防止过拟合相关技术
1. 防止过拟合 (Preventing Overfitting)
- 中文名称:防止过拟合
- 英文全称:Preventing Overfitting
- 英文缩写:无
- 英文音标:/prɪˈvɛntɪŋ ˌoʊvərˈfɪtɪŋ/
直观理解
过拟合是指机器学习模型在训练数据上表现得过于完美,甚至学习了噪声和无关特征,导致在新数据(测试数据)上泛化能力差。想象一个学生只死记硬背了课本习题,但遇到新题就不会了。防止过拟合的目标是让模型更通用,避免“死记硬背”。
数学本质
过拟合可以从模型复杂度和偏差-方差权衡来理解。假设我们有一个模型,其训练误差很低但测试误差很高。数学上,过拟合常与高方差相关。损失函数通常表示为:
L(θ)=1n∑i=1nℓ(yi,f(xi;θ))
L(\theta) = \frac{1}{n} \sum_{i=1}^{n} \ell(y_i, f(x_i; \theta))
L(θ)=n1i=1∑nℓ(yi,f(xi;θ))
其中,L(θ)L(\theta)L(θ) 是损失函数,θ\thetaθ 是模型参数,nnn 是样本数,ℓ\ellℓ 是损失(如均方误差)。过拟合时,模型参数 θ\thetaθ 变得过于复杂,导致泛化误差增大。
优劣对比
- 优点:防止过拟合能提高模型泛化能力,减少在未知数据上的错误。
- 缺点:如果过度防止,可能导致欠拟合(模型过于简单,无法捕捉数据模式)。需要平衡。
实战应用
在实践中,我们使用多种技术来防止过拟合,如正则化、数据增强等。接下来,我们将详细讲解这些具体方法。
2. 正则化 (Regularization)
- 中文名称:正则化
- 英文全称:Regularization
- 英文缩写:无
- 英文音标:/ˌrɛɡjələrɪˈzeɪʃən/
直观理解
正则化是一种通过向模型添加约束来防止过拟合的技术。它就像给模型戴上一个“紧箍咒”,限制其复杂度,避免它学习太多噪声。例如,在训练时,我们不仅最小化误差,还惩罚大的参数值,让模型更平滑。
数学本质
正则化通过修改损失函数来加入惩罚项。一般形式为:
Lreg(θ)=L(θ)+λR(θ)
L_{\text{reg}}(\theta) = L(\theta) + \lambda R(\theta)
Lreg(θ)=L(θ)+λR(θ)
其中,L(θ)L(\theta)L(θ) 是原始损失函数,λ\lambdaλ 是正则化参数(控制惩罚强度),R(θ)R(\theta)R(θ) 是正则化项。常见的有L1和L2正则化。
优劣对比
- 优点:简单有效,能显著减少过拟合,提高泛化能力。
- 缺点:需要调优参数 λ\lambdaλ,不当选择可能导致欠拟合或过拟合。
实战应用
在深度学习框架如TensorFlow或PyTorch中,可以通过在优化器中设置权重衰减(相当于L2正则化)或自定义损失函数来实现。例如,在PyTorch中:
import torch.nn as nn
model = nn.Linear(10, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-5) # weight_decay即L2正则化
3. 数据增强 (Data Augmentation)
- 中文名称:数据增强
- 英文全称:Data Augmentation
- 英文缩写:无
- 英文音标:/ˈdeɪtə ɔːɡmɛnˈteɪʃən/
直观理解
数据增强是通过对训练数据进行随机变换(如旋转、缩放、翻转)来生成更多样化的训练样本,从而增加数据量,防止模型过拟合。就像给学生提供更多练习题,让他们学会通用解法。
数学本质
数据增强不直接修改损失函数,而是通过扩充数据集来影响训练。假设原始数据集 D={(xi,yi)}i=1nD = \{(x_i, y_i)\}_{i=1}^nD={(xi,yi)}i=1n,增强后数据集 D′D'D′ 包含变换后的样本,例如:
x′=T(x)
x' = T(x)
x′=T(x)
其中 TTT 是随机变换(如旋转、裁剪)。训练时,我们使用 D′D'D′ 来计算损失:
L(θ)=1m∑j=1mℓ(yj,f(xj′;θ))
L(\theta) = \frac{1}{m} \sum_{j=1}^{m} \ell(y_j, f(x_j'; \theta))
L(θ)=m1j=1∑mℓ(yj,f(xj′;θ))
其中 mmm 是增强后的样本数。
优劣对比
- 优点:无需修改模型结构,简单易用,尤其适用于图像和语音数据。
- 缺点:可能引入不真实的变换,对某些领域(如文本)效果有限。
实战应用
在图像处理中,常用库如TensorFlow的ImageDataGenerator或PyTorch的torchvision.transforms实现数据增强。例如:
from torchvision import transforms
transform = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.RandomRotation(10),
])
在目标识别领域常用的方法是将图片进行旋转、平移、缩放等(图片变换的前提是通过变换不能改变图片所属类别,例如手写数字识别,类别6和9进行旋转后容易改变类目)。 语音识别中对输入数据添加随机噪声。 NLP中常用思路是进行近义词替换。
4. L1正则化 (L1 Regularization)
- 中文名称:L1正则化
- 英文全称:L1 Regularization
- 英文缩写:L1
- 英文音标:/ɛl wʌn ˌrɛɡjələrɪˈzeɪʃən/
直观理解
L1正则化通过在损失函数中添加参数绝对值的和作为惩罚项,促使模型参数稀疏化(即许多参数变为零)。这就像“特征选择”,只保留最重要的特征。
数学本质
L1正则化的损失函数为:
LL1(θ)=L(θ)+λ∑i∣θi∣
L_{\text{L1}}(\theta) = L(\theta) + \lambda \sum_{i} |\theta_i|
LL1(θ)=L(θ)+λi∑∣θi∣
其中,λ\lambdaλ 是正则化参数,∑i∣θi∣\sum_{i} |\theta_i|∑i∣θi∣ 是L1范数。在优化过程中,梯度包含符号函数,导致某些参数精确为零。
优劣对比
- 优点:能产生稀疏解,适用于特征选择,模型更易解释。
- 缺点:非光滑优化,可能收敛慢;不适用于所有问题(如需要所有特征的情况)。
实战应用
在Scikit-learn中,可以在线性模型设置penalty='l1',或在深度学习中使用自定义损失。例如,在TensorFlow中:
import tensorflow as tf
loss = tf.reduce_mean(tf.square(y_true - y_pred)) + tf.reduce_sum(tf.abs(weights)) * lambda_val
5. L2正则化 (L2 Regularization)
- 中文名称:L2正则化
- 英文全称:L2 Regularization
- 英文缩写:L2
- 英文音标:/ɛl tuː ˌrɛɡjələrɪˈzeɪʃən/
直观理解
L2正则化通过在损失函数中添加参数平方和的惩罚项,促使参数值变小但不一定为零。这就像“平滑”模型,避免某些参数过大,提高泛化能力。
数学本质
L2正则化的损失函数为:
LL2(θ)=L(θ)+λ∑iθi2
L_{\text{L2}}(\theta) = L(\theta) + \lambda \sum_{i} \theta_i^2
LL2(θ)=L(θ)+λi∑θi2
其中,λ\lambdaλ 是正则化参数,∑iθi2\sum_{i} \theta_i^2∑iθi2 是L2范数的平方。在优化中,梯度与参数成正比,导致参数衰减。
优劣对比
- 优点:光滑优化,收敛稳定;广泛适用于各种模型。
- 缺点:不能产生稀疏解,所有参数都被保留但缩小。
实战应用
在深度学习框架中,L2正则化常通过权重衰减实现。例如,在PyTorch中:
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4) # weight_decay即L2
6. Dropout
- 中文名称:丢弃法
- 英文全称:Dropout
- 英文缩写:无
- 英文音标:/ˈdrɒpaʊt/
直观理解
Dropout是一种在训练过程中随机“关闭”一部分神经元的技术,迫使网络不依赖任何单个神经元,从而增强鲁棒性。就像团队合作中,每个人都能独立工作,避免过度依赖某个人。
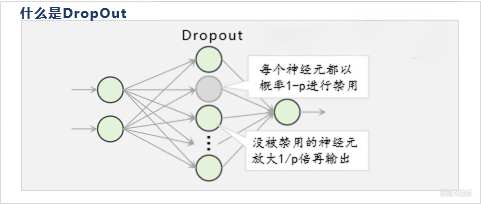
数学本质
在训练时,每个神经元以概率 ppp 被保留,以 1−p1-p1−p 被丢弃。数学上,对于一层输出 hhh,Dropout操作如下:
h′=h⊙m
h' = h \odot m
h′=h⊙m
其中 mmm 是一个二进制掩码,元素独立服从伯努利分布(如 mi∼Bernoulli(p)m_i \sim \text{Bernoulli}(p)mi∼Bernoulli(p))。在测试时,所有神经元都使用,但输出乘以 ppp 以保持期望值一致。
优劣对比
- 优点:有效防止过拟合,尤其适用于大型神经网络;实现简单。
- 缺点:训练时间可能增加;需要调整丢弃率 (p)。
实战应用
在TensorFlow或PyTorch中,可以直接添加Dropout层。例如,在PyTorch中:
import torch.nn as nn
model = nn.Sequential(nn.Linear(100, 50),nn.ReLU(),nn.Dropout(p=0.5), # 丢弃率50%nn.Linear(50, 10)
)
7. 提前终止 (Early Stopping)
- 中文名称:提前终止
- 英文全称:Early Stopping
- 英文缩写:无
- 英文音标:/ˈɜrli ˈstɒpɪŋ/
直观理解
提前终止是通过监控验证集性能,在模型开始过拟合时停止训练。就像考试前不再熬夜复习,避免“学过头”导致效率下降。
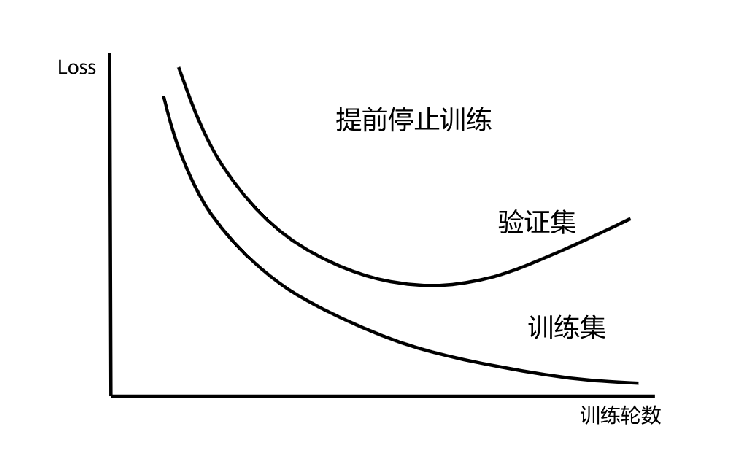
数学本质
假设训练迭代次数为 ttt,验证损失为 Lval(t)L_{\text{val}}(t)Lval(t)。我们记录最佳验证损失,当连续多个epoch(如耐心值)未改善时,停止训练。数学上,这可以看作一种正则化,因为它限制了模型复杂度(训练时间)。
优劣对比
- 优点:无需修改模型或损失函数;计算高效。
- 缺点:需要验证集;可能过早停止,导致欠拟合。
实战应用
在训练循环中实现回调。例如,在Keras中:
from keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='val_loss', patience=5)
model.fit(X_train, y_train, validation_data=(X_val, y_val), callbacks=[early_stopping])
8. BN (Batch Normalization)
- 中文名称:批量归一化
- 英文全称:Batch Normalization
- 英文缩写:BN
- 英文音标:/bætʃ ˌnɔːrmələˈzeɪʃən/
直观理解
批量归一化通过对每个小批量的输入进行标准化(减均值、除标准差),使数据分布稳定,加速训练并减少过拟合。就像在体育训练中,先热身再运动,避免受伤。
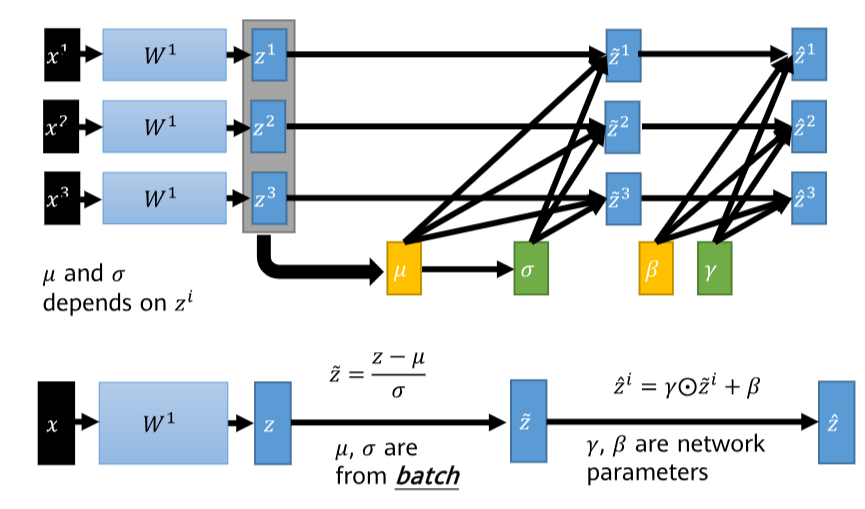
数学本质
对于一个小批量 B={x1,x2,…,xm}B = \{x_1, x_2, \dots, x_m\}B={x1,x2,…,xm},BN操作如下:
μB=1m∑i=1mxi,σB2=1m∑i=1m(xi−μB)2
\mu_B = \frac{1}{m} \sum_{i=1}^{m} x_i, \quad \sigma_B^2 = \frac{1}{m} \sum_{i=1}^{m} (x_i - \mu_B)^2
μB=m1i=1∑mxi,σB2=m1i=1∑m(xi−μB)2
x^i=xi−μBσB2+ϵ,yi=γx^i+β
\hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}}, \quad y_i = \gamma \hat{x}_i + \beta
x^i=σB2+ϵxi−μB,yi=γx^i+β
其中,μB\mu_BμB 和 σB2\sigma_B^2σB2 是批量的均值和方差,ϵ\epsilonϵ 是小常数防止除零,γ\gammaγ 和 β\betaβ 是可学习参数。
优劣对比
- 优点:加速收敛,减少内部协变量偏移;有一定正则化效果(因为引入噪声)。
- 缺点:对小批量大小敏感;在推理时需使用移动平均。
实战应用
在深度学习框架中,BN作为一层添加。例如,在PyTorch中:
nn.BatchNorm2d(64) # 用于卷积层
nn.BatchNorm1d(128) # 用于全连接层
总结与对比
以上方法都是防止过拟合的有效手段,它们可以结合使用。例如,在一个卷积神经网络中,我们可能同时使用数据增强、Dropout、L2正则化和Batch Normalization。
- 直观理解:所有方法都旨在让模型更通用,避免记忆噪声。
- 数学本质:正则化修改损失函数,Dropout和BN改变网络结构,数据增强扩充数据集。
- 优劣对比:L1适合特征选择,L2更平滑;Dropout适用于大型网络;提前终止简单;BN加速训练。