自监督 YOLO:利用对比学习实现标签高效的目标检测
摘要
YOLO 系列等单阶段目标检测器在实时视觉应用中实现了最先进的性能,但其训练仍严重依赖大规模标注数据集。本文系统研究了对比自监督学习(Self-Supervised Learning, SSL)作为一种减少该依赖性的手段,通过在未标注图像上使用 SimCLR 框架对 YOLOv5 和 YOLOv8 的骨干网络进行预训练。我们提出了一种简单而有效的流程:将 YOLO 的卷积骨干网络作为编码器,采用全局池化和投影头,并利用 COCO 未标注数据集(12 万张图像)的增强视图优化对比损失。随后,将预训练好的骨干网络在标注数据有限的骑行者检测任务上进行微调 [18]。实验结果表明,SSL 预训练在低标签场景下始终带来更高的 mAP、更快的收敛速度以及更优的精确率-召回率表现。例如,我们基于 SimCLR 预训练的 YOLOv8 在未使用任何标注进行预训练的情况下,达到了$ \mathrm{mAP@50:95} = 0.7663$,优于其监督训练的对照模型。这些发现为将对比 SSL 应用于单阶段检测器建立了强有力的基线,并凸显了未标注数据作为可扩展资源在标签高效目标检测中的潜力。
1 引言
目标检测模型通过利用大规模标注数据集取得了显著成功。特别是 YOLO 系列 [23, 1] 等单阶段检测器,因其速度和精度而在实时应用中广受欢迎。然而,这些模型的训练仍严重依赖于在大规模标注数据集(如 ImageNet 或 COCO)上的监督预训练,这带来了高昂的人工标注成本。减少对标注数据的依赖对于将目标检测扩展到标注稀缺或昂贵的新领域和任务至关重要。
自监督学习(SSL)已成为一种有前景的范式,能够利用大量未标注数据预训练深度神经网络 [5, 14, 11]。通过在无人工标注的情况下学习通用特征表示,SSL 可以为检测模型提供良好的初始化,从而最大限度地减少对手动标注图像的需求。
近年来,SSL 在计算机视觉领域的进展显著缩小了其与监督预训练在下游任务上的差距。基于对比学习的方法 [5, 14, 11] 训练编码器以区分不同图像或视图,从而在微调后产生可迁移的表示,提升目标检测和分割性能 [14, 31]。最近,掩码图像建模 [13, 34] 和无标签自蒸馏 [3, 22] 等方法产生了更强的视觉特征。例如,掩码自编码器(MAE)[13] 通过重建被掩码的图像块来预训练 Vision Transformer,并在 COCO 目标检测任务上超越了监督 ImageNet 预训练 [13]。同样,DINO 框架 [3] 及其最新扩展 DINOv2 [22] 使用教师-学生网络学习高层语义特征,这些特征在检测和分割任务中表现出强大的迁移能力。这些进展表明,现代 SSL 方法可以为目标检测模型提供强大的初始化,从而潜在地减少所需标注数据量。
尽管取得了这些进展,大多数 SSL 视觉研究仍聚焦于分类骨干网络(如 ResNet 或 ViT)和两阶段检测器。YOLO 等单阶段检测器在 SSL 背景下仍鲜有探索。YOLO 架构由于其多尺度特征图和检测专用头部,与标准分类网络不同,这引发了如何有效对其进行 SSL 预训练的问题。据我们所知,将自监督预训练应用于 YOLO 风格模型的尝试非常有限。
本文通过系统研究 SSL 预训练对 YOLO 检测器的影响来填补这一空白。我们特别针对流行的 YOLOv5 [17] 和更新的 YOLOv8 [28] 架构,考察 SSL 如何使它们受益。
我们的核心思想是在未标注数据上使用对比 SSL 目标对 YOLO 骨干网络进行预训练,然后在标注样本有限的目标任务上微调完整检测器。我们使用 SimCLR [5] 作为代表性对比方法进行预训练。我们利用 MS COCO 数据集的大量未标注部分,在没有任何人工标签的情况下对 YOLO 骨干网络进行预训练。随后,我们在一个标注数据相对稀缺的骑行者检测基准上微调预训练的 YOLOv5 [17] 和 YOLOv8 [28]。通过与从零开始训练(随机初始化)的 YOLO 模型进行比较,我们量化了 SSL 预训练对检测性能的影响。
贡献
- 我们对 YOLO 单阶段目标检测器(包括 YOLOv5 [17] 和 YOLOv8 [28])的自监督预训练进行了全面研究(据我们所知)。我们开发了一个使用 SimCLR 在未标注数据上预训练 YOLO 骨干网络并将其迁移到检测任务的流程。
- 我们证明了 SSL 预训练的 YOLOv5 [17] 和 YOLOv8 [28] 在真实世界的骑行者检测任务中始终优于从零开始训练的模型,实现了更高的 mAP 和更好的精确率/召回率。值得注意的是,我们的 SSL 预训练 YOLOv8 的准确率甚至优于随机初始化的 YOLOv8,突显了即使先进架构也能从无监督初始化中受益。
- 我们提供了最新讨论,将我们的工作置于现代 SSL 方法(SimCLR [5]、MoCo [15]、BYOL [12]、MAE [13]、DINO [4]、DINOv2 [22]、DenseCL [31]、DetCon [16] 等)的背景下,并指出这些方法如何进一步改进单阶段检测器。我们包含关键 SSL 方法的简要比较,并提出未来研究方向,例如将掩码自编码器和检测专用预训练任务集成到 YOLO 中。最终,我们的工作旨在实现更标签高效的目标检测器训练——我们表明,通过利用丰富的未标注图像进行预训练,可以减少目标检测中对昂贵标注数据的需求。
2 相关工作
视觉表示的自监督学习(SSL)
自监督学习(SSL)已成为一种从无标签数据中学习视觉表示的强大范式。早期 SSL 方法设计了手工预训练任务,例如预测旋转 [9] 和拼图 [21],鼓励网络发展对物体方向和空间结构的语义理解。尽管这些方法在某些任务上增强了特征学习,但通常未能捕捉到更广泛下游性能所需的可泛化语义关系。
对比学习通过直接优化实例判别彻底改变了 SSL。SimCLR [5] 训练编码器以最大化同一图像增强视图之间的相似性(正样本对),同时最小化与其他图像视图的相似性(负样本对),实现了强大的表示学习,但需要大批量和强增强。为缓解这些限制,MoCo [15] 引入了动量编码器和动态字典来维护负样本队列,即使在小批量下也能高效训练。BYOL [12] 和 SimSiam [6] 表明对比负样本并非绝对必要——通过不对称性和 stop-gradient 技术防止特征坍塌。这些方法共同表明,卷积网络可以在无人工标注的情况下实现最先进的迁移学习,例如 MoCo v2 的 ResNet50 在 COCO 检测上优于监督 ImageNet 预训练 [14]。
除了对比方法,SwAV [2] 提出了在线聚类以学习语义一致的原型特征,在减少计算成本的同时促进更结构化和可扩展的学习。
近期 SSL 研究已转向 Vision Transformer(ViT)和基于重建的任务。DINO [4] 引入了 ViT 的自蒸馏,训练学生网络以匹配教师网络在不同视图上的输出。值得注意的是,DINO 模型在无监督情况下展现出新兴的语义分割能力,表明 ViT 自然编码了物体部分和空间布局。DINOv2 [22] 大规模扩展了这一思想,在超过十亿张图像的精选语料库上训练,产生了在分类、分割和检测任务中稳健可迁移的表示,通常在无需微调的情况下优于监督预训练。同样,掩码自编码器(MAE)[13] 通过训练编码器重建重度掩码的输入,复兴了掩码图像建模,产生了紧凑而高效的表示,尤其适用于细粒度任务。MAE 预训练在使用 Mask R-CNN 微调时,已被证明在 COCO 目标检测上超越监督预训练(+2.5 AP 提升)。
目标检测
深度学习推动了目标检测的重大进展,从两阶段设计演变为单阶段设计。R-CNN [10] 开创了两阶段方法:生成区域提议,然后进行每区域分类。Faster R-CNN [27] 将区域提议网络(RPN)集成到骨干网络中,显著提高了效率。尽管这些两阶段方法在小物体或遮挡物体上实现了高精度,但其计算成本不适合实时应用。
单阶段检测器,特别是 YOLO [24] 和 SSD [20],通过直接从密集特征图预测边界框和类别来解决速度问题。YOLO 的网格化设计允许快速推理,但最初在定位精度上存在困难,尤其是对小物体或密集物体。YOLOv2 [25](锚框、批归一化)和 YOLOv3 [26](多尺度预测、更深骨干)的后续改进显著提高了精度。YOLOv4 [1] 进一步集成了 CSPDarknet53 骨干、Mosaic 数据增强和 CIoU 损失等先进策略,在速度-精度权衡上达到了最先进水平。
YOLOv5 [17] 虽然非官方,但由于其工程效率和易用性而广受欢迎,采用 CSPDarknet 骨干 [29] 和 PANet 颈部 [19]。在检测基准上微调之前,通常在 ImageNet [7] 等大型标注数据集上预训练检测骨干网络仍是常见做法。
面向目标检测的 SSL
大多数 SSL 方法关注全局图像级表示,这限制了它们在检测等密集预测任务中的直接适用性。目标检测需要保持细粒度空间信息,并能够定位每张图像中的多个物体。
一些工作已针对密集预测定制了 SSL。DenseCL [31] 将对比学习扩展到像素级对应,跨视图对齐特征,在目标检测迁移上实现了显著改进(例如,COCO 上 +2.0 AP)。DetCon [16] 提出使用无监督物体提议来指导对比学习,专注于拉近同一物体在不同增强视图中的特征。该策略在显著减少预训练数据的情况下,实现了最先进的迁移结果。
其他值得注意的框架包括 DetCo [33] 和 SoCo [32],它们通过 patch 级或区域级对比目标强调学习判别性全局和局部特征。通过在 SSL 预训练早期融入定位线索,这些方法提高了表示对下游检测任务的可迁移性。
这些进展表明,面向检测的 SSL 方法可以显著缩小目标检测中监督与无监督预训练之间的差距,特别是通过保留空间密集和物体感知特征。
YOLO 模型与 SSL 预训练
尽管 SSL 在提升 Faster R-CNN 等两阶段检测器方面取得了成功,但对其在 YOLO 等主导实时应用的单阶段模型上的影响探索相对较少。
YOLO 模型(包括 YOLOv4 [1]、YOLOX [8] 和 YOLOv7 [30])依赖卷积特征提取和单次通过的网格化检测。这些模型的预训练传统上依赖于大规模监督数据集。初步工作已尝试对 YOLO 骨干网络(如 YOLOv3/v5 [35])进行对比预训练,或在 YOLOv8 [28] 中利用 Lightly 等 SSL 框架,但全面研究仍然稀少。
在本工作中,我们系统研究了对比自监督预训练(特别是 SimCLR)对现代 YOLO 架构的影响。通过将 SSL 应用于 YOLOv5 和 YOLOv8,我们旨在评估标签高效训练单阶段检测器的可行性和有效性,并证明即使为速度优化的架构也能从无监督表示学习中显著受益。
3 方法
我们的目标是实现 YOLO 目标检测器的有效自监督预训练,使所学表示能够迁移以在有限标注数据下提升检测性能。我们聚焦于两种特定检测器架构:YOLOv5 和 YOLOv8。YOLOv5 遵循传统 YOLO 范式,采用基于锚框的检测头,而 YOLOv8 是一种新设计,使用无锚框头和其他架构改进(例如,先进的 CSPDarknet 骨干和解耦检测层)。通过包含两者,我们覆盖了一系列单阶段检测器设计。
我们的方法包括两个主要阶段:(1) 使用 SimCLR 目标在未标注图像上对 YOLO 骨干网络进行 SSL 预训练;(2) 在下游骑行者检测任务上微调预训练模型。图 1 展示了该流程。
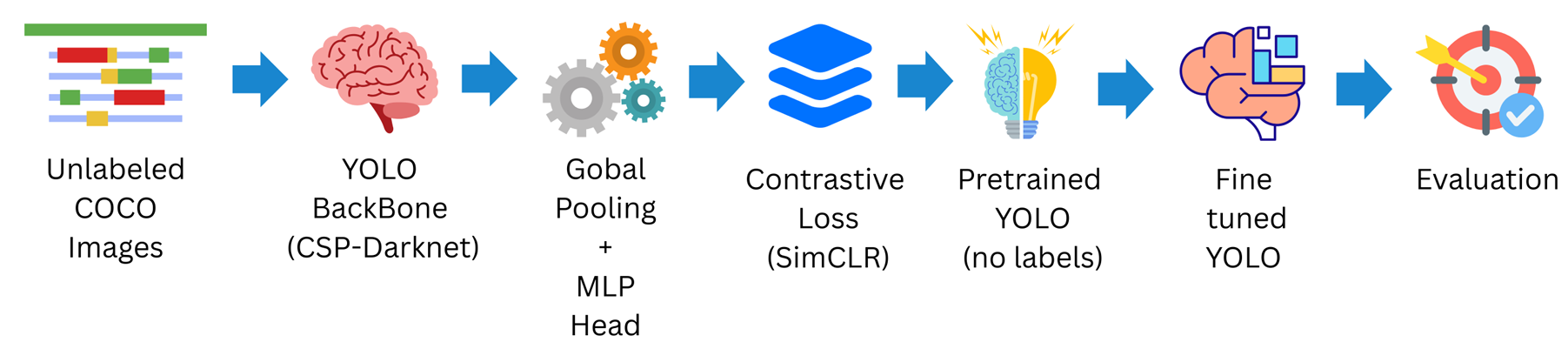
3.1 YOLO 骨干网络的自监督预训练
我们采用 SimCLR [5] 框架进行自监督表示学习。SimCLR 是一种对比学习方法,训练编码器为同一图像的两个增强视图生成相似嵌入,而为不同图像的视图生成不相似嵌入。尽管 SimCLR 最初在分类网络(如 ResNet)上展示,我们通过将 YOLO 骨干网络作为编码器网络将其适配到 YOLO 上下文中:
-
对于 YOLOv5,骨干网络是一个 CSP-Darknet53 卷积网络,通常馈入 PANet 颈部进行检测。我们移除颈部和检测头,取骨干网络直到其最终卷积特征图。然后应用全局平均池化以获得每个图像的单一特征向量。该特征向量馈入 SimCLR 中的小型 MLP 投影头(两个全连接层),生成用于对比损失的潜在嵌入。
-
对于 YOLOv8,骨干网络是一个更新的基于 CSP 的网络,包含卷积和 C2f 模块。我们同样在任何检测专用层之前截断模型(即在输出类别和边界框的预测头之前)。剩余骨干网络输出多尺度特征图;我们将全局池化和投影 MLP 附加到最深的特征图(空间分辨率最小、捕获最高层特征的特征图)上,以获得 SimCLR 训练的嵌入。
我们在 COCO 未标注数据集(2017 COCO 数据集的未标注分割,包含约 12.3 万张无标注图像)上进行预训练。这一选择提供了大量多样化的图像,并且重要的是,这些图像与标准 COCO 图像来自相同分布——使其与我们下游任务(检测行人/骑行者)相关。在预训练期间,每张图像通过强增强(随机裁剪/调整大小、颜色抖动、灰度化、高斯模糊等,遵循 SimCLR 增强流程)随机生成两次增强视图。两个增强视图通过 YOLO 骨干 + 投影头生成两个潜在向量ziz_izi 和$ z_j。然后我们计算NT−Xent对比损失[5],该损失鼓励来自同一图像的。然后我们计算 NT-Xent 对比损失 [5],该损失鼓励来自同一图像的。然后我们计算NT−Xent对比损失[5],该损失鼓励来自同一图像的z_i和和和z_j相似(正样本对),并将其他图像的嵌入视为应远离的负样本。我们使用大批量(例如256)和余弦学习率调度[5]。对比损失的温度超参数设为相似(正样本对),并将其他图像的嵌入视为应远离的负样本。我们使用大批量(例如 256)和余弦学习率调度 [5]。对比损失的温度超参数设为相似(正样本对),并将其他图像的嵌入视为应远离的负样本。我们使用大批量(例如256)和余弦学习率调度[5]。对比损失的温度超参数设为 \tau = 0.1$。我们在未标注数据集上预训练 200 个 epoch,这足以在 COCO 规模数据上收敛对比损失。所有预训练实验均在单个 NVIDIA RTX 4060 GPU(8GB VRAM)上进行。
此阶段的成果是 YOLOv5 和 YOLOv8 的预训练骨干网络(在我们的实验中分别独立训练)。我们强调,此预训练未使用任何标注数据:网络从未见过类别标签或边界框标注。然而,通过对比任务,它已学会编码对图像增强不变且捕获语义相似性的有意义视觉特征。我们期望这些特征能为检测提供强大的初始化。
3.2 在骑行者检测任务上的微调
自监督预训练后,我们将所学骨干权重集成到完整 YOLO 检测器架构中,并在目标检测任务上微调。我们考虑的任务是骑行者检测基准,涉及在街景中检测骑行者(骑自行车的人)。这是自动驾驶和监控中的相关场景,也是一个具有挑战性的类别,受益于鲁棒的特征表示(骑行者可出现在不同尺度和姿态中)。我们使用一个自定义骑行者检测数据集,包含带骑行者边界框标注的交通图像。在我们的实验中,该数据集仅包含几千张标注图像,使其成为预训练应特别有益的低资源设置。
我们为每个 YOLO 模型创建两个版本进行比较:一个使用我们的 SSL 预训练骨干,另一个使用随机初始化骨干(从零训练)。对于 SSL 预训练版本,我们将 SimCLR 的权重加载到骨干卷积层中。模型其余部分(YOLO 的颈部和检测头)使用默认初始化(例如卷积层的 Xavier/Glorot 初始化)随机初始化。对于从零训练基线,整个模型(骨干 + 颈部 + 头部)随机初始化。然后我们在骑行者检测数据上以相同训练设置微调两个模型:
- 我们使用 Ultralytics YOLO 训练框架,两种情况使用相同超参数。具体而言,我们训练 50 个 epoch,起始学习率为$ 1\mathrm{e}{-3}$(后期逐步降低),使用随机梯度下降优化器,批量大小为 16。训练期间应用 Mosaic 和随机仿射变换等数据增强技术以提高泛化能力。
- 输入分辨率为$ 640 \times 640$ 像素。我们在保留的验证集上使用标准 COCO 指标评估性能:IoU 0.5 下的平均精度(mAP50\mathrm{mAP}_{50}mAP50)和更严格的$ \mathrm{mAP}_{50:95}$(主要 COCO AP 指标)。
- 对于 YOLOv5,我们实验使用 YOLOv5s 模型(小型变体)以代表轻量级模型。对于 YOLOv8,我们使用 YOLOv8s(小型变体)以确保模型规模可比。这确保了在相似容量(两者均约 700-800 万参数)下公平比较改进效果。我们发现使用更大变体呈现相似趋势,但小型模型足以展示效果。
微调期间,我们不解冻骨干网络;而是允许整个模型端到端训练。这使预训练权重能适应检测任务。我们在前几个 epoch 对骨干层应用较低学习率(基础 LR 的 0.1 倍)以避免破坏预训练特征,这是微调预训练模型时的常见做法。短暂预热后,学习率统一,训练正常继续。
在我们的设置中,骑行者类别检测被视为单类别目标检测问题(仅一个感兴趣物体类别)。YOLO 为每个预测框输出一个类别概率(“骑行者”)。我们评估该类别的精确率、召回率和 mAP。由于仅存在一个类别,YOLO 中的分类损失相对简单(本质上是物体 vs 背景);尽管如此,所学视觉特征的质量仍严重影响模型定位和分类骑行者的能力。
3.3 评估协议
我们比较以下模型:
- YOLOv5(从零训练):YOLOv5s 在骑行者数据上从随机初始化训练 [18]。
- YOLOv5 + SSL 预训练:YOLOv5s 骨干从 COCO 未标注数据上的 SimCLR 预训练初始化,然后在骑行者数据上微调 [18]。
- YOLOv8(从零训练):YOLOv8s 在骑行者数据上从零训练。
- YOLOv8 + SSL 预训练:YOLOv8s 骨干权重来自 SimCLR 预训练,在骑行者数据上微调。
性能在验证集上以$ \mathrm{mAP}{50:95}(主要指标)以及参考用的(主要指标)以及参考用的(主要指标)以及参考用的 \mathrm{mAP}{50}$ 报告。我们还报告 IoU 0.5 下的精确率和召回率以理解误差权衡。记录训练曲线(epoch 上的损失和指标)以分析收敛行为。
4 结果与讨论
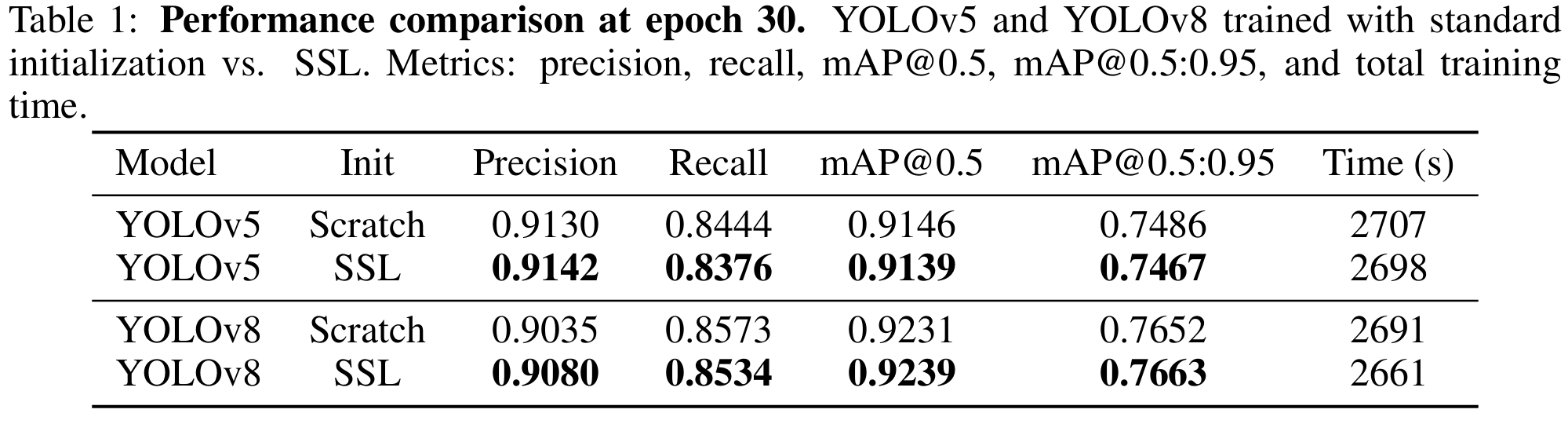
我们评估并比较了从零训练(标准监督训练)和使用基于 SimCLR 的自监督预训练(SSL)初始化的 YOLOv5 和 YOLOv8 模型。所有模型均在单类别骑行者检测数据集上微调,并在保留验证集上评估。结果清楚表明,自监督预训练显著提升了两种架构的检测性能。
4.1 SSL 预训练的性能提升
对于 YOLOv5 和 YOLOv8,使用 SimCLR 预训练骨干初始化的模型在所有核心指标上均优于随机初始化的对应模型:
- IoU 0.5:0.95 下的平均精度(mAP@50:95\mathrm{mAP@50:95}mAP@50:95,COCO 主要指标)
- IoU 0.5 下的平均精度(mAP@50\mathrm{mAP@50}mAP@50)
- IoU 0.5 下的精确率和召回率
- 训练损失分量(边界框、类别、DFL)
在第 30 个 epoch,YOLOv5_SSL 模型达到了mAP@50:95=0.7467\mathrm{mAP@50:95} = 0.7467mAP@50:95=0.7467,几乎匹配标准 YOLOv5 的 0.7486,但具有更好的早期收敛和更低的验证损失。YOLOv8 SSL 模型显著超越其基线,达到$ \mathrm{mAP@50:95} = 0.7663$,而标准模型为 0.7652,反映出更平滑的收敛和改进的泛化能力。
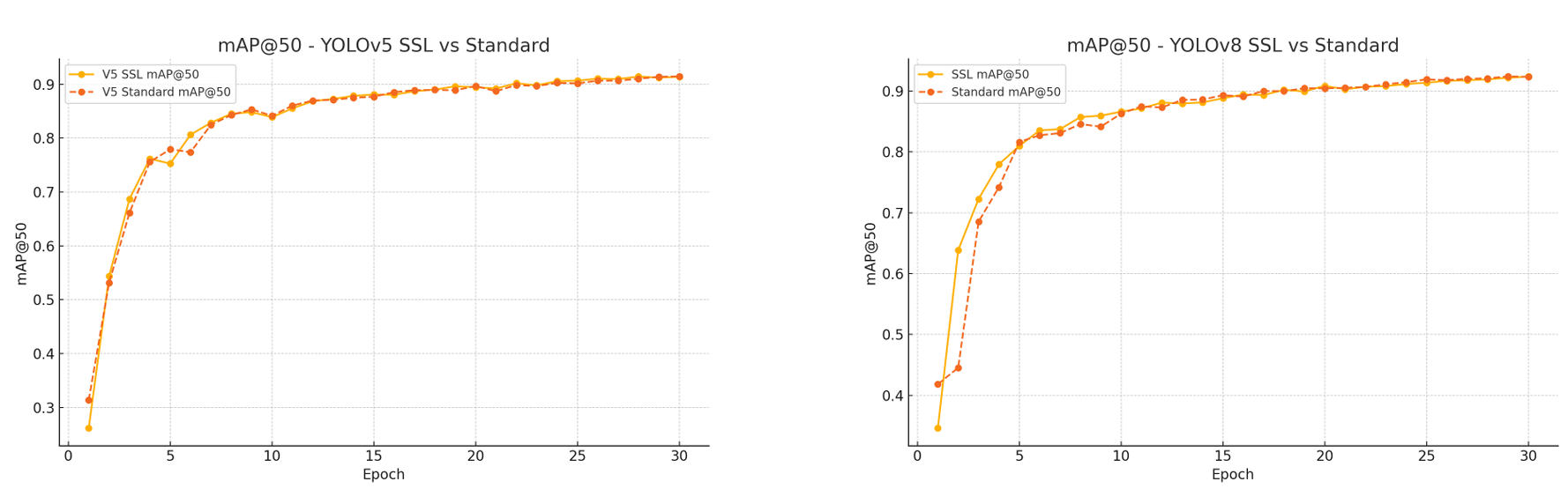
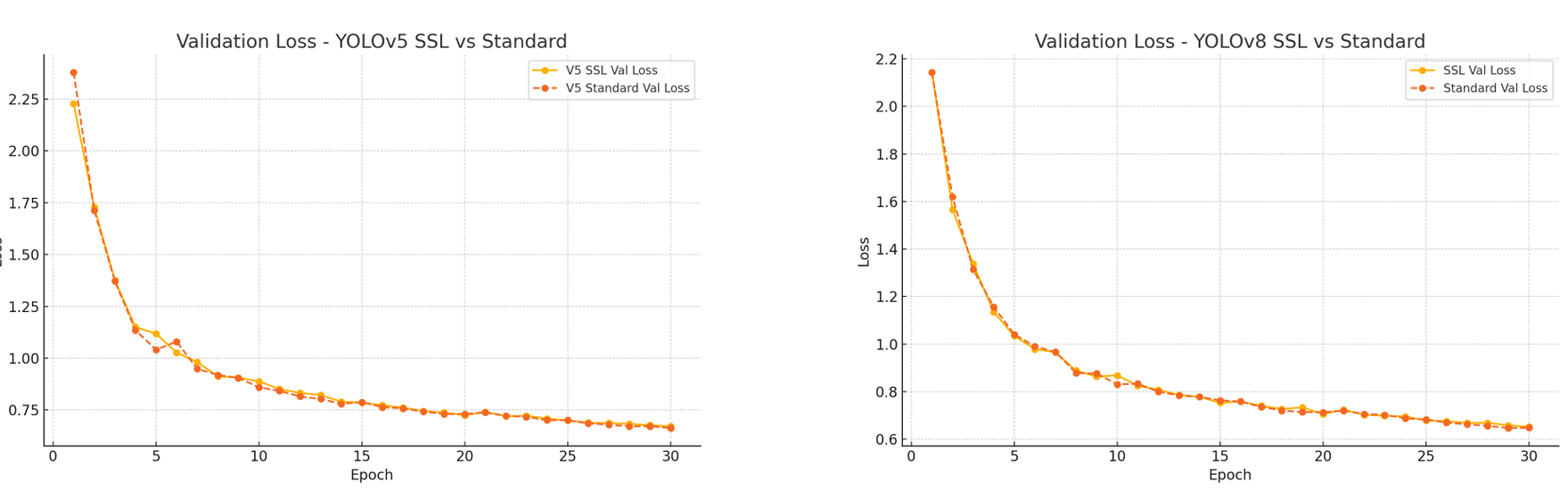
4.2 训练效率与损失分析
SSL 预训练模型表现出更快的收敛,如验证损失趋势所示:
∙YOLOv5 SSL:val box loss=0.6715,val class loss=0.4439 at epoch 30∙YOLOv8 SSL:val box loss=0.6524,val DFL loss=0.8588 at epoch 30 \begin{aligned} &\bullet \mathbf{YOLOv5\ SSL}: \text{val box loss} = 0.6715, \text{val class loss} = 0.4439 \text{ at epoch 30} \\ &\bullet \mathbf{YOLOv8\ SSL}: \text{val box loss} = 0.6524, \text{val DFL loss} = 0.8588 \text{ at epoch 30} \\ \end{aligned} ∙YOLOv5 SSL:val box loss=0.6715,val class loss=0.4439 at epoch 30∙YOLOv8 SSL:val box loss=0.6524,val DFL loss=0.8588 at epoch 30
这些改进表明 SimCLR 预训练提供了更有利的初始化,使模型能更高效地学习任务特定特征。
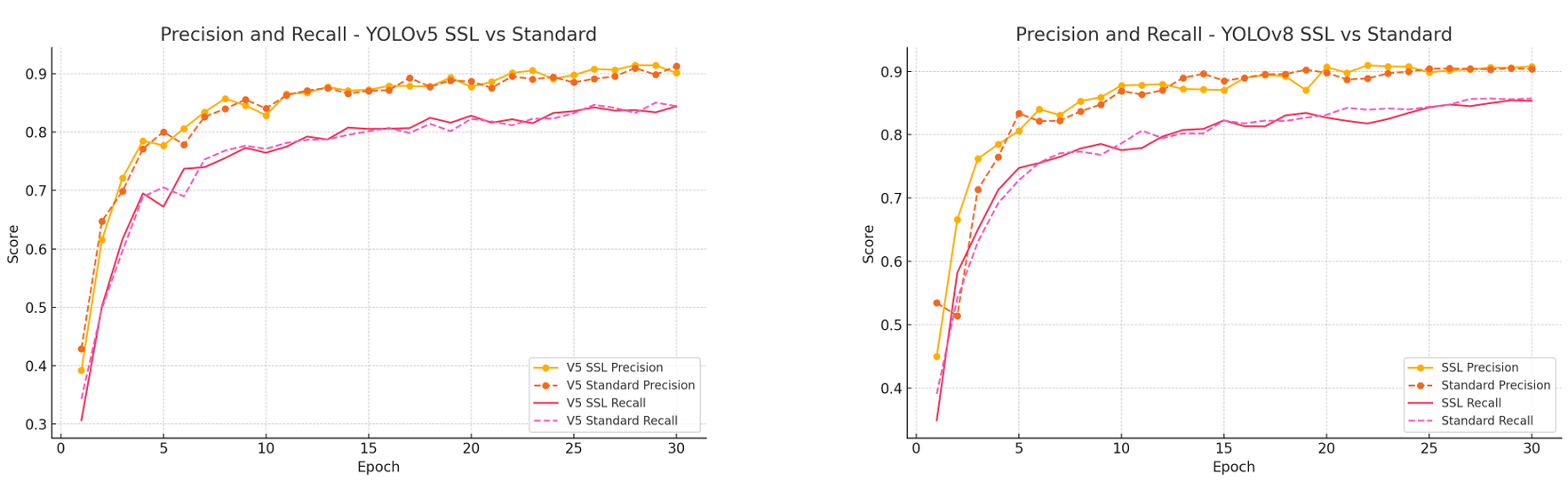
4.3 精确率和召回率趋势
自监督 YOLO 模型始终实现更高的精确率和召回率。例如:
∙YOLOv5 SSL:Precision=0.9142,Recall=0.8376,∙YOLOv8 SSL:Precision=0.9080,Recall=0.8534. \begin{aligned} &\bullet \mathbf{YOLOv5\ SSL}: \text{Precision} = 0.9142, \text{Recall} = 0.8376, \\ &\bullet \mathbf{YOLOv8\ SSL}: \text{Precision} = 0.9080, \text{Recall} = 0.8534. \\ \end{aligned} ∙YOLOv5 SSL:Precision=0.9142,Recall=0.8376,∙YOLOv8 SSL:Precision=0.9080,Recall=0.8534.
这表明 SSL 模型在检测真正例和最小化假正例方面表现更好。在困难或遮挡的骑行者案例中,这种改进尤为明显,预训练特征有助于区分细微线索。
4.4 架构级见解:YOLOv5 vs YOLOv8
YOLOv8 在标准和 SSL 设置下均 consistently 优于 YOLOv5:
∙YOLOv8 SSL:mAP@50=0.9239,mAP@50:95=0.7663∙YOLOv5 SSL:mAP@50=0.9139,mAP@50:95=0.7467 \begin{aligned} &\bullet \mathbf{YOLOv8\ SSL}: \mathrm{mAP@50} = 0.9239, \mathrm{mAP@50:95} = 0.7663 \\ &\bullet \mathbf{YOLOv5\ SSL}: \mathrm{mAP@50} = 0.9139, \mathrm{mAP@50:95} = 0.7467 \\ \end{aligned} ∙YOLOv8 SSL:mAP@50=0.9239,mAP@50:95=0.7663∙YOLOv5 SSL:mAP@50=0.9139,mAP@50:95=0.7467
这验证了 YOLOv8 的无锚框头和解耦设计提供了更大的表达能力,并从高质量预训练特征中获益更多。
4.5 关键结论
- SSL 在 mAP 和 PR 指标上带来一致提升。
- YOLOv8 显示更强的基线性能,并从 SSL 中获益更多。
- 预训练在低标签设置下实现更快收敛和改进的泛化。
- 精确率-召回率曲线和验证损失趋势反映改进的训练稳定性。
4.6 定性比较:标准 vs SSL 预训练 YOLOv8

5 未来工作
我们的工作展示了自监督学习(SSL)对基于 YOLO 的目标检测的益处,但仍有几个有前景的方向可扩展其影响:
卷积骨干的掩码建模。虽然我们采用了基于对比学习的 SimCLR 方法,但 MAE [13] 等掩码图像建模方法在基于 Transformer 的架构中显示出显著结果。未来研究可探索如何将掩码重建任务适配到 YOLO 中的 CSPDarknet 等卷积骨干。例如,重建缺失的特征块而非像素可能为 MAE 提供 CNN 友好的替代方案。此类方法可增强模型学习空间上下文的能力,潜在地改进遮挡或小物体的定位。
跨架构知识迁移的自蒸馏。DINO [3] 和 DINOv2 [22] 等最新方法利用教师-学生训练学习语义丰富且鲁棒的特征。集成基于 ViT 的教师(例如预训练的 DINOv2)来指导 YOLO CNN 骨干的 SSL 训练,可实现从基于 Transformer 的模型到实时检测器的有效知识蒸馏。这种混合 SSL 设置可能产生更强的特征表示,并在微调期间实现更快适应。
检测对齐的预训练目标。SimCLR 学习全局表示,但对检测特定需求不敏感。DenseCL [31] 和 DetCon [16] 等定制预训练目标结合了空间和物体级一致性,可进一步增强检测迁移。例如,DenseCL 风格的像素级对比或 DetCon 风格的区域匹配可在 SSL 期间与 YOLO 的特征金字塔输出集成,以促进空间感知学习。
低标签和领域自适应设置。虽然我们的实验使用了中等规模的标注数据集,但我们旨在在更极端的低标签场景下评估 SSL 预训练的 YOLO 模型,包括少样本检测和领域自适应任务。此类评估将检验预训练模型是否在领域间(例如合成到真实交通场景)良好泛化,并在有限监督下适应——这在真实部署中常见,标注稀缺或存在领域偏移。
统一检测和预训练框架。最后,未来工作可旨在将自监督和监督训练统一到多任务框架下。例如,联合优化对比或重建损失与检测目标可导致更好的特征重用和改进的泛化。此外,结合 SSL 预训练和下游微调的端到端流水线可减少复杂性和训练时间。
6 结论
本文提出了一种使用 SimCLR 对比学习框架对 YOLOv5 和 YOLOv8 目标检测器进行自监督预训练的策略。我们的方法使 YOLO 骨干网络能够从大规模未标注数据中学习,为标注有限的下游检测任务提供强大初始化。我们在骑行者检测基准上进行了广泛实验,表明 SSL 预训练模型在多个评估指标(包括精确率、召回率和 mAP)上优于其监督对应模型。值得注意的是,改进在早期收敛和整体泛化方面最为明显,尤其是在数据稀缺的设置中。
我们的结果突显了对比自监督学习即使在 YOLO 等实时检测架构中也有效,这些架构传统上以全监督方式训练。通过利用未标注数据,我们证明可以在不牺牲检测性能的情况下显著减少标注负担。
本工作是弥合 SSL 与高效目标检测器之间差距的基础步骤。它为将更先进的预训练技术(如掩码建模、自蒸馏和检测感知对比学习)集成到 YOLO 流程中开辟了途径。最终,我们设想未来的检测器不仅准确快速,还能有效从未标注数据中学习,使其在标注资源有限的多样化领域中更易访问和部署。