Retrieval Augmented Time Series Forecasting 论文笔记
基本信息
发表刊物
ICML 2025
作者

第一完成单位
School of Computing, KAIST, Daejeon, South Korea
解决的问题
Motivation(背景)
现实世界时间序列的复杂性与模型的局限性:
现实世界中的时间序列表现出复杂、非平稳的模式,具有不同的周期和形状 。
模式可能缺乏固有的时间相关性,源于非确定性过程,导致不经常重复和多样化分布 。
现有模型在从这些不经常出现的模式中进行推理时,效果令人担忧 。
现有深度学习模型的学习负担:
传统的深度学习模型(如基于CNN、RNN和Transformer的模型)通过学习模型的权重来隐式地捕获历史观测中的模式 。
强行让模型去学习所有可能的复杂模式会增加学习负担 。
不加选择地记忆所有模式(包括噪声和不相关的模式)在泛化性和效率方面都有疑问 。
对稀有模式的记忆困难:
如果某个模式在历史数据中很少出现,模型很难将其记忆下来 。
论文解决的问题(核心创新点)
为解决上述问题,本文提出 RAFT (Retrieval-Augmented Forecasting of Time-series) ,其核心是借鉴了大型语言模型中的“检索增强生成(RAG)”思想 ,将检索模块引入到时间序列预测。
减轻预测模型的学习负担,增强泛化性:
通过检索模块,直接从训练数据集中检索与当前输入模式最相似的历史数据片段 。
相当于外部提供了关于过去模式的信息,从而增强了模型的容量,并减少了预测模型在学习复杂模式上的负担 。
显式利用历史模式,解决稀有模式问题:
通过直接利用检索到的信息,过去有用的模式在推理时可以显式地提供给模型,而不是仅仅依赖于模型权重中学习到的隐式信息 。
这样即使一个模式很少出现,检索模块也能让模型在它再次出现时轻松地利用历史模式进行预测 。
RAFT 的目标是提供足够的归纳偏置(inductive biases)并补充模型的学习能力,使其能更有效地处理时间序列中复杂、不经常重复或缺乏时间相关性的模式,从而提高预测的准确性 。
实验证明,RAFT 在十个基准数据集上平均胜率达到 86%,显著优于现有基线模型 。
论文的方法
问题概述
问题定义
给定 为含有C个变量的、长度为T的时间序列,
RAFT 利用历史观测值 来预测未来值
。
核心思想
增强机制: RAFT 的核心是引入一个检索模块。
检索内容: 给定输入
,检索模块会从整个历史时间序列
中找到最相关的 Patch 。
附加信息: 随后,这些相关Patch 的后续Patches(subsequent patches,即它们在历史中对应的未来值)被检索出来,作为额外的预测信息。
检索过程: 检索过程遵循一种类似注意力 (attention-like) 的结构:
相似度计算: 基于输入
聚合: 检索到的后续patch 通过加权求和 (weighted sum) 的方式进行聚合,生成一个有用的历史信息摘要。
与 Transformer 的关键区别
传统注意力 (如 Transformer): 依赖于一个固定的回溯窗口 (fixed lookback window) 内的数据进行注意力计算和模式学习。
RAFT 的检索: 能够从整个时间序列 (the entire time series) 中检索相关数据。这意味着 RAFT 可以找到很久以前出现过的、与当前输入模式相似的稀有模式,这在处理非平稳或具有不经常重复模式的时间序列时,具有显著优势。
整体架构 (Overall Architecture)
为了全面捕获时间序列的特征,RAFT 进一步引入了多周期检索:
多周期处理: 考虑到时间序列在不同时间尺度(如天、周、月)上表现出不同的特性,RAFT 通过对原始时间序列
独立检索: 对每个下采样后的序列,都应用一个独立的检索模块进行检索。
聚合:
每个周期的检索结果先经过一个线性投影 (linear projection)。
然后,通过求和 (summation) 的方式进行聚合,形成最终的检索增强特征。
最终预测:
将原始输入
这个组合特征被送入一个线性模型 (linear model) 中,生成最终的预测
。
Retrieval module architecture(检索模块架构)
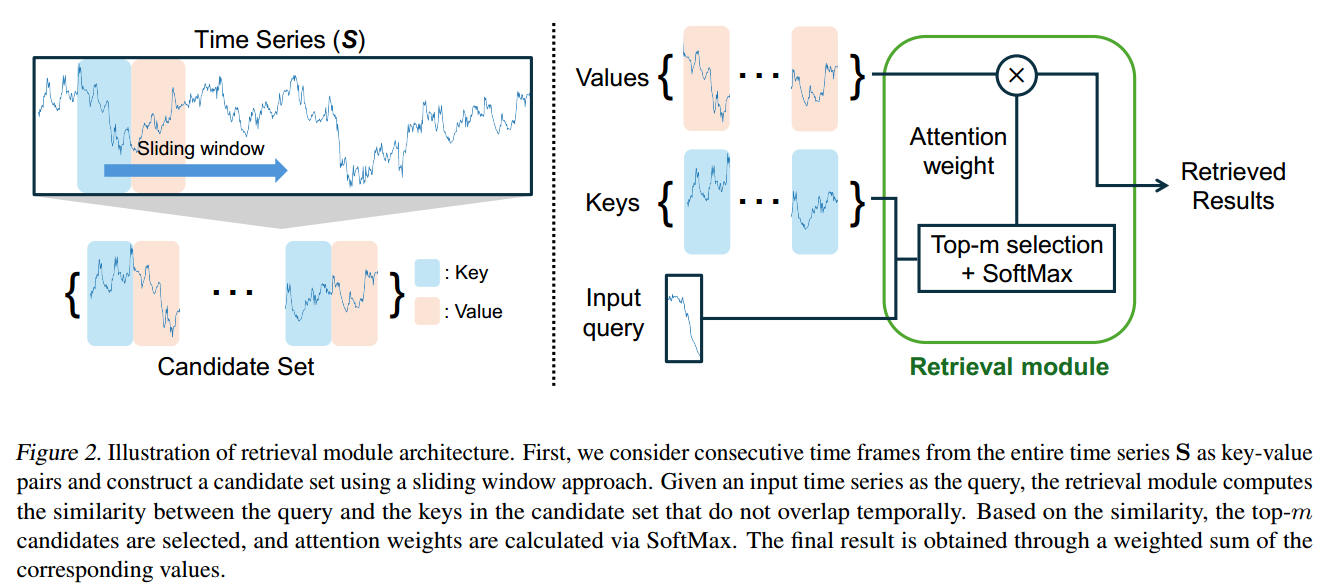
检索模块是 RAFT 的关键创新,它使用了一种类似注意力(attention-like)的结构来进行检索。
构建候选集(Key-Value Pairs)
首先,模型将完整的历史时间序列 转化为可供检索的候选集合:
Key 集合 (
): 使用步长为 1(或可调整以提高计算效率)的滑动窗口方法,从
的历史片段。 集合
中的每个
都是一个 Key 补丁。
排除重叠: 训练阶段 任何与当前输入
Value 集合 (
): 对于
,紧随其后的、窗口大小为
的时间片段被定义为对应的 Value
。
如果
被选中,这个
就是模型将用于预测的历史未来值。
数据预处理 (Offset Subtraction)
为了使 Patch比较 更具意义,并消除数值的绝对偏移影响,所有参与检索的 Patch 都进行标准化预处理:
机制: 将每个 Patch 的 最后一个时间步的值(
)视为偏移量 (offset)。
操作: 将这个偏移量从该片段中的所有时间步数值中减去。
对于查询
:
所有 Key
和 $\hat{V}$。
目的: 确保相似度比较侧重于时间序列的 形状 和 趋势,而不是绝对值的高低。
计算相似度与选择 (Top-m Selection)
使用经过预处理的输入 作为查询 (Query),与所有预处理后的 Key
进行比较:
相似度函数 (
): 采用皮尔逊相关系数 作为相似度函数
优势: 皮尔逊相关系数对 尺度变化 和 值偏移 不敏感,能够有效地捕获时间序列的增减趋势 (increasing and decreasing tendencies)。
Top-m 选择: 选出相似度
最高的
个 Key 及其对应的 Value。索引集合记为
。
加权求和(Weighted Sum)
检索到的 个历史未来值(Value Patch )被加权聚合,生成最终的检索结果
:
注意力权重 (
): 对 Top-m 的相关系数
。
其中,
是一个温度参数 (temperature
),用于控制权重的集中程度。
加权求和: 最终的检索结果
是所有 Value 补丁
的加权和:
就是从整个历史中提炼出的、与当前输入最相关的历史未来信息,将被送入后续的预测模块中。
Forecast with retrieval module
如何将检索到的历史信息与当前输入结合起来,生成最终的预测。分为单周期和多周期两种情况。
单周期预测 (Single period)
这是最基础的预测过程:
输入准备:
获取原始输入
和经过加权求和得到的检索结果
。
对
(即减去了
特征提取与投影:
输入特征
: 通过线性投影
将预处理后的输入
映射到预测长度
(即
)。
检索特征
: 通过线性投影
将检索结果
)。
特征融合与预测:
融合(拼接
): 将
的融合特征。
最终预测: 将融合特征送入一个线性预测器
(即
),得到去偏移量的预测结果
。
多周期预测 (Multiple periods)
为了捕获时间序列在不同尺度上的模式(局部模式 vs. 全局趋势),RAFT 引入了多周期检索:
多周期下采样:
定义一组周期
(例如
)。
对输入
和 Value 集合
进行平均池化 (average pooling) 下采样,得到
个不同周期下的序列。
对于每个周期
,得到相应的查询
、Key 集合
和 Value 集合
。
独立检索:
对每个周期
的下采样序列,都运行一个独立的检索模块。
得到
个周期下的检索结果
。
聚合:
投影: 每个
各不相同)都通过一个独立的线性层
,将它们投影到相同的嵌入空间
。
求和: 将所有投影后的检索结果求和 (Summation),形成最终的聚合检索特征
最终预测:
将输入特征
送入线性预测器
恢复偏移量与损失函数
无论是单周期还是多周期,模型都需要进行最后的处理和训练:
恢复偏移量: 预测结果
。
训练损失: 模型通过最小化预测值
之间的 均方误差(MSE)来训练。