BERT 原理解析:从 Transformer 到双向语义理解
BERT 原理全解析:从 Transformer 到双向语义理解
一、前言:BERT 的革命性突破
在 BERT 出现之前,NLP 主要依靠:
词向量模型(Word2Vec、GloVe) —— 静态词向量;
RNN / LSTM 模型 —— 处理顺序信息但计算慢;
单向语言模型(GPT、ELMo) —— 只能理解部分上下文。
而 BERT(Bidirectional Encoder Representations from Transformers) 的诞生改变了一切:
它首次让模型能在大规模语料上双向理解上下文语义,并通过预训练 + 微调(Pre-train & Fine-tune) 机制通吃各类 NLP 任务。
二、BERT 的技术核心:Transformer Encoder
1. Transformer 概览
BERT 基于 Transformer 编码器(Encoder) 堆叠而成。
Transformer 由 Vaswani 等人在 2017 年提出,核心是 Self-Attention 自注意力机制。
Transformer 的优势:
完全抛弃循环结构(RNN),支持并行训练;
捕捉全局依赖;
结构模块化,可扩展性强。
2. BERT 模型结构图(简化)
输入序列:[CLS] 我 喜欢 自然语言处理 [SEP]→ 词嵌入 + 位置编码 + 句段编码
→ 多层 Transformer Encoder
→ 输出上下文表示(每个词一个向量)[CLS] 向量 → 用于分类任务
BERT-base 模型包含:
12 层 Transformer Encoder;
每层有 12 个自注意力头;
隐藏层维度为 768;
参数量约 1.1 亿。
三、BERT 的输入表示机制
BERT 的输入不仅是词,而是三类嵌入向量的组合:
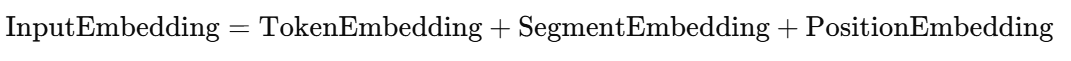
1. Token Embedding(词向量)
将每个 token(词或子词)映射为一个固定维度的向量。
2. Segment Embedding(句段向量)
用于区分句子 A 和句子 B(如在问答、句子对任务中)。
| 句子 | Segment ID |
|---|---|
| [CLS] 我喜欢学习 [SEP] | 0 |
| 因为知识能改变命运 [SEP] | 1 |
3. Position Embedding(位置向量)
Transformer 不具备顺序信息,因此要通过位置编码(Positional Encoding)提供位置信息。
位置编码可分为:
固定编码(sin/cos):Transformer 原版;
可学习编码(Learnable):BERT 采用的版本。
四、BERT 的自注意力机制(Self-Attention)
1. 自注意力的动机
传统的 RNN/LSTM 只能逐步处理序列,难以捕捉远距离依赖。
而 Self-Attention 能让每个词直接与句中所有词建立联系。
例如:
句子:她说苹果很好吃。
在理解“她”时,模型可以直接关注“说”;理解“好吃”时可以关注“苹果”,无需逐步传递。
2. Attention 的数学原理
每个词的表示由三个向量组成:
Query(Q):当前词的查询向量;
Key(K):所有词的键向量;
Value(V):所有词的值向量。
注意力计算公式为:
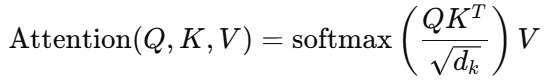
其中:
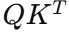 :计算相似度;
:计算相似度;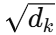 :缩放因子防止梯度爆炸;
:缩放因子防止梯度爆炸;softmax:归一化得到注意力权重;
结果是当前词对所有词的加权平均。
3. 多头注意力(Multi-Head Attention)
单个注意力头可能只学习到一种语义关系,为了让模型同时学习多种语义依赖,Transformer 使用了 多头注意力:
![]()
每个头的 ( Q, K, V ) 都是通过不同的线性变换得到的。
五、BERT 的双向特性与 MLM 原理
1. 单向语言模型的局限
传统语言模型只能从左到右或右到左预测下一个词。
比如:
我今天很 [MASK]
若模型只能看到“我今天很”,则无法利用右边“开心”这样的信息。
2. 双向训练的挑战
若模型同时看到左右上下文,它可能“作弊”直接记住词本身。
BERT 采用 Masked Language Model(MLM) 来避免这个问题。
3. Masked Language Model (MLM) 机制
BERT 训练时会随机遮盖 15% 的 token:
| 类型 | 比例 | 示例 | 说明 |
|---|---|---|---|
[MASK] 替换 | 80% | 我今天[MASK]好 | 用 [MASK] |
| 随机词替换 | 10% | 我今天学习好 | 替换成随机词 |
| 不变 | 10% | 我今天很 | 不替换,保持上下文一致 |
模型需要预测被遮盖的原始词,从而学会根据上下文推理。
4. 下一句预测(Next Sentence Prediction, NSP)
为学习句子间关系,BERT 加入了 NSP 任务:
输入:句子对 (A, B)
输出:B 是否为 A 的下一句(二分类)
举例:
正样本:“我喜欢机器学习。” → “因为它很有趣。”
负样本:“我喜欢机器学习。” → “今天天气真好。”
通过 NSP,模型学习句间逻辑和语篇连贯性。
六、[CLS] 表示与梯度流向
在输入的首位添加 [CLS](classification)标记。
经过 Transformer 编码后,[CLS] 的输出向量会聚合整个句子的语义信息。
在分类任务中,梯度从输出层沿着 [CLS] 的通道反向传播,最终影响整句的编码权重,使 [CLS] 成为“句子级别表示向量”。
七、BERT 的训练流程(总体框架)
预训练阶段(Pre-training)
使用海量语料(BooksCorpus + Wikipedia)
任务:MLM + NSP
输出:通用语言理解模型
微调阶段(Fine-tuning)
将预训练模型加载到下游任务中
添加少量任务特定层(如分类头)
小规模任务数据训练即可
这种两阶段设计让 BERT 能在各类 NLP 任务中快速迁移,效果惊人。
八、从梯度传播角度理解 BERT 的强大
BERT 的优势在于:
Transformer 的多层非线性结构能捕捉不同层次语义;
注意力层的梯度能在任意两个词之间直接传播;
MLM 训练强迫模型理解双向依赖;
NSP 训练促进跨句信息的建模。
梯度在整个 Transformer 中流动时,能够动态地学习“语义共现”关系,从而形成深层语义表征。
九、BERT 的改进与衍生模型
| 模型 | 关键改进 | 特点 |
|---|---|---|
| RoBERTa | 去除 NSP、使用更大 batch、更长训练 | 性能显著提升 |
| ALBERT | 参数共享 + 因式分解嵌入矩阵 | 参数量减少 80% |
| DistilBERT | 知识蒸馏压缩 | 更轻量、更快 |
| ERNIE(百度) | 融入知识图谱实体信息 | 中文理解更强 |
| MacBERT | MLM 改进为“近义词替换”策略 | 更贴近语义预测 |
| SpanBERT | 随机 mask 整个短语 span | 改善句法理解 |
十、BERT 的局限性与未来方向
| 问题 | 说明 |
|---|---|
| 训练成本高 | 预训练需巨大算力(TPU 级别) |
| 静态长度限制 | 输入序列最大 512 |
| 推理慢 | 多层 Transformer 堆叠导致延迟高 |
| 缺乏生成能力 | 只能理解,不能生成文本 |
为此,后续模型如 T5、GPT、BART 采用 Encoder-Decoder 或 Decoder-only 架构,实现理解与生成的统一。
十一、总结
BERT 的革命性意义:
首次实现了双向语义建模;
创造了“预训练 + 微调”范式;
极大推动了 NLP 的工业落地;
成为后续所有大模型(GPT、ChatGPT)的奠基。
一句话总结:
BERT 是 NLP 的“语言理解引擎”,
它让模型第一次真正学会了“读懂”句子。