智谱GLM 大模型家族与 ChatGLM3-6B 微调入门
智谱AI开放平台
https://open.bigmodel.cn/overview
智谱GLM大模型家族
1、介绍
智谱AI GLM 大模型家族由清华大学知识工程组(KEG)和数据挖掘组(THUDM)开发,该团队发布的一系列大型语言模型及相关系统
- ChatGLM: 开源双语对话模型,其中 ChatGLM-6B 系列在 Hugging Face 上的下载量已超过 1000 万次(这是一个非常突出的成就)。
- CodeGeeX: 多语言代码生成模型(在 KDD 2023 发表)。
- CogVLM (VisualGLM): 开源视觉语言模型。
- WebGLM: 高效的网络增强问答系统(在 KDD 2023 发表)。
- GLM-130B: 开源双语预训练模型(在 ICLR 2023 发表)。
- CogView: 开源文生图模型(在 NeurIPS 2021 发表)。
- CogVideo: 开源文生视频模型(在 ICLR 2023 发表)。
- AgentTuning: 用于增强大模型通用智能体能力的技术。
2、GLM基座模型设计
不像BERT(只编码)、GPT(只自回归生成)或T5(编码器-解码器)那样各有侧重,而是通过**“自回归空白填充”** 这一创新技术,在一个模型里同时实现了双向上下文理解和自回归生成的能力,旨在成为一个真正通用的预训练基石。
所有自然语言处理任务都是生成任务。GLM试图用一个统一的“生成”框架来解决各种不同类型的NLP问题,无论是文本分类、问答还是文本生成。
- 自回归空白填充核心机制如下:
这种类似于BERT的完形填空,但以自回归的方式完成,非常适合训练模型对语言的深层理解,适用于自然语言理解任务。
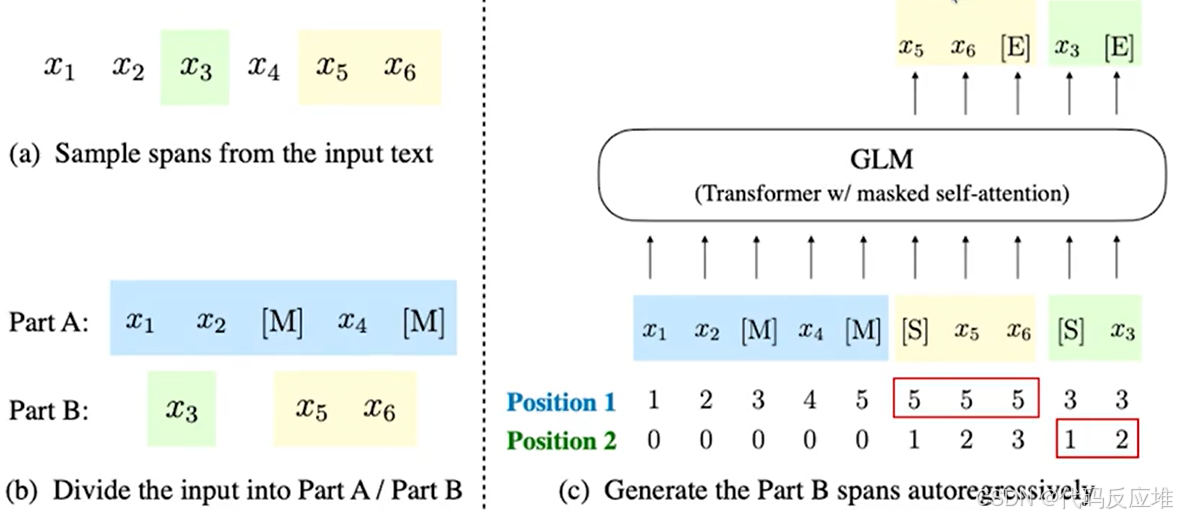
a图,原始文本由6个词元组成:[x1, x2, x3, x4, x5, x6]。从中随机采样了两个文本跨度(Spans平均长度 λ=3 的片段):第一个跨度:[x3](长度为1)、第二个跨度:[x5, x6](长度为2);这模拟了在文本中随机挖空的行为
b图,Part A:将原始文本中被采样的跨度用单个 [M] 标记(代表 [MASK])替换,这部分是模型可见的上下文。Part B:将所有被挖走的跨度收集起来,并进行随机洗牌。
c图,GLM最核心的创新,将 Part A 和 Part B 拼接起来作为输入:[x1, x2, [M], x4, [M], [S], x5, x6, [S], x3],在每个待生成的跨度前加上 [S](代表 [START])作为生成开始的信号。模型需要自回归地(一个一个地)预测 Part B 中的内容。在这个例子中,它需要依次预测 x5, x6, [E], x3, [E]([E] 代表 [END],表示一个跨度的结束),Part A的词元均为0,Part B中每个跨度内部的词元从1开始计数。这指导模型在生成时按正确顺序产出跨度内的内容。通过这种设计,GLM在一个统一的模型中实现了双向编码器(理解Part A)和自回归解码器(生成Part B)的功能。
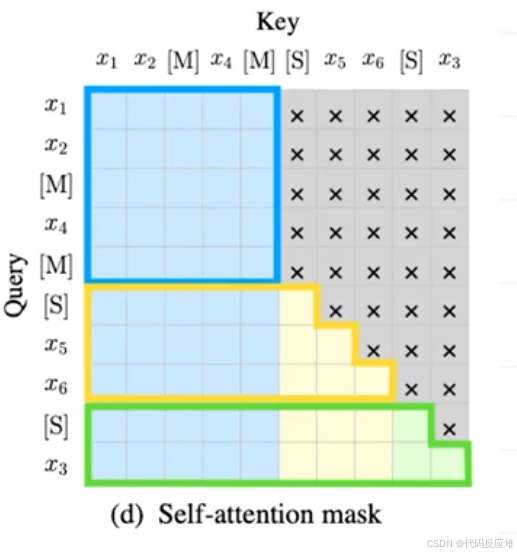
d图,这张矩阵图清晰地规定了在训练过程中,序列中的每个元素(Query)可以关注(Attention)到哪些其他元素(Key)。
- 文本生成核心机制如下
为了让模型同时具备强大的文本生成能力,作者增加了两个新的预训练目标,与原始目标一起进行多任务优化。这两个新目标都使用同样的“自回归空白填充”机制。唯一的区别在于所遮盖的文本跨度的数量和长度。文档级生成目标从整个文档中随机抽取一个非常长的跨度,其长度为原文的 50% 到 100%。这迫使模型根据前半部分文档(Part A)的有限上下文,来生成后半部分(Part B)。这种任务专门针对长文本生成(如续写文章、生成长报告)进行优化。句子级生成目标随机遮盖一些完整的句子,所有被遮盖的句子总长度占原文的 15%。这模拟了摘要、翻译、改写等序列到序列(seq2seq)任务。模型需要理解全文(Part A),然后生成完整的句子(Part B)来重构原文。
3、GLM扩展模型
1、联网检索
WebGLM是一个高效的、基于网络增强的问答系统(Q&A),原理是将网络搜索和检索能力整合到预训练语言模型中。
工作流程:
- 输入问题:例如 “Why is it sometimes hard to eat after not eating for a while?”
- 检索网络内容:从多个网页中提取相关段落。
- 引用增强:通过“LLM参考采纳”和“微调密集检索器”增强引用的准确性。
- 生成答案:系统综合多个来源(如 Reference [1], [2], [3])生成最终回答。
- 评分筛选:使用“人类偏好感知评分器”对生成答案打分(如 -0.2, -0.3 等),确保质量。
2、多模态
- VisualGLM-6B
VisualGLM-6B是一个开源的多模态对话语言模型,基于ChatGLM-6B(62亿参数),支持图像、中英文对话。图像与文字的关联通过 BLIP2-Qformer(一种高效的视觉-语言连接器)使用CogView 数据集的 3000万 高质量中文图文对,同时使用 3亿 经过筛选的英文图文对,实现了将视觉信息有效地对齐到 ChatGLM 的语义空间中。
可用SwissArmyTransformer(SAT) 库进行训练VisualGLM-6B模型。这是一个支持灵活修改和训练 Transformer 的工具库,并支持 Lora、P-tuning 等参数高效微调方法。提供了用户熟悉的 Huggingface 接口,也提供了基于 SAT 的原始接口。结合模型量化技术,用户可以在消费级显卡上部署。特别是在 INT4量化 级别下,最低仅需 8.7GB 的显存。
- CogVLM
VisualGLM-6B进阶版模型CogVLM,一个更强大的开源视觉语言基础模型。
3、代码生成
- CodeGeeX2
CodeGeeX2是多语言代码生成模型 CodeGeeX 的第二代版本,完全基于国产华为昇腾芯片训练。模型基于ChatGLM2-6B 语言模型,并使用 6000亿 代码数据进行预训练。经量化后仅需6GB显存即可运行,支持轻量级本地部署。
CodeGeeX插件(支持 VS Code 和 Jetbrains IDE)后端已升级,支持超过100种编程语言。
PEFT库QLoRA微调ChatGLM3-6B微调入门
0、定义全局变量和参数
# 定义全局变量和参数
model_name_or_path = 'THUDM/chatglm3-6b' # 模型ID或本地路径
train_data_path = 'HasturOfficial/adgen' # 训练数据路径
eval_data_path = None # 验证数据路径,如果没有则设置为None
seed = 8 # 随机种子
max_input_length = 512 # 输入的最大长度
max_output_length = 1536 # 输出的最大长度
lora_rank = 4 # LoRA秩
lora_alpha = 32 # LoRA alpha值
lora_dropout = 0.05 # LoRA Dropout率
resume_from_checkpoint = None # 如果从checkpoint恢复训练,指定路径
prompt_text = ''
compute_dtype = 'fp32'
1、数据集准备
- 从Hugging face上加载数据集
from datasets import load_datasetdataset = load_dataset(train_data_path)
可以查看展示数据集的方法,也可以在huggingface上直接看
from datasets import ClassLabel, Sequence
import random
import pandas as pd
from IPython.display import display, HTMLdef show_random_elements(dataset, num_examples=10):assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."picks = []for _ in range(num_examples):pick = random.randint(0, len(dataset)-1)while pick in picks:pick = random.randint(0, len(dataset)-1)picks.append(pick)df = pd.DataFrame(dataset[picks])for column, typ in dataset.features.items():if isinstance(typ, ClassLabel):df[column] = df[column].transform(lambda i: typ.names[i])elif isinstance(typ, Sequence) and isinstance(typ.feature, ClassLabel):df[column] = df[column].transform(lambda x: [typ.feature.names[i] for i in x])display(HTML(df.to_html()))show_random_elements(dataset["train"], num_examples=3)
- Tokenizer 处理数据
关于 ignore_label_id 的设置:
在许多自然语言处理和机器学习框架中,ignore_label_id 被设置为 -100 是一种常见的约定。这个特殊的值用于标记在计算损失函数时应该被忽略的目标标签。让我们详细了解一下这个选择的原因:
-
损失函数忽略特定值:训练语言模型时,损失函数(例如交叉模拟失)通常只计算对于模型预测重要或关键的标签的损失。在某些情况下,你可能不希望某些标签对损失计算产生影响。例如,在序列到序列的模型中,输入部分的标签通常被设置为一个忽略值,因为只有输出部分的标签对于训练是重要的。
-
为何选择-100:这个具体的值是基于实现细节选择的。在 PyTorch 的交叉模拟失函数中,可以指定一个 ignore_index 参数。当损失函数看到这个索引值时,它就会忽略对应的输出标签。使用 -100 作为默认值是因为它是一个不太可能出现在标签中的数字(特别是在处理分类问题时,标签通常是从0开始的正整数)。
-
标准化和通用性:由于这种做法在多个库和框架中被采纳,-100 作为忽略标签的默认值已经变得相对标准化,这有助于维护代码的通用性和可读性。
总的来说,将 ignore_label_id 设置为 -100 是一种在计算损失时排除特定标签影响的便捷方式。这在处理特定类型的自然语言处理任务时非常有用,尤其是在涉及序列生成或修改的任务中。
关于 ChatGLM3 的填充处理说明
- input_id (query) 里的填充补全了输入长度,目的是不改变原始文本的含义。
- label (answer) 里的填充会用来跟模型基于 query 生成的结果计算 Loss。为了不影响损失值计算,也需要设置。咱们计算损失时,是针对 answer 部分的 Embedding Vector,因此 label 这样填充,前面的序列就自动忽略掉了,只比较生成内容的 loss。因此,需要将 answer前面的部分做忽略填充。
from transformers import AutoTokenizer# revision='b898244' 版本对应的 ChatGLM3-68 设置 use_reentrant=False
# 最新版本 use_reentrant 被设置为 True,会增加不必要的是存开销
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path,trust_remote_code=True,revision='b898244')
# tokenize_func 函数
def tokenize_func(example, tokenizer, ignore_label_id=-100):""" 对单个数据样本进行tokenize处理。参数:example (dict): 包含'content'和'summary'键的字典,代表训练数据的一个样本。tokenizer (transformers.PreTrainedTokenizer): 用于tokenize文本的tokenizer。ignore_label_id (int, optional): 在label中用于填充的忽略ID,默认为-100。返回:dict: 包含'tokenized_input_ids'和'labels'的字典,用于模型训练。"""# 构建问题文本question = prompt_text + example['content']if example.get('input', None) and example['input'].strip():question += f'\n{example["input"]}'# 构建答案文本answer = example['summary']# 对问题和答案文本进行tokenize处理q_ids = tokenizer.encode(text=question, add_special_tokens=False)a_ids = tokenizer.encode(text=answer, add_special_tokens=False)# 如果tokenize后的长度超过最大长度限制,则进行截断if len(q_ids) > max_input_length - 2: # 保留空间给gmask和pos标记q_ids = q_ids[:max_input_length - 2]if len(a_ids) > max_output_length - 1: # 保留空间给eos标记a_ids = a_ids[:max_output_length - 1]# 构建模型的输入格式input_ids = tokenizer.build_inputs_with_special_tokens(q_ids, a_ids)question_length = len(q_ids) + 2 # 加上gmask和pos标记# 构建标签,对于问题部分的输入使用ignore_label_id进行填充labels = [ignore_label_id] * question_length + input_ids[question_length:]return {'input_ids': input_ids, 'labels': labels}
column_names = dataset['train'].column_names
tokenized_dataset = dataset['train'].map(lambda example: tokenize_func(example, tokenizer),batched=False,remove_columns=column_names
)
show_random_elements(tokenized_dataset, num_examples=1)
数据集处理:shuffle & flatten
洗牌(shuffle)会将数据集的索引列表打乱,以创建一个索引映射。
然而,一旦您的数据集具有索引映射,速度可能会变慢10倍。这是因为需要额外的步骤来使用索引映射获取要读取的行索引,并且最重要的是,您不再连续地读取数据块。
要恢复速度,需要再次使用 Dataset.flatten_indices() 将整个数据集重新写入磁盘上,从而删除索引映射。
ref: https://huggingface.co/docs/datasets/v2.15.0/en/package_reference/main_classes#datasets.Dataset.flatten_indices
tokenized_dataset = tokenized_dataset.shuffle(seed=seed)
tokenized_dataset = tokenized_dataset.flatten_indices()
定义 DataCollatorForChatGLM 类 批量处理数据
import torch
from typing import List, Dict, Optional# DataCollatorForChatGLM 类
class DataCollatorForChatGLM:"""用于处理批量数据的DataCollator,尤其是在使用 ChatGLM 模型时。该类负责将多个数据样本 (tokenized input) 合并为一个批量,并在必要时进行填充(padding)。属性:pad_token_id (int): 用于填充(padding)的token ID。max_length (int): 单个批量数据的最大长度限制。ignore_label_id (int): 在标签中用于填充的ID。"""def __init__(self, pad_token_id: int, max_length: int = 2048, ignore_label_id: int = -100):"""初始化DataCollator。参数:pad_token_id (int): 用于填充(padding)的token ID。max_length (int): 单个批量数据的最大长度限制。ignore_label_id (int): 在标签中用于填充的ID,默认为-100。"""self.pad_token_id = pad_token_idself.ignore_label_id = ignore_label_idself.max_length = max_lengthdef __call__(self, batch_data: List[Dict[str, List]]) -> Dict[str, torch.Tensor]:""" 处理批量数据。参数:batch_data (List[Dict[str, List]]): 包含多个样本的字典列表。返回:Dict[str, torch.Tensor]: 包含处理后的批量数据的字典。"""# 计算批量中每个样本的长度len_list = [len(d['input_ids']) for d in batch_data]batch_max_len = max(len_list) # 找到最长的样本长度input_ids, labels = [], []for len_of_d, d in sorted(zip(len_list, batch_data), key=lambda x: -x[0]):pad_len = batch_max_len - len_of_d # 计算需要填充的长度# 添加填充,并确保数据长度不超过最大长度限制ids = d['input_ids'] + [self.pad_token_id] * pad_lenlabel = d['labels'] + [self.ignore_label_id] * pad_lenif batch_max_len > self.max_length:ids = ids[:self.max_length]label = label[:self.max_length]input_ids.append(torch.LongTensor(ids))labels.append(torch.LongTensor(label))# 将处理后的数据堆叠成一个tensorinput_ids = torch.stack(input_ids)labels = torch.stack(labels)return {'input_ids': input_ids, 'labels': labels}
# 准备数据整理器
data_collator = DataCollatorForChatGLM(pad_token_id=tokenizer.pad_token_id)
2、训练模型
- 加载 ChatGLM3-6B 量化模型
使用 nf4 量化数据类型加载模型,开启双重化配置,以 bf16 混合精度训练,预估显存占用接近4GB
from transformers import AutoModel, BitsAndBytesConfig_compute_dtype_map = {'fp32': torch.float32,'fp16': torch.float16,'bf16': torch.bfloat16
}# QLoRA 量化配置
q_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type='nf4',bnb_4bit_use_double_quant=True,bnb_4bit_compute_dtype=_compute_dtype_map['bf16'])
- 加载模型
# revision='b898244' 版本对应的 ChatGLM3-6B 设置 use_reentrant=False
# 最新版本 use_reentrant 被设置为 True,会增加不必要的显存开销
model = AutoModel.from_pretrained(model_name_or_path,quantization_config=q_config,device_map='auto',trust_remote_code=True,revision='b898244')
可以检查模型显存占用
# 计算模型显存占用
memory_footprint_bytes = model.get_memory_footprint()
memory_footprint_mib = memory_footprint_bytes / (1024 ** 2) # 转换为 MiBprint(f"{memory_footprint_mib:.2f} MiB")
- 预处理量化模型
预处理量化后的模型,使其可以支持低精度微调训练
ref: https://huggingface.co/docs/peft/main/en/developer_guides/quantization#quantize-a-model
from peft import TaskType, LoraConfig, get_peft_model, prepare_model_for_kbit_trainingkbit_model = prepare_model_for_kbit_training(model)
- PEFT 适配模块设置
在PEFT库的 constants.py 文件中定义了不同的 PEFT 方法,在各类大模型上的微调适配模块。
通常,名称相同的模型架构也类似,应用微调方法时的适配器设置也几乎一致。
例如,如果新模型架构是 mistral 模型的变体,并且您想应用 LoRA 微调。在 TRANSFORMERS_MODELS_TO_LORA_TARGET_MODULES_MAPPING中 mistral 包含 [“q_proj”, “v_proj”]。
这表示说,对于 mistral 模型,LoRA 的 target_modules 通常是 [“q_proj”, “v_proj”]。
可以直接查看constants.py中有target_modules的推荐配置
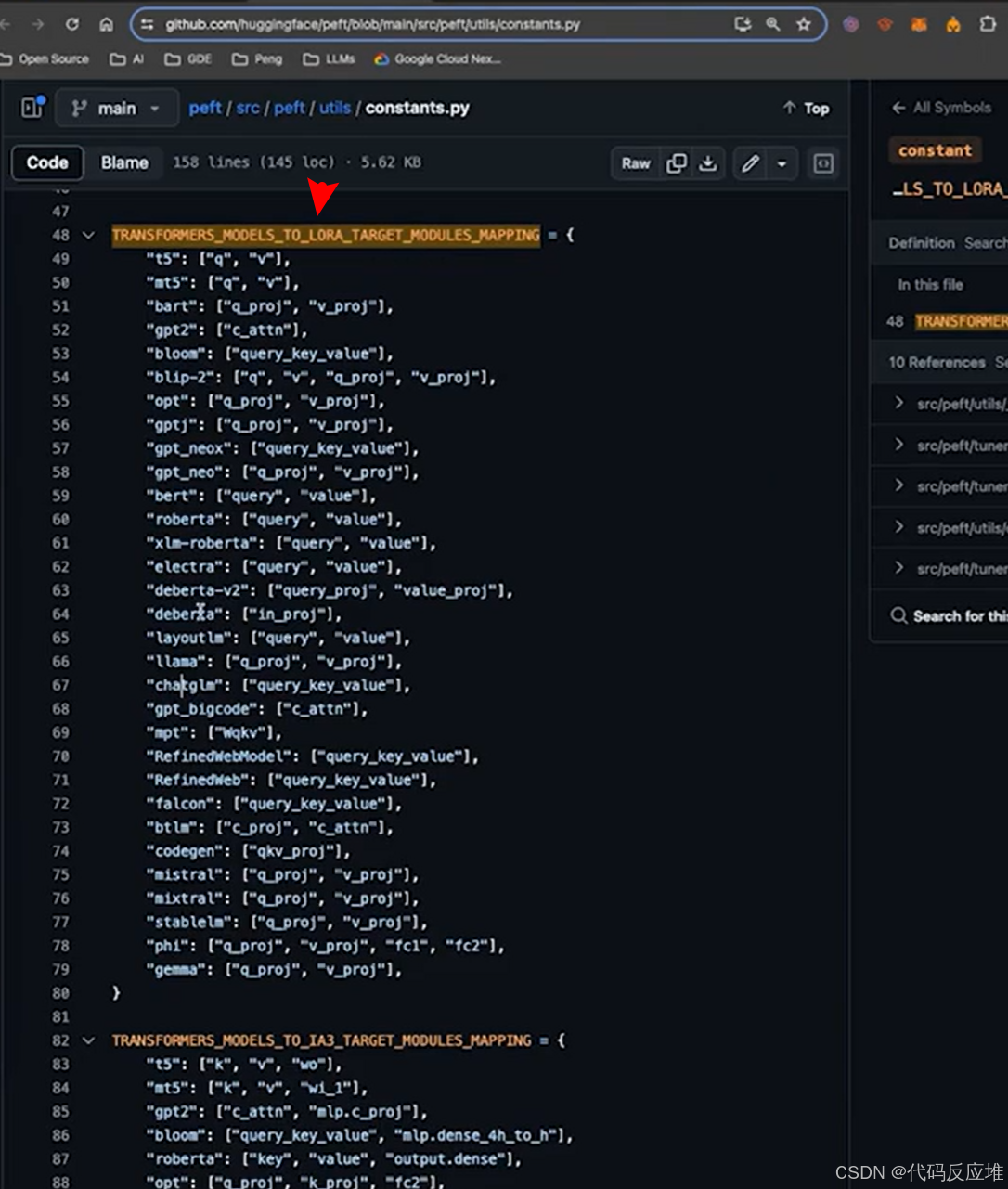
from peft.utils import TRANSFORMERS_MODELS_TO_LORA_TARGET_MODULES_MAPPINGtarget_modules = TRANSFORMERS_MODELS_TO_LORA_TARGET_MODULES_MAPPING['chatglm']
- LoRA 适配器配置
lora_config = LoraConfig(target_modules=target_modules,r=lora_rank,lora_alpha=lora_alpha,lora_dropout=lora_dropout,bias='none',inference_mode=False,task_type=TaskType.CAUSAL_LM
)qlora_model = get_peft_model(kbit_model, lora_config)qlora_model.print_trainable_parameters()
- 训练参数设置
from transformers import TrainingArguments, Trainertraining_demo_args = TrainingArguments(output_dir=f"models/demo/{model_name_or_path}", # 输出目录per_device_train_batch_size=16, # 每个设备的训练批量大小gradient_accumulation_steps=4, # 梯度累积步数learning_rate=1e-3, # 学习率max_steps=100, # 训练步数lr_scheduler_type="linear", # 学习率调度器类型warmup_ratio=0.1, # 预热比例logging_steps=10, # 日志记录步数save_strategy="steps", # 模型保存策略save_steps=20, # 模型保存步数optim="adamw_torch", # 优化器类型fp16=True, # 是否使用混合精度训练
)trainer = Trainer(model=qlora_model,args=training_demo_args,train_dataset=tokenized_dataset,data_collator=data_collator
)
- 开始训练
# 根据硬件不同,跑的时间不同
trainer.train()
# 保存模型
trainer.model.save_pretrained(f"models/demo/{model_name_or_path}")
3、使用模型
使用 QLoRA 微调后的 ChatGLM3-6B进行模型推理任务
# 模型推理 - 使用 QLoRA 微调后的 ChatGLM3-6Bimport torch
from transformers import AutoModel, AutoTokenizer, BitsAndBytesConfig
from peft import PeftModel, PeftConfig# 定义全局变量和参数
model_name_or_path = 'THUDM/chatglm3-6b' # 模型ID或本地路径
peft_model_path = f"models/demo/{model_name_or_path}"
config = PeftConfig.from_pretrained(peft_model_path)q_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type='nf4',bnb_4bit_use_double_quant=True,bnb_4bit_compute_dtype=torch.float32)base_model = AutoModel.from_pretrained(config.base_model_name_or_path,quantization_config=q_config,trust_remote_code=True,device_map='auto')base_model.requires_grad(False)
base_model.eval()
input_text = '类型#地+版型#星宿+风格#文艺+风格#简约+图案#印花+图案#撞色+裙下摆#压褶+裙长#连衣裙+裙领型#圆领'
对比微调前后的效果
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path, trust_remote_code=True)
response, history = base_model.chat(tokenizer=tokenizer, query=input_text)
print(f'ChatGLM3-6B 微调前: \n{response}')
微调前输出:连衣裙是女孩子们重要的单品之一,这款连衣裙采用撞色圆领设计,简洁大方,修饰脸型。衣身采用印花图案点缀,展现出优雅文艺的气质。袖子采用压褶设计,轻松遮挡风扇,修饰臀部线条。简约的款式设计,穿着舒适,轻松百搭。
model = PeftModel.from_pretrained(base_model, peft_model_path)
response, history = model.chat(tokenizer=tokenizer, query=input_text)
print(f'ChatGLM3-6B 微调后: \n{response}')
ChatGLM3-6B 微调后:
这于连衣裙简约的需领设计,辐显出修长的颈部线条,丁衣身采用撞色印花没汁,更显佣皮儿美,再袍口和裙摆处加入压珊设计,增漂层次感,更具艺术感,而裙身整体设计简约大气,彩显出优末文艺的气质.