用n8n工作流+DeepSeek大模型基于k8s做一个运维智能体
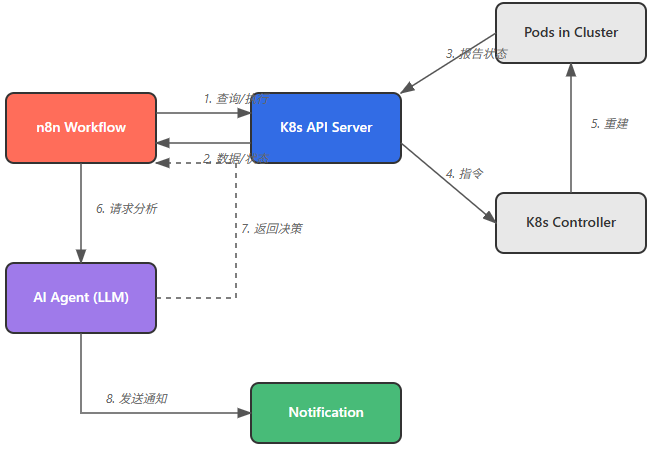
一、整体架构设计和思路
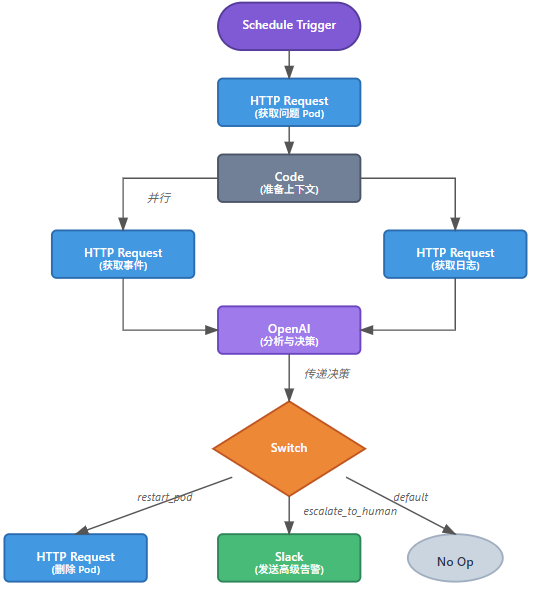
新的工作流增加了一个核心的 AI 分析模块。
1、监控: 定时获取所有非正常状态的 Pod。
2、数据收集: 对于发现的问题 Pod,不仅获取其基本信息,还要获取它的详细事件和日志。这是 AI 分析的关键上下文。
3、AI 分析: 将 Pod 的状态、事件和日志信息,打包成一个精心设计的提示词,发送给大语言模型(如 DeepSeek)。
4、智能决策: 要求 LLM 返回一个结构化的 JSON,包含根本原因分析和建议的操作(例如:"restart_pod", "escalate_to_human", "ignore")。
5、执行/通知: 根据 LLM 的建议执行相应操作:
如果建议
restart_pod,则删除 Pod。如果建议
escalate_to_human,则发送包含 AI 分析结果的高级告警给运维人员。如果建议
ignore,则记录日志并结束流程。
二、n8s中构建工作流
节点 1: Schedule Trigger (定时触发器)
这是工作流的入口。
节点类型: Schedule Trigger
配置: 设置触发间隔,例如 Every Minute,这样智能体就会每分钟检查一次。
节点 2: HTTP Request (获取所有问题 Pod)
这个节点负责调用 K8s API,获取所有非正常状态的 Pod。
节点类型:
HTTP Request
配置:
1)Method: GET
2)URL: https://your-k8s-api-server/api/v1/pods
your-k8s-api-server是你的 K8s 集群 API Server 地址。如果 n8n 运行在集群内,可以使用kubernetes.default.svc。
3)Authentication: Generic Credential Type -> Header Auth
Name:
Authorization
Value:
Bearer YOUR_SERVICE_ACCOUNT_TOKEN(粘贴上一步获取的 Token)
4)Query Parameters:
fieldSelector:status.phase!=Running,status.phase!=Succeeded这个参数是关键,它只返回状态不是
Running和Succeeded的 Pod,大大减少了需要分析的数据量。
5)Options:
Reject Unauthorized: 取消勾选 (如果你的 K8s API 使用自签名证书)。
节点 3: Code (准备上下文)
这个节点是数据准备的关键。它从第一个问题 Pod 中提取 name 和 namespace,供后续节点使用。
节点类型:
Code模式: Run Once for All ItemsJavaScript 代码:
// 找到第一个处于 CrashLoopBackOff 状态的 Podconst pods = $input.all().map(item => item.json).filter(pod => {if (pod.status && pod.status.containerStatuses) {return pod.status.containerStatuses.some(container =>container.state && container.state.waiting && container.state.waiting.reason === 'CrashLoopBackOff');}return false;});if (pods.length > 0) {const pod = pods[0];return [{json: {podName: pod.metadata.name,podNamespace: pod.metadata.namespace,podDetails: pod // 保存完整的 Pod 信息}}];} else {// 如果没有问题 Pod,返回空数组,工作流将在此停止return [];}
节点 4: HTTP Request (获取 Pod 事件)
获取 Pod 的事件,这通常包含了错误原因(如镜像拉取失败、被 Liveness 探针杀死等)。
节点类型: HTTP Request
配置:
Method: GET
URL:https://your-k8s-api-server/api/v1/namespaces/{{ $json.podNamespace }}/events?fieldSelector=involvedObject.name={{ $json.podName }}
Authentication: 同节点2
节点 5: HTTP Request (获取 Pod 日志)
获取容器内部的日志,这是定位代码层面问题的直接证据。
节点类型:
HTTP Request配置:
Method: GET
URL: https://your-k8s-api-server/api/v1/namespaces/{{ $json.podNamespace }}/pods/{{ $json.podName }}/log
Authentication: 同节点2
节点 6: OpenAI (AI 分析与决策)
这是整个工作流的大脑。
节点类型:
OpenAI配置:
Credential: 创建你的 OpenAI API Key 凭证。
Model: DeepSeek (或其它性价比更高的模型,以降低成本)
Prompt Text: 这是核心!一个精心设计的 Prompt。
你是一位资深的 Kubernetes 运维专家。请分析以下处于 CrashLoopBackOff 状态的 Pod 信息,并提供根本原因和修复建议。**Pod 基本信息:**{{ $('Code').first().json.podDetails }}**Pod 事件:**{{ $json }}**Pod 日志:**{{ $('HTTP Request1').first().json }}请根据以上信息进行分析,并以严格的 JSON 格式返回结果,包含 `root_cause` 和 `suggested_action` 两个字段。- `root_cause`: 对问题的根本原因进行简洁、准确的描述。- `suggested_action`: 建议采取的操作,只能是以下三个值之一:- `restart_pod`: 如果问题是临时的,重启 Pod 可能解决。- `escalate_to_human`: 如果问题是配置错误、镜像问题或需要人工介入的复杂情况。- `ignore`: 如果问题不严重或可以自行恢复。返回的 JSON 示例:{"root_cause": "应用程序因缺少 'DATABASE_URL' 环境变量而无法启动。","suggested_action": "escalate_to_human"}
节点 7: Switch (智能路由)
根据 AI 的决策,将工作流路由到不同的分支。
节点类型:
Switch配置:
Rules:
Rule 1:
Value 1:
{{ $json.suggested_action }}Operation:
EqualValue 2:
escalate_to_human
Rule 2:Value 1:
{{ $json.suggested_action }}Operation:
EqualValue 2:
restart_pod
Default: (处理ignore或其他未预料到的值)
节点 8, 9, 10: 执行分支
节点 8 (连接到 Rule 1):
HTTP Request (Delete Pod)配置: 与之前相同,用于重启 Pod。
节点 9 (连接到 Rule 2):
Slack (发送高级告警)配置: 与之前类似,但消息内容更丰富,包含 AI 的分析结果。
节点 10 (连接到 Default):
No Op, do nothing配置: 空操作节点,用于结束工作流。
三、完整工作流概览