chp04【组队学习】Post-training-of-LLMs
文章目录
- 在线强化学习基础理论
- 语言模型中的强化学习:在线vs离线
- 在线学习(Online Learning)
- 离线学习(Offline Learning)
- 在线强化学习的工作机制
- 奖励函数的选择
- 训练好的奖励模型(Reward Model)
- 可验证奖励
- 两种主流的在线强化学习算法对比
- PPO(Proximal Policy Optimization) 近端策略优化
- GPRO(group relative policy optimization)
- KL散度
- 4_2 Online RL实践
- 加载评估数据集
- 数据后处理
- 模型加载与初次评估
- 评估结果
- 训练阶段
- 配置GRPO训练
- 启动训练
- 训练完成与现象
- 全量训练模型评估
- 结论与建议
- 实验探索与思考
在线强化学习基础理论
语言模型中的强化学习:在线vs离线
在线学习(Online Learning)
实时生成响应并不断学习
- 生成新的响应(Response)
- 获取对应的奖励(Reward)
- 使用这些响应与奖励来更新模型权重
- 模型持续学习并优化生成的响应
离线学习(Offline Learning)
模型只从预先收集的(prompt, response, reward)三元组中学习:
不会在训练过程中生成新的响应。
因此,当我们提到 “在线强化学习(Online RL)”时,通常指的是 在在线学习场景中应用的强化学习方法
在线强化学习的工作机制
在线强化学习通常让模型自主探索更好的响应。 其典型流程如下:
- 准备一批 Prompt(输入提示);
- 将这些 Prompt 输入语言模型;
- 模型生成对应的 Response;
- 将 (prompt, response) 对送入 奖励函数(Reward Function);
- 奖励函数为每对 (prompt, response) 打分;
- 获得 (prompt, response, reward) 三元组;
- 使用这些数据来更新语言模型。
模型更新可采用不同方法,本课重点介绍两种:
- PPO(Proximal Policy Optimization)
- GRPO(Group Relative Policy Optimization)
奖励函数的选择
在在线强化学习中,奖励函数的设计至关重要。常见有两种类型:
训练好的奖励模型(Reward Model)
- 收集多个模型响应,由人类进行偏好标注(选择更优的响应)。
- 使用这些人类偏好数据训练奖励模型。
- 奖励模型通过优化如下损失函数学习
L=log(σ(rj−rk))L = log(\sigma(r_j - r_k))L=log(σ(rj−rk))
其中
- 若人类认为响应j优于k,则鼓励模型提升rjr_jrj,降低rkr_krk
特点:
- 通常基于已有的Instruct模型初始化;
- 通过大规模人类或机器生成偏好数据训练
- 可应用于开放任务,如聊天能力,安全性提升等。
- 但在正确性导向的任务中可能不够精确。
可验证奖励
在“正确性导向”场景中,更推荐使用可验证奖励:
- 数学任务:验证模型输出是否与标准答案匹配
- 编程任务:通过单元测试检验代码执行结果是否正确。
特点: - 需提前准备真值或测试集
- 准备成本较高 ,但奖励信息更精确可靠。
- 更适合训练推理类模型,如代码、数学领域。
两种主流的在线强化学习算法对比
PPO(Proximal Policy Optimization) 近端策略优化
是第一个chatGPT所使用的强化学习算法
工作流程:
- 输入一组查询
- 通过策略模型生成响应。
- 响应被送入以下模块:
- 参考模型(Reference Model):计算KL散度,限制模型不偏离原始分布;
- 奖励模型(Reward Model):计算奖励。
- 价值模型(Value Model)或评论者模型(Critic Model):为每个Token分配价值。
- 使用广义优势估计(Generalized Advantage Estimation,GAE),计算每个Token的优势函数,反映该Token的贡献。
PPO 的目标函数
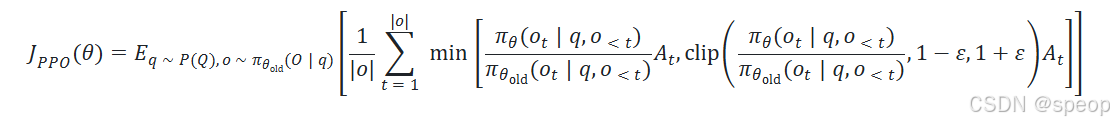
总结:
- 每个 Token 拥有独立的优势值;
- 反馈粒度更细;
- 但需额外训练价值模型 → 占用更多 GPU 内存。
GPRO(group relative policy optimization)
群体相对策略优化(GRPO)
GRPO 由 Deepseek 提出,用于优化大型语言模型的推理能力。
工作流程:
- 对每个 Prompt,模型生成多个响应(O1,O2,...,Og)(O_1,O_2,...,O_g )(O1,O2,...,Og);
- 对每个响应计算:
- 奖励((Reward)
- 与参考模型的 KL 散度;
- 对同一组(Group)响应计算相对奖励(Relative Reward);
- 将相对奖励作为整个响应的优势值;
- 使用此优势更新策略模型。
主要区别:
- 不再需要价值模型(Value Model);
- 所有 Token 在同一响应中共享相同优势值;
- 更节省显存,但优势估计较粗糙。
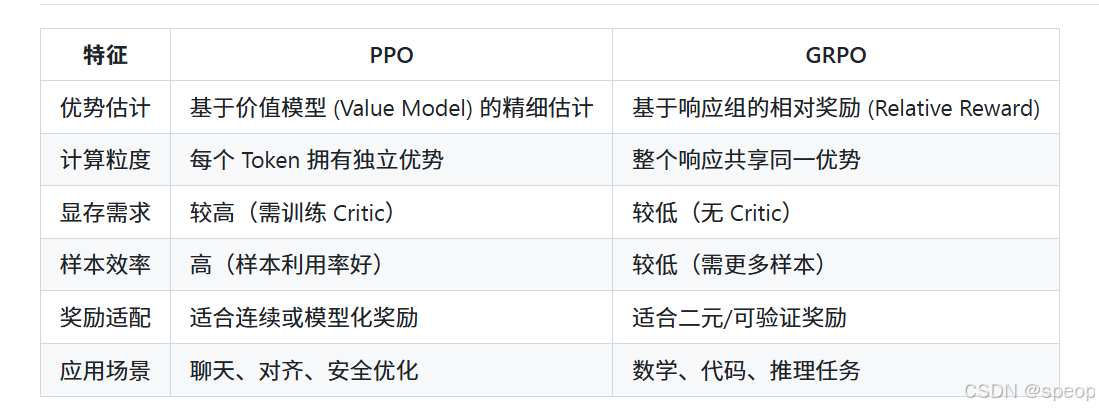
有无 Critic(评论者模型)

KL散度



- 在线强化学习(Online RL) 与 离线强化学习(Offline RL) 的区别;
- 奖励函数的两种设计方式:奖励模型 与 可验证奖励;
- 两种关键算法的机制与对比:PPO 与 GRPO
4_2 Online RL实践
针对分组相对策略优化(GRPO)——一种主流的在线强化学习方法。
如你所忆,在线强化学习旨在让模型自主探索更优回复。
在本实验中,我们将首先策划一组数学题目,(GSM8K数据集,下图)将其输入当前语言模型,并让模型生成多条回复;随后设计一个可验证奖励函数,用于检验回复是否与标准答案一致;由此获得〈提示,回复,奖励〉三元组,并利用 GRPO 更新语言模型。接下来让我们在代码中完整体验
import torch
from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM
from trl import GRPOTrainer, GRPOConfig
from datasets import load_dataset, Dataset
from helper import generate_responses, test_model_with_questions, load_model_and_tokenizer
import re
import pandas as pd
from tqdm import tqdm
此处与DPO/SFT类似,区别在于我们使用 HuggingFace 的 TRL 库中的 GRPOTrainer 与 GRPOConfig_来配置 GRPO 训练环境.
不同于前两节仅用少量示例提示测试,对于数学的评估数据集,本节将_使用 GSM8K 数学评测集_。首先设置 use_gpu=False;若在本机 GPU 上运行,可改为 True。还需设定系统提示(persistent prompt):
USE_GPU = FalseSYSTEM_PROMPT = ("You are a helpful assistant that solves problems step-by-step. ""Always include the final numeric answer inside \\boxed{}."
)
“你是一位乐于助人的助手,请逐步解题,并在最后用 \boxed{} 给出最终数值答案。”
该提示至关重要,可确保模型输出结构化,便于后续提取与比对。
如何定义一个奖励函数,用于评估模型生成结果与真实结果(ground truth)的匹配度
见于强化学习(RL)或模型评估场景(如 GSM8K 这类数学推理任务的评估)。
接下来定义_奖励函数_,这可能是有用且重要的适用于两种培训,使用o_RL_ 与 使用GSM8K 评估 。
需要模型生成的completions或者生成结果和ground_truth,所以我们在这里要做的是:我们首次尝试做正则表达式网格,去捕获盒内的内容,正如我们提供的那样,在系统提示的指令中。
在我们看到所有的matches,我们就拿到contents 和阿尔法退出模型。如果没有匹配,我们就让模型的输出在这里为空。接下来我们就直接比较一下具有基本事实的内容
- 从模型生成的completionscompletionscompletions中提取特定格式的内容(文中提到的\boxed{}包裹的内容,常见于数学题答案的格式化输出);
- 将提取的内容与ground_truth(真实答案)对比,给出奖励(匹配则奖励 1,否则奖励 0)。
正则表达式:
matches = [re.search(r"\\boxed\{(.*?)\}", completion[0]['content']) for completion in completions]
contents = [match.group(1) if match else "" for match in matches]
- 正则表达式r"\boxed{(.*?)}":用于匹配字符串中被\boxed{}包裹的内容。\boxed{}是 LaTeX 中用于给内容加框的语法,在这里作为 “答案区域” 的标记。
- \boxed{ 匹配字面量
\boxed{; (.*?)是非贪婪匹配,用于捕获\boxed{}内部的所有内容(即我们需要的答案);\}匹配字面量}
- \boxed{ 匹配字面量
- matchesmatchesmatches列表:对每个completioncompletioncompletion,用正则表达式搜索是否存在\boxed{}包裹的内容,返回匹配对象(无匹配则为None)。
- contentscontentscontents列表:从匹配对象中提取分组(即(.*?)捕获的内容),无匹配则记为空字符串""。
jcontents列表:从匹配对象中提取分组(即(.*?)捕获的内容),无匹配则记为空字符串""。
奖励函数逻辑
return [1.0 if c == gt else 0.0 for c, gt in zip(contents, ground_truth)]
- 遍历提取的contents和真实答案ground_truth,逐一对比:
- 若内容c与真实答案gt完全一致,奖励1.0;
- 否则奖励0.0。
- 最终返回一个奖励列表,每个元素对应一个completion的奖励值。
def reward_func(completions, ground_truth, **kwargs):# Regular expression to capture content inside \boxed{}去捕获盒内的内容的正则表达式matches = [re.search(r"\\boxed\{(.*?)\}", completion[0]['content']) for completion in completions]contents = [match.group(1) if match else "" for match in matches]# Reward 1 if the content is the same as the ground truth, 0 otherwisereturn [1.0 if c == gt else 0.0 for c, gt in zip(contents, ground_truth)]
具体步骤:
- 正则匹配提取 \boxed{}中的内容;
- 若匹配成功,取首项并去除字母;
- 若无匹配,则置输出为空。
随后直接比对提取结果与标准答案,这是一种二元的奖励函数:
- 一致 → 奖励 = 1
- 不一致 → 奖励 = 0
先测试奖励函数行为:
- 正例预测:72,GT=72→奖励=1\boxed{72},GT=72 → 奖励 = 172,GT=72→奖励=1
- 负例预测:71,GT=72→奖励=0\boxed{71},GT=72 → 奖励 = 071,GT=72→奖励=0
sample_pred = [[{"role": "assistant", "content": r"...Calculating the answer. \boxed{72}"}]]#这是一个模拟的模型预测结果#使用latex格式\boxed{72}来标记最终答案#前面的文字是解题过程
ground_truth = ["72"]
reward = reward_func(sample_pred, ground_truth)
#这个函数# 从sample_pred中提取答案(解析\boxed{}中的内容)# 与ground_truth比较#返回一个奖励函数
print(f"Positive Sample Reward: {reward}")#-------------------------------
sample_pred = [[{"role": "assistant", "content": r"...Calculating the answer \boxed{71}"}]]
ground_truth = ["72"]
reward = reward_func(sample_pred, ground_truth)
print(f"Negative Sample Reward: {reward}")
加载评估数据集
从 OpenAI GSM8K 加载测试集(test split)为加速演示,仅取前 5 条样本,并将 test_size 设为 5。该数据集总计包括1319条数据。
数据集包含:
- question:题干
- answer:原答案(含推理与最终数字)
需进一步提取答案中的数字作为 ground truth。
#定义要选取的样本数量
data_num = 5
#加载GSM8K数据集的测试集,并选取前data_num个样本
eval_dataset = load_dataset("openai/gsm8k", "main")["test"].select(range(data_num))
#将选取的数据集转换为pandas.DataFrame,方便展示和处理
#从测试集中选取前data_num(这里是 5)个样本,返回一个新的数据集对象。
sample_df = eval_dataset.to_pandas()
#在Jupyter Notebook等环境中可视化DataFrame内容
#将数据集转换为 Pandas 的DataFrame格式,便于用表格形式展示、筛选或进行数据预处理。
display(sample_df)
#在支持的环境(如 Jupyter Notebook)中以表格形式展示 DataFrame 内容,方便直观查看数据结构和样本内容。
如果我们需要进行随机样本的选取,可以使用一下代码
# Random select 20 example as the evaluate dataset# Define the number of examples to randomly select
num_examples_to_select = 20# Load the full test dataset
full_test_dataset = load_dataset("openai/gsm8k", "main")["test"]# Randomly select 20 examples
# You can use the 'shuffle' method and then 'select' the first N examples
eval_dataset = full_test_dataset.shuffle(seed=42).select(range(num_examples_to_select)) # Using a seed for reproducibility# Convert the selected dataset to a Pandas DataFrame for display or further use
eval_df = eval_dataset_random_20.to_pandas()# Display the head of the DataFrame to see the selected examples
print(f"Randomly selected {num_examples_to_select} examples for evaluation:")
display(eval_df)
数据后处理
定义后处理函数
- 利用
####分隔提取最终数字 - 构造提示:将系统提示与问题拼接
后处理后数据集仅含两列: - ground_truth:标准答案数字
- prompt:系统提示+问题
def post_processing(example):match = re.search(r"####\s*(-?\d+)", example["answer"])example["ground_truth"] = match.group(1) if match else Noneexample["prompt"] = [{"role": "system", "content": SYSTEM_PROMPT},{"role": "user", "content": example["question"]}]return example
eval_dataset = eval_dataset.map(post_processing).remove_columns(["question", "answer"])sample_df = eval_dataset.select(range(5)).to_pandas()
display(sample_df)
模型加载与初次评估
加载 Qwen2.5-0.5B-Instruct 模型,
#加载模型和分词器
model, tokenizer = load_model_and_tokenizer("./models/Qwen/Qwen2.5-0.5B-Instruct", USE_GPU)
#作用:从指定路径 ./models/Qwen/Qwen2.5-0.5B-Instruct 加载预训练模型(Qwen2.5-0.5B-Instruct)和对应的分词器。
#参数:USE_GPU 控制是否使用 GPU 加速(若为 True 则使用 GPU,否则使用 CPU)。
#返回:model 是加载的模型对象,tokenizer 是用于文本预处理(分词、编码)的工具。#初始化存储变量
all_preds = []
all_labels = []
#作用:创建两个空列表,分别存储模型的预测结果(all_preds)和数据集中的真实标签(all_labels)
for example in tqdm(eval_dataset):input_prompt = example["prompt"] # 获取样本中的提示词(包含系统指令和用户问题)ground_truth = example["ground_truth"] # 获取样本的真实标签
#为循环添加进度条,显示处理进度。
#input_prompt:从数据集中获取预处理后的提示词,用于引导模型生成回答。# 禁用梯度计算(节省内存,加速推理)# 禁用PyTorch的自动梯度计算,减少内存占用并加速模型推理(因为推理阶段不需要计算梯度)。with torch.no_grad():# 调用生成函数,根据提示词生成模型回答response = generate_responses(model, tokenizer, full_message=input_prompt)# 存储预测结果(格式化为包含"assistant"角色的列表,与提示词结构一致)all_preds.append([{"role": "assistant", "content": response}])# 存储真实标签all_labels.append(ground_truth)# 打印当前样本的预测结果和真实标签(用于调试或观察中间结果)print(response)print("Ground truth: ", ground_truth)在 5 条 GSM8K 测试样本上评估:
- 初始化空列表存储预测与标签;
- 调用 generate_response 生成回复;
- 利用奖励函数计算准确率。
评估结果
- 第 1 条:无 \boxed{} → 不匹配
- 第 2 条:3vsGT=3\boxed{3} vs GT=33vsGT=3 → 匹配
- 第 3 条:未完成(token 限制)→ 不匹配
- 第 4 条:180vsGT=…\boxed{180} vs GT=…180vsGT=… → 不匹配
- 第 5 条:未完成 → 不匹配
准确率:20%(1/5)
建议:
- 提高 max_new_tokens;
- 在完整测试集上评估以减少方差。
训练阶段
完成评估后,进入训练流程:
- 加载训练集:再次取自 GSM8K 的 train split,应用相同后处理。
若无 GPU,仅取前 10 条样本加速。
#加载GSM8K数据集(main是数据集的默认配置)
dataset = load_dataset("openai/gsm8k", "main")
#提取数据集的训练集部分
train_dataset = dataset["train"]# Apply to dataset
#对训练集应用自定义的后处理函数
#map 对数据集的每个样本批量应用自定义处理逻辑的核心工具
train_dataset = train_dataset.map(post_processing)
#移除训练集中不需要的question和answer列。
train_dataset = train_dataset.remove_columns(["question", "answer"])#如果不使用GPU,只选择前10个样本
if not USE_GPU:train_dataset = train_dataset.select(range(10))
#打印处理后训练集的第一个样本,用于调试和确认数据格式。
print(train_dataset[0])
配置GRPO训练
设置GRPOConfig超参数:
- per_device_train_batch_size 每个设备(如单张 GPU)上的训练批次大小
- num_epochs 训练轮数
- learning_rate 学习率,控制模型参数更新的步长
- logging_steps 每训练 2 步就输出一次训练日志
关键参数:num_generations=4(同一提示生成 4 条回复,可设为 64/128 以提升多样性) 对同一个输入提示,模型会生成 4 条不同的回复
config = GRPOConfig(per_device_train_batch_size=1,gradient_accumulation_steps=8,#梯度累积步数。由于批次大小设为 1,为了模拟更大的批次(提升训练稳定性),会累积 8 次梯度后再进行一次模型参数更新。实际等效批次大小为 1×8=8num_generations=4, # Can set as high as 64 or 128num_train_epochs=1,#训练轮数,即整个训练数据集会被模型遍历 1 次。learning_rate=5e-6,#学习率,控制模型参数更新的步长。logging_steps=2,no_cuda= not USE_GPU # keeps the whole run on CPU, incl. MPS
)
启动训练
- 由于 0.5B 模型在 CPU 上训练极慢,
- 使用更小的 SmolLM2-135M-Instruct 模型加速演示。
- 将 模型、配置、奖励函数、训练集 传入 GRPOTrainer 并启动训练。
- 训练过程已加速剪辑。
## If this block hangs or the kernel restarts during training, please skip loading the previous 0.5B model for evaluationmodel, tokenizer = load_model_and_tokenizer("./models/HuggingFaceTB/SmolLM2-135M-Instruct", USE_GPU)grpo_trainer = GRPOTrainer(model=model,args=config,reward_funcs=reward_func,train_dataset=train_dataset
)grpo_trainer.train()
训练完成与现象
训练 loss 始终为 0:
小模型几乎无法答对 → 相对奖励全为 0。
若换用 Qwen2.5B 等更大模型,将观察到有意义的 loss 与提升。如果想使用已经微调好的 Qwen2.5B 模型,可以在 Hugging Face - banghua 下载
全量训练模型评估
加载此前用 GPU + 更大资源 + 微调配置 训练的 Qwen 模型:
- 依次生成 5 条回复并比对 GT
- 第 1 条:20vsGT=18\boxed{20} vs GT=1820vsGT=18 → 不匹配
- 第 2 条:3vsGT=3\boxed{3} vs GT=33vsGT=3 → 匹配
- 第 3 条:未完成 → 不匹配
- 第 4 条:540vsGT=540\boxed{540} vs GT=540540vsGT=540 → 匹配
- 第 5 条:40vsGT=20\boxed{40} vs GT=2040vsGT=20 → 不匹配
准确率:40%(2/5)
结论与建议
- 若需 严谨对比,请在 完整 GSM8K 测试集 上运行评估。
- 上述结果来自 GPU 训练的 Qwen 模型(配置略有差异)。
- 将 fully_trained_qwen 设为 False 即可查看 小模型 + 小数据集 的 GRPO 结果,适合有限算力场景。
#测试代码
fully_trained_qwen = True
if fully_trained_qwen:model, tokenizer = load_model_and_tokenizer("./models/banghua/Qwen2.5-0.5B-GRPO", USE_GPU)
else:model = grpo_trainer.model# Store predictions and ground truths
all_preds = []
all_labels = []for example in tqdm(eval_dataset):input_prompt = example["prompt"]ground_truth = example["ground_truth"]# Run the model to generate an answerwith torch.no_grad():response = generate_responses(model, tokenizer, full_message = input_prompt) all_preds.append([{"role": "assistant", "content": response}])all_labels.append(ground_truth)print(response)print("Ground truth: ", ground_truth)# 3. Evaluate using reward_func
rewards = reward_func(all_preds, all_labels)# 4. Report accuracy
accuracy = sum(rewards) / len(rewards)
print(f"Evaluation Accuracy: {accuracy:.2%}")
实验探索与思考
- 本实验所用的reward function是二元奖励函数(即答案对了就是1分,答案错了就是0分),我们是否能够优化中间步骤的计算,融合CoT,帮助模型进行中间运算步骤的准确性。
- 在本实验过程中,我们使用前5个数据进行eval: 模型的正确率从20%提升到到40%,就是从答对1个,到答对2个。这是否是属于偶然误差?
我们在这里随机选取20个test集里面的数据(shuffle(seed=42)):模型的正确从55%降低到50%。这个好像微调后似乎还起了少许副作用。
- 我们发现有些output_token似乎太小,有几题模型都还没有到最后一步输出,中间就被截断了。
我们在helper.py中默认最大输出的token数是300,如果想扩大token数,可以在Lesson_7.ipynb文件中将 generate_responses函数加入max_new_tokens参数,并进行修改,例如变成1000。
数据集