[人工智能-大模型-87]:模型层技术 - “神经网络架构演进的全景地图”,“从简单到复杂、从单一到智能” - 通俗易懂版。
我们用“从简单到复杂、从单一到智能”的思路,把神经网络的演进比作一个“人工智能大脑的进化史”,用通俗易懂的话来讲述它的发展过程。
🧠 想象一下:我们是在教一个“电子大脑”学会看、听、说、思考和创造。
1. 神经元MCP(1943年)——“电子神经细胞”的诞生
🧩 就像灯的开关:亮 or 灭
- 背景:科学家发现人脑由神经元组成,于是想造一个“电子版”。
- MCP模型(McCulloch-Pitts Neuron)是第一个数学模型,像一个简单的开关:
- 输入:几个信号(比如“今天下雨吗?”“带伞了吗?”)
- 处理:加权求和
- 输出:是 or 否(1 or 0)
✅ 意义:第一次用数学模拟“神经元”,是AI的起点。
🌰 例子:如果“下雨”且“没带伞”,就输出“要淋湿” → 触发“快跑”指令。
2. 单层感知机(Perceptron,1958年)——会“学习”的简单大脑
🧩 像一个小学生,能从错误中改错
- 在MCP基础上加了“学习能力”:可以自动调整权重。
- 只能解决线性问题(比如:用一条直线分开红点和蓝点)。
- 但遇到“异或问题”(XOR)就傻眼了—— 使用直线,不开0和1,区分不了0和1。该升级网络学不了,解决不了!这就是MCP的异或问题。
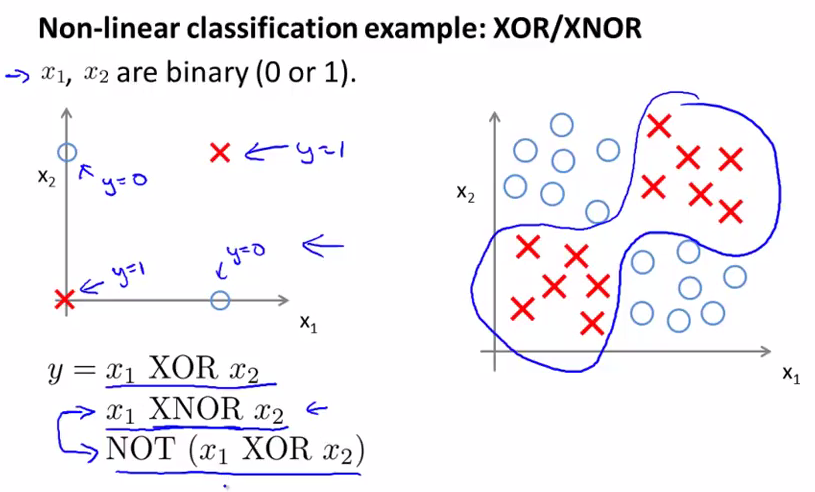
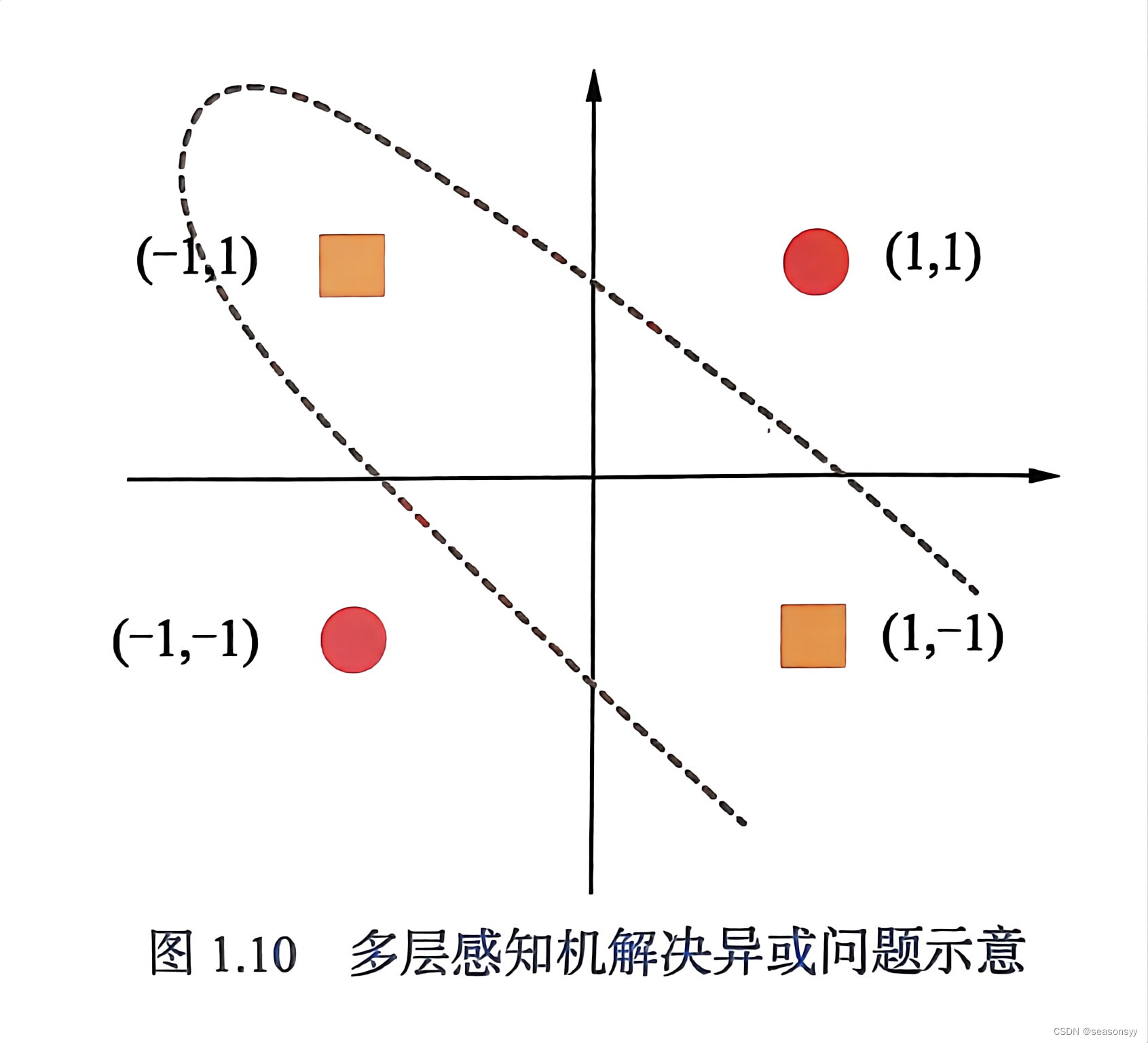
❌ 局限:太简单,解决不了复杂问题。
🌰 例子:能学会“如果下雨 + 没伞 → 要躲雨”,但学不会更复杂的逻辑。
3. 深度全连接网络(FCN / MLP,1980s)——多层“神经网络”来了
🧩 像搭积木:一层接一层,越深越聪明
- 把多个感知机堆起来,形成“多层神经网络”(MLP)。
- 中间层叫“隐藏层”,能提取更复杂的特征。
- 配合“反向传播算法”(BP),可以自动调整所有层的参数。
✅ 突破:能解决非线性问题,比如识别手写数字。
🌰 例子:输入一张手写“8”,网络通过多层计算,最终输出“这是8”。
4. 卷积神经网络(CNN,1998年兴起,2012年爆发)——专为“看图”而生
🧩 像显微镜+特征探测器:专门识别图像
- 图像有“局部相关性”(比如眼睛、鼻子是局部特征)。
- CNN用“卷积核”像小窗口一样在图上滑动,检测边缘、纹理、形状。
- 再用“池化”缩小图像,保留重要信息,得到图形中的特征。
- 最后用全连接层根据前面得到的特征判断是什么。
✅ 成就:让AI能“看懂”图片,用于人脸识别、自动驾驶、医学影像。
🌰 例子:输入一张猫的照片,CNN先找“耳朵”“胡须”“眼睛”,再判断“这是一只猫”。
5. 循环神经网络(RNN / LSTM,1990s-2000s)——会“记时间”的大脑
🧩 像录音机:记住前面的内容,理解顺序
- 传统网络只看“当前输入”,但语言、语音、股价都有“时间顺序”。
- RNN有个“记忆环”,能把上一步的结果传给下一步。
- 但普通RNN记不住太久(“健忘”)。
- LSTM(长短期记忆)加了“门控机制”,能选择记住或忘记。
✅ 应用:语音识别、机器翻译、写文章、预测股价。
🌰 例子:输入“今天天气很好,所以我去___”,RNN能根据前面内容预测“公园”。
6. 生成对抗网络(GAN,2014年)——“造假高手”与“鉴伪专家”对决
🧩 像画家和警察比赛:一个造,一个抓
- 两个网络“打架”:
- 生成器(Generator):伪造图片(比如假人脸)
- 判别器(Discriminator):判断是真是假
- 两者不断对抗,越练越强,直到判别器依据指定的特征,判决不了是原始图片和伪造图片!!!
- 最终生成器能造出真假难辨的图像。
✅ 应用:AI绘画、换脸、超分辨率、艺术创作。
🌰 例子:输入“画一个穿汉服的宇航员”,GAN能生成一张逼真的图。
7. 强化学习 DQN(2015年)——“打游戏练出的AI高手”
🧩 像玩游戏:试错+奖励,越玩越强
- AI不是被“教”,而是自己“试”。
- 在环境中行动,得到“奖励”或“惩罚”。
- 目标:最大化长期奖励。
- DQN(深度Q网络)用神经网络来预测“哪个动作最赚”。
✅ 成就:AlphaGo 打败人类围棋冠军!
🌰 例子:AI玩“打砖块”游戏,一开始乱打,但每次得分就奖励,慢慢学会精准击球。
8. 注意力机制 & Transformer(2017年)——“抓重点”的超级大脑
🧩 像阅读时划重点:只关注关键信息
- 以前RNN要一个字一个字读,太慢。
- 注意力机制:让AI“一眼扫全文”,直接找到关键词。
- Transformer:完全抛弃RNN,只用“注意力”处理序列。
- 能并行计算,速度快,效果好。
✅ 革命性:成为大模型(如GPT、BERT)的基础。
🌰 例子:句子“小明喜欢苹果,因为他每天吃一个。”
AI通过注意力发现“他”指的是“小明”,“苹果”是水果不是公司。
9. 多模态混合与扩展架构(2020s - 现在)——“全能型AI”登场
🧩 像一个全才:能看、能听、能说、能想
- 单一模型只能处理一种数据(文本 or 图像)。
- 多模态模型能同时处理多种信息:
- 图像 + 文本(如:CLIP、Flamingo)
- 语音 + 文本(如:Whisper)
- 视频 + 音频 + 文本
- 用Transformer作为“通用引擎”,连接不同模态。
✅ 应用:
- 输入一张图 + 问“这是什么?”,AI回答“一只在草地上奔跑的金毛犬”
- AI生成“一段带配乐的短视频”
- 智能眼镜实时翻译看到的文字并朗读
🌟 代表:GPT-4V(视觉)、Gemini、Qwen-VL、Meta Llama-3 多模态版
📊 总结:神经网络的“进化树”
MCP神经元(开关)↓
单层感知机(会学习)↓
深度全连接网络(多层神经网络)├──→ 卷积神经网络(CNN) → 擅长“看图”├──→ 循环神经网络(RNN/LSTM) → 擅长“听和说”├──→ 生成对抗网络(GAN) → 擅长“造假”├──→ 强化学习(DQN) → 擅长“试错与决策”└──→ 注意力机制 → Transformer(核心突破)↓多模态大模型(GPT、Gemini等) → 全能AI✅ 一句话总结每一代
| 架构 | 一句话 |
|---|---|
| MCP | “神经元的起点,像一个开关” |
| 感知机 | “会改错的小学生” |
| 深度网络 | “搭积木,越深越聪明” |
| CNN | “专为看图而生的显微镜” |
| RNN/LSTM | “记得住前后顺序的记忆大师” |
| GAN | “造假高手和鉴伪专家打架” |
| DQN | “靠打游戏练出的冠军” |
| Transformer | “一眼抓重点的阅读高手” |
| 多模态 | “能看、能听、能说的全能AI” |
AI的强项在于语音、语言(自然语言与计算机语言)、文字、图形、视频。而不是逻辑处理!!!