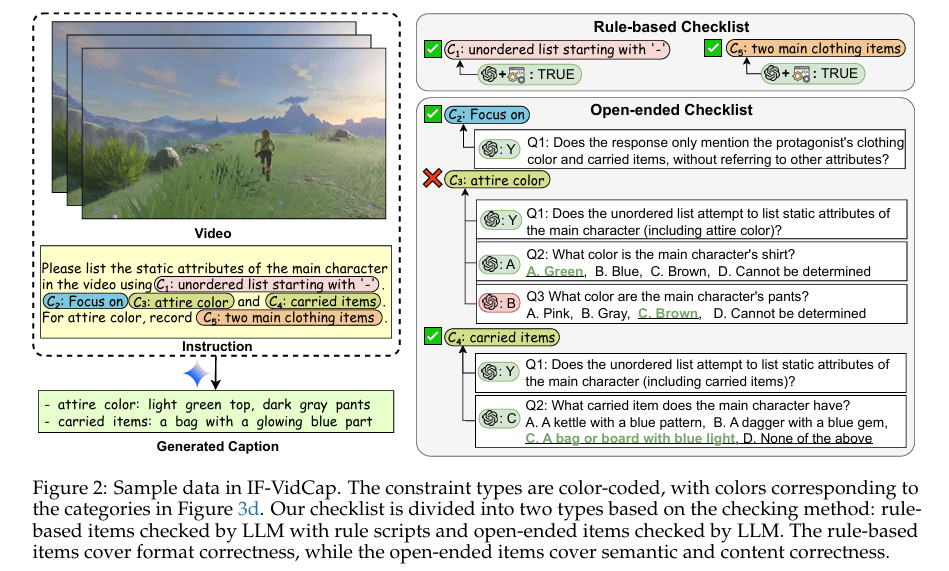
1、IF-VidCap: Can Video Caption Models Follow Instructions?
作者:Shihao Li, Yuanxing Zhang, Jiangtao Wu, Zhide Lei, Yiwen He, Runzhe Wen, Chenxi Liao, Chengkang Jiang, An Ping, Shuo Gao, Suhan Wang, Zhaozhou Bian, Zijun Zhou, Jingyi Xie, Jiayi Zhou, Jing Wang, Yifan Yao, Weihao Xie, Yingshui Tan, Yanghai Wang, Qianqian Xie, Zhaoxiang Zhang, Jiaheng Liu
亮点:提出IF-VidCap基准,用于评估可控视频描述的指令跟随能力,包含1400个高质量样本,从格式正确性和内容正确性双维度进行评估。对20余款主流模型的全面评测显示,专有模型仍占主导但开源模型差距缩小,专注于密集描述的模型在复杂指令上表现不及通用型MLLM,为后续模型优化指明方向。
论文:https://arxiv.org/abs/2510.18726
开源代码:https://github.com/NJU-LINK/IF-VidCap
Comments:填补视频描述领域指令跟随评估空白,为实际应用场景中的可控视频生成提供评估标准。
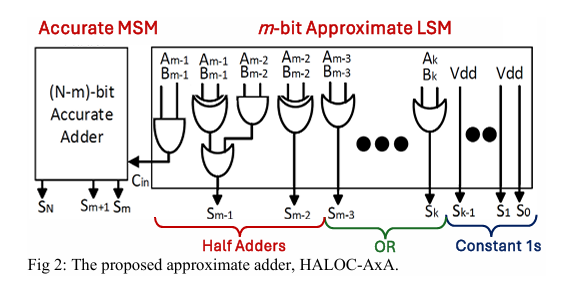
2、HALOC-AxA: An Area/-Energy-Efficient Approximate Adder for Image Processing Application
作者:Hasnain A. Ziad, Ashiq A. Sakib
亮点:设计新型近似加法器HALOC-AxA,专为计算密集型图像处理等多媒体应用优化。在面积和能效上优于现有加法器,同时保持相当或更优的计算精度。通过图像处理任务部署验证,该加法器能够数字重建高质量图像,平衡了性能、精度与能效的冲突需求。
论文:https://arxiv.org/abs/2510.20137
Comments:5 Pages, 6 Figures, and 1 Table
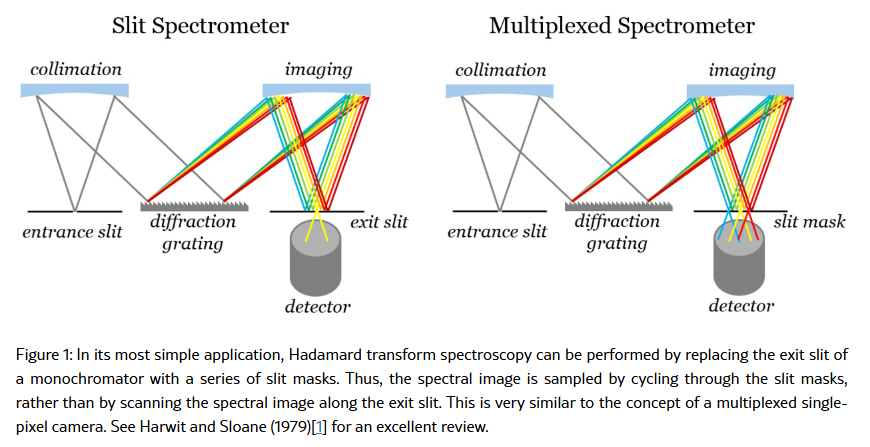
3、Performance analysis of a Hadamard Transform Spectral Imaging system
作者:John Nijim, Zoran Ninkov, Dmitry Vorobiev, Kevin Kearney
亮点:深入分析哈达玛变换光谱成像(HTSI)系统性能,该技术通过多缝掩模编码恢复光谱,适用于低光子通量场景。对比单缝扫描等直接测量方法,发现HTSI在存在探测器读出噪声等信号无关噪声时能提升光谱平均信噪比,在仅存在泊松光子噪声时无明显净效应;发射线的信噪比在两种噪声场景下均优于单缝扫描,且随读出噪声与散粒噪声比增加而提升。
论文:https://arxiv.org/abs/2510.20195
四、视觉应用与安全防御方向
1、PartNeXt: A Next-Generation Dataset for Fine-Grained and Hierarchical 3D Part Understanding
作者:Penghao Wang, Yiyang He, Xin Lv, Yukai Zhou, Lan Xu, Jingyi Yu, Jiayuan Gu
亮点:推出下一代3D部件理解数据集PartNeXt,包含23000余个样本,解决现有PartNet数据集依赖无纹理几何和专家标注的局限性。支持细粒度和层次化的3D部件理解,为计算机视觉、图形学和机器人学领域的部件级任务提供更具扩展性和可用性的数据支撑。

论文:https://arxiv.org/abs/2510.20155
开源代码:https://authoritywang.github.io/partnext
Comments:NeurIPS 2025 DB Track. Project page: https://authoritywang.github.io/partnext
2、Kinematic Analysis and Integration of Vision Algorithms for a Mobile Manipulator Employed Inside a Self-Driving Laboratory
作者:Shifa Sulaiman, Tobias Busk Jensen, Stefan Hein Bengtson, Simon Bøgh
亮点:针对自动驾驶实验室(SDL)场景,开发移动机械臂系统并进行运动学分析,基于Denavit-Hartenberg(DH)公约建立运动学模型并求解逆运动学。集成先进视觉算法,结合基于特征的检测与单应性驱动的姿态估计,利用深度信息实现3D空间中物体姿态的2D平面投影表示,支持动态抓取和跟随任务,提升机械臂对纹理物体的可靠抓取能力。

论文:https://arxiv.org/abs/2510.19081
Comments:International Journal of Intelligent Robotics and Applications 2025
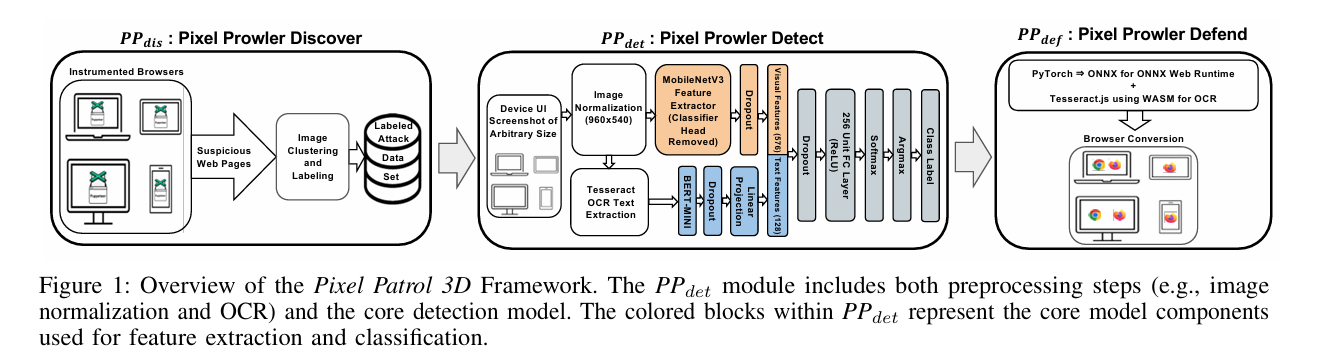
3、PP3D: An In-Browser Vision-Based Defense Against Web Behavior Manipulation Attacks
作者:Spencer King, Irfan Ozen, Karthika Subramani, Saranyan Senthivel, Phani Vadrevu, Roberto Perdisci
亮点:提出首个端到端浏览器框架PP3D,用于实时发现、检测和防御网页行为操纵攻击(BMA)。通过浏览器扩展部署视觉检测模型,在客户端运行以保护隐私,支持桌面和移动设备。评估显示检测率超99%(假阳性率1%), latency和开销表现良好,对训练后新收集的攻击样本仍保持97%以上的检测率。
论文:https://arxiv.org/abs/2510.18465
开源代码:https://github.com/NISLabUGA/PixelPatrol3D_Code
Comments:Appear in the Proceedings of the 41st Annual Computer Security Applications Conference (ACSAC 2025)