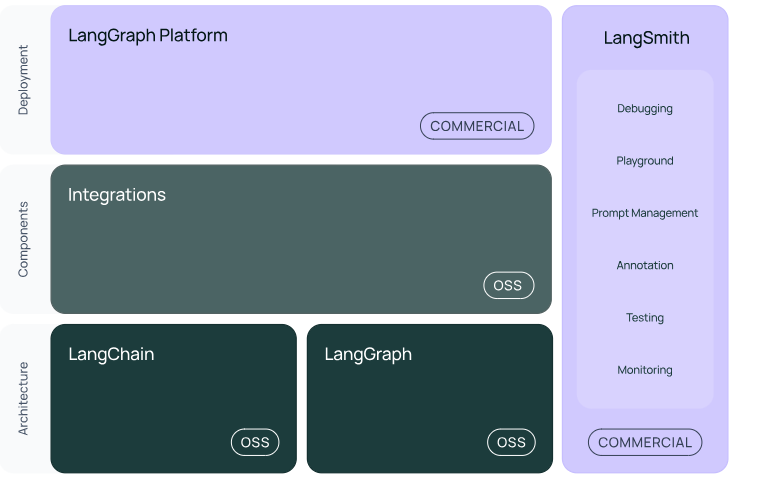
【大模型应用开发 6.LangChain多任务应用开发】
目录
一、LangChain的核心组件
1.模型I/O封装
Ⅰ、模型API:ChatModel
① OpenAI模型封装
② 多轮对话Session封装
③ 使用国产模型
④ 流式输出
2.模型的输入与输出
Ⅰ、Prompt模板封装
① PromptTemplate 可以在模板中自定义变量
② ChatPromptTemplate 用模板表示的对话上下文
③ 把多轮对话变成模板
Ⅱ、从文件加载Prompt模板
3.结构化输出
Ⅰ、直接输出Pydantic对象
Ⅱ、输出指定格式的JSON
Ⅲ、使用OutputParser
Ⅳ、使用PydanticOutputParser
Ⅴ、OutputFixingParser格式自动纠错
4.Function Calling
Ⅰ、Function Calling 成立的模型能力基础
Ⅱ、常见 Function Calling 的应用场景包括
Ⅲ、Calling是结果,理解和选择才是第一步
Ⅳ、代码演示
① 定义工具
② 调用工具
③ 回传Function Calling的结果
④ 结合Function Calling结果进行查询
二、数据连接封装
1.文档加载器:Document Loaders
2.文档处理器:TextSplitter
3.向量数据库与向量检索
4.代码示例
三、Chain和LangChain Expression Language
1.Pipeline 式调用 PromptTemplate, LLM 和 OutputParser
Ⅰ、LCEL 的一些亮点包括:
2.用 LCEL 实现 RAG
示例(加载并拆分)
3.用 LCEL 实现模型切换(工厂模式)
4.ICEL的其他功能
四、LangChain与LlamaIndex的错位竞争
总结
等下次 等不忙 等有钱 等有时间 等我们都不在彼此身边
—— 25.9.7
一、LangChain的核心组件
1.模型 I/O 封装
Chat Models:对语言模型接口的封装
PromptTemple:提示词模板
OutputParser:解析输出
2.数据连接封装(弱于 LlamaIndex)
Document Loaders:各种格式文件的加载器
Document Transformers:对文档的常用操作,如:split, filter, translate, extract metadata, etc
Text Embedding Models:文本向量化表示,用于检索等操作
Verctorstores & Retrievers:向量数据库与向量检索
3.架构封装
Chain/LCEL:实现一个功能或者一系列顺序功能组合
Agent:根据用户输入,自动规划执行步骤,自动选择每步需要的工具,最终完成用户指定的功能
Tools:调用外部功能的函数,例如:调 google 搜索、文件 I/O、Linux Shell 等等
LangGraph:工作流开发框架
4.LangSmith:过程监控与调试框架
1.模型I/O封装
把不同的模型,统一封装成一个接口,方便更换模型而不用重构代码。
Ⅰ、模型API:ChatModel
① OpenAI模型封装
清华源下载:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -U langchain-openai
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -U langchain
langchain:一个开源的大语言模型(LLM)应用开发框架,旨在简化基于大语言模型的复杂应用构建(如智能问答、RAG、AI 智能体、工具调用等)。
langchain.chat_models:langchain 框架下的子模块,专门用于处理 “聊天型大语言模型” 的交互逻辑。
model:LangChain 聊天模型实例,封装了与 OpenAI 服务交互的逻辑(如 API 调用、参数配置等),是后续调用 gpt-4o-mini 模型的 “入口对象”。
response:LangChain 的 AIMessage 实例(大语言模型的响应消息对象)。存储模型对输入查询(此处为 "你是谁")的完整响应信息,不仅包含文本内容,还可能包含元数据(如生成时间、token 数量等)。
response.content:字符串(str),AIMessage 对象的核心属性,存储模型生成的具体文本回复内容(即模型对查询的 “回答文字”)。
init_chat_model():通用型自定义函数,用于封装各类大语言模型(如 OpenAI GPT、Anthropic Claude、阿里云通义千问等)的初始化逻辑,统一处理模型配置、认证信息、生成规则等,最终返回一个可直接调用的聊天模型实例,减少重复代码并提升配置灵活性。
| 参数名 | 类型 | 默认值 | 是否必填 | 详细描述 |
|---|---|---|---|---|
model_provider | str | "openai" | 否 | 模型提供商,决定初始化的模型类型,常见值:"openai"(OpenAI)、"anthropic"(Anthropic)、"dashscope"(阿里云)、"baidu"(百度文心一言)等。 |
model_name | str | "gpt-3.5-turbo" | 否 | 具体模型名称,需与model_provider匹配:- OpenAI:"gpt-3.5-turbo"/"gpt-4";- 阿里云:"qwen-max"/"qwen-plus";- Anthropic:"claude-3-sonnet-20240229"。 |
api_key | str | None | 否 | 模型服务的 API 密钥,用于身份认证;若为None,默认从环境变量读取(需与model_provider对应,如 OpenAI 读OPENAI_API_KEY,阿里云读DASHSCOPE_API_KEY)。 |
base_url | str | None | 否 | 模型服务的自定义基础 URL(用于私有部署、代理服务或非官方接口):- OpenAI 默认:"https://api.openai.com/v1";- 阿里云通义千问兼容 URL:"https://dashscope.aliyuncs.com/compatible-mode/v1";- 若为None,使用对应提供商的默认 URL。 |
temperature | float | 0.7 | 否 | 生成文本的随机性控制:取值范围0.0~2.0;- 低值(如0.1~0.3):回复更严谨、确定;- 高值(如1.0~1.5):回复更多样、有创造性。 |
max_tokens | int | 2048 | 否 | 模型生成回复的最大 token 数(含输入 token + 输出 token),超过则截断;需根据模型上下文窗口设置(如 GPT-4 默认8192,qwen-max 支持128000)。 |
stop | List[str] 或 str | None | 否 | 生成终止符:当模型生成内容中出现指定字符串时,立即停止生成;- 示例:stop=["\n用户:", "### 结束"],避免模型模拟后续对话。 |
top_p | float | 1.0 | 否 | 采样阈值(核采样):取值范围0.0~1.0;- 仅保留概率和达到top_p的 token 参与采样(如0.9:仅用前 90% 概率的 token),与temperature配合控制生成多样性,通常不建议同时调整两者。 |
frequency_penalty | float | 0.0 | 否 | 重复内容惩罚:取值范围-2.0~2.0;- 正值(如0.5):降低模型生成重复内容的概率;- 负值(如-0.5):鼓励模型生成重复内容。 |
presence_penalty | float | 0.0 | 否 | 主题新颖性惩罚:取值范围-2.0~2.0;- 正值(如0.5):鼓励模型引入新主题、新词汇;- 负值(如-0.5):鼓励模型聚焦现有主题。 |
timeout | int | 30 | 否 | 模型请求的超时时间(单位:秒),超过时间未收到响应则抛出网络错误,避免长期阻塞。 |
max_retries | int | 2 | 否 | 请求失败后的重试次数(如网络波动、服务临时不可用),减少偶发错误影响。 |
tools | List[Tool] | None | 否 | 需绑定到模型的工具列表(如检索工具、函数调用工具),仅支持支持工具调用的模型(如 GPT-3.5-turbo-0613、qwen-max)。 |
tool_choice | str 或 dict | "auto" | 否 | 工具调用策略:- "auto":模型自主决定是否调用工具;- "none":强制不调用工具,仅生成文本回复;- 工具名(如"retriever_tool"):强制调用指定工具。 |
**kwargs | 任意 | - | 否 | 其他模型专属参数,如 Anthropic 的top_k、百度文心一言的penalty_score等,根据model_provider灵活传递。 |
.invoke():LangChain 框架中 Runnable 接口的通用调用方法(适用于聊天模型、检索器、向量库、状态图等),用于触发目标对象的核心逻辑,接收输入数据并返回处理结果;在聊天模型场景中,主要用于传入消息列表,生成 AI 回复。
| 参数名 | 类型 | 默认值 | 是否必填 | 详细描述 |
|---|---|---|---|---|
input | Sequence[BaseMessage] | 无 | 是 | 聊天模型的核心输入,必须是 BaseMessage 子类实例的列表(如 SystemMessage、HumanMessage、AIMessage、ToolMessage),包含对话上下文(系统提示、用户输入、历史回复、工具结果等)。 |
temperature | float | None | 否 | 临时覆盖模型初始化时的 temperature 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
max_tokens | int | None | 否 | 临时覆盖模型初始化时的 max_tokens 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
stop | List[str] 或 str | None | 否 | 临时覆盖模型初始化时的 stop 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
top_p | float | None | 否 | 临时覆盖模型初始化时的 top_p 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
frequency_penalty | float | None | 否 | 临时覆盖模型初始化时的 frequency_penalty 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
presence_penalty | float | None | 否 | 临时覆盖模型初始化时的 presence_penalty 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
metadata | dict | None | 否 | 附加的请求元数据,用于日志记录、追踪或模型服务的自定义标识(如请求 ID、用户 ID),部分模型服务支持通过元数据筛选日志。 |
timeout | int | None | 否 | 临时覆盖模型初始化时的 timeout 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
tools | List[Tool] | None | 否 | 临时绑定到模型的工具列表,仅在本次调用中生效,优先级高于初始化时绑定的工具;若为None,沿用模型初始化的工具配置。 |
tool_choice | str 或 dict | None | 否 | 临时覆盖模型初始化时的 tool_choice 配置,仅在本次调用中生效,优先级高于初始化值;若为None,沿用模型初始化的工具调用策略。 |
callbacks | List[BaseCallbackHandler] | None | 否 | 回调函数列表,用于监听调用过程中的事件(如请求发送、响应接收、错误发生),可实现日志打印、进度跟踪、结果存储等自定义逻辑。 |
tags | List[str] | None | 否 | 用于分类或筛选的标签列表(如 "chat"、"rag"、"debug"),可配合回调函数或日志系统,对不同类型的调用进行区分处理。 |
**kwargs | 任意 | - | 否 | 其他模型专属的临时参数(如 Anthropic 的stream、OpenAI 的user),根据模型支持的参数灵活传递,仅在本次调用中生效。 |
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-4o-mini", model_provider="openai")
response = model.invoke("你是谁")
print(response.content)② 多轮对话Session封装
langchain:一个开源的大语言模型(LLM)应用开发框架,旨在简化基于大语言模型的复杂应用构建(如智能问答、RAG、AI 智能体、工具调用等)。
langchain.schema:langchain 框架的核心数据结构模块,定义了 LLM 应用中最基础的数据类型(如消息、文档、工具调用格式等),是框架内各组件(模型、记忆、工具)之间 “数据传递的通用语言”。
messages:List[BaseMessage](LangChain 消息对象列表,包含 SystemMessage、HumanMessage、AIMessage),存储完整的多轮对话上下文,为模型提供 “角色定义、历史互动、当前问题” 的全部信息,确保模型生成符合语境的回复。
SystemMessage():创建 “系统提示消息”,用于向大语言模型传递角色定义、行为规则或背景信息,约束 AI 的回复逻辑(如 “你是专业的技术顾问,回答需基于文档内容”)。系统消息的优先级通常高于用户消息,会从全局影响 AI 的行为模式。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
content | str | 无 | 是 | 系统提示的核心文本内容,用于定义 AI 的角色、任务或规则。示例:"你是医疗知识助手,仅回答与医学相关的问题,避免猜测。" |
additional_kwargs | dict | {} | 否 | 附加元数据(键值对),用于存储与系统提示相关的额外信息(如提示的版本、适用场景等),不影响模型生成逻辑,仅用于日志或下游处理。示例:{"version": "1.0", "scene": "medical"} |
type | str | "system" | 否 | 消息类型标识,固定为 "system"(无需手动设置,类内部自动定义),用于区分消息来源。 |
HumanMessage():创建 “用户消息”,用于封装人类用户的输入内容(如查询、指令、补充信息等),是 AI 需要直接响应或处理的核心输入。在多轮对话中,所有用户输入均需包装为 HumanMessage 传递给模型。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
content | str | 无 | 是 | 用户输入的具体文本内容,即需要 AI 处理的查询或指令。示例:"什么是大语言模型的涌现能力?" |
additional_kwargs | dict | {} | 否 | 附加元数据,用于存储用户相关信息(如用户 ID、输入时间戳、会话 ID 等),便于多用户场景或会话跟踪。示例:{"user_id": "123", "timestamp": "2024-10-24 15:30"} |
type | str | "human" | 否 | 消息类型标识,固定为 "human"(无需手动设置,类内部自动定义),用于区分消息来源。 |
AIMessage():创建 “AI 回复消息”,用于封装大语言模型生成的输出内容(如对用户查询的回答、工具调用指令等)。在多轮对话中,AI 的回复会被包装为 AIMessage 存入对话历史,作为后续交互的上下文。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
content | str | 无 | 是 | AI 生成的具体文本回复内容,即对用户查询的直接回应。示例:"涌现能力是指大语言模型在规模达到一定阈值后,突然表现出的未被显式训练的能力..." |
additional_kwargs | dict | {} | 否 | 附加元数据,用于存储 AI 回复的相关信息(如生成时间、使用的模型版本等)。示例:{"model_used": "gpt-4o-mini", "generate_time": "2024-10-24 15:31"} |
tool_calls | Optional[List[ToolCall]] | None | 否 | 若 AI 调用了工具(如检索、函数调用),则存储工具调用指令列表(每个指令含工具名、参数、ID),仅支持工具调用的模型会有此内容。示例:[{"name": "retriever_tool", "args": {"query": "涌现能力定义"}, "id": "call_123"}] |
response_metadata | dict | {} | 否 | 模型返回的原始响应元数据(如 token 消耗、finish_reason 等),通常由模型调用接口自动填充。示例:{"token_usage": {"prompt_tokens": 50, "completion_tokens": 100}, "finish_reason": "stop"} |
type | str | "ai" | 否 | 消息类型标识,固定为 "ai"(无需手动设置,类内部自动定义),用于区分消息来源。 |
.invoke():LangChain 框架中 Runnable 接口的通用调用方法(适用于聊天模型、检索器、向量库、状态图等),用于触发目标对象的核心逻辑,接收输入数据并返回处理结果;在聊天模型场景中,主要用于传入消息列表,生成 AI 回复。
| 参数名 | 类型 | 默认值 | 是否必填 | 详细描述 |
|---|---|---|---|---|
input | Sequence[BaseMessage] | 无 | 是 | 聊天模型的核心输入,必须是 BaseMessage 子类实例的列表(如 SystemMessage、HumanMessage、AIMessage、ToolMessage),包含对话上下文(系统提示、用户输入、历史回复、工具结果等)。 |
temperature | float | None | 否 | 临时覆盖模型初始化时的 temperature 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
max_tokens | int | None | 否 | 临时覆盖模型初始化时的 max_tokens 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
stop | List[str] 或 str | None | 否 | 临时覆盖模型初始化时的 stop 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
top_p | float | None | 否 | 临时覆盖模型初始化时的 top_p 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
frequency_penalty | float | None | 否 | 临时覆盖模型初始化时的 frequency_penalty 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
presence_penalty | float | None | 否 | 临时覆盖模型初始化时的 presence_penalty 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
metadata | dict | None | 否 | 附加的请求元数据,用于日志记录、追踪或模型服务的自定义标识(如请求 ID、用户 ID),部分模型服务支持通过元数据筛选日志。 |
timeout | int | None | 否 | 临时覆盖模型初始化时的 timeout 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
tools | List[Tool] | None | 否 | 临时绑定到模型的工具列表,仅在本次调用中生效,优先级高于初始化时绑定的工具;若为None,沿用模型初始化的工具配置。 |
tool_choice | str 或 dict | None | 否 | 临时覆盖模型初始化时的 tool_choice 配置,仅在本次调用中生效,优先级高于初始化值;若为None,沿用模型初始化的工具调用策略。 |
callbacks | List[BaseCallbackHandler] | None | 否 | 回调函数列表,用于监听调用过程中的事件(如请求发送、响应接收、错误发生),可实现日志打印、进度跟踪、结果存储等自定义逻辑。 |
tags | List[str] | None | 否 | 用于分类或筛选的标签列表(如 "chat"、"rag"、"debug"),可配合回调函数或日志系统,对不同类型的调用进行区分处理。 |
**kwargs | 任意 | - | 否 | 其他模型专属的临时参数(如 Anthropic 的stream、OpenAI 的user),根据模型支持的参数灵活传递,仅在本次调用中生效。 |
ret:AIMessage 实例,承载模型对 messages 上下文的完整响应结果,不仅包含文本回复,还隐含模型生成过程中的元数据(如回复生成时间、token 消耗等,未显式调用时不外露)。
ret.content:str(字符串),AIMessage 对象的核心属性,存储模型生成的具体文本回复内容,即用户最终能看到的 AI 回答。
from langchain.schema import (AIMessage, # 等价于OpenAI接口中的assistant roleHumanMessage, # 等价于OpenAI接口中的user roleSystemMessage # 等价于OpenAI接口中的system role
)messages = [SystemMessage(content="你是聚客AI大模型课的课程助理。"),HumanMessage(content="我是学员,我叫小聚。"),AIMessage(content="欢迎!"),HumanMessage(content="我是谁?")
]ret = model.invoke(messages)print(ret.content)③ 使用国产模型
清华源下载:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -U langchain-deepseek
langchain:一个开源的大语言模型(LLM)应用开发框架,旨在简化基于大语言模型的复杂应用构建(如智能问答、RAG、AI 智能体、工具调用等)。
langchain.chat_models:langchain 框架下的子模块,专门用于处理 “聊天型大语言模型” 的交互逻辑。
model:封装了与 DeepSeek 模型服务交互的逻辑(如 API 调用、身份验证、参数配置等),是后续调用 deepseek-chat 模型的 “操作入口”。
init_chat_model():通用型自定义函数,用于封装各类大语言模型(如 OpenAI GPT、Anthropic Claude、阿里云通义千问等)的初始化逻辑,统一处理模型配置、认证信息、生成规则等,最终返回一个可直接调用的聊天模型实例,减少重复代码并提升配置灵活性。
| 参数名 | 类型 | 默认值 | 是否必填 | 详细描述 |
|---|---|---|---|---|
model_provider | str | "openai" | 否 | 模型提供商,决定初始化的模型类型,常见值:"openai"(OpenAI)、"anthropic"(Anthropic)、"dashscope"(阿里云)、"baidu"(百度文心一言)等。 |
model_name | str | "gpt-3.5-turbo" | 否 | 具体模型名称,需与model_provider匹配:- OpenAI:"gpt-3.5-turbo"/"gpt-4";- 阿里云:"qwen-max"/"qwen-plus";- Anthropic:"claude-3-sonnet-20240229"。 |
api_key | str | None | 否 | 模型服务的 API 密钥,用于身份认证;若为None,默认从环境变量读取(需与model_provider对应,如 OpenAI 读OPENAI_API_KEY,阿里云读DASHSCOPE_API_KEY)。 |
base_url | str | None | 否 | 模型服务的自定义基础 URL(用于私有部署、代理服务或非官方接口):- OpenAI 默认:"https://api.openai.com/v1";- 阿里云通义千问兼容 URL:"https://dashscope.aliyuncs.com/compatible-mode/v1";- 若为None,使用对应提供商的默认 URL。 |
temperature | float | 0.7 | 否 | 生成文本的随机性控制:取值范围0.0~2.0;- 低值(如0.1~0.3):回复更严谨、确定;- 高值(如1.0~1.5):回复更多样、有创造性。 |
max_tokens | int | 2048 | 否 | 模型生成回复的最大 token 数(含输入 token + 输出 token),超过则截断;需根据模型上下文窗口设置(如 GPT-4 默认8192,qwen-max 支持128000)。 |
stop | List[str] 或 str | None | 否 | 生成终止符:当模型生成内容中出现指定字符串时,立即停止生成;- 示例:stop=["\n用户:", "### 结束"],避免模型模拟后续对话。 |
top_p | float | 1.0 | 否 | 采样阈值(核采样):取值范围0.0~1.0;- 仅保留概率和达到top_p的 token 参与采样(如0.9:仅用前 90% 概率的 token),与temperature配合控制生成多样性,通常不建议同时调整两者。 |
frequency_penalty | float | 0.0 | 否 | 重复内容惩罚:取值范围-2.0~2.0;- 正值(如0.5):降低模型生成重复内容的概率;- 负值(如-0.5):鼓励模型生成重复内容。 |
presence_penalty | float | 0.0 | 否 | 主题新颖性惩罚:取值范围-2.0~2.0;- 正值(如0.5):鼓励模型引入新主题、新词汇;- 负值(如-0.5):鼓励模型聚焦现有主题。 |
timeout | int | 30 | 否 | 模型请求的超时时间(单位:秒),超过时间未收到响应则抛出网络错误,避免长期阻塞。 |
max_retries | int | 2 | 否 | 请求失败后的重试次数(如网络波动、服务临时不可用),减少偶发错误影响。 |
tools | List[Tool] | None | 否 | 需绑定到模型的工具列表(如检索工具、函数调用工具),仅支持支持工具调用的模型(如 GPT-3.5-turbo-0613、qwen-max)。 |
tool_choice | str 或 dict | "auto" | 否 | 工具调用策略:- "auto":模型自主决定是否调用工具;- "none":强制不调用工具,仅生成文本回复;- 工具名(如"retriever_tool"):强制调用指定工具。 |
**kwargs | 任意 | - | 否 | 其他模型专属参数,如 Anthropic 的top_k、百度文心一言的penalty_score等,根据model_provider灵活传递。 |
.invoke():LangChain 框架中 Runnable 接口的通用调用方法(适用于聊天模型、检索器、向量库、状态图等),用于触发目标对象的核心逻辑,接收输入数据并返回处理结果;在聊天模型场景中,主要用于传入消息列表,生成 AI 回复。
| 参数名 | 类型 | 默认值 | 是否必填 | 详细描述 |
|---|---|---|---|---|
input | Sequence[BaseMessage] | 无 | 是 | 聊天模型的核心输入,必须是 BaseMessage 子类实例的列表(如 SystemMessage、HumanMessage、AIMessage、ToolMessage),包含对话上下文(系统提示、用户输入、历史回复、工具结果等)。 |
temperature | float | None | 否 | 临时覆盖模型初始化时的 temperature 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
max_tokens | int | None | 否 | 临时覆盖模型初始化时的 max_tokens 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
stop | List[str] 或 str | None | 否 | 临时覆盖模型初始化时的 stop 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
top_p | float | None | 否 | 临时覆盖模型初始化时的 top_p 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
frequency_penalty | float | None | 否 | 临时覆盖模型初始化时的 frequency_penalty 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
presence_penalty | float | None | 否 | 临时覆盖模型初始化时的 presence_penalty 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
metadata | dict | None | 否 | 附加的请求元数据,用于日志记录、追踪或模型服务的自定义标识(如请求 ID、用户 ID),部分模型服务支持通过元数据筛选日志。 |
timeout | int | None | 否 | 临时覆盖模型初始化时的 timeout 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
tools | List[Tool] | None | 否 | 临时绑定到模型的工具列表,仅在本次调用中生效,优先级高于初始化时绑定的工具;若为None,沿用模型初始化的工具配置。 |
tool_choice | str 或 dict | None | 否 | 临时覆盖模型初始化时的 tool_choice 配置,仅在本次调用中生效,优先级高于初始化值;若为None,沿用模型初始化的工具调用策略。 |
callbacks | List[BaseCallbackHandler] | None | 否 | 回调函数列表,用于监听调用过程中的事件(如请求发送、响应接收、错误发生),可实现日志打印、进度跟踪、结果存储等自定义逻辑。 |
tags | List[str] | None | 否 | 用于分类或筛选的标签列表(如 "chat"、"rag"、"debug"),可配合回调函数或日志系统,对不同类型的调用进行区分处理。 |
**kwargs | 任意 | - | 否 | 其他模型专属的临时参数(如 Anthropic 的stream、OpenAI 的user),根据模型支持的参数灵活传递,仅在本次调用中生效。 |
response:LangChain 的 AIMessage 实例,存储 deepseek-chat 模型对输入查询的完整响应信息,不仅包含文本回复,还可能包含元数据(如生成时间、token 消耗等)。
response.content:字符串(str),AIMessage 对象的核心属性,存储 deepseek-chat 模型生成的具体文本回复内容(即模型对查询的自然语言回答)。
from langchain.chat_models import init_chat_modelmodel = init_chat_model(model="deepseek-chat", model_provider="deepseek")response = model.invoke("你是谁")
print(response.content)
④ 流式输出
model:封装了与 DeepSeek 模型服务交互的逻辑(如 API 调用、身份验证、参数配置等),是后续调用 deepseek-chat 模型的 “操作入口”。
token:LangChain 中的 AIMessageChunk 实例,示模型流式输出的单个文本片段对象。当调用 model.stream(...) 时,模型不会一次性返回完整回复,而是将回复拆分成多个连续的小片段(类似 “打字效果”),每个片段就是一个 token。
model.stream():LangChain 聊天模型实例(如通过 init_chat_model 初始化的模型)的流式响应方法,用于实现 “模型生成回复时逐段返回结果” 的效果。与 model.invoke() 一次性返回完整回复不同,stream() 会将回复拆分为多个连续的文本片段(AIMessageChunk),通过迭代器逐段输出,模拟 “实时打字” 的交互体验,提升用户对长回复的等待体验(常见于聊天界面、实时问答场景)。
| 参数名 | 类型 | 默认值 | 是否必填 | 详细描述 |
|---|---|---|---|---|
input | str 或 Sequence[BaseMessage] | 无 | 是 | 模型的输入内容:- 若为 str:直接作为用户查询文本(等效于 HumanMessage(content=input));- 若为 Sequence[BaseMessage]:消息列表(含 SystemMessage、HumanMessage 等),支持多轮对话上下文。示例:"你是谁" 或 [HumanMessage(content="你是谁")]。 |
temperature | float | None | 否 | 临时覆盖模型初始化时的随机性参数(0.0~2.0),优先级高于模型默认值;None 则沿用模型初始化配置。 |
max_tokens | int | None | 否 | 临时覆盖模型生成的最大 token 数限制,优先级高于模型默认值;None 则沿用模型初始化配置。 |
stop | List[str] 或 str | None | 否 | 临时覆盖模型的生成终止符,当片段中出现指定字符串时停止生成;None 则沿用模型初始化配置。 |
stream_options | dict | {"include_usage": False} | 否 | 流式输出的额外配置:- include_usage(bool):是否在最后一个片段中包含 token 消耗统计(如 {"usage": {"prompt_tokens": 10, "completion_tokens": 20}});- chunk_size(int):部分模型支持指定每个片段的最大字符数(默认由模型自动决定)。 |
callbacks | List[BaseCallbackHandler] | None | 否 | 回调函数列表,用于监听流式输出过程中的事件(如片段生成、结束、错误),可实现日志记录、进度更新等。 |
tags | List[str] | None | 否 | 用于分类的标签列表(如 "stream_chat"、"user_123"),便于后续追踪或筛选该次流式调用。 |
**kwargs | 任意 | - | 否 | 其他模型专属的流式参数(如部分模型支持 stream_timeout 控制超时时间),根据模型提供商的 API 扩展。 |
token.content:str(字符串),AIMessageChunk 对象的核心属性,存储当前流式片段的具体文本内容(即模型实时生成的部分回复文字)。
for token in model.stream("你是谁"):print(token.content, end="")2.模型的输入与输出
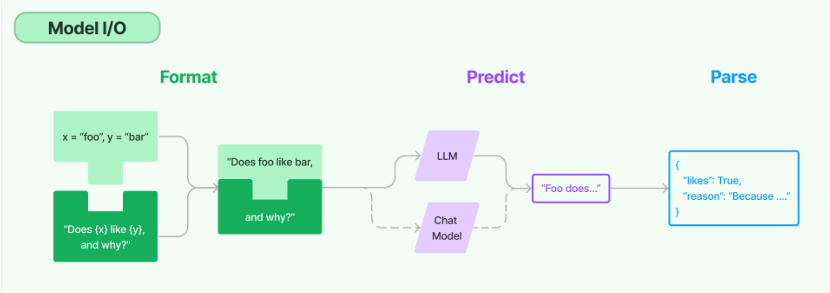
Ⅰ、Prompt模板封装
① PromptTemplate 可以在模板中自定义变量
langchain:开源的大语言模型(LLM)应用开发框架,核心目标是简化 “模型 + 工具 + 数据” 协同应用的构建(如智能问答、RAG、AI 智能体等)。
langchain.prompts:langchain 框架下的提示词管理子模块,专门用于处理 “提示词的创建、格式化、复用”,解决提示词硬编码、动态参数拼接、模板化管理等问题。
langchain.prompts.PromptTemplate:langchain.prompts 子模块中的核心类,用于创建 “带变量占位符的提示词模板”,支持通过动态参数替换生成具体提示词,是构建结构化提示词的基础工具。
langchain.chat_models:LangChain 框架中专门用于处理聊天模型(Chat Models) 的核心模块,提供了统一的接口来调用各类主流大语言模型(如 GPT、DeepSeek、通义通千问等),支持对话交互、流式输出、工具调用等功能。
template:存储 “结构化的提示词模板”,通过预留的 {subject} 变量占位符,实现 “固定提示词框架 + 动态参数替换”,避免手动拼接提示词的繁琐,确保提示词格式统一。
PromptTemplate.from_template():PromptTemplate 类的类方法,用于从模板字符串快速创建 PromptTemplate 实例。与直接初始化 PromptTemplate 相比,它会自动解析模板中的变量占位符(如 {variable}),无需手动声明 input_variables,简化了模板创建流程。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
template | str | 无 | 是 | 提示词模板字符串,包含 {变量名} 形式的占位符(如 "请解释{concept}的定义:")。方法会自动提取这些变量作为 input_variables。 |
template_format | str | "f-string" | 否 | 模板格式:"f-string"(默认,Python 风格的 {变量})或 "jinja2"(支持条件、循环等复杂语法)。 |
validate_template | bool | True | 否 | 是否校验模板合法性:True 时会检查模板中的占位符是否符合格式(如是否有未闭合的 { 或 }),不合法则抛错;False 则跳过校验。 |
template.format():PromptTemplate 实例的方法,用于将模板中的变量占位符替换为具体值,生成最终可直接传给模型的提示词字符串。会自动校验传入的参数是否与 input_variables 匹配(缺失或多余变量会抛错),确保提示词完整性。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
**kwargs(动态参数) | 任意 | 无 | 是 | 需替换到模板中的变量值,键名必须与 input_variables 中的变量名一致。示例:若 input_variables=["user", "question"],则需传入 user="小聚"、question="什么是LLM"。 |
llm:LangChain 聊天模型实例,封装与 DeepSeek 模型服务交互的全部逻辑(如 API 身份验证、请求发送、响应接收),是调用 deepseek-chat 模型生成结果的 “操作入口”。
init_chat_model():通用型自定义函数,用于封装各类大语言模型(如 OpenAI GPT、Anthropic Claude、阿里云通义千问等)的初始化逻辑,统一处理模型配置、认证信息、生成规则等,最终返回一个可直接调用的聊天模型实例,减少重复代码并提升配置灵活性。
| 参数名 | 类型 | 默认值 | 是否必填 | 详细描述 |
|---|---|---|---|---|
model_provider | str | "openai" | 否 | 模型提供商,决定初始化的模型类型,常见值:"openai"(OpenAI)、"anthropic"(Anthropic)、"dashscope"(阿里云)、"baidu"(百度文心一言)等。 |
model_name | str | "gpt-3.5-turbo" | 否 | 具体模型名称,需与model_provider匹配:- OpenAI:"gpt-3.5-turbo"/"gpt-4";- 阿里云:"qwen-max"/"qwen-plus";- Anthropic:"claude-3-sonnet-20240229"。 |
api_key | str | None | 否 | 模型服务的 API 密钥,用于身份认证;若为None,默认从环境变量读取(需与model_provider对应,如 OpenAI 读OPENAI_API_KEY,阿里云读DASHSCOPE_API_KEY)。 |
base_url | str | None | 否 | 模型服务的自定义基础 URL(用于私有部署、代理服务或非官方接口):- OpenAI 默认:"https://api.openai.com/v1";- 阿里云通义千问兼容 URL:"https://dashscope.aliyuncs.com/compatible-mode/v1";- 若为None,使用对应提供商的默认 URL。 |
temperature | float | 0.7 | 否 | 生成文本的随机性控制:取值范围0.0~2.0;- 低值(如0.1~0.3):回复更严谨、确定;- 高值(如1.0~1.5):回复更多样、有创造性。 |
max_tokens | int | 2048 | 否 | 模型生成回复的最大 token 数(含输入 token + 输出 token),超过则截断;需根据模型上下文窗口设置(如 GPT-4 默认8192,qwen-max 支持128000)。 |
stop | List[str] 或 str | None | 否 | 生成终止符:当模型生成内容中出现指定字符串时,立即停止生成;- 示例:stop=["\n用户:", "### 结束"],避免模型模拟后续对话。 |
top_p | float | 1.0 | 否 | 采样阈值(核采样):取值范围0.0~1.0;- 仅保留概率和达到top_p的 token 参与采样(如0.9:仅用前 90% 概率的 token),与temperature配合控制生成多样性,通常不建议同时调整两者。 |
frequency_penalty | float | 0.0 | 否 | 重复内容惩罚:取值范围-2.0~2.0;- 正值(如0.5):降低模型生成重复内容的概率;- 负值(如-0.5):鼓励模型生成重复内容。 |
presence_penalty | float | 0.0 | 否 | 主题新颖性惩罚:取值范围-2.0~2.0;- 正值(如0.5):鼓励模型引入新主题、新词汇;- 负值(如-0.5):鼓励模型聚焦现有主题。 |
timeout | int | 30 | 否 | 模型请求的超时时间(单位:秒),超过时间未收到响应则抛出网络错误,避免长期阻塞。 |
max_retries | int | 2 | 否 | 请求失败后的重试次数(如网络波动、服务临时不可用),减少偶发错误影响。 |
tools | List[Tool] | None | 否 | 需绑定到模型的工具列表(如检索工具、函数调用工具),仅支持支持工具调用的模型(如 GPT-3.5-turbo-0613、qwen-max)。 |
tool_choice | str 或 dict | "auto" | 否 | 工具调用策略:- "auto":模型自主决定是否调用工具;- "none":强制不调用工具,仅生成文本回复;- 工具名(如"retriever_tool"):强制调用指定工具。 |
**kwargs | 任意 | - | 否 | 其他模型专属参数,如 Anthropic 的top_k、百度文心一言的penalty_score等,根据model_provider灵活传递。 |
ret:LangChain 的 AIMessage 实例,存储 deepseek-chat 模型对输入查询("你是谁")的完整响应信息,不仅包含文本回复,还可能包含元数据(如生成时间、token 消耗等)。
.invoke():LangChain 框架中 Runnable 接口的通用调用方法(适用于聊天模型、检索器、向量库、状态图等),用于触发目标对象的核心逻辑,接收输入数据并返回处理结果;在聊天模型场景中,主要用于传入消息列表,生成 AI 回复。
| 参数名 | 类型 | 默认值 | 是否必填 | 详细描述 |
|---|---|---|---|---|
input | Sequence[BaseMessage] | 无 | 是 | 聊天模型的核心输入,必须是 BaseMessage 子类实例的列表(如 SystemMessage、HumanMessage、AIMessage、ToolMessage),包含对话上下文(系统提示、用户输入、历史回复、工具结果等)。 |
temperature | float | None | 否 | 临时覆盖模型初始化时的 temperature 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
max_tokens | int | None | 否 | 临时覆盖模型初始化时的 max_tokens 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
stop | List[str] 或 str | None | 否 | 临时覆盖模型初始化时的 stop 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
top_p | float | None | 否 | 临时覆盖模型初始化时的 top_p 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
frequency_penalty | float | None | 否 | 临时覆盖模型初始化时的 frequency_penalty 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
presence_penalty | float | None | 否 | 临时覆盖模型初始化时的 presence_penalty 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
metadata | dict | None | 否 | 附加的请求元数据,用于日志记录、追踪或模型服务的自定义标识(如请求 ID、用户 ID),部分模型服务支持通过元数据筛选日志。 |
timeout | int | None | 否 | 临时覆盖模型初始化时的 timeout 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
tools | List[Tool] | None | 否 | 临时绑定到模型的工具列表,仅在本次调用中生效,优先级高于初始化时绑定的工具;若为None,沿用模型初始化的工具配置。 |
tool_choice | str 或 dict | None | 否 | 临时覆盖模型初始化时的 tool_choice 配置,仅在本次调用中生效,优先级高于初始化值;若为None,沿用模型初始化的工具调用策略。 |
callbacks | List[BaseCallbackHandler] | None | 否 | 回调函数列表,用于监听调用过程中的事件(如请求发送、响应接收、错误发生),可实现日志打印、进度跟踪、结果存储等自定义逻辑。 |
tags | List[str] | None | 否 | 用于分类或筛选的标签列表(如 "chat"、"rag"、"debug"),可配合回调函数或日志系统,对不同类型的调用进行区分处理。 |
**kwargs | 任意 | - | 否 | 其他模型专属的临时参数(如 Anthropic 的stream、OpenAI 的user),根据模型支持的参数灵活传递,仅在本次调用中生效。 |
ret.content:str(字符串),AIMessageChunk 对象的核心属性,存储当前流式片段的具体文本内容(即模型实时生成的部分回复文字)。
from langchain.prompts import PromptTemplatetemplate = PromptTemplate.from_template("给我讲个关于{subject}的笑话")
print("===Template===")
print(template)
print("===Prompt===")
print(template.format(subject='小明'))from langchain.chat_models import init_chat_model# 定义 LLM
llm = init_chat_model("deepseek-chat", model_provider="deepseek")
# 通过 Prompt 调用 LLM
ret = llm.invoke(template.format(subject='小明'))
# 打印输出
print(ret.content)② ChatPromptTemplate 用模板表示的对话上下文
langchain:开源的大语言模型(LLM)应用开发框架,核心目标是简化 “模型 + 工具 + 数据” 协同应用的构建(如智能问答、RAG、AI 智能体等)。
langchain.prompts:langchain 框架下的提示词管理子模块,专门用于处理 “提示词的创建、格式化、复用”,解决提示词硬编码、动态参数拼接、模板化管理等问题。
langchain.prompts.PromptTemplate:langchain.prompts 子模块中的核心类,用于创建 “带变量占位符的提示词模板”,支持通过动态参数替换生成具体提示词,是构建结构化提示词的基础工具。
langchain.prompts.HumanMessagePromptTemplate:生成 “用户消息(HumanMessage)的模板”,用于将动态内容(如用户输入的变量)与固定文本结合,生成结构化的 HumanMessage 实例。相比直接手动创建 HumanMessage,它支持通过变量动态替换内容,更适合需要根据上下文生成用户消息的场景(如多轮对话中动态插入用户的新输入)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
prompt | PromptTemplate | 无 | 是 | 基础提示词模板(PromptTemplate 实例),包含用户消息的固定结构和变量占位符(如 PromptTemplate.from_template("用户问:{question}"))。 |
additional_kwargs | dict | {} | 否 | 附加元数据,会被传递到生成的 HumanMessage 实例中(如用户 ID、时间戳等),格式为键值对。 |
langchain.prompts.SystemMessagePromptTemplate:生成 “系统消息(SystemMessage)的模板”,用于将动态配置(如角色参数、场景变量)与固定系统指令结合,生成结构化的 SystemMessage 实例。适合需要根据不同场景动态调整系统提示的场景(如切换 AI 角色、修改回答规则)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
prompt | PromptTemplate | 无 | 是 | 基础提示词模板(PromptTemplate 实例),包含系统指令的固定结构和变量占位符(如 PromptTemplate.from_template("你是{role},需{rule}"))。 |
additional_kwargs | dict | {} | 否 | 附加元数据,会被传递到生成的 SystemMessage 实例中(如提示版本、场景标识等),格式为键值对。 |
langchain:一个开源的大语言模型(LLM)应用开发框架,旨在简化基于大语言模型的复杂应用构建(如智能问答、RAG、AI 智能体、工具调用等)。
langchain.chat_models:langchain 框架下的子模块,专门用于处理 “聊天型大语言模型” 的交互逻辑。
model:封装了与 DeepSeek 模型服务交互的逻辑。
llm:LangChain 聊天模型实例,封装与 DeepSeek 模型服务交互的全部逻辑(如 API 身份验证、请求发送、响应接收),是调用 deepseek-chat 模型生成结果的 “操作入口”。
init_chat_model():通用型自定义函数,用于封装各类大语言模型(如 OpenAI GPT、Anthropic Claude、阿里云通义千问等)的初始化逻辑,统一处理模型配置、认证信息、生成规则等,最终返回一个可直接调用的聊天模型实例,减少重复代码并提升配置灵活性。
| 参数名 | 类型 | 默认值 | 是否必填 | 详细描述 |
|---|---|---|---|---|
model_provider | str | "openai" | 否 | 模型提供商,决定初始化的模型类型,常见值:"openai"(OpenAI)、"anthropic"(Anthropic)、"dashscope"(阿里云)、"baidu"(百度文心一言)等。 |
model_name | str | "gpt-3.5-turbo" | 否 | 具体模型名称,需与model_provider匹配:- OpenAI:"gpt-3.5-turbo"/"gpt-4";- 阿里云:"qwen-max"/"qwen-plus";- Anthropic:"claude-3-sonnet-20240229"。 |
api_key | str | None | 否 | 模型服务的 API 密钥,用于身份认证;若为None,默认从环境变量读取(需与model_provider对应,如 OpenAI 读OPENAI_API_KEY,阿里云读DASHSCOPE_API_KEY)。 |
base_url | str | None | 否 | 模型服务的自定义基础 URL(用于私有部署、代理服务或非官方接口):- OpenAI 默认:"https://api.openai.com/v1";- 阿里云通义千问兼容 URL:"https://dashscope.aliyuncs.com/compatible-mode/v1";- 若为None,使用对应提供商的默认 URL。 |
temperature | float | 0.7 | 否 | 生成文本的随机性控制:取值范围0.0~2.0;- 低值(如0.1~0.3):回复更严谨、确定;- 高值(如1.0~1.5):回复更多样、有创造性。 |
max_tokens | int | 2048 | 否 | 模型生成回复的最大 token 数(含输入 token + 输出 token),超过则截断;需根据模型上下文窗口设置(如 GPT-4 默认8192,qwen-max 支持128000)。 |
stop | List[str] 或 str | None | 否 | 生成终止符:当模型生成内容中出现指定字符串时,立即停止生成;- 示例:stop=["\n用户:", "### 结束"],避免模型模拟后续对话。 |
top_p | float | 1.0 | 否 | 采样阈值(核采样):取值范围0.0~1.0;- 仅保留概率和达到top_p的 token 参与采样(如0.9:仅用前 90% 概率的 token),与temperature配合控制生成多样性,通常不建议同时调整两者。 |
frequency_penalty | float | 0.0 | 否 | 重复内容惩罚:取值范围-2.0~2.0;- 正值(如0.5):降低模型生成重复内容的概率;- 负值(如-0.5):鼓励模型生成重复内容。 |
presence_penalty | float | 0.0 | 否 | 主题新颖性惩罚:取值范围-2.0~2.0;- 正值(如0.5):鼓励模型引入新主题、新词汇;- 负值(如-0.5):鼓励模型聚焦现有主题。 |
timeout | int | 30 | 否 | 模型请求的超时时间(单位:秒),超过时间未收到响应则抛出网络错误,避免长期阻塞。 |
max_retries | int | 2 | 否 | 请求失败后的重试次数(如网络波动、服务临时不可用),减少偶发错误影响。 |
tools | List[Tool] | None | 否 | 需绑定到模型的工具列表(如检索工具、函数调用工具),仅支持支持工具调用的模型(如 GPT-3.5-turbo-0613、qwen-max)。 |
tool_choice | str 或 dict | "auto" | 否 | 工具调用策略:- "auto":模型自主决定是否调用工具;- "none":强制不调用工具,仅生成文本回复;- 工具名(如"retriever_tool"):强制调用指定工具。 |
**kwargs | 任意 | - | 否 | 其他模型专属参数,如 Anthropic 的top_k、百度文心一言的penalty_score等,根据model_provider灵活传递。 |
template:存储 “结构化的提示词模板”,通过预留的 {subject} 变量占位符,实现 “固定提示词框架 + 动态参数替换”,避免手动拼接提示词的繁琐,确保提示词格式统一。
prompt:List[BaseMessage](SystemMessage 和 HumanMessage 组成的列表,即结构化的消息对象列表)。作为模型的完整输入上下文,包含系统提示(定义 AI 角色)和用户查询(需要 AI 响应的问题),确保模型明确自身角色和用户需求。
ChatPromptTemplate.from_messages():ChatPromptTemplate 类的类方法,用于整合多个消息模板(或消息字符串),创建一个包含多角色的聊天提示词模板。支持将 SystemMessagePromptTemplate、HumanMessagePromptTemplate 等不同角色的模板组合成一个整体,生成可动态替换变量的结构化提示词模板,最终用于生成完整的对话上下文消息列表。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
messages | List[Union[BaseMessagePromptTemplate, str, Tuple[str, str]]] | 无 | 是 | 消息模板列表,支持三种元素类型:- BaseMessagePromptTemplate:如 SystemMessagePromptTemplate、HumanMessagePromptTemplate(带变量的消息模板);- str:纯文本消息(默认视为 HumanMessage);- Tuple[str, str]:元组 (角色标识, 文本),角色标识支持 "system"/"human"/"ai"(如 ("system", "你是助手") 等价于 SystemMessage)。 |
.from_template():ChatPromptTemplate 类的简化类方法,用于从单一字符串模板快速创建聊天提示词模板,默认将模板视为 “人类消息(HumanMessage)”,适合仅需单一角色(用户)提示词的场景,避免手动创建 HumanMessagePromptTemplate 的繁琐。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
template | str | 无 | 是 | 字符串模板,含变量占位符(如 "请分析{text}的情感倾向"),默认作为人类消息的内容。 |
template_format | str | "f-string" | 否 | 模板格式:"f-string"(默认)或 "jinja2",与 PromptTemplate 一致。 |
validate_template | bool | True | 否 | 是否校验模板合法性(如占位符格式),不合法则抛错。 |
.format_messages():ChatPromptTemplate 实例的方法,用于将模板中的所有变量替换为具体值,生成结构化的消息对象列表(SystemMessage/HumanMessage 等实例),可直接作为模型 invoke 或 stream 方法的 messages 参数,无需手动转换格式。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
**kwargs(动态参数) | 任意 | 无 | 是 | 需替换到模板中的变量值,键名必须与 input_variables 中的变量名一致。示例:若 input_variables=["topic", "question"],则需传入 topic="AI"、question="什么是RAG"。 |
ret:AIMessage 实例,存储模型(gpt-4o-mini)对输入 prompt 的完整响应结果,不仅包含文本回复,还隐含生成过程的元数据(如 token 消耗、生成时间等,未显式展示)。
.invoke():LangChain 框架中 Runnable 接口的通用调用方法(适用于聊天模型、检索器、向量库、状态图等),用于触发目标对象的核心逻辑,接收输入数据并返回处理结果;在聊天模型场景中,主要用于传入消息列表,生成 AI 回复。
| 参数名 | 类型 | 默认值 | 是否必填 | 详细描述 |
|---|---|---|---|---|
input | Sequence[BaseMessage] | 无 | 是 | 聊天模型的核心输入,必须是 BaseMessage 子类实例的列表(如 SystemMessage、HumanMessage、AIMessage、ToolMessage),包含对话上下文(系统提示、用户输入、历史回复、工具结果等)。 |
temperature | float | None | 否 | 临时覆盖模型初始化时的 temperature 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
max_tokens | int | None | 否 | 临时覆盖模型初始化时的 max_tokens 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
stop | List[str] 或 str | None | 否 | 临时覆盖模型初始化时的 stop 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
top_p | float | None | 否 | 临时覆盖模型初始化时的 top_p 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
frequency_penalty | float | None | 否 | 临时覆盖模型初始化时的 frequency_penalty 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
presence_penalty | float | None | 否 | 临时覆盖模型初始化时的 presence_penalty 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
metadata | dict | None | 否 | 附加的请求元数据,用于日志记录、追踪或模型服务的自定义标识(如请求 ID、用户 ID),部分模型服务支持通过元数据筛选日志。 |
timeout | int | None | 否 | 临时覆盖模型初始化时的 timeout 配置,优先级高于初始化值;若为None,沿用模型初始化的默认值。 |
tools | List[Tool] | None | 否 | 临时绑定到模型的工具列表,仅在本次调用中生效,优先级高于初始化时绑定的工具;若为None,沿用模型初始化的工具配置。 |
tool_choice | str 或 dict | None | 否 | 临时覆盖模型初始化时的 tool_choice 配置,仅在本次调用中生效,优先级高于初始化值;若为None,沿用模型初始化的工具调用策略。 |
callbacks | List[BaseCallbackHandler] | None | 否 | 回调函数列表,用于监听调用过程中的事件(如请求发送、响应接收、错误发生),可实现日志打印、进度跟踪、结果存储等自定义逻辑。 |
tags | List[str] | None | 否 | 用于分类或筛选的标签列表(如 "chat"、"rag"、"debug"),可配合回调函数或日志系统,对不同类型的调用进行区分处理。 |
**kwargs | 任意 | - | 否 | 其他模型专属的临时参数(如 Anthropic 的stream、OpenAI 的user),根据模型支持的参数灵活传递,仅在本次调用中生效。 |
ret.content:str(字符串),AIMessage 对象的核心属性,存储模型生成的具体文本回复内容(即用户最终看到的 AI 回答)。
from langchain.prompts import (ChatPromptTemplate,HumanMessagePromptTemplate,SystemMessagePromptTemplate,
)
from langchain.chat_models import init_chat_model
llm = init_chat_model("gpt-4o-mini", model_provider="openai")template = ChatPromptTemplate.from_messages([SystemMessagePromptTemplate.from_template("你是{product}的客服助手。你的名字叫{name}"),HumanMessagePromptTemplate.from_template("{query}")]
)prompt = template.format_messages(product="聚客AI大模型课程",name="小聚",query="你是谁"
)print(prompt)ret = llm.invoke(prompt)print(ret.content)③ 把多轮对话变成模板
langchain:开源的大语言模型(LLM)应用开发框架,核心目标是简化 “模型 + 工具 + 数据” 协同应用的构建(如智能问答、RAG、AI 智能体等)。
langchain.prompts:langchain 框架下的提示词管理子模块,专门用于处理 “提示词的创建、格式化、复用”,解决提示词硬编码、动态参数拼接、模板化管理等问题。
langchain.prompts.PromptTemplate:langchain.prompts 子模块中的核心类,用于创建 “带变量占位符的提示词模板”,支持通过动态参数替换生成具体提示词,是构建结构化提示词的基础工具。
langchain:一个开源的大语言模型(LLM)应用开发框架,旨在简化基于大语言模型的复杂应用构建(如智能问答、RAG、AI 智能体、工具调用等)。
langchain.chat_models:langchain 框架下的子模块,专门用于处理 “聊天型大语言模型” 的交互逻辑。
langchain_core:LangChain 生态的 底层核心模块,是整个框架的 “骨架” 和 “基础设施”。它定义了所有组件的基础数据结构、抽象接口和核心交互逻辑,为上层模块(如 langchain、langchain_community、langchain_openai 等)提供统一的 “语言” 和 “规则”,确保不同组件(模型、工具、链等)能无缝协作。
langchain_core.messages:langchain_core 中专注于 对话消息处理 的子模块,定义了一系列消息类,用于规范 LLM 对话中 “不同角色的输入输出” 格式(如系统提示、用户提问、AI 回复、工具调用结果等),是构建多轮对话、工具调用等场景的基础。
init_chat_model():LangChain 提供的聊天模型统一初始化函数,支持通过简单参数快速创建不同厂商的聊天模型实例(如 DeepSeek、OpenAI、通义千问),屏蔽不同模型的底层差异,降低切换模型的成本。
| 参数名 | 类型 | 默认值 | 是否必填 | 核心描述 |
|---|---|---|---|---|
model | str | 无 | 是 | 模型名称,需与 model_provider 匹配,如:- provider="deepseek" 时:"deepseek-chat"- provider="openai" 时:"gpt-3.5-turbo"。 |
model_provider | str | 无 | 是 | 模型厂商 / 提供方,可选值:"deepseek"(深度求索)、"openai"(OpenAI)、"tongyi"(阿里云通义千问)等。 |
model_kwargs | Dict[str, Any] | {} | 否 | 模型专属参数,如:- api_key(API 密钥,本地模型可填任意字符串)- base_url(模型接口地址,本地模型填 http://localhost:8000/v1/chat/completions)- temperature(随机性,0-1)- max_tokens(最大生成长度)。 |
streaming | bool | False | 否 | 是否默认启用流式输出。设为 True 后,调用 model.invoke() 也会返回流式生成器(需配合循环处理)。 |
callbacks | List[BaseCallbackHandler] | None | 否 | 回调函数列表,用于监听模型调用过程(如记录日志、统计耗时),需传入 BaseCallbackHandler 子类实例。 |
llm:
human_prompt:
human_message_template:
HumanMessagePromptTemplate.from_template():创建仅包含 “人类用户角色” 的提示词模板,用于快速生成标准化的用户输入格式(封装为 HumanMessage 类型)。区别于普通文本模板,该函数生成的模板会明确标记消息角色为 “human”,直接适配聊天模型的输入要求(无需手动创建 HumanMessage 对象)。
| 参数名 | 类型 | 默认值 | 是否必填 | 核心描述 |
|---|---|---|---|---|
template | str | 无 | 是 | 人类用户的提示词模板字符串,支持变量占位符(用 {变量名} 表示,如 "请分析{文本}的情感")。 |
template_format | str | "f-string" | 否 | 模板解析格式,可选值:- "f-string"(默认,Python 格式化字符串)- "jinja2"(支持 Jinja2 语法,如条件判断、循环)。 |
input_variables | List[str] | None | 否 | 模板中需要填充的变量名列表(如 ["文本"])。若为 None,会自动从 template 中提取占位符作为变量。 |
validate_template | bool | True | 否 | 是否验证模板格式合法性(如检查占位符是否匹配变量)。设为 False 可跳过验证(用于复杂模板场景)。 |
chat_prompt:
human_message:
ai_message:
ChatPromptTemplate.from_messages():创建多角色对话的提示词模板,支持组合 “系统提示(System)”“人类输入(Human)”“AI 历史回答(AI)” 等多种角色的消息,构建完整的对话上下文模板,是构建复杂聊天场景的核心工具(如带系统角色的对话、含历史记录的多轮交互)。
| 参数名 | 类型 | 默认值 | 是否必填 | 核心描述 |
|---|---|---|---|---|
messages | List[Union[BaseMessagePromptTemplate, Tuple[str, str]]] | 无 | 是 | 多角色消息列表,支持两种格式:1. 元组格式:(角色名, 模板字符串),角色名可选 "system"/"human"/"ai"(如 ("system", "你是数学老师"));2. 模板对象格式:直接传入 SystemMessagePromptTemplate/HumanMessagePromptTemplate 实例(如前文创建的 human_template)。 |
template_format | str | "f-string" | 否 | 统一的模板解析格式,优先级低于单个消息模板的 template_format(即单个消息模板可单独指定格式),可选 "f-string" 或 "jinja2"。 |
input_variables | List[str] | None | 否 | 整个对话模板中需要填充的所有变量名列表。若为 None,会自动合并所有子模板的变量。 |
validate_template | bool | True | 否 | 是否验证所有子模板的格式合法性(如变量占位符是否完整)。设为 False 可跳过验证。 |
from langchain.prompts import (ChatPromptTemplate,HumanMessagePromptTemplate,MessagesPlaceholder,
)from langchain.chat_models import init_chat_model# 定义 LLM
llm = init_chat_model("deepseek-chat", model_provider="deepseek")human_prompt = "Translate your answer to {language}."
human_message_template = HumanMessagePromptTemplate.from_template(human_prompt)chat_prompt = ChatPromptTemplate.from_messages(# variable_name 是 message placeholder 在模板中的变量名# 用于在赋值时使用[MessagesPlaceholder("history"), human_message_template]
)from langchain_core.messages import AIMessage, HumanMessagehuman_message = HumanMessage(content="Who is Elon Musk?")
ai_message = AIMessage(content="Elon Musk is a billionaire entrepreneur, inventor, and industrial designer"
)messages = chat_prompt.format_prompt(# 对 "history" 和 "language" 赋值history=[human_message, ai_message], language="中文"
)print(messages.to_messages())result = llm.invoke(messages)
print(result.content)Ⅱ、从文件加载Prompt模板
langchain:开源的大语言模型(LLM)应用开发框架,核心目标是简化 “模型 + 工具 + 数据” 协同应用的构建(如智能问答、RAG、AI 智能体等)。
langchain.prompts:langchain 框架下的提示词管理子模块,专门用于处理 “提示词的创建、格式化、复用”,解决提示词硬编码、动态参数拼接、模板化管理等问题。
template:提示词模板对象。它本质上是一个包含占位符(如 {topic})的文本模板,用于动态生成特定场景的提示词。
.from_file():通常是类的类方法(如提示词模板类、配置类),用于从本地文件加载内容并创建类实例,避免将模板文本、配置信息硬编码在代码中,方便单独管理文件(如提示词模板文件、JSON 配置文件)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
file_path | str | 无 | 是 | 本地文件路径(如 "./prompts/qa_template.txt"),文件内容为提示词模板字符串(含 {变量} 占位符)。 |
input_variables | List[str] | 无 | 是 | 模板中变量的名称列表(需与文件中 {变量名} 一一对应,如 ["question", "context"])。 |
encoding | str | "utf-8" | 否 | 文件编码格式(如读取 GBK 编码文件需指定 encoding="gbk")。 |
.format():实例方法,用于将对象中的 “变量占位符” 替换为具体值,生成最终内容。在 LangChain 中,最常用的是 PromptTemplate 实例的 .format() 方法,用于将提示词模板中的 {变量} 替换为实际值,返回纯字符串;此外,Python 字符串本身也有 .format() 方法(功能类似)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
**kwargs | 键值对 | 无 | 是 | 模板中变量的具体值,键为变量名(如 text="..."),值为替换后的内容(字符串、数字等)。 |
from langchain.prompts import PromptTemplatetemplate = PromptTemplate.from_file("example_prompt_template.txt")
print("===Template===")
print(template)
print("===Prompt===")
print(template.format(topic='黑色幽默'))3.结构化输出
Ⅰ、直接输出Pydantic对象
pydantic:pydantic 是一个 数据验证与序列化库,核心作用是通过 “定义模型” 确保输入 / 输出数据的类型、结构、约束符合预期,自动捕获数据错误(如类型不匹配、值超出范围),同时支持数据格式转换(如字典转模型、模型转 JSON)。
pydantic.BaseModel:pydantic.BaseModel 是 pydantic 库的 数据模型基类,所有自定义的数据模型都需继承它,通过 “类属性定义字段” 即可自动生成数据验证逻辑和便捷方法(如 dict()、json())。
langchain:开源的大语言模型(LLM)应用开发框架,核心目标是简化 “模型 + 工具 + 数据” 协同应用的构建(如智能问答、RAG、AI 智能体等)。
langchain.prompts:langchain 框架下的提示词管理子模块,专门用于处理 “提示词的创建、格式化、复用”,解决提示词硬编码、动态参数拼接、模板化管理等问题。
langchain_core:LangChain 生态的 底层核心模块,是整个框架的 “骨架”,定义了所有组件的基础数据结构、抽象接口和核心交互逻辑,是 langchain、langchain_community 等上层模块的依赖基础。
langchain_core.output_parsers:langchain_core 中专注于 模型输出解析 的子模块,提供一系列工具将 LLM 生成的原始响应(通常是 AIMessage 对象或字符串)转换为结构化数据(如纯字符串、JSON、列表、自定义对象),解决 “模型输出格式不统一、手动解析繁琐” 的问题。
Data(BaseModel):定义自定义数据模型(继承pydantic.BaseModel)
llm:基础的大语言模型实例,用于处理自然语言输入并生成文本输出。
init_chat_model():通用型自定义函数,用于封装各类大语言模型(如 OpenAI GPT、Anthropic Claude、阿里云通义千问等)的初始化逻辑,统一处理模型配置、认证信息、生成规则等,最终返回一个可直接调用的聊天模型实例,减少重复代码并提升配置灵活性。
| 参数名 | 类型 | 默认值 | 是否必填 | 详细描述 |
|---|---|---|---|---|
model_provider | str | "openai" | 否 | 模型提供商,决定初始化的模型类型,常见值:"openai"(OpenAI)、"anthropic"(Anthropic)、"dashscope"(阿里云)、"baidu"(百度文心一言)等。 |
model_name | str | "gpt-3.5-turbo" | 否 | 具体模型名称,需与model_provider匹配:- OpenAI:"gpt-3.5-turbo"/"gpt-4";- 阿里云:"qwen-max"/"qwen-plus";- Anthropic:"claude-3-sonnet-20240229"。 |
api_key | str | None | 否 | 模型服务的 API 密钥,用于身份认证;若为None,默认从环境变量读取(需与model_provider对应,如 OpenAI 读OPENAI_API_KEY,阿里云读DASHSCOPE_API_KEY)。 |
base_url | str | None | 否 | 模型服务的自定义基础 URL(用于私有部署、代理服务或非官方接口):- OpenAI 默认:"https://api.openai.com/v1";- 阿里云通义千问兼容 URL:"https://dashscope.aliyuncs.com/compatible-mode/v1";- 若为None,使用对应提供商的默认 URL。 |
temperature | float | 0.7 | 否 | 生成文本的随机性控制:取值范围0.0~2.0;- 低值(如0.1~0.3):回复更严谨、确定;- 高值(如1.0~1.5):回复更多样、有创造性。 |
max_tokens | int | 2048 | 否 | 模型生成回复的最大 token 数(含输入 token + 输出 token),超过则截断;需根据模型上下文窗口设置(如 GPT-4 默认8192,qwen-max 支持128000)。 |
stop | List[str] 或 str | None | 否 | 生成终止符:当模型生成内容中出现指定字符串时,立即停止生成;- 示例:stop=["\n用户:", "### 结束"],避免模型模拟后续对话。 |
top_p | float | 1.0 | 否 | 采样阈值(核采样):取值范围0.0~1.0;- 仅保留概率和达到top_p的 token 参与采样(如0.9:仅用前 90% 概率的 token),与temperature配合控制生成多样性,通常不建议同时调整两者。 |
frequency_penalty | float | 0.0 | 否 | 重复内容惩罚:取值范围-2.0~2.0;- 正值(如0.5):降低模型生成重复内容的概率;- 负值(如-0.5):鼓励模型生成重复内容。 |
presence_penalty | float | 0.0 | 否 | 主题新颖性惩罚:取值范围-2.0~2.0;- 正值(如0.5):鼓励模型引入新主题、新词汇;- 负值(如-0.5):鼓励模型聚焦现有主题。 |
timeout | int | 30 | 否 | 模型请求的超时时间(单位:秒),超过时间未收到响应则抛出网络错误,避免长期阻塞。 |
max_retries | int | 2 | 否 | 请求失败后的重试次数(如网络波动、服务临时不可用),减少偶发错误影响。 |
tools | List[Tool] | None | 否 | 需绑定到模型的工具列表(如检索工具、函数调用工具),仅支持支持工具调用的模型(如 GPT-3.5-turbo-0613、qwen-max)。 |
tool_choice | str 或 dict | "auto" | 否 | 工具调用策略:- "auto":模型自主决定是否调用工具;- "none":强制不调用工具,仅生成文本回复;- 工具名(如"retriever_tool"):强制调用指定工具。 |
**kwargs | 任意 | - | 否 | 其他模型专属参数,如 Anthropic 的top_k、百度文心一言的penalty_score等,根据model_provider灵活传递。 |
Field():pydantic.Field 用于为 Pydantic 模型的字段添加精细化约束(如默认值、值范围、描述等),是定义结构化数据(如工具输入、模型输出格式)的核心工具,确保数据类型和规则符合预期。
| 参数 | 作用 |
|---|---|
default | 设置默认值(... 表示必填,None 表示可选) |
ge/le | 数值类型的 “大于等于”/“小于等于” 约束(如 ge=1 表示值≥1) |
min_length/max_length | 字符串的最小 / 最大长度约束 |
description | 字段描述(用于提示模型生成符合要求的输出) |
structured_llm:在基础 llm 上增强结构化输出能力的模型实例,能直接返回符合指定数据结构(如 Pydantic 模型)的结果。
.with_structured_output():LangChain 中 为语言模型(LLM)配置结构化输出 的方法,通过指定输出 schema(如 Pydantic 模型、JSON 结构),让模型直接返回符合结构的结果,无需手动解析原始文本,简化 “模型输出→结构化数据” 的流程。
| 参数 | 作用 |
|---|---|
schema | 输出结构定义(可以是 Pydantic 模型类、dict 或 list,指定输出格式) |
parser | 自定义输出解析器(可选,默认自动匹配 schema 类型) |
template:字符串 """提取用户输入中的日期。用户输入:{query}""",固定逻辑为 “提取用户输入中的日期”,{query} 为待填充的用户输入变量。
prompt:基于 template 创建的提示词模板对象,自动识别变量 {query} 作为输入参数。
PromptTemplate():LangChain 中用于 创建带变量的提示词模板 的类,将固定文本与动态变量分离(如 {query}、{context}),通过变量替换生成具体提示词,避免手动拼接字符串,确保提示词结构统一。
| 参数 | 作用 |
|---|---|
input_variables | 模板中变量名称的列表(如 ["query", "context"]) |
template | 提示词模板字符串(含 {变量名} 占位符,如 "基于{context}回答:{query}") |
query:用户的原始输入文本,即需要模型处理的内容。
input_prompt:填充变量后的最终提示词对象,是模型实际接收的输入。
.format_prompt():PromptTemplate 实例的方法,用于 将模板中的变量替换为具体值,生成 PromptValue 对象(而非纯字符串)。PromptValue 是适配不同模型输入格式的 “中间载体”:
- 对文本模型(如
GPT-3):通过.to_string()转为字符串; - 对聊天模型(如
gpt-3.5-turbo):通过.to_messages()转为BaseMessage列表(如HumanMessage)。
.invoke():是 LangChain 中 Runnable 接口(所有可参与流程编排的组件,如模型、链、检索器、提示词模板等均实现此接口)的核心同步调用方法,用于触发组件执行并返回结果。其核心作用是接收输入数据,经过组件处理后返回输出结果,是连接 “组件定义” 与 “实际执行” 的桥梁。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
input | 任意类型(因组件而异) | 无 | 是 | 组件的输入数据,类型随组件不同而变化:- 模型(如 ChatOpenAI):可接收字符串、BaseMessage 列表或 PromptValue;- 检索器(Retriever):接收查询字符串(str);- 链(Chain):接收字典(dict,键为链的输入变量);- 提示词模板(PromptTemplate):接收字典(dict,键为模板变量)。 |
config | RunnableConfig 或 None | None | 否 | 组件执行的配置信息,包含:- callbacks:回调函数列表(用于日志、进度跟踪);- tags:标签列表(用于分类执行记录);- metadata:元数据字典(附加执行信息);- 动态参数(如通过 configurable_alternatives 定义的可替换组件参数)。 |
**kwargs | 任意 | 无 | 否 | 组件特定的额外参数(不同组件可能有专属参数,如模型调用时的 temperature 临时覆盖,但不推荐,优先通过 config 或组件初始化时配置)。 |
from pydantic import BaseModel, Field
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain_core.output_parsers import PydanticOutputParserfrom langchain.chat_models import init_chat_model
llm = init_chat_model("gpt-4o-mini", model_provider="openai")# 定义你的输出对象
class Date(BaseModel):year: int = Field(description="Year")month: int = Field(description="Month")day: int = Field(description="Day")era: str = Field(description="BC or AD")# 定义结构化输出的模型
structured_llm = llm.with_structured_output(Date)template = """提取用户输入中的日期。
用户输入:
{query}"""prompt = PromptTemplate(template=template,
)query = "2023年四月6日天气晴..."
input_prompt = prompt.format_prompt(query=query)structured_llm.invoke(input_prompt)Ⅱ、输出指定格式的JSON
json_schema:定义模型输出的JSON 结构规范,相当于给模型的输出 “画一个模板”,强制模型按照返回符合该结构的 JSON 数据。
structured_llm:在基础 llm(如 OpenAI 的 gpt-4o-mini)上增强了结构化输出能力的模型实例,能够直接返回符合 json_schema 定义的 JSON 格式数据。
.with_structured_output():LangChain 中 为语言模型(LLM)配置结构化输出 的方法,通过指定输出 schema(如 Pydantic 模型、JSON 结构),让模型直接返回符合结构的结果,无需手动解析原始文本,简化 “模型输出→结构化数据” 的流程。
| 参数 | 作用 |
|---|---|
schema | 输出结构定义(可以是 Pydantic 模型类、dict 或 list,指定输出格式) |
parser | 自定义输出解析器(可选,默认自动匹配 schema 类型) |
.invoke():是 LangChain 中 Runnable 接口(所有可参与流程编排的组件,如模型、链、检索器、提示词模板等均实现此接口)的核心同步调用方法,用于触发组件执行并返回结果。其核心作用是接收输入数据,经过组件处理后返回输出结果,是连接 “组件定义” 与 “实际执行” 的桥梁。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
input | 任意类型(因组件而异) | 无 | 是 | 组件的输入数据,类型随组件不同而变化:- 模型(如 ChatOpenAI):可接收字符串、BaseMessage 列表或 PromptValue;- 检索器(Retriever):接收查询字符串(str);- 链(Chain):接收字典(dict,键为链的输入变量);- 提示词模板(PromptTemplate):接收字典(dict,键为模板变量)。 |
config | RunnableConfig 或 None | None | 否 | 组件执行的配置信息,包含:- callbacks:回调函数列表(用于日志、进度跟踪);- tags:标签列表(用于分类执行记录);- metadata:元数据字典(附加执行信息);- 动态参数(如通过 configurable_alternatives 定义的可替换组件参数)。 |
**kwargs | 任意 | 无 | 否 | 组件特定的额外参数(不同组件可能有专属参数,如模型调用时的 temperature 临时覆盖,但不推荐,优先通过 config 或组件初始化时配置)。 |
# OpenAI 模型的JSON格式
json_schema = {"title": "Date","description": "Formated date expression","type": "object","properties": {"year": {"type": "integer","description": "year, YYYY",},"month": {"type": "integer","description": "month, MM",},"day": {"type": "integer","description": "day, DD",},"era": {"type": "string","description": "BC or AD",},},
}
structured_llm = llm.with_structured_output(json_schema)structured_llm.invoke(input_prompt)Ⅲ、使用OutputParser
langchain_core:LangChain 生态的 底层核心模块,是整个框架的 “骨架” 和 “基础设施”。它定义了所有组件的基础数据结构、抽象接口和核心交互逻辑,为上层模块(如 langchain、langchain_community、langchain_openai 等)提供统一的 “语言” 和 “规则”,确保不同组件(模型、工具、链等)能无缝协作。
langchain_core.messages:langchain_core 中专注于 对话消息处理 的子模块,定义了一系列消息类,用于规范 LLM 对话中 “不同角色的输入输出” 格式(如系统提示、用户提问、AI 回复、工具调用结果等),是构建多轮对话、工具调用等场景的基础。
parser:将模型生成的原始文本输出(通常是 JSON 格式的字符串)解析为结构化数据(如 Pydantic 模型对象或字典),避免手动处理字符串解析的繁琐。
JsonOutputParser():LangChain 中用于 解析模型输出为 JSON 结构 的工具,能将模型生成的 JSON 格式文本转换为 Python 字典或 Pydantic 模型对象,并自动校验 JSON 格式的合法性。若模型输出不符合 JSON 规范(如语法错误),会抛出明确错误,避免下游逻辑因格式混乱崩溃。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
pydantic_object | Type[BaseModel] | None | 可选参数,指定 Pydantic 模型类(如自定义的 UserInfo)。若传入,解析结果会自动转换为该模型实例,并校验字段类型和约束(如数值范围、字符串长度);若不传入,默认解析为 Python 字典。 |
prompt:定义包含 “格式约束” 的提示词模板,确保模型生成的文本符合 parser 可解析的格式(如标准 JSON)。
PromptTemplate():LangChain 中用于 创建带动态变量的提示词模板 的类,通过分离 “固定文本结构” 和 “动态变量”(如 {query}、{context}),实现提示词的复用和标准化。核心价值是避免手动拼接字符串,确保不同输入场景下提示词格式一致。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
input_variables | List[str] | 必传 | 模板中所有变量的名称列表(如 ["question", "limit"]),需与模板中的 {变量名} 一一对应。 |
template | str | 必传 | 提示词模板字符串,包含 {变量名} 占位符(如 "请用{limit}字回答:{question}")。 |
template_format | str | "f-string" | 模板格式,支持:- "f-string"(默认):简单变量替换(如 {name});- "jinja2":支持复杂逻辑(如条件判断 {% if age > 18 %})。 |
validate_template | bool | True | 是否校验模板合法性(如变量名是否存在于 input_variables 中),不合法则抛错。 |
input_prompt:填充变量后的完整提示词,是模型实际接收的输入。
prompt.format_prompt():PromptTemplate 实例的方法,用于 将模板中的变量替换为具体值,生成 PromptValue 对象(而非纯字符串)。PromptValue 是适配不同模型输入格式的 “中间载体”:
- 对文本模型(如
GPT-3):通过.to_string()转为字符串; - 对聊天模型(如
gpt-3.5-turbo):通过.to_messages()转为BaseMessage列表(如HumanMessage)。
output:存储模型生成的原始文本输出(包含符合格式约束的内容,但仍是未解析的字符串)。
.invoke():是 LangChain 中 Runnable 接口(所有可参与流程编排的组件,如模型、链、检索器、提示词模板等均实现此接口)的核心同步调用方法,用于触发组件执行并返回结果。其核心作用是接收输入数据,经过组件处理后返回输出结果,是连接 “组件定义” 与 “实际执行” 的桥梁。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
input | 任意类型(因组件而异) | 无 | 是 | 组件的输入数据,类型随组件不同而变化:- 模型(如 ChatOpenAI):可接收字符串、BaseMessage 列表或 PromptValue;- 检索器(Retriever):接收查询字符串(str);- 链(Chain):接收字典(dict,键为链的输入变量);- 提示词模板(PromptTemplate):接收字典(dict,键为模板变量)。 |
config | RunnableConfig 或 None | None | 否 | 组件执行的配置信息,包含:- callbacks:回调函数列表(用于日志、进度跟踪);- tags:标签列表(用于分类执行记录);- metadata:元数据字典(附加执行信息);- 动态参数(如通过 configurable_alternatives 定义的可替换组件参数)。 |
**kwargs | 任意 | 无 | 否 | 组件特定的额外参数(不同组件可能有专属参数,如模型调用时的 temperature 临时覆盖,但不推荐,优先通过 config 或组件初始化时配置)。 |
output.content:存储模型生成的纯文本内容,即需要被 parser 解析的原始数据。
from langchain_core.output_parsers import JsonOutputParserparser = JsonOutputParser(pydantic_object=Date)prompt = PromptTemplate(template="提取用户输入中的日期。\n用户输入:{query}\n{format_instructions}",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()},
)input_prompt = prompt.format_prompt(query=query)
output = llm.invoke(input_prompt)
print("原始输出:\n"+output.content)print("\n解析后:")
parser.invoke(output)Ⅳ、使用PydanticOutputParser
langchain_core:LangChain 生态的 底层核心模块,是整个框架的 “骨架” 和 “基础设施”。它定义了所有组件的基础数据结构、抽象接口和核心交互逻辑,为上层模块(如 langchain、langchain_community、langchain_openai 等)提供统一的 “语言” 和 “规则”,确保不同组件(模型、工具、链等)能无缝协作。
langchain_core.output_parsers:LangChain 核心模块中专注于 模型输出解析 的子模块,提供了一系列工具将大语言模型(LLM)生成的原始文本(通常是无结构或半结构化的字符串)转换为结构化数据(如纯字符串、JSON、列表、自定义对象等),同时解决 “格式校验”“错误处理” 等问题。它是连接 “模型生成” 与 “应用逻辑” 的关键桥梁,让模型输出能直接被下游系统(如数据库、业务逻辑)使用。
parser:用于将模型生成的原始文本输出转换为结构化数据(如字典、Pydantic 模型、列表等)的工具类实例(如 JsonOutputParser、PydanticOutputParser 等)。自动处理模型输出的文本格式,提取关键信息并转换为程序可直接使用的结构化形式,避免手动编写字符串解析逻辑。
PydanticOutputParser():LangChain 中 专为 Pydantic 模型设计的输出解析器,用于将大语言模型生成的文本(通常是 JSON 格式)直接解析为指定的 pydantic.BaseModel 实例。相比 JsonOutputParser,它更聚焦于 “结构化对象生成”,会自动校验字段的类型、约束(如数值范围、字符串长度),并在解析失败时抛出详细错误,确保输出严格符合预定义的 schema。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
pydantic_object | Type[BaseModel] | 无 | 是 | 目标 Pydantic 模型类(如自定义的 UserInfo、ToolArgs),解析结果会转换为该类的实例,并自动应用模型中定义的字段约束(如 ge、min_length 等)。 |
input_prompt:填充变量后的完整提示词对象(通常是 PromptValue 类型),是模型实际接收的输入。
prompt.format_prompt():PromptTemplate 实例的方法,用于 将模板中的变量替换为具体值,生成 PromptValue 对象(而非纯字符串)。PromptValue 是适配不同模型输入格式的 “中间载体”:
- 对文本模型(如
GPT-3):通过.to_string()转为字符串; - 对聊天模型(如
gpt-3.5-turbo):通过.to_messages()转为BaseMessage列表(如HumanMessage)。
output:模型调用(如 llm.invoke(input_prompt))返回的结果对象(通常是 AIMessage 或 BaseMessage 子类)。封装模型生成的所有信息,包括文本内容、元数据(如生成时间、模型名)等。
output.content:output 对象的核心属性,存储模型生成的原始文本内容(字符串类型)。
.invoke():是 LangChain 中 Runnable 接口(所有可参与流程编排的组件,如模型、链、检索器、提示词模板等均实现此接口)的核心同步调用方法,用于触发组件执行并返回结果。其核心作用是接收输入数据,经过组件处理后返回输出结果,是连接 “组件定义” 与 “实际执行” 的桥梁。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
input | 任意类型(因组件而异) | 无 | 是 | 组件的输入数据,类型随组件不同而变化:- 模型(如 ChatOpenAI):可接收字符串、BaseMessage 列表或 PromptValue;- 检索器(Retriever):接收查询字符串(str);- 链(Chain):接收字典(dict,键为链的输入变量);- 提示词模板(PromptTemplate):接收字典(dict,键为模板变量)。 |
config | RunnableConfig 或 None | None | 否 | 组件执行的配置信息,包含:- callbacks:回调函数列表(用于日志、进度跟踪);- tags:标签列表(用于分类执行记录);- metadata:元数据字典(附加执行信息);- 动态参数(如通过 configurable_alternatives 定义的可替换组件参数)。 |
**kwargs | 任意 | 无 | 否 | 组件特定的额外参数(不同组件可能有专属参数,如模型调用时的 temperature 临时覆盖,但不推荐,优先通过 config 或组件初始化时配置)。 |
from langchain_core.output_parsers import PydanticOutputParserparser = PydanticOutputParser(pydantic_object=Date)input_prompt = prompt.format_prompt(query=query)
output = llm.invoke(input_prompt)
print("原始输出:\n"+output.content)print("\n解析后:")
parser.invoke(output)Ⅴ、OutputFixingParser格式自动纠错
llm:对模型原始输出文本(output.content)进行手动篡改后得到的格式错误的字符串,用于模拟模型生成的不符合预期格式的输出。测试解析器的容错能力,验证 OutputFixingParser 是否能修复格式错误。
init_chat_model():通用型自定义函数,用于封装各类大语言模型(如 OpenAI GPT、Anthropic Claude、阿里云通义千问等)的初始化逻辑,统一处理模型配置、认证信息、生成规则等,最终返回一个可直接调用的聊天模型实例,减少重复代码并提升配置灵活性。
| 参数名 | 类型 | 默认值 | 是否必填 | 详细描述 |
|---|---|---|---|---|
model_provider | str | "openai" | 否 | 模型提供商,决定初始化的模型类型,常见值:"openai"(OpenAI)、"anthropic"(Anthropic)、"dashscope"(阿里云)、"baidu"(百度文心一言)等。 |
model_name | str | "gpt-3.5-turbo" | 否 | 具体模型名称,需与model_provider匹配:- OpenAI:"gpt-3.5-turbo"/"gpt-4";- 阿里云:"qwen-max"/"qwen-plus";- Anthropic:"claude-3-sonnet-20240229"。 |
api_key | str | None | 否 | 模型服务的 API 密钥,用于身份认证;若为None,默认从环境变量读取(需与model_provider对应,如 OpenAI 读OPENAI_API_KEY,阿里云读DASHSCOPE_API_KEY)。 |
base_url | str | None | 否 | 模型服务的自定义基础 URL(用于私有部署、代理服务或非官方接口):- OpenAI 默认:"https://api.openai.com/v1";- 阿里云通义千问兼容 URL:"https://dashscope.aliyuncs.com/compatible-mode/v1";- 若为None,使用对应提供商的默认 URL。 |
temperature | float | 0.7 | 否 | 生成文本的随机性控制:取值范围0.0~2.0;- 低值(如0.1~0.3):回复更严谨、确定;- 高值(如1.0~1.5):回复更多样、有创造性。 |
max_tokens | int | 2048 | 否 | 模型生成回复的最大 token 数(含输入 token + 输出 token),超过则截断;需根据模型上下文窗口设置(如 GPT-4 默认8192,qwen-max 支持128000)。 |
stop | List[str] 或 str | None | 否 | 生成终止符:当模型生成内容中出现指定字符串时,立即停止生成;- 示例:stop=["\n用户:", "### 结束"],避免模型模拟后续对话。 |
top_p | float | 1.0 | 否 | 采样阈值(核采样):取值范围0.0~1.0;- 仅保留概率和达到top_p的 token 参与采样(如0.9:仅用前 90% 概率的 token),与temperature配合控制生成多样性,通常不建议同时调整两者。 |
frequency_penalty | float | 0.0 | 否 | 重复内容惩罚:取值范围-2.0~2.0;- 正值(如0.5):降低模型生成重复内容的概率;- 负值(如-0.5):鼓励模型生成重复内容。 |
presence_penalty | float | 0.0 | 否 | 主题新颖性惩罚:取值范围-2.0~2.0;- 正值(如0.5):鼓励模型引入新主题、新词汇;- 负值(如-0.5):鼓励模型聚焦现有主题。 |
timeout | int | 30 | 否 | 模型请求的超时时间(单位:秒),超过时间未收到响应则抛出网络错误,避免长期阻塞。 |
max_retries | int | 2 | 否 | 请求失败后的重试次数(如网络波动、服务临时不可用),减少偶发错误影响。 |
tools | List[Tool] | None | 否 | 需绑定到模型的工具列表(如检索工具、函数调用工具),仅支持支持工具调用的模型(如 GPT-3.5-turbo-0613、qwen-max)。 |
tool_choice | str 或 dict | "auto" | 否 | 工具调用策略:- "auto":模型自主决定是否调用工具;- "none":强制不调用工具,仅生成文本回复;- 工具名(如"retriever_tool"):强制调用指定工具。 |
**kwargs | 任意 | - | 否 | 其他模型专属参数,如 Anthropic 的top_k、百度文心一言的penalty_score等,根据model_provider灵活传递。 |
new_parser:当原始解析器(parser)无法解析错误格式的输出(如 bad_output)时,new_parser 会调用大模型(llm)生成修复方案,将错误输出修正为符合格式要求的文本,再用原始解析器解析。
OutputFixingParser.from_llm():LangChain 中 用于自动修复模型输出格式错误的解析器。当模型生成的输出不符合预期格式(如 JSON 语法错误、字段缺失)时,它会调用另一个 LLM(通常是格式修复能力强的模型)自动修正错误,再交给基础解析器(如 PydanticOutputParser)解析,解决 “模型偶尔输出格式混乱导致解析失败” 的问题。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
llm | BaseLanguageModel | 无 | 是 | 用于修复格式错误的 LLM 实例(如 ChatOpenAI,需具备理解格式要求的能力)。 |
parser | BaseOutputParser | 无 | 是 | 基础解析器(如 PydanticOutputParser、JsonOutputParser),用于修复后的文本解析。 |
bad_output:对模型原始输出文本(output.content)进行手动篡改后得到的格式错误的字符串,用于模拟模型生成的不符合预期格式的输出。
output.content:模型(如 llm)对输入提示词的原始响应文本(字符串类型),通常是符合预期格式的输出(如正确的 JSON 字符串)。
replace():Python 字符串的内置方法,用于 替换字符串中的指定子串,返回替换后的新字符串(原字符串不变)。在 LLM 应用中,常用于预处理模型输出(如去除多余空格、特殊符号)或清理提示词模板中的干扰字符,确保后续解析(如 PydanticOutputParser)顺利进行。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
old | str | 无 | 是 | 需要被替换的子串(如 "\n"、" ")。 |
new | str | 无 | 是 | 用于替换的新子串(如 ""、" ")。 |
count | int | -1 | 否 | 替换次数(-1 表示替换所有匹配的子串,正数表示仅替换前 count 次)。 |
.invoke():是 LangChain 中 Runnable 接口(所有可参与流程编排的组件,如模型、链、检索器、提示词模板等均实现此接口)的核心同步调用方法,用于触发组件执行并返回结果。其核心作用是接收输入数据,经过组件处理后返回输出结果,是连接 “组件定义” 与 “实际执行” 的桥梁。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
input | 任意类型(因组件而异) | 无 | 是 | 组件的输入数据,类型随组件不同而变化:- 模型(如 ChatOpenAI):可接收字符串、BaseMessage 列表或 PromptValue;- 检索器(Retriever):接收查询字符串(str);- 链(Chain):接收字典(dict,键为链的输入变量);- 提示词模板(PromptTemplate):接收字典(dict,键为模板变量)。 |
config | RunnableConfig 或 None | None | 否 | 组件执行的配置信息,包含:- callbacks:回调函数列表(用于日志、进度跟踪);- tags:标签列表(用于分类执行记录);- metadata:元数据字典(附加执行信息);- 动态参数(如通过 configurable_alternatives 定义的可替换组件参数)。 |
**kwargs | 任意 | 无 | 否 | 组件特定的额外参数(不同组件可能有专属参数,如模型调用时的 temperature 临时覆盖,但不推荐,优先通过 config 或组件初始化时配置)。 |
from langchain.output_parsers import OutputFixingParser
from langchain.chat_models import init_chat_modelllm = init_chat_model(model="deepseek-chat", model_provider="deepseek")# 纠错能力与大模型能力相关
new_parser = OutputFixingParser.from_llm(parser=parser, llm=llm)bad_output = output.content.replace("4","四")
print("PydanticOutputParser:")
try:parser.invoke(bad_output)
except Exception as e:print(e)print("OutputFixingParser:")
new_parser.invoke(bad_output)4.Function Calling
Function Calling 函数调用,顾名思义,为模型提供了一种调用函数的方法 / 能力
Ⅰ、Function Calling 成立的模型能力基础
① 问题理解和行动规划
② 结构化数据输出
③ 上下文学习 in-Context Learning
Function Calling 让模型输出不再局限于自身推理输出,而是可以与外部系统交互,完成更复杂的任务
Ⅱ、常见 Function Calling 的应用场景包括
① 查询检索,补充额外信息(如RAG、搜索)
② 理解用户输入,向外部系统写入信息(如表单填写)
③ 调用外部系统能力,完成实际行为动作(如下订单)
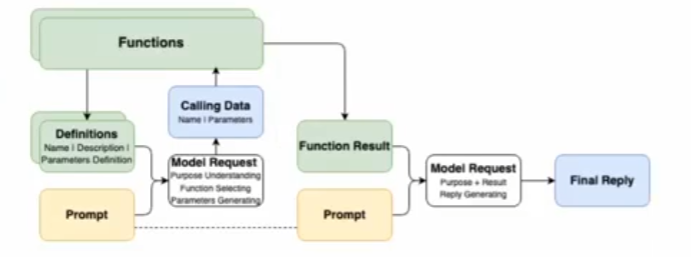
Ⅲ、Calling是结果,理解和选择才是第一步
除了代表用户诉求的Prompt之外,Function Caling还需要将可用的工具信息(Function Defnitions)也提供给模型在第一次请求时,模型的核心工作如下:
1.理解Prompt所代表的“诉求”和Definitions所代表的”行动可能性
2.“选择"完成"诉求"所需要进行的"行动"(从”行动可能性”中获得)
3.根据所选择的”行动",给出执行“行动"所需的"行动参数”(Parameters)
Ⅳ、代码演示
① 定义工具
langchain_core:LangChain 生态的 底层核心模块,定义了整个框架的基础数据结构、抽象接口和核心交互逻辑,是所有上层模块(包括工具、模型、链等)的 “骨架”。它确保不同组件(如工具、模型、解析器)遵循统一的规范,实现无缝协作。
langchain_core.tools:langchain_core 中专注于 工具定义与管理 的子模块,负责规范 “工具” 的基础结构、调用方式和元数据格式,让大语言模型(LLM)能够理解并调用外部工具(如计算器、数据库查询、API 调用等)。
langchain_core.tools.tool:langchain_core.tools 中的 核心工具类,主要包含 BaseTool 抽象基类和 Tool 实现类,是所有具体工具的 “模板”,定义了工具的基础属性和行为。
@tool:langchain_core.tools 提供的 便捷装饰器,用于将普通 Python 函数快速转换为符合 BaseTool 规范的工具实例,简化工具定义流程(无需手动继承 BaseTool 类)。
from langchain_core.tools import tool@tool
def add(a: int, b: int) -> int:"""Add two integers.Args:a: First integerb: Second integer"""return a + b@tool
def multiply(a: float, b: float) -> float:"""Multiply two integers.Args:a: First integerb: Second integer"""return a * b② 调用工具
llm:具备自然语言理解和生成能力,是工具调用的 “大脑”,负责判断是否需要调用工具、如何调用工具。
init_chat_model():通用型自定义函数,用于封装各类大语言模型(如 OpenAI GPT、Anthropic Claude、阿里云通义千问等)的初始化逻辑,统一处理模型配置、认证信息、生成规则等,最终返回一个可直接调用的聊天模型实例,减少重复代码并提升配置灵活性。
| 参数名 | 类型 | 默认值 | 是否必填 | 详细描述 |
|---|---|---|---|---|
model_provider | str | "openai" | 否 | 模型提供商,决定初始化的模型类型,常见值:"openai"(OpenAI)、"anthropic"(Anthropic)、"dashscope"(阿里云)、"baidu"(百度文心一言)等。 |
model_name | str | "gpt-3.5-turbo" | 否 | 具体模型名称,需与model_provider匹配:- OpenAI:"gpt-3.5-turbo"/"gpt-4";- 阿里云:"qwen-max"/"qwen-plus";- Anthropic:"claude-3-sonnet-20240229"。 |
api_key | str | None | 否 | 模型服务的 API 密钥,用于身份认证;若为None,默认从环境变量读取(需与model_provider对应,如 OpenAI 读OPENAI_API_KEY,阿里云读DASHSCOPE_API_KEY)。 |
base_url | str | None | 否 | 模型服务的自定义基础 URL(用于私有部署、代理服务或非官方接口):- OpenAI 默认:"https://api.openai.com/v1";- 阿里云通义千问兼容 URL:"https://dashscope.aliyuncs.com/compatible-mode/v1";- 若为None,使用对应提供商的默认 URL。 |
temperature | float | 0.7 | 否 | 生成文本的随机性控制:取值范围0.0~2.0;- 低值(如0.1~0.3):回复更严谨、确定;- 高值(如1.0~1.5):回复更多样、有创造性。 |
max_tokens | int | 2048 | 否 | 模型生成回复的最大 token 数(含输入 token + 输出 token),超过则截断;需根据模型上下文窗口设置(如 GPT-4 默认8192,qwen-max 支持128000)。 |
stop | List[str] 或 str | None | 否 | 生成终止符:当模型生成内容中出现指定字符串时,立即停止生成;- 示例:stop=["\n用户:", "### 结束"],避免模型模拟后续对话。 |
top_p | float | 1.0 | 否 | 采样阈值(核采样):取值范围0.0~1.0;- 仅保留概率和达到top_p的 token 参与采样(如0.9:仅用前 90% 概率的 token),与temperature配合控制生成多样性,通常不建议同时调整两者。 |
frequency_penalty | float | 0.0 | 否 | 重复内容惩罚:取值范围-2.0~2.0;- 正值(如0.5):降低模型生成重复内容的概率;- 负值(如-0.5):鼓励模型生成重复内容。 |
presence_penalty | float | 0.0 | 否 | 主题新颖性惩罚:取值范围-2.0~2.0;- 正值(如0.5):鼓励模型引入新主题、新词汇;- 负值(如-0.5):鼓励模型聚焦现有主题。 |
timeout | int | 30 | 否 | 模型请求的超时时间(单位:秒),超过时间未收到响应则抛出网络错误,避免长期阻塞。 |
max_retries | int | 2 | 否 | 请求失败后的重试次数(如网络波动、服务临时不可用),减少偶发错误影响。 |
tools | List[Tool] | None | 否 | 需绑定到模型的工具列表(如检索工具、函数调用工具),仅支持支持工具调用的模型(如 GPT-3.5-turbo-0613、qwen-max)。 |
tool_choice | str 或 dict | "auto" | 否 | 工具调用策略:- "auto":模型自主决定是否调用工具;- "none":强制不调用工具,仅生成文本回复;- 工具名(如"retriever_tool"):强制调用指定工具。 |
**kwargs | 任意 | - | 否 | 其他模型专属参数,如 Anthropic 的top_k、百度文心一言的penalty_score等,根据model_provider灵活传递。 |
llm_with_tools:通过 llm.bind_tools([add, multiply]) 处理后的模型实例,绑定了具体工具(如 add 加法工具、multiply 乘法工具)。在基础 llm 能力上,新增了工具调用格式生成能力,能根据输入生成符合规范的工具调用指令(而非直接回答问题)。
.bind_tools():LangChain 中聊天模型(如ChatTongyi、ChatOpenAI)的实例方法,用于为模型绑定可调用的工具(Tool对象或工具列表),让模型知道 “可以使用哪些工具”,并在需要时生成符合工具调用格式的输出(如包含name和parameters的 JSON)。是构建 “工具调用型智能体(Agent)” 的核心步骤。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
tools | List[Tool] 或 Tool | 无 | 是 | 模型可调用的工具列表(单个工具也可),每个Tool需包含name(工具名)、func(调用函数)、description(功能描述,供模型判断是否调用)。 |
**kwargs | 任意 | 无 | 否 | 额外配置(如tool_choice指定强制调用的工具,{"name": "calculator"})。 |
query:用户输入的自然语言问题(如 "3.5的4倍是多少?"),是模型需要处理的任务。触发模型的工具调用逻辑 —— 模型通过分析 query 的语义,决定是否调用工具及调用哪个工具。
messages:作为模型的输入格式,符合聊天模型对 “多轮对话上下文” 的处理要求(即使是单轮查询,也需用消息对象包装)。
HumanMessage():LangChain(langchain_core.messages)中的消息类,代表 “人类用户的消息”,用于构建对话历史(与AIMessage、SystemMessage配合),明确告知模型 “这是用户输入的内容”,是聊天模型的标准输入格式之一。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
content | str 或 List | 无 | 是 | 消息内容:- 通常为字符串(如用户问题"什么是LLM?");- 也可为列表(含文本和多媒体内容,如[{"type": "text", "text": "图中内容是什么?"}, {"type": "image_url", "image_url": "..."}],支持多模态模型)。 |
additional_kwargs | Dict | {} | 否 | 额外参数(如消息 ID、时间戳等元数据)。 |
type | str | "human" | 否 | 消息类型(固定为"human",无需修改)。 |
.invoke():是 LangChain 中 Runnable 接口(所有可参与流程编排的组件,如模型、链、检索器、提示词模板等均实现此接口)的核心同步调用方法,用于触发组件执行并返回结果。其核心作用是接收输入数据,经过组件处理后返回输出结果,是连接 “组件定义” 与 “实际执行” 的桥梁。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
input | 任意类型(因组件而异) | 无 | 是 | 组件的输入数据,类型随组件不同而变化:- 模型(如 ChatOpenAI):可接收字符串、BaseMessage 列表或 PromptValue;- 检索器(Retriever):接收查询字符串(str);- 链(Chain):接收字典(dict,键为链的输入变量);- 提示词模板(PromptTemplate):接收字典(dict,键为模板变量)。 |
config | RunnableConfig 或 None | None | 否 | 组件执行的配置信息,包含:- callbacks:回调函数列表(用于日志、进度跟踪);- tags:标签列表(用于分类执行记录);- metadata:元数据字典(附加执行信息);- 动态参数(如通过 configurable_alternatives 定义的可替换组件参数)。 |
**kwargs | 任意 | 无 | 否 | 组件特定的额外参数(不同组件可能有专属参数,如模型调用时的 temperature 临时覆盖,但不推荐,优先通过 config 或组件初始化时配置)。 |
json.dumps():Python 内置json模块的序列化函数,将 Python 对象(字典、列表、字符串等)转换为 JSON 格式字符串,用于数据存储(如保存模型配置)、网络传输(如 API 请求参数)或格式化模型的工具调用输出。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
obj | 可序列化对象 | 无 | 是 | 需转换为 JSON 的 Python 对象(如{"name": "calculator", "parameters": {"a": 3}})。 |
indent | int/str | None | 否 | 缩进空格数(如indent=2),使 JSON 更易读(常用于调试)。 |
ensure_ascii | bool | True | 否 | 若为False,保留非 ASCII 字符(如中文),否则转义(如"\u4e2d\u6587")。 |
sort_keys | bool | False | 否 | 若为True,按字母序排序字典的键。 |
import jsonllm = init_chat_model("deepseek-chat", model_provider="deepseek")llm_with_tools = llm.bind_tools([add, multiply])query = "3.5的4倍是多少?"
messages = [HumanMessage(query)]output = llm_with_tools.invoke(messages)print(json.dumps(output.tool_calls, indent=4))③ 回传Function Calling的结果
messages:在原有 [HumanMessage(query)] 基础上,新增了模型的工具调用指令(output)和工具返回结果(tool_msg)的对话列表。维护完整的对话上下文,包括用户输入、模型的工具调用决策、工具返回的结果,供后续模型生成最终回答时参考。
.append():Python 列表(list)的实例方法,用于在列表末尾添加单个元素,修改原列表(无返回值)。常用于动态收集数据(如批量加载文档时收集Document对象、记录对话历史等)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
object | 任意类型 | 是 | 需添加到列表的元素。 |
available_tools:一个字典,键为工具名称(字符串,如 "add"、"multiply"),值为对应的工具函数(如 add 加法函数、multiply 乘法函数)。建立 “工具名称” 与 “实际工具函数” 的映射,方便根据模型生成的 tool_call["name"] 快速找到并调用对应的工具。
selected_tool:从 available_tools 中根据 tool_call["name"] 匹配到的实际工具函数(如 multiply 函数)。执行具体的计算或操作(如乘法运算),是工具调用的 “执行者”。
.lower():Python 字符串(str)的实例方法,用于将字符串中的所有大写字符转换为小写,返回新的小写字符串(不修改原字符串)。常用于统一文本格式(如用户输入的大小写规范化),避免因大小写差异导致的匹配错误。
tool_msg:工具函数执行后返回的结果,封装为 ToolMessage 类型的消息对象(LangChain 中专门用于存储工具输出的消息类型)。将工具的原始返回结果(如 14.0)转换为对话上下文可识别的格式,包含结果内容和对应的工具调用 ID(与 tool_call["id"] 关联)。
.invoke():LangChain 中 **Runnable接口的核心同步调用方法 **,适用于模型、链、检索器、提示词模板等组件,用于接收输入并返回处理结果。是 “组件定义” 到 “实际运行” 的桥梁,支持从输入到输出的端到端处理。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
input | 任意类型(因组件而异) | 无 | 是 | 组件的输入数据:- 模型(如ChatTongyi):BaseMessage列表或PromptValue;- 链(Chain):字典(如{"query": "xxx"});- 检索器(Retriever):查询字符串;- 提示词模板:字典(键为模板变量)。 |
config | RunnableConfig 或 None | None | 否 | 执行配置,含callbacks(回调)、tags(标签)、configurable(动态参数)等。 |
**kwargs | 任意 | 无 | 否 | 组件专属参数(如临时覆盖模型temperature,优先用config)。 |
messages.append(output)available_tools = {"add": add, "multiply": multiply}for tool_call in output.tool_calls:selected_tool = available_tools[tool_call["name"].lower()]tool_msg = selected_tool.invoke(tool_call)messages.append(tool_msg)④ 结合Function Calling结果进行查询
new_output:返回的模型输出对象(通常是 AIMessage 类实例),包含模型基于 “用户原始查询 + 工具调用指令 + 工具返回结果” 生成的最终响应。结合完整的上下文(用户问题、工具调用过程、工具结果),生成自然语言形式的最终回答,而非工具调用指令(区别于第一次输出的 output)。
.model_dump():在 LangChain 和 Pydantic 框架中,.model_dump() 是 Pydantic 模型实例的内置方法,用于将模型对象(如 HumanMessage、AIMessage、ToolMessage 等)转换为 Python 字典(dict),方便后续序列化(如转 JSON)、打印或数据处理。
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
import json@tool
def add(a: int, b: int) -> int:"""Add two integers.Args:a: First integerb: Second integer"""return a + b@tool
def multiply(a: float, b: float) -> float:"""Multiply two integers.Args:a: First integerb: Second integer"""return a * bllm = init_chat_model("deepseek-chat", model_provider="deepseek")llm_with_tools = llm.bind_tools([add, multiply])query = "3.5的4倍是多少?"messages = [HumanMessage(query)]output = llm_with_tools.invoke(messages)print(json.dumps(output.tool_calls, indent=4))# 回传FunctionCalling的结果
messages.append(output)available_tools = {"add": add, "multiply": multiply}for tool_call in output.tool_calls:selected_tool = available_tools[tool_call["name"].lower()]tool_msg = selected_tool.invoke(tool_call)messages.append(tool_msg)new_output = llm_with_tools.invoke(messages)
for message in messages:print(json.dumps(message.model_dump(), indent=4, ensure_ascii=False))
print(new_output.content)
二、数据连接封装
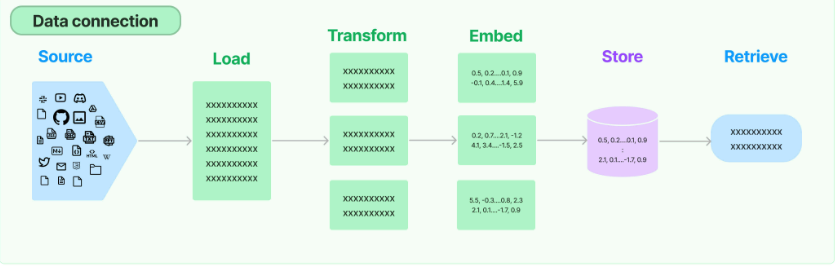
1.文档加载器:Document Loaders
清华源下载:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -U langchain-community pymupdf
2.文档处理器:TextSplitter
清华源下载:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade langchain-text-splitters
类似 LlamaIndex,LangChain 也提供了丰富的 Document Loaders 和 Text Splitters。
3.向量数据库与向量检索
清华源下载:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple dashscope
清华源下载:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple faiss-cpu
4.代码示例
os:Python 标准库中用于与操作系统交互的模块,提供文件 / 目录操作、环境变量读取、进程管理等基础功能,是所有 Python 应用的常用工具。
langchain_text_splitter:LangChain 生态中专注于长文本拆分的模块,用于将超长文档(如 PDF、小说)拆分为符合大模型上下文窗口限制的小片段(Document 对象),是 RAG(检索增强生成)流程的核心预处理工具。
langchain_community:LangChain 生态中的社区扩展库,包含第三方贡献的工具、集成和适配器,补充官方核心模块(langchain_core、langchain)未覆盖的功能,支持更多模型、存储、工具等。
langchain_community.embeddings:langchain_community 下专注于文本嵌入(Embedding)模型的子模块,提供各种开源 / 第三方嵌入模型的统一接口,将文本转换为向量(用于后续向量检索)。
langchain_community.vectorstores:langchain_community 下专注于向量数据库 / 存储的子模块,提供向量存储的统一接口,用于存储文本向量并支持相似性检索(RAG 流程中 “检索” 环节的核心)。
langchain_community.document_loaders:langchain_community 下专注于文档加载的子模块,提供各种格式 / 来源文档的加载工具,将非结构化数据(如 PDF、Word、网页)转换为 LangChain 标准的 Document 对象(便于后续拆分、嵌入)。
loader:读取并解析指定路径的 PDF 文档(此处为 ./data/deepseek-v3-1-4.pdf),将 PDF 内容转换为 LangChain 可处理的 Document 对象。
PyMuPDFLoader():LangChain(langchain_community.document_loaders)中基于 PyMuPDF 库 的 PDF 文档加载器,用于读取 PDF 文件内容并生成结构化 Document 对象,是处理 PDF 最常用的加载器之一(优势:速度快、支持加密 PDF、保留文本格式)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
file_path | str | 无 | 是 | PDF 文件的本地路径(如 "./docs/guide.pdf")或远程 URL(部分场景支持)。 |
password | str | None | 否 | 加密 PDF 的解密密码(若 PDF 未加密,无需传递)。 |
extract_images | bool | False | 否 | 若为 True,会提取 PDF 中的图片并保存到临时目录(需额外处理图片内容)。 |
pages:存储从 PDF 中加载的所有页面内容,每个 Document 对象包含:
.page_content:该页的文本内容(字符串);.metadata:该页的元数据(如页码{"page": 0}、文档路径等)。
.load_and_split():PyMuPDFLoader(及其他文档加载器)的 实例方法,用于一站式完成 “PDF 加载→文本拆分”:先调用 load() 加载 PDF 生成每页 Document,再用指定的文本拆分器将长页面文本拆分为语义完整的短片段,直接返回拆分后的小 Document 列表,简化 RAG 预处理流程。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
text_splitter | TextSplitter | RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0) | 否 | 文本拆分器实例(如 RecursiveCharacterTextSplitter、TokenTextSplitter),若不指定则使用默认拆分器。 |
**kwargs | 任意 | 无 | 否 | 传递给拆分器的额外参数(如 chunk_size、chunk_overlap,若 text_splitter 已指定则失效)。 |
text_splitter:将长文本(如单页 PDF 内容)切分为固定长度的短文本片段(chunk),避免因文本过长导致后续嵌入(Embedding)或模型调用失败。
RecursiveCharacterTextSplitter():LangChain 中最常用的文本拆分工具,用于将长文本(如 PDF、文档)拆分为语义完整的短片段(chunk),解决大语言模型 “上下文窗口限制” 问题,是 RAG 预处理的核心步骤。拆分逻辑:优先按大分隔符(如\n\n段落)拆分,若片段过长,再按小分隔符(\n、空格、标点)递归拆分,最大程度保留语义完整性。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
chunk_size | int | 4000 | 否 | 单个片段的最大长度(按字符数,或按 token 数,取决于length_function)。 |
chunk_overlap | int | 200 | 否 | 相邻片段的重叠长度(保留上下文关联,通常为chunk_size的 10%-20%)。 |
separators | List[str] | ["\n\n", "\n", " ", ""] | 否 | 拆分分隔符列表(优先级从高到低,优先按前面的分隔符拆分)。 |
length_function | 函数 | len | 否 | 计算文本长度的函数(默认按字符数,可改为tiktoken_len按 token 数计算)。 |
texts:存储经过 text_splitter 切分后的短文本,是后续生成嵌入向量(Embedding)的输入单位。
texts_splitter.create_documents(): LangChain 中文本拆分器(如 RecursiveCharacterTextSplitter、CharacterTextSplitter 等)的核心实例方法,用于将原始文本列表转换为结构化的 Document 对象列表。它是 RAG(检索增强生成)流程中 “文本预处理” 环节的关键步骤,为后续 “向量化”“向量存储” 提供标准化的输入格式。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
texts | List[str] | 无 | 是 | 原始文本列表,每个元素为一段待处理的文本(如 ["第1页内容...", "第2页内容..."])。 |
metadatas | List[Dict] 或 None | None | 否 | 元数据列表,与 texts 一一对应:- 若为 List[Dict]:每个字典为对应文本的元数据(如 [{"source": "doc1.pdf", "page": 1}, {"source": "doc1.pdf", "page": 2}]);- 若为 None:所有 Document 的 metadata 为空字典 {}。 |
embeddings:将文本片段(texts)转换为数值向量(Embedding),实现 “文本→向量” 的映射,以便后续通过向量相似度进行检索。
DashScopeEmbeddings():langchain_community.embeddings中的类,用于调用阿里云达摩院的文本嵌入模型(如text-embedding-v2),生成文本向量(适合中文场景,兼容 LangChain 的向量存储)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
model | str | "text-embedding-v2" | 否 | 嵌入模型名称(达摩院提供的嵌入模型,如"text-embedding-v2")。 |
dashscope_api_key | str | None | 否 | 阿里云 DashScope API 密钥(建议通过os.getenv("DASHSCOPE_API_KEY")加载)。 |
index:存储文本片段的向量数据(embeddings 生成的向量),并提供高效的向量相似度检索能力。
FAISS.from_documenys():langchain_community.vectorstores.FAISS的类方法,从Document对象列表创建 FAISS 向量索引(index)。内部逻辑:先用embeddings模型将Document.page_content转为向量,再构建 FAISS 索引存储向量及关联的Document。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
documents | List[Document] | 无 | 是 | 拆分后的Document对象列表(含page_content和metadata)。 |
embedding | Embeddings | 无 | 是 | 嵌入模型实例(如DashScopeEmbeddings()),用于生成文本向量。 |
metadatas | List[Dict] 或 None | None | 否 | 额外元数据(通常无需传入,documents已包含metadata)。 |
retriever:提供 “自然语言查询→相似文本片段” 的检索能力,是连接用户查询与向量数据库的 “接口”。
.as_retriever():向量库(如 FAISS)的实例方法,将向量索引(index)转换为检索器(retriever),方便直接调用检索功能(无需手动处理向量生成和相似度计算)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
search_kwargs | Dict | {"k": 4} | 否 | 检索参数:- k:返回最相关的文档数量(默认 4 条);- filter:按元数据过滤(如{"source": "doc1.pdf"})。 |
docs:存储与用户查询("deepseek v3有多少参数")最相关的文本内容,是后续生成回答的 “知识来源”。
.invoke():LangChain 中 **Runnable接口的核心同步调用方法 **,用于触发组件(如模型、链、检索器、提示词模板等)执行并返回结果。是连接 “组件定义” 与 “实际运行” 的桥梁,支持从输入到输出的端到端处理。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
input | 任意类型(因组件而异) | 无 | 是 | 组件的输入数据,类型随组件变化:- 模型(如ChatTongyi):BaseMessage列表或PromptValue;- 链(Chain):字典(键为输入变量);- 检索器(Retriever):查询字符串;- 提示词模板:字典(键为模板变量)。 |
config | RunnableConfig 或 None | None | 否 | 执行配置,包含:- callbacks:回调函数(日志、进度跟踪);- tags:标签(分类记录);- metadata:元数据;- configurable:动态参数(如切换模型)。 |
**kwargs | 任意 | 无 | 否 | 组件专属参数(如模型调用时临时覆盖temperature,不推荐,优先用config)。 |
doc.page_content:存储单个检索结果(doc)的具体文本内容,即从文档中匹配到的与查询相关的片段。
import os
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import PyMuPDFLoader# 加载文档
loader = PyMuPDFLoader("./data/deepseek-v3-1-4.pdf")
pages = loader.load_and_split()# 文档切分
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512,chunk_overlap=200,length_function=len,add_start_index=True,
)texts = text_splitter.create_documents([page.page_content for page in pages[:1]]
)# 灌库
embeddings = DashScopeEmbeddings(model="text-embedding-v1", dashscope_api_key=os.getenv("DASHSCOPE_API_KEY")
)
index = FAISS.from_documents(texts, embeddings)# 检索 top-5 结果
retriever = index.as_retriever(search_kwargs={"k": 5})docs = retriever.invoke("deepseek v3有多少参数")for doc in docs:print(doc.page_content)print("----")更多的三方检索组件链接,参考:https://python.langchain.com/docs/integrations/vectorstores/
文档处理部分,建议在实际应用中详细测试后使用
与向量数据库的链接部分本质是接口封装,向量数据库需要自己选型
三、Chain和LangChain Expression Language
1.Pipeline 式调用 PromptTemplate, LLM 和 OutputParser
LangChain Expression Language(LCEL)是一种声明式语言,可轻松组合不同的调用顺序构成 Chain。LCEL 自创立之初就被设计为能够支持将原型投入生产环境,无需代码更改,从最简单的“提示+LLM”链到最复杂的链(已有用户成功在生产环境中运行包含数百个步骤的 LCEL Chain)。
Ⅰ、LCEL 的一些亮点包括:
① 流支持:使用 LCEL 构建 Chain 时,你可以获得最佳的首个令牌时间(即从输出开始到首批输出生成的时间)。对于某些 Chain,这意味着可以直接从 LLM 流式传输令牌到流输出解析器,从而以与 LLM 提供商输出原始令牌相同的速率获得解析后的、增量的输出。
② 异步支持:任何使用 LCEL 构建的链条都可以通过同步 API(例如,在 Jupyter 笔记本中进行原型设计时)和异步 API(例如,在 LangServe 服务器中)调用。这使得相同的代码可用于原型设计和生产环境,具有出色的性能,并能够在同一服务器中处理多个并发请求。
③ 优化的并行执行:当你的 LCEL 链条有可以并行执行的步骤时(例如,从多个检索器中获取文档),我们会自动执行,无论是在同步还是异步接口中,以实现最小的延迟。
④ 重试和回退:为 LCEL 链的任何部分配置重试和回退。这是使链在规模上更可靠的绝佳方式。目前我们正在添加重试/回退的流媒体支持,因此你可以在不增加任何延迟成本的情况下获得增加的可靠性。
⑤ 访问中间结果:对于更复杂的链条,访问在最终输出产生之前的中间步骤的结果通常非常有用。这可以用于让最终用户知道正在发生一些事情,甚至仅用于调试链条。你可以流式传输中间结果,并且在每个 LangServe 服务器上都可用。
⑥ 输入和输出模式:输入和输出模式为每个 LCEL 链提供了从链的结构推断出的 Pydantic 和 JSONSchema 模式。这可以用于输入和输出的验证,是 LangServe 的一个组成部分。
⑦ 无缝 LangSmith 跟踪集成:随着链条变得越来越复杂,理解每一步发生了什么变得越来越重要。通过 LCEL,所有步骤都自动记录到 LangSmith,以实现最大的可观察性和可调试性。
⑧ 无缝 LangServe 部署集成:任何使用 LCEL 创建的链都可以轻松地使用 LangServe 进行部署。
原文:https://python.langchain.com/docs/expression_language/
os:操作系统交互工具,负责 “环境配置” 与 “文件管理”,是 LLM 应用的基础支撑。
langchain:LangChain 主模块,封装高层 API 和常用功能,是快速构建 LLM 应用的 “一站式工具包”。
langchain.prompts:提示词模板管理工具,负责 “结构化提示词” 的创建与动态变量替换。
langchain_core:LangChain 底层骨架,定义 “基础数据结构” 和 “抽象接口”,确保所有组件兼容。
langchain_core.runnables:流程编排工具,通过 LCEL(LangChain Expression Language)串联组件,构建复杂 LLM 流程。
pydantic:数据验证与结构化建模库,通过 “模型类” 定义数据规则,确保输入 / 输出合法。
typing:类型提示工具,标注变量 / 函数的类型,支持 IDE 类型检查和代码补全。
List:用于标注 列表(List)类型 的泛型(需指定列表内元素的具体类型),明确 “这是一个包含某类元素的列表”。
Dict:用于标注 字典(Dictionary)类型 的泛型(需指定字典的 “键类型” 和 “值类型”),明确 “这是一个键为某类、值为某类的字典”。
Optional:用于标注 可选类型,表示变量 / 参数 “可以是指定类型,也可以是 None”,明确 “这个值不是必须的”。
enum:枚举类型定义工具,用于管理 “固定选项集合”(避免魔法字符串,提升代码可读性)。
json:JSON 数据处理工具,实现 “Python 对象” 与 “JSON 字符串” 的相互转换。
langchain_community:社区贡献的扩展模块,集成第三方工具(非官方模型、存储、文档加载器等)。
langchain_community.chat_models:社区模块中专门集成 “第三方聊天模型” 的子模块,提供与 LangChain 兼容的接口。
data:排序维度选项之一,表示 “按流量(data)排序”
price:排序维度选项之一,表示 “按价格(price)排序”
ascend:排序方向选项之一,表示 “升序”(从小到大)
descend:排序方向选项之一,表示 “降序”(从大到小)
name:解析出的 “流量包名称”,可选(用户未指定时为 None)
price_lower:解析出的 “价格下限”(整数,单位默认元),用户未提及时为 None
price_upper:解析出的 “价格上限”(整数,单位默认元),用户未提及时为 None
data_lower:解析出的 “流量下限”(未指定单位,需结合业务定义),用户未提及时为 None
data_upper:解析出的 “流量上限”(未指定单位,需结合业务定义),用户未提及时为 None
sort_by:解析出的 “排序维度”,取值为 SortEnum 枚举(data/price),未指定为 None
odering:解析出的 “排序方向”,取值为 OrderingEnum 枚举(ascend/descend),未指定为 None
Field():Pydantic 中用于定义模型字段元数据和约束的函数,通过Field()可指定字段描述、默认值、数据范围(如数值大小、字符串长度)等,用于校验输入合法性并辅助 LLM 理解字段含义。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
default | 任意 | ... | 否 | 字段默认值(未传参时使用),若未设置则为必填字段。 |
default_factory | 可调用对象 | None | 否 | 动态生成默认值的函数(如lambda: []默认返回空列表),与default互斥。 |
alias | str | None | 否 | 字段别名(序列化时可用别名代替原字段名)。 |
description | str | None | 否 | 字段描述(用于生成 LLM 格式提示,如"用户姓名,非空字符串")。 |
gt | 数值 | None | 否 | 数值类型字段约束:值必须大于gt(如gt=0表示值 > 0)。 |
ge | 数值 | None | 否 | 数值类型字段约束:值必须大于等于ge(如ge=0表示值≥0)。 |
lt | 数值 | None | 否 | 数值类型字段约束:值必须小于lt(如lt=100表示值 < 100)。 |
le | 数值 | None | 否 | 数值类型字段约束:值必须小于等于le(如le=100表示值≤100)。 |
min_length | int | None | 否 | 字符串 / 列表类型字段约束:长度≥min_length。 |
max_length | int | None | 否 | 字符串 / 列表类型字段约束:长度≤max_length。 |
pattern | str | None | 否 | 字符串类型字段约束:必须匹配正则表达式(如r"^[a-zA-Z0-9]+$"限制字母数字)。 |
prompt:定义模型的任务指令,引导模型将用户输入解析为指定结构化格式,而非生成自然语言回答。
ChatPromptTemplate。from_messages():langchain.prompts中ChatPromptTemplate的类方法,用于从消息列表(含角色信息)创建聊天提示词模板,支持多角色对话(系统提示、用户输入、AI 回复),适配聊天模型输入格式。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
messages | List[Union[BaseMessagePromptTemplate, Tuple[str, str]]] | 无 | 是 | 消息模板列表,支持两种形式:- 元组(角色, 模板):如("system", "你是{field}专家");- 消息模板实例:如SystemMessagePromptTemplate.from_template(...)。 |
template_format | str | "f-string" | 否 | 模板格式("f-string"或"jinja2"),指定变量替换方式。 |
llm:提供语义理解与结构化输出能力的基础模型,负责解析用户输入并生成符合要求的内容。
ChatTongyi():langchain_community.chat_models中的类,用于调用阿里云通义千问聊天模型(如qwen-plus、qwen-max),封装 API 调用逻辑,兼容 LangChain 的流程编排(如与Runnable串联)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
model_name | str | "qwen-plus" | 否 | 通义千问模型名称,如"qwen-turbo"(轻量版)、"qwen-plus"(标准版)、"qwen-max"(增强版)。 |
temperature | float | 0.7 | 否 | 模型随机性(0.0= 确定性高,1.0= 随机性高,范围[0, 1])。 |
dashscope_api_key | str | None | 否 | 阿里云 DashScope API 密钥(建议通过环境变量os.getenv("DASHSCOPE_API_KEY")加载)。 |
base_url | str | "https://dashscope.aliyuncs.com/compatible-mode/v1" | 否 | 通义千问 OpenAI 兼容接口地址(固定为阿里云提供的 URL)。 |
max_tokens | int | None | 否 | 模型生成的最大 token 数(超出则截断)。 |
structured_llm:在基础 llm 能力上,强制模型输出符合 Semantics 类(Pydantic 模型)定义的结构化数据,无需手动解析 JSON 文本。
.with_structured_output():LangChain 中模型类的方法(如ChatTongyi、ChatOpenAI),用于让模型直接返回结构化输出(如 Pydantic 模型、字典),无需手动解析,简化 “模型输出→结构化数据” 的流程。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
schema | Type[BaseModel]/dict/str | 无 | 是 | 输出结构定义:- BaseModel:Pydantic 模型类(如UserInfo),模型会严格遵循其字段约束;- dict:字典结构(如{"name": str, "age": int});- str:JSON Schema 字符串。 |
include_raw | bool | False | 否 | 若为True,返回结果中包含原始模型输出(raw字段),否则仅返回结构化数据。 |
**kwargs | 任意 | 无 | 否 | 额外参数(如parser指定自定义解析器,prompt覆盖默认格式提示)。 |
runnable:封装 “用户输入→提示词填充→模型调用→结构化输出” 的完整流程,实现端到端的语义解析。
{"text": RunnablePassthrough()}:将用户输入(如"不超过100元的流量大的套餐有哪些")直接传递给prompt中的{text}占位符;| prompt:用传递的text填充prompt,生成完整的提示词;| structured_llm:将完整提示词传入structured_llm,获取结构化输出。
ret:存储模型解析用户输入后的结构化结果,每个字段对应 Semantics 中定义的含义。
invoke():LangChain 中 **Runnable接口的核心同步调用方法 **,用于触发组件(如模型、链、检索器、提示词模板等)执行并返回结果。是连接 “组件定义” 与 “实际运行” 的桥梁,支持从输入到输出的端到端处理。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
input | 任意类型(因组件而异) | 无 | 是 | 组件的输入数据,类型随组件变化:- 模型(如ChatTongyi):BaseMessage列表或PromptValue;- 链(Chain):字典(键为输入变量);- 检索器(Retriever):查询字符串;- 提示词模板:字典(键为模板变量)。 |
config | RunnableConfig 或 None | None | 否 | 执行配置,包含:- callbacks:回调函数(日志、进度跟踪);- tags:标签(分类记录);- metadata:元数据;- configurable:动态参数(如切换模型)。 |
**kwargs | 任意 | 无 | 否 | 组件专属参数(如模型调用时临时覆盖temperature,不推荐,优先用config)。 |
json.dumps():Python 内置json模块的序列化函数,将 Python 对象(字典、列表、字符串等)转换为 JSON 格式字符串,用于数据存储、传输或模型输出的格式化。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
obj | 任意可序列化对象 | 无 | 是 | 需转换为 JSON 字符串的 Python 对象(如{"name": "qwen"}、[1, 2, 3])。 |
skipkeys | bool | False | 否 | 若为True,跳过非字符串类型的键(如整数键),否则抛出TypeError。 |
ensure_ascii | bool | True | 否 | 若为True,非 ASCII 字符会被转义(如 “中文”→"\u4e2d\u6587");False则保留原字符。 |
check_circular | bool | True | 否 | 若为True,检查循环引用(如a = {}; a['a'] = a),否则可能导致无限递归。 |
allow_nan | bool | True | 否 | 若为True,允许NaN、Infinity等特殊值;False则抛出ValueError。 |
indent | int/str | None | 否 | 缩进空格数(int)或缩进字符串(str),用于格式化输出(如indent=2使 JSON 更易读)。 |
separators | tuple | (', ', ': ') | 否 | 元组(item_sep, key_sep),指定元素分隔符和键值分隔符(如(',', ':')压缩输出)。 |
default | 函数 | None | 否 | 自定义序列化函数,处理非标准类型(如datetime对象,需转为字符串)。 |
sort_keys | bool | False | 否 | 若为True,按字母顺序排序字典的键。 |
.model_dump():Pydantic 模型(BaseModel)的实例方法,将模型实例转换为 Python 字典(键为字段名,值为字段值),用于数据序列化、存储或传递给下游系统(如 LLM 工具调用参数)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
mode | str | "python" | 否 | 序列化模式:- "python":返回 Python 原生类型(如datetime保留为对象);- "json":返回 JSON 兼容类型(如datetime转为 ISO 字符串)。 |
include | 任意 | None | 否 | 指定需包含的字段(如{"name"}仅保留name字段)。 |
exclude | 任意 | None | 否 | 指定需排除的字段(如{"age"}移除age字段)。 |
by_alias | bool | False | 否 | 若为True,使用字段别名(alias)作为键,而非原字段名。 |
exclude_unset | bool | False | 否 | 若为True,排除未显式设置的字段(仅保留用户赋值的字段)。 |
exclude_defaults | bool | False | 否 | 若为True,排除值为默认值的字段。 |
exclude_none | bool | False | 否 | 若为True,排除值为None的字段。 |
import osfrom langchain.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from pydantic import BaseModel, Field
from typing import List, Dict, Optional
from enum import Enum
import json
from langchain_community.chat_models import ChatTongyi# 输出结构
class SortEnum(str, Enum):data = 'data'price = 'price'class OrderingEnum(str, Enum):ascend = 'ascend'descend = 'descend'class Semantics(BaseModel):name: Optional[str] = Field(description="流量包名称", default=None)price_lower: Optional[int] = Field(description="价格下限", default=None)price_upper: Optional[int] = Field(description="价格上限", default=None)data_lower: Optional[int] = Field(description="流量下限", default=None)data_upper: Optional[int] = Field(description="流量上限", default=None)sort_by: Optional[SortEnum] = Field(description="按价格或流量排序", default=None)ordering: Optional[OrderingEnum] = Field(description="升序或降序排列", default=None)# Prompt 模板
prompt = ChatPromptTemplate.from_messages([("system", "你是一个语义解析器。你的任务是将用户的输入解析成JSON表示。不要回答用户的问题。"),("human", "{text}"),]
)# 模型
llm = ChatTongyi(model_name="qwen-max", api_key=os.environ["DASHSCOPE_API_KEY"], temperature=0.01)
structured_llm = llm.with_structured_output(Semantics)# LCEL 表达式
runnable = ({"text": RunnablePassthrough()} | prompt | structured_llm
)# 直接运行
ret = runnable.invoke("不超过100元的流量大的套餐有哪些")
print(json.dumps(ret.model_dump(),indent = 4,ensure_ascii=False)
)
2.用 LCEL 实现 RAG
os:Python 标准库中 与操作系统交互的底层辅助工具,无依赖,是 LLM 应用(如 RAG)中 “环境配置、文件管理” 的基础支撑。
langchain_community:LangChain 生态的 第三方扩展库,基于 langchain_core 构建,集成开源 / 小众厂商的模型、存储、工具,补充官方模块未覆盖的 “长尾需求”,是快速扩展 LLM 应用能力的关键。
langchain_community.chat_models:第三方聊天模型集成工具,封装非官方聊天模型的调用逻辑,提供与 langchain_openai.ChatOpenAI 一致的接口,无缝适配 LangChain 流程。
langchain_community.vectorstores:向量存储集成工具,用于存储文本向量并支持相似性检索,是 RAG 流程中 “检索” 环节的核心,支持本地 / 云端多种存储方案。
langchain_community.document_loaders:多格式文档加载工具,将非结构化数据(PDF、网页、Word)转为 LangChain 标准 Document 对象(含 page_content 文本 +metadata 元数据),是 RAG 预处理的 “第一步”。
langchain_community.embedding:第三方嵌入模型集成工具,将文本转为向量(Embedding),适配 RAG 中 “文本向量化” 需求,支持开源 / 国产嵌入模型。
langchain_core:LangChain 生态的 底层骨架,定义所有组件的 “基础数据结构” 和 “抽象接口”,是 langchain、langchain_community 等上层模块的依赖基础,确保组件间兼容性。
langchain_core.prompts:提示词基础结构定义,提供提示词模板的 “抽象基类”,为上层 langchain.prompts 提供底层支撑(区别:上层是可直接使用的模板类,下层是抽象定义)。
langchain_text_splitters:专门处理 长文本拆分 的独立模块,解决大模型 “上下文窗口限制” 问题,是 RAG 预处理的 “核心环节”,确保长文档能被模型处理。
loader:读取指定路径的 PDF 文档(./data/deepseek-v3-1-4.pdf),解析文档内容并转换为 LangChain 可处理的格式。
PyMuPDFLoader():langchain_community.document_loaders 中的 PDF 文档加载器,基于轻量级 PDF 处理库 PyMuPDF(即 fitz)实现,用于高效加载 PDF 文件并转换为 LangChain 标准的 Document 对象(包含文本内容和元数据,如页码)。相比其他 PDF 加载器(如 PyPDFLoader),它速度更快,支持加密 PDF 解密(需密码)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
file_path | str | 无 | 是 | PDF 文件的本地路径(如 "./docs/report.pdf")。 |
password | str | "" | 否 | 若 PDF 加密,需传入解密密码(如 password="123456")。 |
pages:存储从 PDF 中加载的所有页面,每个 Document 对象对应 PDF 的一页,包含:
.page_content:该页的文本内容;.metadata:该页的元数据(如页码{"page": 0}、文档路径等)。
.load_and_split():文档加载器(如 PyMuPDFLoader、WebBaseLoader)的 便捷方法,将 “加载文档” 和 “拆分文档” 两步合并:先加载原始文档,再用指定的文本拆分器(TextSplitter)拆分,直接返回拆分后的小片段 Document 列表,简化 RAG 预处理流程。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
text_splitter | TextSplitter | RecursiveCharacterTextSplitter()(默认) | 否 | 文本拆分器实例,用于将长文档拆分为小片段(如 RecursiveCharacterTextSplitter(chunk_size=500))。 |
text_splitter:RecursiveCharacterTextSplitter 实例(递归字符切分工具)。将长文本(如单页 PDF 内容)切分为固定长度的短片段(chunk),避免因文本过长导致嵌入(Embedding)或模型处理失败。
RecursiveCharacterTextSplitter():langchain_text_splitter 中最常用的 文本拆分器,通过 “递归按分隔符拆分” 策略处理长文本:优先按大分隔符(如 \n\n 段落)拆分,若片段仍过长,再按小分隔符(如 \n 换行)拆分,直到符合 chunk_size 限制。适合绝大多数自然语言文本(如文档、网页、小说),能最大程度保留语义完整性。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
chunk_size | int | 1000 | 否 | 每个拆分片段的最大长度(按字符数或 token 数,取决于 length_function)。 |
chunk_overlap | int | 200 | 否 | 相邻片段的重叠长度(用于保留上下文关联性,建议为 chunk_size 的 10%-20%)。 |
separators | List[str] | ["\n\n", "\n", " ", ""] | 否 | 拆分分隔符优先级列表(从大到小),默认优先按段落拆分,再按行、空格拆分。 |
length_function | Callable | len | 否 | 计算文本长度的函数(默认 len 按字符数,可替换为 tiktoken_len 按 token 数)。 |
texts:存储经过 text_splitter 处理后的短文本,是后续生成嵌入向量的基本单位。
.create_documents():文本拆分器(如 RecursiveCharacterTextSplitter)的 方法,将原始文本列表(List[str])转换为 LangChain 标准的 Document 对象列表(每个 Document 含 page_content 文本和 metadata 元数据),用于后续嵌入和存储。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
texts | List[str] | 无 | 是 | 原始文本列表(如 ["文本1...", "文本2..."])。 |
metadatas | Optional[List[dict]] | None | 否 | 元数据列表,与 texts 一一对应(如 [{"source": "doc1"}, {"source": "doc2"}]),若为 None 则元数据为空。 |
embeddings:将文本片段(texts)转换为数值向量(Embedding),实现 “文本→向量” 的映射,为后续相似度检索奠定基础。
DashScopeEmbeddings():langchain_community.embeddings 中集成的 阿里达摩院(DashScope)嵌入模型 类,用于将文本转换为向量(Embedding),支持达摩院的 text-embedding-v1 等模型,适配中文场景效果较好。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
model | str | "text-embedding-v1" | 否 | 嵌入模型名称(达摩院支持的模型,如 "text-embedding-v2")。 |
api_key | str | None | 否 | 达摩院 API 密钥(若为 None,从环境变量 DASHSCOPE_API_KEY 读取)。 |
timeout | int | 60 | 否 | 请求超时时间(秒)。 |
db:存储文本片段的向量数据(embeddings 生成的向量),并提供高效的向量相似度检索功能。
FAISS.from_documents():langchain_community.vectorstores 中 FAISS 向量存储 的类方法,从 Document 对象列表创建 FAISS 向量库:自动调用嵌入模型将文档文本转为向量,并存入 FAISS 索引,用于后续相似性检索(RAG 核心步骤)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
documents | List[Document] | 无 | 是 | 拆分后的 Document 列表(需包含 page_content 文本)。 |
embedding | Embeddings | 无 | 是 | 嵌入模型实例(如 DashScopeEmbeddings、OpenAIEmbeddings)。 |
metadatas | Optional[List[dict]] | None | 否 | 元数据列表(若 documents 已含元数据,可省略)。 |
retriever:接收用户查询,从 db 中检索与查询最相似的文本片段,是连接用户问题与知识库的桥梁。
.as_retriever():向量存储(如 FAISS、Chroma)的 方法,将向量库转换为 检索器(Retriever),提供统一的相似性检索接口(如 get_relevant_documents()),用于在 RAG 中根据用户查询检索最相关的文档片段。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
search_kwargs | dict | {"k": 4} | 否 | 检索参数:- k:返回最相关的 k 个文档(默认 4);- filter:按元数据筛选(如 {"source": "doc1"})。 |
docs:存储与用户查询(如 "deepseek v3有多少参数")相关的文本内容,是后续生成回答的 “知识来源”。
.invoke():LangChain 中 **Runnable接口的核心同步调用方法 **,用于触发组件(如模型、链、检索器、提示词模板等)执行并返回结果。是连接 “组件定义” 与 “实际运行” 的桥梁,支持从输入到输出的端到端处理。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
input | 任意类型(因组件而异) | 无 | 是 | 组件的输入数据,类型随组件变化:- 模型(如ChatTongyi):BaseMessage列表或PromptValue;- 链(Chain):字典(键为输入变量);- 检索器(Retriever):查询字符串;- 提示词模板:字典(键为模板变量)。 |
config | RunnableConfig 或 None | None | 否 | 执行配置,包含:- callbacks:回调函数(日志、进度跟踪);- tags:标签(分类记录);- metadata:元数据;- configurable:动态参数(如切换模型)。 |
**kwargs | 任意 | 无 | 否 | 组件专属参数(如模型调用时临时覆盖temperature,不推荐,优先用config)。 |
.page_content:存储单个检索结果(doc)的具体文本内容,即从文档中匹配到的与查询相关的片段。
langchain_schema:LangChain 历史遗留的 数据结构 / 接口兼容模块,多数核心功能已迁移至 langchain_core,仅保留部分接口用于兼容旧代码(新开发优先用 langchain_core)。
langchain_schema.output_parser:输出解析基础接口,定义 BaseOutputParser 及基础解析器(如 StrOutputParser),功能与 langchain_core.output_parsers 一致,用于兼容旧代码。
langchain_schema.runnable:流程编排基础接口,定义 Runnable 接口及相关工具(如 RunnableSequence),功能与 langchain_core.runnables 一致,用于兼容旧代码。
template:定义模型生成回答的规则,明确要求 “仅基于提供的上下文({context})回答问题({question})”,避免模型编造信息。
prompt:封装 template 并提供格式化方法,用于将 context(检索到的文档)和 question(用户查询)填充到模板中,生成模型可接收的完整提示词。
ChatPromptTemplate():LangChain 中用于 构建聊天场景提示词模板 的类,支持多角色消息(如系统提示、用户输入、AI 回复),生成符合聊天模型(如通义千问、GPT)输入格式的 PromptValue 对象,是构建结构化对话的核心工具。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
messages | List[BaseMessagePromptTemplate] | 是 | 消息模板列表,每个元素对应一个角色的模板(如系统消息模板、用户消息模板)。 |
llm:基于检索到的上下文(context)和用户问题(question),生成自然语言回答。
ChatTongyi():langchain_community.chat_models 中用于 调用阿里云通义千问聊天模型 的类,封装了通义千问的 API 调用逻辑,提供与 LangChain 其他组件(如 ChatPromptTemplate、Runnable)兼容的接口,是国内场景下替代 OpenAI 模型的核心工具。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
model_name | str | "qwen-plus" | 否 | 通义千问模型名称(如 "qwen-plus" 标准版、"qwen-max" 增强版、"qwen-turbo" 轻量版)。 |
temperature | float | 0.7 | 否 | 模型随机性(0.0 = 确定性高,1.0 = 随机性高,范围 [0, 1])。 |
dashscope_api_key | str | None | 否 | 阿里云 DashScope API 密钥(建议通过环境变量 os.getenv("DASHSCOPE_API_KEY") 加载)。 |
rag_chain:封装 “用户查询→检索→提示词生成→模型调用→结果解析” 的完整 RAG 流程,实现端到端的问答功能。
{"question": RunnablePassthrough(), "context": retriever}:将用户输入作为question,同时调用retriever获取context(检索结果);| prompt:用question和context填充prompt,生成完整提示词;| llm:将提示词传入llm,生成回答;| StrOutputParser():将模型输出的AIMessage对象转换为纯字符串。
res:存储 RAG 流程的最终输出,即模型基于检索到的上下文对用户问题的回答。
import osfrom langchain_community.chat_models import ChatTongyi
from langchain_core.prompts import ChatPromptTemplate
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.embeddings.dashscope import DashScopeEmbeddings# 加载文档
loader = PyMuPDFLoader("./data/deepseek-v3-1-4.pdf")
pages = loader.load_and_split()# 文档切分
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512,chunk_overlap=200,length_function=len,add_start_index=True,
)texts = text_splitter.create_documents([page.page_content for page in pages[:1]]
)# 灌库
embeddings = DashScopeEmbeddings(model="text-embedding-v1", dashscope_api_key=os.getenv("DASHSCOPE_API_KEY")
)
db = FAISS.from_documents(texts, embeddings)# 检索 top-5 结果
retriever = db.as_retriever(search_kwargs={"k": 5})docs = retriever.invoke("deepseek v3有多少参数")for doc in docs:print(doc.page_content)print("----")from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough# Prompt模板
template = """Answer the question based only on the following context:
{context}Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)llm = ChatTongyi(model_name="qwen-max", api_key=os.environ["DASHSCOPE_API_KEY"], temperature=0.01)# Chain
rag_chain = ({"question": RunnablePassthrough(), "context": retriever}| prompt| llm| StrOutputParser()
)res = rag_chain.invoke("deepseek V3有多少参数")
print(res)
3.用 LCEL 实现模型切换(工厂模式)
langchain_core:LangChain 生态的底层核心模块,包含所有组件的基础数据结构、抽象接口和核心逻辑,是整个框架的 “骨架”,其他模块(如 langchain、langchain_openai)均基于此扩展。
langchain_core.runnables:langchain_core 中负责流程编排的子模块,提供 Runnable 接口及相关工具,用于将不同组件(模型、提示词、工具、解析器等)串联成 “链(Chain)”,实现复杂逻辑的有序执行(如 “输入→提示词→模型→解析→输出” 的流水线)。
langchain:LangChain 的主框架模块,基于 langchain_core 构建,集成了 “提示词管理、模型调用、工具链、记忆系统、文档处理” 等完整功能,是构建 LLM 应用的 “一站式入口”。
langchain.prompts:langchain 框架中专注于提示词管理的子模块,提供标准化的提示词模板工具,解决 “动态生成提示词、复用提示词结构、适配多角色消息” 等问题。
langchain_openai:LangChain 官方提供的OpenAI 生态集成模块,专门适配 OpenAI 及兼容其 API 的模型(如 GPT-3.5/4 系列、Azure OpenAI 等),提供统一接口调用这些模型的功能。
qw_model:通义千问(Qwen)大语言模型的实例,用于调用阿里云的 qwen-max 模型。
ds_model:DeepSeek 大语言模型的实例,用于调用 deepseek-r1 模型(同样通过阿里云 DashScope 平台)。
ChatOpenAI():LangChain(langchain_openai 模块)中用于初始化 OpenAI 聊天模型实例的类,封装了与 OpenAI 聊天模型(如 gpt-3.5-turbo、gpt-4o 等)的交互逻辑,提供统一接口调用 OpenAI 的 API,支持文本生成、工具调用等功能。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
model | str | "gpt-3.5-turbo" | 否 | 模型名称,如 "gpt-4o"、"gpt-4-turbo"、"gpt-3.5-turbo-1106" 等。 |
api_key | str | None | 否 | OpenAI API 密钥,若为 None 则从环境变量 OPENAI_API_KEY 读取。 |
base_url | str | None | 否 | 自定义 API 基础 URL(如代理地址或私有部署地址),默认使用 OpenAI 官方 URL。 |
temperature | float | 0.7 | 否 | 生成随机性(0.0~2.0),值越低回复越越确定。 |
max_tokens | int | None | 否 | 最大生成 token 数(输入 + 输出),超过则截断,默认由模型上下文窗口决定。 |
stop | List[str] 或 str | None | 否 | 生成终止符,出现时停止生成。 |
timeout | int | 30 | 否 | 超时时间(秒),超过则终止请求。 |
max_retries | int | 2 | 否 | 请求失败失败重试次数。 |
tools | List[Tool] | None | 否 | 绑定的工具列表,支持模型调用工具(需模型支持,如 gpt-3.5-turbo-0613)。 |
tool_choice | str 或 dict | "auto" | 否 | 工具调用策略:"auto"(自动)、"none"(不调用)或指定工具名。 |
**kwargs | 任意 | - | 否 | 其他 OpenAI API 支持的参数(如 top_p、frequency_penalty 等)。 |
model:可配置的模型选择器,支持运行时动态切换 qw_model(通义千问)和 ds_model(DeepSeek)。
通过 qw_model.configurable_alternatives() 方法创建,核心参数:
ConfigurableField(id="llm"):定义配置字段 ID 为llm(用于后续指定模型);default_key="qwen":默认使用qw_model(通义千问);deepseek=ds_model:添加deepseek选项,对应ds_model(DeepSeek)。后续可通过with_config(configurable={"llm": "qwen"/"deepseek"})动态选择使用哪个模型。
.configurable_alternatives():LangChain 中 Runnable 接口的配置方法,用于为流程组件(如模型、工具、链)定义 “可替换的实现方案”,支持动态切换不同的实现(如不同模型、不同检索器),无需修改整体流程逻辑,提升灵活性。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
name | str | 无 | 是 | 配置项名称(用于标识该可替换组件,如 "llm"、"retriever")。 |
default | Runnable | 无 | 是 | 默认实现(如默认模型 ChatOpenAI())。 |
alternatives | Dict[str, Runnable] | {} | 否 | 可选实现的字典,键为别名(如 "gpt4"、"claude"),值为对应 Runnable 实例(如 ChatAnthropic())。 |
**kwargs | 任意 | - | 否 | 其他配置参数(如验证逻辑、描述信息)。 |
.configurableFiled():LangChain 中用于标记组件可配置字段的工具,允许在 Runnable 组件(如模型、链、工具)中定义 “可动态修改的参数”,支持在运行时通过 config 参数调整组件属性(无需重新初始化组件),提升流程的灵活性(例如动态切换模型温度、调整检索阈值等)。
| 核心参数(装饰器形式) | 类型 | 描述 |
|---|---|---|
name | str | 配置字段的名称(用于在 config 中引用,如 "temperature")。 |
description | str | 字段描述(可选,用于文档说明)。 |
prompt:聊天提示词模板,用于生成符合模型输入格式的用户消息。
.from_messages():ChatPromptTemplate 类的类方法,用于从多角色消息模板列表创建聊天提示模板,支持整合 SystemMessagePromptTemplate、HumanMessagePromptTemplate 等,生成包含系统提示、用户输入等的结构化模板,最终用于生成模型可直接接收的 messages 列表。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
messages | List[Union[BaseMessagePromptTemplate, str, Tuple[str, str]]] | 无 | 是 | 消息模板列表,支持:- 消息模板类(如 SystemMessagePromptTemplate);- 纯文本(默认视为 HumanMessage);- 元组 (角色标识, 文本)(如 ("system", "你是助手"))。 |
.from_template():对于 PromptTemplate:从单一字符串模板创建提示词模板,自动解析变量(简化 PromptTemplate 初始化)。对于 ChatPromptTemplate:从单一字符串模板创建聊天提示模板,默认将模板视为 HumanMessage(简化单一角色提示词构建)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
template | str | 无 | 是 | 字符串模板(含 {变量}),默认作为 HumanMessage 内容(如 "请分析{text}")。 |
template_format | str | "f-string" | 否 | 模板格式("f-string" 或 "jinja2")。 |
validate_template | bool | True | 否 | 是否校验模板合法性(如占位符格式)。 |
chain:通过 LCEL(LangChain Expression Language)构建的完整处理链,实现 “输入→提示词生成→模型调用→输出解析” 的端到端流程。
{"query": RunnablePassthrough()} # 1. 接收输入(如用户问题),传递给 "query" 变量
| prompt # 2. 用 prompt 模板将 "query" 转为模型输入消息
| model # 3. 调用选中的模型(qw_model 或 ds_model)生成响应
| StrOutputParser() # 4. 将模型响应解析为纯字符串.RunnablePassthrough():LangChain 中 Runnable 接口的工具类,用于在链(Chain)中传递输入数据而不做修改,或通过 assign 方法添加额外键值对(扩展上下文),是流程编排中连接不同组件的 “桥梁”。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
assign | dict | None | 否 | 键值对字典,用于在传递输入时添加新字段(值可以是静态数据或函数)。示例:RunnablePassthrough(assign={"timestamp": datetime.now})。 |
StrOutputPasser():LangChain 中最常用的输出解析器,用于将模型返回的 AIMessage 对象(或其他包含 content 属性的响应对象)解析为纯字符串,直接提取 content 字段的值,简化从模型响应中获取文本结果的流程(避免手动访问 response.content)。
ret1:使用 DeepSeek 模型执行 chain 后得到的结果(即 deepseek-r1 对问题的回答)。
ret2:使用 通义千问 模型执行 chain 后得到的结果(即 qwen-max 对问题的回答)。
chain.with_config():LangChain 中 Chain 或 Runnable 对象的配置方法,用于为链的执行设置额外配置(如回调、标签、元数据等),控制链的执行行为(如日志记录、追踪、权限控制),不改变链的核心逻辑。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
callbacks | List[BaseCallbackHandler] | None | 否 | 回调函数列表,监听链执行事件(如开始、结束、错误),用于日志、进度跟踪。 |
tags | List[str] | None | 否 | 标签列表(如 "rag_chain"、"user_123"),用于分类或筛选链执行记录。 |
metadata | dict | None | 否 | 元数据字典(如 {"version": "1.0"}),附加到链执行信息中。 |
run_name | str | None | 否 | 链执行的名称(用于日志或追踪中标识该次运行)。 |
max_concurrency | int | None | 否 | 最大并发数(用于并行执行的链)。 |
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_core.runnables.utils import ConfigurableField
from langchain.prompts import (ChatPromptTemplate,HumanMessagePromptTemplate,
)
import osfrom langchain_openai import ChatOpenAI# 模型1
qw_model = ChatOpenAI(model="qwen-max", # 通义千问api_key=os.getenv("DASHSCOPE_API_KEY"),base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)# 模型2
ds_model = ChatOpenAI(model="deepseek-r1", # DeepSeekapi_key=os.getenv("DASHSCOPE_API_KEY"),base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)# 通过 configurable_alternatives 按指定字段选择模型
model = qw_model.configurable_alternatives(ConfigurableField(id="llm"),default_key="qwen",deepseek=ds_model,# claude=claude_model,
)# Prompt 模板
prompt = ChatPromptTemplate.from_messages([HumanMessagePromptTemplate.from_template("{query}"),]
)# LCEL
chain = ({"query": RunnablePassthrough()}| prompt| model| StrOutputParser()
)# 运行时指定模型 "qwen" or "deepseek"
ret1 = chain.with_config(configurable={"llm": "deepseek"}).invoke("请介绍你的模型结构")print(ret1)print("----------------------------------------------------------------------------------------------------------------")
ret2 = chain.with_config(configurable={"llm": "qwen"}).invoke("请介绍你的模型结构")print(ret2)
扩展阅读:什么是工厂模式;设计模式概览。
4.ICEL的其他功能
- 配置运行时变量:https://python.langchain.com/docs/how_to/configure/
- 故障回退:https://python.langchain.com/docs/how_to/fallbacks/
- 并行调用:https://python.langchain.com/docs/how_to/parallel/
- 逻辑分支:https://python.langchain.com/docs/how_to/routing/
- 动态创建 Chain: https://python.langchain.com/docs/how_to/dynamic_chain/
更多例子:https://python.langchain.com/docs/how_to/lcel_cheatsheet/
四、LangChain与LlamaIndex的错位竞争
- LangChain 侧重与 LLM 本身交互的封装
- Prompt、LLM、Message、OutputParser 等工具丰富
- 在数据处理和 RAG 方面提供的工具相对粗糙
- 主打 LCEL 流程封装
- 配套 Agent、LangGraph 等智能体与工作流工具
- 另有 LangServe 部署工具和 LangSmith 监控调试工具
- LlamaIndex 侧重与数据交互的封装
- 数据加载、切割、索引、检索、排序等相关工具丰富
- Prompt、LLM 等底层封装相对单薄
- 配套实现 RAG 相关工具
- 同样配套智能体与工作流工具
- 提供 LlamaDeploy 部署工具,通过与三方合作提供过程监控调试工具
注:LangGraph在下一篇单独进行讲解
总结
① LangChain 随着版本迭代可用性有明显提升
② 使用 LangChain 要注意维护自己的 Prompt,尽量 Prompt 与代码逻辑解依赖
③ 它的内置基础工具,建议充分测试效果后再决定是否使用